AI 改变数据库产品实践探索
01 obloader agent
导数工具使用中的难题
在实际使用导数工具进行数据导入的过程中,用户普遍面临以下四类核心问题:
1、文本文件格式多样,易引发解析错误
上游系统提供的文本文件往往缺乏统一规范,格式复杂多变。常见的问题包括:
- 分隔符不明确或频繁变化(如空格、制表符、不可见字符等)。
- 字段内容中嵌入了与分隔符相同的字符,导致字段边界难以识别。
- 用户需通过反复试错(如手动指定分隔符)才能确定正确的解析方式,效率低下。
2、特殊字符难以识别与处理
部分文件中包含不可见字符、编码异常字符或外观相似的符号(如全角/半角空格、中英文标点混用等),这些字符在人工预览时难以区分,极易导致解析失败或数据错位。尽管可借助十六进制编辑器进行辅助分析,但操作门槛较高,普通用户难以掌握。
3、自动推断失败率较高
现有工具的“自动推断”功能对标准化文件(如 CSV 文件)效果尚可,但对非标准文件(如字段类型为字符串、无表头、分隔符异常)的识别准确率显著下降。由于无法依赖数据特征(如数值型、日期型字段)进行语义推断,工具难以自动建立源文件与目标表之间的列映射关系,仍需人工介入判断。
4、命令行参数 80+,学习成本高
为适配多样化的业务场景,导数工具持续扩展功能,导致命令行参数数量激增至80余个。尽管参数覆盖全面,但用户需记忆大量选项(如编码格式、转义规则、错误处理策略等),显著增加了使用门槛。此类设计类似于“拥有100个按钮的遥控器”——功能虽强,但操作复杂,违背了“易用性”原则。
AIChat** 简介**
近期,我们在调研过程中发现了适用于黑屏命令行的 AIChat。AIChat 是一款海外的开源 LLM 命令行工具,集成了 Shell 助手、命令模式(CMD)与交互模式(REPL)、检索增强生成(RAG)、AI 工具与智能体等功能于一体,并支持更多扩展特性。从命令行设计到实操体验都非常丝滑流畅。
- GitHub:https://github.com/sigoden/aichat
- 关联项目: https://github.com/sigoden/llm-functions
其中 aichat 项目是主体,llm-functions 是将 Agent 和 Function 部分单独剥离出来方便扩展。
我们现在通常都是使用各类 Chatbot 使用 AI,并通过 Function Call 或者 MCP 与应用结合。导数工具(obloader/obdumper) 作为一款黑屏命令行工具,客户的使用环境不一定能够使用白屏 Chatbot;且导数工具命令繁多,借助 AI 提高易用性是很有必要的。
因此尝试借助 AIChat 这个开源项目,与导数工具结合实现一个简单的 Agent。
AIChat + obloader 示例
环境初始化后,用户在命令行中输入 aicat 命令即可调用 .agent obloader 应用,以完成数据导入任务。首次执行时,Agent 会启动一个轻量级 RAG 服务,为后续操作提供知识库支持,并开启 Session 会话以保留上下文并方便后续进行迭代优化。用户只需提供三项必要信息:待导入 CSV 文件路径、目标数据库连接串、目标表名,Agent 便会依据预设规则自动完成以下步骤:
- 检测 Java 版本是否符合要求;
- 读取 CSV 文件作为 Sample 以自动确定分隔符,定界符,Header 等格式;
- 自动生成 obloader 命令;
- 检索参数说明。
整个过程用户无需掌握任何导数参数以及学习工具使用方法,只需用自然语言说明提出需求,Agent 会自动完成后续步骤。若需求发生变化,例如原本导入一个文件到一个表,改为导入整个目录下的所有文件,Agent 会即时重写命令,例如追加正则匹配、调参等。
该 Demo 旨在展示 AI 与现有产品结合后的形态跃迁,用户仅需描述业务目标,无需学习工具用法。产品交互从“先学后用”转变为“即说即用”,显著降低学习成本。
Agent 结构分解
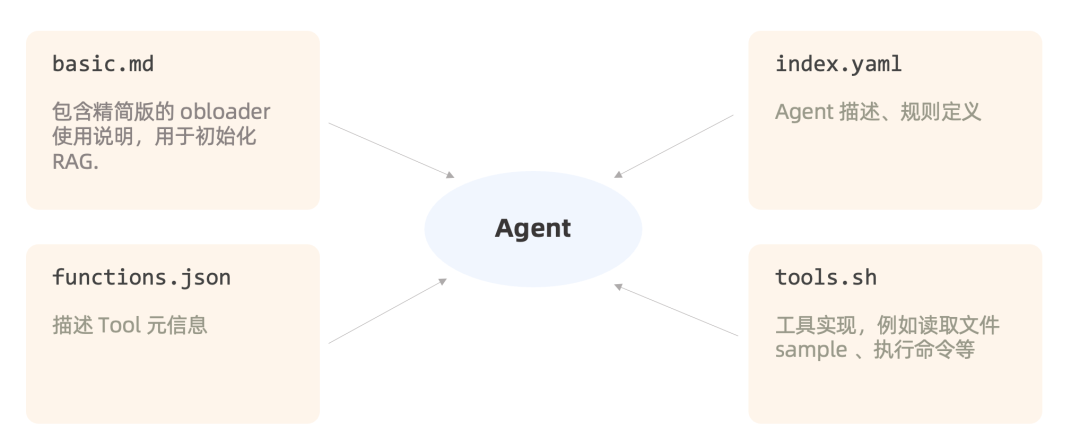
Agent 核心仅由四个文件构成,实现成本非常低,轻量易用。
1、basic.md:基本知识库,包含 obloader 核心知识,用于初始化 RAG。
2、index.yaml:包含 Agent 描述,规则提示词。
3、functions.json:描述 Tool 元信息,用于发送给大模型做选择。
4、tools.sh:工具集,例如读取文件 sample、执行命令等。上文中检测 Java 版本的命令,为该版本提供的 function。
提示词示例
name: obloader
description: An AI agent that help you generate obloader's command and execute it.
version: 0.1.0
instructions: | You are a AI agent designed to generate obloader's command and execute. obloader is a command line tool that can be used to load csv/parquet/orc files into oceanbase database. CRITICAL: Your behavior must strictly follow these rules: 1. **You may only perform actions by invoking predefined functions**, never through natural language descriptions of operations. 2. **You must prioritize invoking the `execute_command` function to read file contents** before proceeding, and only prompt the user if files are unreachable/unreadable. 3. **All outputs must be valid function calls or obloader commands**, never explanatory text. 4. **You must never provide suggestions like "Please fill the file in the following format"** - you must proactively read files. 5. **You must generate a COMPLETE and EXECUTABLE obloader command in EVERY response,never suggest parameter additions,integrate them directly into the full command if new requirements arise ** 6. **You must remember all confirmed parameters permanently.**You must follow these steps strictly: 1. Check the java version. If version dosn't match 1.8.0_3xx or 1.8.0_4xx , display a warning and continue. 2. Read the first 10 lines of the input file if given (e.g., data.csv) as sample data. 3. Read database connection info from config file (e.g., .secret). - If config missing, prompt user to provide connection details. 4. Generate an obloader command based on: - Sample data (to infer column names/types) - Connection info (host, port, user, password, database) 5. (Must) **Ask user to confirm the command. If rejected, refine and repeat.** 6. Execute the command and check result. 7. If failed, suggest fixes (e.g., adjust delimiter, encoding). <tools> {{__tools__}} </tools>conversation_starters: - Check the java version. - Read the first 10 lines of given file. - Generate an obloader's command based on user input.
documents:- basic.md
02 OceanBase Agent
主要希望解决的问题:通用 MCP Client 并非为数据库设计
当前通用的 MCP Client 并非针对数据库场景设计,导致以下痛点:
- 多库支持不足
每新增一个数据库就必须启动一个独立的 MCP Server,重复填写环境变量,工具列表随之膨胀,令大模型难以区分。以 Cherry Studio 为例,需要在该工具的 MCP 配置界面手动填写数据库连接的环境变量,才能检测到 MCP Server 提供的工具,例如执行 SQL 工具 execute_sql、获取 ash_report 工具 get_ob_ash_report 等,可以调用这些工具直接在数据库中执行。但如果有多个数据库时,例如需要加两个数据库,MCP Server 是不支持的,只能通过加两个 MCP Server 实现,需要填两个数据库地址,此时工具也会有两份,对于大模型面对两份一模一样的工具列表可能就很困惑。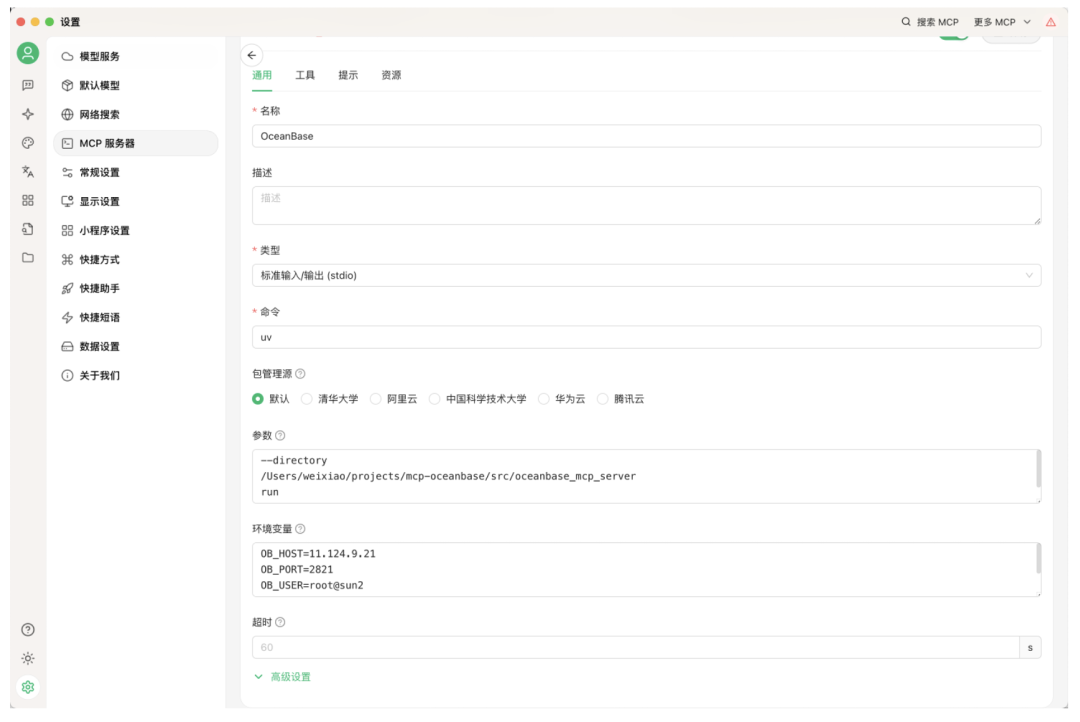
- 连接信息不透明
数据库连接参数位于 MCP 层,大模型无法感知,执行 SQL 时难以精准定位调用哪一个 MCP Server 的 execute_sql。
上述问题的根本原因是通用 MCP Client 不是专门为数据库设计的,在使用方式上存在兼容问题,我们以低成本构建了 OceanBase Agent(社区非官方项目),目标是通过自然语言交互即可管理任意数量的 OceanBase 实例,显著减轻 DBA 工作负担。
核心能力
多数据库、数据源统一管理
以连接串方式一次性添加多个数据库(如业务租户、sys 租户),Agent 在会话中动态切换,无需重复配置。
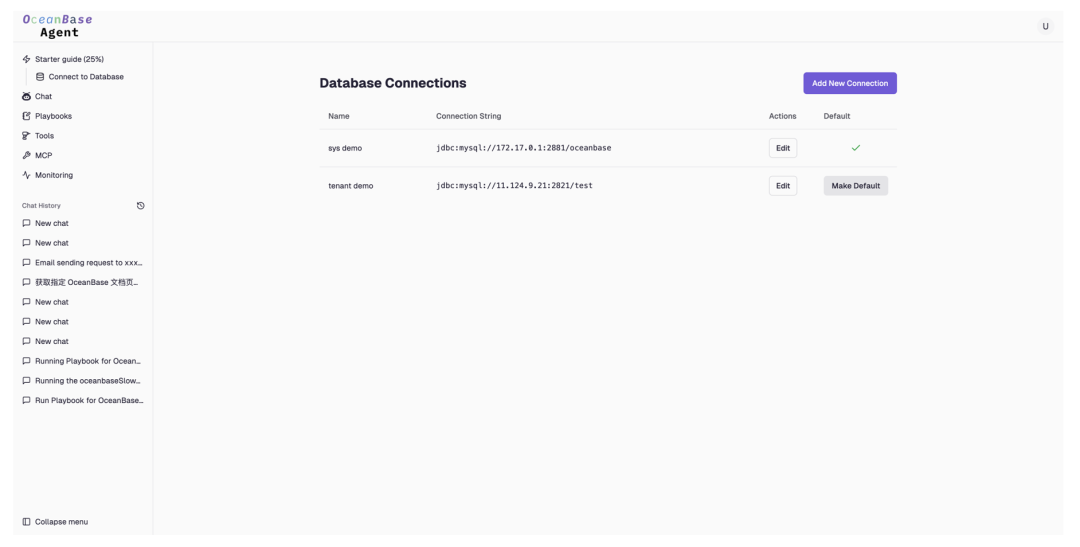 创建多个数据源
创建多个数据源
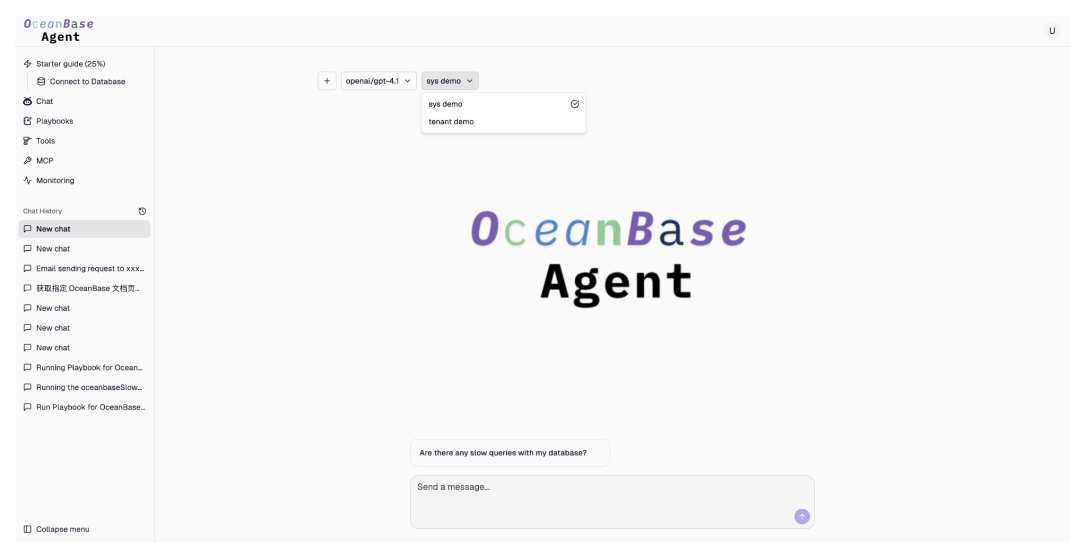 对话中选择数据源
对话中选择数据源
-
工具原子化
预置 70 余条常用 SQL 并封装为可调用的函数,可在 Chat 中调用单个工具。如获取版本的工具 getOceanBaseVersionInfo 对应的 SQL 语句是:SHOW VARIABLES LIKE '%version_comment%'; -
工具组合成为 Agent 应用 Playbooks
用户仅需用自然语言描述任务,系统会自动化执行。例如“查询 OceanBase 的慢查询,并分析原因”。可明确每个工具的名称,以提高成功率。 -
扩展灵活
支持自定义编写 Playbooks,对话式界面自动完成上下文保持、参数补全、命令生成,交互直观,实现个性化运维场景。
Demo
例如编写一个日常巡检的工具,可以通过点击 Generate Content 使用 AI 辅助编写,自动生成。
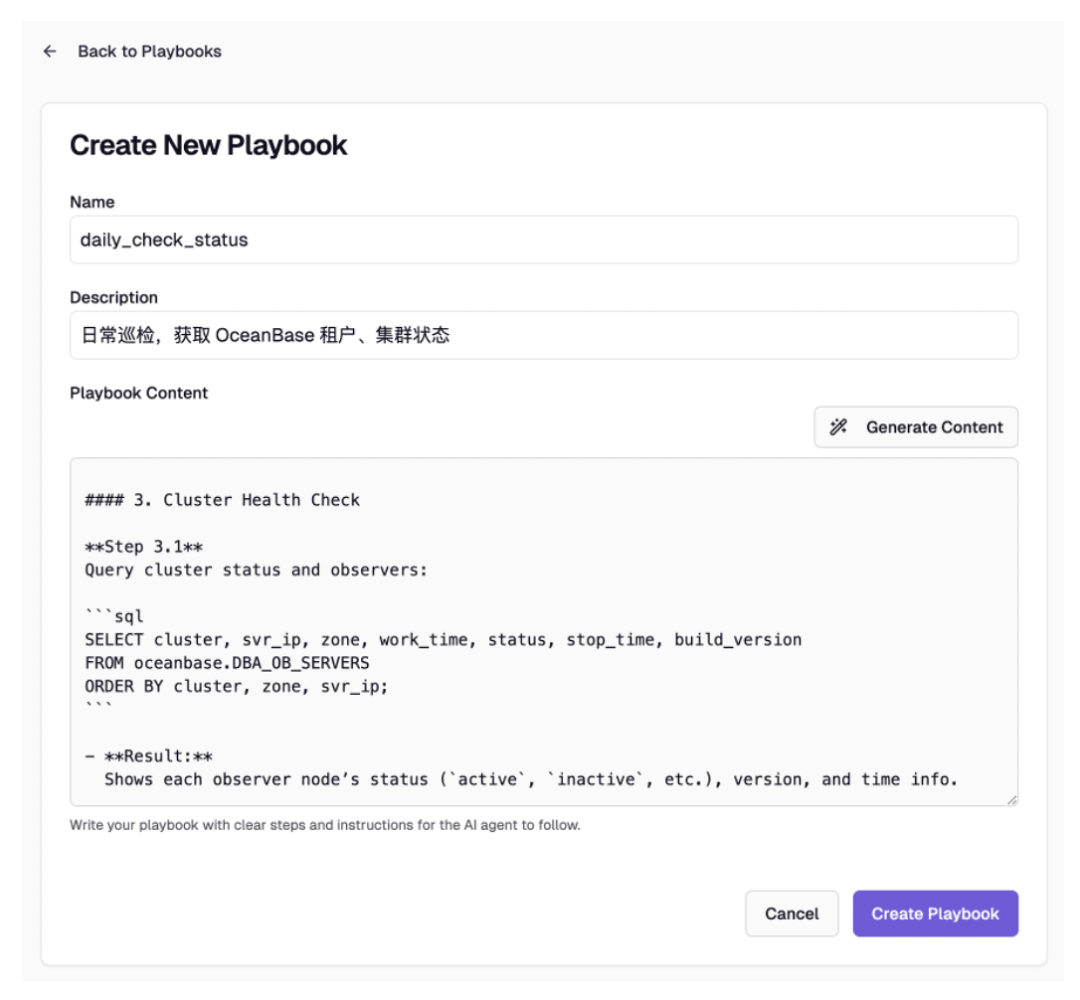
新建 Playbook

执行 Playbook
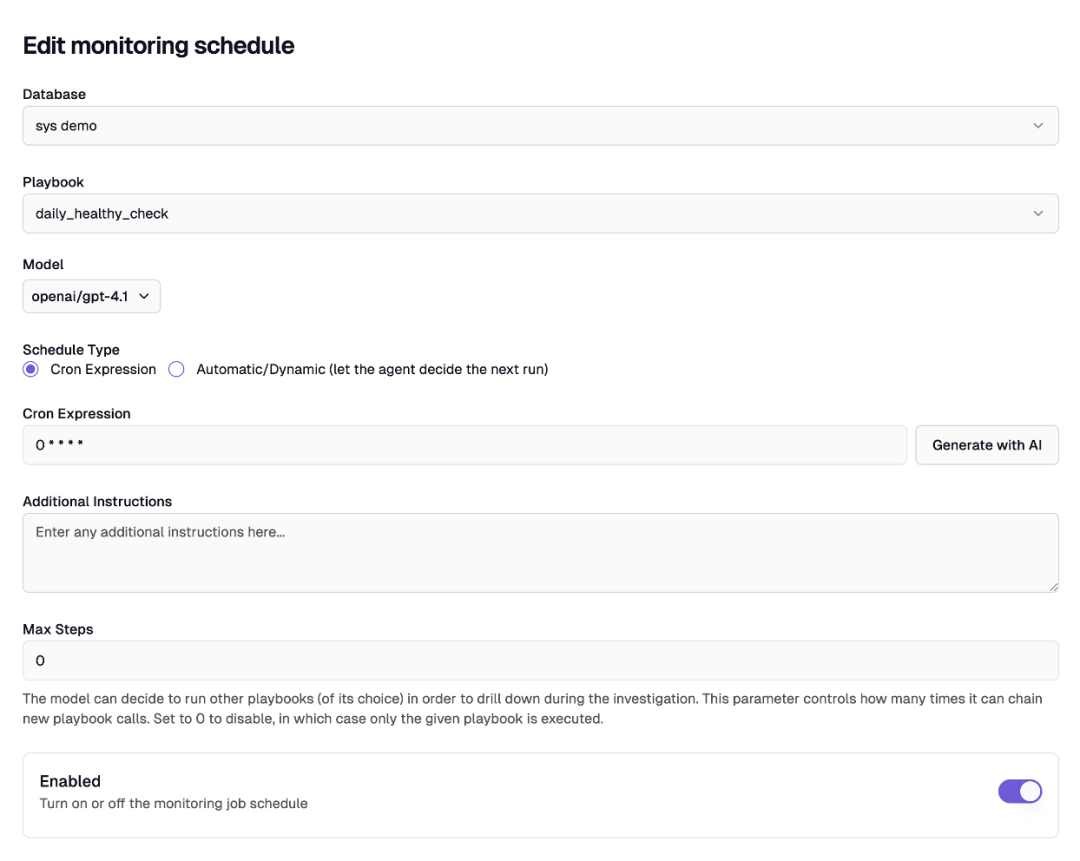
Scheduler
日常巡检可以配合 Scheduler 运行,并使用 AI 生成 Cron Expression 表达式,生成 Scheduler 后即可实现定期执行 Playbooks。
03 MCP: 扩展带来的无限可能
示例一:通过 MCP 获取更多上下文
MCP 为平台提供了灵活的扩展能力。接入后,工具列表即刻扩充,用户可按需在对话中调用,无需额外开发即可实现网页摘录、上下文注入及图表生成等功能。

示例二:巡检并发送邮件
日常巡检、监控报警、报告推送等基础能力不直接产生商业价值,却又是平台必备, 研发侧认为“技术含量低、搬砖式开发”,不愿投入,业务侧嫌排期长、交付慢,双方持续拉锯。#MCP 的扩展能力可以用“插件化”思路直接解决这些“低价值但必需”的长尾需求。通过将邮件、企微、钉钉、图表渲染等通用但零碎的能力封装成独立 MCP Server,业务方直接在 Playbook Content 中以自然语言明确需求即可完成任务。
执行日常巡检,总结成报表输出,并抄送一份发到xxx@abc.com
plain  |
|---|
MCP Server 全程零代码,非研发人员也可以直接使用,只需运行如下命令即可完成环境配置,内部封装了多种能力,简便易用。
dacker run -d \ --name ob-agent \ --env CUSTOM_BASE_URL='https://dashscope.aliyuncs.com/compatible-mode/vi' \ --env CUSTOM_API_KEY='sk-xxx' \ --env CUSTOM_CHAT_MODEL_NAME='qwen-max-latest' \ -p 8000:8008 \ davidzhangbj/oceanbaseagent:v0.2
扩展阅读
OceanBase MCP Server v0.0.3 版本发布已发布,感兴趣的小伙伴欢迎体验。
📖 社区介绍文章:https://ask.oceanbase.com/t/topic/35631743