如何基于OneAPI构建langchain RAG系统
langchain是LLM时代广泛使用的agent和rag构建工具。
这里尝试构建基于langchain的RAG系统。
1 OneAPI安装
langchain主要采用openai接口访问大模型,然而面临访问受限的问题。
使用openai接口访问其他大模型,需要大模型厂商提供openai兼容接口,往往面临不可用问题。
OneAPI是LLM OpenAI接口的管理、分发系统,通过标准的OpenAI API访问所有的大模型。
OneAPI(2025.10.10)支持Deepseek、阿里通义、百度千帆、火山豆包、腾讯元宝等大部分LLM。
这里采用docker方式部署One API,命令如下
docker run --name one-api -d --restart always -p 3000:3000 -e TZ=Asia/Shanghai -v /data/apps/llm/oneapi/data/one-api:/data justsong/one-api
并基于OneAPI配置Deepseek R1大模型,具体过程参考
https://blog.csdn.net/liliang199/article/details/151393128
2 langchain安装
这里基于conda python 3.1,假设python环境已经安装。
2.1 安装依赖工具
gcc、g++、rust、pymupdf
conda install -c conda-forge gcc=12 gxx=12
conda install conda-forge::rust
conda install conda-forge::mupdf
conda install conda-forge::pymupdf
2.2 向量库
faiss-cpu, gcc, g++
conda install -c pytorch faiss-cpu
2.3 框架
langchian
pip install --upgrade langchain -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade langchain-openai -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade langchain-community -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade langchain_ollama -i https://pypi.tuna.tsinghua.edu.cn/simple
3 model配置
这里分别配置LLM模型Deepseek r1和向量模型bge-m3。
3.1 LLM模型
在OneAPI配置对Deepseek r1的访问,支持本地以openai接口方式访问。具体配置过程参考
https://blog.csdn.net/liliang199/article/details/151393128
3.2 embedding模型
在OneAPI配置对本地ollama embedding模型的访问,模型为bge-m3
本地采用docker部署ollama,命令如下。
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
具体过程参考 https://blog.csdn.net/liliang199/article/details/151393128
模型pull过程示例如下
ollama pull bge-m3
1.3 OneAPI配置ollama
需要注意的是,OneAPI配置ollama embedding模型时,需要配置proxy代理地址。
OneAPI配置Ollama时默认proxy地址是http://localhost:11334
OneAPI运行在docker 容器,不能通过localhost:11334访问部署在宿主机的ollama服务。
因此,需要将localhost改为宿主机的ip,示例如下
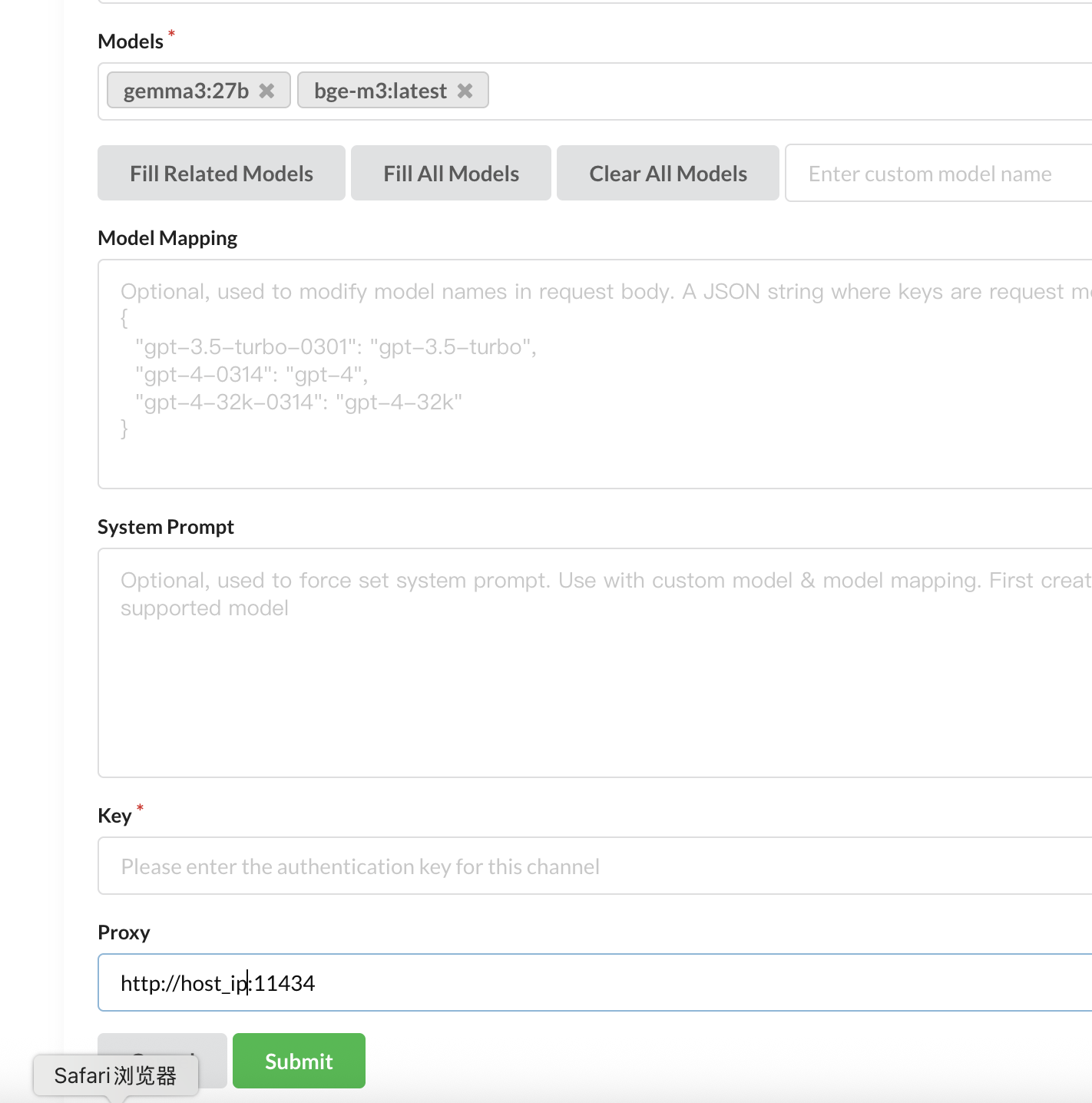
4 运行langchain
基于langchain、ollama、faiss、oneapi构建RAG系统,进行数据导入、向量化、检索生成示例。
测试输入为llama2.pdf,原始链接如下
https://arxiv.org/pdf/2307.09288
4.1 加载文档
输入为"data/llama2.pdf",通过环境变量设置OneAPI的令牌和部署地址,代替OpenAI默认配置。
import os
os.environ['OPENAI_API_KEY'] = "sk-xxxxxxxxxxx" # OneAPI生成的令牌
os.environ['OPENAI_BASE_URL'] = "http://localhost:3000/v1" # OneAPI部署地址from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyMuPDFLoaderfrom dotenv import load_dotenv,find_dotenv
_ = load_dotenv(find_dotenv(),verbose=True)# 加载文档
loader = PyMuPDFLoader("data/llama2.pdf")
pages = loader.load_and_split()# 文档切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=100,length_function=len,add_start_index=True,
)texts = text_splitter.create_documents([page.page_content for page in pages[:4]]
)4.2 RAG向量化
faiss向量化代码如下,注意这里采用OllamaEmbedding,调用ollama的bge-m3向量化。
# RAG向量化
embeddings = OllamaEmbeddings(model="bge-m3")
db = FAISS.from_documents(texts, embeddings)# 检索 top-2 结果
retriever = db.as_retriever(search_kwargs={"k": 2}) 4.3 在线检索
以下是在线检索代码,注意这里采用ChatOpenAI,以OpenAI的方式访问deepseek-r1。
首先,将文本转向量,召回相似的文本片段;
然后,将召回的结果和原始的query输入到大模型,进行总结。
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthroughfrom langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,SystemMessagePromptTemplate,
)
# Prompt模板
template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(model="deepseek-r1")# Chain
rag_chain = ({"question": RunnablePassthrough(), "context": retriever}| prompt| llm| StrOutputParser()
)rag_chain.invoke("Llama 2有多少参数")输入如下所示
Llama 2的参数量级覆盖从70亿到700亿(7 billion至70 billion parameters),具体模型规模包括7B、13B等不同版本,最高达到700亿参数。这一信息在提供的上下文中明确提到参数范围是从7 billion到70 billion。
reference
---
OneAPI-通过OpenAI API访问所有大模型
https://blog.csdn.net/liliang199/article/details/151393128
docker ollama部署轻量级嵌入模型 - EmbeddingGemma
https://blog.csdn.net/liliang199/article/details/151393128
开源向量LLM - BGE (BAAI General Embedding)
https://blog.csdn.net/liliang199/article/details/149773775
bge-m3
https://www.ollama.com/library/bge-m3