【Java虚拟机(JVM)全面解析】从原理到面试实战、JVM故障处理、类加载、内存区域、垃圾回收
文章目录
- 前言
- 1. JVM核心基础:架构与内存区域
- 1.1 JVM整体架构
- 1.2 运行时数据区(线程共享vs私有)
- 关键补充:
- 1.3 JDK 1.6~1.8内存区域变化
- 迁移原因:
- 2. 对象模型:创建、布局与访问
- 2.1 对象创建的完整流程
- 线程安全:
- 2.2 对象的内存布局(HotSpot)
- 示例:`new Object()`的大小
- 2.3 对象的4种引用类型
- 3. 垃圾收集(GC):从原理到收集器
- 3.1 如何判断对象存活?
- 1. GC Roots的类型:
- 2. 对比引用计数法:
- 3.2 4种垃圾收集算法对比
- 3.3 主流垃圾收集器详解
- 重点收集器流程:
- 3.4 Minor GC/Major GC/Full GC区别
- 4. 类加载机制:双亲委派与热部署
- 4.1 类的生命周期
- 4.2 类加载器体系与双亲委派模型
- 1. 类加载器种类:
- 2. 双亲委派模型:
- 5. JVM调优与问题排查实战
- 5.1 常用监控工具
- 1. 命令行工具:
- 2. 可视化工具:
- 5.2 核心JVM参数配置
- 1. 堆内存配置:
- 2. GC收集器配置:
- 3. GC日志配置:
- 5.3 高频问题排查流程
- 1. CPU占用过高:
- 2. 内存飙高/频繁Full GC:
- 6. 面试高频问题总结
- 总结
前言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在Java开发中,JVM是跨平台特性的基石,也是面试中的“必考点”——从内存区域划分到垃圾回收机制,从类加载流程到性能调优,每一个模块都直接影响程序的稳定性与性能。系统梳理JVM核心知识点,结合高频面试题与实战案例,帮你彻底掌握JVM,应对面试与工作中的技术难题。
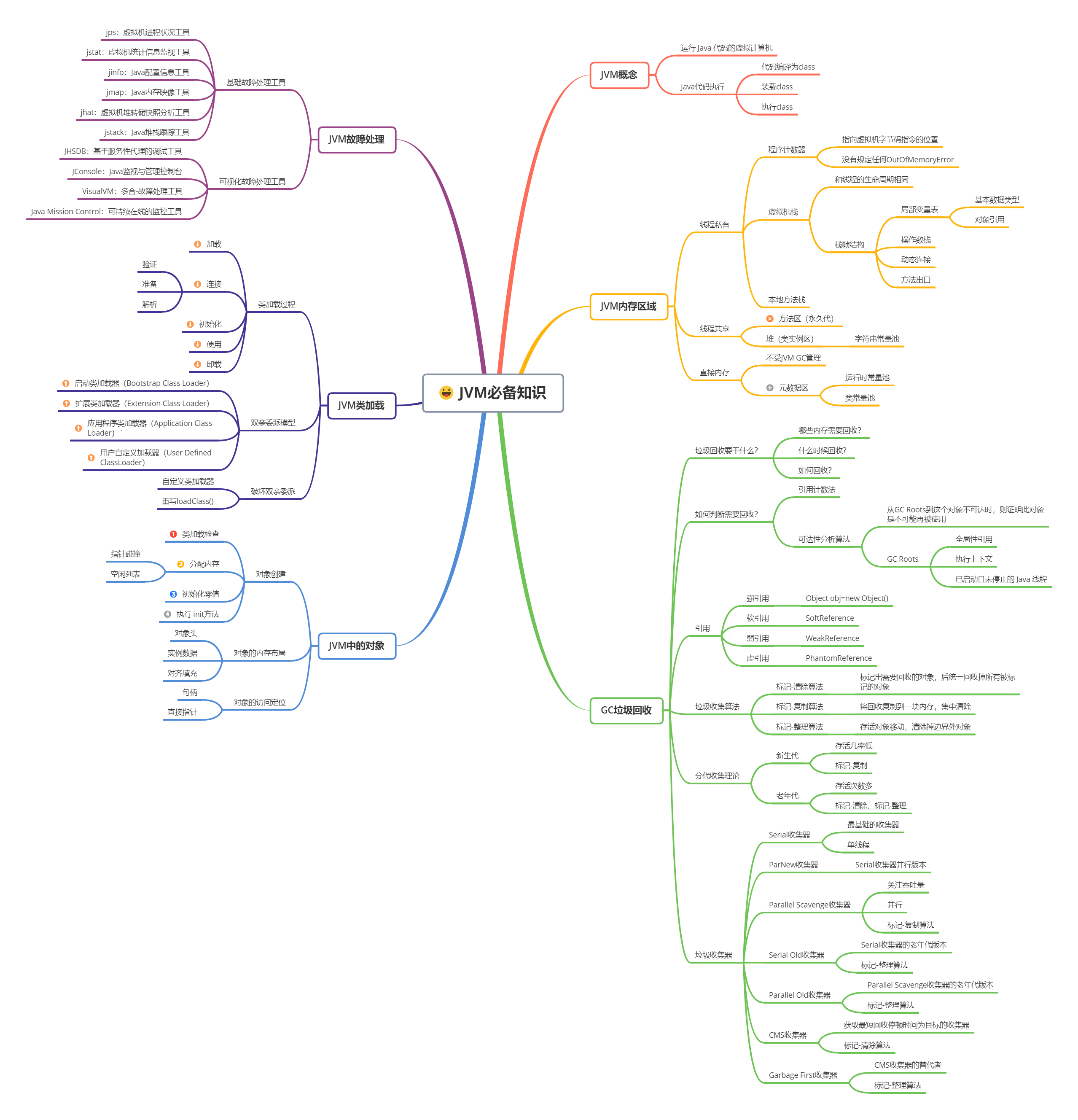
1. JVM核心基础:架构与内存区域
1.1 JVM整体架构
JVM主要由类加载器、运行时数据区、执行引擎三部分组成,是Java“一次编译,处处运行”的核心:
- 类加载器:加载Class文件到内存,验证、准备、解析类信息;
- 运行时数据区:存储程序运行中的数据(堆、方法区、虚拟机栈等);
- 执行引擎:解析字节码,通过解释器逐行执行,热点代码由JIT编译器编译为机器码加速。
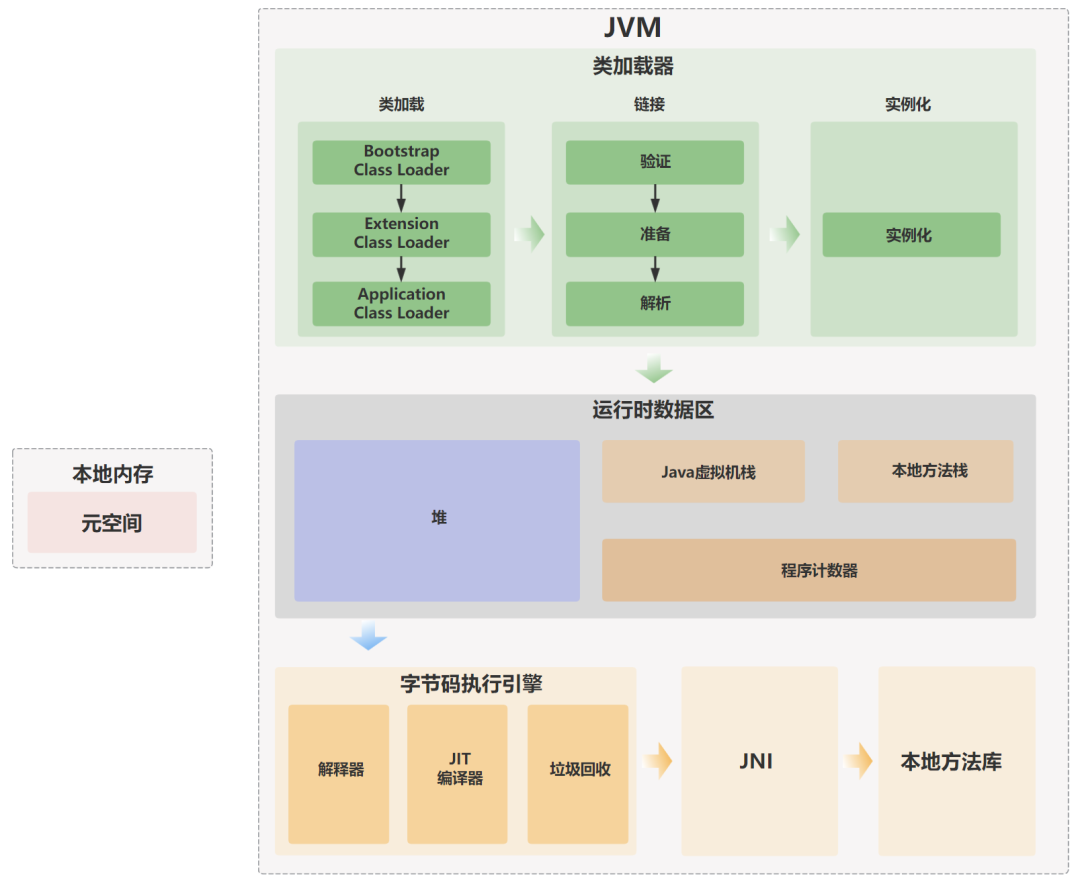
graph TDA[JVM架构] --> B[类加载器]A --> C[运行时数据区]A --> D[执行引擎]B --> B1[启动类加载器(Bootstrap)]B --> B2[扩展类加载器(Extension)]B --> B3[应用类加载器(Application)]B --> B4[自定义类加载器]C --> C1[线程共享:堆+方法区(元空间)]C --> C2[线程私有:程序计数器+虚拟机栈+本地方法栈]D --> D1[解释器]D --> D2[JIT编译器]D --> D3[垃圾回收器]
1.2 运行时数据区(线程共享vs私有)
Java虚拟机规范将运行时数据区划分为5个部分,核心区别是“线程共享”与“线程私有”:
| 内存区域 | 线程共享/私有 | 核心作用 | 关键特性 |
|---|---|---|---|
| 程序计数器 | 私有 | 存储当前线程执行的字节码行号指示器 | 唯一不会OOM的区域,CPU切换线程的“快照” |
| 虚拟机栈 | 私有 | 存储方法栈帧(局部变量表、操作数栈等) | 栈深度超过阈值抛StackOverflowError |
| 本地方法栈 | 私有 | 为Native方法(C/C++实现)提供栈空间 | 与虚拟机栈逻辑一致,仅服务Native方法 |
| 堆 | 共享 | 存储new创建的对象,GC主要区域 | JDK 8后分为新生代(Eden+Survivor)+老年代 |
| 方法区(元空间) | 共享 | 存储类信息、常量、静态变量、JIT编译缓存 | JDK 8前为永久代,8后改为元空间(本地内存) |
关键补充:
- 虚拟机栈的栈帧:每个方法调用对应一个栈帧,方法执行完自动出栈,局部变量表存储this(非静态方法)、参数、局部变量;
- 堆的分代:新生代(Eden:S0:S1=8:1:1)用于短期对象,老年代用于长期对象,大对象(>Region 50%)直接进入G1的Humongous区。
1.3 JDK 1.6~1.8内存区域变化
JDK版本迭代中,方法区的实现是核心变化点,从“永久代”迁移到“元空间”,原因与差异如下:
| JDK版本 | 方法区实现 | 核心存储内容 | 内存限制 | 问题点 |
|---|---|---|---|---|
| 1.6 | 永久代 | 类信息、字符串常量池、静态变量 | -XX:MaxPermSize(默认64M/85M) | 易OOM,依赖JVM内存限制 |
| 1.7 | 永久代 | 类信息,字符串常量池/静态变量移至堆 | 同1.6 | 部分缓解OOM,仍有永久代限制 |
| 1.8 | 元空间 | 仅类信息(常量/静态变量在堆) | 依赖本地内存(无JVM限制) | 彻底解决OOM,兼容JRockit特性 |
迁移原因:
- 客观:永久代有固定大小上限,易触发OOM;元空间使用本地内存,仅受系统内存限制;
- 主观:Oracle收购BEA后,需整合JRockit(无永久代)特性,元空间统一实现方案。
2. 对象模型:创建、布局与访问
2.1 对象创建的完整流程
使用new关键字创建对象时,JVM执行4步核心操作:
- 类加载检查:判断类是否已加载(未加载则执行类加载流程:加载→验证→准备→解析→初始化);
- 内存分配:从堆中分配内存(指针碰撞:内存连续;空闲列表:内存碎片化,老年代用);
- 内存初始化:将分配的内存清零(成员变量默认值:0/false/null);
- 对象头设置:填充Mark Word(哈希码、GC分代年龄、锁状态)、类型指针(指向类元数据),数组对象额外存储数组长度;
- 执行():调用构造方法,为成员变量赋值(如
int age=18)。
线程安全:
- 内存分配时可能出现线程抢占,JVM通过TLAB(线程本地分配缓冲区) 解决:每个线程预分配一小块堆内存,优先从TLAB分配,耗尽后再竞争全局内存。
2.2 对象的内存布局(HotSpot)
HotSpot中,对象内存分为3部分,总大小需8字节对齐(64位JVM):
| 组成部分 | 大小(64位JVM) | 核心内容 |
|---|---|---|
| 对象头(Mark Word+类型指针) | 12字节(压缩指针) | Mark Word:哈希码、GC年龄、锁状态;类型指针:指向类元数据 |
| 实例数据 | 按需分配 | 成员变量(按类型对齐,如int4字节、long8字节) |
| 对齐填充 | 0~7字节 | 保证总大小为8字节倍数,提升CPU访问效率 |
示例:new Object()的大小
- 64位JVM+压缩指针:对象头12字节 + 对齐填充4字节 = 16字节;
- 关闭压缩指针:对象头16字节 + 对齐填充0字节 = 16字节。
2.3 对象的4种引用类型
Java通过引用类型控制对象的生命周期,核心区别是GC回收时机:
| 引用类型 | 实现类 | 回收时机 | 适用场景 |
|---|---|---|---|
| 强引用 | 直接赋值(Object o=new Object()) | 仅当引用断开时回收 | 普通对象(如业务对象) |
| 软引用 | SoftReference | 内存不足时回收 | 缓存(如图片缓存) |
| 弱引用 | WeakReference | 下次GC时必回收 | ThreadLocal的Entry、临时缓存 |
| 虚引用 | PhantomReference | 任何时候可回收,仅跟踪GC过程 | 监控对象回收(如资源释放) |
3. 垃圾收集(GC):从原理到收集器
3.1 如何判断对象存活?
JVM通过可达性分析算法判断对象是否存活,核心是“从GC Roots出发,不可达的对象为垃圾”。
1. GC Roots的类型:
- 虚拟机栈中引用的对象(局部变量、参数);
- 本地方法栈中JNI引用的对象;
- 类静态变量引用的对象;
- 运行时常量池中的常量引用(如String常量)。
2. 对比引用计数法:
- 引用计数法:通过计数器记录引用次数,0则回收,但无法解决循环引用(A引用B,B引用A);
- 可达性分析:彻底解决循环引用,是主流JVM的实现方案。
3.2 4种垃圾收集算法对比
不同代的对象特性不同,对应不同的GC算法:
| 算法 | 核心逻辑 | 优点 | 缺点 | 适用区域 |
|---|---|---|---|---|
| 标记-清除 | 标记垃圾→直接清除 | 实现简单 | 产生内存碎片,后续分配效率低 | 老年代(CMS) |
| 标记-复制 | 内存分两块,复制存活对象→清空原块 | 无碎片,效率高 | 浪费一半内存 | 新生代(Serial/ParNew) |
| 标记-整理 | 标记存活对象→向一端移动→清除边界外内存 | 无碎片,利用率高 | 移动对象成本高 | 老年代(Parallel Old/G1) |
| 分代收集 | 新生代用复制,老年代用标记-清除/整理 | 兼顾效率与利用率 | 实现复杂 | 全堆(主流方案) |
3.3 主流垃圾收集器详解
HotSpot提供多种收集器,核心差异在“并发/并行”“停顿时间”“内存碎片”:
| 收集器组合 | 新生代算法 | 老年代算法 | 并发特性 | 停顿时间 | 内存碎片 | 适用场景 |
|---|---|---|---|---|---|---|
| Serial+Serial Old | 复制 | 标记-整理 | 串行 | 长 | 无 | 单CPU、小内存(客户端) |
| ParNew+CMS | 复制 | 标记-清除 | 并发 | 短 | 有 | 低延迟服务(Web服务器) |
| Parallel Scavenge+Parallel Old | 复制 | 标记-整理 | 并行 | 中 | 无 | 高吞吐量服务(数据分析) |
| G1 | 复制+标记-整理 | 复制+标记-整理 | 并发 | 可控 | 无 | 大内存(>4G)、低延迟(电商/金融) |
重点收集器流程:
-
CMS(并发标记清除):4阶段,仅初始标记和重新标记STW:
- 初始标记:标记GC Roots直接可达对象(STW,快);
- 并发标记:遍历引用链,标记所有存活对象(与用户线程并发);
- 重新标记:修正并发标记的遗漏(STW,短);
- 并发清除:清除垃圾对象(与用户线程并发)。
-
G1(垃圾优先):基于Region的分代收集,支持可预测停顿:
- 并发标记:遍历全堆,计算每个Region的回收价值(垃圾占比);
- 混合收集:优先回收价值高的Region(含新生代+部分老年代);
- 整理:回收后压缩Region,无碎片。
3.4 Minor GC/Major GC/Full GC区别
| GC类型 | 触发区域 | 触发条件 | 影响范围 |
|---|---|---|---|
| Minor GC(Young GC) | 新生代 | Eden区满 | 仅新生代,停顿短 |
| Major GC | 老年代 | 老年代空间不足(CMS特有) | 仅老年代,停顿较长 |
| Full GC | 全堆+元空间 | 老年代满、元空间满、System.gc() | 全堆回收,停顿最长,应避免 |
4. 类加载机制:双亲委派与热部署
4.1 类的生命周期
类从加载到卸载,经历7个阶段,核心是“加载→链接→初始化”三阶段:
- 加载:读取Class文件,生成Class对象;
- 链接:验证(格式校验)→准备(静态变量赋默认值)→解析(符号引用转直接引用);
- 初始化:执行静态代码块+静态变量赋值(执行()方法);
- 使用:对象实例化、方法调用;
- 卸载:类加载器被回收,类对象无引用。
4.2 类加载器体系与双亲委派模型
1. 类加载器种类:
| 类加载器 | 加载路径 | 父加载器 | 核心作用 |
|---|---|---|---|
| 启动类加载器 | JAVA_HOME/jre/lib(rt.jar等) | 无(C++实现) | 加载JVM核心类库 |
| 扩展类加载器 | JAVA_HOME/jre/lib/ext | 启动类加载器 | 加载扩展类库 |
| 应用类加载器 | ClassPath(项目类、第三方jar) | 扩展类加载器 | 加载应用业务类 |
| 自定义类加载器 | 自定义路径(如网络、加密文件) | 应用类加载器 | 热部署、加密类加载 |
2. 双亲委派模型:
- 核心规则:类加载器收到请求时,先委托父加载器加载,父加载器无法加载时才自己加载;
- 好处:1)避免类重复加载;2)保护核心类库(如java.lang.String无法被篡改);
- 破坏场景:1)SPI加载JDBC驱动(线程上下文类加载器);2)Tomcat类加载(WebApp优先加载自身类)。
5. JVM调优与问题排查实战
5.1 常用监控工具
1. 命令行工具:
| 工具 | 核心命令 | 作用 |
|---|---|---|
| jps | jps -l | 查看Java进程ID |
| jstat | jstat -gcutil 12345 5000 10 | 每5秒输出GC统计,共10次 |
| jmap | jmap -heap 12345 jmap -dump:format=b,file=heap.hprof 12345 | 查看堆信息 生成堆快照 |
| jstack | jstack -l 12345 > thread.log | 查看线程堆栈,定位死锁/CPU高 |
2. 可视化工具:
- VisualVM:集成JDK工具,支持堆分析、GC监控、线程分析;
- MAT(Memory Analyzer Tool):分析堆快照,定位内存泄漏;
- Arthas:阿里开源,在线排查(无侵入),支持trace、jad反编译。
5.2 核心JVM参数配置
1. 堆内存配置:
-Xms2g -Xmx2g # 初始堆=最大堆=2G(避免频繁扩容)
-Xmn1g # 新生代=1G(建议占堆的1/2~1/3)
-XX:SurvivorRatio=8 # Eden:S0:S1=8:1:1
2. GC收集器配置:
# 使用G1收集器,目标停顿100ms
-XX:+UseG1GC -XX:MaxGCPauseMillis=100
# 使用CMS收集器
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
3. GC日志配置:
-Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
5.3 高频问题排查流程
1. CPU占用过高:
top找到高CPU进程ID(如12345);top -Hp 12345找到高CPU线程ID(如1234);printf "%x\n 1234"将线程ID转为十六进制(如4d2);jstack 12345 | grep 4d2 -A 20查看线程堆栈,定位死循环/热点方法。
2. 内存飙高/频繁Full GC:
jstat -gcutil 12345 1000观察GC频率(Full GC频繁则异常);jmap -dump:format=b,file=heap.hprof 12345生成堆快照;- 用MAT分析快照,查看大对象/泄漏对象(如静态集合未清理、ThreadLocal未remove);
- 优化代码(如释放资源、减少大对象创建)。
6. 面试高频问题总结
-
JVM内存区域划分?堆和栈的区别?
答:分线程共享(堆、元空间)和私有(程序计数器、虚拟机栈、本地方法栈);堆存对象(生命周期长,GC管理),栈存栈帧(局部变量,方法结束释放)。 -
为什么用元空间替代永久代?
答:永久代有JVM内存限制,易OOM;元空间用本地内存,无限制,且兼容JRockit特性。 -
CMS和G1的区别?
答:CMS用标记-清除(有碎片),并发收集(低延迟);G1用Region+标记-整理(无碎片),支持可预测停顿,适合大内存。 -
双亲委派模型的好处?如何破坏?
答:好处是避免类重复加载、保护核心类库;破坏方式是重写ClassLoader的loadClass(),如Tomcat类加载、SPI加载JDBC。
总结
JVM是Java生态的基石,掌握其内存模型、垃圾收集、类加载机制,不仅能应对面试,更能在工作中快速排查性能问题(如内存泄漏、频繁GC)。本文基于高频面试题梳理核心知识点,建议结合实际工具(如jmap、VisualVM)动手实践,才能真正内化。后续可深入学习ZGC(低延迟收集器)、JVM字节码等进阶内容,进一步提升技术深度。