【YOLO 模型进阶】(2)YOLO v1 超详解:从网络架构到优缺点剖析
前言
作为 YOLO 系列的 “开山之作”,2016 年发布的 YOLO v1 彻底打破了传统两阶段检测算法(如 R-CNN)的范式,首次实现了 “单网络、端到端” 的实时目标检测。虽然如今 YOLO 已迭代到 v8 版本,但理解 v1 的核心设计 —— 从网络架构到损失函数的逻辑,是掌握整个 YOLO 家族的关键。本文将从核心思想、网络结构、损失函数、NMS 机制到优缺点,全方位拆解 YOLO v1。
一、YOLO v1 的核心思想:把检测变成 “网格回归”
YOLO v1 的核心思想可以用一句话概括:将整幅图像划分为网格,让每个网格 “负责” 检测中心落在其中的目标,通过单网络直接回归目标的位置和类别。
具体拆解为 3 个关键逻辑:
- 图像网格化划分:将输入图像固定为 448×448 像素,然后均匀划分为 7×7=49 个网格(Grid Cell)。例:如果一只猫的中心坐标落在 “第 3 行第 5 列” 的网格内,那么这个网格就必须 “负责” 预测这只猫的位置和类别。
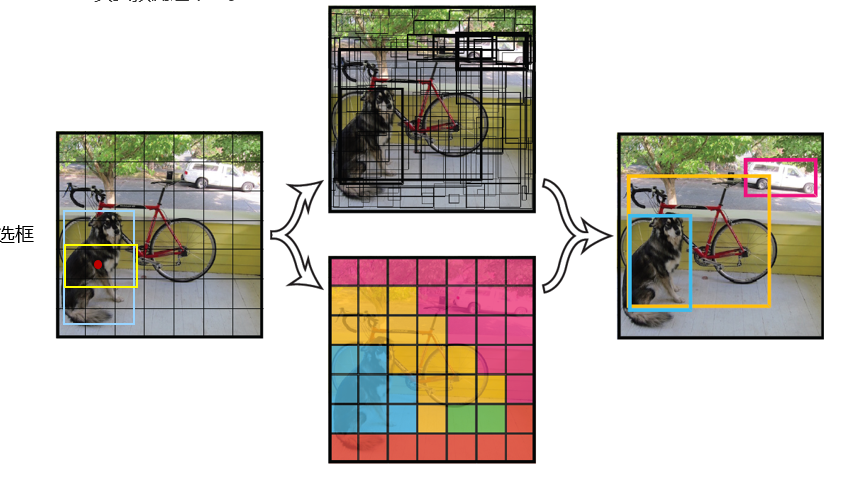
- 每个网格的预测任务:每个网格需要输出两组核心信息:
- 2 个边界框(Bounding Box):每个边界框包含 5 个参数 ——
(x, y, w, h, c)。其中:x, y:边界框中心相对于当前网格左上角的偏移量(取值范围 0~1,确保中心在网格内);w, h:边界框的宽和高,相对于整幅图像的比例(取值范围 0~1,适配不同大小的目标);c:置信度(Confidence)—— 表示该边界框内 “有目标” 的概率,同时反映边界框与真实目标的重合度(IoU),公式为:c = Pr(Object) × IoU(Bbox, GT)(若网格内无目标,Pr(Object)=0,则c=0)。
- 20 个类别概率:对应 PASCAL VOC 数据集的 20 个类别(如猫、狗、汽车等),表示 “当前网格内的目标属于某类别的概率”(仅当网格内有目标时,该概率才有意义)。
- 2 个边界框(Bounding Box):每个边界框包含 5 个参数 ——
- 端到端回归:整个过程无需 “生成候选框”“分类器筛选” 等分步操作,输入图像经过一次网络推理,直接输出
7×7×30的张量(30=2 个边界框 ×5 个参数 + 20 个类别概率),实现 “输入即输出”。
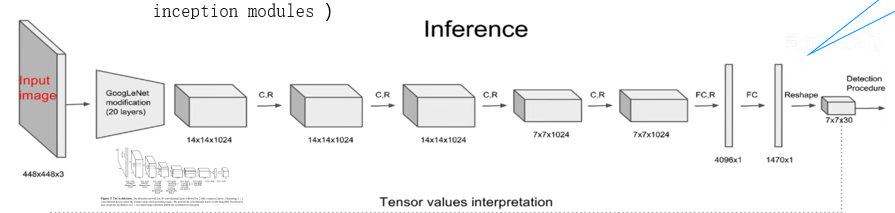
二、YOLO v1 的网络架构:借鉴 GoogLeNet,聚焦 “特征提取 + 回归”
YOLO v1 的网络架构借鉴了 GoogLeNet 的设计思路,但简化了 Inception 模块,改用 “1×1 卷积降维 + 3×3 卷积提特征” 的组合,核心目标是高效提取图像特征,并通过全连接层完成回归任务。
网络结构分为 3 个部分:输入层、卷积层、全连接层,具体如下表所示:
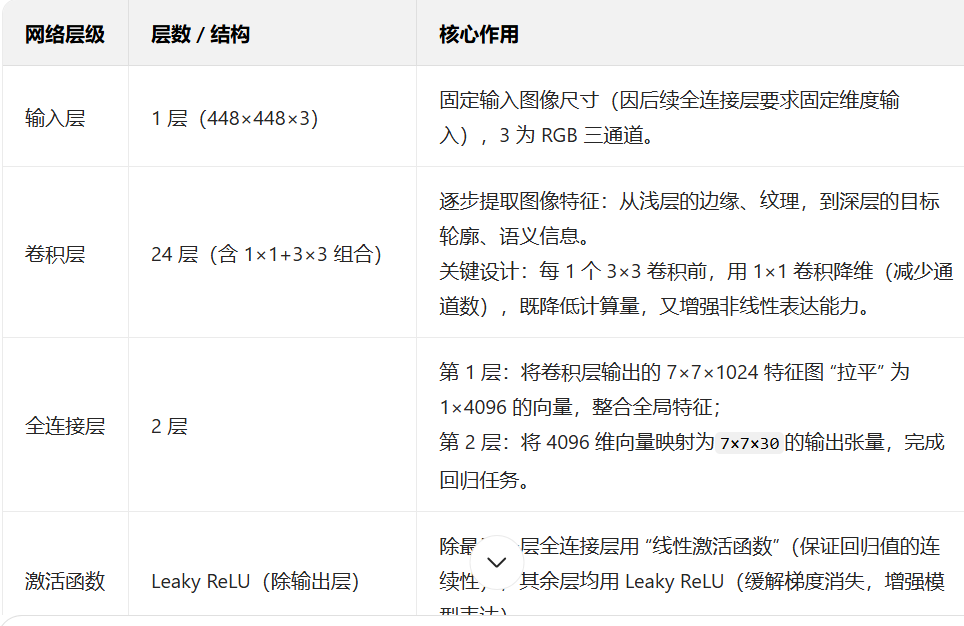
为什么最终输出是 7×7×30?再次明确:7×7 是网格数量,30 是每个网格的输出维度 ——2 个边界框各输出 5 个参数(2×5=10),加上 20 个类别概率,总计 10+20=30。这个维度设计是 YOLO v1 实现 “网格回归” 的核心载体。
三、YOLO v1 的损失函数:平衡 “位置、置信度、分类” 三大误差
YOLO v1 的损失函数是其性能的关键 —— 目标是同时最小化 “边界框位置误差”“置信度误差” 和 “类别概率误差”,且需要对不同误差赋予不同权重,避免某类误差主导训练。
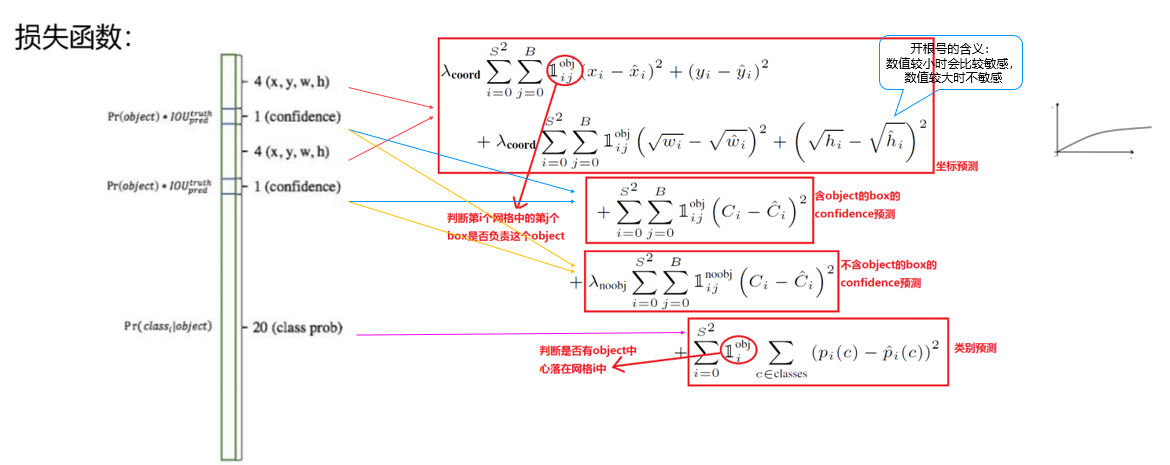
损失函数整体采用均方误差(MSE),但通过 “权重系数” 和 “逻辑判断” 区分不同误差的重要性,具体拆解为 3 部分:
1. 边界框位置误差(权重 λ_coord=5)
目标:让预测的边界框(x, y, w, h)尽可能接近真实框(GT)。关键逻辑:
- 仅对 “包含目标的网格” 中的边界框计算位置误差(网格内无目标则位置误差为 0);
- 对
w和h采用 “平方根” 处理:因为大目标的宽高误差对检测效果影响较小(比如大汽车宽差 10 像素影响不大),小目标宽高误差影响较大(比如小猫宽差 10 像素就会框偏),平方根可缩小大目标的误差权重,放大小目标的误差权重,平衡大小目标的位置精度。
位置误差公式(简化版):Loss_coord = λ_coord × Σ[(x_pred - x_gt)² + (y_pred - y_gt)² + (√w_pred - √w_gt)² + (√h_pred - √h_gt)²](λ_coord=5:位置误差对检测至关重要,所以赋予较高权重)

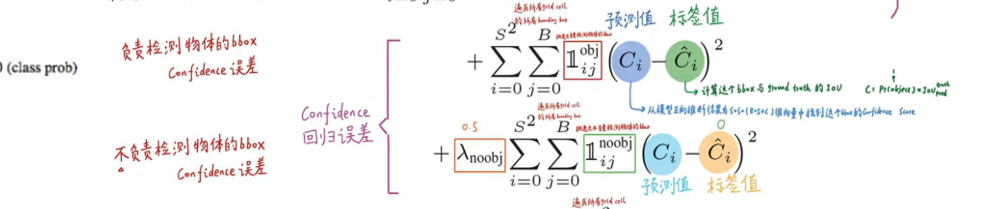
2. 置信度误差(权重 λ_noobj=0.5)
目标:让预测的置信度c尽可能接近真实置信度(c_gt = Pr(Object) × IoU(Bbox, GT))。关键逻辑:
- 分两种情况计算:
- 包含目标的网格(Pr (Object)=1):计算该网格内两个边界框的置信度误差,权重为 1(因为需要精准预测 “有目标” 的置信度);
- 不包含目标的网格(Pr (Object)=0):计算该网格内两个边界框的置信度误差,权重 λ_noobj=0.5(避免无目标网格的置信度误差过大,掩盖其他误差)。
置信度误差公式(简化版):Loss_conf = Σ[(c_pred - c_gt)²](含目标网格) + λ_noobj × Σ[(c_pred - 0)²](无目标网格)
3. 类别概率误差(权重 λ_class=1)
目标:让预测的类别概率尽可能接近真实类别(GT 类别为 1,其他为 0)。关键逻辑:
- 仅对 “包含目标的网格” 计算类别误差(无目标网格的类别概率无意义,误差为 0);
- 类别概率与边界框数量无关(每个网格仅输出一组类别概率,而非每个边界框对应一组)。
类别误差公式(简化版):Loss_class = Σ[(p_pred - p_gt)²](仅含目标网格)

损失函数总结
整体损失 = 位置误差 + 置信度误差 + 类别误差通过权重 λ_coord=5、λ_noobj=0.5 的设计,YOLO v1 优先保证 “位置精度” 和 “有目标网格的置信度精度”,同时避免无目标网格的误差干扰训练。
四、NMS 非极大值抑制:解决 “重复检测” 问题
YOLO v1 虽然通过网格划分减少了重复检测,但仍可能出现 “多个网格预测同一目标” 或 “同一网格的两个边界框都预测同一目标” 的情况 —— 此时需要NMS(非极大值抑制) 筛选最优边界框,剔除冗余框。
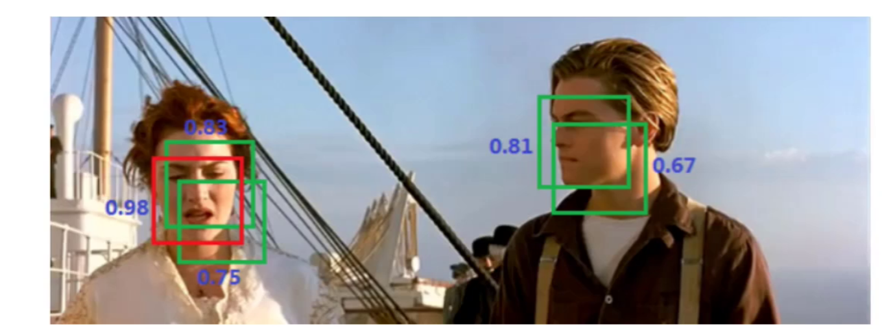
NMS 的核心逻辑的 4 个步骤:
- 筛选高置信度框:先将所有预测框的置信度低于阈值(如 0.1)的框直接剔除,减少计算量;
- 按置信度排序:将剩余的预测框按置信度从高到低排序;
- 迭代抑制冗余框:
- 取置信度最高的框作为 “基准框”,保留该框;
- 计算其他框与 “基准框” 的 IoU,若 IoU 大于阈值(如 0.5,表示两个框高度重叠),则剔除这些冗余框;
- 从剩余框中再取置信度最高的框作为新的 “基准框”,重复上述步骤,直到所有框都被处理;
- 输出最终框:最后保留的框即为无重复的检测结果。
通过 NMS,YOLO v1 能有效解决 “同一目标被多次检测” 的问题,让检测结果更简洁、准确。
五、YOLO v1 的优缺点:开山之作的光芒与局限
作为 YOLO 系列的第一个版本,YOLO v1 的优点奠定了其 “实时检测标杆” 的地位,但也存在明显的局限性,这些局限也成为后续版本(v2~v8)迭代的核心方向。
1. 核心优点:重新定义 “实时检测”
- 速度极快:标准版本(24 层卷积)每秒可处理 45 帧图像(45 FPS),精简版(9 层卷积)甚至可达 150 FPS,完全满足视频实时检测需求(通常要求≥30 FPS);
- 假阳性率低:由于采用 “全局图像推理”(而非局部候选框),YOLO v1 能更好地结合上下文信息,减少 “将背景误判为目标” 的情况(比如不会把树干误判为行人);
- 泛化能力强:模型学到的是目标的 “全局特征”,而非局部细节,因此迁移到新场景(如从 “检测汽车” 迁移到 “检测无人机”)时,性能下降较少。
2. 主要缺点:奠定后续迭代方向
- 小目标检测精度差:每个网格仅输出 2 个边界框,且仅负责检测 “中心落在网格内” 的目标 —— 若多个小目标(如一群鸟)的中心落在同一个网格内,模型只能检测出 1 个,导致漏检;
- 边界框定位不准:损失函数中对大小目标的位置误差采用相同权重(虽用平方根优化,但仍不够),且无 “先验框(Anchor)” 引导,导致大目标的边界框容易偏位;
- 对非常规比例目标不友好:由于没有 Anchor 框的 “形状先验”,对于宽高比例极端的目标(如细长的电线杆、扁平的书本),模型难以预测出精准的边界框;
- 网格敏感问题:目标中心若刚好落在两个网格的交界处,可能导致两个网格都 “不愿” 负责检测该目标,出现漏检。
六、总结:YOLO v1 的 “开创性” 与 “传承性”
YOLO v1 的意义不仅在于 “实现了实时检测”,更在于它开创了 “单阶段检测” 的新思路 —— 用 “网格回归” 替代 “候选框 + 分类” 的分步流程,为后续目标检测算法的发展提供了方向。
虽然 YOLO v1 存在小目标检测差、定位不准等问题,但这些局限也成为后续版本的优化重点:
- YOLO v2 引入 “Anchor 框” 解决定位不准和比例适应问题;
- YOLO v3 用 “多尺度检测” 提升小目标精度;
- 最新的 YOLO v8 则通过 “Anchor-Free” 和 “动态头部” 进一步优化速度与精度。
理解 YOLO v1 的设计逻辑,就像掌握了一把钥匙 —— 能更清晰地看懂后续版本的迭代思路,也能更深入地理解目标检测的核心挑战。下一篇文章,我们将继续讲解 YOLO v2~v3 的核心改进,看看 YOLO 是如何一步步走向成熟的。