python进阶_Day7
思维导图:
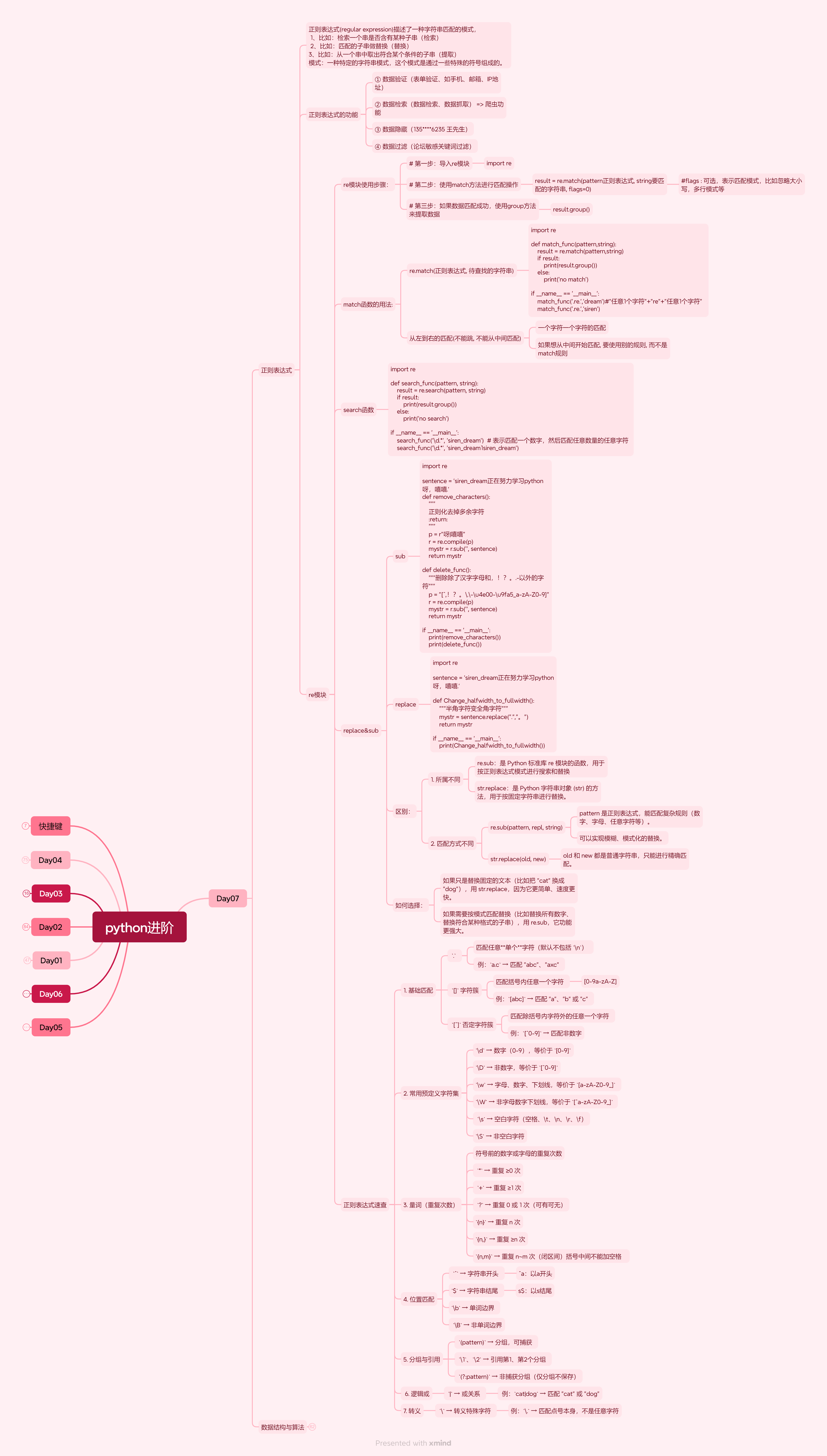
1.正则化:
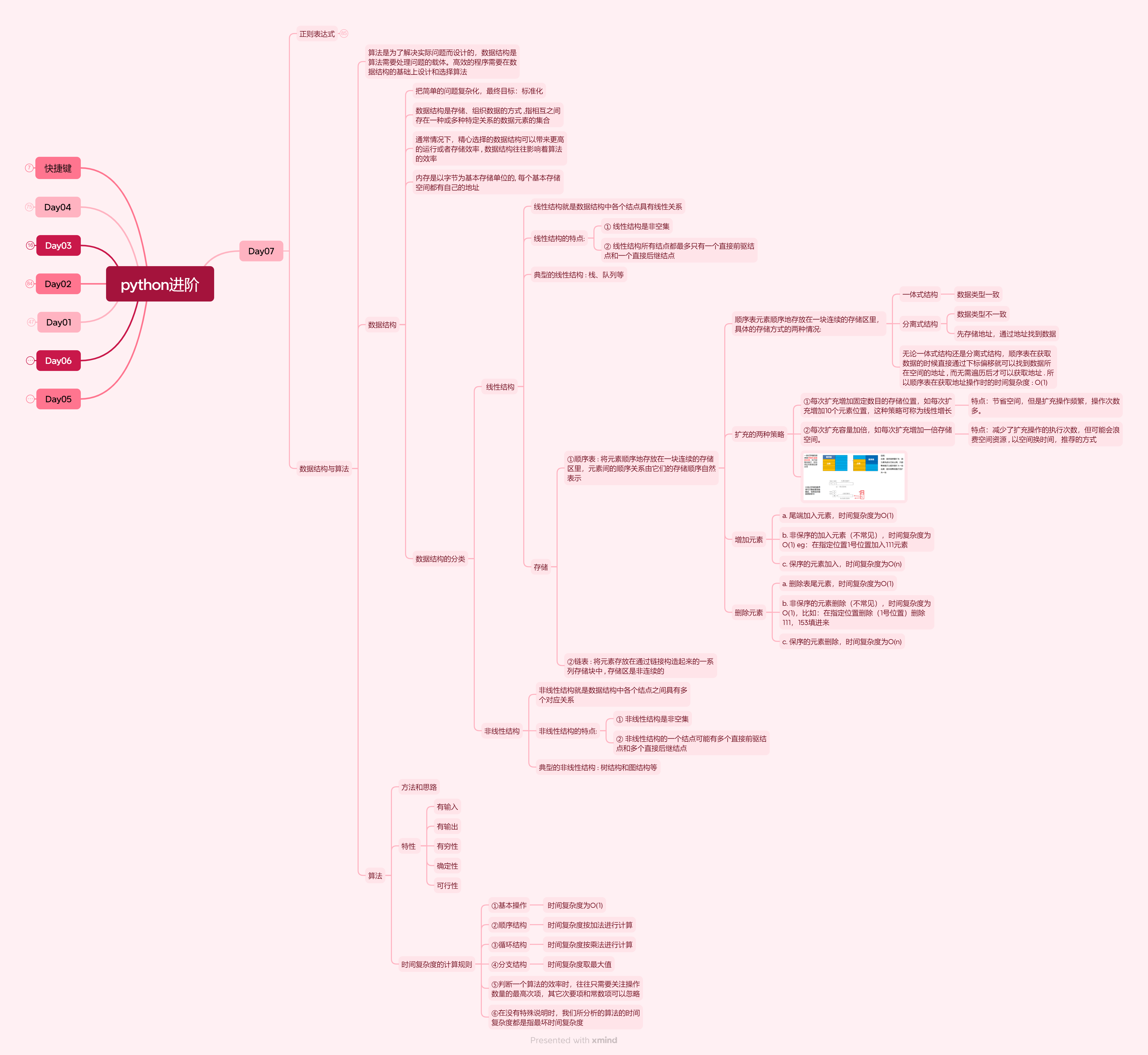
2.数据结构
附:正则化表达式例子(有条件的可以直接下载绑定资源,和下面代码相同,会更方便一些~)
import resentence = 'siren_dream111,siren_dream1'def fun1(pattern, string):result = re.match(pattern, string)if result:print(result.group())else:print('未查询到')if __name__ == '__main__':# . 匹配任意单个字符(默认不包括 `\n`)fun1('.iren.', sentence) # siren_# `[]` 字符簇fun1('[a-z]', sentence) # sfun1('[A-Z]', sentence) # 未查询到fun1('[A-Za-z]', sentence) # s# `[ ^]` ** 否定字符簇 **fun1('[^a-z]', sentence) # 未查询到fun1('[^A-Z]', sentence) # s# `\d` → 数字(0-9),等价于 `[0-9]`fun1('\d', sentence) # 未查询到# `\D` → 非数字,等价于 `[^0-9]`fun1('\D', sentence) # s# `\w` → 字母、数字、下划线,等价于 `[a-zA-Z0-9_]`fun1('\w', sentence) # s# `\W` → 非字母数字下划线,等价于 `[^a-zA-Z0-9_]`fun1('\W', sentence) # 未查询到# `\s` → 空白字符(空格、\t、\n、\r、\f)fun1('\s', sentence) # 未查询到# `\S` → 非空白字符fun1('\S', sentence) # s# `*` → 重复 ≥0 次fun1('siren_dream1*', sentence) # siren_dream111fun1('siren_dream\d*', sentence) # siren_dream111# `+` → 重复 ≥1 次fun1('siren_dream\d+', sentence) # siren_dream111fun1('siren_dream111\d+', sentence) # 未查询到# `?` → 重复 0 或 1 次(可有可无)fun1('siren_dream\?siren_dream', sentence) # 未查询到fun1('siren_dream11\d?,siren_dream', sentence) # siren_dream111,siren_dreamfun1('siren_dream111,?siren_dream', sentence) # siren_dream111,siren_dream# `{n}` → 重复 n 次fun1('siren_dream1{3},siren_dream', sentence) # siren_dream111,siren_dreamfun1('siren_dream1{2},siren_dream', sentence) # 未查询到# `{n,m}` → 重复 n~m 次(闭区间)括号中间不能加空格fun1('siren_dream\d{3,5},siren_dream', sentence) # siren_dream111,siren_dreamfun1('siren_dream\d{1,3},siren_dream', sentence) # siren_dream111,siren_dream# `^` → 字符串开头fun1('^siren', sentence) # sirenfun1('^\dsiren', '2siren') # 2sirenfun1('^siren.*', sentence) # '.*'以字符结尾 #siren_dream111,siren_dream1# `$` → 字符串结尾fun1('^siren.*\d$', sentence) # siren_dream111,siren_dream1fun1('.*[a-z]$', sentence) # 未查询到# `[^]` 否定字符簇fun1('^siren.*[^A-Z]$', sentence) # siren_dream111,siren_dream1fun1('^siren.*[^0-9]$', sentence) # 未查询到# 分组+转义字符/fun1('[a-zA-Z]{4,20}@(163|126|qq)\.com', 'sirendream@qq.com') # sirendream@qq.com# 把qq与qq号分别提取出来result = re.match('(qq):(\d{5,11})', 'qq:1234567')print(result.group(0))print(result.group(1))print(result.group(2))# `\1`、`\2` → 引用第1、第2个分组result = re.match("<([a-zA-Z1-6]{4})>.*</\\1>", "<html>hh</html>")print(result.group(1)) # htmlprint(result.group()) # <html>hh</html># 匹配出<html><h1>www.itcast.cn</h1></html>result = re.match("<([a-zA-Z1-6]{4})><([a-zA-Z1-6]{2})>.*</\\2></\\1>", "<html><h1>www.itcast.cn</h1></html>")print(result.group(1)) # htmlprint(result.group(2)) # h1print(result.group()) # <html><h1>www.itcast.cn</h1></html>#给分组起别名:# # (?P<name>) 分组起别名# # (?P=name) 引用别名为name分组匹配到的字符串result = re.match("<(?P<html>[a-zA-Z1-6]{4})><(?P<h1>[a-zA-Z1-6]{2})>.*</(?P=h1)></(?P=html)>", "<html><h1>www.itcast.cn</h1></html>")print(result.group(1))print(result.group(2))print(result.group())