AI【前端浅学】
前言
当前互联网大环境AI非常发达,应用广泛,作为前端人员,学习AI还是非常必要的,但是刚开始又不知道从哪里开始学习,搜了一些资料,我的学习是参考了这篇博客来进行的:AI应用开发入门,我根据这篇博客并结合了自己的项目来进行了简单的学习。
这篇博客给了两个AI学习方向,可供参考
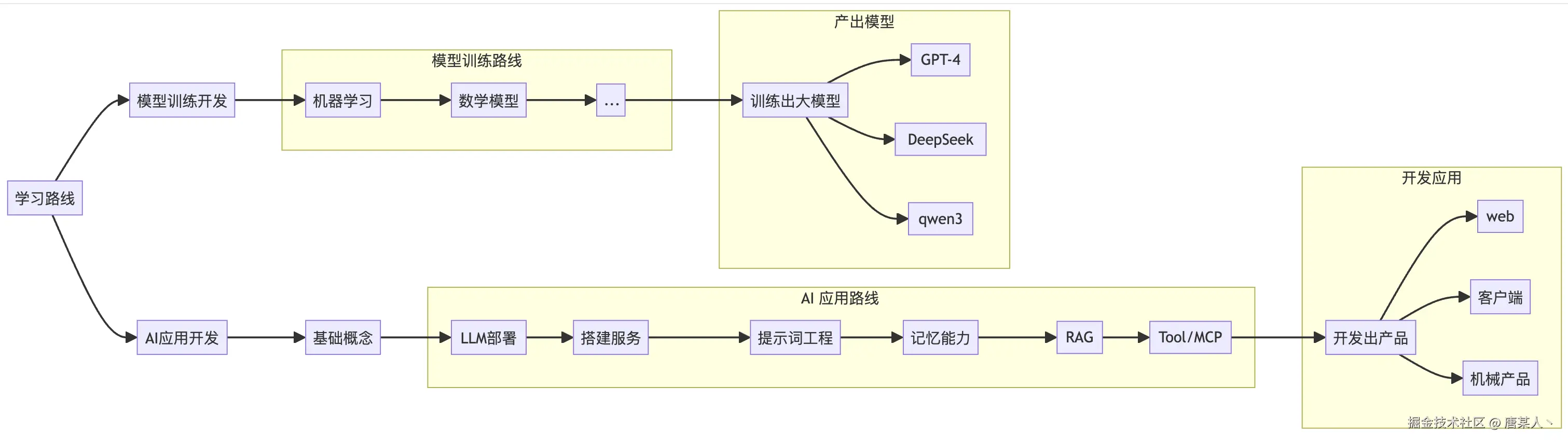
学习总结
简单认识
常见AI应用
- AI低代码平台
类似 Dify、Coze 通过配置,制作出不同的 AI 应用(或者说智能体) - AI辅助编程
类似 Cursor、Trae,通过 IDE 集成 AI 能力,帮助专注程序员的编码提效 - AI应用客户端
类似 ChatBox、Claude for Desktop、豆包客户端。通过本地客户端与 AI 结合,让 AI 能力边界扩展到你的电脑(如文件读写、操作 word 等)
AI应用基本结构
三个主体
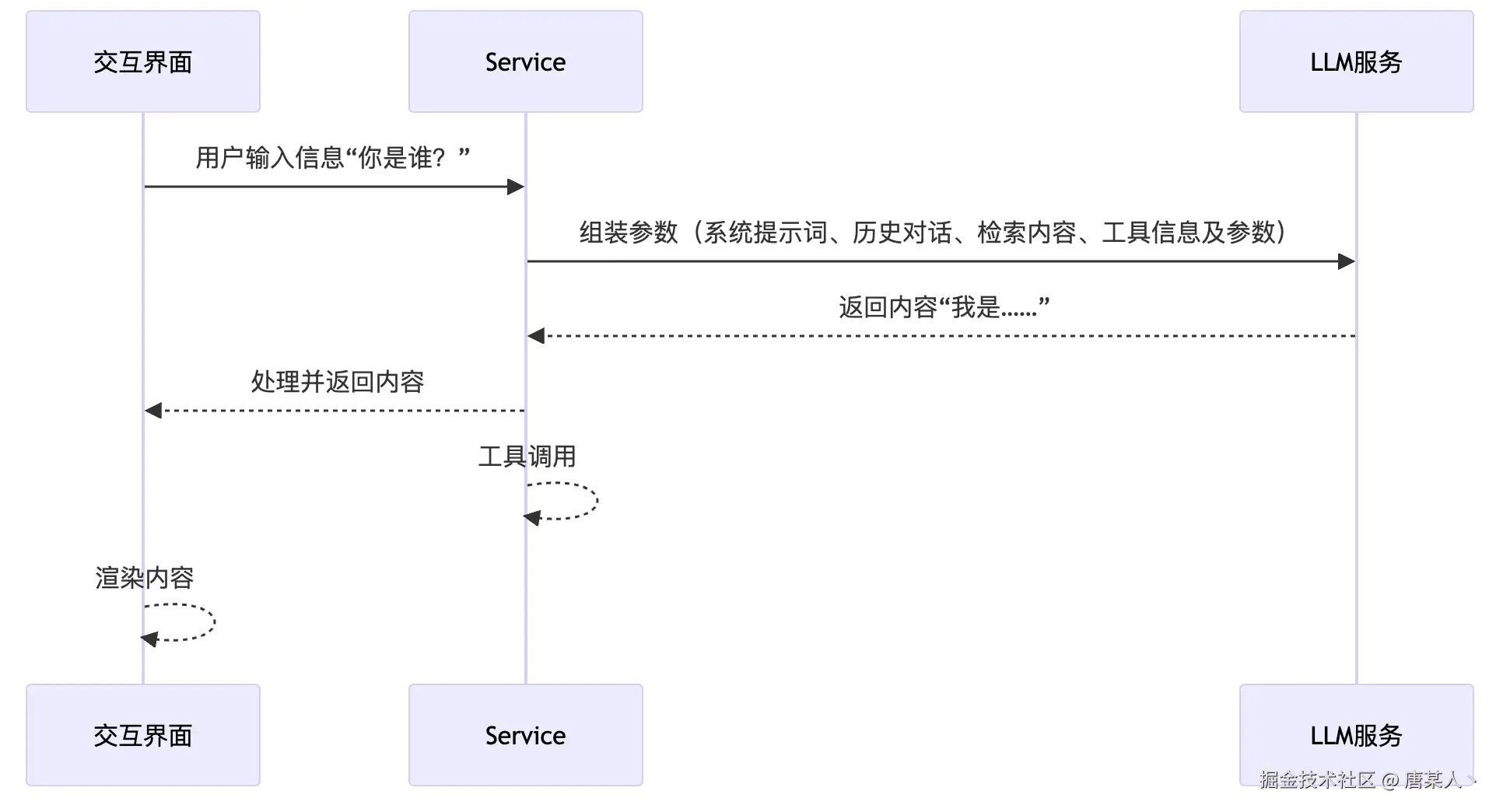
● 交互界面:用户可操作的界面,用来处理用户输入和渲染 LLM 的输出
● Service:处理用户的输入,主要负责提示词的组装和工具调用
● LLM:大模型的核心服务
基础知识
大模型、模型参数、参数文件
大模型(大脑)
大语言模型LLM(Large Language Model),通过学习海量的数据,能够理解和生成像人类一样的语言或完成复杂任务
模型参数(神经元)
将学到的东西记录在模型参数中,大模型参数越大能力越强(1.5b、7b)
参数文件
参数文件是存储人工智能模型中【已训练参数】的重要文件(错题本+解题经验),它包含模型在训练过程中学到的所有权重和偏置值,模型通过这些参数来完成特定任务,比如语言生成、图像识别等
大模型交互
本地LLM:Ollama(用于本地部署和使用大模型的工具)
执行下载命令下载适合自己设备的模型:ollama run deepseek-r1:7b
LLM 本身是一个“离线可执行的智能程序”,它并不需要联网搜索外界信息,它是一个提前“学习”了很多知识的“智能程序”(或“可执行文件”)。当你通过olllama run deepseek-r1:7b时,它就会把这些“知识”加载进来。
本地大模型一般是经过量化的,一般来说个人电脑的配置有限,能跑的参数规格也会比较小,所以不要期待它有太高的智商。实际开发中可以选择大模型厂商提供的服务来进行使用。
提示词Prompt
提示词(Prompt)是大模型中的一种输入方式,就是我们给模型的一段文字或问题,用来告诉它我们想要得到什么样的回答。提示词就像是在和模型对话时的指令或提示,帮助引导模型生成更符合你需求的输出。
(换句话说,如果大模型是你的程序员,你是一个产品需求。如何让程序员把产品做的更符合要求,取决于你给程序员描述的是否清楚。)
开发实践
搭建基础服务
1. 创建模型服务
可以选择任意一家模型厂商,开通一个模型服务使用
以下推荐几个:
字节火山引擎:字节
讯飞星火:星火
OpenAI:OpenAI
然后还从别人的文章中找到一个获取免费key的链接:GPT(能用的AI模型和次数有限制,也可以购买)
2. 开发接口
面临的问题
- 角色的设定,这个AI创立的目的主要是为了什么,需要给LLM设定一个角色,让它知道自己是谁,要做什么
- 记住历史对话,LLM本身不具备对话记忆能力,历史对话的内容需要靠上层的应用管理,并且需要在新一轮的对话中传递给它
- 输出格式规范
- 信息有限,LLM一般都是基于公开的数据进行训练的,但是问到公司资料、代码之类的是肯定不懂的,可能会胡乱回答,这就是所谓的【幻觉】
· · · · ·
这些问题都可以通过提示词工程来解决
提示词工程
代码层提示词
代码层大部分来说,传给LLM的messages是一组对话,messages中的role用来表示说话的角色,常见的分为四种:
messages: [{ role: 'system', content : '你是一个专业的AI助手' },{ role: 'user', content : query },{ role: 'assistant', content : 'AI的回复' },{ role: 'tool', content : '工具' },
]
● system:系统提示词。一般是应用开发者设定好的。
● user: 用户。表述用户输入的信息。
● assistant: AI。表示 AI 回复的信息。
● tool:工具。表示工具执行的结果
content 则是表示具体的说话内容,最终它会被拼接成一个单一的提示词字符串传给 LLM。
系统提示词
一般来说system提示词部分的内容会被重点标记,LLM分配给这部分的注意力权重也会更加高,一般它的作用是作为模型的行为指导,让模型在整个对话中保持一致的角色、风格、内容主题。
const newMessages = [{role: 'system',content: `## 角色你是一个专业的前端导师,你最擅长React、Webpack、Antd这些前端框架,你能够由浅入深的回答用户关于前端的问题## 输出规范- 关于代码问题,你能够按照"设计思路"、"代码实现"两个维度来回答- 跟编程无关的问题你可以拒绝回答`, // 使用了 Markdown 的形式,目的是为了让提示词的结构更加清晰。},...messages, // 传入的用户输入的问题,以及历史聊天记录
];
设置完以后询问,回答:

历史对话
LLM不具备记忆对话功能,但是可以通过每次对话都把历史对话记录传过去(如上面的方法),或者加到提示词中,理解上下文
信息有限
将公司的内部数据塞到提示词里面
const externalContent ='智汇云舟(Wisdom Ark)是一个便于用户查询、学习、使用的前端知识库';
const newMessages = [{role: 'system',content: `## 角色你是一个专业的前端导师,你最擅长React、Webpack、Antd这些前端框架,你能够由浅入深的回答用户关于前端的问题## 参考内容${externalContent}## 输出规范- 关于代码问题,你能够按照"设计思路"、"代码实现"两个维度来回答- 跟编程无关的问题你可以拒绝回答`,},...messages,
];
效果:

Memory记忆
整体流程
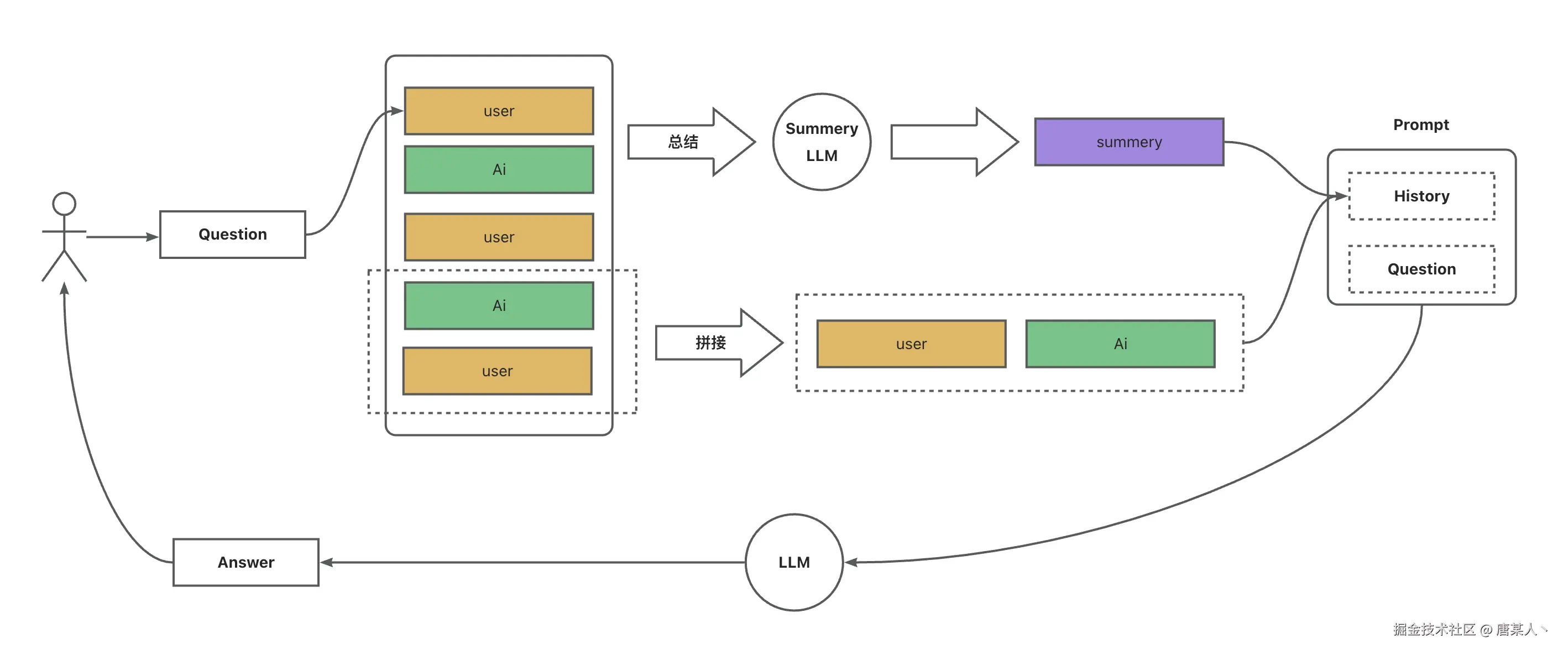
核心就是四个流程:
- 实现一个消息管理队列,用于记录用户和 LLM 的对话内容
- 用户输入时,会将过去的对话总结
– 指定轮次拼接:将指定轮次的对话,通过字符串拼接起来
– LLM 总结:将过往的内容不断通过 LLM 进行浓缩总结 - 将对话总结插入提示词
- 提示词输入给 LLM
代码实现
一、 方案一:
将过去的固定轮次的对话,直接用字符串拼接起来插入到提示词中
优点:会详细的保留过去固定轮次的对话细节
缺点:更久远的对话会丢失,这将导致LLM忘记很早之前聊了什么
二、 方案二:
只记录当前这轮对话,在LLM回复完毕之后,再后置的让总结作用的LLM总结一次过去的聊天内容+当前这一轮的聊天内容
优点:让LLM能够知道过去很久远的聊天内容
缺点:对于过往聊天的细节会越来越模糊
上下文限制
LLM 的输入输出上下文 token 是有限的。大模型的上下文 token 限制 是指模型在每次生成或推理时,能够处理的最大输入和输出文本片段的长度(用 tokens 表示)。如果输入和输出的总长度超过这个限制,模型将无法正常处理,会报错或截断部分内容
RGA
整体流程
- 数据导入:将私域的数据进行分块、向量化处理,然后将向量数据导入到向量数据库中
- 数据检索:将用户的问题向量化处理,然后去向量数据库中匹配相似或者相关语义的内容,然后插入到提示词中交给 LLM 进行分析
核心就是基于用户问题,在内部数据中搜索相关语义的内容,插入到提示词中让 LLM 参考回答。
方案讲解
一般数据的保存形式有三种:1. 文本 2. PDF 3. 网站
要做的就是将私域的数据向量化处理以后,存到一个向量数据库里面,向量库语义搜索;因为传统的全文检索或关键字匹配,依赖单词的字面匹配,无法理解用户输入的语义。
● 先将用户问题(Query)和文档中的文本转换为向量表示。
● 在向量空间里,通过向量相似度(如余弦相似度)比较,找到与用户问题语义相近的内容。
实现
数据导入
导入数据、拆分数据、数据向量化、存入数据库
langChain提供了相关的工具:langChain 侧重javascript的langChain:js_langChain
将数据进行向量化处理需要用到额外的Emedding模型
下载langchain:npm add @langchain/core @langchain/community @langchain/openai langchain -S
下载faiss-node,需要额外build一下:npm add faiss-node@0.5.1 npm rebuild faiss-node
【Faiss是一个用于高效相似性搜索和稠密向量聚类的库】
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { FaissStore } from "langchain/vectorstores/faiss";// 使用TextLoader导入文档
const loader = new TextLoader("/db/faiss/faiss.index");
const docs = await loader.load();// 创建一个分割器将文档进行分割
const splitter = new RecursiveCharacterTextSplitter();
const splitDocs = await splitter.splitDocuments(docs);// 创建Embedding模型
const embeddings = new OpenAIEmbeddings({model: process.env.EMBEDDING_MODEL,configuration: {apiKey: process.env.OPENAI_API_KEY,organization: process.env.API_BASE_URL,},
});// 分批处理,每次最多处理200个文档
const batchSize = 200;
for (let i = 0; i < splitDocs.length; i += batchSize) {const batch = splitDocs.slice(i, i + batchSize);const vectorStore = await FaissStore.fromDocuments(batch, embeddings);await vectorStore.save("/db/faiss");
}
数据检索
主要做的就是基于用户的问题在向量数据库中查询相关的内容,
第一步创建一个向量模型,第二步加载向量数据库,第三步将用户的输入进行检索匹配,第四步拼接内容,最后就是基于搜到内容,插入到提示词中,让 LLM 进行参考回答。
// 数据检索
// 加载向量数据库
const vectorStore = await FaissStore.load(dbPath, embeddings);
// 检索相关内容
const retriever = vectorStore.asRetriever(2);
const result = await retriever.invoke(query);
// 拼接内容
const externalContent = result.map((item) => item.pageContent).join("\n");
// 基于搜到的内容,插入到提示词中,让LLM进行参考回答
Tools
让LLM具备了调用外部接口的能力,可以实际帮你执行一些任务
整体流程
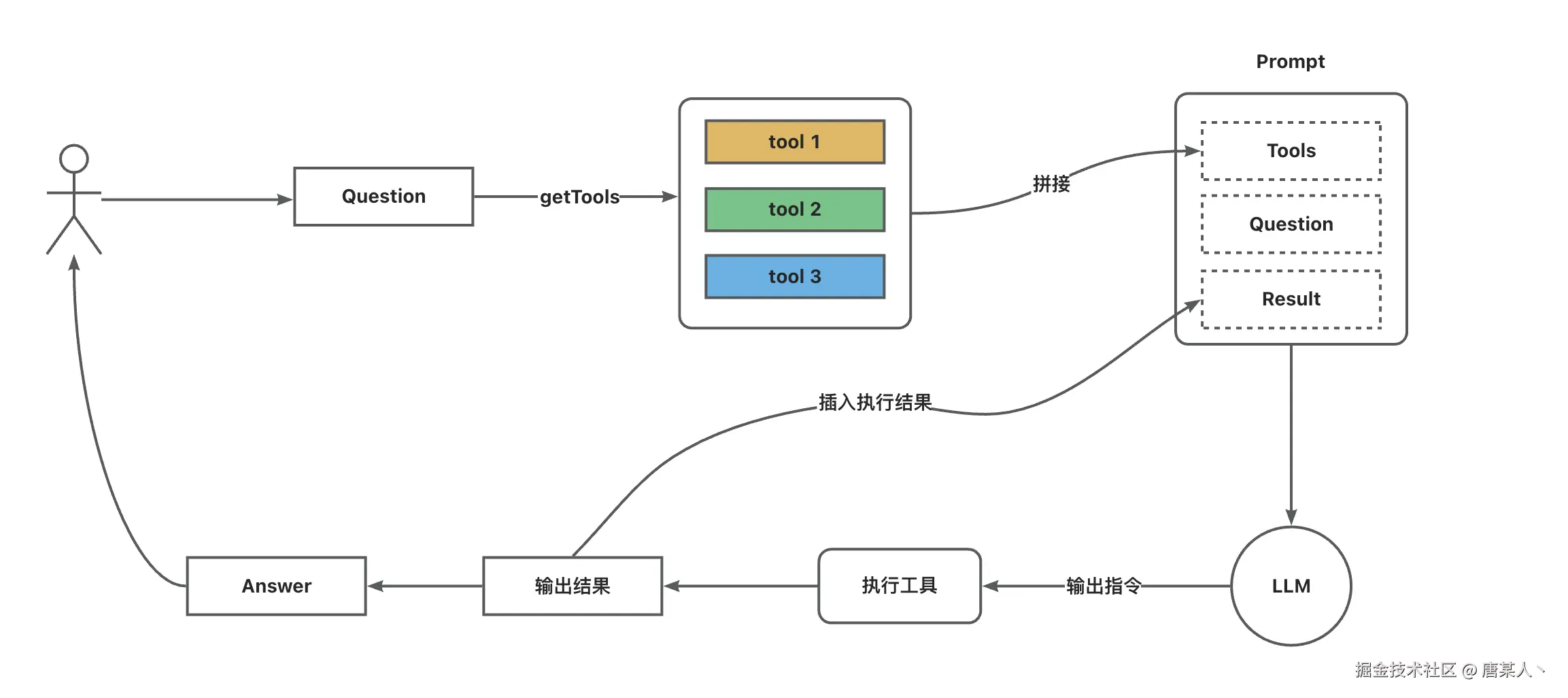
核心思路如下
- 先定义一些工具描述(告诉 LLM 这个什么时候调用)传入给LLM
- LLM 会根据你的问题,自主思考决策是否调用工具
- 如果 LLM决策是调用工具,就会返回工具调用的指令(包含函数名、所需的调用参数)
- 然后我们根据函数名找到对应的 tool 传入参数并执行
- 再将执行结果输入给 LLM,继续推进对话
代码实现
- 声明工具
function的参数:
- name:函数名
- description:函数的描述,一般是描述什么场景,怎么使用
- parameter:函数所需的参数类型
fun 就是我们要执行的具体的函数,一般工具有两个核心场景: - 查询外部提供给LLM
- 执行一些操作(文件的读写等等)
import path from 'path';
import { z } from 'zod';
import * as fs from 'fs';// 声明工具集
// 这个方法需要结合node使用才可储存
const toolsMap = new Map([['writeCode',{type: 'function',function: {name: 'writeCode',description: '将代码写入到文件中',parameters: z.object({code: z.string().describe('代码'),}),},fun: async ({ code }) => {let result = '';try {await fs.promises.writeFile(path.join(__dirname, 'code.ts'), code);result = '代码写入成功';} catch (error) {result = '代码写入失败';}return [{role: 'tool',content: result,},];},},],
]);// 该方法将用户提供的代码转换为txt文件返回并下载
const toolsMap = new Map([['writeCode',{type: 'function',function: {name: 'writeCode',description: '将代码储存为文件',parameters: z.object({code: z.string().describe('代码'),}),},fun: async ({ code }: { code: string }) => {try {// 在浏览器中创建一个可下载的文件const blob = new Blob([code], { type: 'text/plain;charset=utf-8' });const url = URL.createObjectURL(blob);const a = document.createElement('a');a.href = url;a.download = 'code.txt'; // 默认文件名document.body.appendChild(a);a.click();document.body.removeChild(a);URL.revokeObjectURL(url); // 清理 URLreturn {role: 'tool',content: '代码已生成并开始下载',};} catch (error) {console.error('下载失败:', error);return {role: 'tool',content: '代码下载失败',};}},},],
]);export default toolsMap;
在调用对话AI接口,传入tools参数
// 获取tools
const tools = Array.from(toolsMap.values()).map(({ fun, ...item }) => {const jsonSchema = zodToJsonSchema(item.function.parameters);return {type: item.type,function: {name: item.function.name,description: item.function.description,parameters: {type: 'object',properties: jsonSchema.properties,required: jsonSchema.required,},},};
});// 调用API并流式返回结果
const response = await openai.chat.completions.create({model: 'gpt-4o-mini',messages: newMessages, // 消息格式: [{role: "user", content: "你好"}]temperature: 0.7,tools: tools as any,
});// const tools = Array.from(toolsMap.values()).map(({ fun, ...item }) => ({
// ...item,
// parameters: zodToJsonSchema(item.function.parameters),
// }));
注:上面文件的下面注释写法不正确×,parameters是一个zod对象不是JSONSchema,会导致OpenAI API无法解析工具参数引发503等其他错误
2. 执行
- 区分LLM返回类型,如果返回的是工具调用,则需要记录具体的函数名
- 将不断接收的 arguments 拼接起来
- 解析 arguments,判断参数是否符合预期
- 将 arguments 传入工具函数并执行
const reply = response.choices[0].message.content;
const toolsCall = response.choices[0].message.tool_calls;
console.log(reply);
if (reply) return response.choices[0].message.content;
else if (toolsCall) {console.log('toolsCall', toolsCall);toolsCall.map(async (toolCall) => {const toolId = toolCall.id;if (!toolId) return '没找到对应工具';const functionName = toolCall.function.name;const tool = toolsMap.get(functionName);if (tool) {const args = JSON.parse(toolCall.function.arguments);const toolResponse = await tool.fun(args).content;return toolResponse;} else {return '没找到对应工具';}});
}
因为toolsCall.map不会等待异步执行,导致函数提前返回,所以使用await Promise.all()等待所有工具调用完成
else if (toolsCall) {const toolResponses = await Promise.all(toolsCall.map(async (toolCall) => {const toolId = toolCall.id;if (!toolId)return {role: 'tool',content: '未找到对应工具',tool_call_id: toolId,};const functionName = toolCall.function.name;const tool = toolsMap.get(functionName);if (tool) {try {// 解析参数const args = JSON.parse(toolCall.function.arguments);// 执行工具函数const result = await tool.fun(args);return {role: 'tool',content:typeof result === 'string' ? result : JSON.stringify(result),tool_call_id: toolId,};} catch (error) {console.error('工具执行失败:', error);return {role: 'tool',content: '工具执行失败',tool_call_id: toolId,};}} else {return {role: 'tool',content: '未找到对应工具',tool_call_id: toolId,};}}),);return JSON.parse(toolResponses[0].content).content;
…未完待续