李宏毅机器学习笔记20
目录
摘要
Abstract
1.Feature normalization
2.Batch normalization
3.Batch normalization-testing
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Feature normalization和Batch normalization相关概念及计算方法
Abstract
This article continues the study of Prof. Hung-yi Lee's 2025 Spring Machine Learning Course, focusing on the concepts and computational methods of Feature Normalization and Batch Normalization.
1.Feature normalization
假设两个参数w1,w2对loss的斜率相差很大,w1斜率变化小,w2斜率变化大,用固定的learning rate很难有好的结果,之前我们的解决办法是让learning rate自适应变化,而现在从另一个方向想,我们直接把难做的error surface去掉会不会好做一些。
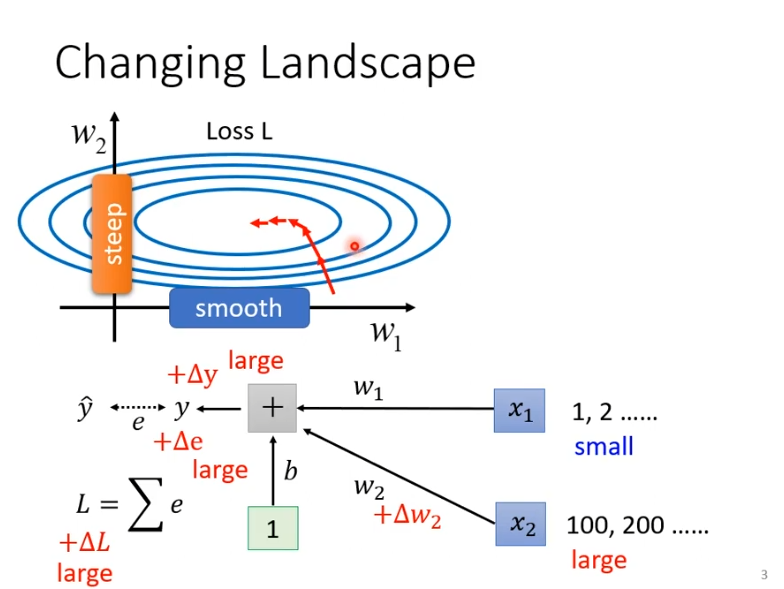
举一个简单的例子,一个非常简单的model为然后计算
与
的距离即为loss。假设x1输入都很小,w1变化对loss的影响就很小,就导致了w1斜率变化小;假设x2输入都很大,w2变化对loss的影响就很大,就算w2变化很,但是因为乘上了x2,所以loss变化很大,也就导致了w1斜率变化大。所以当我们的输入范围差距很大就会出现上述的这种情况。
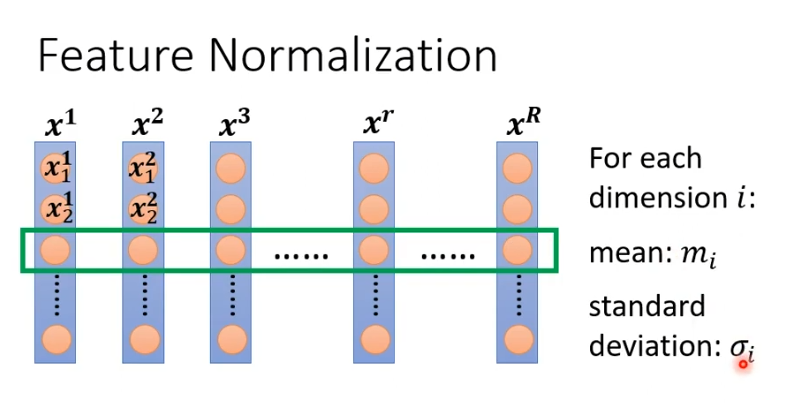
那我们让输入有相同的范围就可以使其变得更好训练, 一种做法是把所有的feature vector都集合起来,那我们把同一个dimension(维度)不同训练资料的feature vector的数值取出来,计算出均值记为,再计算他们的standard deviation(标准差)记为
。
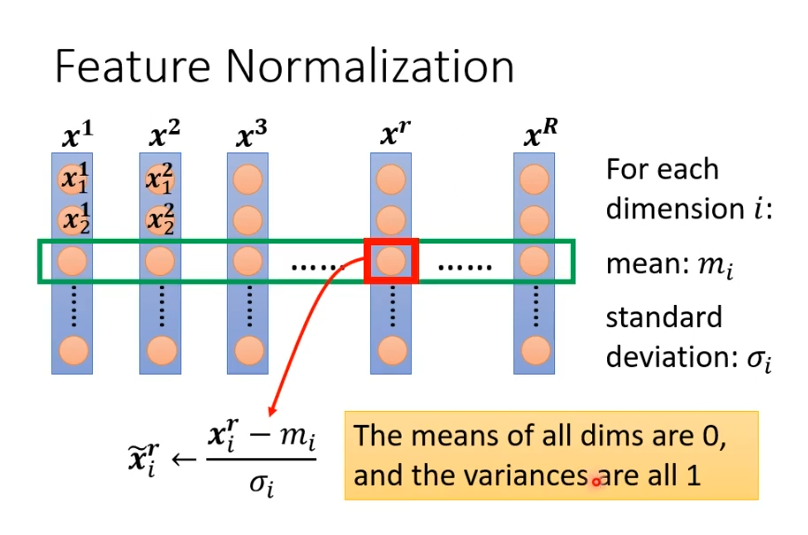
接下来我们就可以做一个normalization,叫做标准化,把某个feature vector的某个维度的值减去之前算出的,再除
得到一个值,记为
。他们有一个特征就是某个维度上的平均值为0,方差为1。对所有的数据都处理后,他们的数值都在0上下,这样就可以制造出比较好训练的error surface。
2.Batch normalization
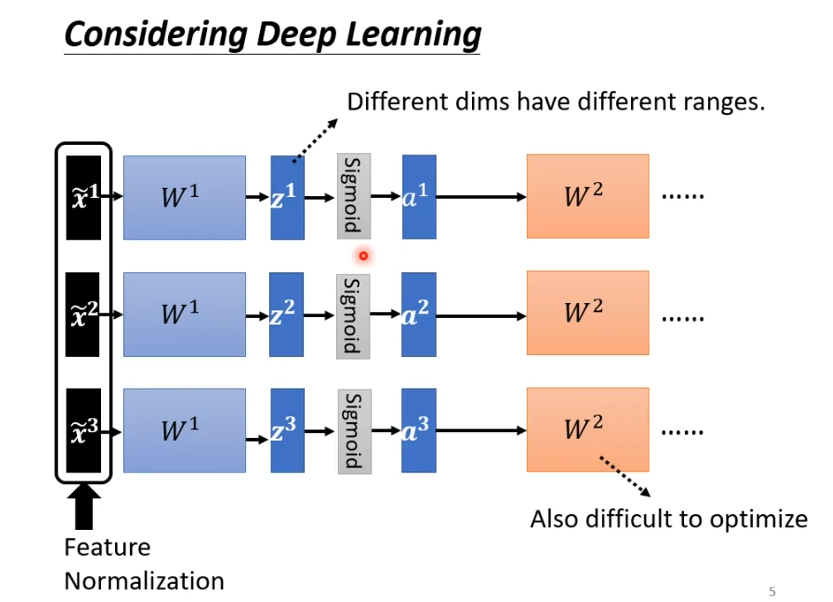
当我们完成feature normalization后,通过layer 1,得到z,通过sigmoid或Relu得到a,再通过下一层,对第二层W2来说,实际上的输入是a,为上一层的输出,输出并没有做feature normalization,所以我们需要对a或z做feature normalization。
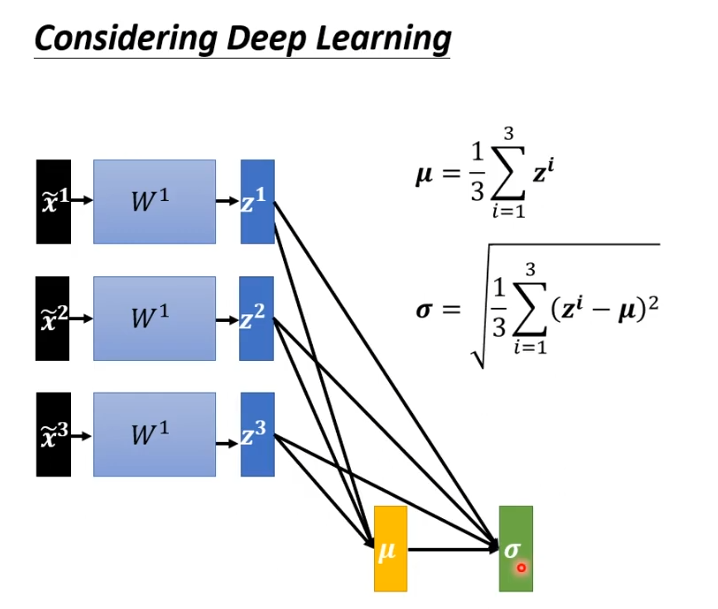
假设对z做feature normalization,我们将z1,z2,z3平均起来记为向量,再去计算向量中每个元素的标准差得到向量
。
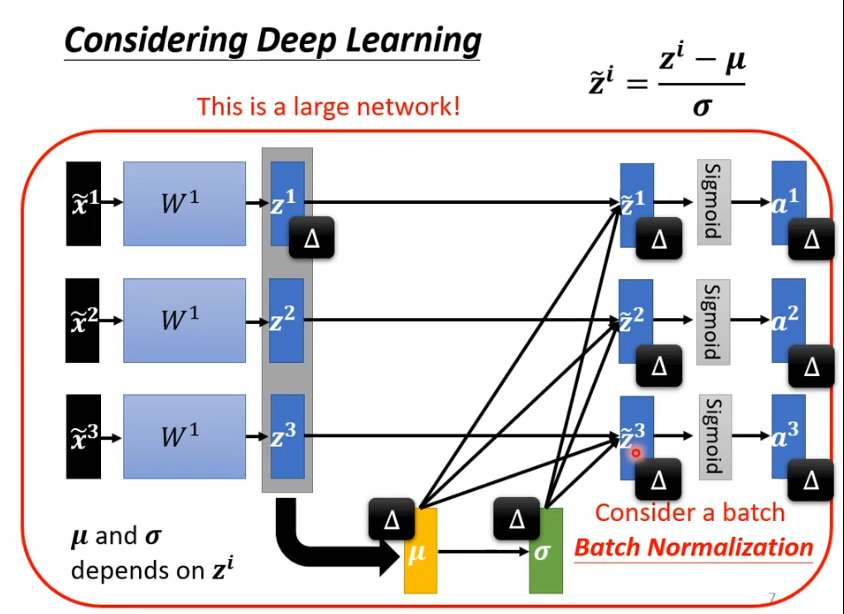
用z1,z2,z3减去再除以
(向量中的每个元素分别计算),最后得出结果向量
,需要注意的是此时如果改变z1,会影响到
,
导致,z2,z3也被更改。实际操作时,我们会让network考虑一个batch,因此我们是对一个batch里的数据做normalization,这也叫做batch normalization,适用于batch比较大的时候。
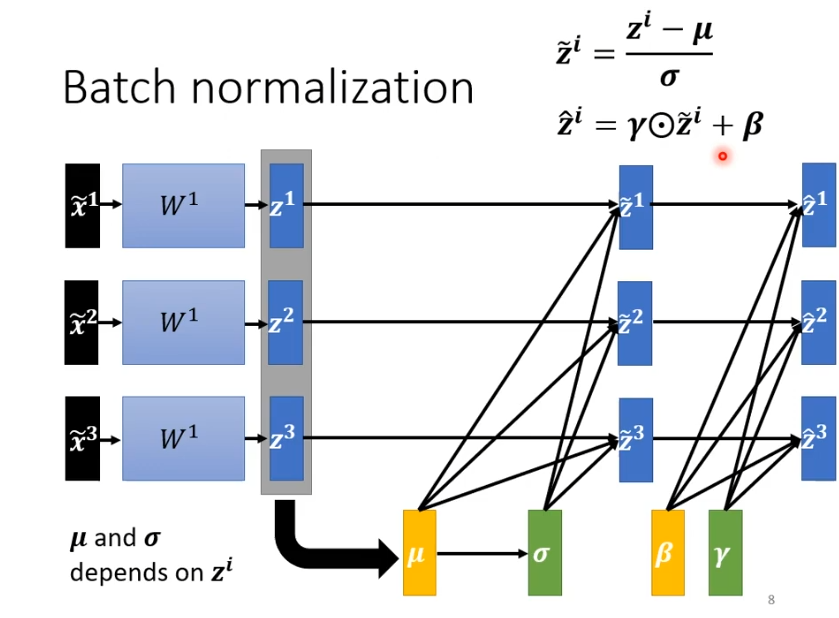
在batch normalization中还会需要进行额外操作,需要让乘上另一个向量
(其中元素各自相乘,结果仍是向量)在加上一个向量
,而
,
是network另外的参数。初始
是全一的向量,
为全零的向量,在开始时不会影响,在后来训练到一定程度,他们会慢慢加进去。
3.Batch normalization-testing

在实际运作中,假设batch设置是64,但是资料并不足填满一个batch,此时的,
如何计算? 在训练中,我们每一个batch计算出的
,
都会拿出来计算moving average,就是在训练中的所有
,
会用于算一个平均值,用平均值代替。