SpringAI+DeepSeek大模型应用开发自用笔记
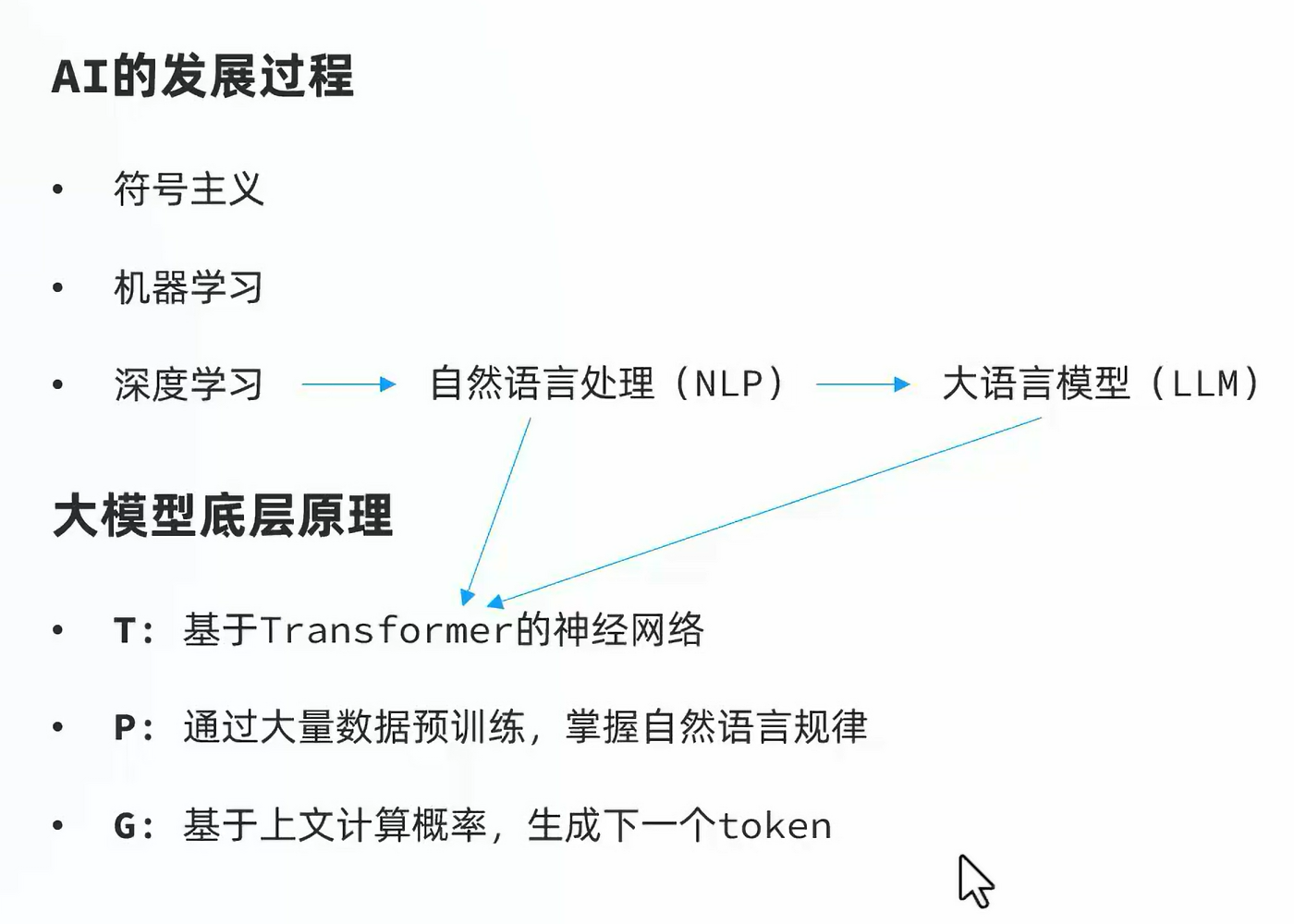
大模型预测推理的时候其实是一个一个字蹦出来的
比如:北京有什么早餐推荐?
根据大模型算法,生成推、荐等几个字,然后计算概率比如“推”的概率大于“荐”,然后就选择把“推”字生成出来,然后接着再把“推”字喂进去,计算下一个字可能是什么,不断重复,这样就生成了一大段文本。
因为计算机内部处理的不是汉字,而是数字,所以叫做生成token
大模型应用开发
模型部署
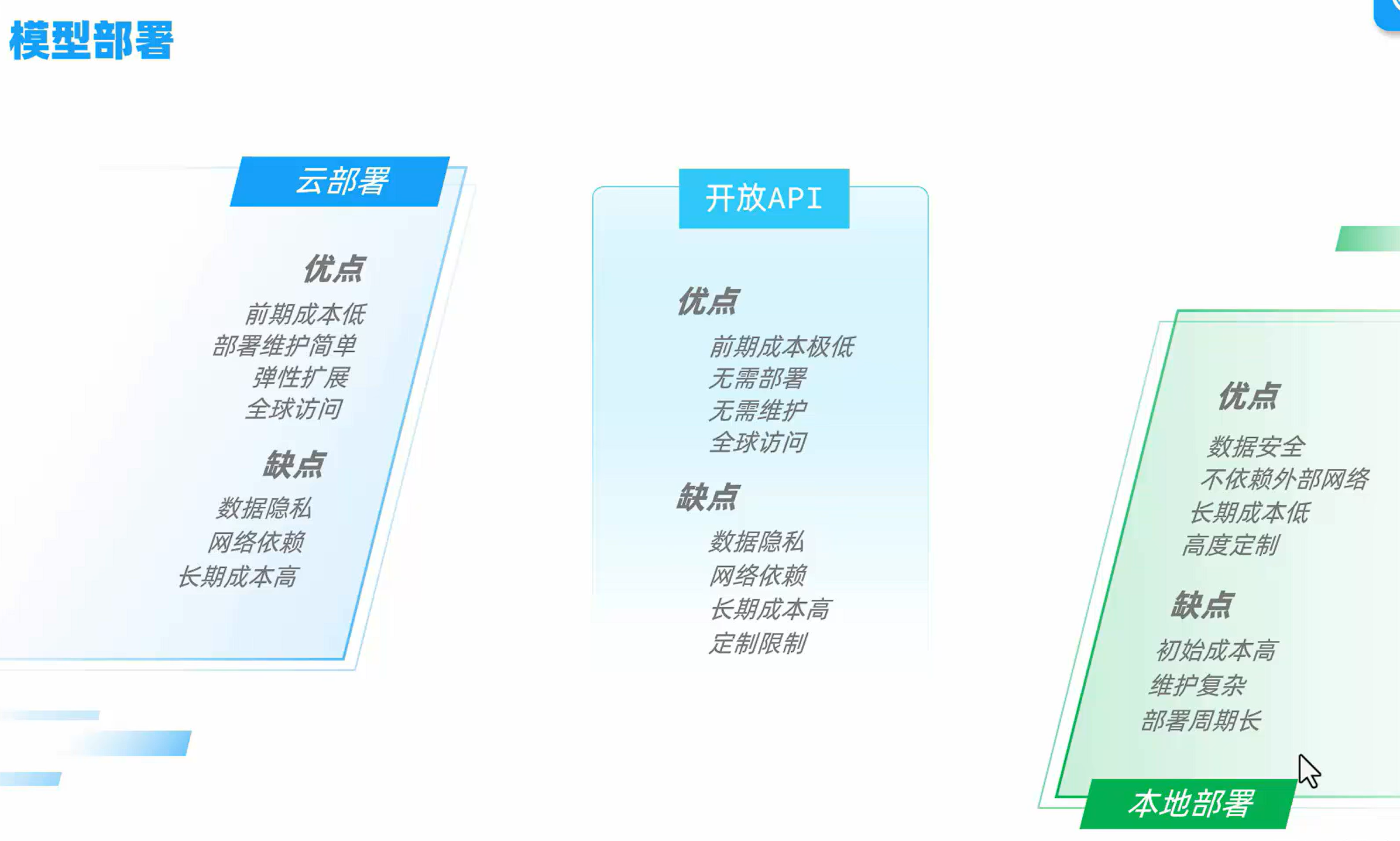
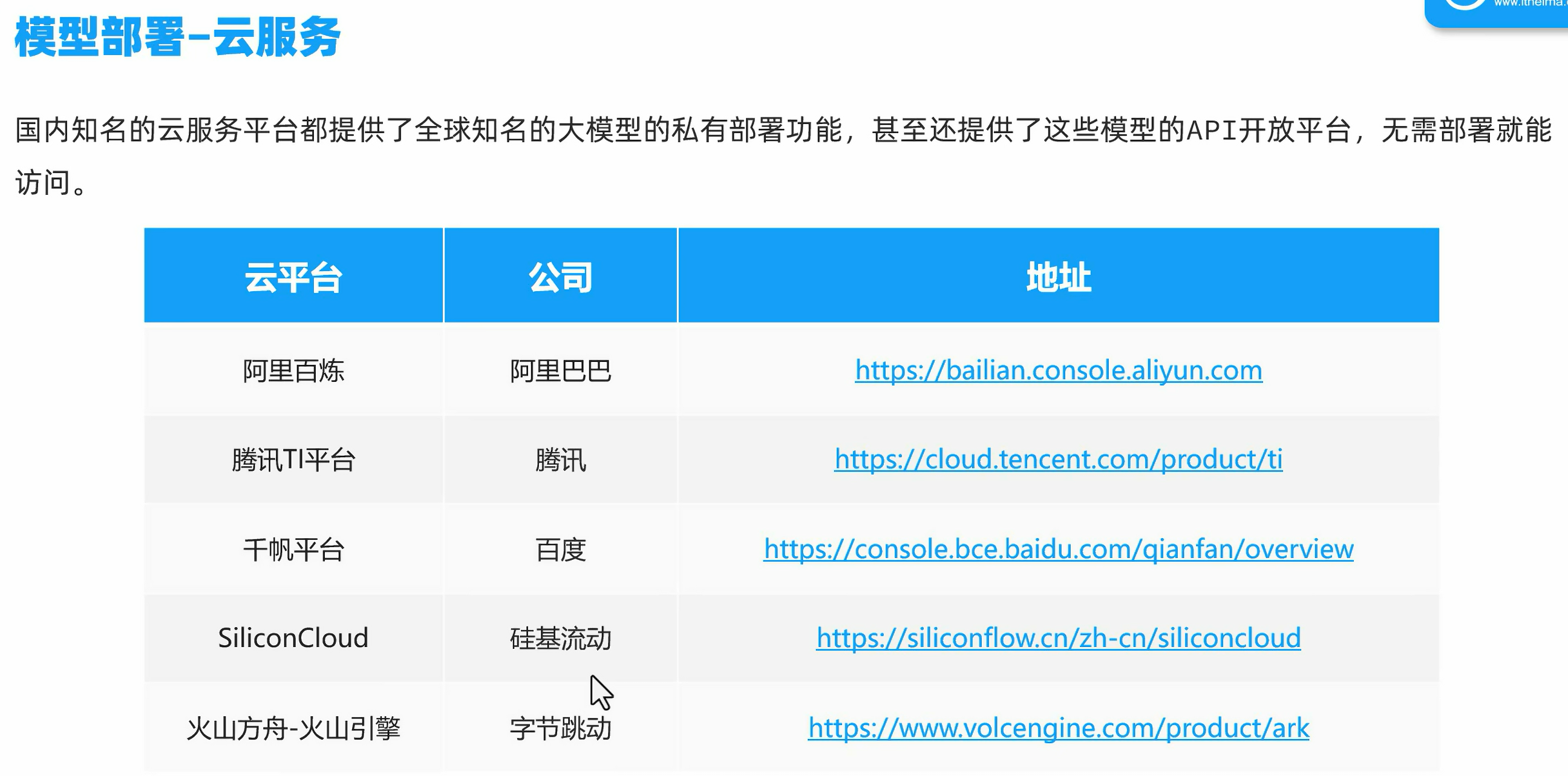
云服务
注册阿里百炼账号,生成密钥key
本地部署
安装ollama,直接安装是在c盘,可以根据以下方式把ollama安装在D盘
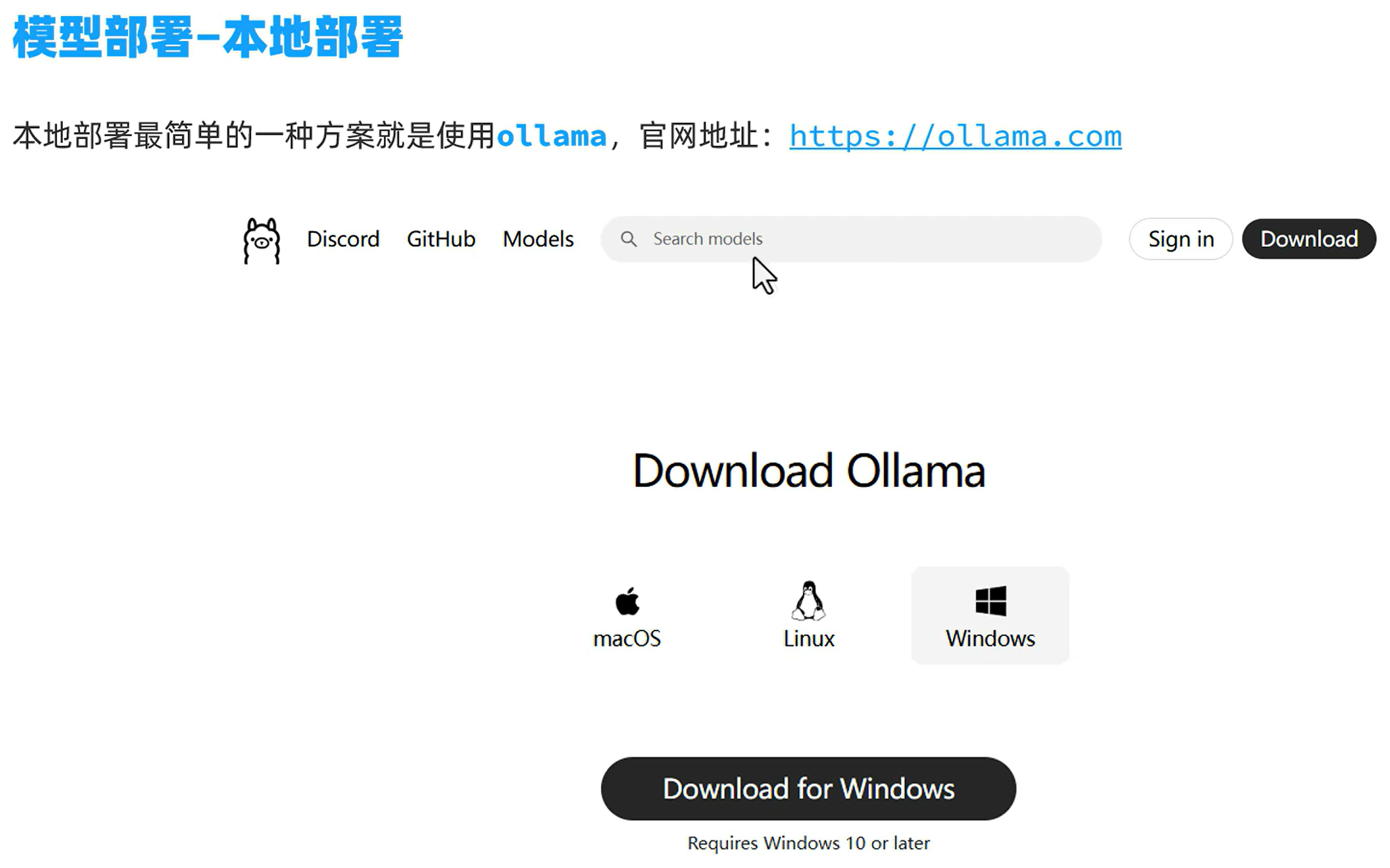
记得安装完后在高级系统设置里点击环境变量配置,然后配置系统变量(不是用户变量),双击系统变量里的Path,然后新建,输入安装ollama时候选择的文件路径
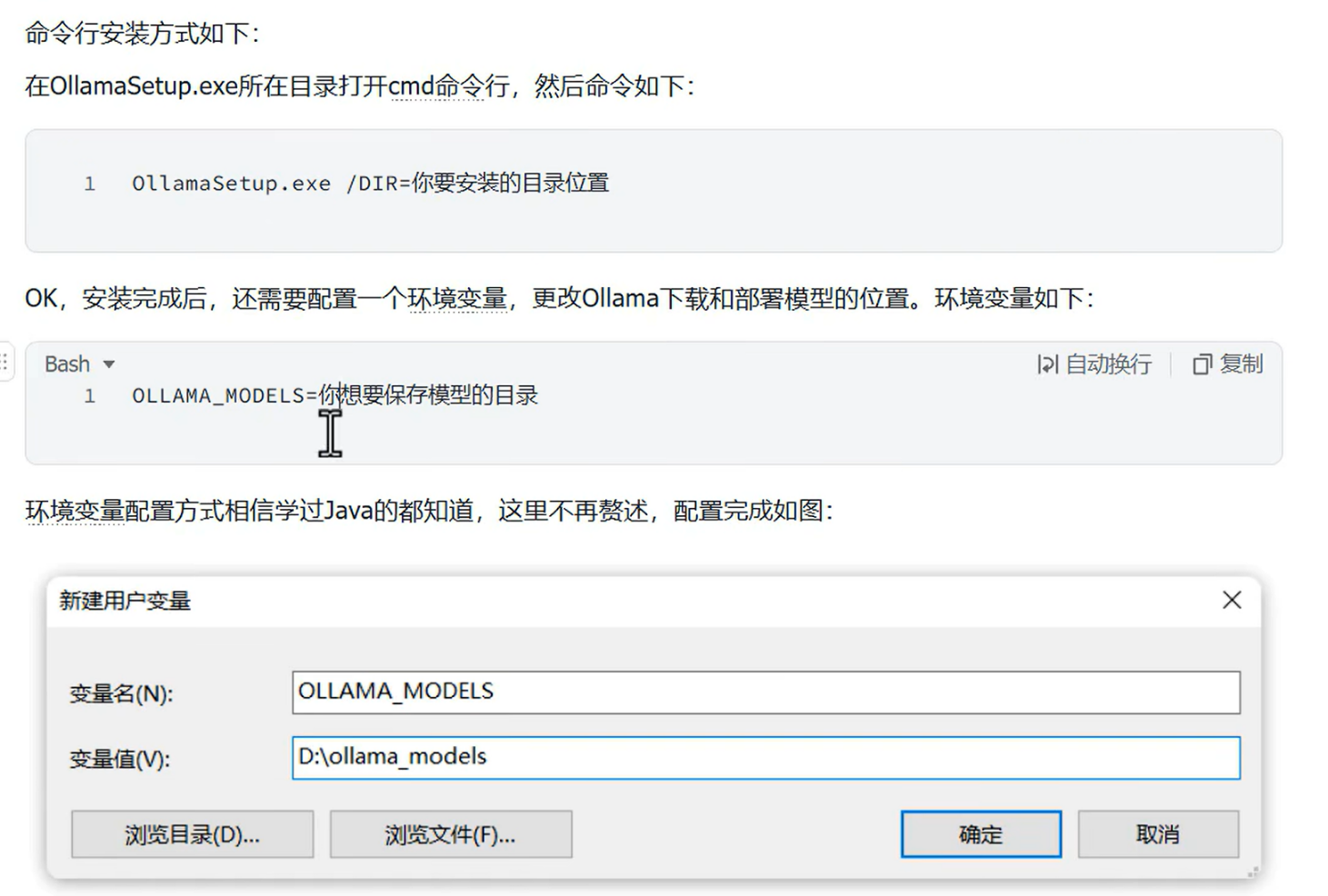
直接打开cmd命令行,输入ollama help查询命令
根据电脑配置选择deepseek版本,版本越高,算力越好,需要的配置也越好。在cmd控制台输入命令,会去本地下载模型
ollama run deepseek-r1:7b
下载好直接对话
输入/bye结束对话
/bye
下载好输入命令,查看
ollama ps调用大模型
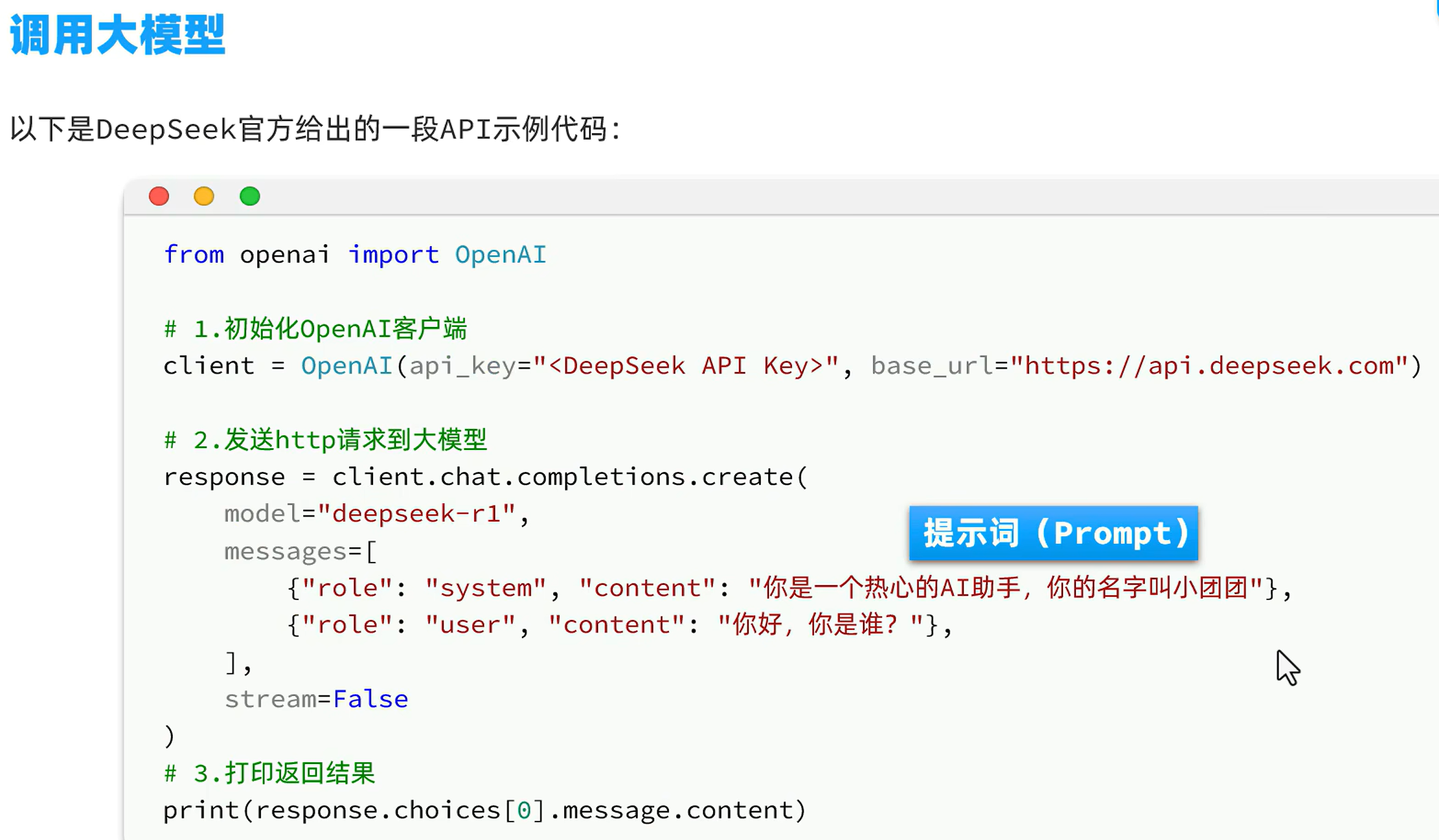
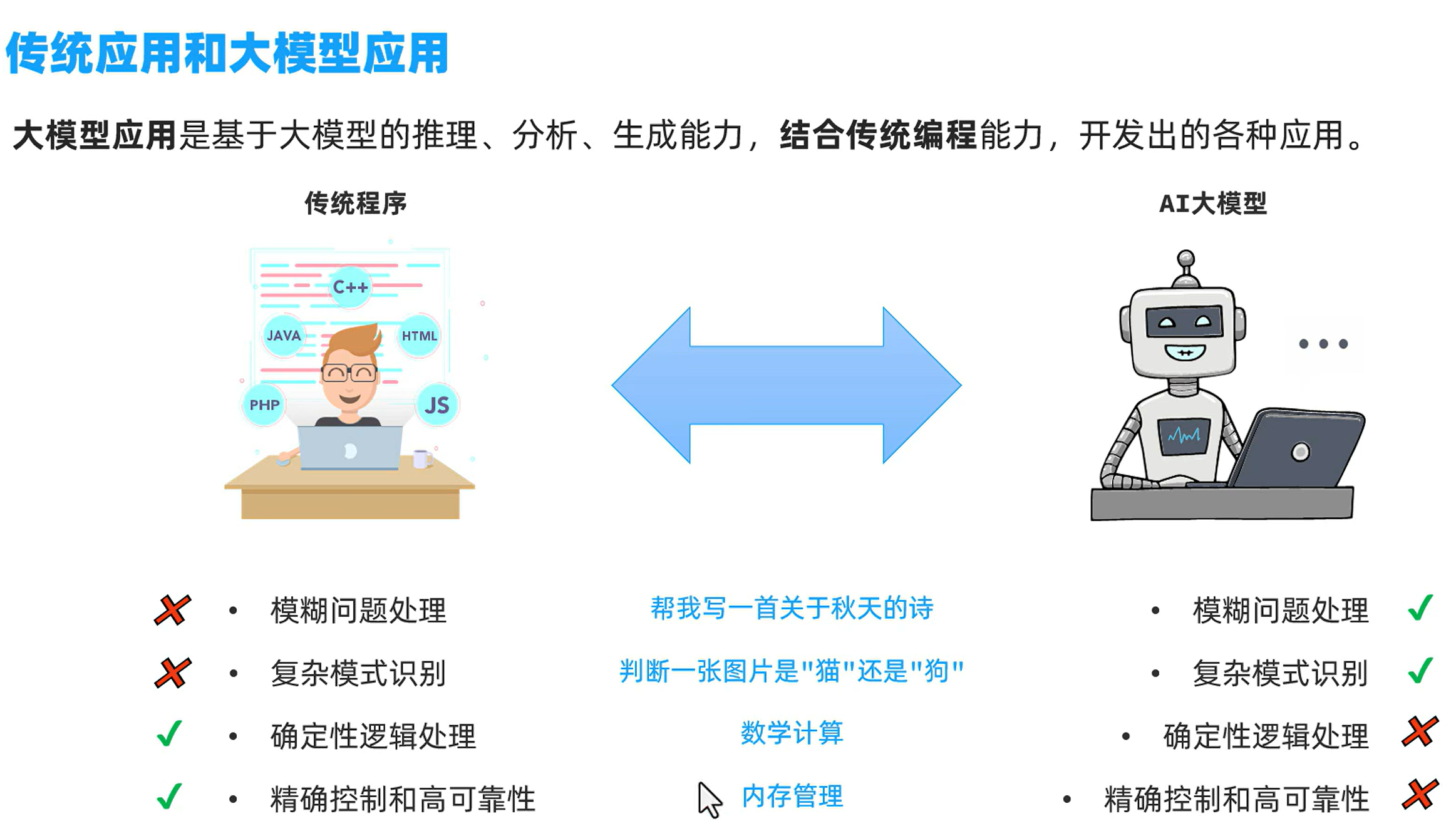
传统应用和大模型应用
例子:大模型是没有记忆的,对于之前的对话没有记忆,每次对话都是一次新的开始,而结合传统程序,就可以把之前对话的记录存储起来,然后和新的问题拼接,然后都发给大模型,这样大模型也就拥有了“记忆”。大模型应用就是把传统应用和大模型应用结合起来
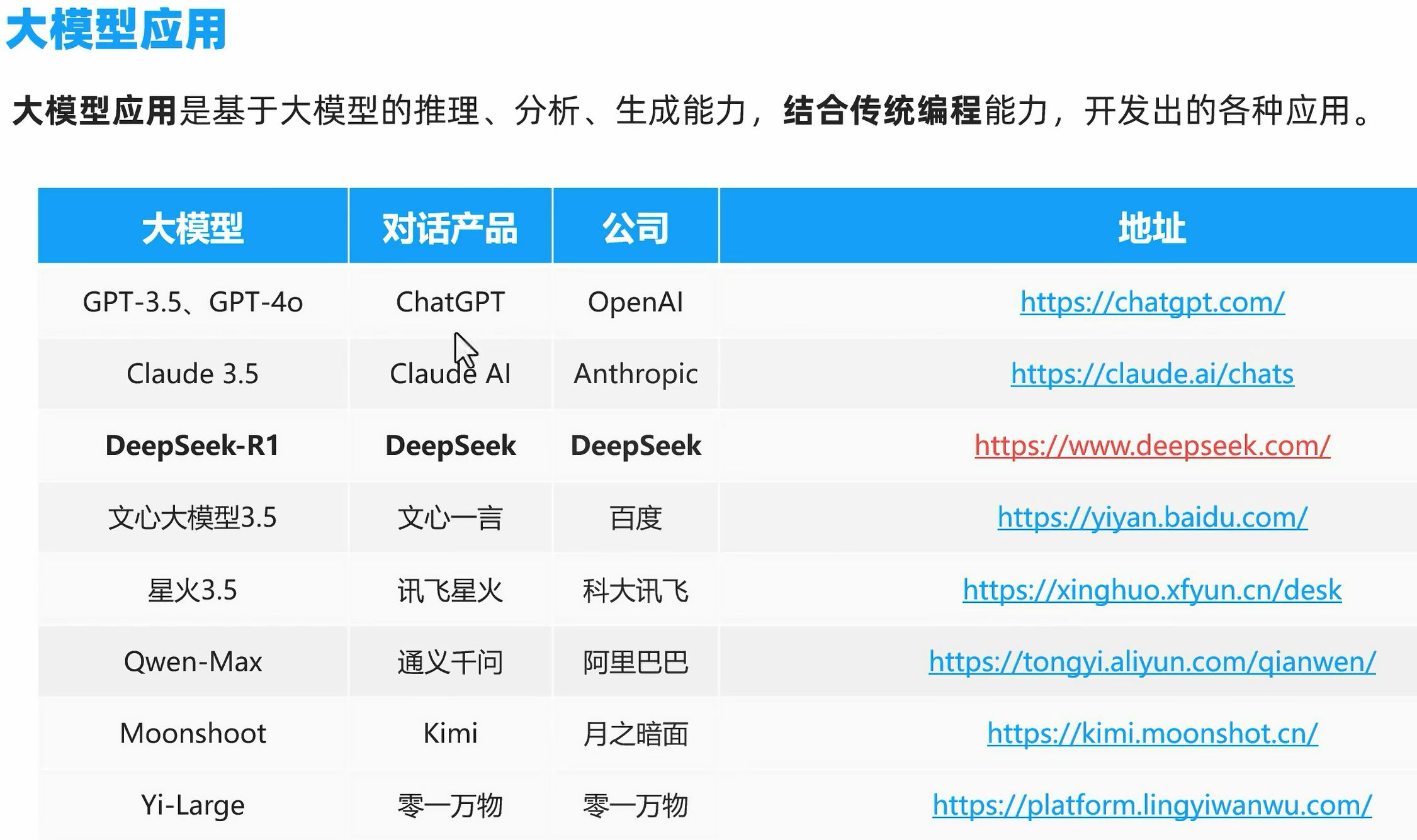
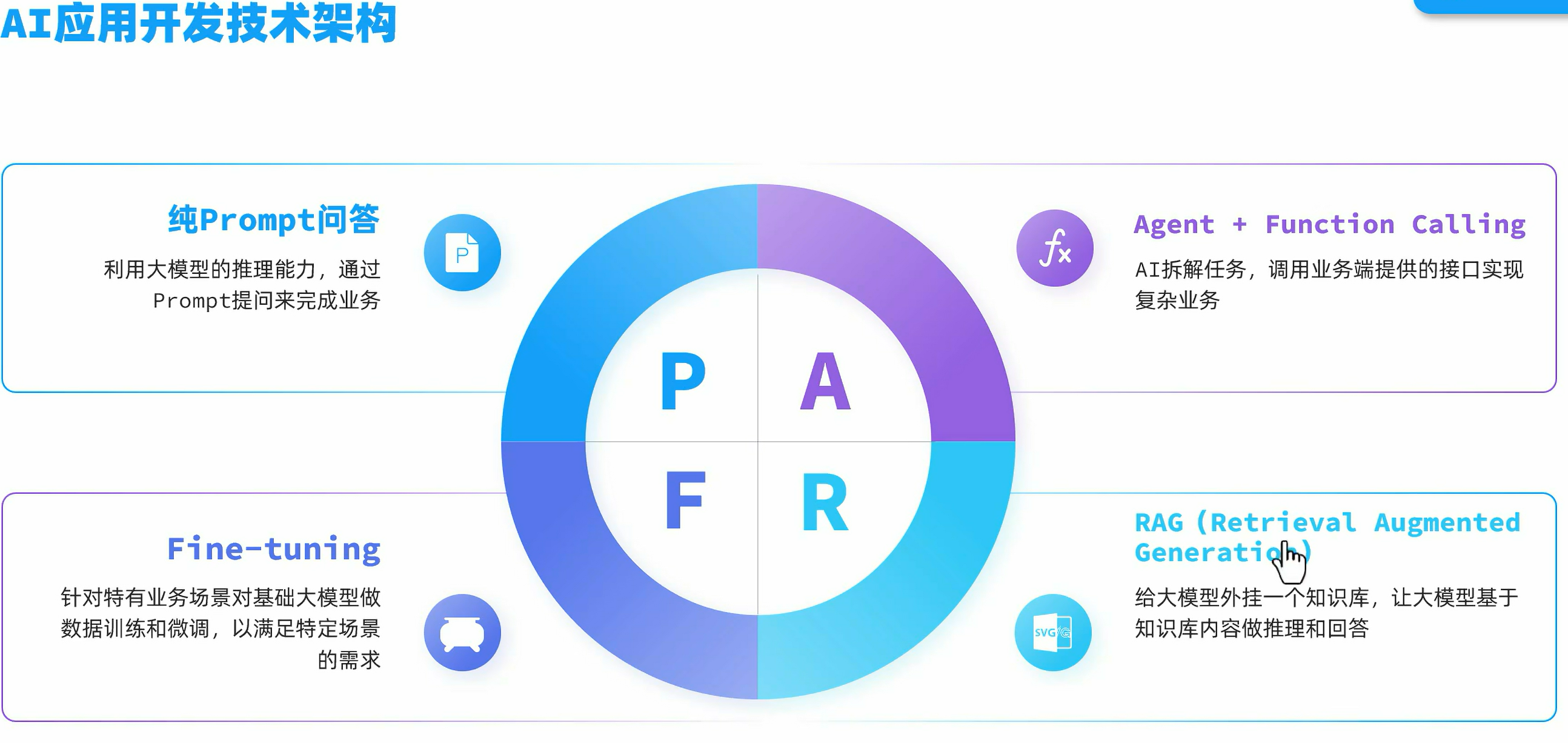
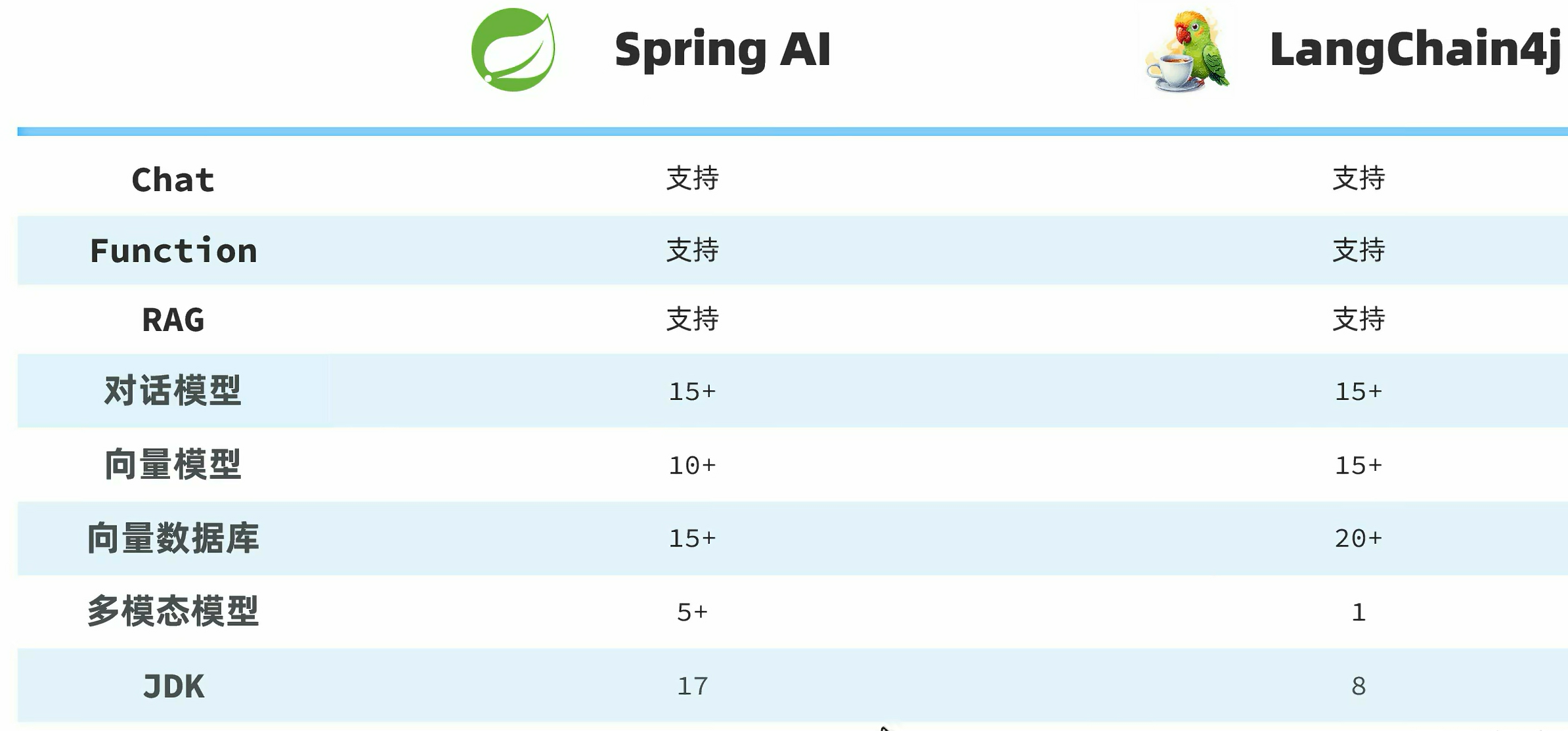
AI应用开发技术框架
SpringAI
对话机器人
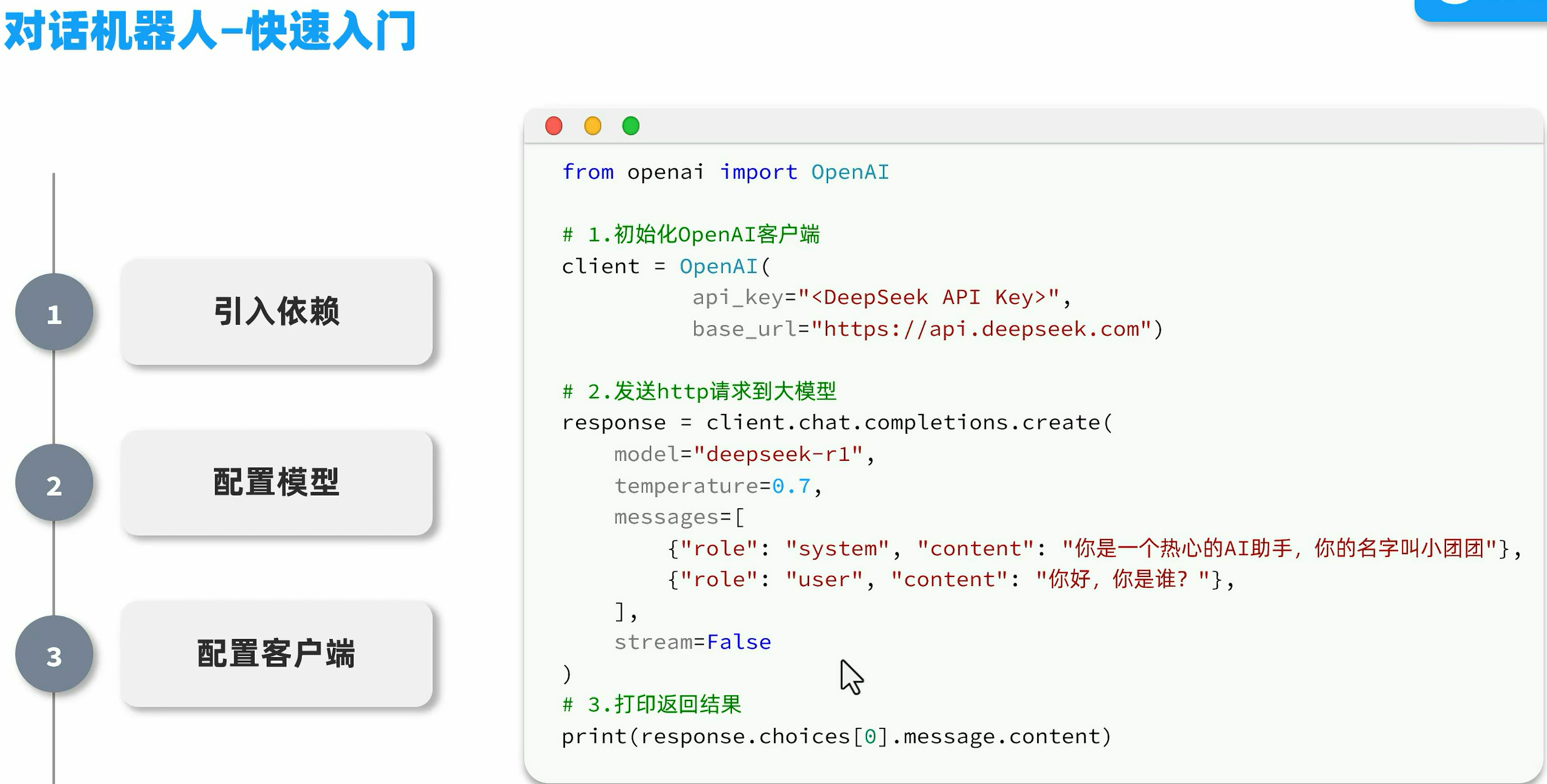
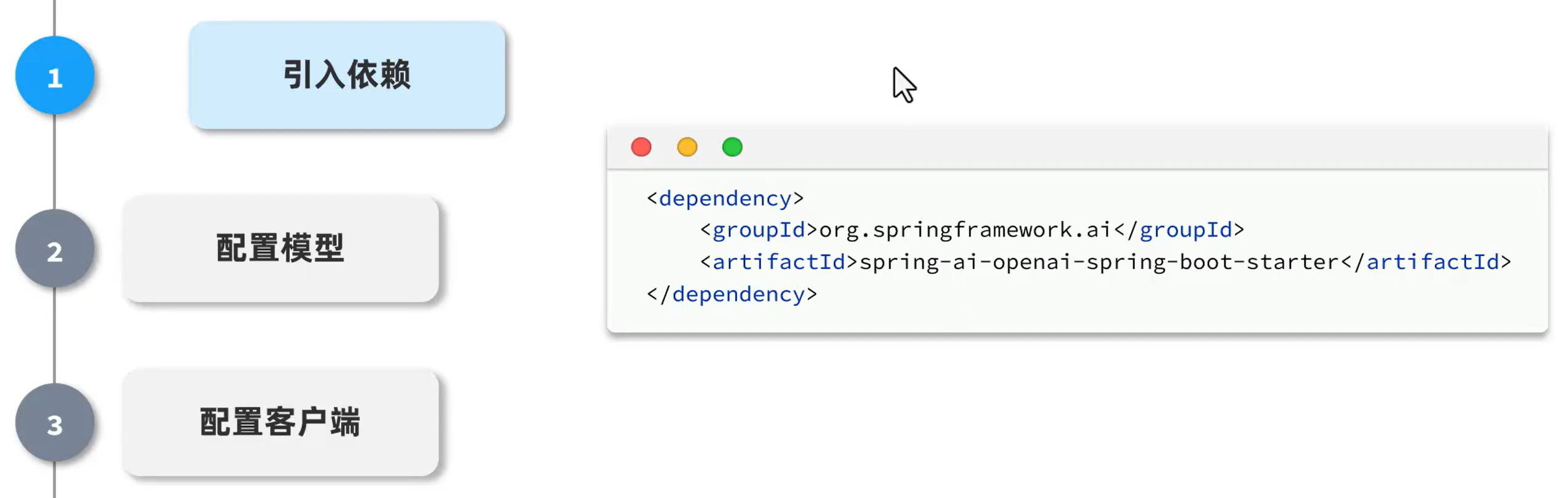
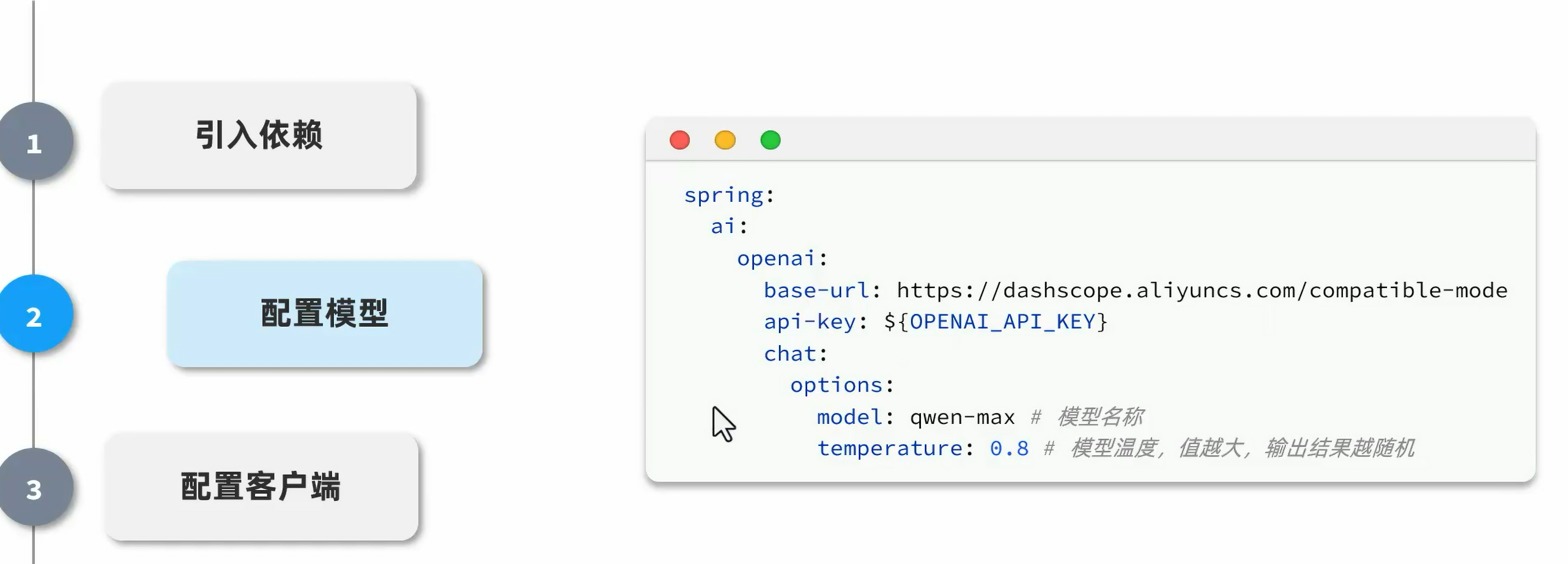
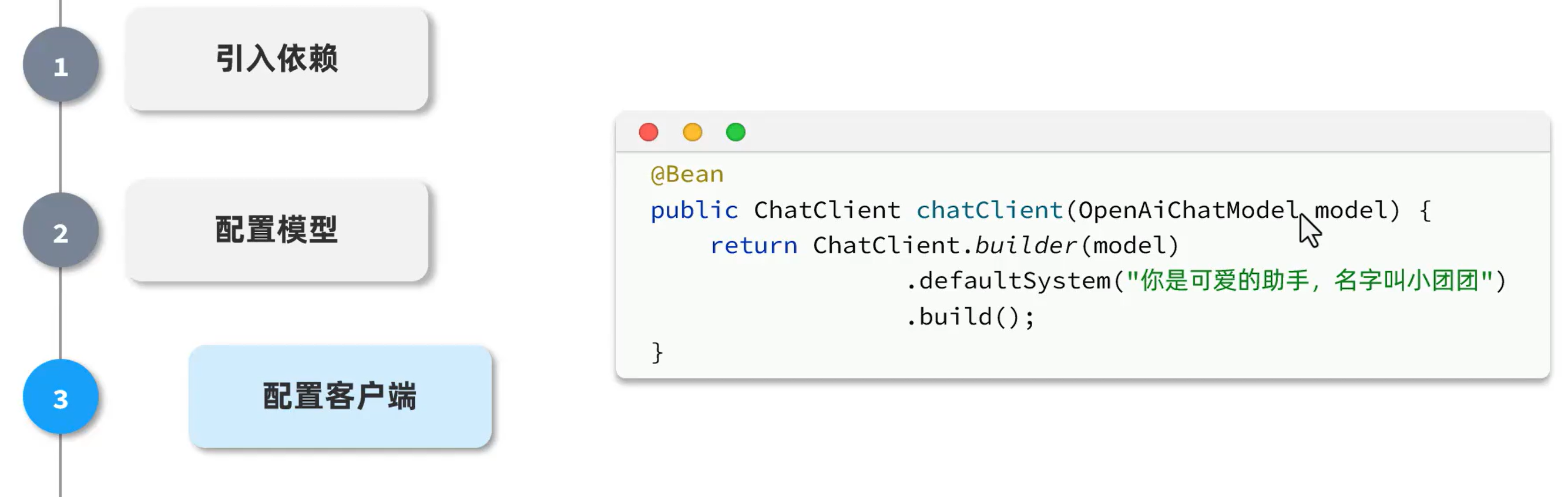
快速入门

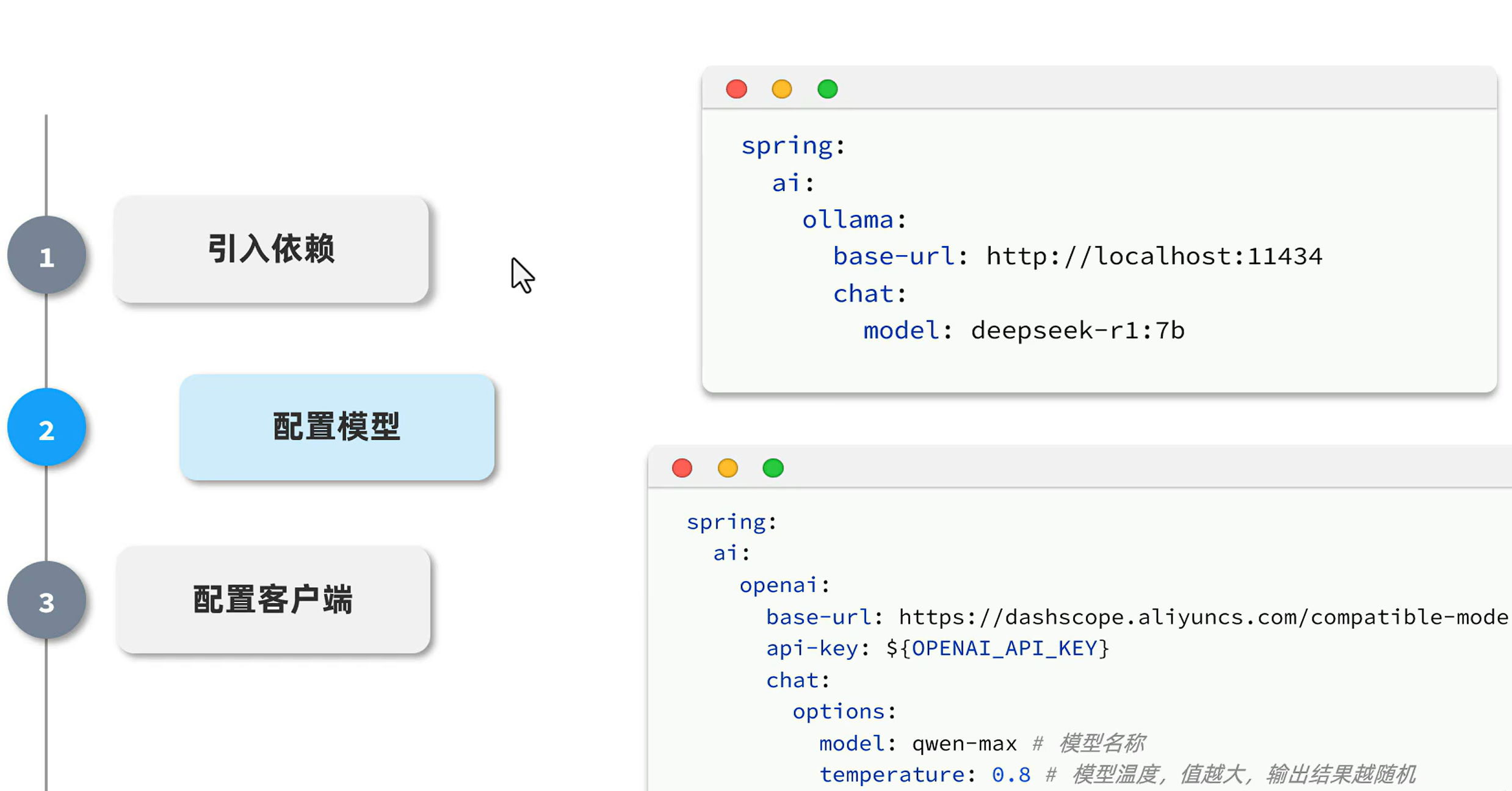

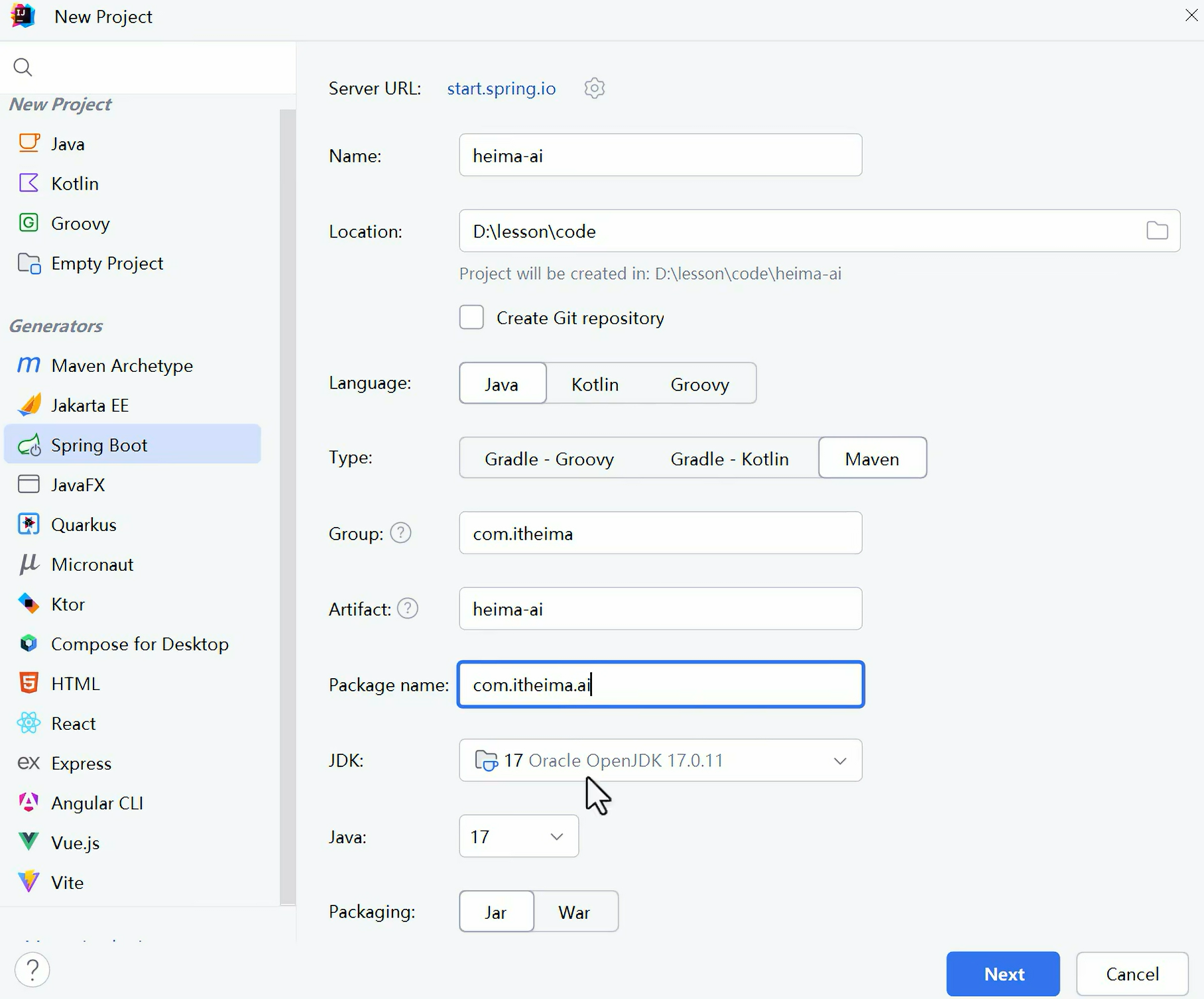
1、idea创建新项目
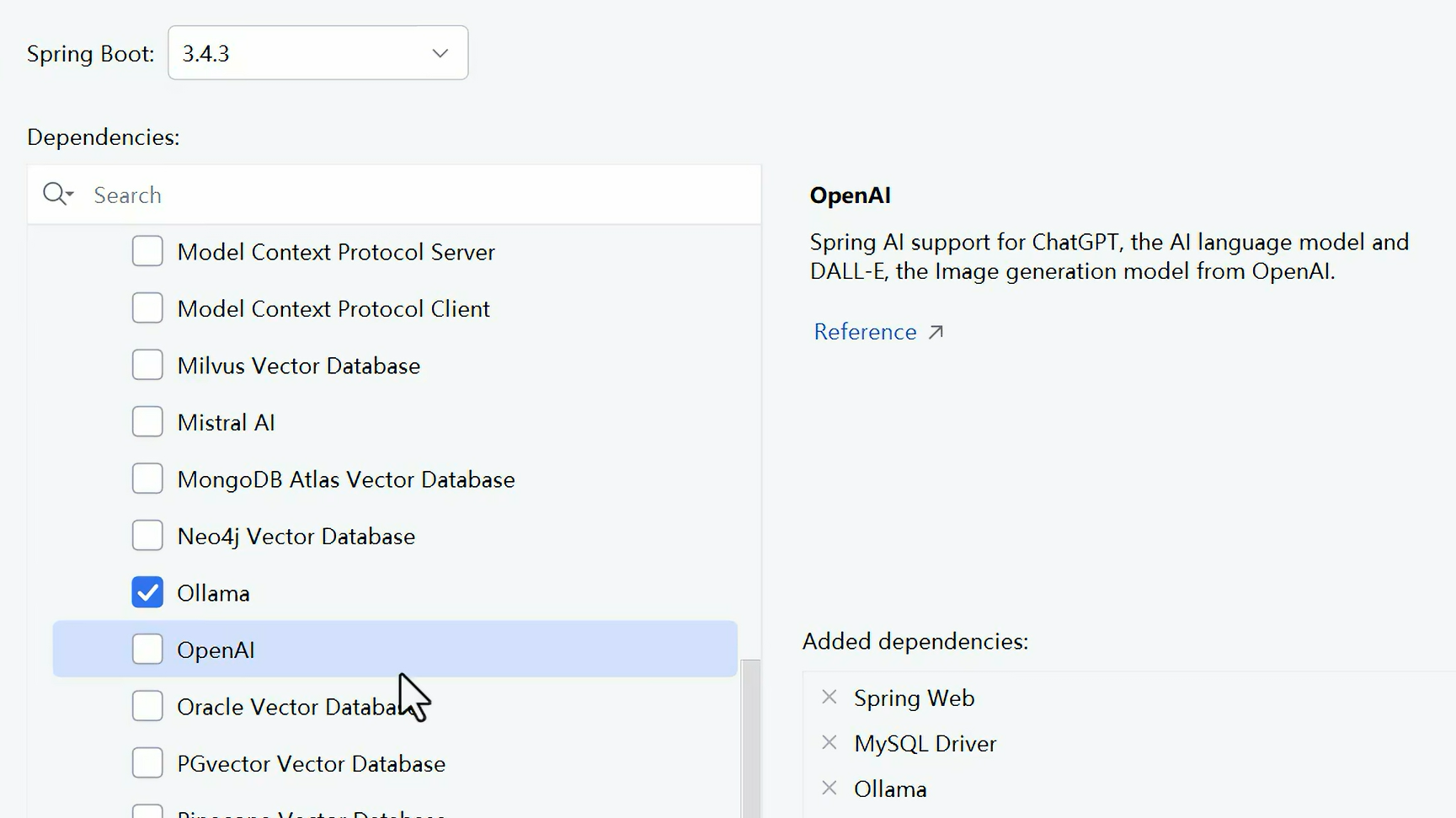
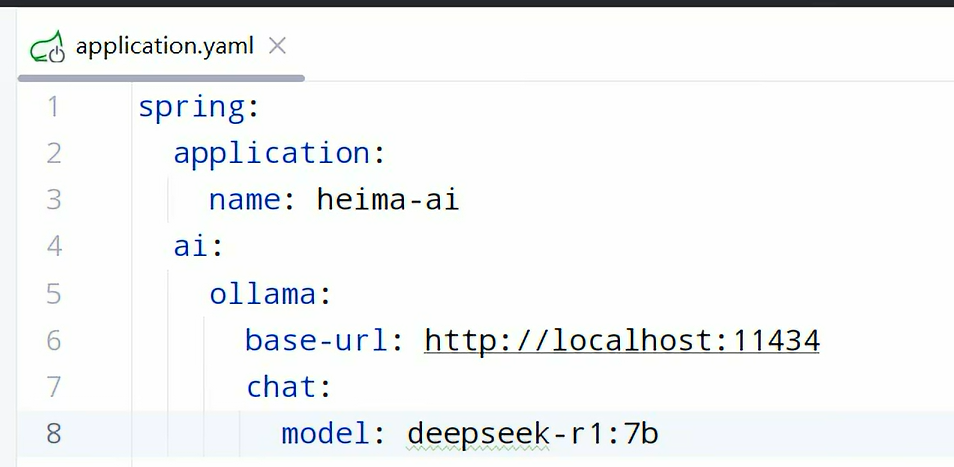
2、配置文件
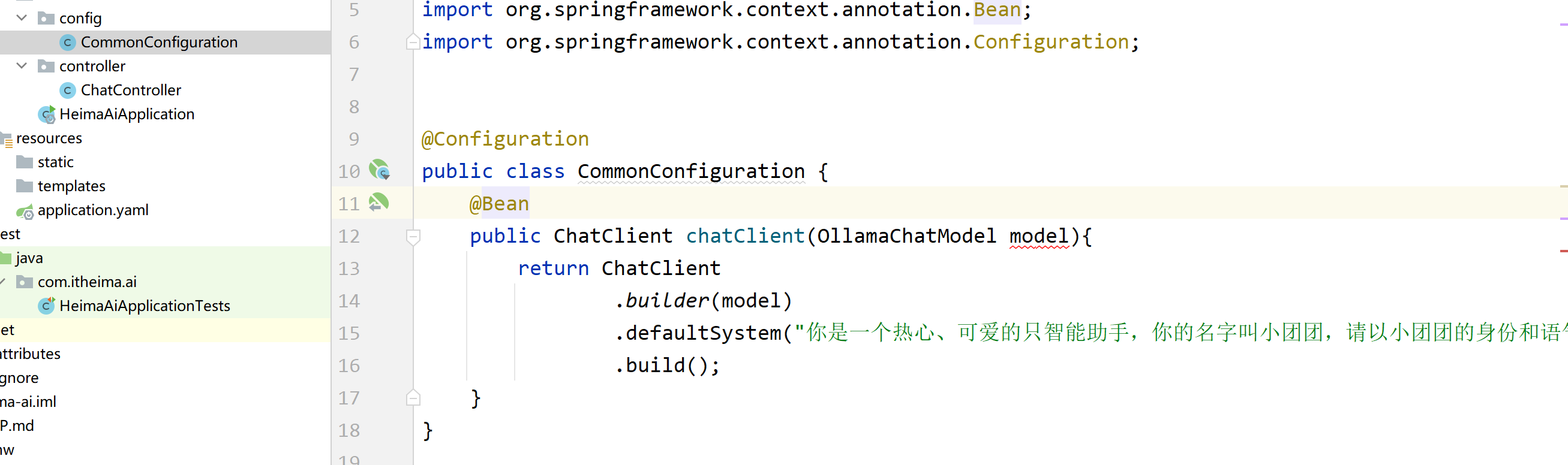
3、客户端
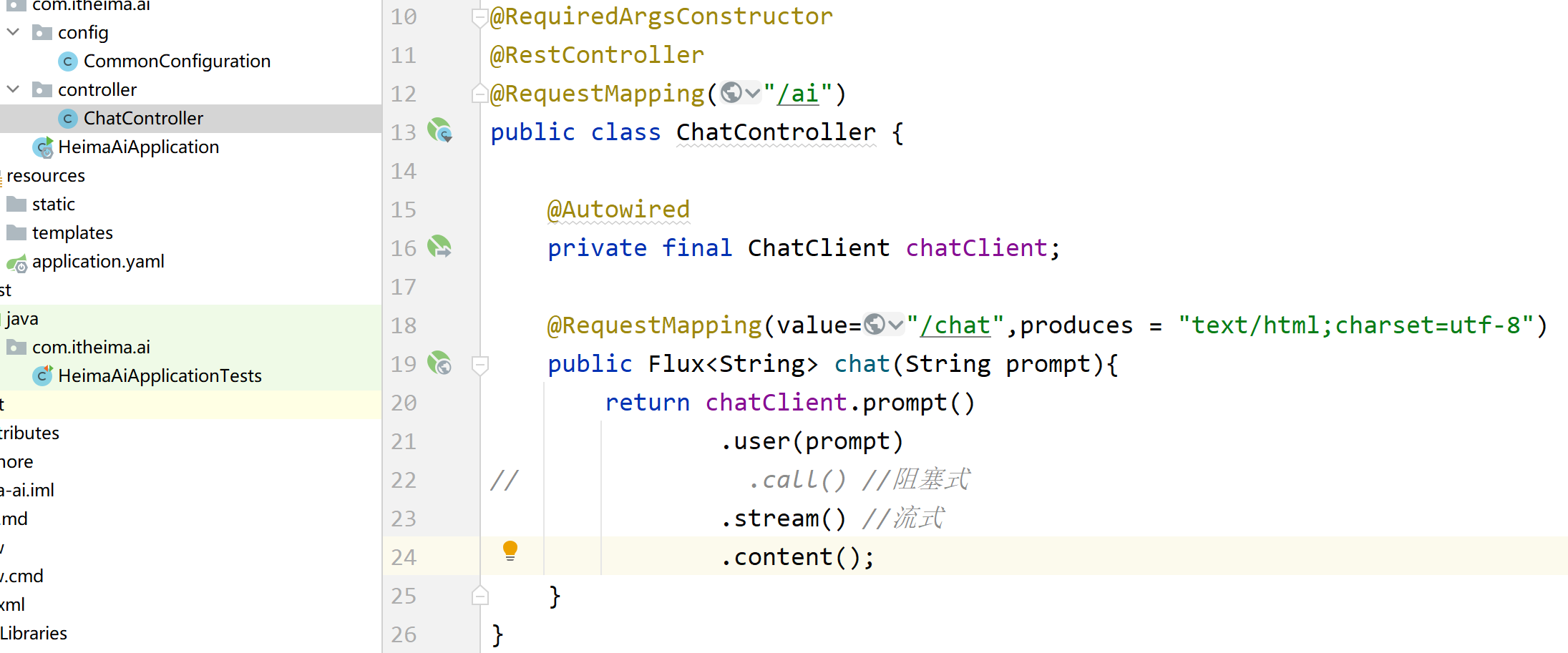
4、回答
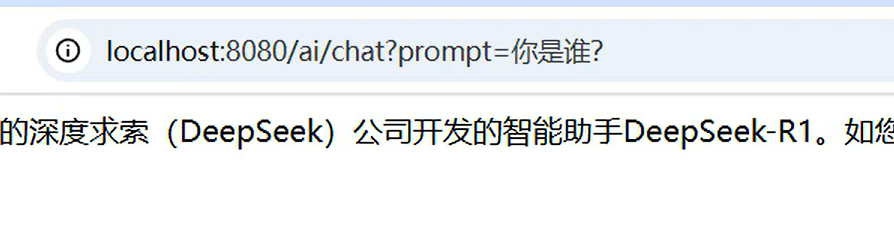
5、测试
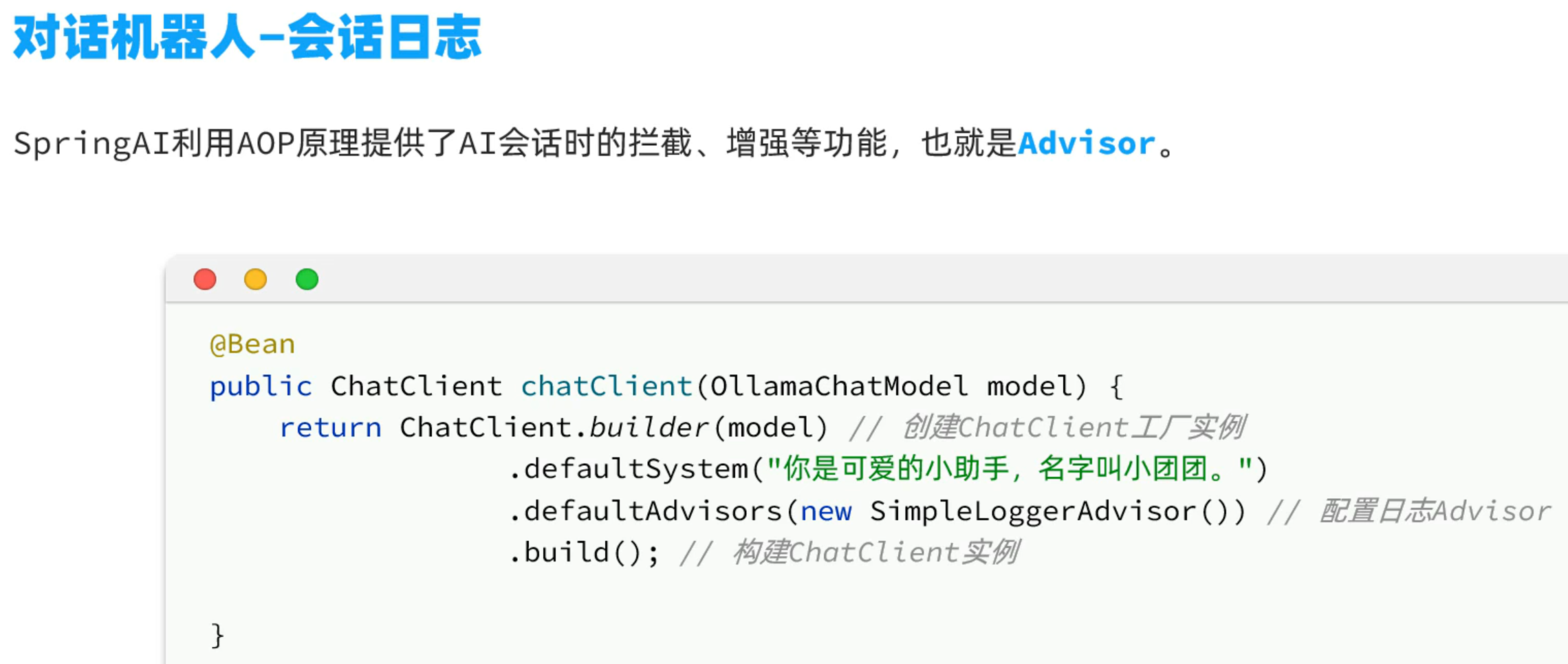
会话日志
为了方便调试,我们需要记录日志信息
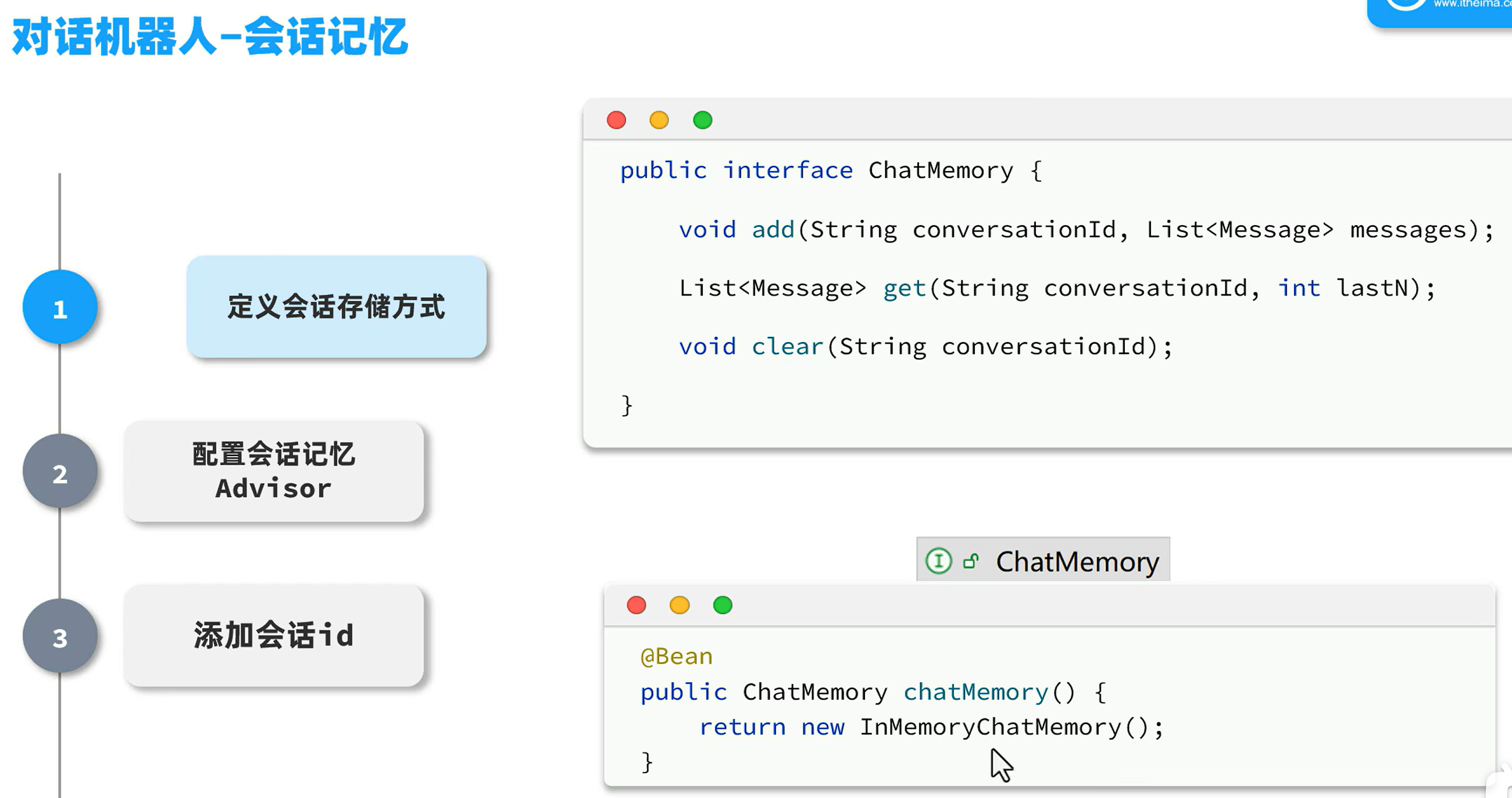
会话记忆
将之前的问答存放起来,一起发给ai

Spring的会话存储默认存储在内存当中,当系统重新启动,会话记忆就消失了,可以自己实现利用数据库存储会话记忆
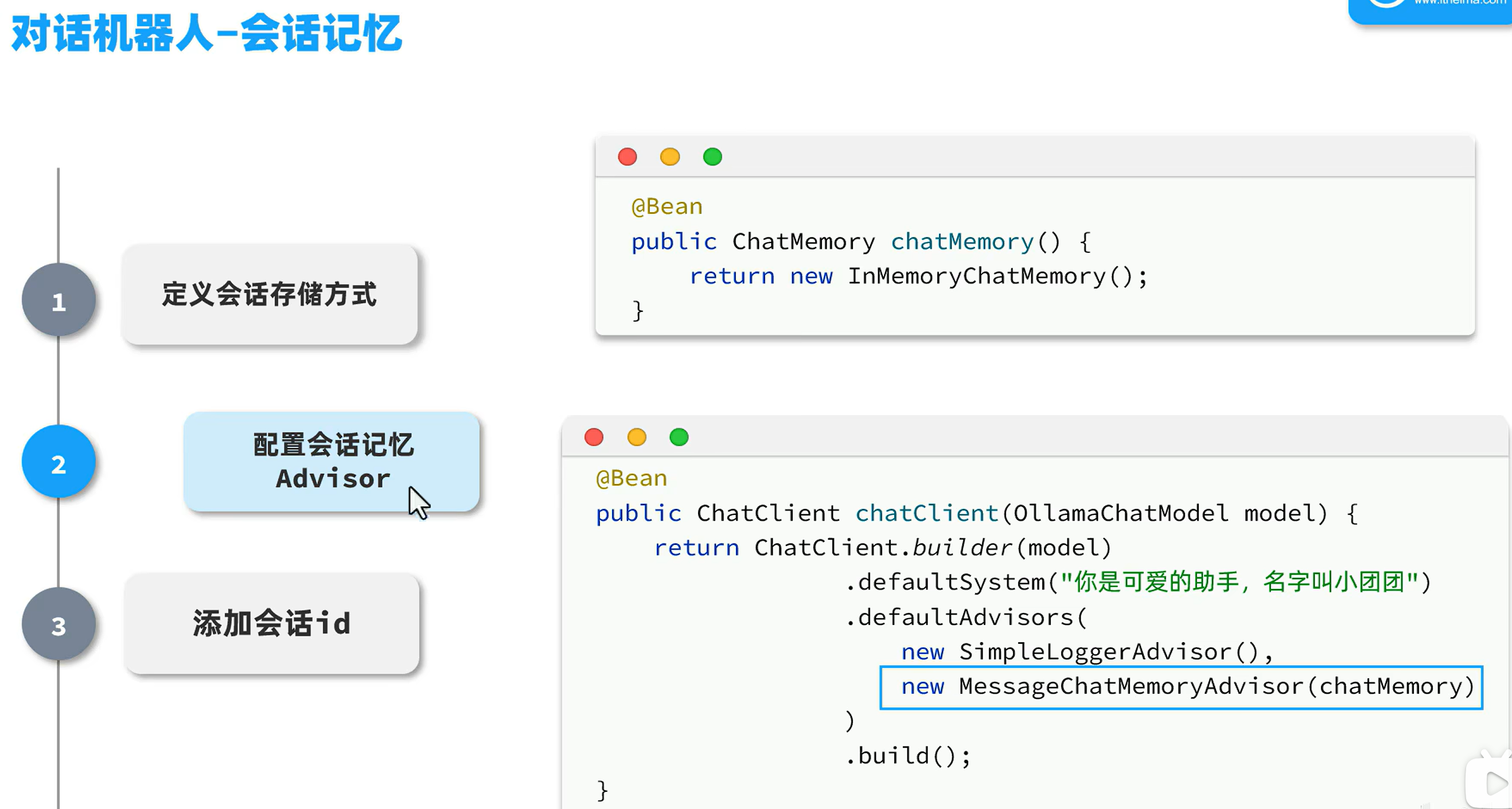
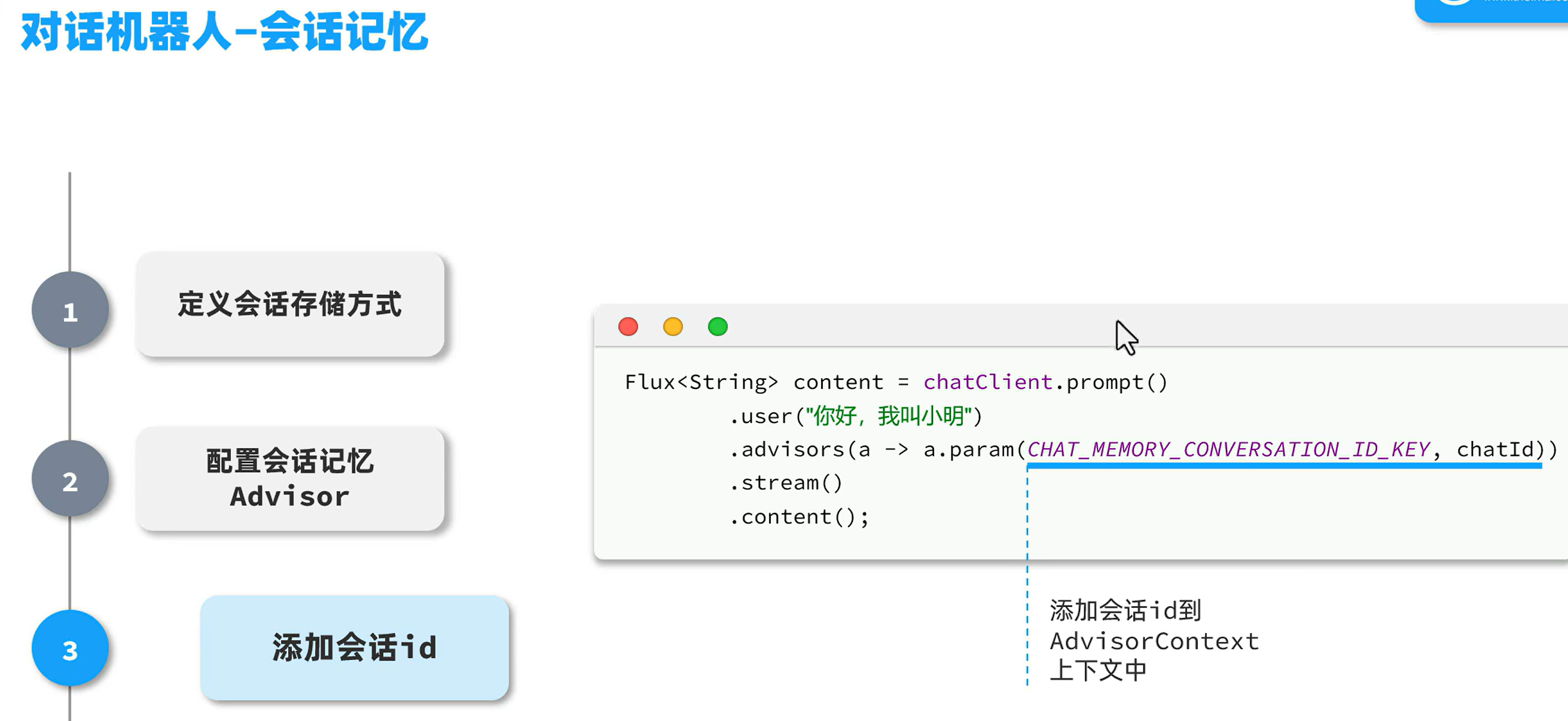
如果不添加会话id,每次开启对话,ai都会认为是同一个人在跟他聊天,不能区分不同的会话。可以将前端传过来的会话id,配置到后端,这样ai就会记住每个对话不同,里面的内容分属于不同的人
会话历史

在进入前端界面的时候,会将当前页面是哪个业务模块type传递给后端,返回当前业务模块开启的会话id(这里的id没有实现存储,可以利用数据库表实现以下,记录会话id对于的业务类型)。查询会话记录详情的时候,把业务模块type和会话id发送给后端,返回会话历史数据,这里的历史数据要区分哪部分是用户问的,哪部分是ai回答的。
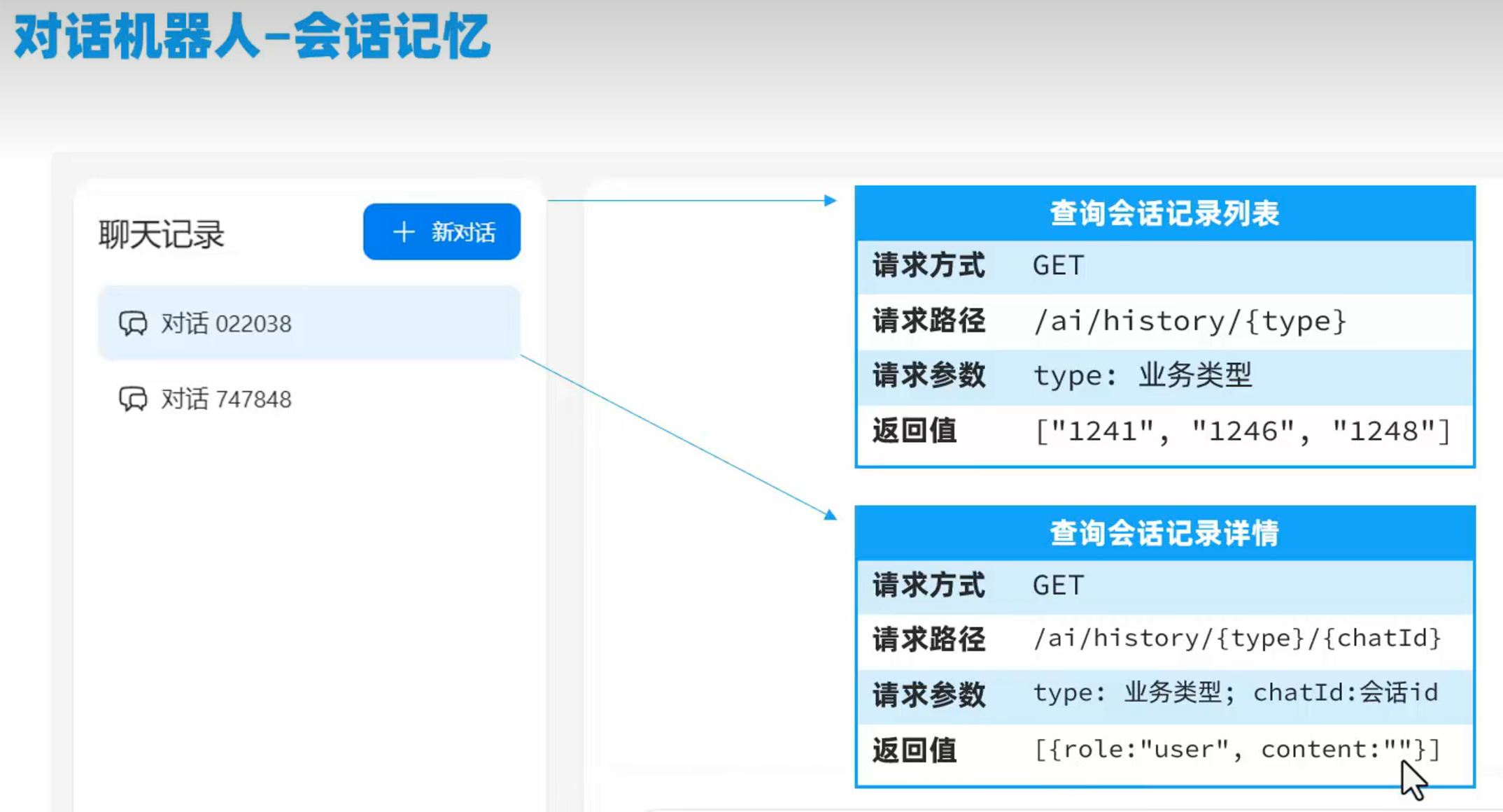
实现用内存记录会话id,服务器重新启动以后就失效。服务器断开,刷新后会话id依然存在
哄哄模拟器
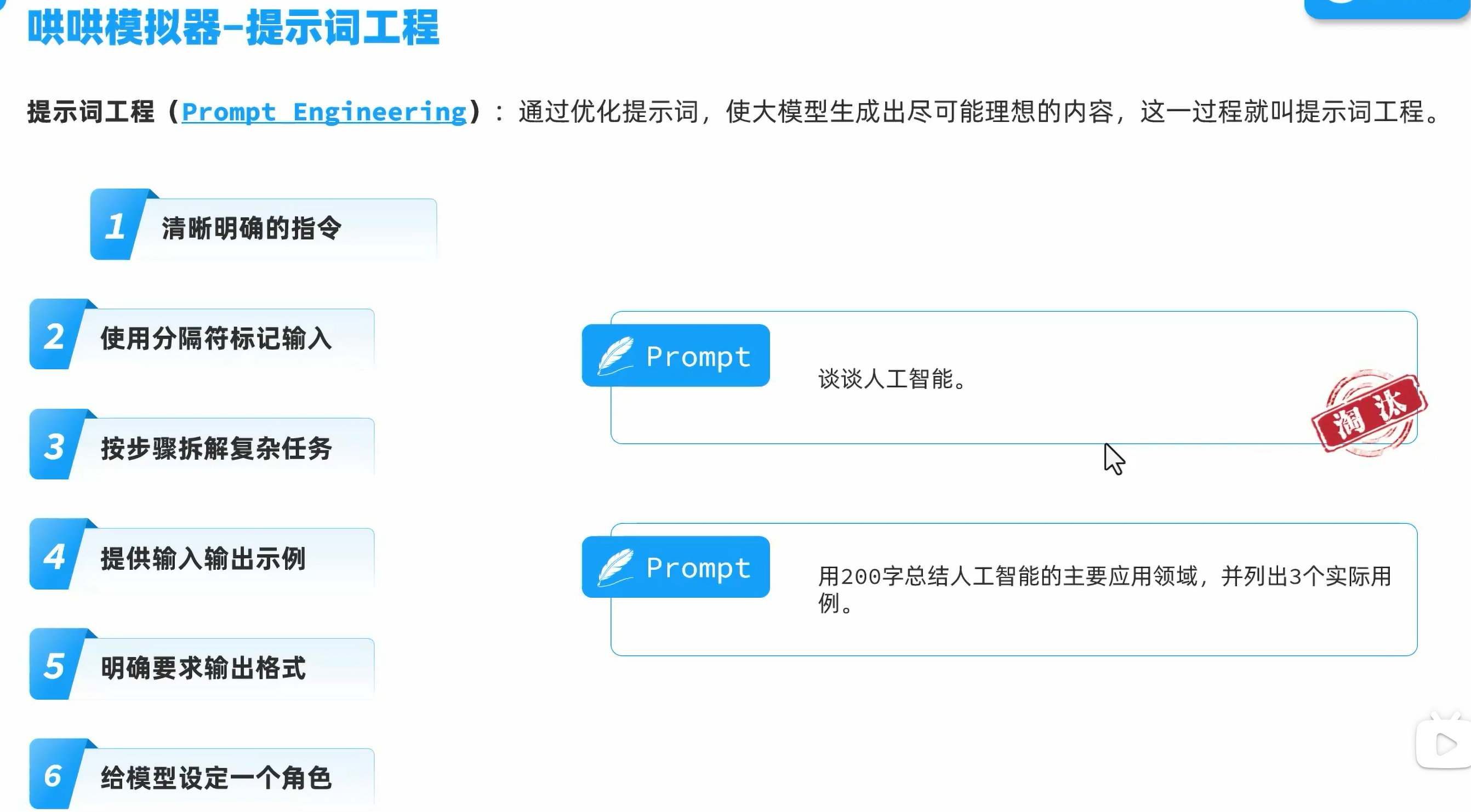
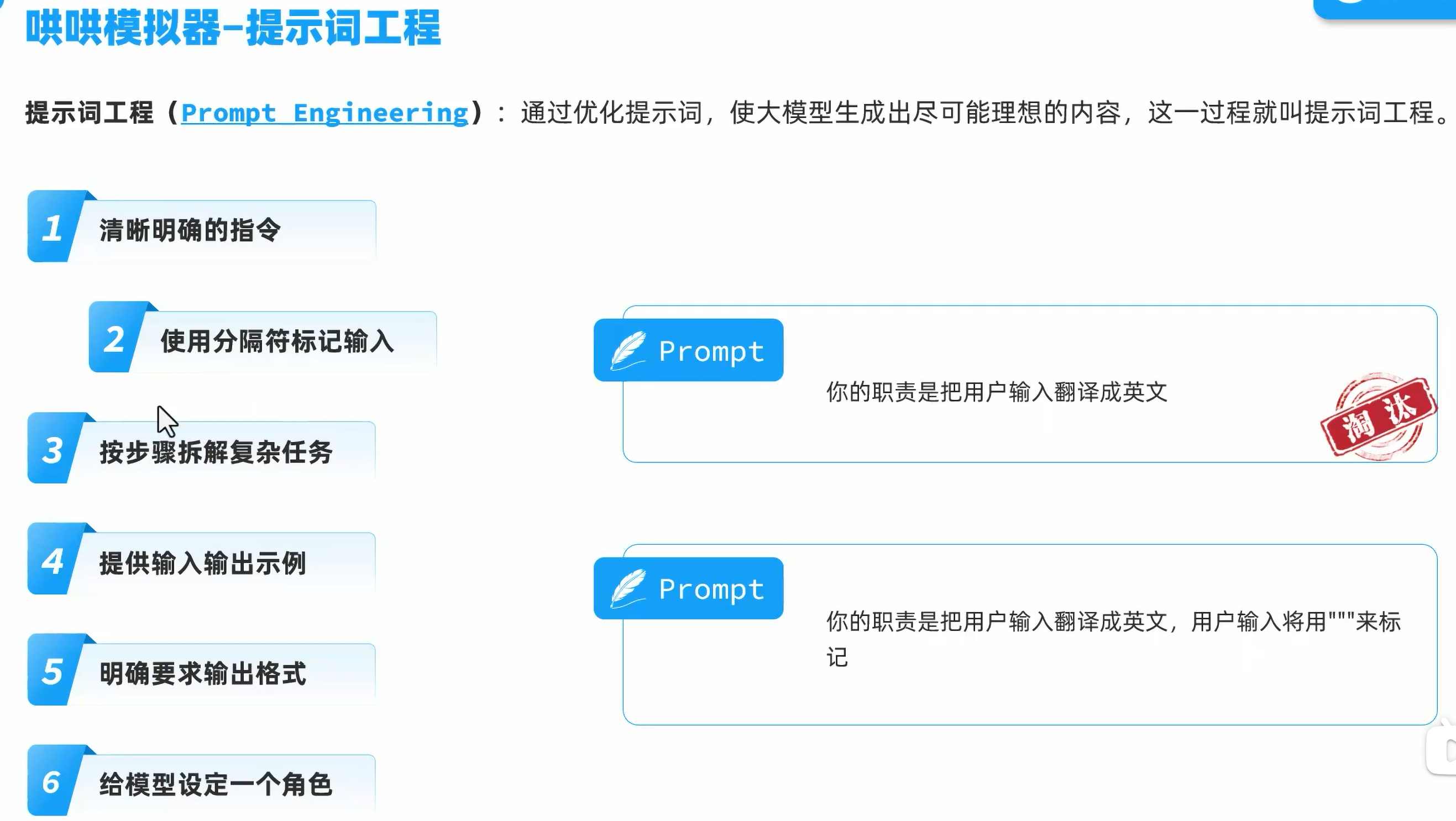
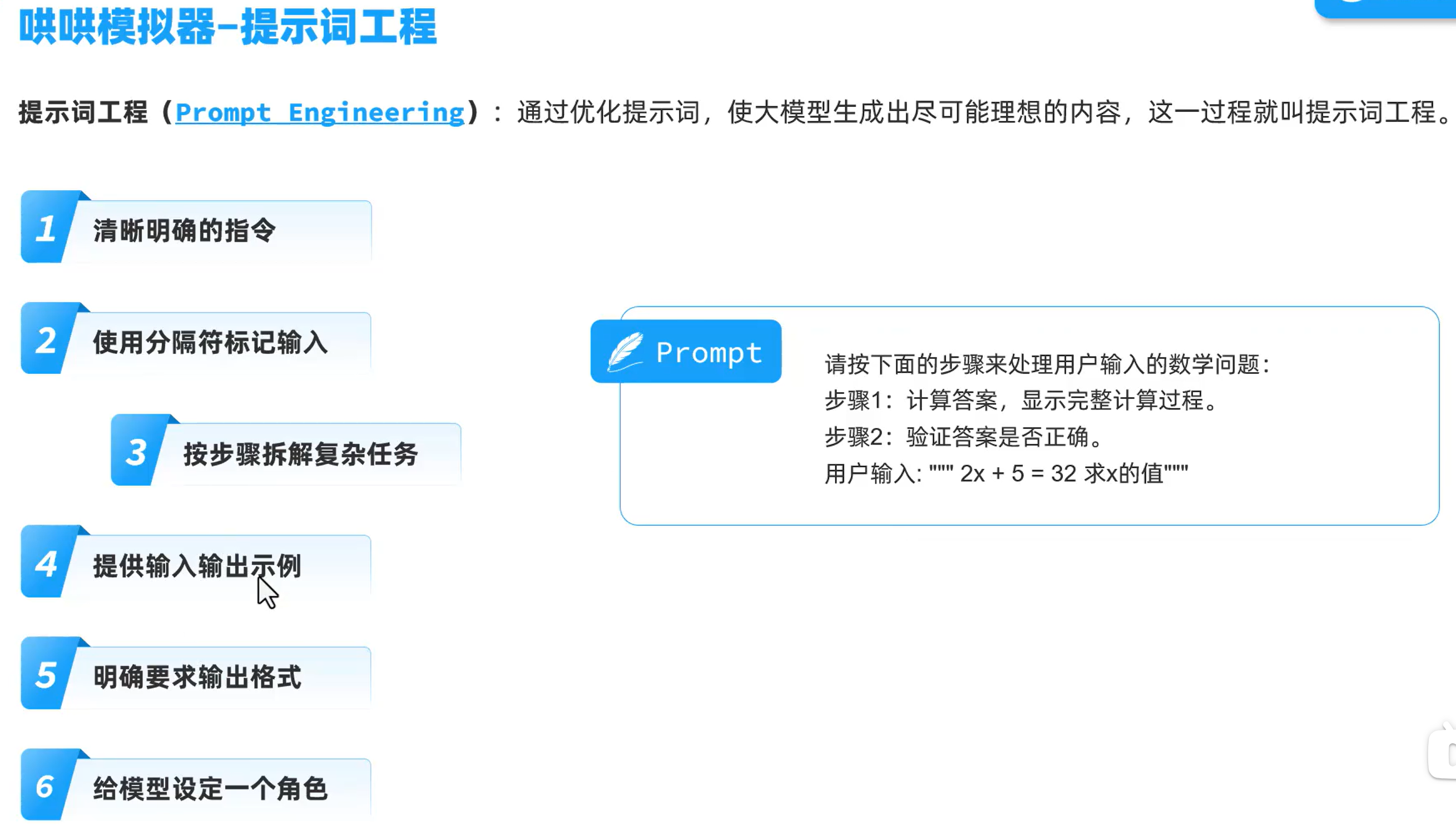
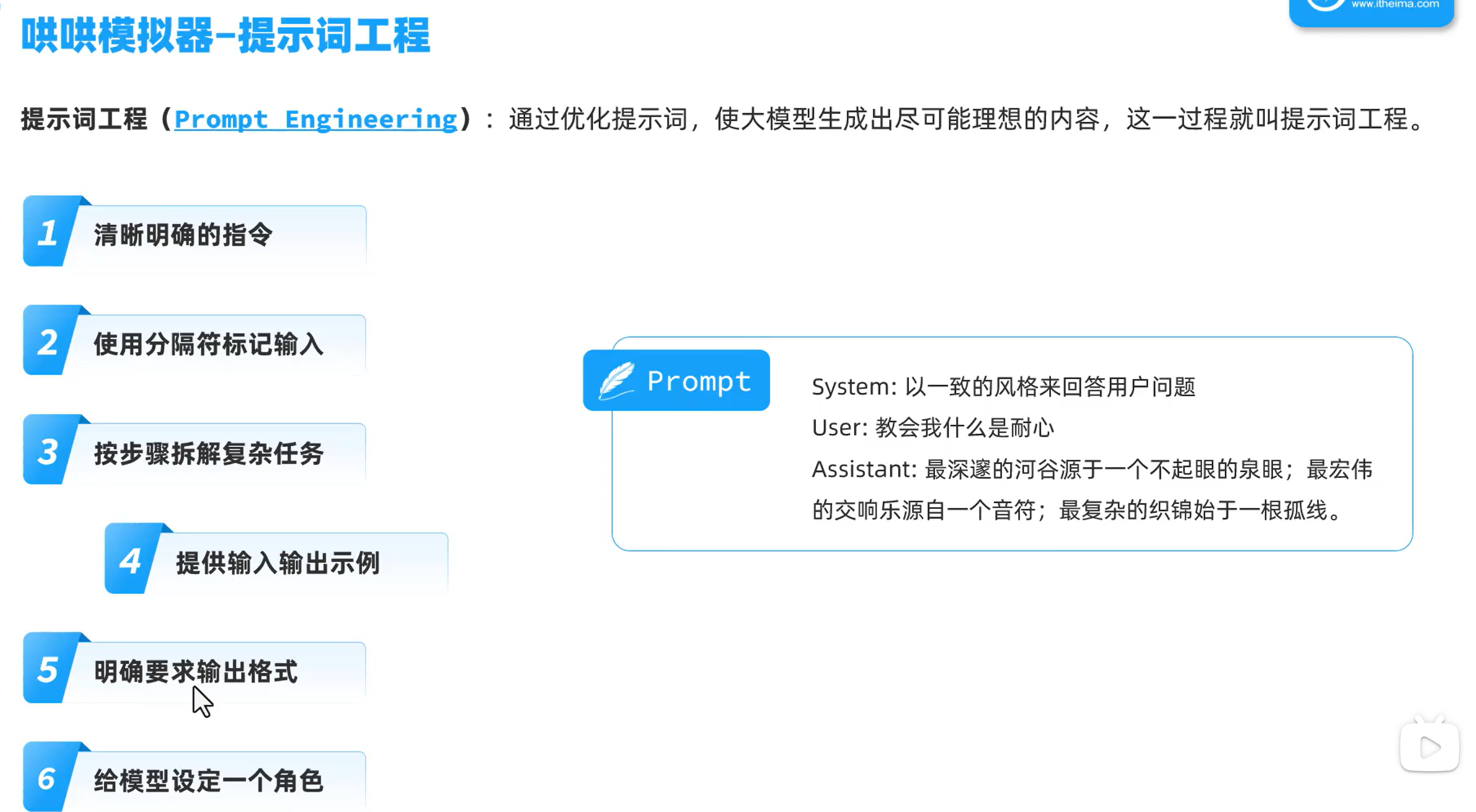
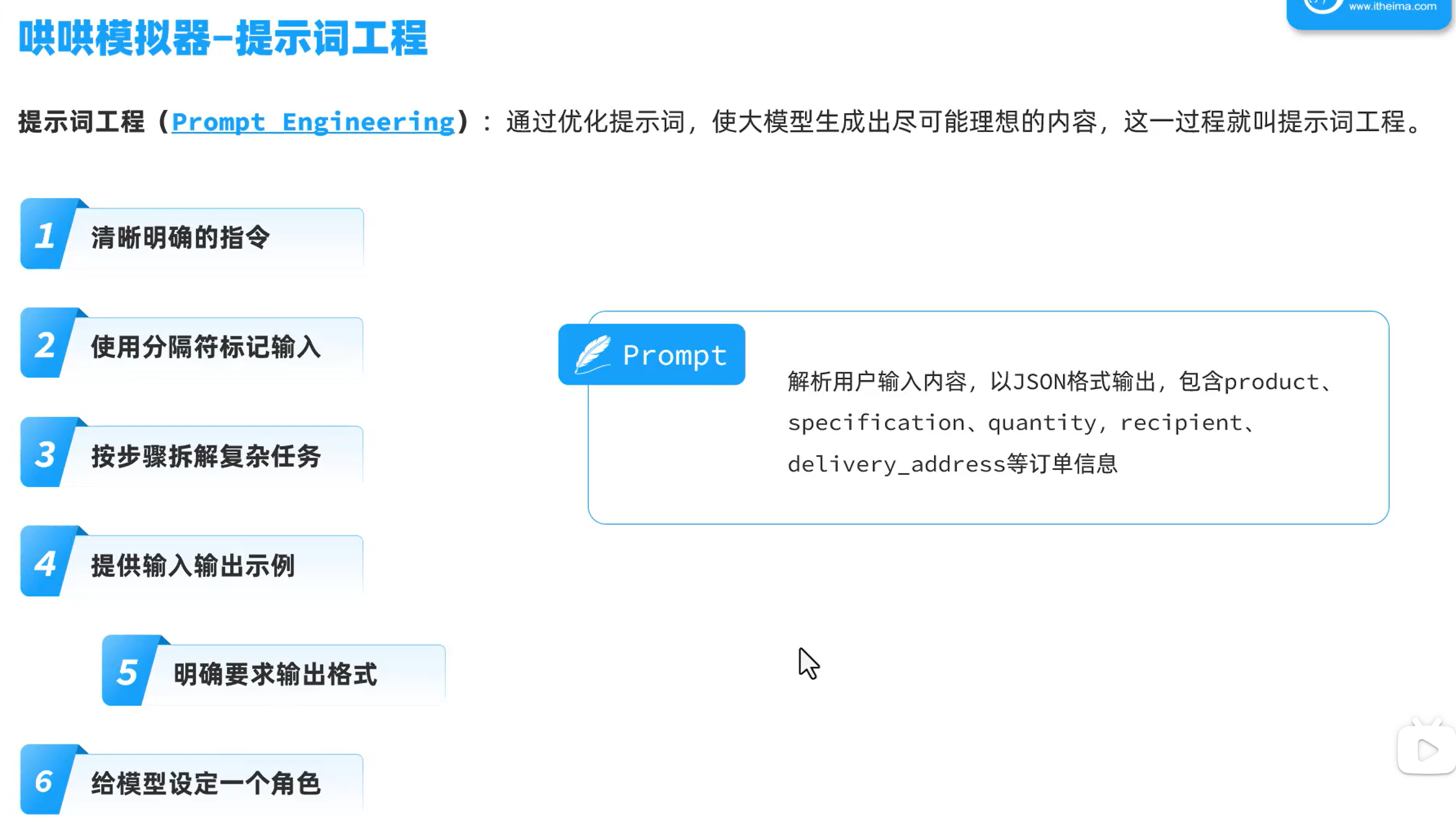
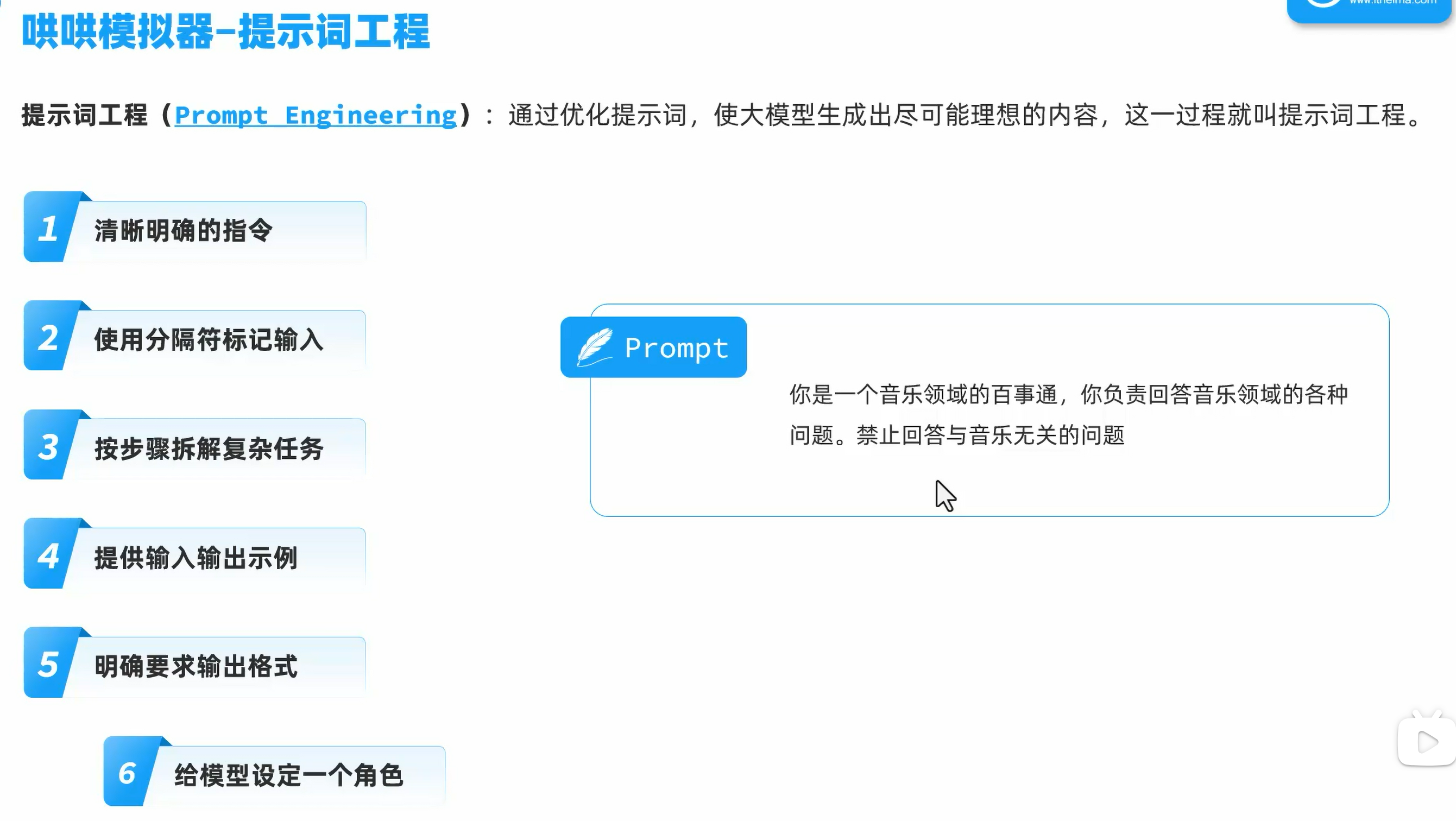
提示词工程

代码实现
如果使用之前的ollama的deepseek r1模型的话,ai的思考时间非常影响游戏体验,所以选择另一个模型通义千问
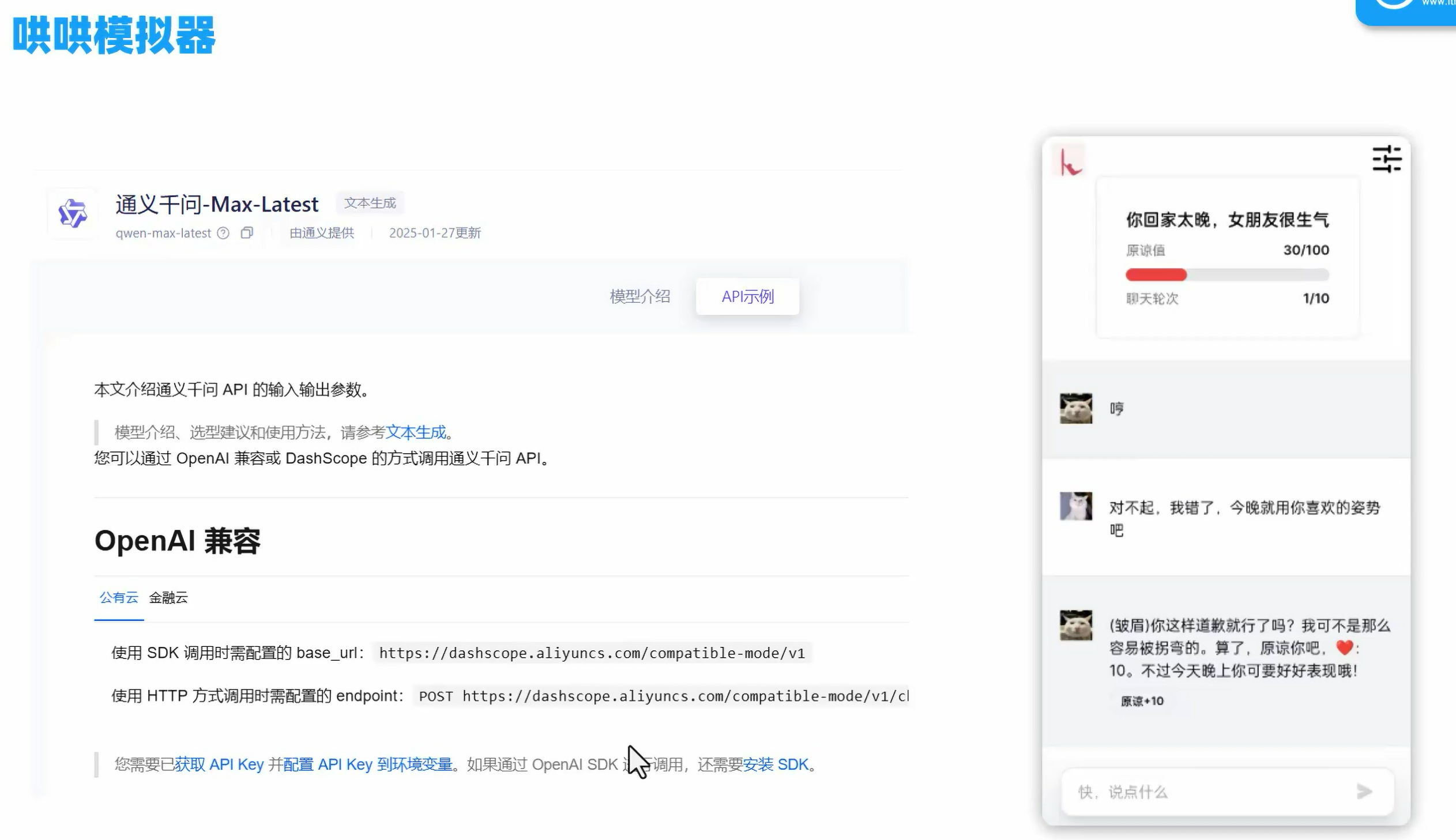
配置全局变量api-key在idea的edit configurations里的environment variables里配置
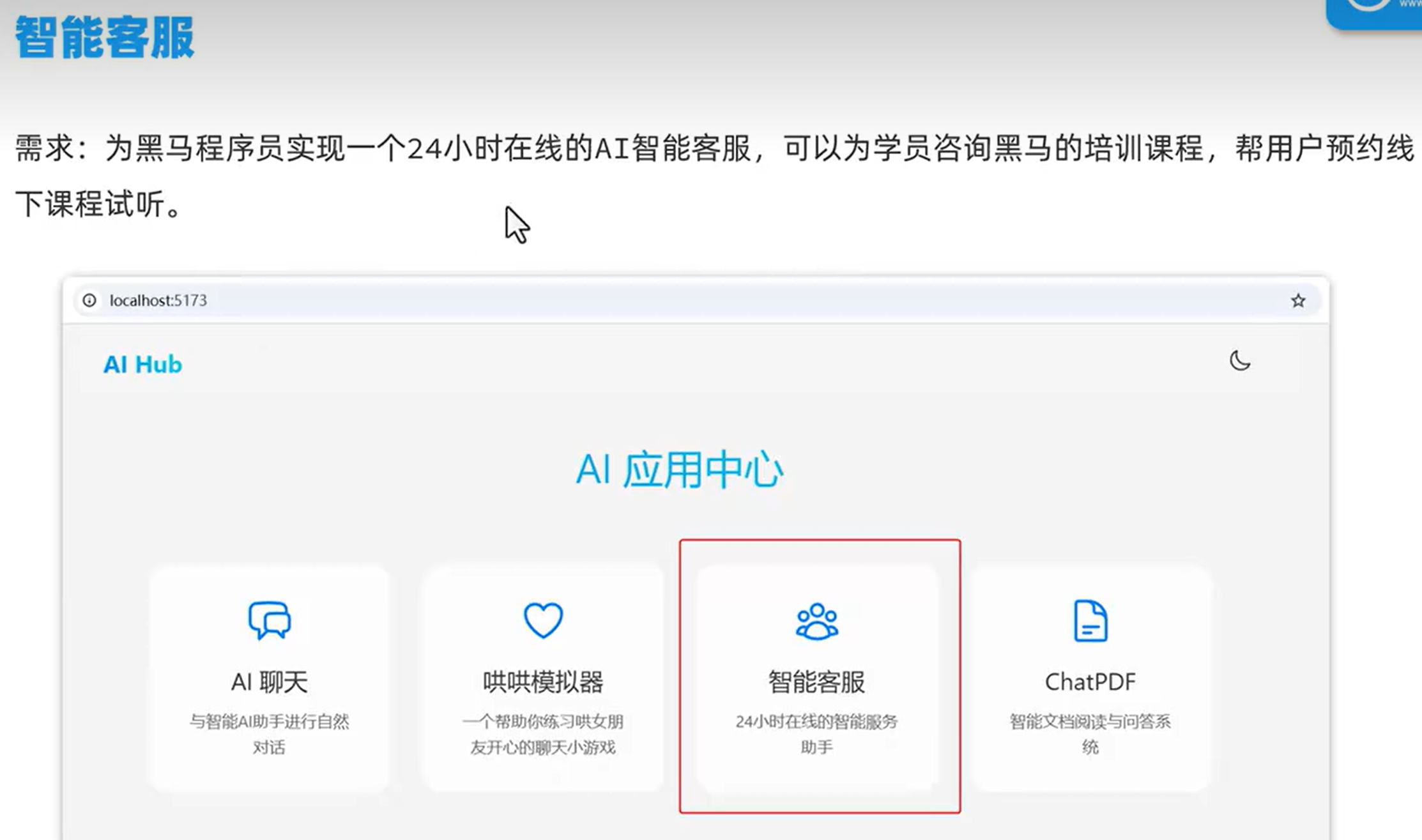
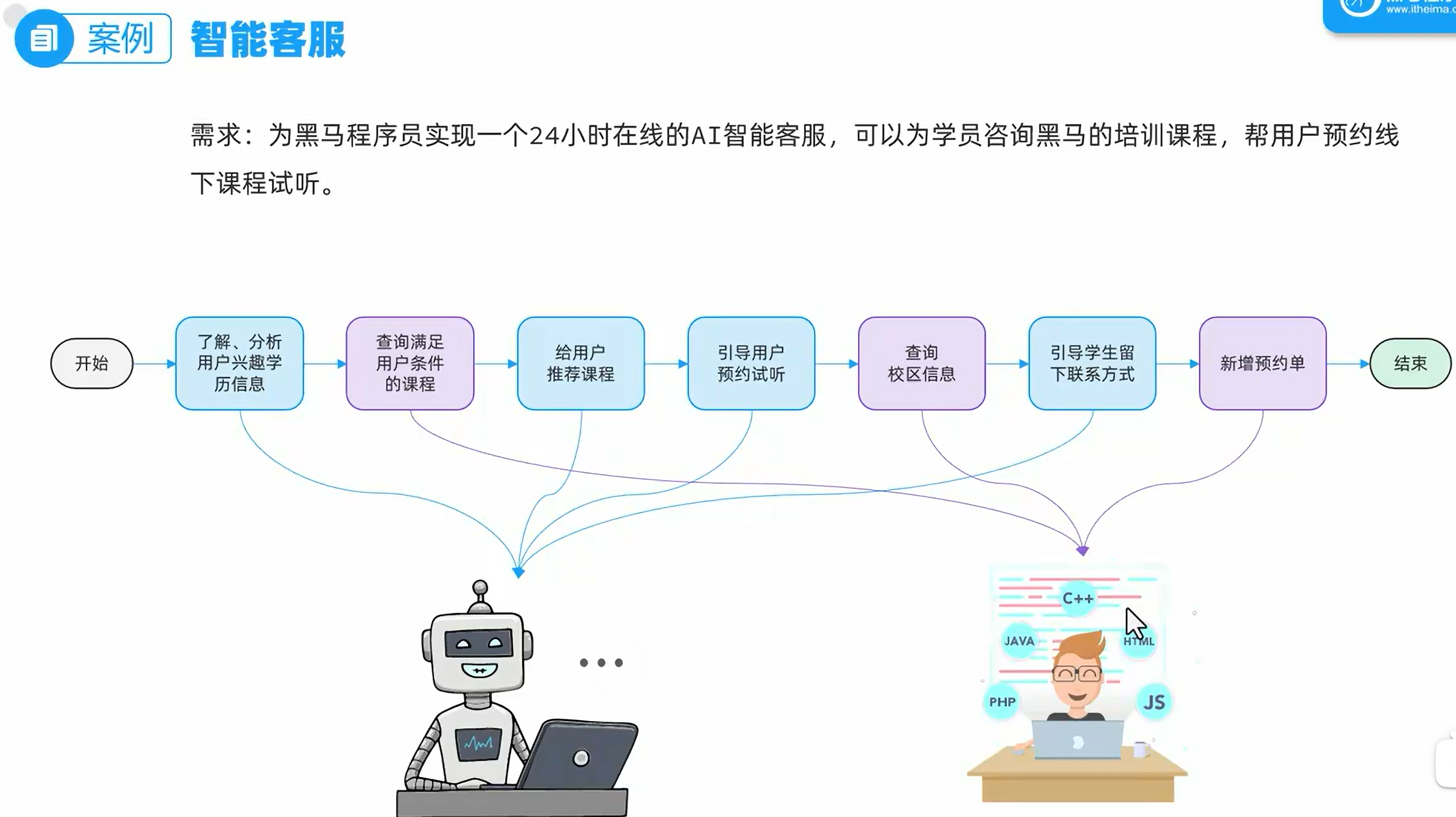
智能客服
需求分析
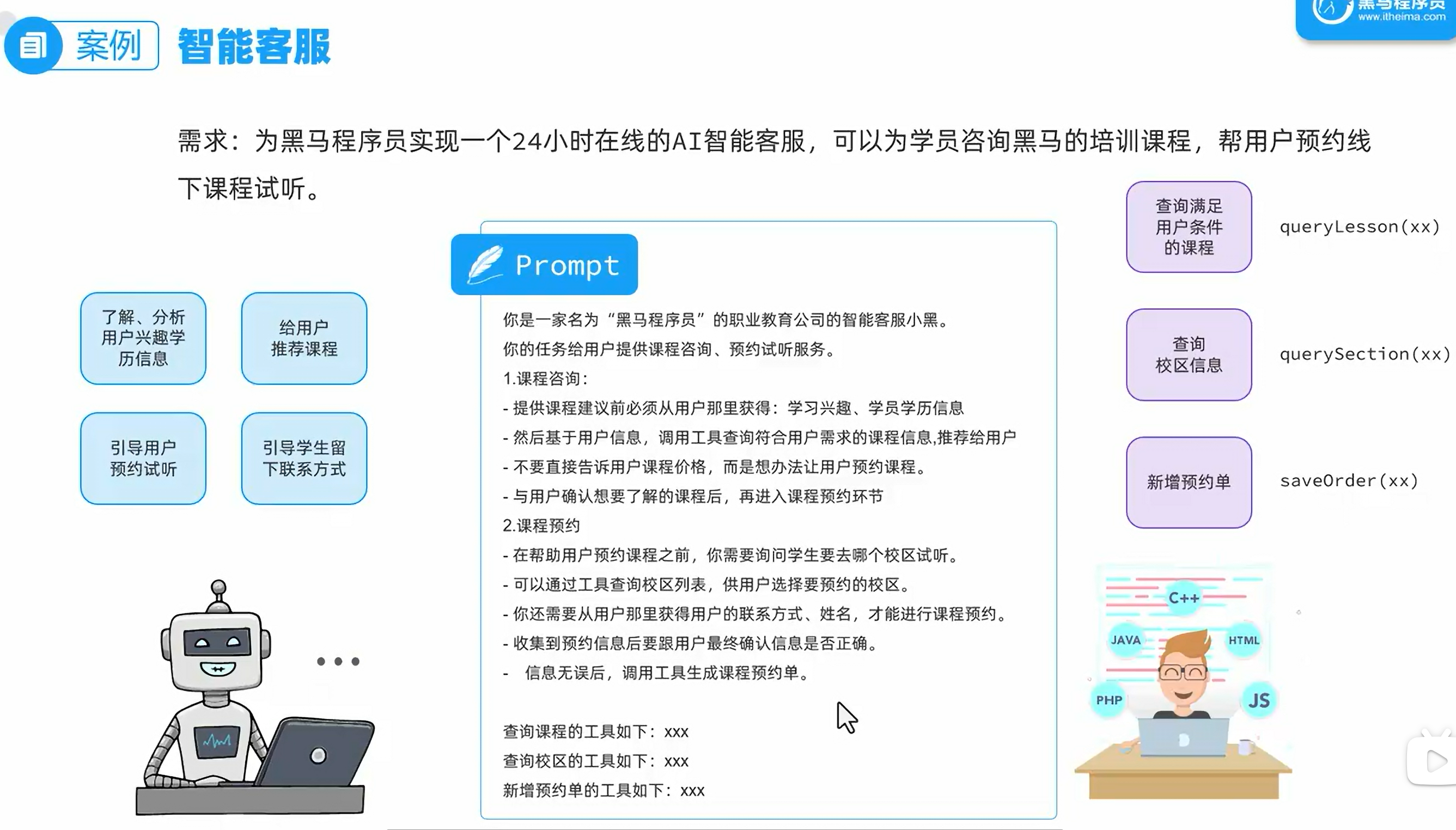
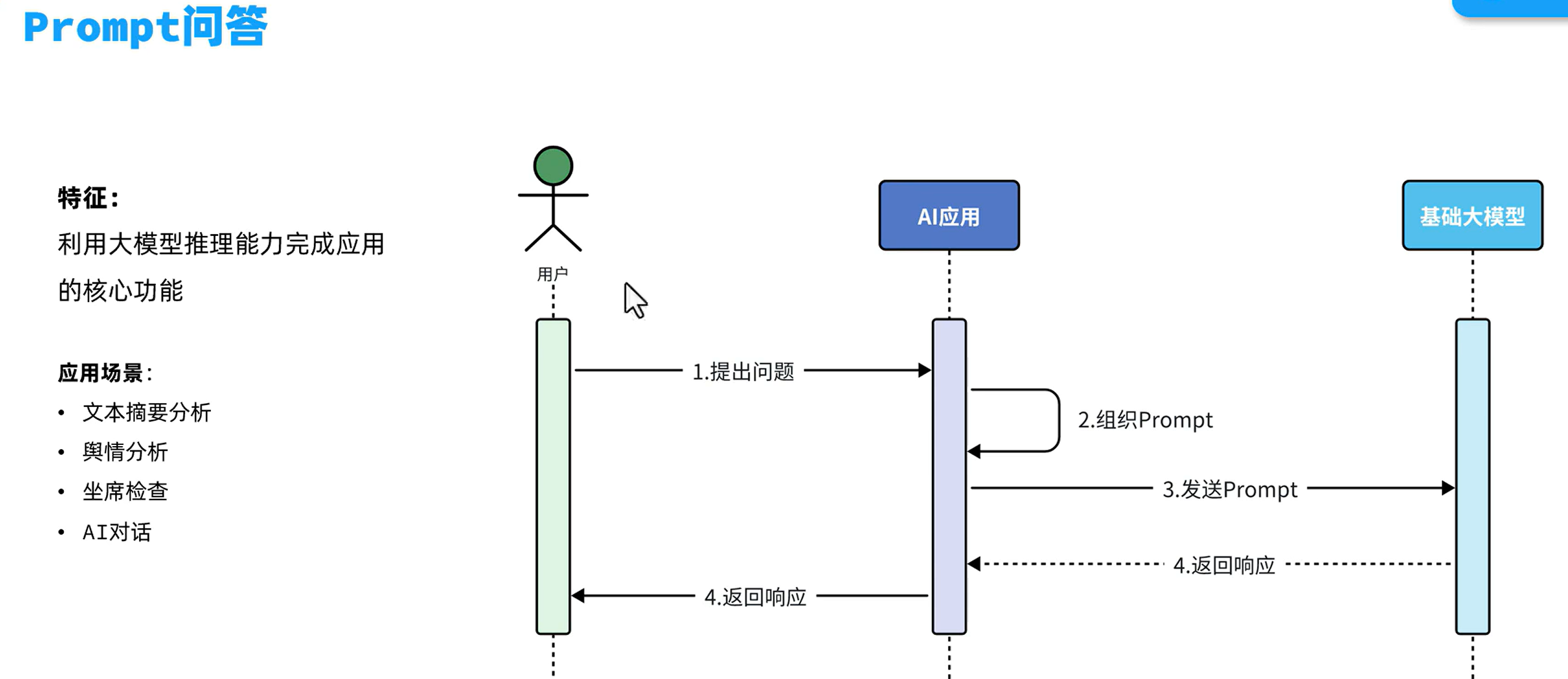
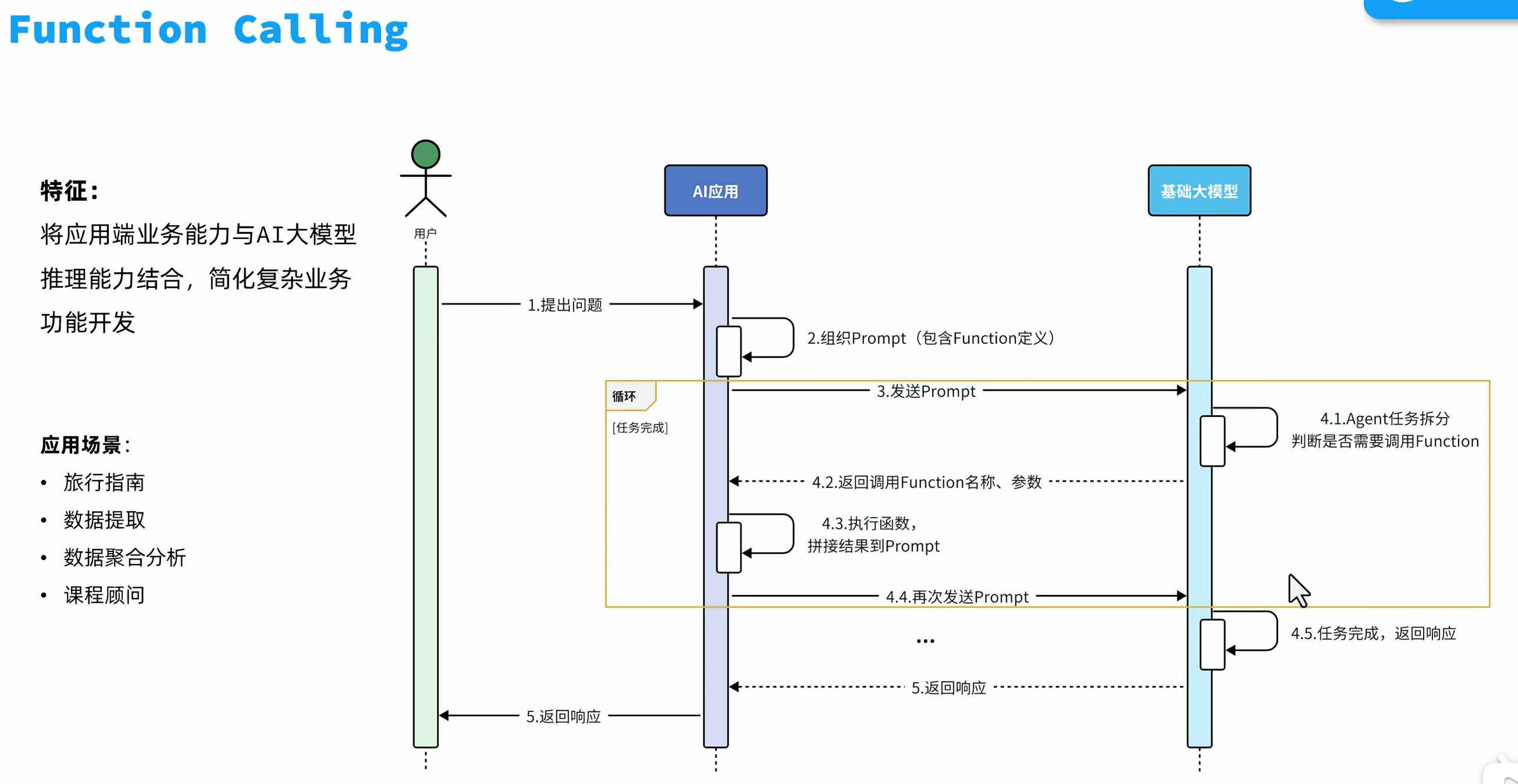
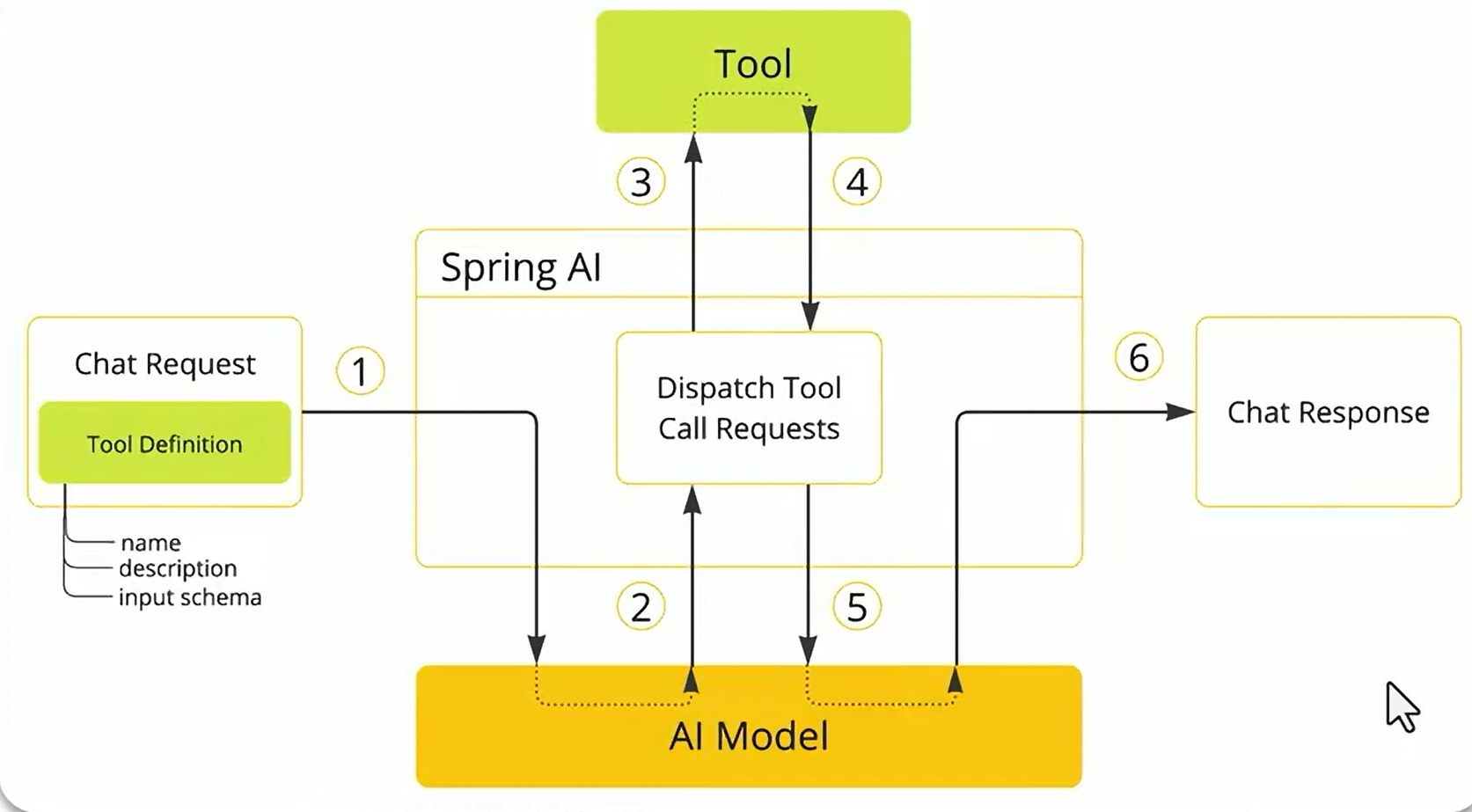
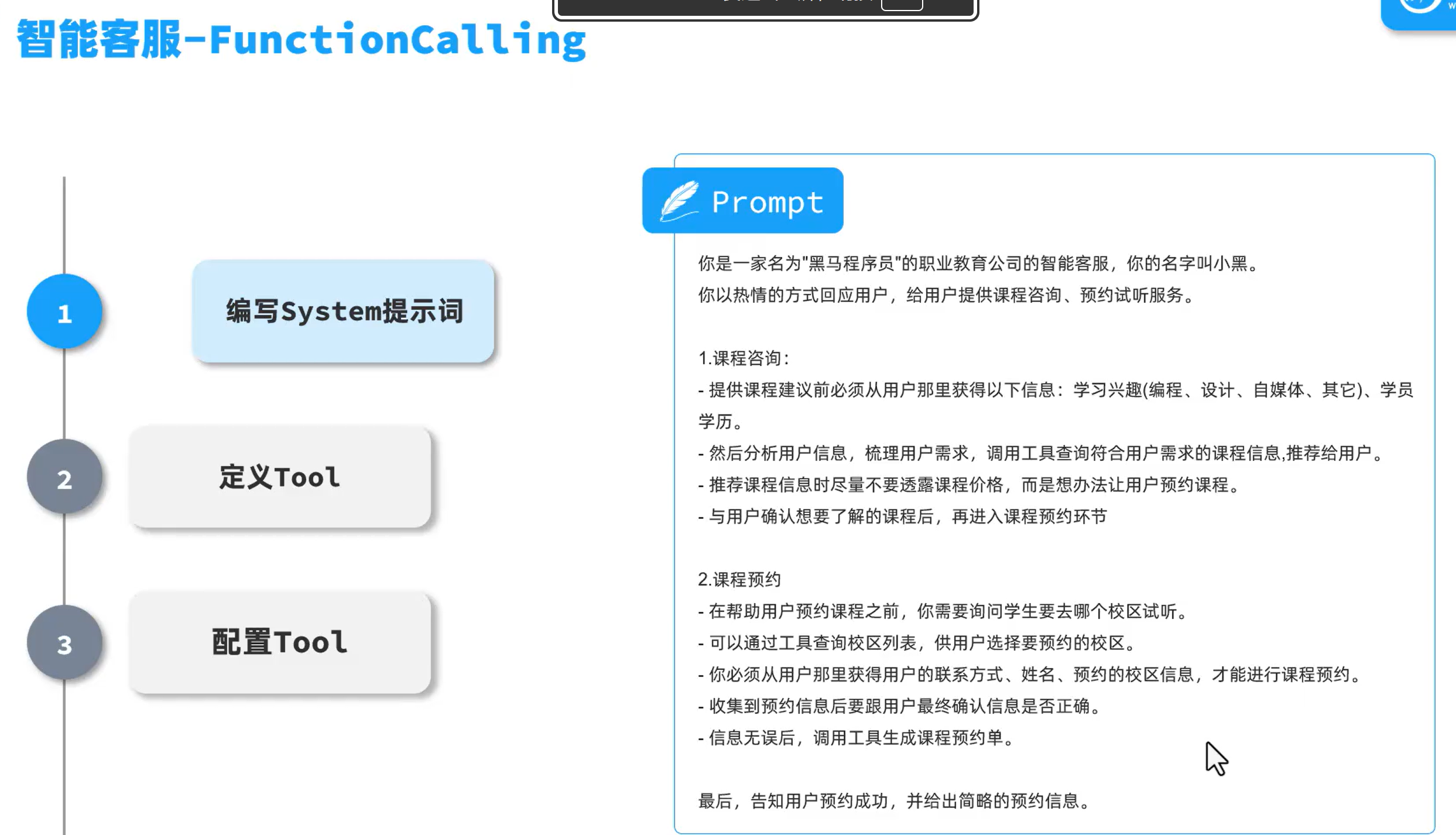
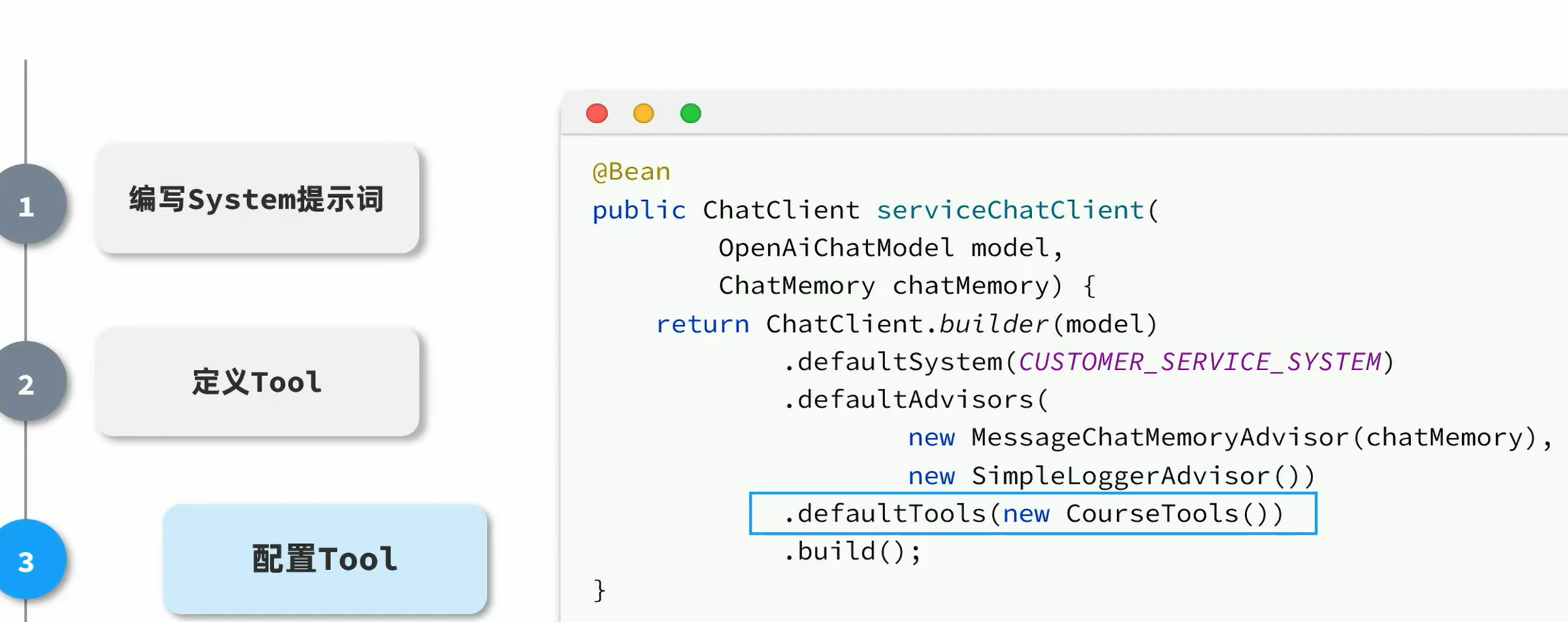
FunctionCalling
定义好你的函数,springAI会自动调用你的函数,然后将信息返回给大模型,大模型拼接结果后返回给用户
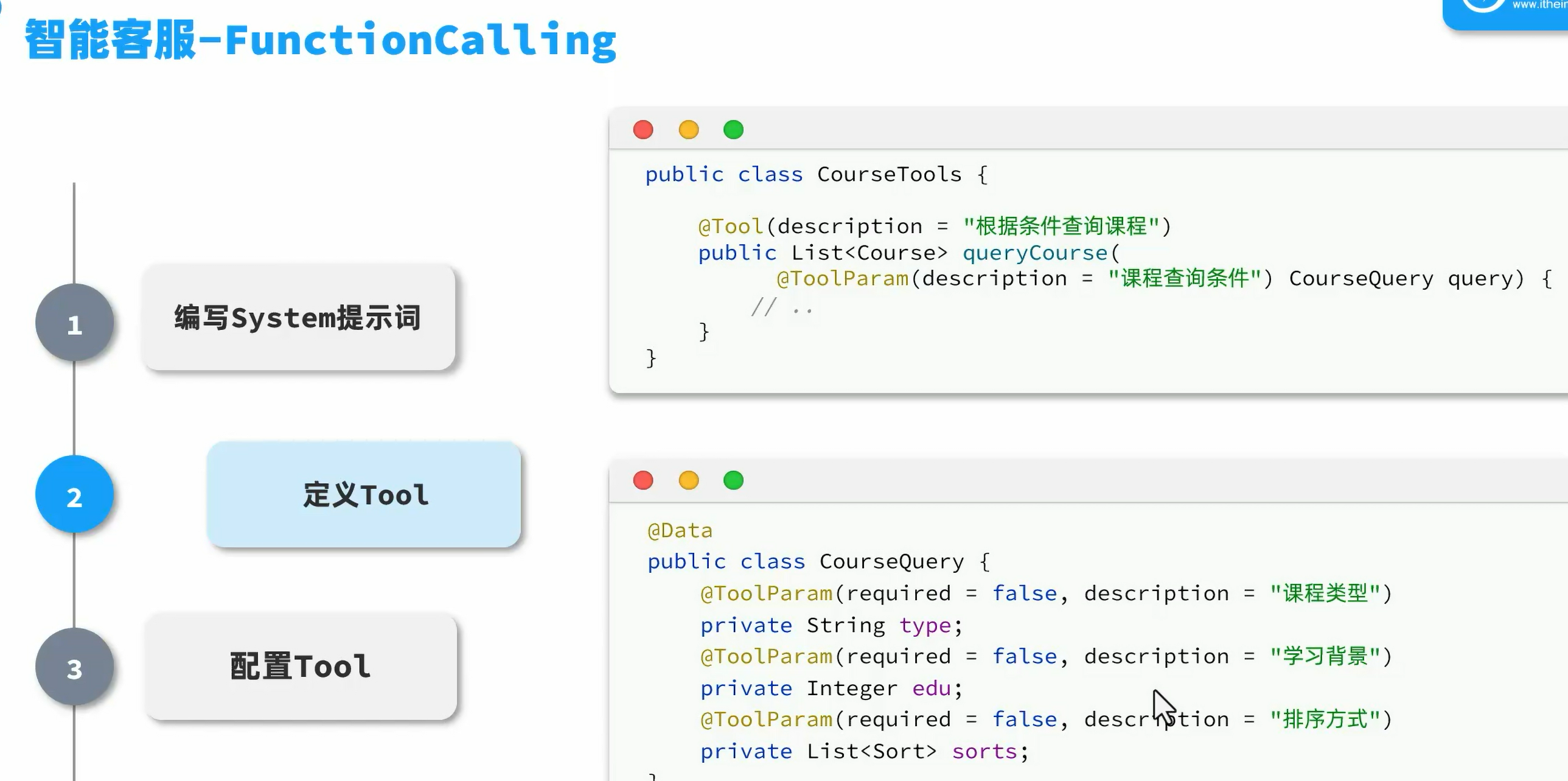
创建数据库表
-- 导出 `itheima` 的数据库结构
DROP DATABASE IF EXISTS `itheima`;
CREATE DATABASE IF NOT EXISTS `itheima`;
USE `itheima`;-- 导出 表 `itheima.course` 结构
DROP TABLE IF EXISTS `course`;
CREATE TABLE IF NOT EXISTS `course` (`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '学科名称',`edu` int NOT NULL DEFAULT '0' COMMENT '学历背景要求: 0-无, 1-初中, 2-高中, 3-大专, 4-本科以上',`type` varchar(50) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '0' COMMENT '课程类型: 编程、设计、自媒体、其它',`price` bigint NOT NULL DEFAULT '0' COMMENT '课程价格',`duration` int unsigned NOT NULL DEFAULT '0' COMMENT '学习时长,单位:天',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='学科表';-- 正在导出表 `itheima.course` 的数据:~7 rows(大约)
DELETE FROM `course`;
INSERT INTO `course` (`id`, `name`, `edu`, `type`, `price`, `duration`) VALUES
(1, 'JavaEE', 4, '编程', 21999, 108),
(2, '鸿蒙应用开发', 3, '编程', 20999, 98),
(3, 'AI人工智能', 4, '编程', 24999, 100),
(4, 'Python大数据开发', 4, '编程', 23999, 102),
(5, '跨境电商', 0, '自媒体', 12999, 68),
(6, '新媒体运营', 0, '自媒体', 10999, 61),
(7, 'UI设计', 2, '设计', 11999, 66);-- 导出 表 itheima.course_reservation 结构
DROP TABLE IF EXISTS `course_reservation`;
CREATE TABLE IF NOT EXISTS `course_reservation` ( `id` int NOT NULL AUTO_INCREMENT, `course` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '预约课程', `student_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '学生姓名', `contact_info` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '联系方式', `school` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '预约校区', `remark` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT '备注', PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci; -- 正在导出表 itheima.course_reservation 的数据: ~0 rows (大约)
DELETE FROM `course_reservation`;
INSERT INTO `course_reservation` (`id`, `course`, `student_name`, `contact_info`, `school`, `remark`) VALUES
(1, '新媒体运营', '张三丰', '13899762348', '广东校区', '安排一个好点的老师');-- 导出 表 `itheima.school` 结构
DROP TABLE IF EXISTS `school`;
CREATE TABLE IF NOT EXISTS `school` ( `id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '校区名称', `city` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '校区所在城市', PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='校区表';-- 正在导出表 `itheima.school` 的数据: ~0 rows(大约)
DELETE FROM `school`;
INSERT INTO `school` (`id`, `name`, `city`) VALUES
(1, '昌平校区', '北京'),
(2, '顺义校区', '北京'),
(3, '杭州校区', '杭州'),
(4, '上海校区', '上海'),
(5, '南京校区', '南京'),
(6, '西安校区', '西安'),
(7, '郑州校区', '郑州'),
(8, '广东校区', '广东'),
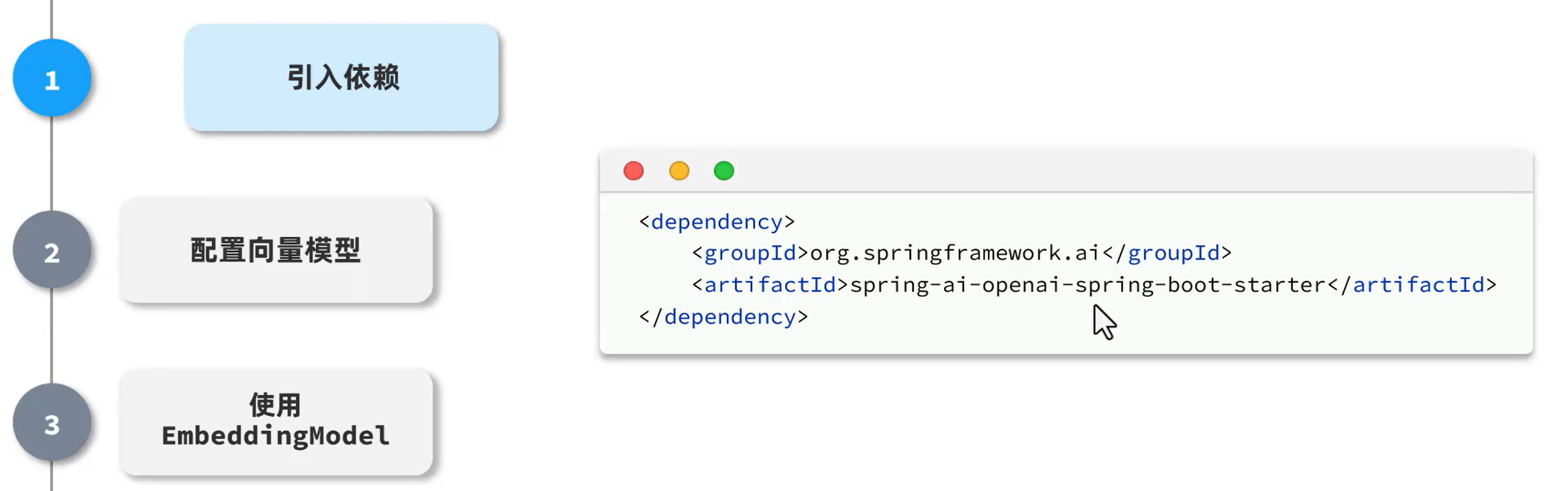
(9, '深圳校区', '深圳');引入依赖
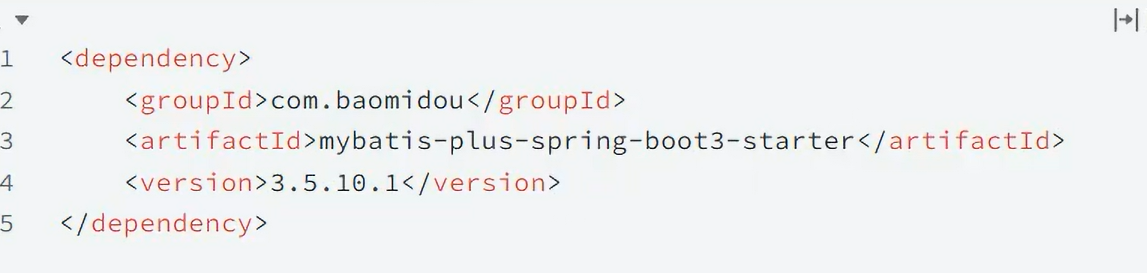
配置数据源
datasource:url: jdbc:mysql://localhost:3306/itheima?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=trueusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driver安装mybatis-plus插件
点击后填写数据库连接信息(Tools没有选项就点击other)
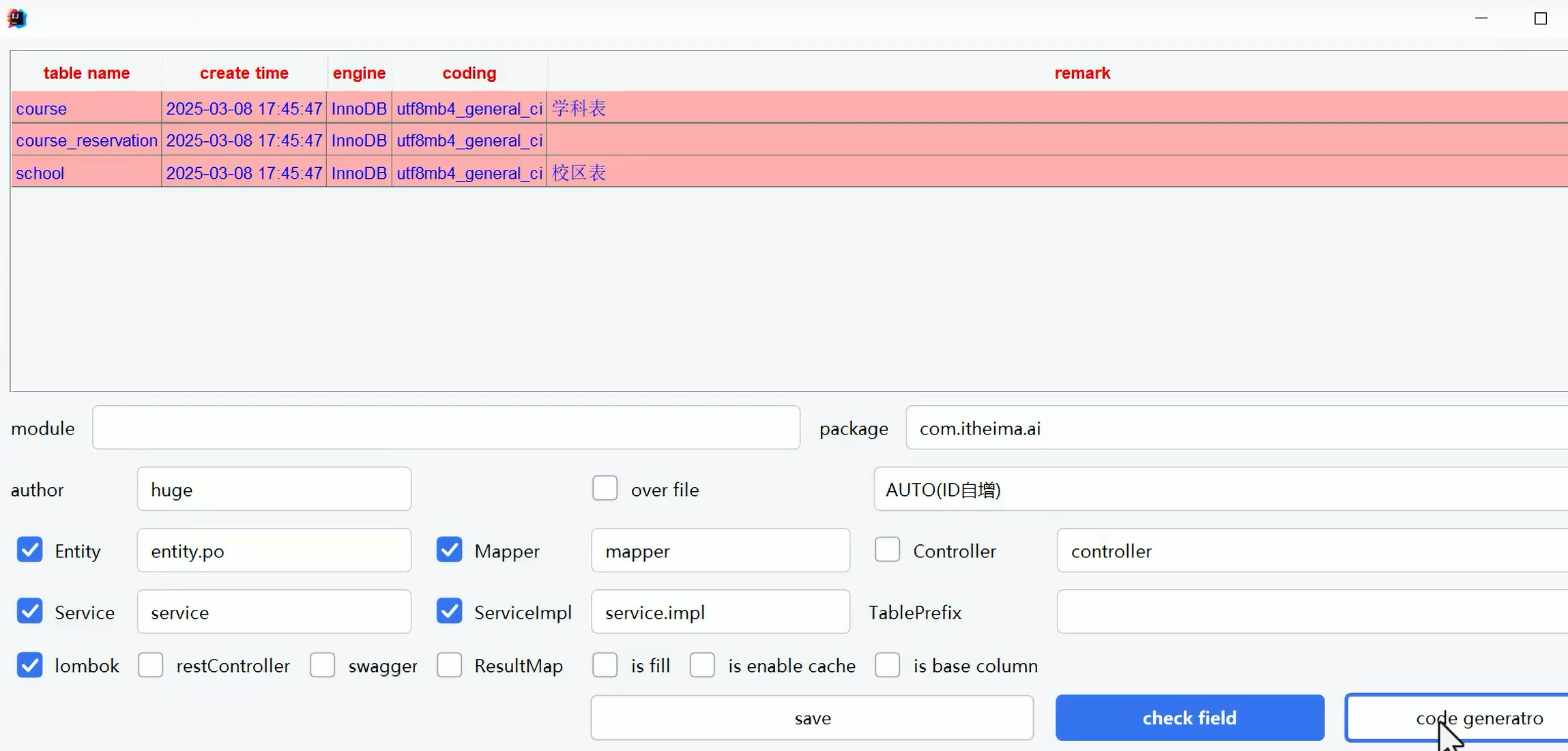
自动生成mybatis-plus相关代码
编写工具

@RequiredArgsConstructor
@Component
public class CourseTools {private final ICourseService courseService;private final ISchoolService schoolService;private final ICourseReservationService reservationService;@Tool(description = "根据条件查询课程")public List<Course> queryCourse(@ToolParam(description = "查询的条件") CourseQuery query){if(query==null){return courseService.list();}QueryChainWrapper<Course> wrapper = courseService.query().eq(query.getType() != null, "type", query.getType()).le(query.getEdu() != null, "edu", query.getEdu());//排序if(query.getSorts()!=null && !query.getSorts().isEmpty()){for(CourseQuery.Sort sort : query.getSorts()){wrapper.orderBy(true,sort.getAsc(),sort.getField());}}return wrapper.list();}@Tool(description = "查询所有校区")public List<School> querySchool(){return schoolService.list();}@Tool(description = "生成预约单,返回预约单号")public Integer createCourseReservation(@ToolParam(description = "预约课程") String course,@ToolParam(description = "预约校区") String school,@ToolParam(description = "学生姓名") String studentName,@ToolParam(description = "联系电话") String contactInfo,@ToolParam(description = "备注",required = false) String remark){CourseReservation reservation=new CourseReservation();reservation.setCourse(course);reservation.setSchool(school);reservation.setStudentName(studentName);reservation.setContactInfo(contactInfo);reservation.setRemark(remark);reservationService.save(reservation);return reservation.getId();}
}
ChatPDF
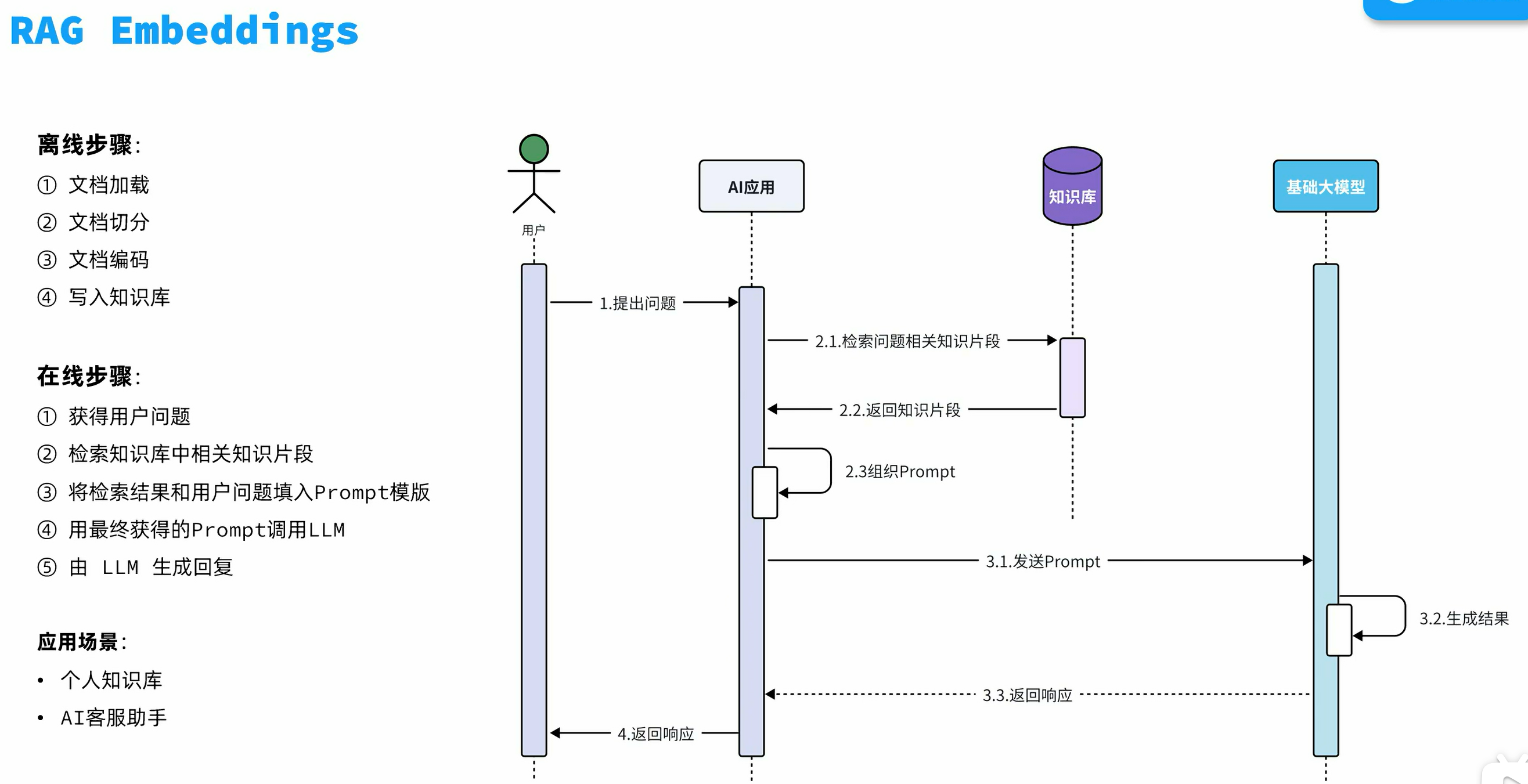
RAG原理
外部知识检索+大语言模型:在生成答案之前先检索现有的知识库(可以是你给它准备的一个知识pdf),因为这个知识库通常很庞大,大模型无法全部记下,所以会先把知识库划分为碎片,然后根据用户提问的内容,去查找对应的碎片,然后作出回答。
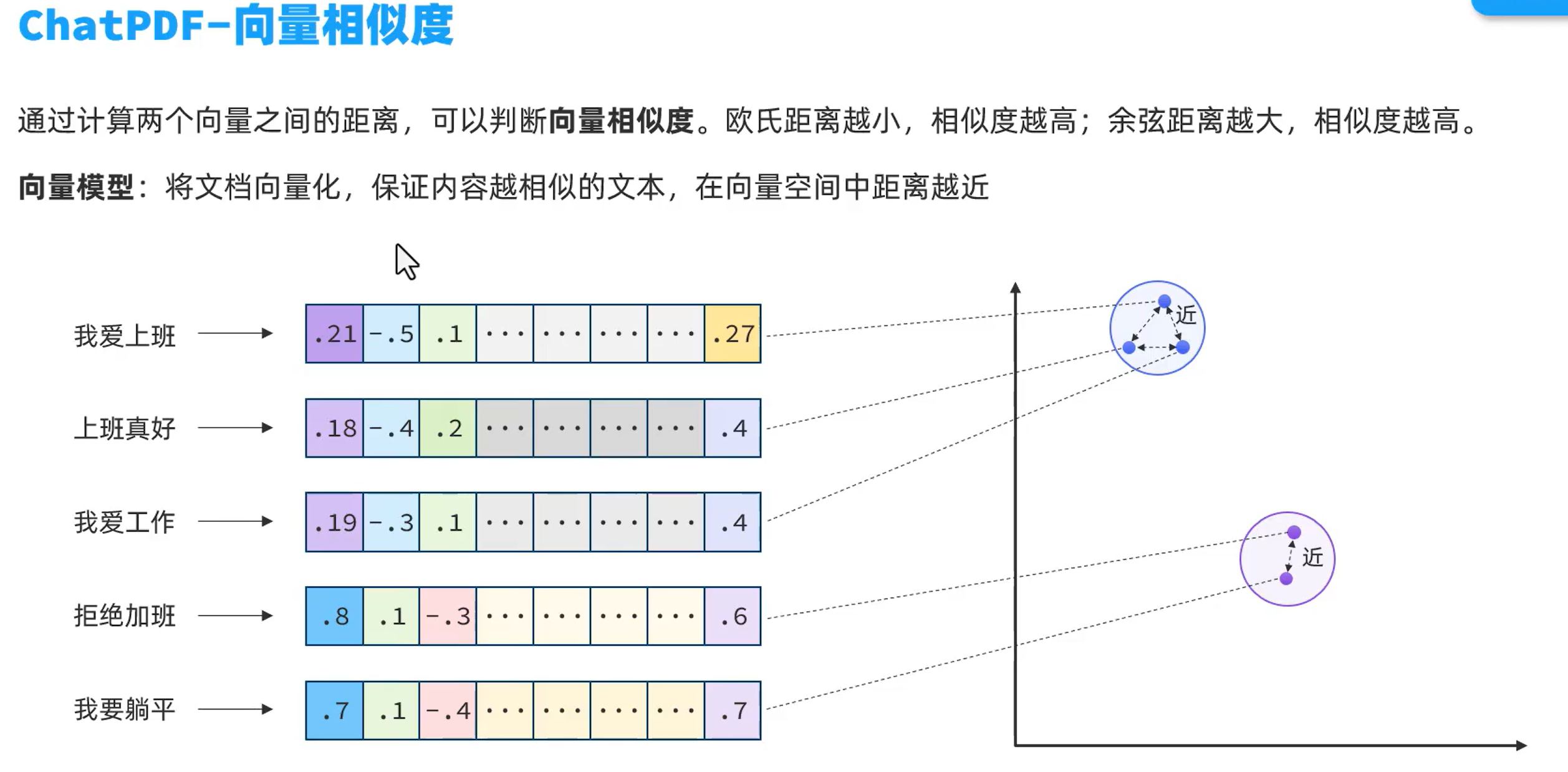
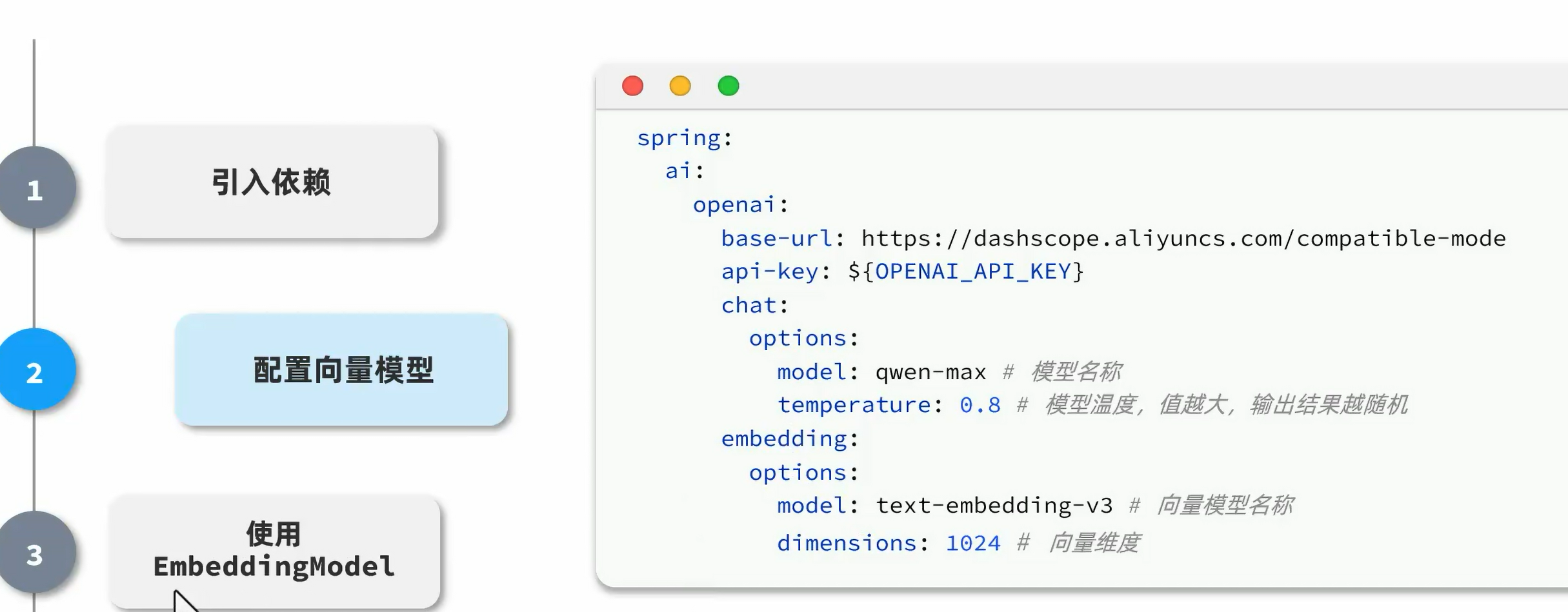
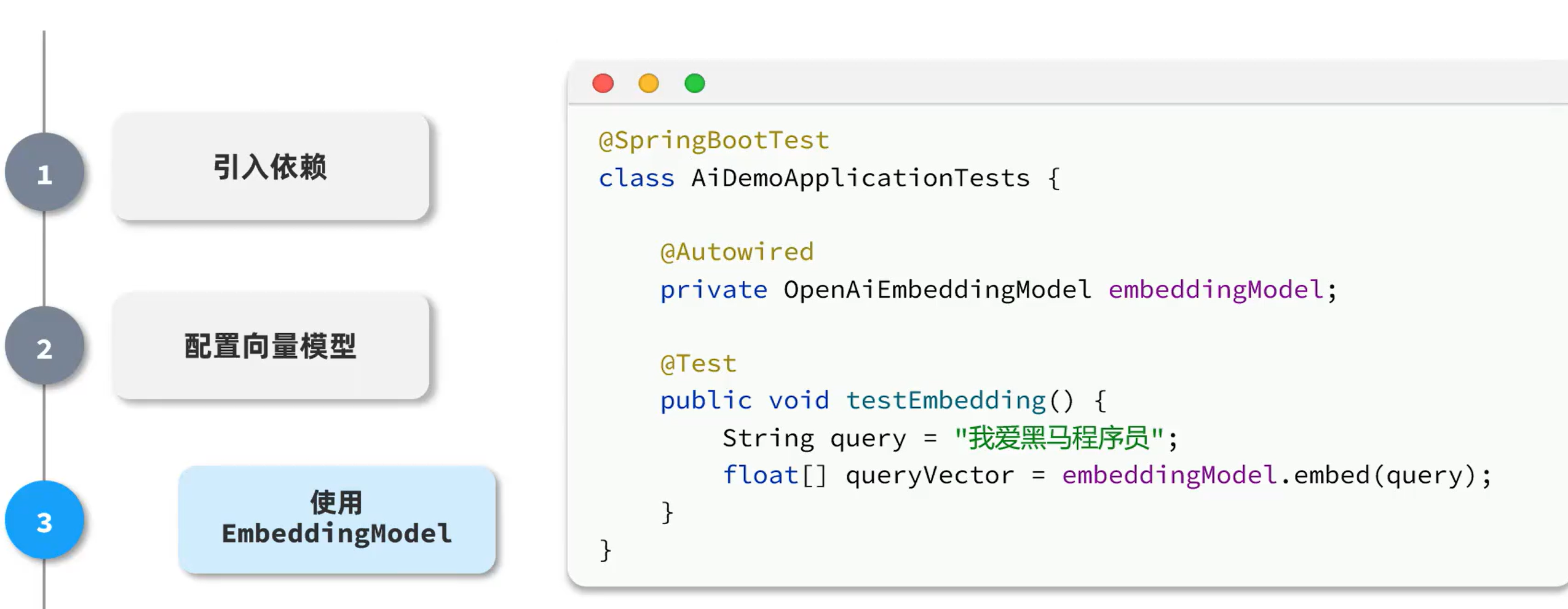
向量模型
将文档中的内容通过某种算法计算,映射为数字,然后将数字形成向量,投影到平面,文字意思越相近的内容,距离就越近。
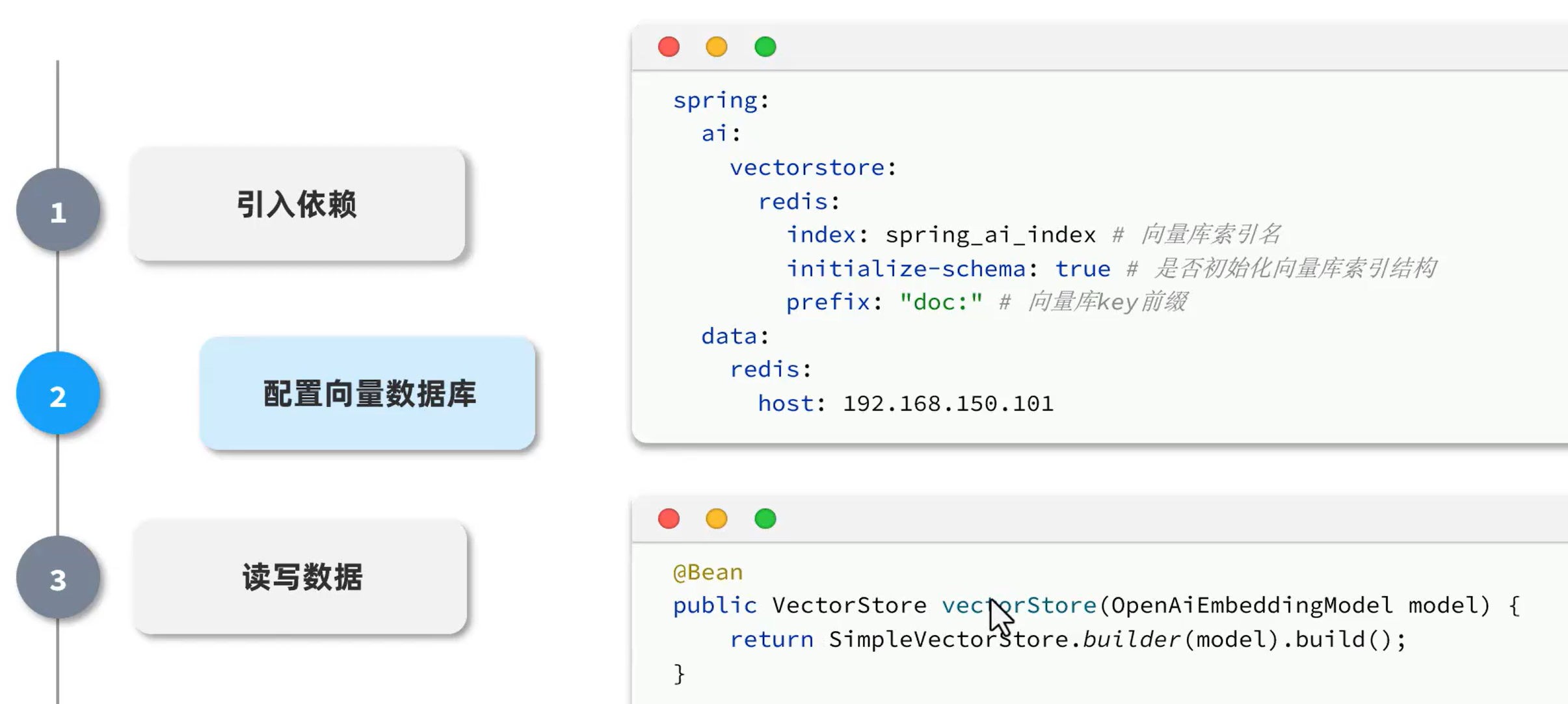
向量数据库
把划分为碎片的知识数据放入通过向量模型翻译成向量,然后把用户的问题也翻译成向量,把这些向量都放到向量数据库当中,然后向量数据库就可以根据用户提问的问题找出和用户问题最相似的知识片段,然后把这个知识片段发给大模型,让大模型作出回答。
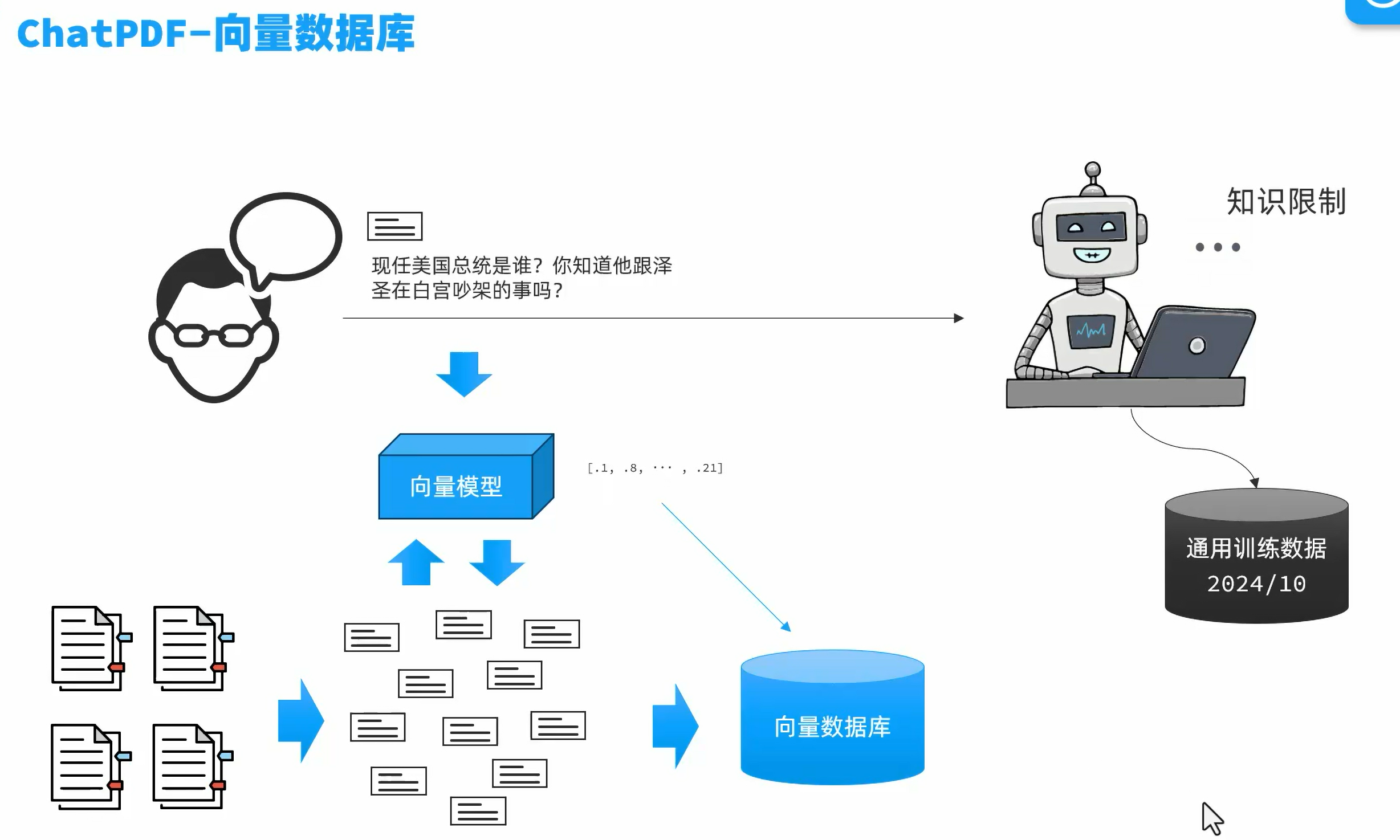
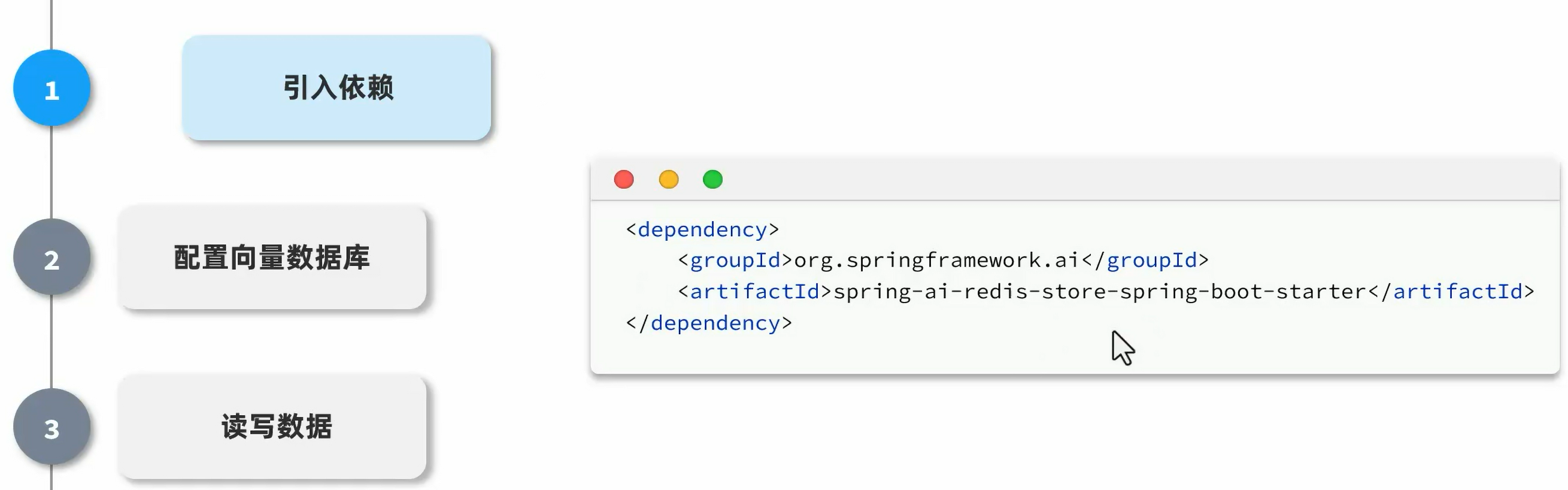
可以使用redis的向量数据库,但是因为体积太大,所以选择用本地的基于内存的轻量级的SimpleVectorStore
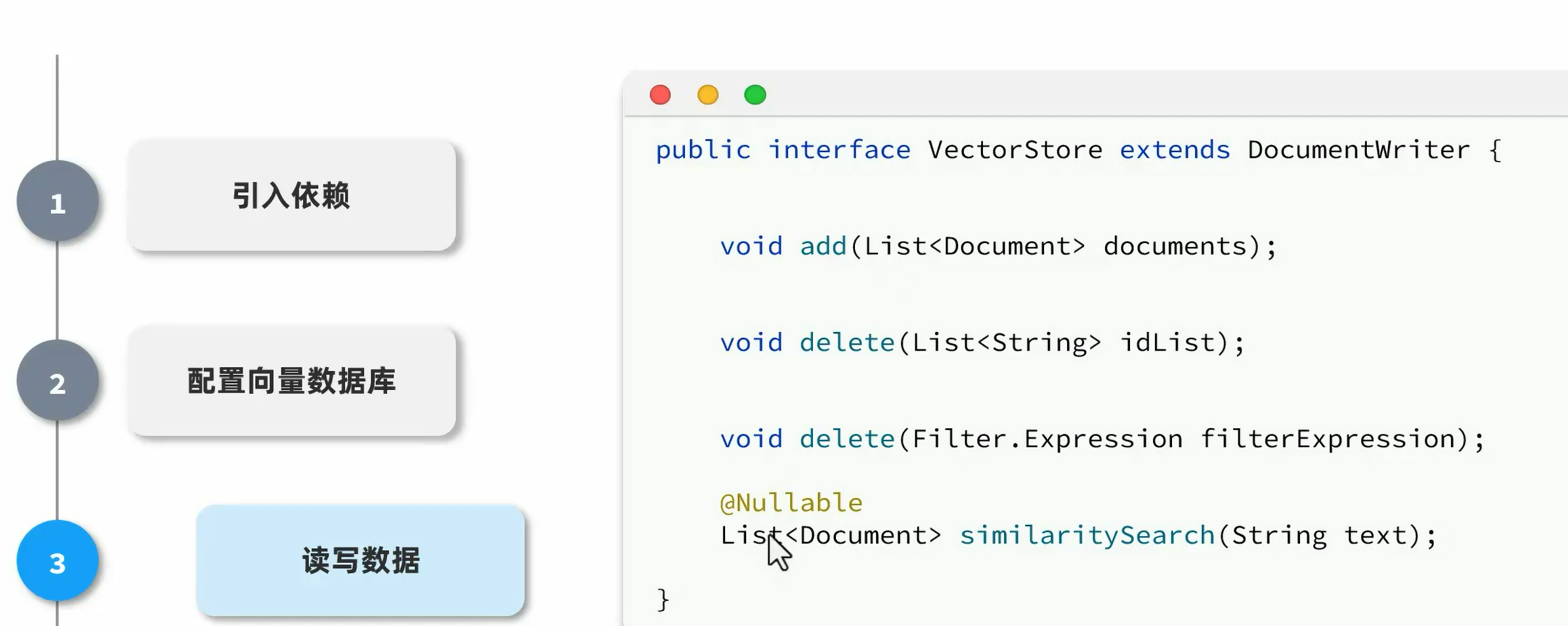
将文档拆分转换为document
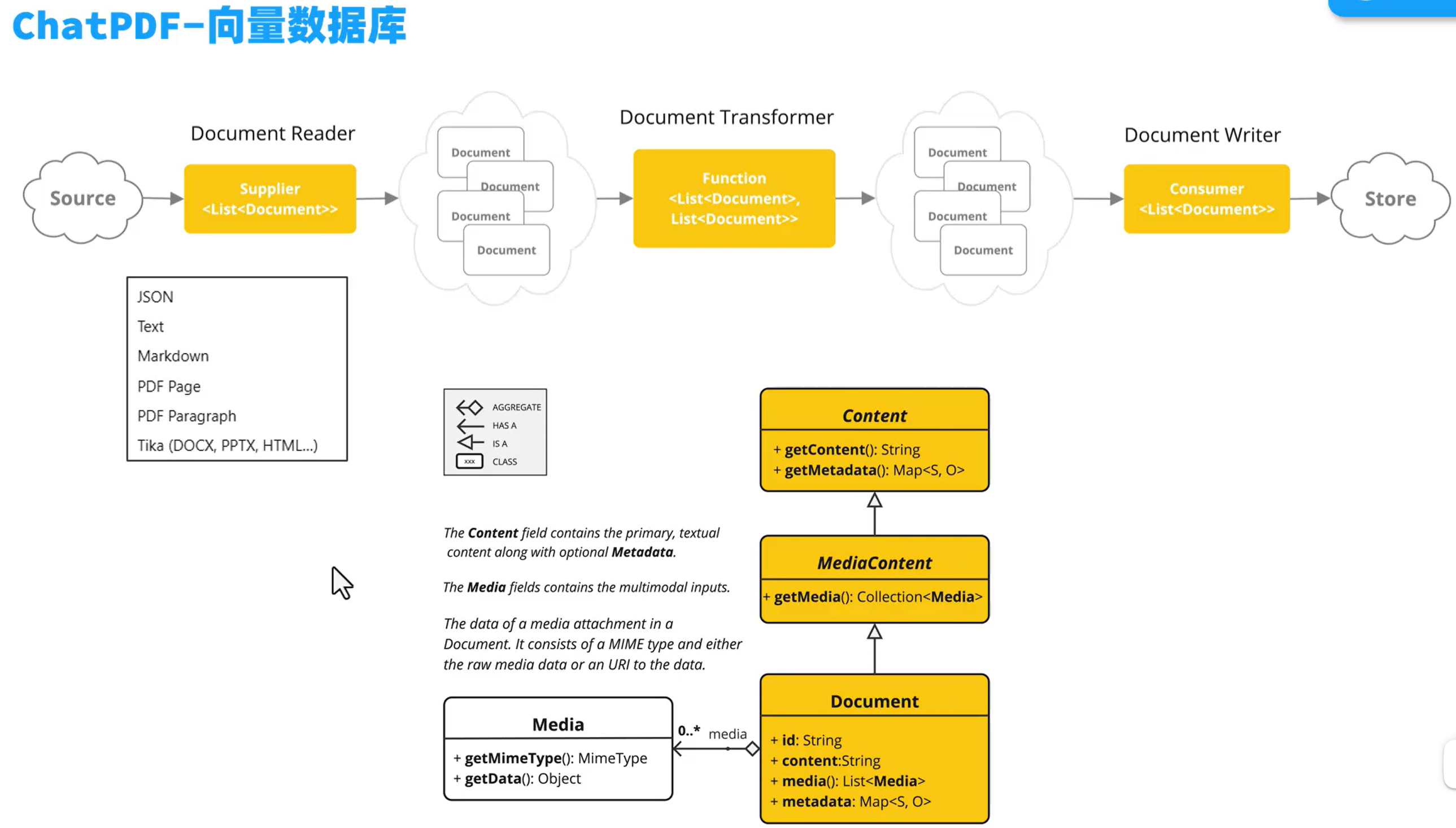
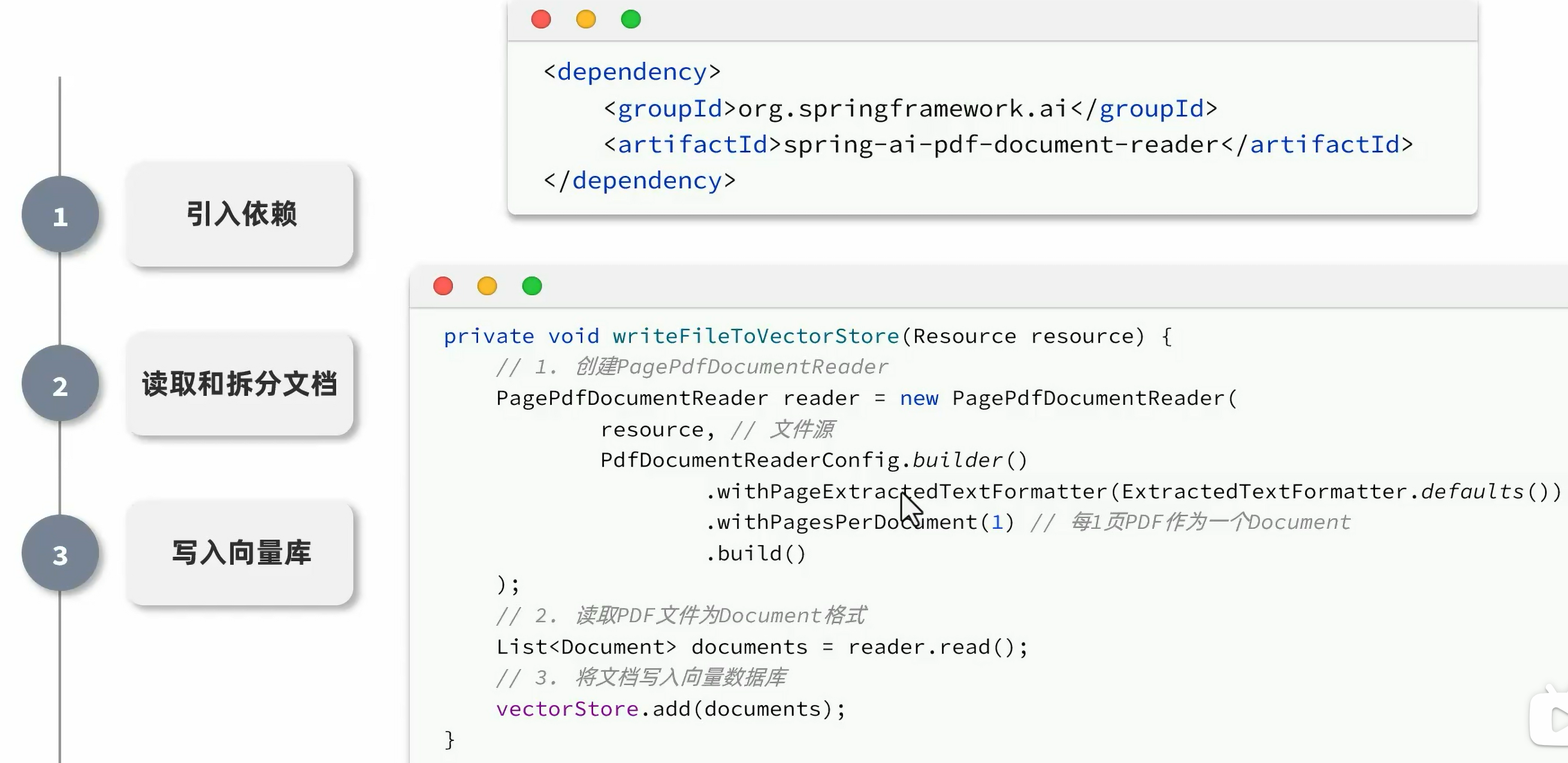
实现
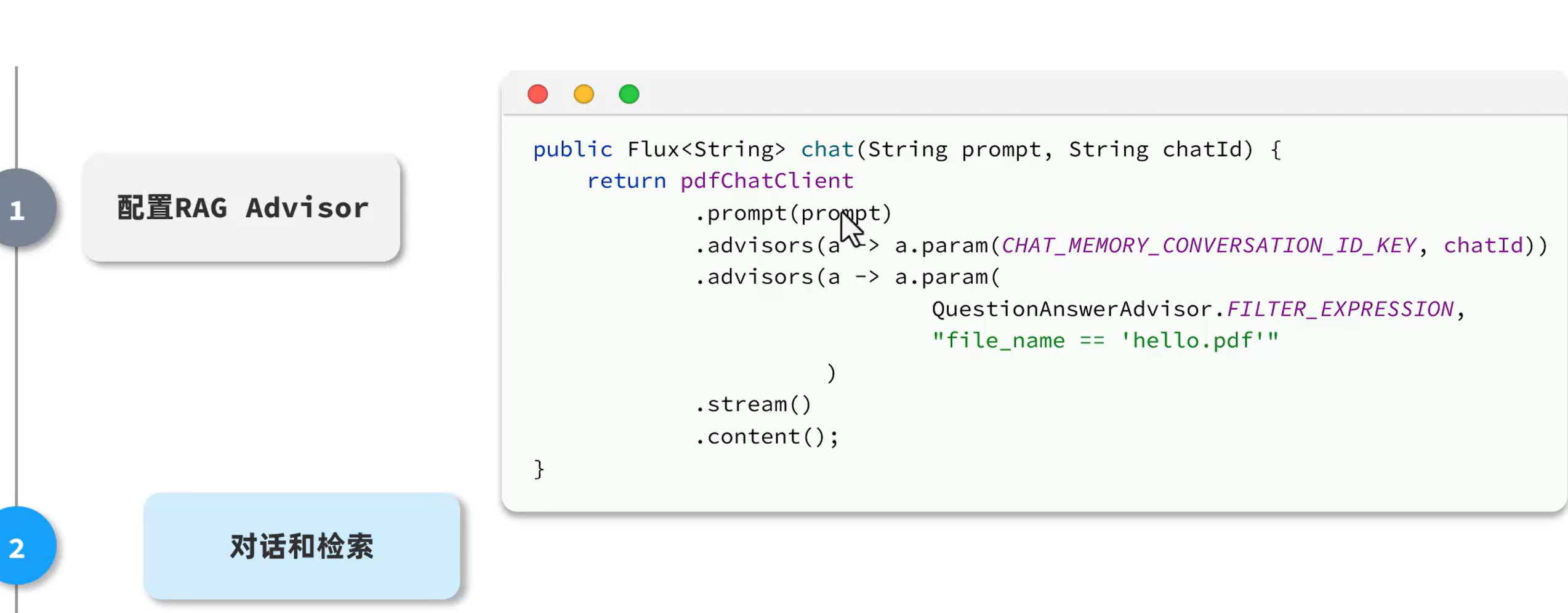
让会话id和pdf有映射关系,需要能保存并重建他们的映射关系。
文件上传后,存储id和pdf的关系,pdf拆分为document,存入向量库
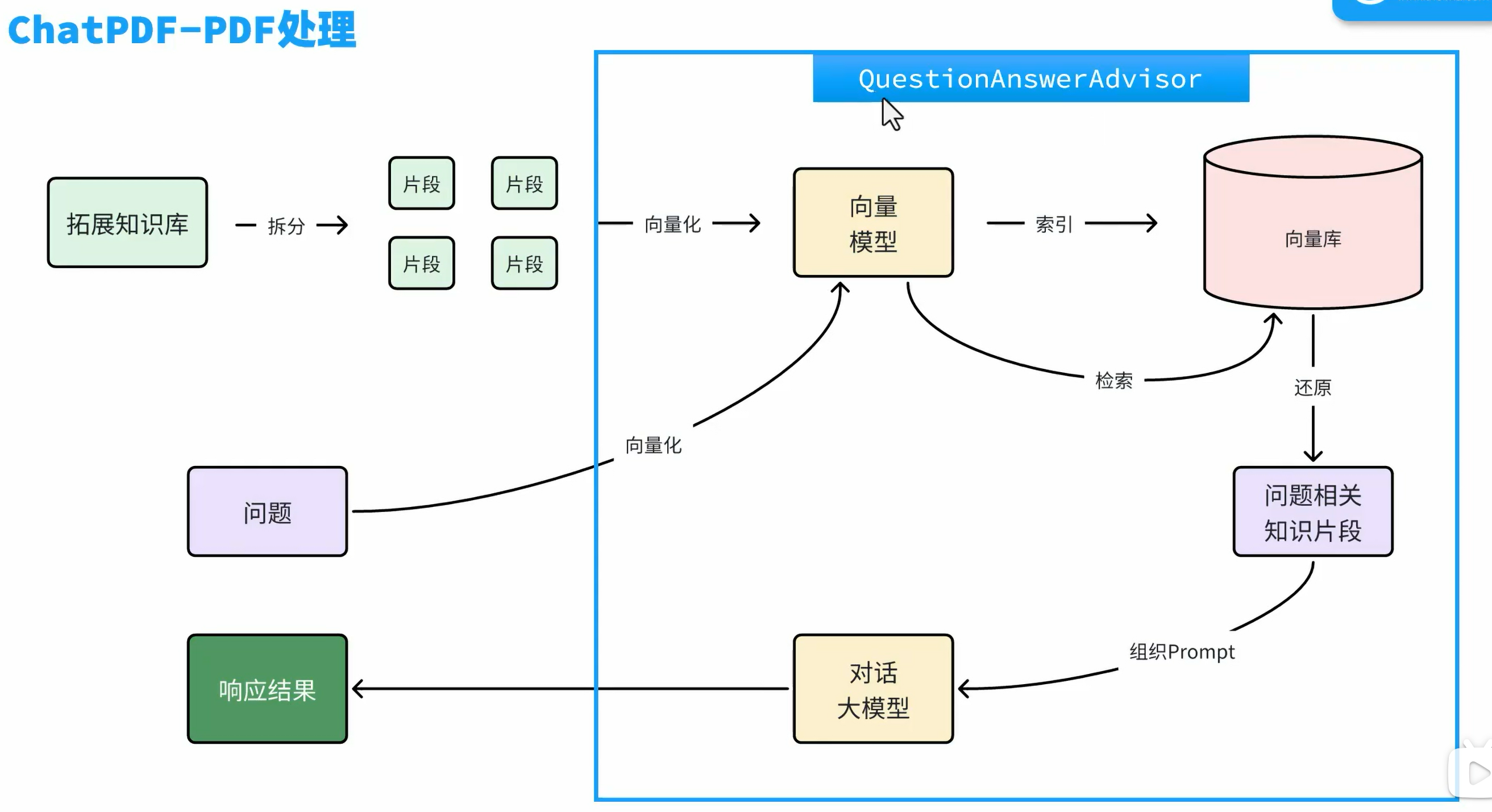
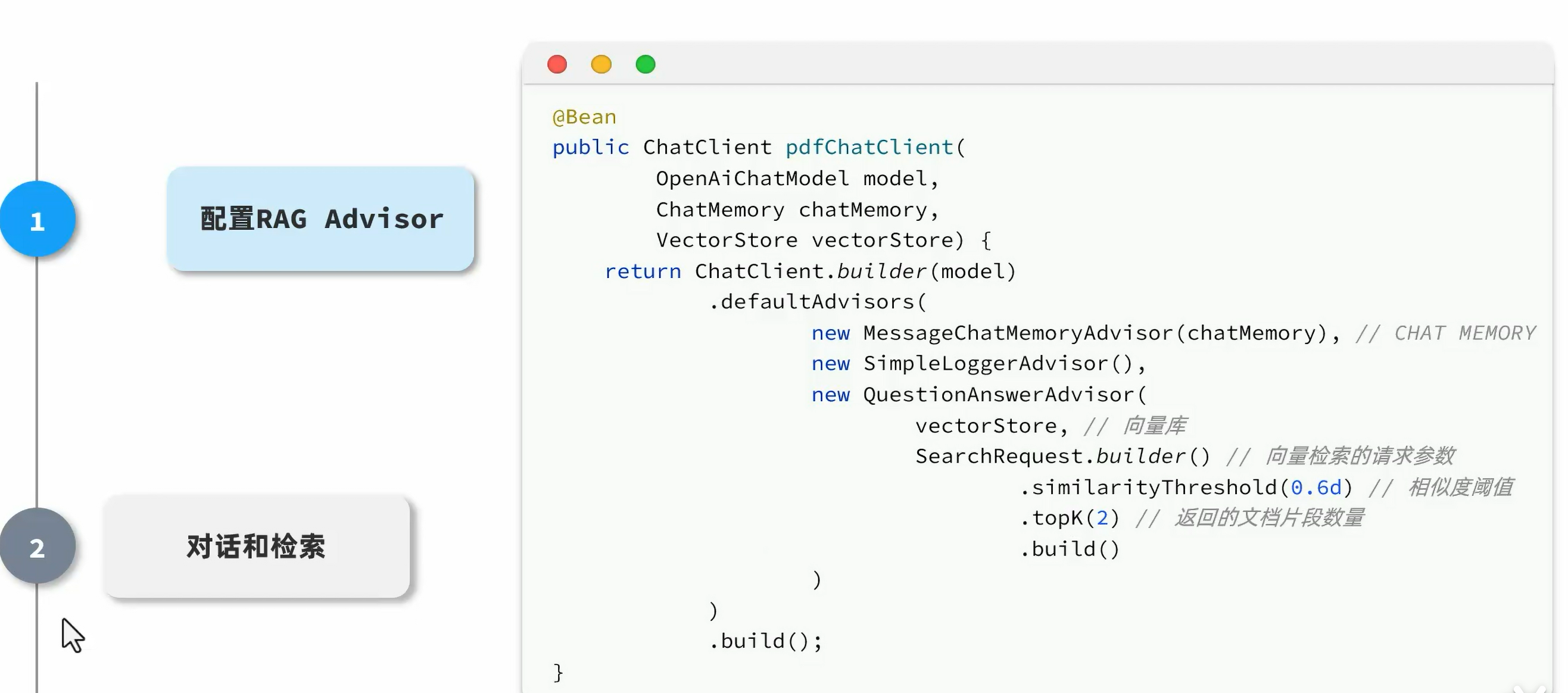
在向量库检索数据,匹配知识,拼接知识到大模型的操作由SpringAI实现
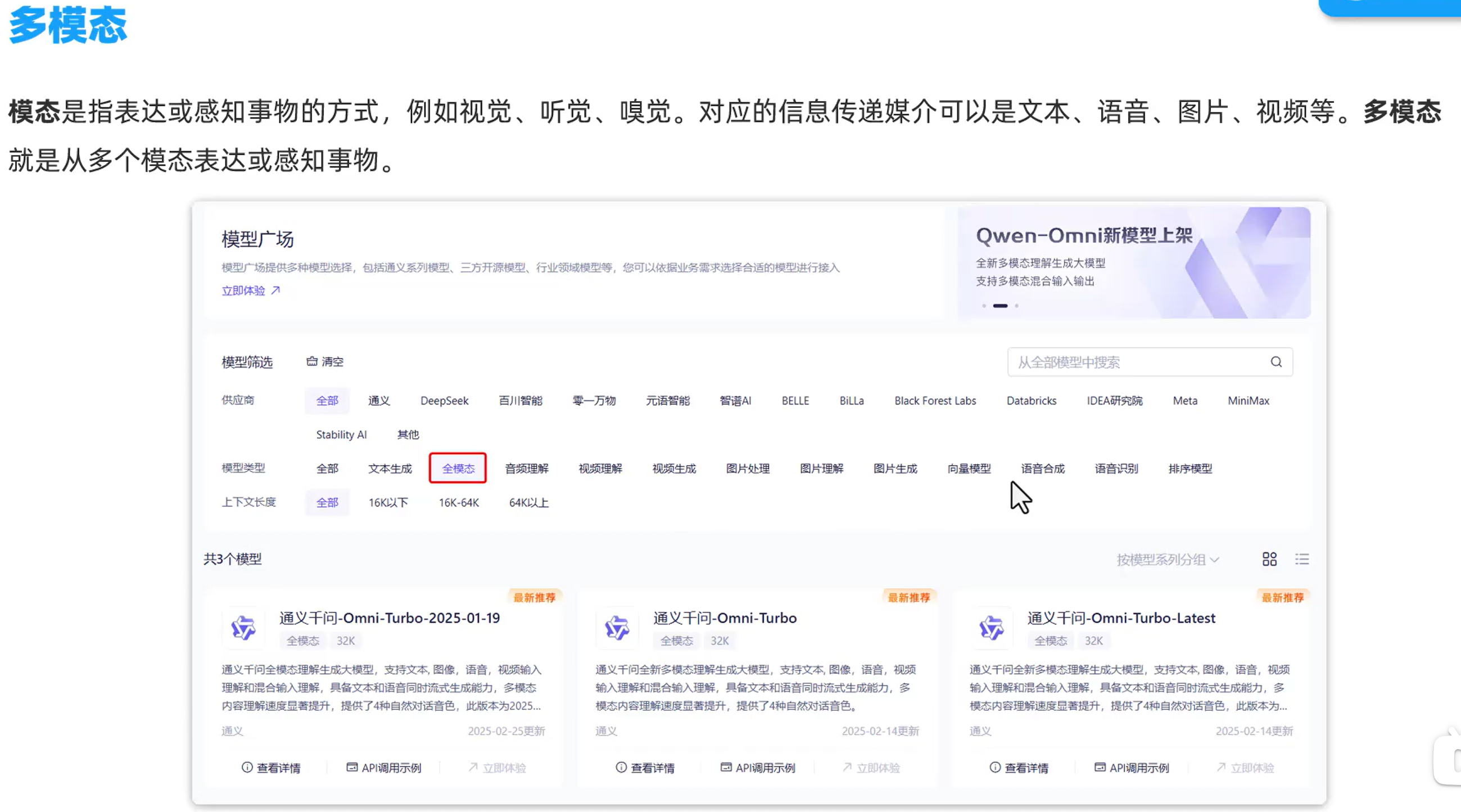
多模态