RND1:目前最强的扩散LLM
引言
在人工智能领域,模型转换(Model Conversion)是一个核心研究方向,旨在优化现有模型架构和训练目标,而非从零开始构建整个系统。通过模型转换,我们可以更快地迭代模型,并使其适应特定的工作流程、硬件和下游任务。本文将深入探讨 Radical Numerics 团队在这一领域取得的最新进展,特别是他们提出的 RND1 模型及其背后的创新技术。
paper:Training Diffusion Language Models at Scale
using Autoregressive Models
博客: https://www.radicalnumerics.ai/blog/rnd1
🤗: https 😕/huggingface.co/radicalnumerics/RND1-Base-0910
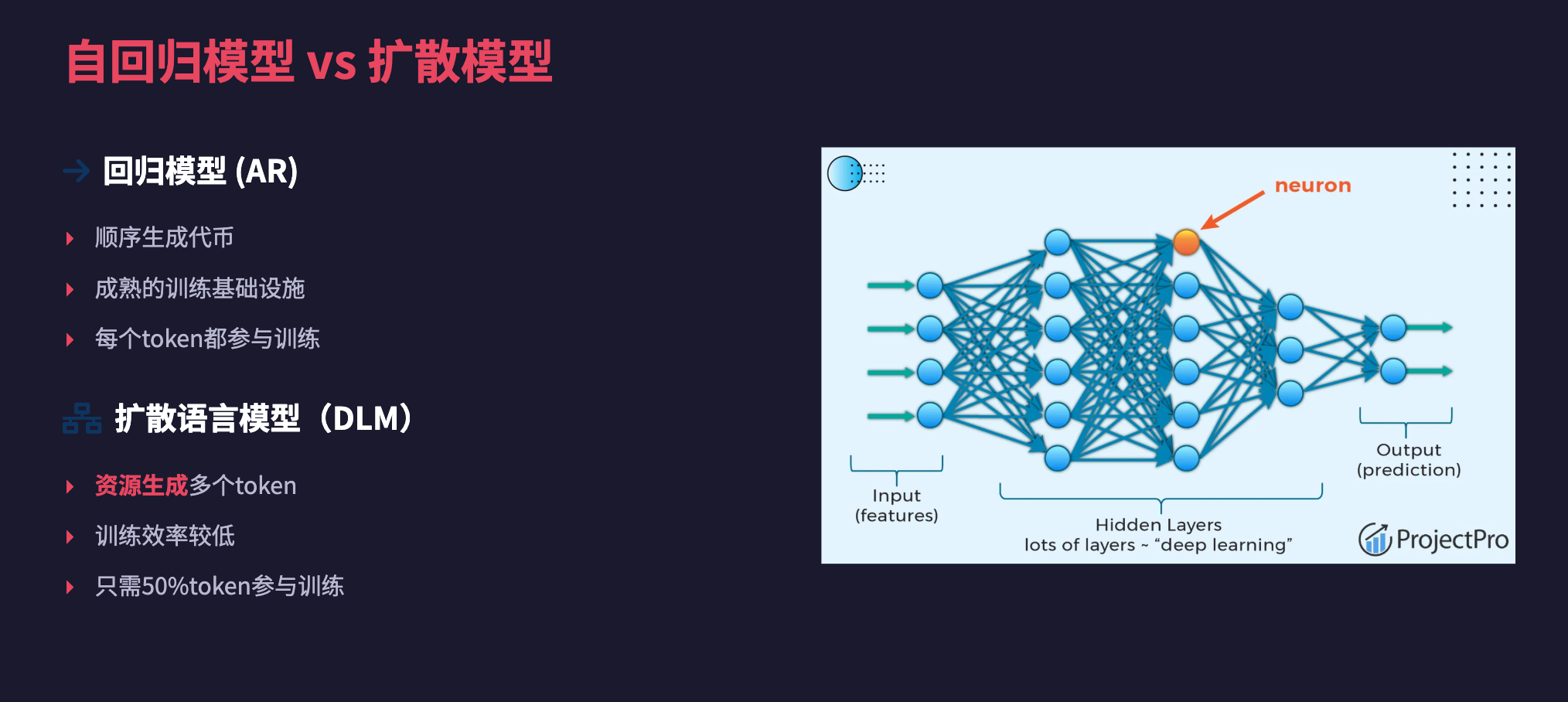
自回归模型与扩散模型
扩散语言模型(DLMs)因其支持并行生成而长期吸引着研究人员的关注,这与受限于顺序生成(从左到右)的自回归(AR)模型形成鲜明对比。尽管 DLMs 潜力巨大,但其训练效率相对较低,难以与 AR 模型相媲美。例如,直接训练 DLMs 需要更多的数据集遍历才能超越直接的 AR 训练 [1]。此外,AR 模型在训练基础设施、稳定配方和实践经验方面拥有显著的先发优势。
Radical Numerics 的工作旨在通过定制自回归模型来扩展扩散语言模型的能力。他们推出了 RND1-Base (Radical Numerics Diffusion),这是迄今为止最大、功能最强大的开源 DLM。RND1 是一个实验性的 30B 参数稀疏专家混合(Mixture-of-Experts)模型,具有 3B 活跃参数,它从预训练的 AR 模型 (Qwen3-30BA3B) 转换而来,并经过 500B token 的持续预训练,最终实现了完整的扩散行为。
以下图表展示了自回归生成器和扩散生成器之间的基本区别:
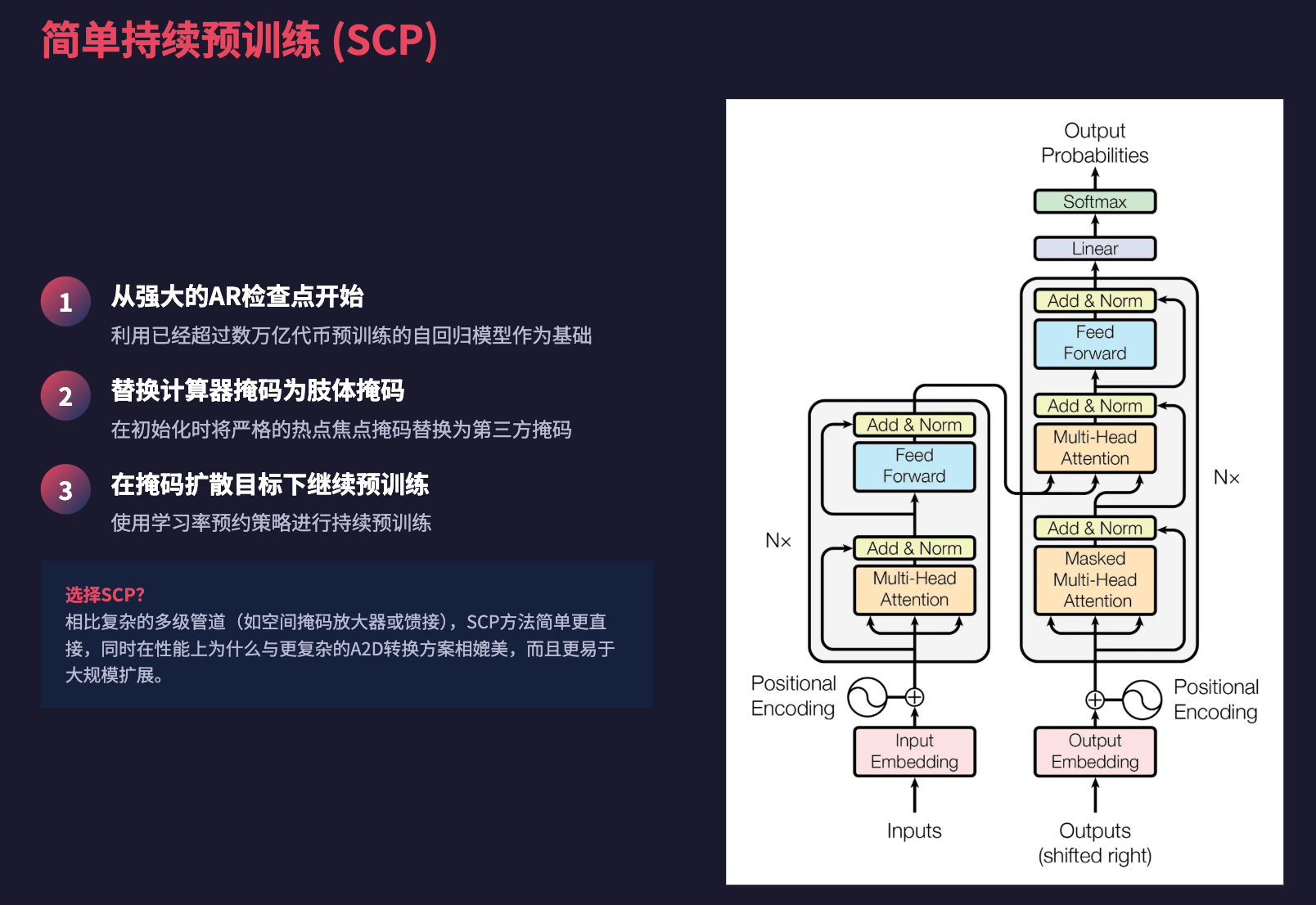
简单持续预训练 (SCP)
将扩散语言模型从自回归(AR)检查点进行训练,面临两个核心问题:
- 如何将双向上下文引入一个在严格因果注意力下训练的架构中?
- 如何保留 AR 模型通过数万亿 token 预训练所编码的庞大语言和事实知识?
早期的工作提出了复杂的多阶段管道,例如注意力掩码退火 [4,5] 或嫁接 [6],这些方法在小规模上有效,但引入了额外的设计选择,使其难以可靠地扩展。
Radical Numerics 发现,一种更简单的方法——简单持续预训练(Simple Continual Pretraining, SCP),能够与更复杂的 A2D 转换方案相媲美。SCP 的方法非常直接:
- 从一个强大的 AR 检查点开始。
- 在初始化时,用双向掩码替换因果掩码。
- 在带有学习率预热的掩码扩散目标下继续预训练。
通过分层学习率保留 AR 预训练知识

A2D 转换中的一个关键问题是灾难性遗忘(catastrophic forgetting):A2D 转换可能会覆盖 AR 预训练期间学到的事实知识。先前的研究表明,基于 Transformer 的语言模型中的知识(特别是事实关联)编码在 FFN/MLP 层中 [2,3]。
基于这一洞察,Radical Numerics 采用了跨参数组的可变学习率。在转换过程中,注意力层获得更高的学习率以促进对双向上下文的适应,而非注意力层(例如 MLP、嵌入层)则以较低的学习率进行训练,以保留 AR 预训练知识。
A2D 转换在大批量训练中表现更佳
自回归训练和扩散训练之间一个微妙但重要的区别在于每个批次提供的监督量。在自回归(AR)模型中,每个 token 都对损失有贡献。相比之下,掩码扩散目标仅监督每个序列中被掩码的位置。在标准掩码扩散目标下,平均掩码比例为 50%,因此批次中只有一半的 token 影响学习。这种减少的学习信号意味着标准的 AR 启发式方法(用于扩展批次大小和学习率)不一定适用于扩散训练。
为了更好地理解这一点,研究人员估计了临界批次大小(Critical Batch Size, CBS)——即数据并行性增加对损失改进的收益递减的阈值。通过分支训练,他们经验性地确定了这一点。
结果表明,扩散语言模型在持续预训练期间受益于大批次大小,这为大规模训练提供了令人鼓舞的信号。
RND1 评估
在涵盖推理、STEM 和编码的通用基准测试中,RND1 在开源扩散语言模型(DLMs)中树立了新的技术标准。RND1 始终优于先前的开源扩散基线(Dream-7B 和 LLaDA-8B),同时保留了其自回归(AR)基础的强大性能。RND1 在推理与常识(MMLU, ARC-C, RACE, BBH)、STEM 与数学(GSM8K)以及代码生成(MBPP)任务上进行了测试。
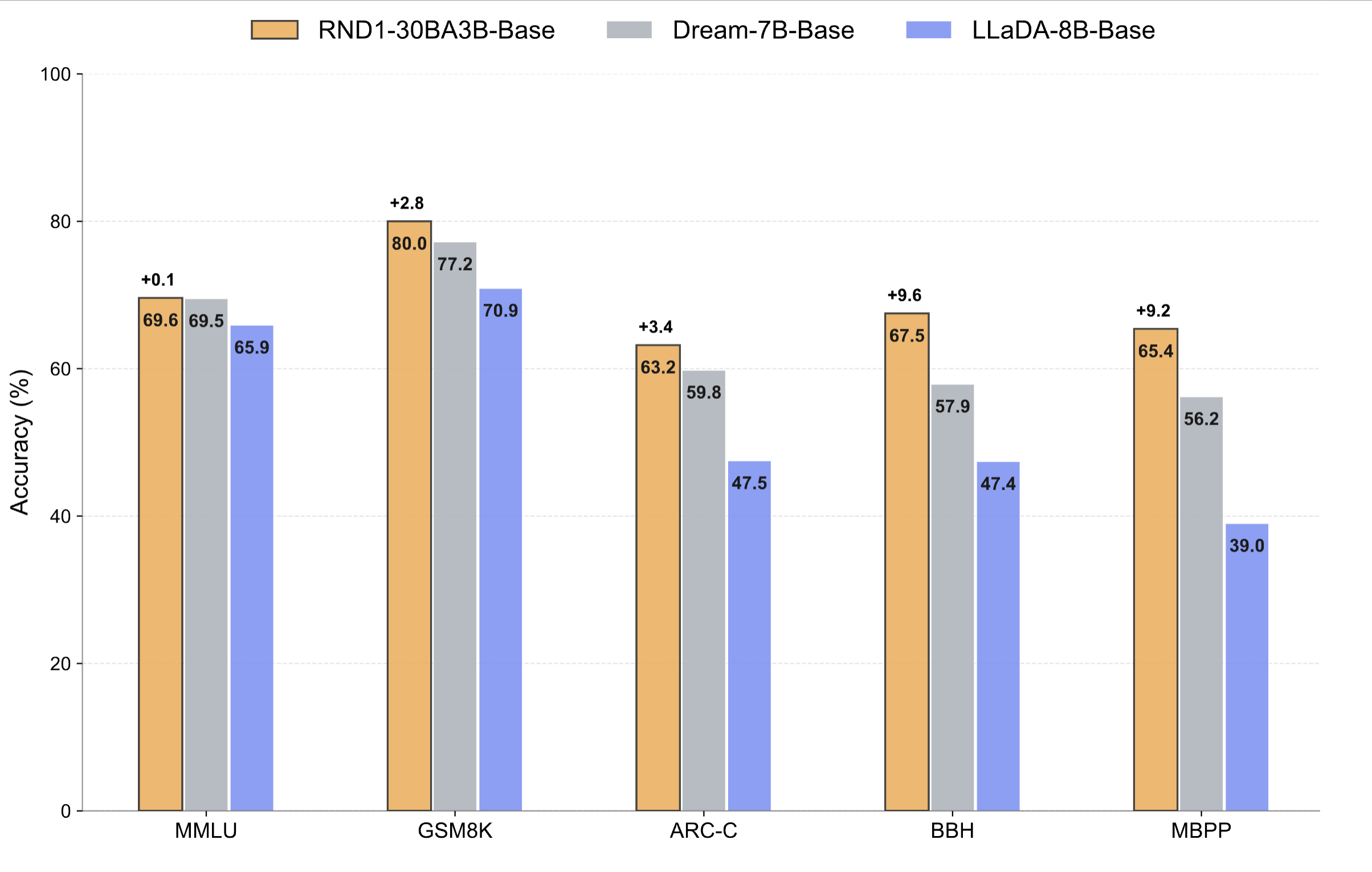
这些结果共同表明,将扩散语言模型扩展到 8B 参数以上不仅可行,而且实用,并且 A2D 可能是训练 DLMs 的更好策略。RND1 代表了第一个在此规模上展示扩散模型训练的开源工作。
模型定制的意义
RND1 展示了如何高效地探索新的架构和训练范式,而无需从头开始。这种效率反映了 Radical Numerics 正在构建的核心:一个自动化的 AI 研究平台,它能够实现递归式自我改进,允许 AI 系统帮助设计和优化下一代 AI 本身。
通过自动化实验循环,他们能够更快地遍历搜索空间并测试更大胆的想法。RND1 是这种方法最先的实际案例之一。
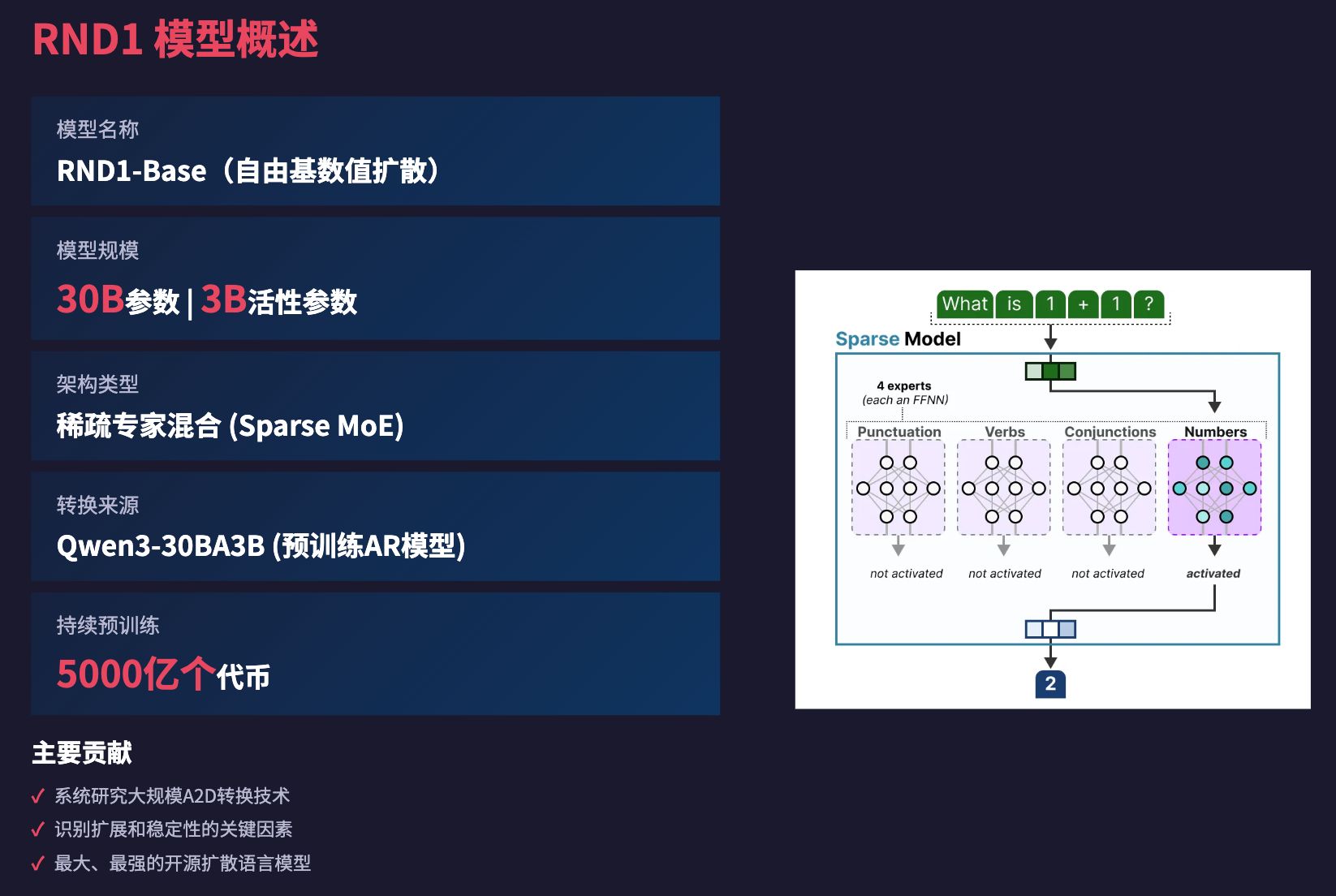
稀疏专家混合 (MoE) 架构
RND1 是一个 30B 参数的稀疏专家混合模型,具有 3B 活跃参数。**专家混合(Mixture-of-Experts, MoE)**是一种神经网络架构,它通过将输入路由到多个“专家”网络中的一个或几个来处理输入,从而在保持计算效率的同时提高模型容量。稀疏 MoE 意味着在任何给定时间,只有一小部分专家被激活,这进一步提高了效率。
结论
Radical Numerics 的 RND1 项目为扩散语言模型的发展开辟了新途径,证明了通过模型转换和创新的训练策略,可以有效地将自回归模型的优势与扩散模型的并行生成能力相结合。这不仅推动了 DLMs 的规模化应用,也为未来 AI 系统的自动化研究和自我改进奠定了基础。
参考文献
[1] Prabhudesai, Mihir, et al. “Diffusion beats autoregressive in data-constrained settings.” arXiv preprint arXiv:2507.15857(2025). https://arxiv.org/abs/2507.15857
[2] Meng, Kevin, et al. “Locating and editing factual associations in gpt.” Advances in neural information processing systems 35 (2022): 17359-17372. https://proceedings.neurips.cc/paper_files/paper/2022/file/02a32ad2669077771263595304312738-Paper-Conference.pdf
[3] Dai, Damai, et al. “Knowledge Neurons in Pretrained Transformers.” Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. https://aclanthology.org/2022.acl-long.239/
[4] Gong, Shansan, et al. “Scaling Diffusion Language Models via Adaptation from Autoregressive Models.” The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=Gf9YhJ9X9P
[5] Ye, Jiacheng, et al. “Dream 7b: Diffusion large language models.” arXiv preprint arXiv:2508.15487 (2025). https://arxiv.org/abs/2508.15487
[6] Chandrasegaran, Keshigeyan, et al. “Exploring Diffusion Transformer Designs via Grafting.” Advances in Neural Information Processing Systems 38 (2025) https://proceedings.neurips.cc/paper_files/paper/2024/file/f220e2a360290740669658064843705d-Paper-Conference.pdf
[7] McCandlish, Sam, et al. “An empirical model of large-batch training.” arXiv preprint arXiv:1812.06162 (2018). https://arxiv.org/abs/1812.06162
[8] Merrill, William, et al. “Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training.” arXiv preprint arXiv:2505.23971 (2025). https://arxiv.org/abs/2505.23971