【完整源码+数据集+部署教程】 面包种类识别系统源码和数据集:改进yolo11-aux
背景意义
研究背景与意义
随着计算机视觉技术的迅猛发展,深度学习在图像识别领域的应用日益广泛,尤其是在食品识别方面。面包作为全球范围内普遍消费的食品,其种类繁多且各具特色,如何准确识别不同种类的面包不仅具有重要的商业价值,也对食品安全、营养分析和消费者教育等方面具有深远的影响。传统的面包识别方法往往依赖于人工分类和经验判断,效率低下且容易出现误差。因此,基于深度学习的自动化识别系统应运而生,成为提升面包种类识别准确性和效率的有效途径。
本研究旨在基于改进的YOLOv11模型,构建一个高效的面包种类识别系统。该系统将利用一个包含4672张图像的多样化数据集,涵盖15种不同类型的面包,包括法棍、牛角包、玉米面包等。这些面包种类的多样性为模型的训练提供了丰富的样本,能够有效提升识别的鲁棒性和准确性。数据集经过精心的预处理和增强,确保了训练过程中模型能够适应不同的光照、角度和背景变化,从而提升其在实际应用中的表现。
通过引入YOLOv11这一先进的目标检测算法,本研究不仅希望在识别精度上取得突破,更期望能够在实时性和计算效率上实现优化。这一系统的成功实施,将为面包行业的自动化检测、智能零售和消费者服务提供强有力的技术支持,同时也为相关领域的研究提供新的思路和方法。最终,本研究将推动计算机视觉技术在食品识别领域的应用,为实现更智能化的食品管理和服务奠定基础。
图片效果
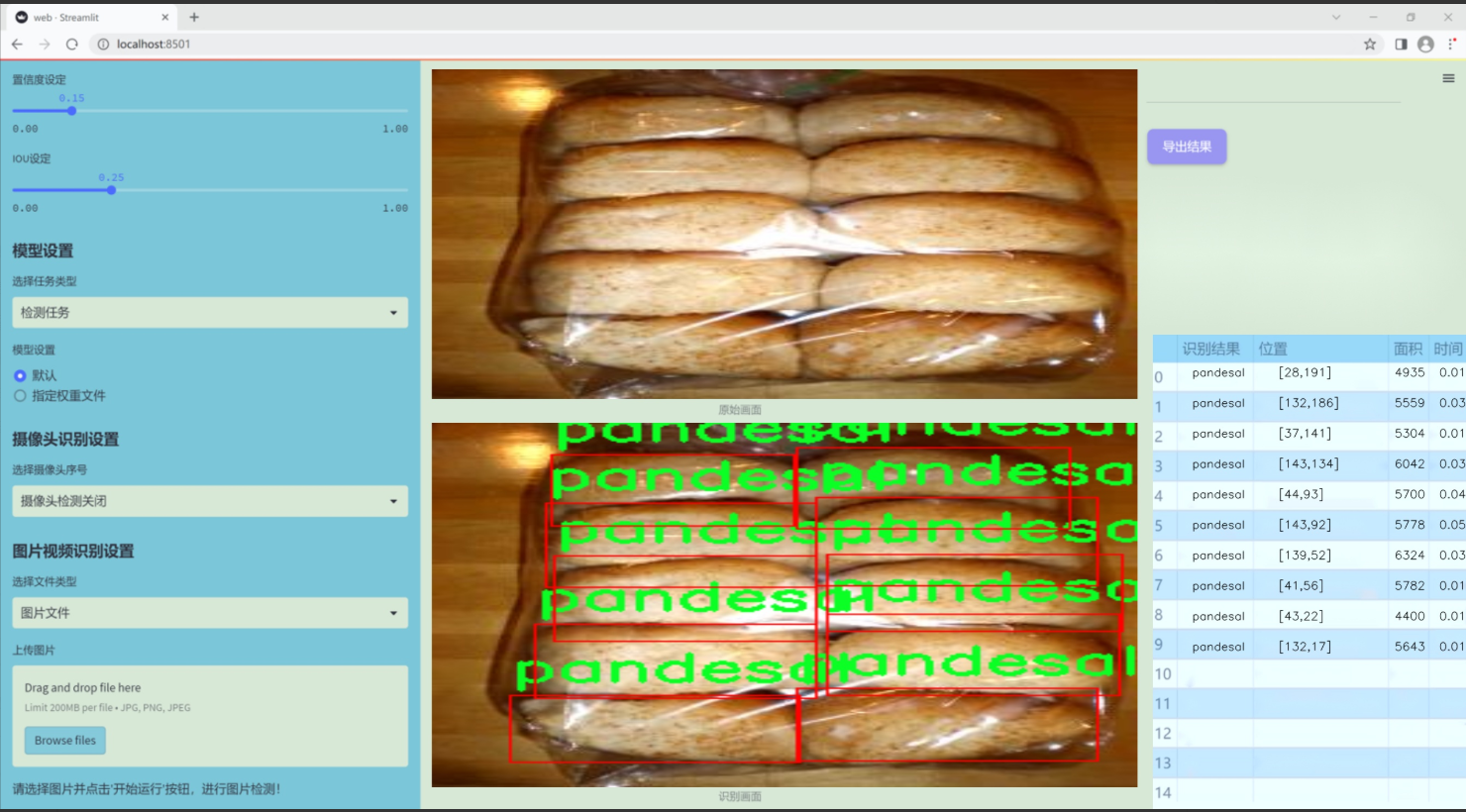
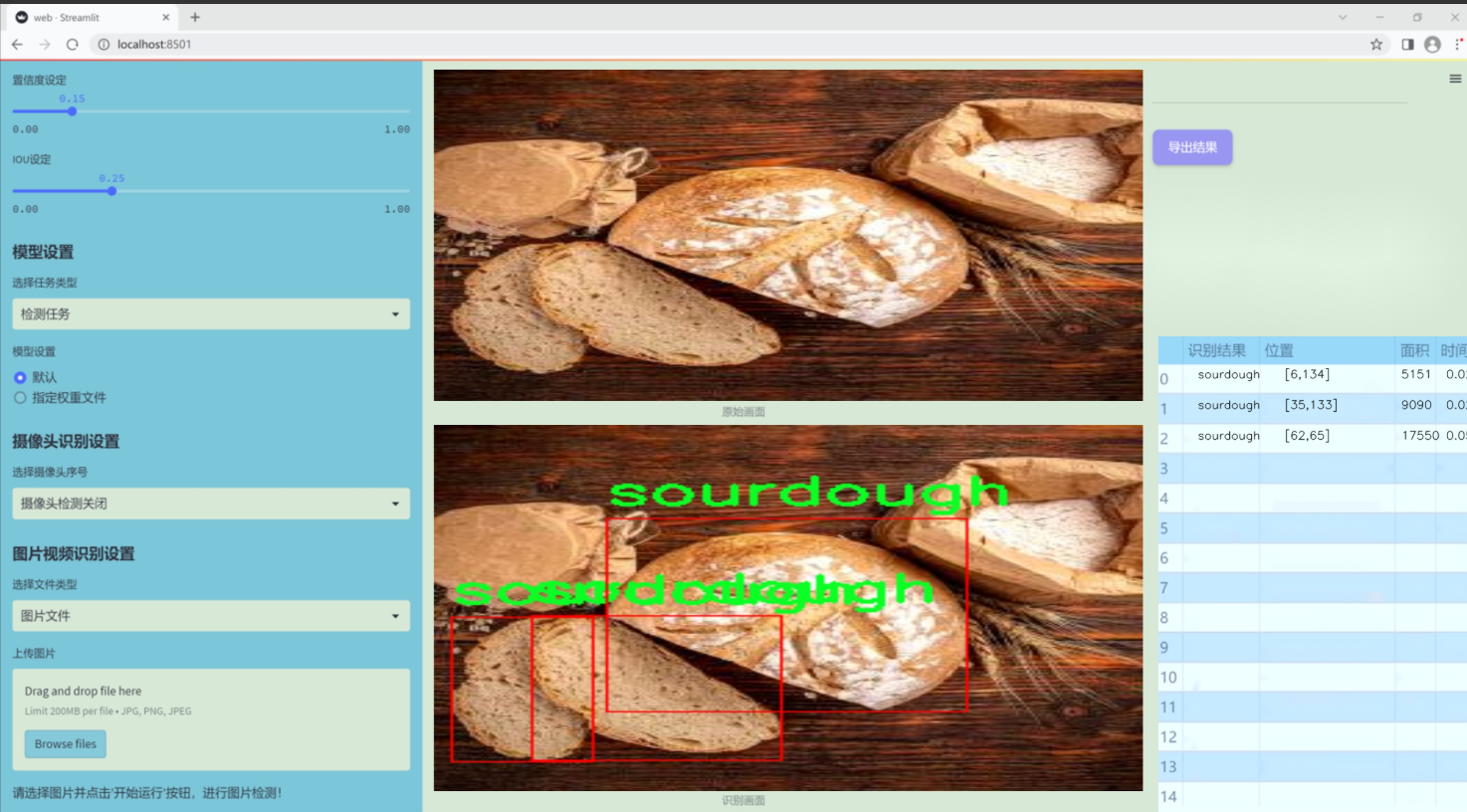
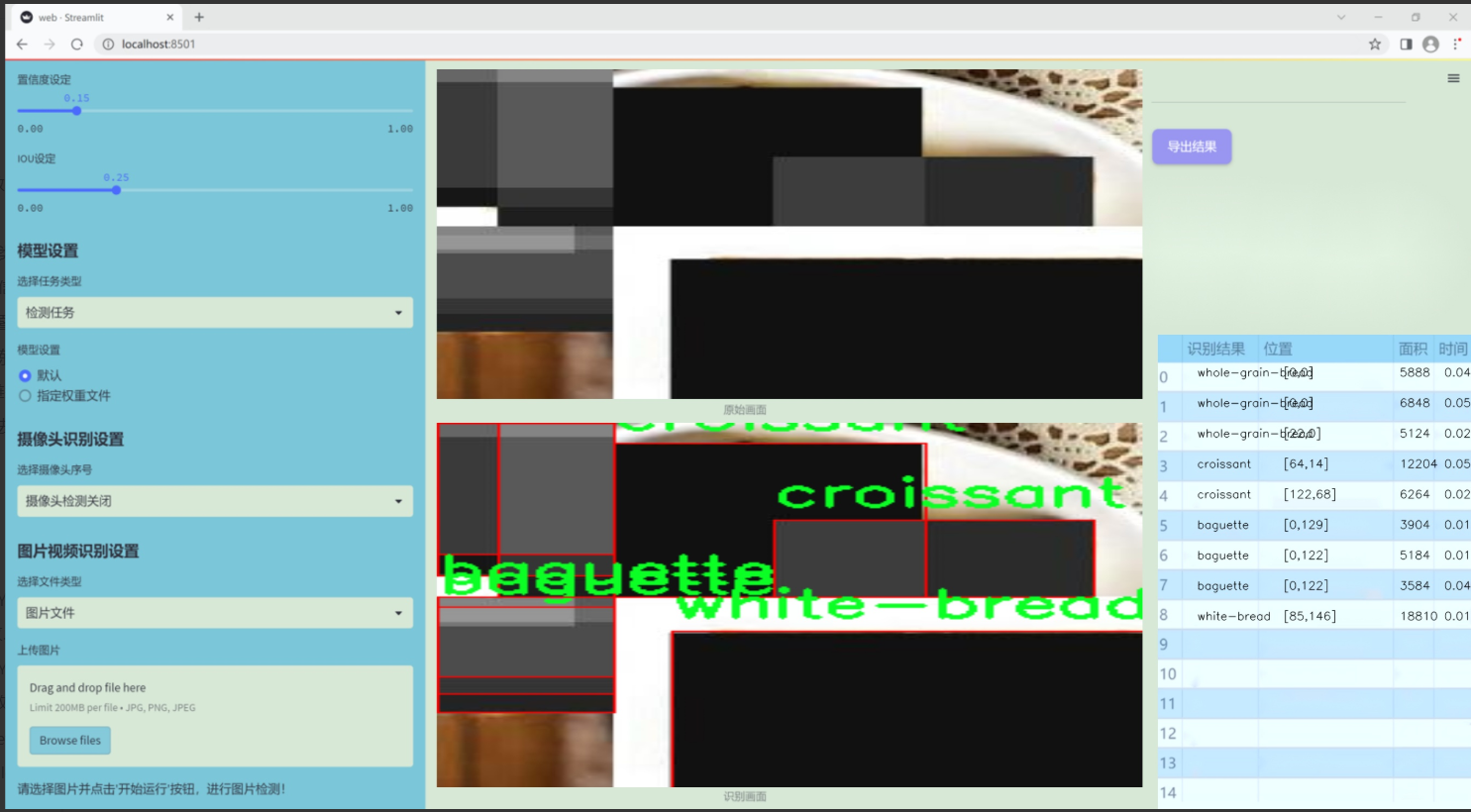
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11算法,构建一个高效的面包种类识别系统,以实现对多种面包的自动分类与识别。为此,我们构建了一个丰富且多样化的数据集,专注于“Bread Detector”主题。该数据集包含15个不同的面包类别,涵盖了从传统到现代的多种面包类型,确保了模型在实际应用中的广泛适用性和准确性。
数据集中包含的面包类别包括:法棍(baguette)、比南卡尔(binangkal)、波内特(bonete)、玉米面包(cornbread)、可颂(croissant)、恩赛马达(ensaymada)、扁面包(flatbread)、卡利希姆(kalihim)、莫纳伊(monay)、潘德萨尔(pandesal)、酸面包(sourdough)、西班牙面包(spanish-bread)、小麦面包(wheat-bread)、白面包(white-bread)以及全谷物面包(whole-grain-bread)。这些类别的选择不仅反映了不同地区的面包文化,也展示了面包制作的多样性和丰富性。
为了确保数据集的质量和有效性,我们在数据收集过程中采用了多种来源,包括面包店、超市和家庭制作的面包,确保每种面包的图像在不同的光照、角度和背景下都有所涵盖。此外,数据集中的每个图像都经过精确标注,确保训练模型时能够准确识别各类面包的特征。这种细致的标注工作为后续的模型训练提供了坚实的基础,能够有效提升YOLOv11在面包种类识别任务中的性能。
总之,本项目的数据集不仅丰富多样,而且经过精心设计和标注,旨在为面包种类识别系统的训练提供强有力的支持,助力于实现更高效的自动化识别和分类。





核心代码
以下是经过简化和注释的核心代码部分:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias):
# 创建一个2D卷积层
return nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias
)
def get_bn(channels):
# 创建一个批归一化层
return nn.BatchNorm2d(channels)
class Mask(nn.Module):
def init(self, size):
super().init()
# 初始化权重参数,并在[-1, 1]范围内均匀分布
self.weight = torch.nn.Parameter(data=torch.Tensor(*size), requires_grad=True)
self.weight.data.uniform_(-1, 1)
def forward(self, x):# 应用sigmoid激活函数并与输入x相乘w = torch.sigmoid(self.weight)masked_wt = w.mul(x)return masked_wt
class ReparamLargeKernelConv(nn.Module):
def init(self, in_channels, out_channels, kernel_size, small_kernel=5, stride=1, groups=1, small_kernel_merged=False, Decom=True, bn=True):
super(ReparamLargeKernelConv, self).init()
self.kernel_size = kernel_size
self.small_kernel = small_kernel
self.Decom = Decom
padding = kernel_size // 2 # 假设卷积不会改变特征图大小
if small_kernel_merged:# 使用大卷积核的卷积层self.lkb_reparam = get_conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bias=True,)else:if self.Decom:# 使用小卷积和大卷积的组合self.LoRA = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=(kernel_size, small_kernel),stride=stride,padding=padding,groups=groups,bn=bn)else:# 使用单一的大卷积self.lkb_origin = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bn=bn,)if (small_kernel is not None) and small_kernel < kernel_size:# 创建小卷积层self.small_conv = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=small_kernel,stride=stride,padding=small_kernel // 2,groups=groups,bn=bn,)self.bn = get_bn(out_channels) # 批归一化层self.act = nn.SiLU() # 激活函数def forward(self, inputs):# 前向传播if hasattr(self, "lkb_reparam"):out = self.lkb_reparam(inputs)elif self.Decom:out = self.LoRA(inputs)if hasattr(self, "small_conv"):out += self.small_conv(inputs)else:out = self.lkb_origin(inputs)if hasattr(self, "small_conv"):out += self.small_conv(inputs)return self.act(self.bn(out)) # 应用激活函数和批归一化def get_equivalent_kernel_bias(self):# 获取等效的卷积核和偏置eq_k, eq_b = fuse_bn(self.lkb_origin.conv, self.lkb_origin.bn)if hasattr(self, "small_conv"):small_k, small_b = fuse_bn(self.small_conv.conv, self.small_conv.bn)eq_b += small_beq_k += nn.functional.pad(small_k, [(self.kernel_size - self.small_kernel) // 2] * 4)return eq_k, eq_bdef switch_to_deploy(self):# 切换到部署模式,合并卷积和批归一化if hasattr(self, 'lkb_origin'):eq_k, eq_b = self.get_equivalent_kernel_bias()self.lkb_reparam = get_conv2d(in_channels=self.lkb_origin.conv.in_channels,out_channels=self.lkb_origin.conv.out_channels,kernel_size=self.lkb_origin.conv.kernel_size,stride=self.lkb_origin.conv.stride,padding=self.lkb_origin.conv.padding,dilation=self.lkb_origin.conv.dilation,groups=self.lkb_origin.conv.groups,bias=True,)self.lkb_reparam.weight.data = eq_kself.lkb_reparam.bias.data = eq_bself.__delattr__("lkb_origin")if hasattr(self, "small_conv"):self.__delattr__("small_conv")
代码注释说明:
get_conv2d: 创建一个2D卷积层的函数,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、扩张、分组和是否使用偏置。
get_bn: 创建一个批归一化层的函数,参数为通道数。
Mask类: 定义了一个Mask模块,包含一个可学习的权重参数,通过sigmoid函数进行归一化,并与输入相乘。
ReparamLargeKernelConv类: 定义了一个大卷积核的重参数化卷积层,支持小卷积核的合并和分解。
init: 初始化函数,设置卷积层和批归一化层。
forward: 前向传播函数,计算输出。
get_equivalent_kernel_bias: 获取等效的卷积核和偏置,用于合并卷积和批归一化。
switch_to_deploy: 切换到部署模式,合并卷积和批归一化层。
这个程序文件 shiftwise_conv.py 实现了一个名为 ReparamLargeKernelConv 的深度学习模块,主要用于卷积操作,特别是处理大卷积核的情况。文件中使用了 PyTorch 框架,包含了多个类和函数,用于构建和管理卷积层及其相关操作。
首先,文件导入了必要的库,包括 math 和 torch 以及 torch.nn 和 torch.nn.functional,后者提供了构建神经网络所需的基本功能。接着,定义了一个 get_conv2d 函数,用于创建一个标准的二维卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、扩张率、分组和是否使用偏置。
然后,定义了一个 Mask 类,它是一个自定义的 PyTorch 模块,包含一个可学习的权重参数,并在前向传播中对输入进行加权处理。接下来的 conv_bn_ori 函数用于构建一个包含卷积层和可选的批归一化层的序列。
LoRAConvsByWeight 类是一个复杂的卷积模块,旨在通过不同的卷积核处理输入数据。它将输入分成多个部分,并通过不同的路径处理,然后将结果合并。这个类的设计允许在卷积操作中实现更灵活的特征提取。
conv_bn 函数根据输入的卷积核大小选择使用 conv_bn_ori 或 LoRAConvsByWeight,从而实现不同的卷积策略。fuse_bn 函数则用于将卷积层和批归一化层融合,以优化模型的推理速度。
最后,ReparamLargeKernelConv 类是整个文件的核心,提供了一个可重参数化的大卷积核模块。它支持小卷积核的合并和分解,允许用户根据需求选择不同的卷积策略。该类的前向传播方法结合了不同卷积的输出,并通过激活函数和批归一化层进行处理。此外,它还提供了获取等效卷积核和偏置的功能,以及切换到部署模式的方法。
整体而言,这个文件实现了一个灵活且高效的卷积模块,适用于处理大卷积核的场景,特别是在深度学习模型中。通过不同的卷积策略和可重参数化的设计,能够在保持模型性能的同时提高计算效率。
10.4 deconv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
from torch import nn
from einops.layers.torch import Rearrange
定义一个自定义的卷积层,Conv2d_cd
class Conv2d_cd(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_cd, self).init()
# 初始化一个标准的2D卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta # 用于调整卷积权重的参数
def get_weight(self):# 获取卷积层的权重conv_weight = self.conv.weightconv_shape = conv_weight.shape # 获取权重的形状# 将权重重排为 (输入通道数, 输出通道数, 卷积核大小)conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 创建一个新的权重张量并初始化为0conv_weight_cd = torch.zeros(conv_shape[0], conv_shape[1], 3 * 3, device=conv_weight.device)conv_weight_cd[:, :, :] = conv_weight[:, :, :] # 复制原始权重# 调整权重以满足特定的卷积需求conv_weight_cd[:, :, 4] = conv_weight[:, :, 4] - conv_weight[:, :, :].sum(2)# 将权重重排回原来的形状conv_weight_cd = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_cd)return conv_weight_cd, self.conv.bias # 返回调整后的权重和偏置
定义另一个自定义的卷积层,Conv2d_ad
class Conv2d_ad(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_ad, self).init()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta
def get_weight(self):# 获取卷积层的权重conv_weight = self.conv.weightconv_shape = conv_weight.shapeconv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)# 根据theta调整权重conv_weight_ad = conv_weight - self.theta * conv_weight[:, :, [3, 0, 1, 6, 4, 2, 7, 8, 5]]conv_weight_ad = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_ad)return conv_weight_ad, self.conv.bias
定义主卷积模块,DEConv
class DEConv(nn.Module):
def init(self, dim):
super(DEConv, self).init()
# 初始化多个自定义卷积层
self.conv1_1 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_2 = Conv2d_ad(dim, dim, 3, bias=True)
self.conv1_5 = nn.Conv2d(dim, dim, 3, padding=1, bias=True)
self.bn = nn.BatchNorm2d(dim) # 批归一化层self.act = nn.ReLU() # 激活函数def forward(self, x):# 前向传播w1, b1 = self.conv1_1.get_weight() # 获取第一个卷积层的权重和偏置w2, b2 = self.conv1_2.get_weight() # 获取第二个卷积层的权重和偏置w5, b5 = self.conv1_5.weight, self.conv1_5.bias # 获取最后一个卷积层的权重和偏置# 将所有卷积层的权重和偏置相加w = w1 + w2 + w5b = b1 + b2 + b5# 使用合并后的权重和偏置进行卷积操作res = nn.functional.conv2d(input=x, weight=w, bias=b, stride=1, padding=1, groups=1)# 进行批归一化和激活res = self.bn(res)return self.act(res)def switch_to_deploy(self):# 切换到部署模式,合并权重和偏置w1, b1 = self.conv1_1.get_weight()w2, b2 = self.conv1_2.get_weight()w5, b5 = self.conv1_5.weight, self.conv1_5.biasself.conv1_5.weight = torch.nn.Parameter(w1 + w2 + w5)self.conv1_5.bias = torch.nn.Parameter(b1 + b2 + b5)# 删除不再需要的卷积层del self.conv1_1del self.conv1_2
代码说明:
卷积层定义:定义了多个自定义卷积层(Conv2d_cd、Conv2d_ad),每个卷积层都包含了一个标准的卷积操作,并提供了获取调整后权重的方法。
权重调整:在每个自定义卷积层中,get_weight方法负责根据特定的逻辑调整卷积权重,以满足特定的需求。
主卷积模块:DEConv类整合了多个自定义卷积层,并在前向传播中使用合并后的权重进行卷积操作,同时应用批归一化和激活函数。
部署模式:switch_to_deploy方法用于合并权重和偏置,以便在推理时减少计算开销。
这个程序文件 deconv.py 定义了一些卷积层的变体,主要用于深度学习中的卷积神经网络(CNN)。文件中包含多个类,每个类实现了不同类型的卷积操作,并且有一个主类 DEConv,它组合了这些卷积层以形成一个更复杂的网络结构。
首先,文件导入了必要的库,包括 math、torch 和 torch.nn,以及 einops 库中的 Rearrange 函数,用于重塑张量的形状。还导入了一个自定义的卷积模块 Conv 和一个用于融合卷积和批归一化的工具 fuse_conv_and_bn。
接下来,定义了多个卷积类:
Conv2d_cd:这是一个自定义的二维卷积层,具有一个方法 get_weight,用于获取卷积权重并进行重塑和调整。它的设计允许在权重中进行特定的操作。
Conv2d_ad:类似于 Conv2d_cd,但在 get_weight 方法中对权重进行了不同的处理,应用了一个参数 theta 来调整权重。
Conv2d_rd:这个类实现了一个特殊的前向传播方法,允许在 theta 接近零时直接使用标准卷积。否则,它会根据调整后的权重进行卷积操作。
Conv2d_hd 和 Conv2d_vd:这两个类分别实现了一维卷积的变体,类似于前面的类,但它们的权重处理方式不同。
主类 DEConv 组合了前面定义的卷积层。它在初始化时创建了多个卷积层,并在 forward 方法中将它们的输出结合起来,形成最终的输出。这个类还实现了一个 switch_to_deploy 方法,用于在推理阶段将多个卷积层的权重合并为一个卷积层,以提高计算效率。
在文件的最后部分,提供了一个测试代码块。它创建了一个随机输入数据,并实例化了 DEConv 类。通过调用 forward 方法获得输出,然后调用 switch_to_deploy 方法后再次获得输出,最后检查两个输出是否相等,以验证合并操作的正确性。
总体而言,这个文件展示了如何在深度学习模型中自定义卷积层,进行权重调整和合并,以优化模型的性能和推理速度。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式