Java HashSet 的实现原理
概述
HashSet集合中的每个元素,其实都被作为HashMap的key存放到了HashMap中,从而保证HashSet集合的不可重复性。对于HashMap来说,它的put方法设定了key重复时的逻辑。如果重复,则会直接覆盖key对应的value,如果不重复,则直接作为HashMap实例的一个key而被存放其中。
源码解析
Set set = new HashSet();
看java.util.HashSet#HashSet()。HashSet类实例初始化时会初始化这个map字段。
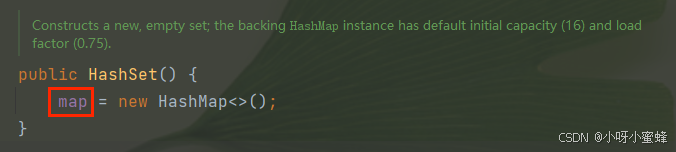
看看这个map字段的定义:

现在我们尝试存入3个元素到Set集合:
Set<String> set = new HashSet();
set.add("test1");
set.add("test2");
set.add("test3");
System.out.println(set);
看java.util.Set#add方法的内部:

这个字段是一个固定的对象。

现在看看,将元素add到Set集合后,此时这个map字段内容的变化:
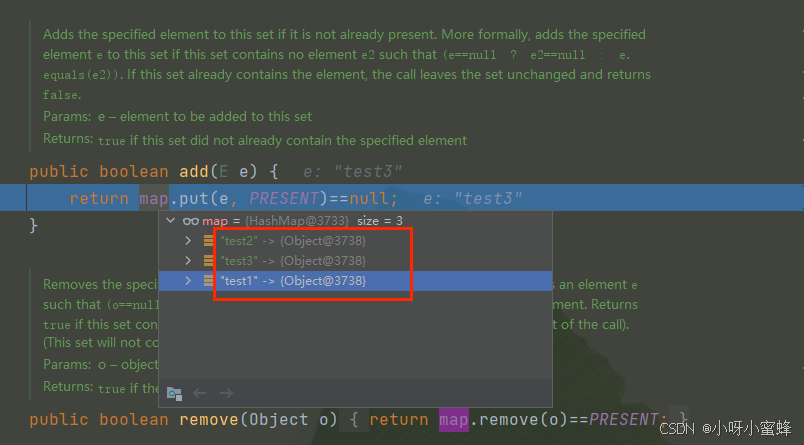
可以看到元素都被加到HashMap实例的key中了。并且,此时的key,引用的都是堆中同一个的Object实例。
再看一下HashMap的put方法,看当put进同一个key的元素时,是如何处理的。相关源码如下所示。可以了解到,当key重复时,会直接覆盖或者保持原样。
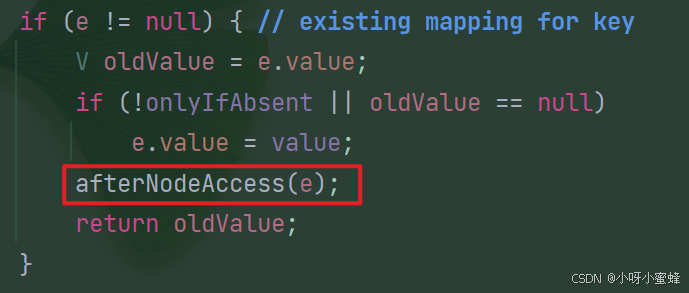
然后再看下这个put方法返回的内容:
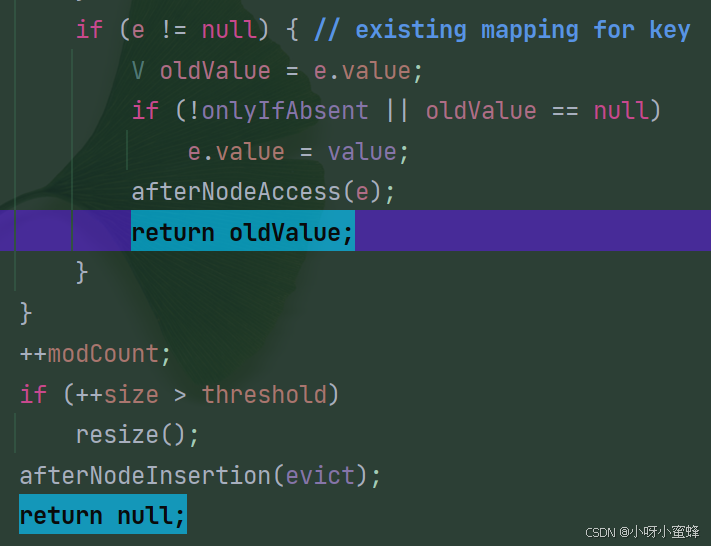
可以看到,如果当前put的key是新key,则返回null,反之则返回当前key原本被对应的value。
现在反过来最后再看下HashSet的add方法:
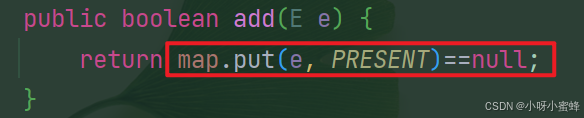
HashSet会通过HashMap的put接口返回的内容,来判断是否为重复添加。如果为true,则说明为新元素的添加,如果为false,则说明为重复元素的添加。所以,如果是重复元素的添加,并不会报错,只是会有一个状态位,true或者false,来判断是否为重复添加。