MongoDB-基本介绍(一)基本概念、特点、适用场景、技术选型

MongoDB基本介绍
- MongoDB是一款开源的文档型NoSQL数据库,由C++编写
- MongoDB使用JSON-like的二进制文档格式(BSON),支持多种复杂数据结构,也可以进行数组、嵌套之类的操作
MongoDB特点
优点
-
无模式/动态数据结构模型
- MongoDB面向文档存储,允许嵌套文档和数组,并且不需要像关系型数据库预定义表结构Schema,更适合复杂、灵活多变的数据结构
-
动态DDL
- 动态 DDL能力,没有强Schema约束,支持快速迭代
-
强大性能
- MongoDB处理大量写和高并发查询时表现出色
- 通过
分片、内存映射文件、高效索引、WiredTiger存储引擎,提供了数据的快速读写能力
-
易于扩展
- MongoDB支持自动分片(
Sharding),可以轻松在多个服务器间分布数据,实现水平扩展。对于需要处理大规模数据和高并发请求时非常重要。
- MongoDB支持自动分片(
-
丰富的查询语言
- MongoDB的查询语言(
MQL)支持丰富的查询操作,包括文本搜索、聚合操作、地理位置搜索等,可以灵活的进行数据操作和分析
- MongoDB的查询语言(
-
与主流开发框架的良好集成
- MongoDB与许多现代开发框架(如
Node.js、Express等)有良好的集成,特别适合全栈开发。
- MongoDB与许多现代开发框架(如
缺点
-
复杂事务支持
- 多文档事务支持:虽然MongoDB在
4.0版本开始支持多文档事务,但在4.0之前只支持单文档事务。即使现在,多文档事务的性能和稳定性可能不如传统的关系型数据库。 - 性能开销:同时,使用事务会带来性能开销,并且在高并发场景下,事务可能会成为瓶颈。MongoDB的多文档事务性能开销显著高于传统关系型数据库(如
PostgreSQL)。在高并发场景下,大量使用事务会严重影响吞吐量。 - 最佳实践限制:官方建议事务执行时间尽量短(通常不超过
1000毫秒),否则会拖累整个系统。这限制了在复杂业务流程中的使用。 - 结论:MongoDB比起关系型数据库而言,事务处理会更弱一些。如果核心业务是大量、长耗时的复杂事务,MongoDB是“能用但不好用”,关系型数据库是更稳妥的选择。
- 多文档事务支持:虽然MongoDB在
-
关联查询性能的短板
$lookup操作性能远不及关系型数据库的JOIN$lookup在内存中进行连接,没有类似关系型数据库为JOIN做优化的哈希连接等算法支持$lookup只支持基本的左外连接,不支持内连接,右外连接等复杂连接类型- 在分布式环境分片集群下,如果参与
$lookup的集合分布在不同的分片上,性能会进一步下降 - 结论:如果查询模式以多表深度关联为主,MongoDB会非常吃力
-
内存依赖
- MongoDB是
内存数据库,对内存依赖极高,内存不足会导致出现性能瓶颈
- MongoDB是
-
查询语言的生态
- 尽管主流BI工具(如Tableau)都提供了MongoDB连接器,但其兼容性和性能通常不如对SQL数据库的支持。很多企业级报表系统仍深度依赖SQL。
-
安全性问题
- MongoDB早期版本默认不启用身份认证,导致了许多安全事件。新版本已经改进,生产环境强制要求配置安全设置。
MongoDB基本概念
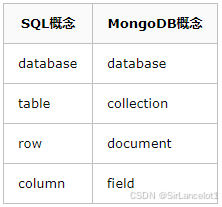
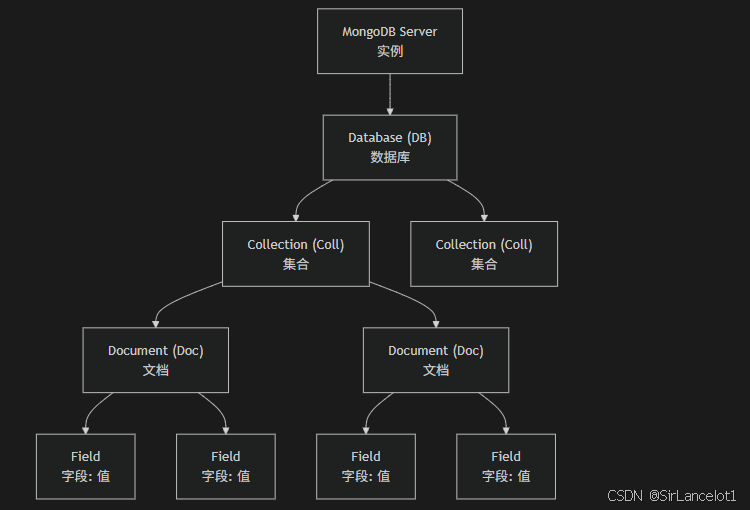
database
-
是什么?
- 数据库是 MongoDB 中的最顶层组织单元,是一个物理容器,用于存储一组相关的集合。一个 MongoDB 实例(例如一个运行中的 mongod 进程)可以承载多个独立的数据库。
-
作用
- 实现数据的逻辑隔离。例如,你可以为一个电商应用创建 shop_db,为一个博客系统创建 blog_db,它们运行在同一个 MongoDB 服务器上但互不干扰。
-
系统默认数据库:
-
admin: 根数据库。用户添加到这个数据库时,自动继承所有数据库的权限。一些服务器级别的命令(如关闭服务)也必须在这个库下执行。
-
local: 用于存储特定单个服务器的数据(如副本集的配置信息)。这个数据库的数据不会被复制到其他节点。
-
config: 当 MongoDB 使用分片时,这个数据库用于存储分片的相关元信息。
-
collection
-
是什么?
- 一组Document文档的集合,相当于关系型数据库的表
-
作用
- 动态DDL,不需要预先定义严格的表结构,同一个Collection内的Document文档可以有不同的字段
document
-
是什么?
- 数据的基本单元,相当于关系型数据库的一行数据
- 文档是一种类似于 JSON 的 BSON 结构。
-
数据格式
- BSON 是 Binary JSON 的缩写。它是一种二进制编码的序列化格式,在保留 JSON 的灵活性的基础上,提供了更快的遍历速度和更丰富的数据类型(如 Date, Binary Data, ObjectId 等)。
{ //示例"_id": ObjectId("507f1f77bcf86cd799439011"), // 1. ObjectId - 12字节的唯一标识符"name": "Charlie","address": { // `address` 字段的值是一个内嵌文档"street": "123 Main St","city": "Springfield","zip": "12345"} }
field
-
是什么?
- Document文档中的一个键值对,相当于关系型数据库的列、字段
-
值的类型
- 字段的值可以是多种 BSON 数据类型,这使得文档结构非常丰富和强大:
- 基本类型:String, Number (整数、浮点数), Boolean, Null, Date, Timestamp。
- 复杂类型:
- Array(数组): { tags: [“mongodb”, “database”, “nosql”] }
- Embedded Document(内嵌文档): 一个文档可以作为另一个文档中某个字段的值。这是实现 非规范化 数据模型、避免多表关联的核心手段。
- 字段的值可以是多种 BSON 数据类型,这使得文档结构非常丰富和强大:
MongoDB使用场景选择
适用MongoDB场景
-
需求多变,数据结构不固定的场景
- 内容管理系统:文章、评论、标签、分类等。这些内容结构多样,变化频繁
- 电商平台:产品目录。不同品类的商品属性差异巨大(比如手机和衣服的属性完全不同),非常适合用文档模型来存储。
-
大数据量,高并发读写,高性能查询的场景
- 物联网IOT:来自成千上万传感器的数据,数据量大,写入频繁,数据结构可能相似但又不完全相同。
- 社交网络:用户档案、动态消息、用户生成的内容。数据结构灵活,读写量巨大。
- 实时分析:日志、点击流分析。可以快速写入海量数据,并利用聚合框架进行实时分析。
-
缓存,实时数据储存
- 实时分析:日志、点击流分析。可以快速写入海量数据,并利用聚合框架进行实时分析。
-
需要使用地理位置的场景
- 部分涉及到地理位置的移动互联网应用
不适用MongoDB的场景
-
需要复杂多表事务和强一致性的场景
-
银行交易
-
财务系统
-
库存管理系统等要求严格的 ACID 事务。
-
为什么不合适:尽管 MongoDB 从 4.0 版本开始支持多文档事务,但其性能和易用性仍然不如成熟的关系型数据库。如果你的业务核心是大量、复杂的跨文档/跨集合事务,关系型数据库是更稳妥的选择。
-
-
数据结构稳定,关系复杂的场景
-
企业内部的 ERP、CRM 系统,数据模型非常稳定,并且实体间存在大量复杂的关系。
-
为什么不合适:虽然 MongoDB 可以使用 $lookup 进行类似 SQL 的 JOIN 操作,但这并非其设计初衷,性能远不如关系型数据库的优化连接。频繁的 $lookup 是反模式的。
-
-
对 SQL 和成熟生态有强依赖的场景
-
需要与大量现有的 BI(商业智能)工具、报表工具集成,或者团队对 SQL 非常精通。
-
为什么不合适:MongoDB 使用自己的查询语言,虽然强大,但生态工具的数量和成熟度仍不及 SQL。让一个 BI 工具连接 MongoDB 可能比连接 MySQL/PostgreSQL 更麻烦。
-
-
对磁盘空间非常敏感的场景
- 嵌入式设备或存储成本极其有限的环境。
- 为什么不合适:由于 BSON 格式存储、预分配空间、索引开销等原因,MongoDB 的磁盘空间利用率通常不如经过良好规范化的关系型数据库。
技术选型:如何决策是否选用MongoDB?
-
数据结构是否频繁变化?数据结构本身是否就是非结构化的?
- 是:建议考虑 MongoDB
- 否:关系型数据库也许更好
-
应用是否需要处理海量数据?并且有需要灵活水平扩展的能力?
- 是:建议考虑 MongoDB
- 否:关系型数据库也许更好
-
大部分查询操作,是否可以在单个“聚合单元(即MongoDB单个文档的概念,或者传统数据库单表)”内完成?不需要频繁跨表连接查询?
- 是:建议考虑 MongoDB
- 否:关系型数据库JOIN查询更好
-
处理的业务是否依赖复杂的事务处理?
- 是:关系型数据库事务处理更好
- 否:建议考虑 MongoDB
-
是否有大量的地理位置查询?
- 是:建议考虑 MongoDB