每天五分钟深度学习:正则化技术解决过拟合(高方差)问题
本文重点
前面课程中我们学习了如何搭建一个良好的神经网络模型,总的来说就是先拟合好训练集,然后在验证集上跑一下,如果效果不好,那么就是高方差的问题,如何解决高方差呢?
解决高方差的两种方法
当算法处于高方差的问题的时候,有两种常用的解决的方式(还有其它的方式,这里先简单的介绍两种),一种方式是准备更多的数据,这张方法是非常的可靠的,但是问题是有些时候我们无法获取足够多的数据,另外一种方式就是正则化。
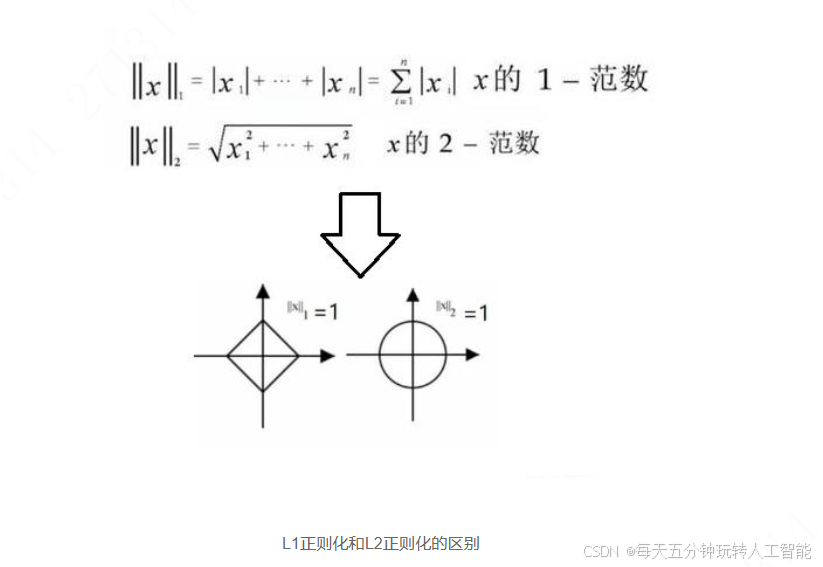
L1正则化和L2正则化
正则化有两种方式,一种方式是L1正则化,另外一种方式是L2正则化,常用L2正则化。
||w||1是L1正则化,||w||2是L2正则化
如果用的是1正则化,最终会是稀疏的,也就是说向量中有很多 0,有人说这样有利于压缩模型,因为集合中参数均为 0,存储模型所占用的内存更少。实际上,虽然1正则化使模型变得稀疏,却没有降低太多存储内存,所以这并不是1正则化的目的,稀疏矩阵的好处就是能够帮助模型找到重要特征,而去掉无用特征或影响甚小的特征。
神经网络中应用正则化
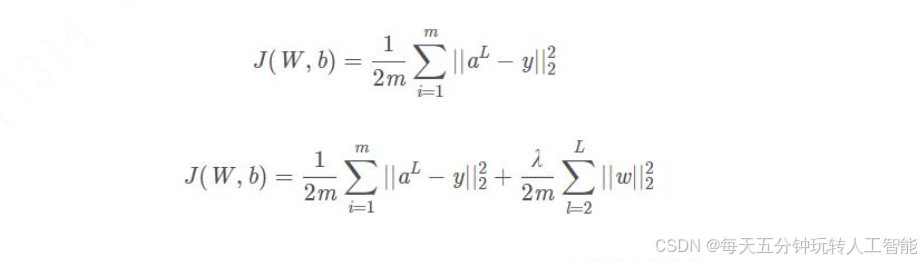
第一个带有不带有正则化