树和二叉树——一文速通
一、二叉树的基本形态
二叉树有5种基本形态,理解了这些形态就掌握了所有复杂二叉树的基础。
(1)空二叉树:没有任何结点。
(2)只有一个根结点的二叉树:只有根结点,左、右子树都为空。
(3)只有根结点和左子树:右子树为空。
(4)只有根结点和右子树:左子树为空。
(5)具有根结点、左子树和右子树:这是最完整的形式。注意 根二叉树 和 空二叉树
二、二叉树的重要性质
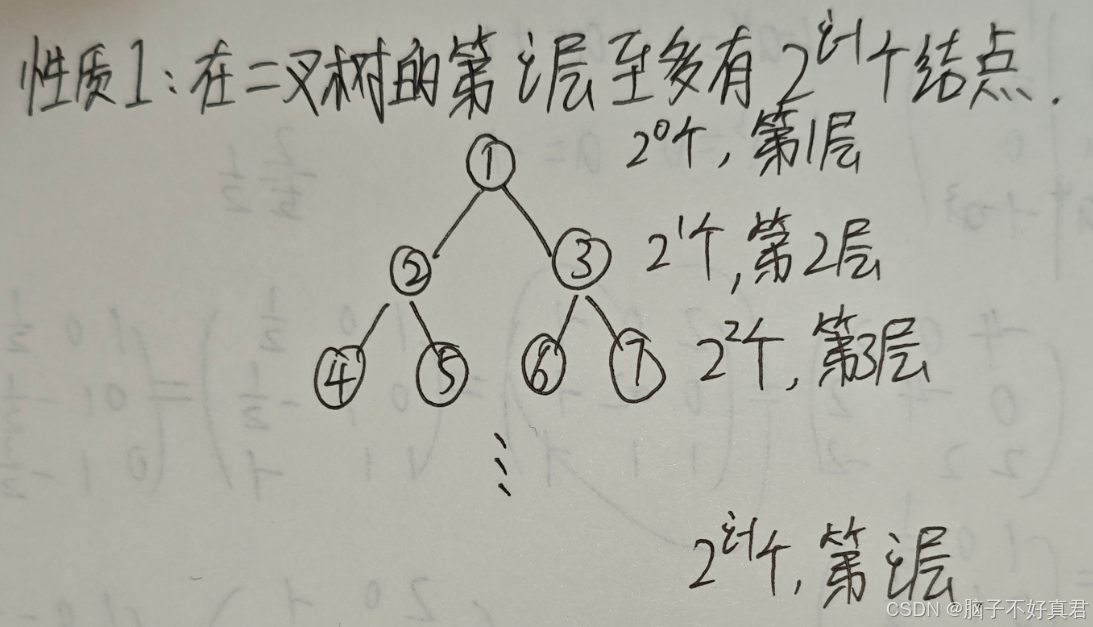
性质1
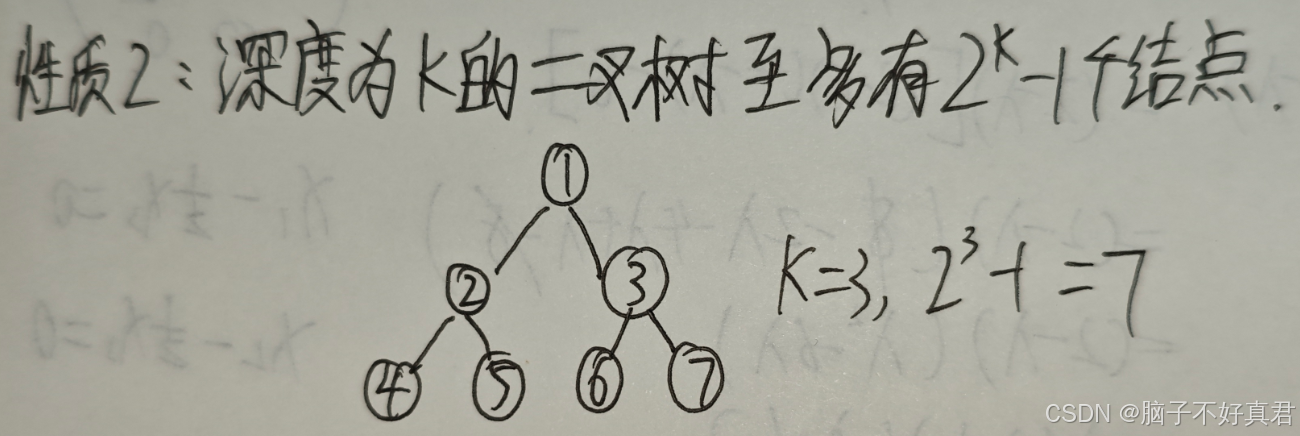
性质2
性质3
性质3推导


性质4
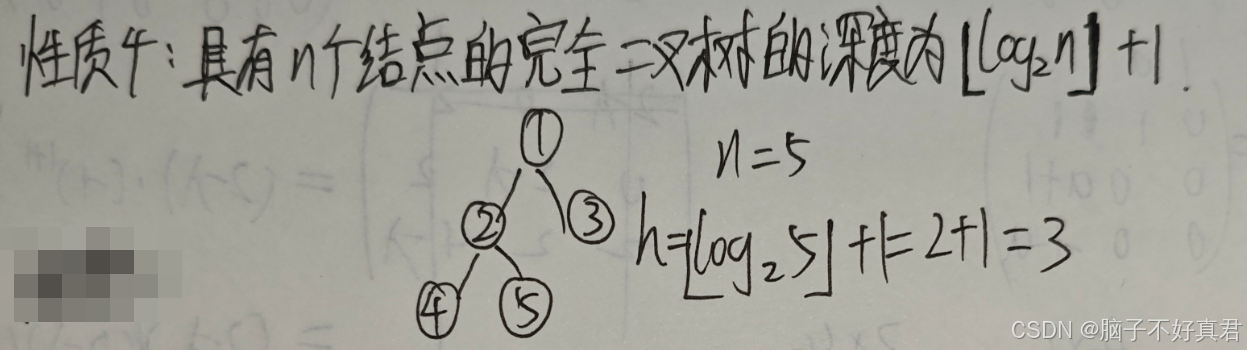
性质5

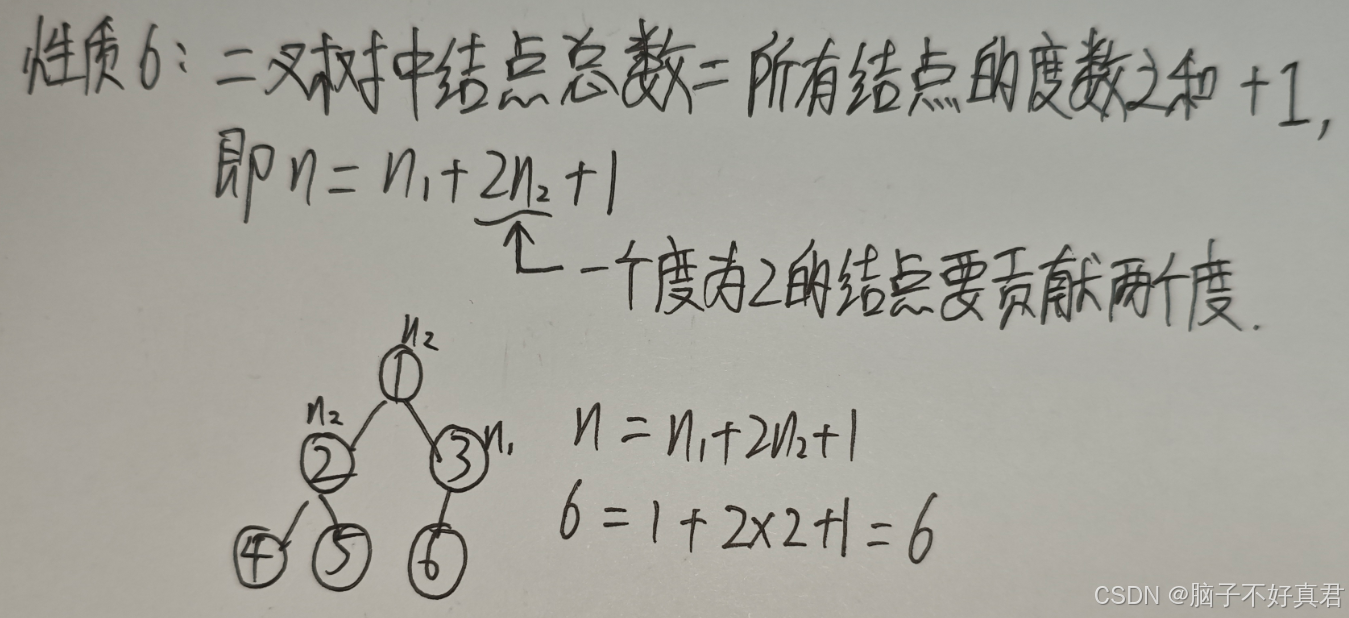
性质6
三、二叉树的顺序存储和链式存储结构
(1)二叉树的顺序存储
完全二叉树的顺序存储
存储方法(层次顺序存储,相当于按层次遍历的顺序把树中元素填入数组):对于一棵具有 n 个结点的完全二叉树,按照从上至下、从左至右的顺序依次为每个结点编号(从1开始),然后将编号为 i 的结点存储到数组下标为 i-1 的位置。
存储到数组中之后,就可以利用二叉树的性质5,通过数组下标直接计算出结点的父子关系:
i(父节点)、2i(左孩子)、2i+1(右孩子)

非完全二叉树的顺序存储
对于非完全二叉树,无法直接存储,需要将二叉树补全成一棵完全二叉树,对不存在的结点在数组中留出空位。
确定是空间浪费:在最坏情况下(二叉树退化成单支树),深度为 k 的树需要长度为 2^k - 1 的数组,但实际只有 k 个有效结点,空间复杂度为 O(2^k),利用率极低。

(2)二叉树的链式存储结构
// 二叉树节点结构 typedef struct TreeNode {int data; // 数据域struct TreeNode *left; // 左子树指针struct TreeNode *right; // 右子树指针 } TreeNode;
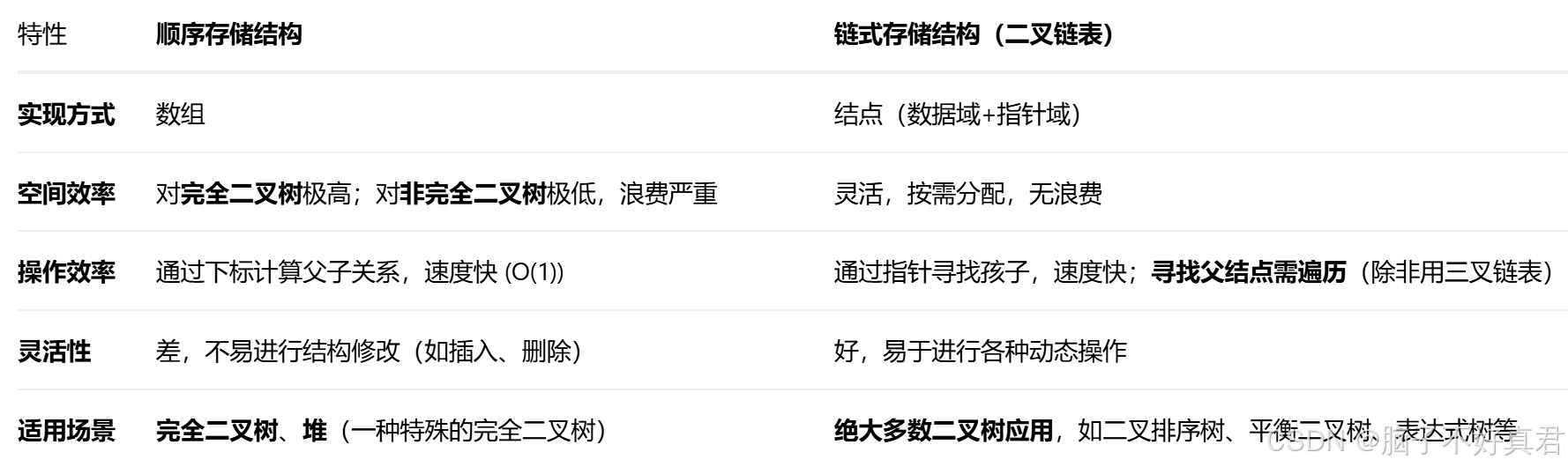
(3)二叉树的顺序存储与链式存储对比
四、二叉树的各种遍历算法
(1)先序遍历
根 -> 左 -> 右
//前序遍历(根-左-右) void preOrderTraversal(TreeNode* root) {if(root==NULL) return;printf("%d ", root->data); //访问根节点preOrderTraversal(root->left); //遍历左子树 preOrderTraversal(root->right); //遍历右子树 }
(2)中序遍历
左 -> 根 -> 右
//中序遍历(左-根-右) void inOrderTraversal(TreeNode* root) {if(root==NULL) return;inOrderTraversal(root->left); //遍历左子树 printf("%d ", root->data); //访问根节点inOrderTraversal(root->right); //遍历右子树 }
(3)后序遍历
左 -> 右 -> 根
//后序遍历(左-右-根) void postOrderTraversal(TreeNode* root) {if(root==NULL) return;postOrderTraversal(root->left); //遍历左子树 postOrderTraversal(root->right); //遍历右子树 printf("%d ", root->data); //访问根节点 }
(4)层次遍历
从上到下,从左到右
// 层次遍历函数 void LevelOrderTraversal(BiTree T) {if (T == NULL) return;BiTree queue[100]; // 定义队列(数组模拟)int front = 0, rear = 0; // 队头和队尾指针queue[rear++] = T; // 根节点入队while (front < rear) { // 队列不为空BiTree current = queue[front++]; // 队头节点出队printf("%d ", current->data); // 访问当前节点// 左子节点入队if (current->lchild != NULL) {queue[rear++] = current->lchild;}// 右子节点入队if (current->rchild != NULL) {queue[rear++] = current->rchild;}} }
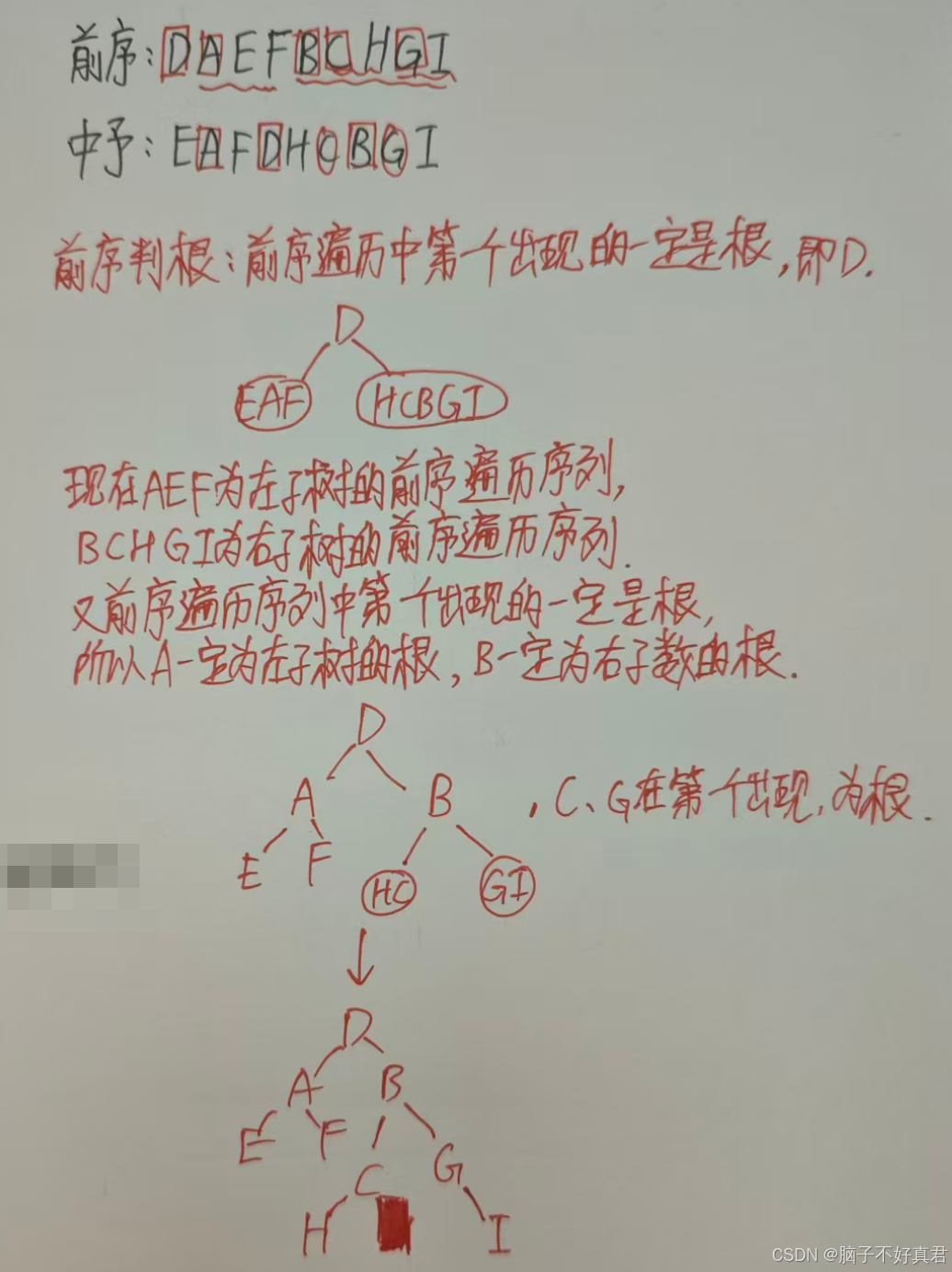
(5)根据中序+x序构造二叉树
核心思想:前/后/层 序判根 + 中序判左右子树
前序+中序遍历序列
后序+中序遍历序列
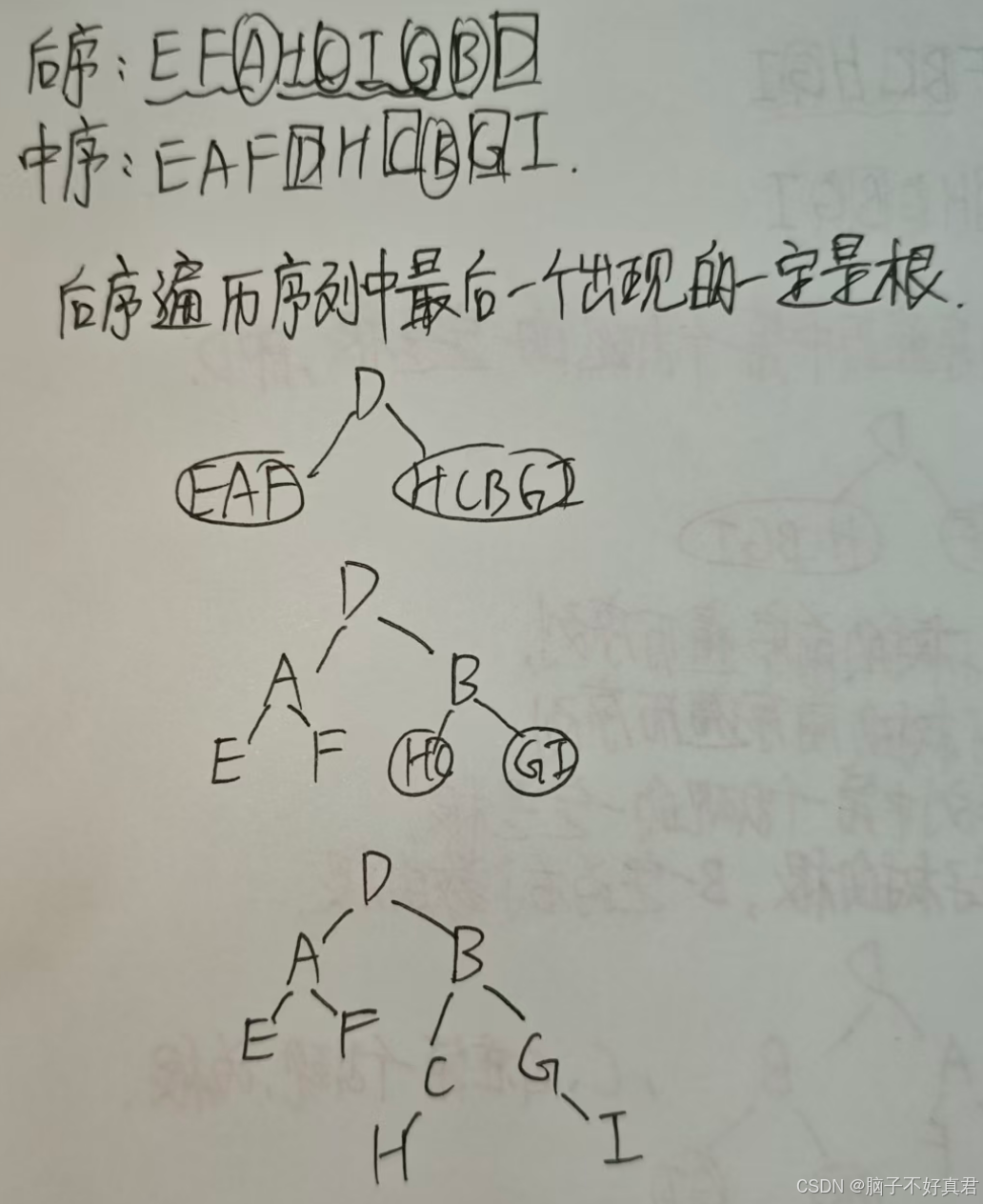
层序+中序遍历序列
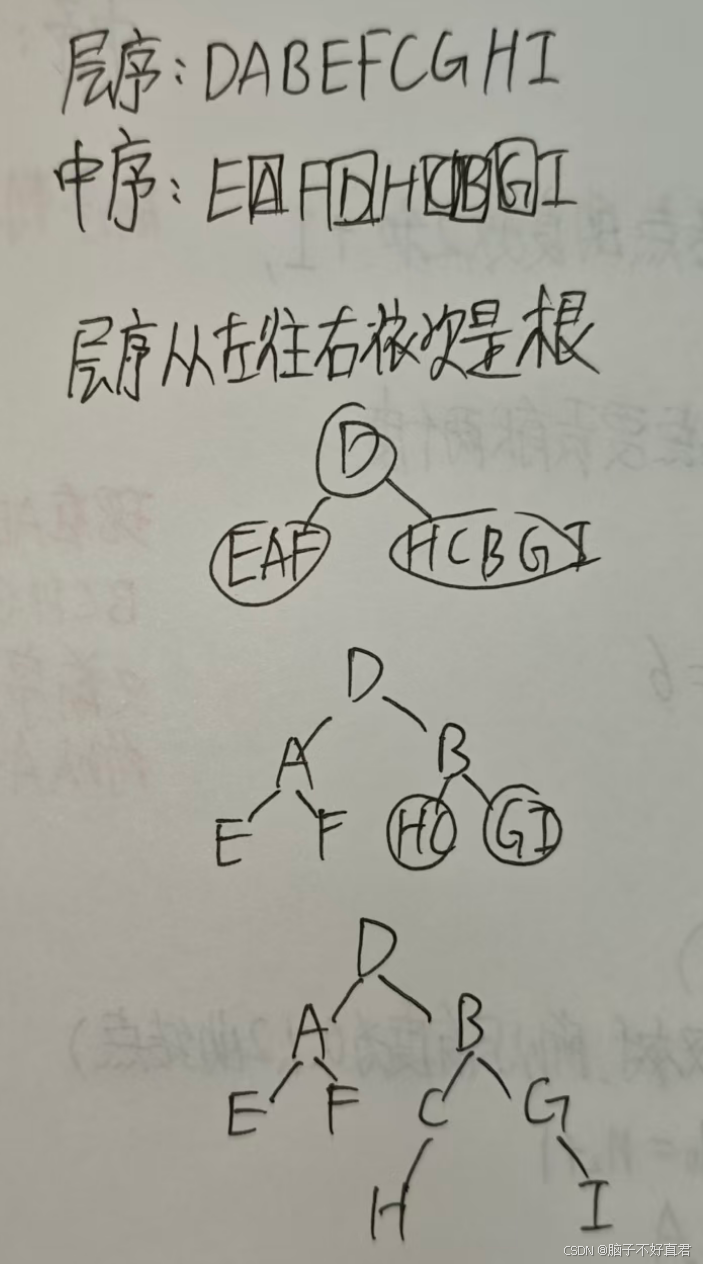
五、二叉树线索化的实质及线索化的过程
(1)线索化的实质
线索化的实质是:将二叉树中的空指针域利用起来,指向该节点在某种遍历序列中的前驱或后继节点。
(2)二叉树线索化的过程
// 全局变量,指向当前访问节点的前驱 ThreadNode *pre = NULL;// 中序遍历二叉树,并对其进行线索化 void InThreading(ThreadNode *p) {if (p == NULL) {return;}// 1. 递归线索化左子树InThreading(p->lchild);// 2. 处理当前节点 p(这里是“根”)// - 线索化前驱:处理 p 的左指针if (p->lchild == NULL) {p->lchild = pre; // 左指针指向前驱 prep->lTag = 1; // 标记为线索} else {p->lTag = 0; // 标记为左孩子}// - 线索化后继:处理前驱节点 pre 的右指针if (pre != NULL && pre->rchild == NULL) {pre->rchild = p; // 前驱 pre 的右指针指向后继 ppre->rTag = 1; // 标记为线索} else if (pre != NULL) {pre->rTag = 0; // 如果pre不为空且右孩子存在,标记为孩子}// 3. 更新前驱:当前节点 p 成为下一个节点的前驱pre = p;// 4. 递归线索化右子树InThreading(p->rchild); }// 主函数,创建中序线索二叉树 void CreateInThread(ThreadTree T) {pre = NULL; // 初始化前驱if (T != NULL) {InThreading(T); // 开始线索化// !!!收尾工作:处理遍历的最后一个节点!!!if (pre->rchild == NULL) {pre->rTag = 1; // 最后一个节点的右指针必为线索// pre->rchild 可以指向NULL,也可以指向头节点}} }
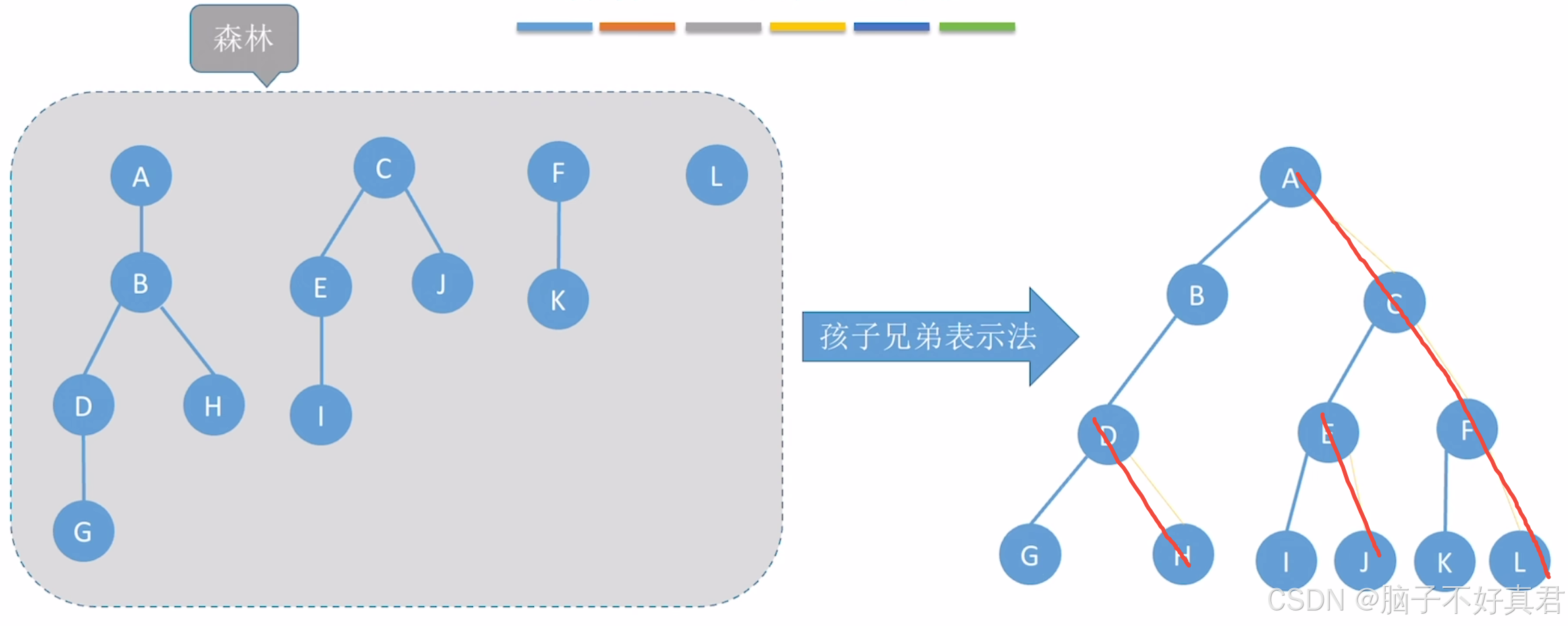
六、树和森林的定义、树的存储结构、树的遍历、树、森林与二叉树之间的相互转换方法
(1)森林的定义
森林是 m(m ≥ 0)棵互不相交的树的集合。
(2)树的存储结构
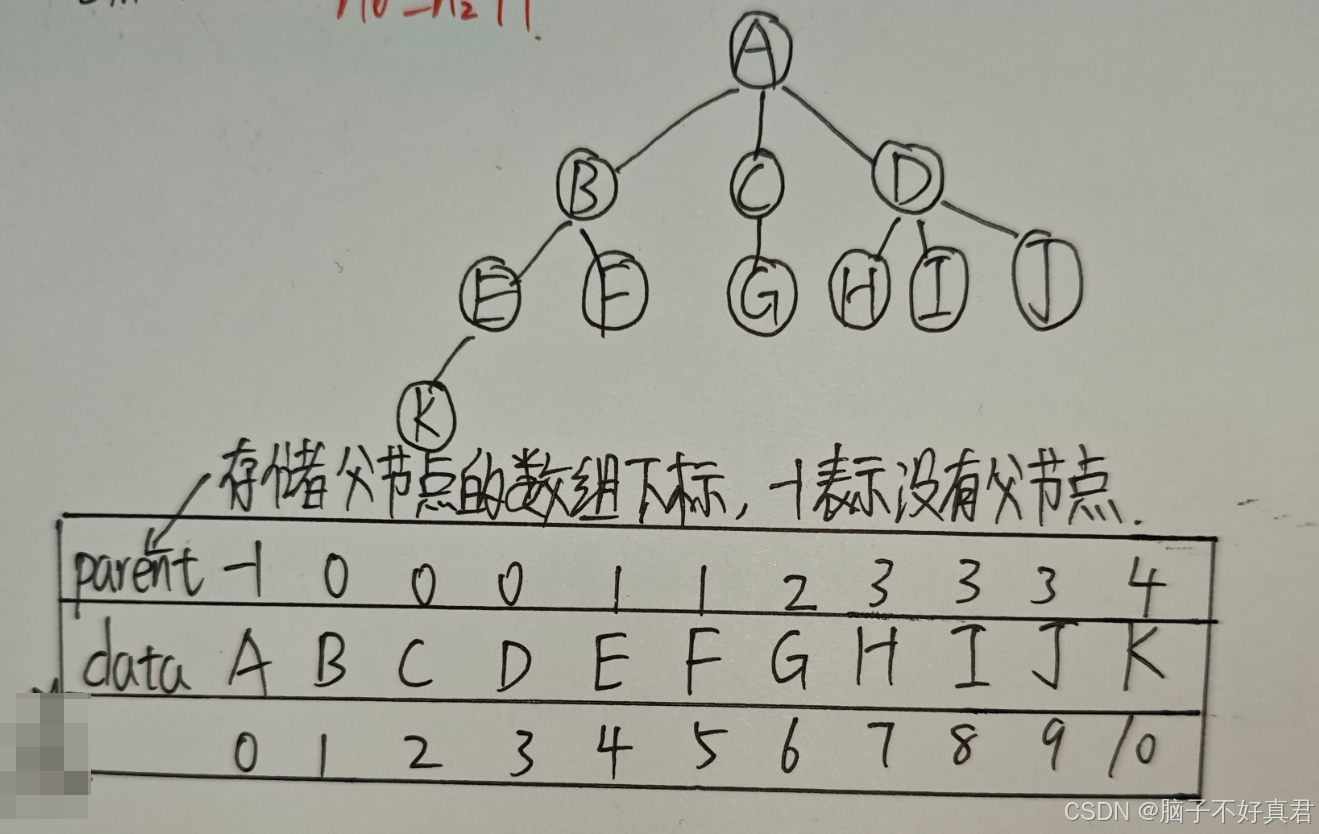
双亲表示法(顺序存储)
每个节点存储其数据和其父节点的指针(或数组下标)。
优点:容易找到父节点和祖先节点。
缺点:寻找子节点或兄弟节点困难,需要遍历整个树。
#define MAX_TREE_SIZE 100 //树中最多结点数typedef struct { //树的结点定义ElemType data; //数据元素int parent; //双亲位置域 } PTNode;typedef struct { //双亲表示PTNode nodes[MAX_TREE_SIZE]; //双亲表示int n; //结点数 } PTree;
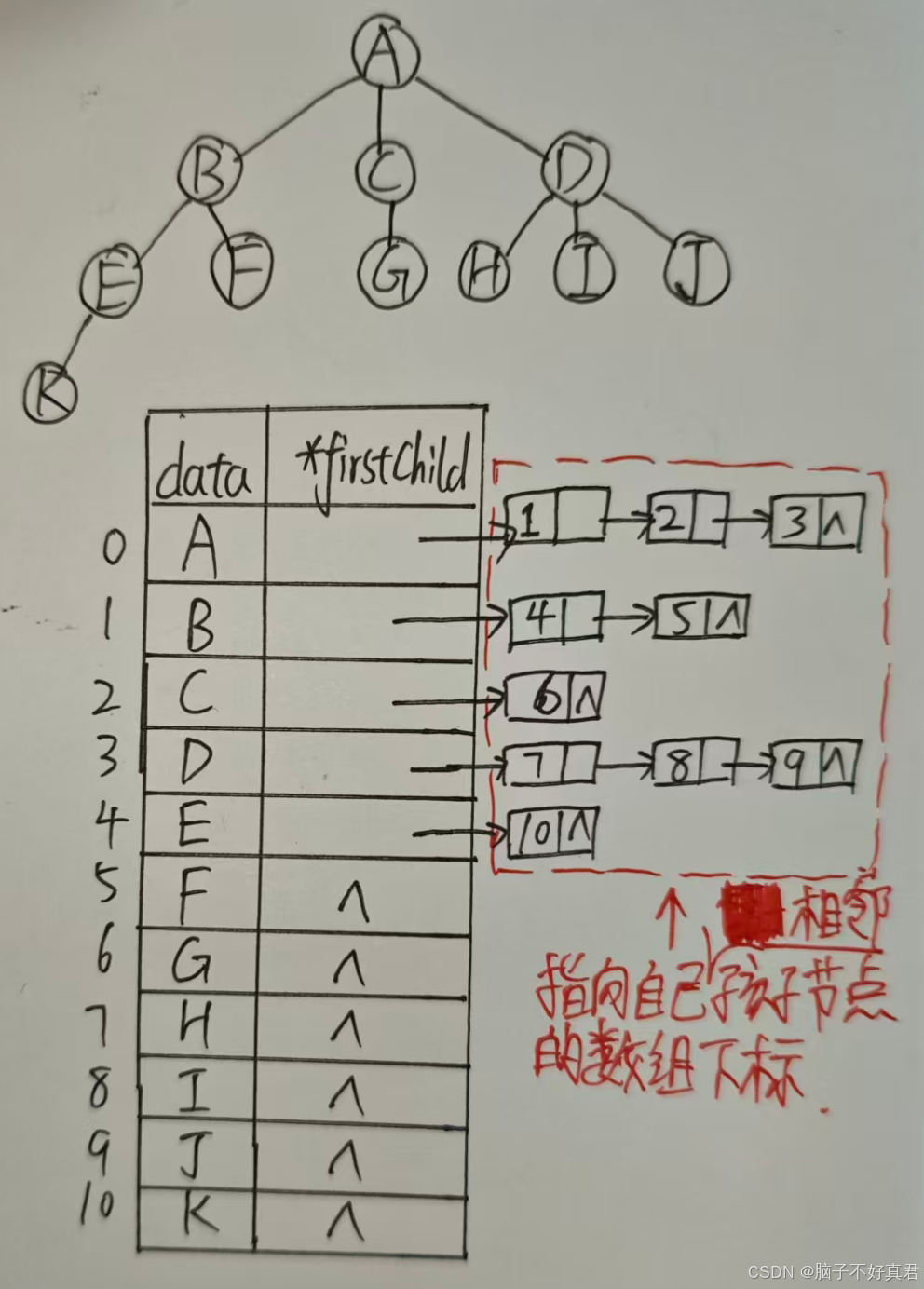
孩子表示法(顺序+链式存储)
将每个节点的所有子节点用单链表链接起来。
优点:容易找到某个节点的所有子节点。
缺点:寻找父节点困难。
// 孩子节点结构 struct CTNode {int child; // 孩子结点在数组中的位置struct CTNode *next; // 下一个孩子 };// 树节点结构 typedef struct {ElemType data; // 节点数据struct CTNode *firstChild; // 第一个孩子 } CTBox;// 树结构 typedef struct {CTBox nodes[MAX_TREE_SIZE]; // 节点数组int n, r; // 结点数和根的位置 } CTree;
孩子兄弟表示法(链式存储)
这是最重要的一种表示法,它是树、森林与二叉树相互转换的基础。
每个节点包含三个域:
数据域:存储节点数据。
第一个孩子指针:指向节点的第一个子节点。
右兄弟指针:指向节点的下一个兄弟节点。
//树的存储——孩子兄弟表示法 typedef struct CSNode {ElemType data; //数据域struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟指针 } CSNode, *CSTree;
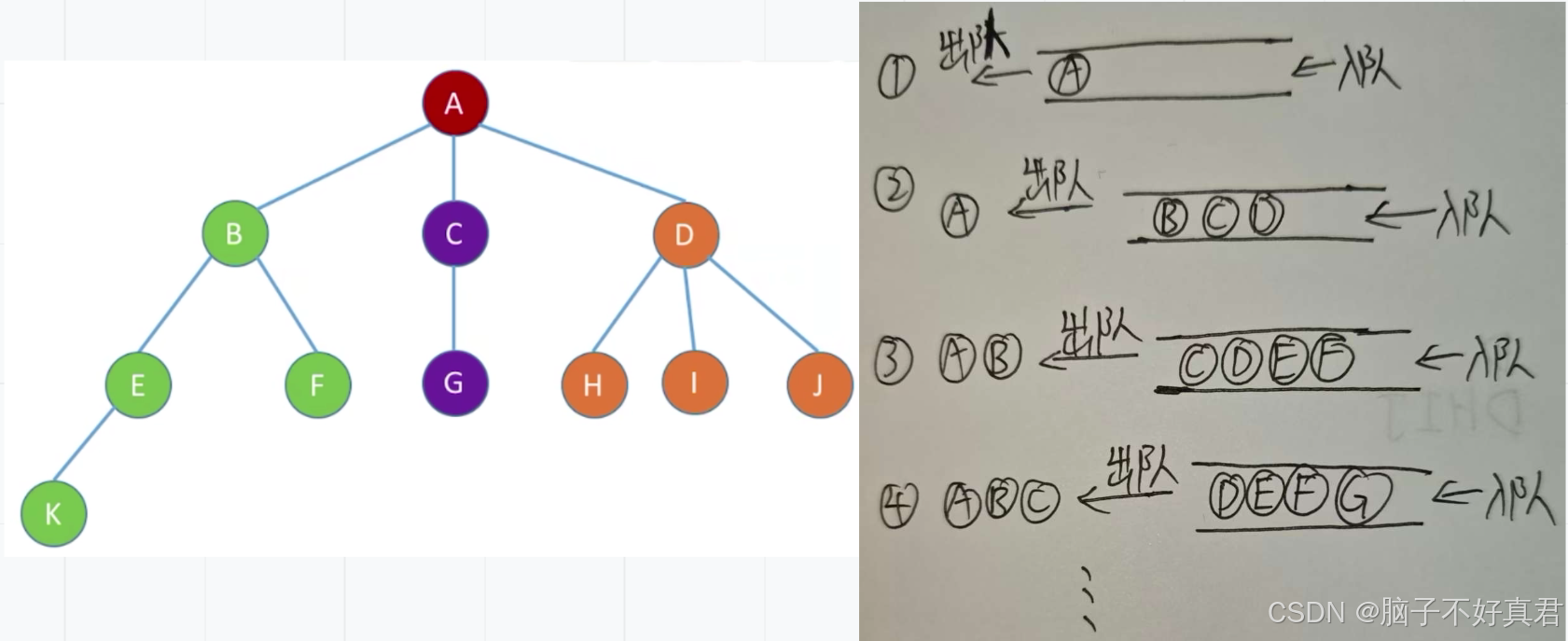
(3)树的遍历
先根遍历
核心思路:先访问根结点,然后按层次的顺序访问每一层的结点

后根遍历
核心思路:从最后一层开始,按层次顺序访问每一层的结点

层次遍历(用队列实现)
①根节点最先入队
②若队列非空,队头元素出队并且将它的孩子孩子从左到右依次入队
③重复第②步直到队列为空
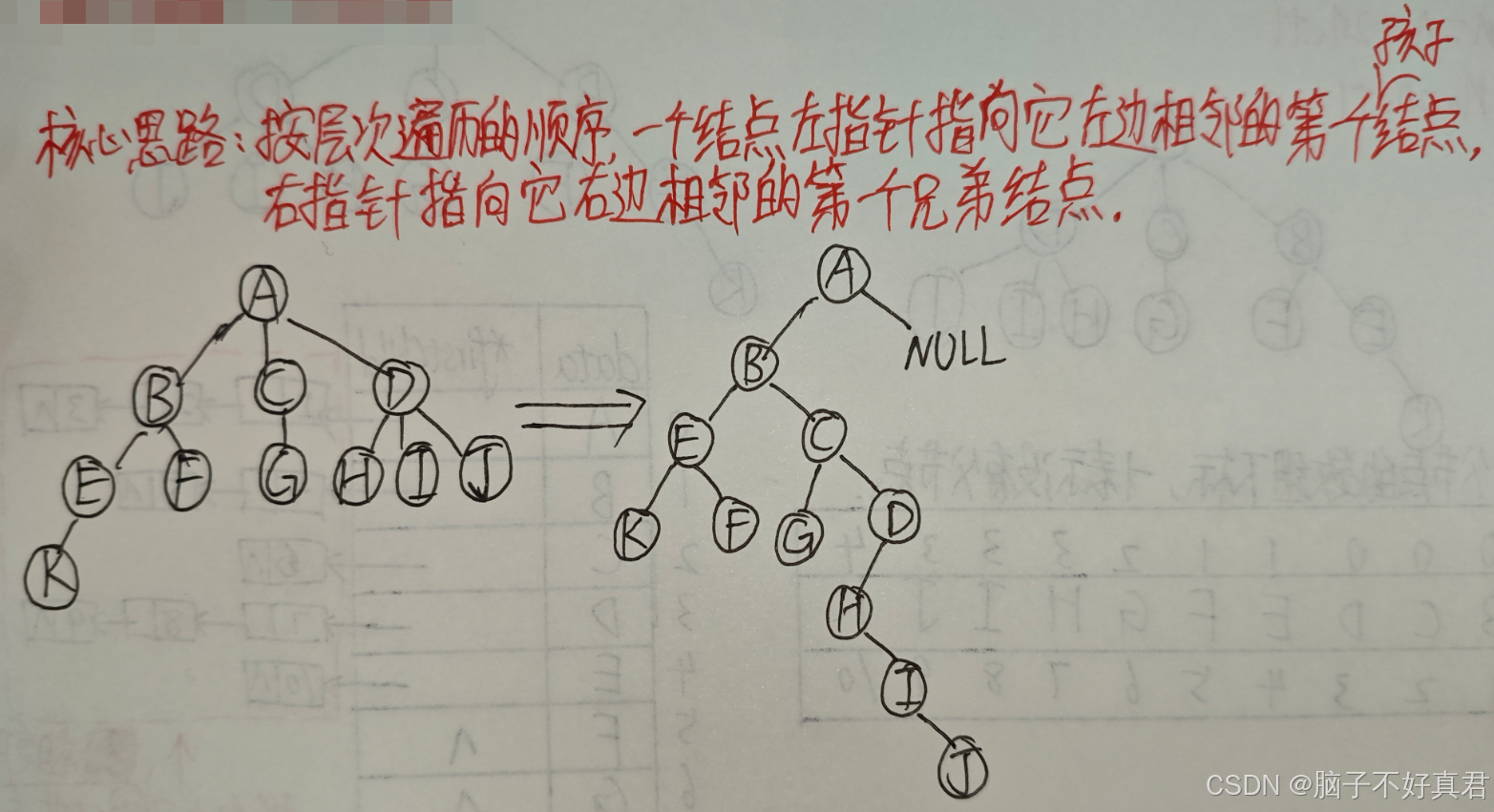
(4)树、森林与二叉树之间的相互转换方法
树→二叉树的转换
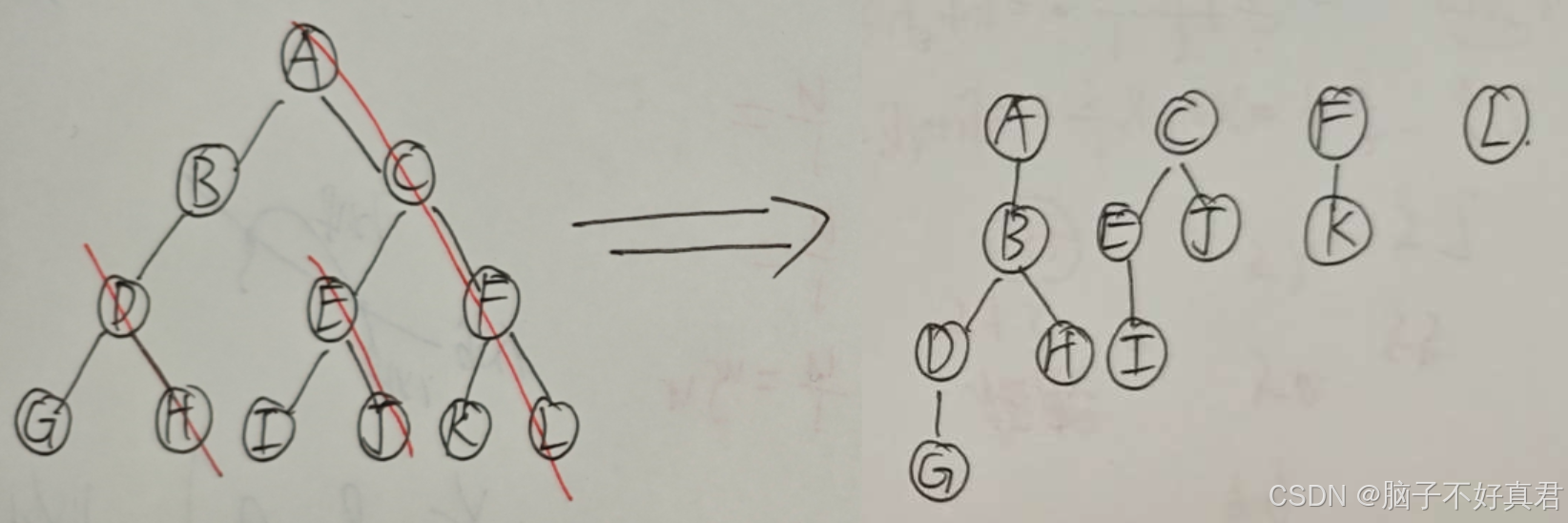
核心思想就是用兄弟孩子表示法按层次遍历顺序处理树,自然树就转化成为了二叉树,
但这个糖葫芦串技巧可以完成快速树转化为二叉树,
树 → 二叉树 转换技巧
具体步骤:
① 先在二叉树中,画一个根节点。
② 按"树的层序"依次处理每个结点。
处理一个结点的方法是:如果当前处理的结点在树中有孩子,就把所有孩子结点"用右指针串成糖葫芦",并在二叉树中把第一个孩子挂在当前结点的左指针下方。
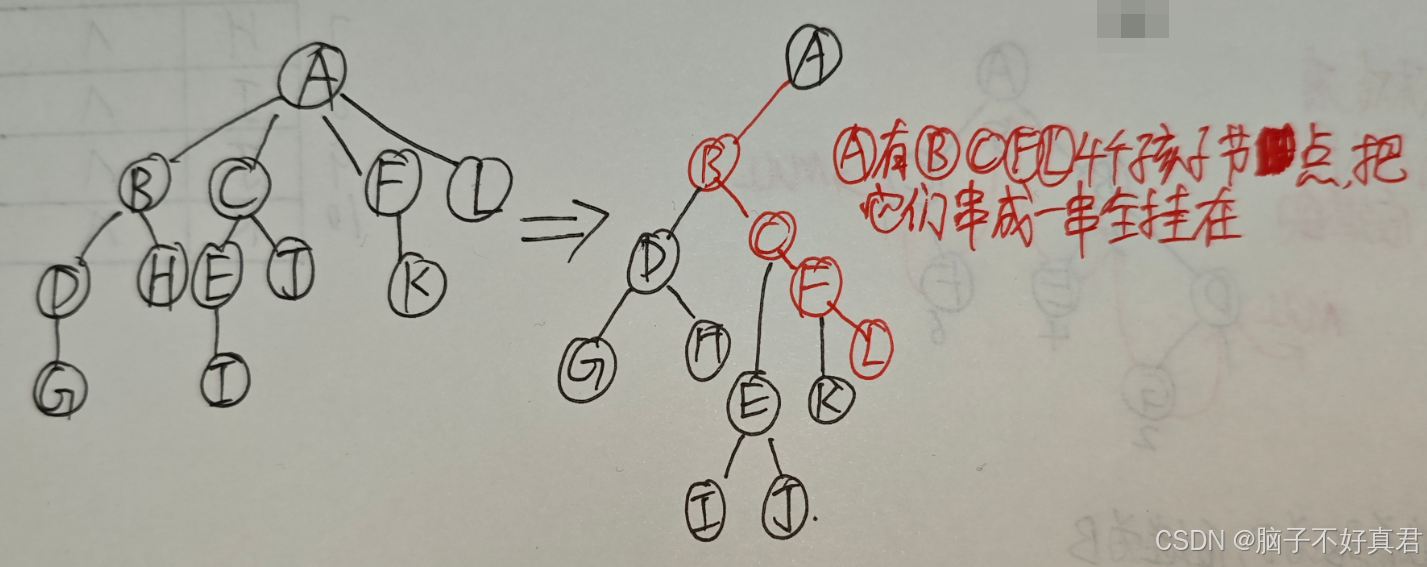
森林 → 二叉树的转换
① 处理所有树的根结点
先把所有树的根结点画出来。
在二叉树中,将这些根结点用右指针串成“糖葫芦”。
② 按“森林的层序”依次处理每个结点
处理单个结点的方法:
如果当前处理的结点在原树中有孩子,就把它的所有孩子结点用右指针串成“糖葫芦”。
在二叉树中,将第一个孩子挂在当前结点的左指针下方。
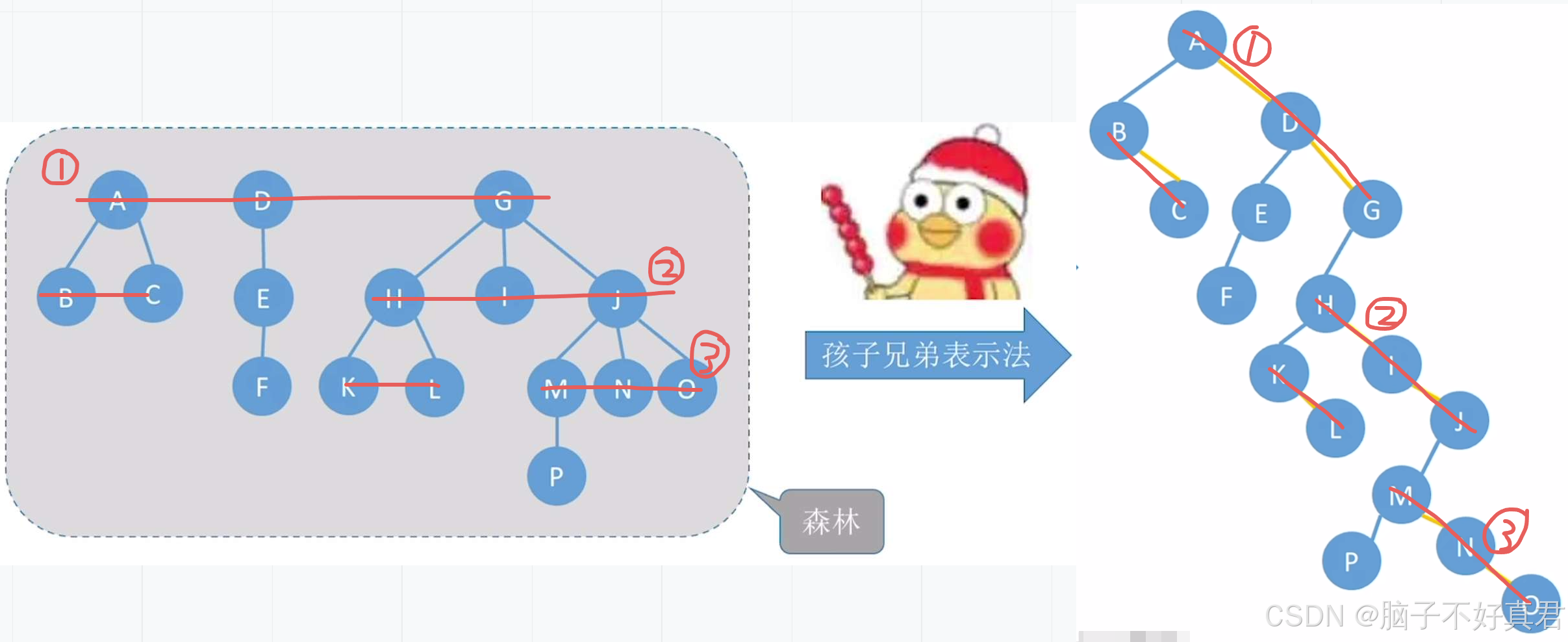
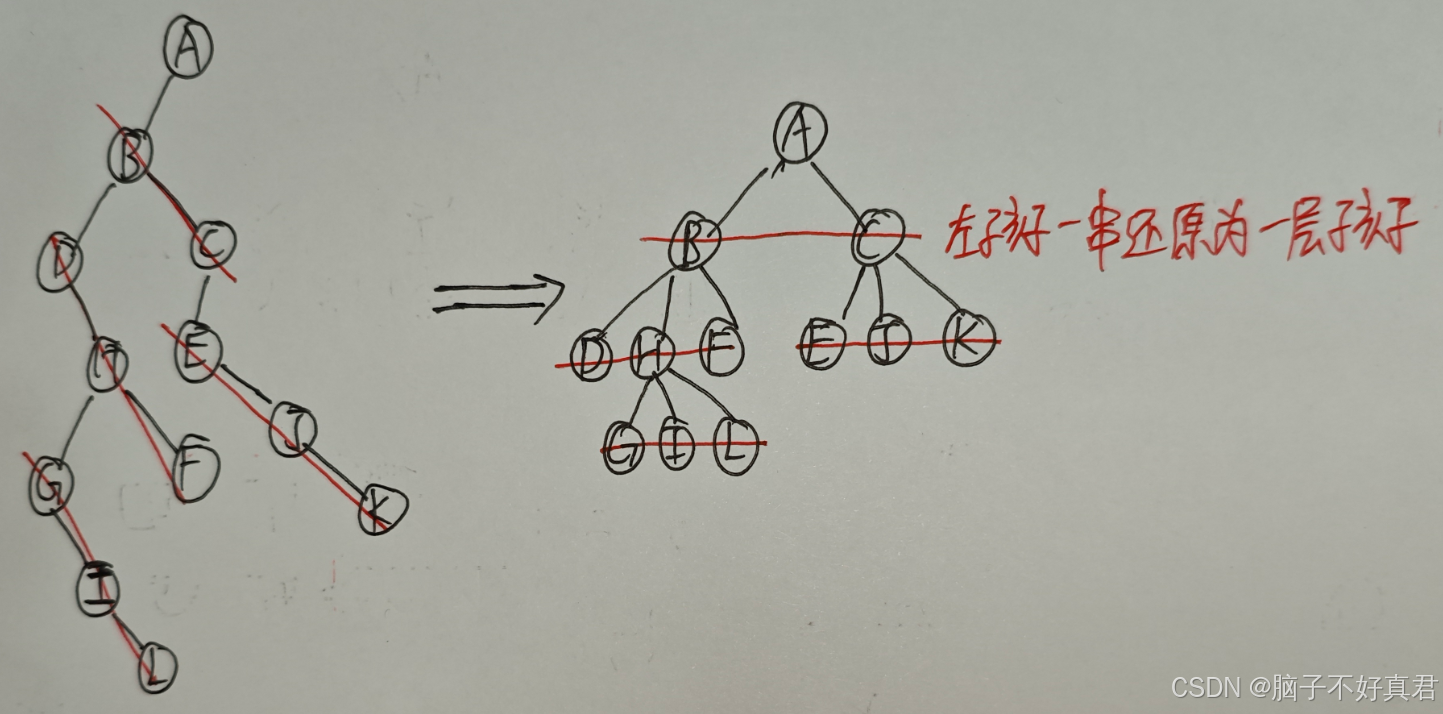
二叉树 → 树的转换
核心思想:按层次顺序把“一串糖葫芦”左孩子还原为一层孩子节点
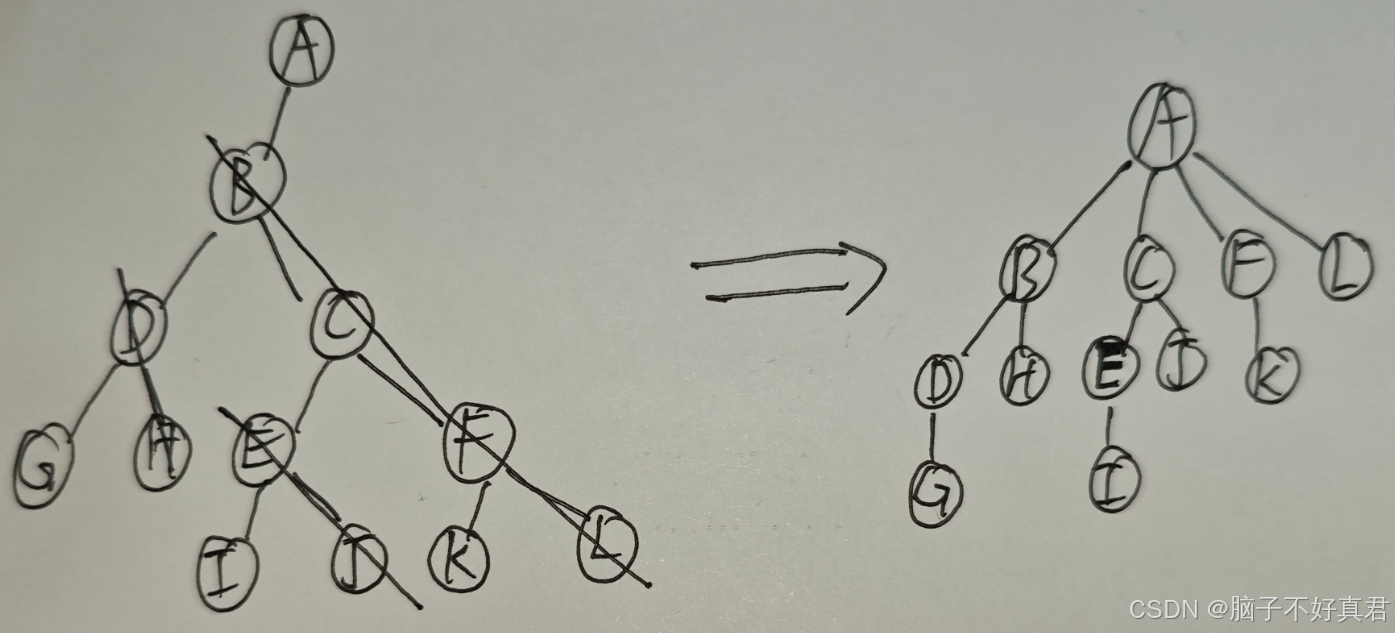
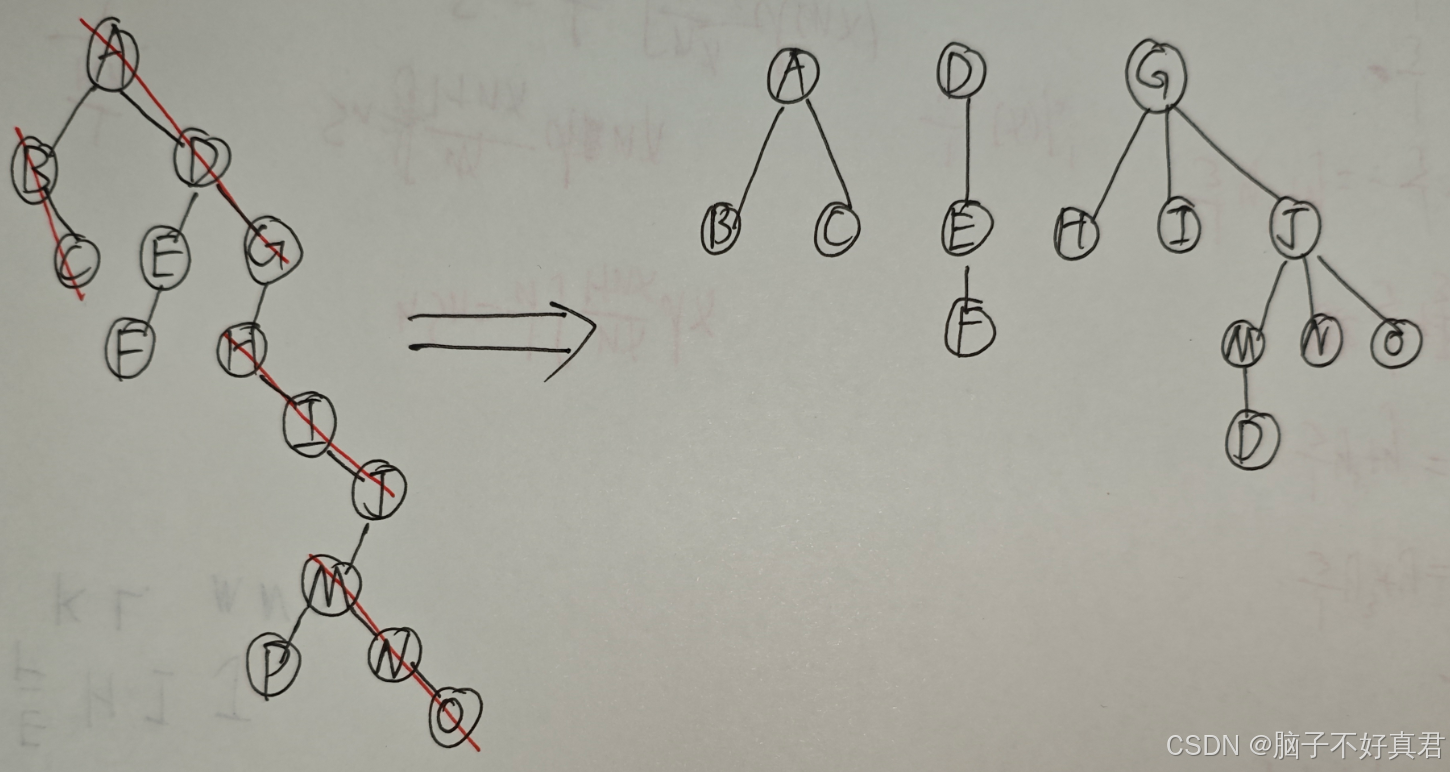
二叉树 → 森林的转换
五、哈夫曼(Huffman)树的概念及构造哈夫曼树和哈夫曼编码的方法
(1)哈夫曼树的概念
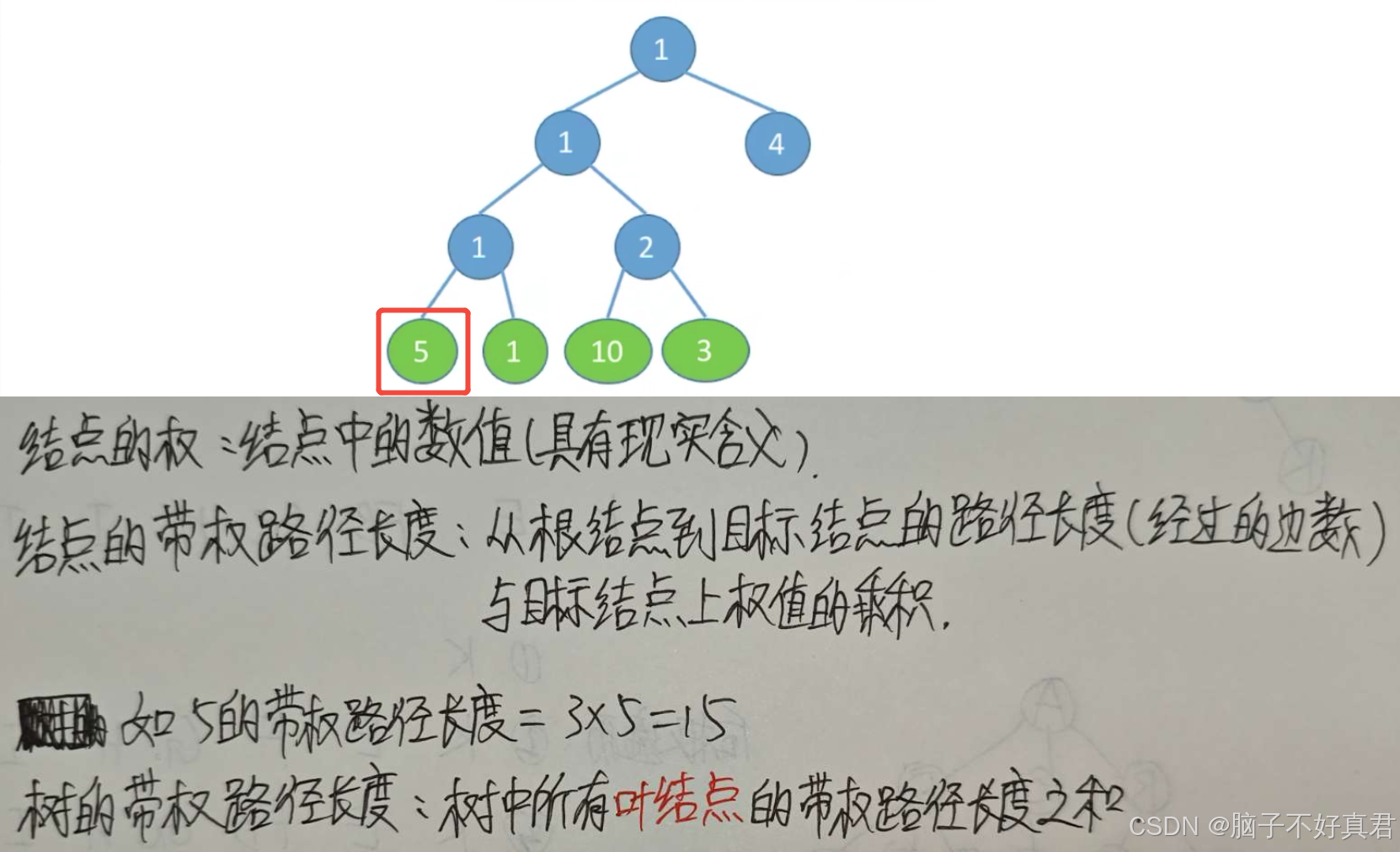
结点的权、结点的带权路径长度、树的带权路径长度(WPL)
哈夫曼树的定义
在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL)最小的二叉树称为哈夫曼树,也称最优二叉树
(2)构造哈夫曼树
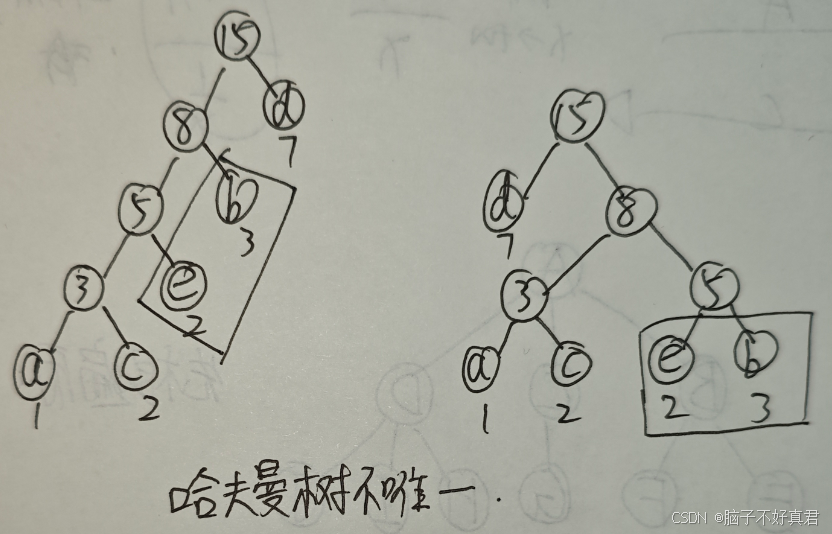
核心思路:开始时从权值结点集合中选取两个权值最小的结点组成树,然后每次再从权值结点集合中选取一个权值最小的结点加入树中(也有可能第二次也选取的是两个权值最小的结点加入树,因为权值结点组合成的新结点的权值可能与权值结点集合的权值相同,这也是哈夫曼树不唯一的原因之一)
哈夫曼树的特性:
叶结点特性
每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大。
结点总数公式
哈夫曼树的结点总数为 2n−1(其中n为初始叶子结点的个数,即权值结点集合中权值个数)。
结点度的情况
哈夫曼树中不存在度为 1 的结点(即每个非叶子结点一定有左右两个孩子)。
树的唯一性与最优性
哈夫曼树并不唯一(同一组权值可能构造出不同形态的树),但所有哈夫曼树的带权路径长度(WPL)必然相同且为最优。
(3)设计哈夫曼编码
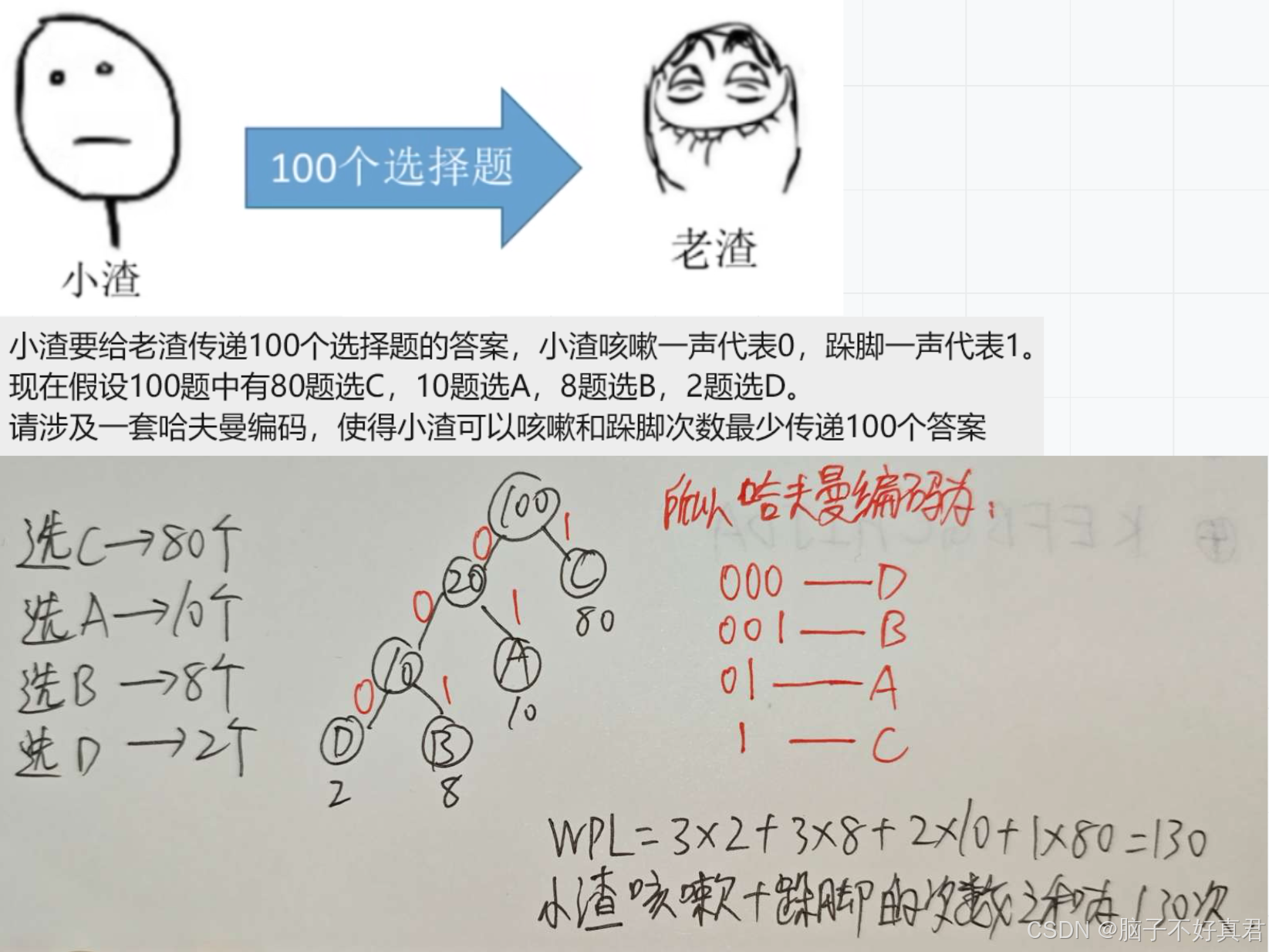
设计哈夫曼编码例题
核心思路:先构造哈夫曼树,在哈夫曼树上,向左分支标0,向右分支标1。
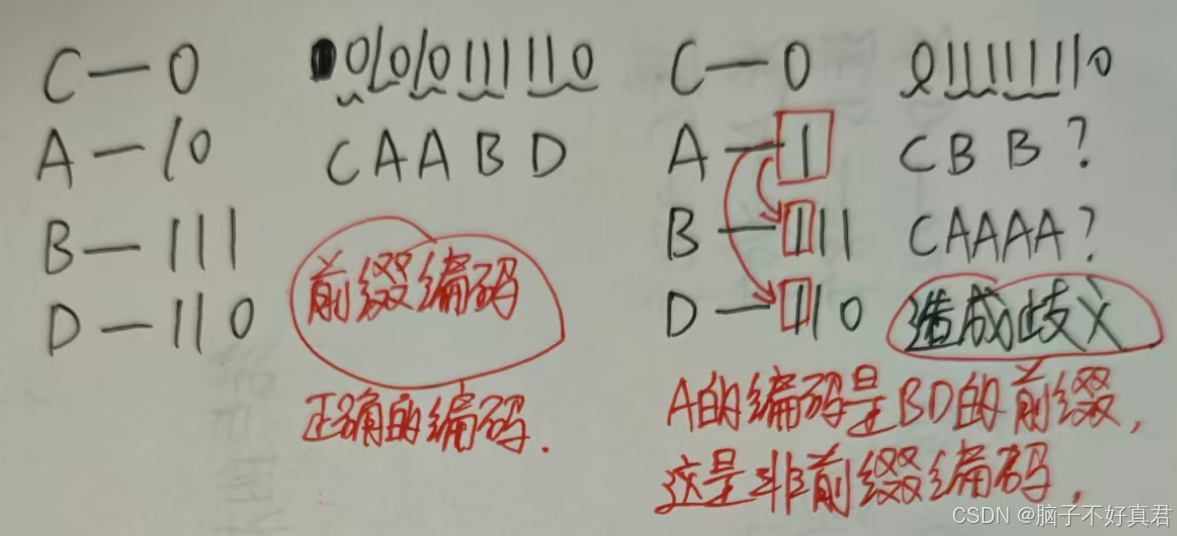
前缀编码和非前缀编码
若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码,前缀编码才能成功传递信息