《早期经验:语言智能体学习的中间道路》Agent Learning via Early Experience论文深度解读
一、研究背景与核心矛盾
1.1 语言智能体的现状困境
当前语言智能体面临两难选择:
| 训练范式 | 优势 | 致命缺陷 |
|---|---|---|
| 模仿学习(Imitation Learning) | • 无需奖励信号 • 训练稳定高效 | • 依赖昂贵的专家数据 • 分布偏移导致泛化能力差 • 无法从失败中学习 |
| 强化学习(Reinforcement Learning) | • 可持续自我改进 • 潜力达到超人性能 | • 许多环境缺乏可验证奖励 • 长期rollout效率低下 • 训练不稳定 |
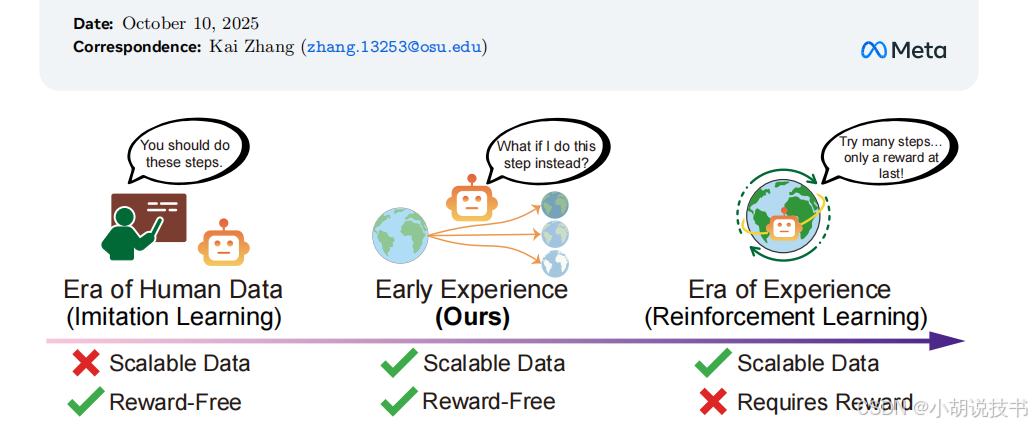
核心洞察:真实世界的多数环境(如网页导航、多轮工具使用)既缺少密集奖励信号,又难以获取大规模专家数据。这构成了当前AI智能体发展的根本瓶颈。
1.2 "早期经验"范式的提出
早期经验(Early Experience)是一个介于模仿学习和强化学习之间的中间范式:
- 数据来源:智能体自己探索产生的状态转移
- 监督信号:未来状态本身(而非奖励)
- 关键特性:无需奖励、可扩展、增强泛化
二、方法论:两条技术路径
2.1 隐式世界建模(Implicit World Modeling)
核心思想
将环境动力学的学习整合到策略模型中,而非构建独立的模拟器。
技术实现
训练目标:
L_IWM = -Σ log p_θ(s'_j | s_i, a'_j)
其中:
s_i:当前状态a'_j:智能体提议的替代动作(包含专家动作)s'_j:执行a'_j后的真实下一状态
数据构建流程:
- 专家轨迹重构:将专家演示中的每一步
(s, a, s')转换为世界模型格式 - 探索性增强:在每个专家状态
s_i处,采样K个替代动作{a'_1, ..., a'_K} - 真实执行:在环境中执行每个
a'_j,获取真实的下一状态s'_j - 规模放大:从N个专家状态-动作对扩展到N×(K+1)个训练样本
训练策略:
- 第一阶段:用世界模型目标
L_IWM预训练 - 第二阶段:继续用标准模仿学习目标
L_IL微调 - 关键:总训练步数保持不变,确保公平比较
适用场景
特别有效于:
- 状态转移规律稳定的环境(如网页购物、家居导航)
- 动作空间有限但需要理解后果的任务
2.2 自我反思(Self-Reflection)
核心思想
让智能体对比自己的动作和专家动作,生成自然语言解释为何专家选择更优,并用这些解释作为训练信号。
技术实现
训练目标:
L_SR = -Σ log p_θ(c_j, a_expert | s_i)
其中:
c_j:对比动作a'_j和专家动作a_expert后生成的思维链- 联合训练思维链和动作预测
数据构建流程:
-
对比场景构造:
- 当前状态
s_i - 专家动作
a_expert及其结果s_expert - K个替代动作
{a'_1, ..., a'_K}及其结果{s'_1, ..., s'_K}
- 当前状态
-
反思生成(使用LLM):
- 输入:状态、专家动作及结果、替代动作及结果
- 输出:自然语言推理链
c_j,解释为何专家动作考虑了约束、效率、长期目标等因素
-
质量过滤:去除结论与专家动作不一致的低质量样本
反思提示模板关键要素
- 情境描述:当前任务和状态
- 对比分析:逐一分析每个替代动作的潜在问题
- 正面论证:基于观察到的未来状态,论证专家动作的优越性
- 约束意识:强调预算、规则、长期目标等多重约束
适用场景
特别有效于:
- 需要复杂推理的长期规划任务(如旅行计划)
- 涉及多重约束权衡的决策场景
- 失败模式复杂多样的环境
三、实验验证:全景评估
3.1 实验设计的系统性
环境覆盖矩阵
| 环境类型 | 代表环境 | 状态空间复杂度 | 动作空间类型 | 主要挑战 |
|---|---|---|---|---|
| 具身导航 | ALFWorld | 低(简洁文本) | 封闭有限 | 多步序列决策 |
| 科学模拟 | ScienceWorld | 中(过程描述) | 封闭有限 | 实验设计与因果推理 |
| 长期规划 | TravelPlanner | 中(结构化) | 结构化大集合 | 多约束优化 |
| 多轮工具使用 | SearchQA, BFCLv3, Tau-Bench | 中到高 | 结构化或开放 | 工具组合与参数选择 |
| 网页导航 | WebShop, WebArena | 极高(DOM树) | 开放组合式 | 信息提取与细粒度操作 |
模型规模覆盖
- 小模型:Llama-3.2-3B
- 中等模型:Qwen-2.5-7B, Llama-3.1-8B
- 大模型:Llama-3.3-70B(WebArena子集)
3.2 核心实验结果
主要性能提升
平均绝对提升(相对于模仿学习基线):
- 任务成功率:+9.6%
- 域外泛化:+9.4%
典型案例:
| 环境 | 基线(模仿学习) | 隐式世界建模 | 自我反思 | 最佳提升 |
|---|---|---|---|---|
| WebShop (Llama-3.2-3B) | 41.8% | 60.2% (+18.4) | 52.7% (+10.9) | +18.4% |
| TravelPlanner (Qwen-2.5-7B) | 16.7% | 22.2% (+5.5) | 31.7% (+15.0) | +15.0% |
| ScienceWorld (Llama-3.1-8B) | 54.7% | 57.0% (+2.3) | 68.0% (+13.3) | +13.3% |
强化学习协同效应
在可获得奖励的环境中,用早期经验训练的检查点作为强化学习的初始化:
WebShop(Llama-3.2-3B):
- 仅模仿学习 → GRPO:82.0%
- 隐式世界建模 → GRPO:92.2% (+10.2)
- 自我反思 → GRPO:89.8% (+7.8)
关键发现:早期经验不仅直接提升性能,其收益可传递到后续的强化学习阶段,最终模型性能显著更高。
3.3 数据效率分析
实验设置:固定总训练预算,变化专家演示数量
关键结果(WebShop, Llama-3.1-8B):
- 仅1/8专家数据的早期经验方法(58.6%)> 全量专家数据的模仿学习(47.3%)
- ALFWorld中1/2专家数据即可超越全量模仿学习
启示:早期经验提供了超越专家演示覆盖范围的额外监督信号。
四、深层机制分析
4.1 为何有效:从认知视角理解
元认知层面
模仿学习的局限:
- 只学习"what to do"(做什么)
- 缺乏对"why not do otherwise"(为何不这样做)的理解
早期经验的突破:
- 世界建模:建立"if I do X, then Y will happen"的因果模型
- 自我反思:内化"X is better than Y because…"的决策准则
结构层面(多主体视角)
在复杂环境中,智能体需要理解:
- 自身位置:当前状态在任务空间中的位置
- 环境响应:环境对不同动作的反馈模式
- 约束网络:多重约束的相互作用
早期经验通过探索,让智能体"试错"而无需付出实际失败的代价。
机制层面
隐式世界建模:
- 增强回路:准确的状态预测 → 更好的动作选择 → 更丰富的经验 → 更准确的预测
- 时间延迟理解:通过观察中间状态,理解动作的渐进效果
自我反思:
- 反馈回路:错误动作的后果 → 自然语言解释 → 可泛化的决策原则
- 跨情境迁移:语言化的推理可迁移到相似但非同一的场景
4.2 方法间的互补性
适用场景对比
| 特征维度 | 隐式世界建模更优 | 自我反思更优 |
|---|---|---|
| 环境动力学 | 规律稳定、可预测 | 复杂多变、长期依赖 |
| 失败模式 | 明确的无效动作 | 推理错误、约束违背 |
| 数据规模 | 可扩展到大量rollout | 需要高质量对比 |
| 典型环境 | WebShop, ALFWorld | TravelPlanner, ScienceWorld |
潜在结合方向
未来可探索:
- 混合训练:两阶段训练或加权组合损失函数
- 自适应选择:根据任务类型动态选择方法
- 层次化应用:世界模型用于低层动作,反思用于高层规划
五、局限性与未来方向
5.1 当前局限
1. 短视性问题
现状:两种方法都基于单步或短期状态转移
挑战:长期信用分配(credit assignment)在无奖励情况下仍未解决
潜在方向:
- 分层世界模型:区分短期动力学和长期目标进展
- 多步反思:生成跨越多个时间步的推理链
2. 计算成本
数据生成开销:
- 隐式世界建模:需在真实环境中执行大量rollout(K×N次)
- 自我反思:需要额外的LLM推理生成解释
优化方向:
- 离线环境模拟器(但引入近似误差)
- 更高效的采样策略(主动学习、不确定性引导)
3. 泛化边界
观察到的失效案例:
- WebArena等极高复杂度环境中,提升相对有限
- 当动作空间组合爆炸时,覆盖不足
5.2 扩展方向
方向1:跨环境迁移
当前:每个环境独立训练
未来:
- 预训练通用世界模型,跨环境共享动力学知识
- 元反思能力:学习如何在新环境中快速生成有效反思
方向2:与强化学习的深度融合
当前:早期经验作为RL的初始化
未来:
- 在线早期经验:RL过程中持续生成和利用早期经验
- 自适应切换:根据学习阶段动态调整监督信号来源
方向3:真实世界部署
挑战:
- 自然交互数据的收集
- 隐私和安全约束下的探索
机遇:
- 用户交互日志作为天然的早期经验数据源
- 联邦学习框架下的分布式早期经验收集
六、理论意义与实践价值
6.1 理论贡献
重新定义监督信号
传统观点:监督 = 标注动作(IL)或奖励(RL)
新视角:未来状态本身携带信息,可作为自监督信号
这呼应了认知科学中的"试错学习"理论,但关键创新在于即使错误动作也产生有价值的训练信号。
架起两个时代的桥梁
| 时代 | Era of Human Data | Era of Experience | Early Experience (本文) |
|---|---|---|---|
| 数据来源 | 人类专家 | 环境奖励 | 智能体自身探索 |
| 可扩展性 | ❌ 受限于标注成本 | ✅ 可无限自我生成 | ✅ 可扩展(无需奖励) |
| 环境要求 | ✅ 无特殊要求 | ❌ 需可验证奖励 | ✅ 只需可交互 |
| 现实可行性 | ⚠️ 专家数据昂贵 | ⚠️ 多数环境无奖励 | ✅ 立即可用 |
6.2 实践指南
何时使用早期经验?
强推荐场景:
- ✅ 环境可交互但无奖励信号
- ✅ 专家数据有限且昂贵
- ✅ 需要强泛化能力
谨慎场景:
- ⚠️ 环境交互成本极高(如真实机器人)
- ⚠️ 已有丰富奖励信号且RL稳定
实施步骤
-
基础设施准备
- 确保环境可重置且可批量执行
- 准备小规模专家演示(100-1000条轨迹)
-
方法选择
- 如果环境动力学稳定 → 优先隐式世界建模
- 如果任务需复杂推理 → 优先自我反思
- 不确定时,两者都尝试(成本不高)
-
超参数调优
- 分支因子K:世界建模可大(8-16),反思适中(2-4)
- 训练步数分配:世界建模1轮预训练+标准SFT,反思与SFT同步数
-
评估与迭代
- 同时评估域内和域外性能
- 如果后续有RL,保留检查点用于warm start
七、批判性思考
7.1 未充分探索的问题
1. 幻觉问题
潜在风险:
- 世界模型预测的下一状态可能不准确
- 反思生成的解释可能不符合实际因果
论文未充分讨论:如何检测和纠正这些幻觉?
2. 对抗性探索
当前方法:采样替代动作主要基于策略分布或随机采样
更优策略:主动寻找最具信息量的动作(如边界案例、反事实场景)
3. 与人类学习的差异
人类的"早期经验"包含:
- 情感反馈(即使无明确奖励)
- 他人观察学习
- 内在好奇心驱动
当前方法尚未整合这些要素。
7.2 对现有AI范式的挑战
挑战1:是否真需要大规模专家数据?
如果早期经验用1/8数据可超越全量模仿学习,那么:
- 当前大规模标注项目的性价比需重新评估
- 应优先投资环境基础设施而非标注
挑战2:奖励设计的必要性
如果无奖励的早期经验可为后续RL提供强初始化,那么:
- 复杂的奖励工程可能不是必需的
- 资源应先用于早期经验收集,再考虑奖励
八、总结:新范式的启示
关键洞察
-
监督信号的重新定义
未来状态不仅是环境反馈,更是可学习的知识载体 -
失败的价值
非专家动作及其后果是数据增强的金矿,而非噪声 -
可扩展性的新路径
在"人类数据"和"强化学习"之间,存在一条可规模化的中间道路 -
语言的独特优势
自然语言使得反思可泛化,这是视觉智能体难以复制的
对未来的展望
短期(1-2年):
- 早期经验成为语言智能体训练的标准步骤
- 更多环境benchmark集成早期经验评估
中期(3-5年):
- 出现专门优化早期经验生成的方法(如主动学习、课程学习)
- 跨任务的通用世界模型和反思引擎
长期愿景:
- 智能体在与人类协作中持续积累早期经验
- 终身学习系统的核心组件
元反思:对本文的批判
优点:
- ✅ 系统的实验覆盖(8环境×3模型规模)
- ✅ 清晰的方法论(两条明确路径)
- ✅ 实践导向(所有方法可复现)
不足:
- ⚠️ 理论分析不够深入(为何有效的机制解释较浅)
- ⚠️ 长期信用分配未解决
- ⚠️ 与人类认知学习的类比不够严谨
对研究者的启示:
这是一篇高度工程化和实验驱动的论文,其价值在于:
- 提出了一个立即可用的实践框架
- 用大规模实验证明了可行性
但理论深度和机制理解仍有待后续工作深化。
最终评价:这是语言智能体领域的一篇里程碑式工作,不在于理论创新的深度,而在于打开了一扇实践上可行的新门,并用扎实的实验证明了这条路径的价值。它的真正影响将在未来2-3年的后续研究和工业应用中显现。