redis基础命令和深入理解底层
一.常用的数据类型
1.通用命令:
KEYS:查看符合模板的所有key
DEL:删除一个指定的key
EXISTS:判断key是否存在
EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
TTL:查看一个KEY的剩余有效期
2.string
set
作用:将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,⽆论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。语法:SET key value [expiration EX seconds|PX milliseconds] [NX|XX]• EX seconds⸺使⽤秒作为单位设置 key 的过期时间。• PX milliseconds⸺使⽤毫秒作为单位设置 key 的过期时间。• NX ⸺只在 key 不存在时才进⾏设置,即如果 key 之前已经存在,设置不执⾏。• XX ⸺只在 key 存在时才进⾏设置,即如果 key 之前不存在,设置不执⾏。返回值:• 如果设置成功,返回 OK。• 如果由于 SET 指定了 NX 或者 XX 但条件不满⾜,SET 不会执⾏,并返回 (nil)。
get
作用:
获取 key 对应的 value。如果 key 不存在,返回 nil。如果 value 的数据类型不是 string,会报错。语法:GET key返回值:key 对应的 value,或者 nil 当 key 不存在。
mget
作用:
⼀次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。语法:MGET key [key ...]返回值:
对应 value 的列表
mset
作用:
⼀次性设置多个 key 的值。语法:MSET key value [key value ...]返回值:
永远是 OK
setnx
就是上面的 SET key value NX
记数命令
incr
作用:
将 key 对应的 string 表⽰的数字加⼀。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。语法:INCR key返回值:
integer 类型的加完后的数值。
incrby
作用:
将 key 对应的 string 表⽰的数字加上对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。语法:INCRBY key decrement返回值:integer 类型的加完后的数值。
decr
作用:
将 key 对应的 string 表⽰的数字减⼀。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。语法:DECR key返回值:integer 类型的减完后的数值。
decrby
作用:
将 key 对应的 string 表⽰的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。语法:
DECRBY key decrement返回值:
integer 类型的减完后的数值。
incrbyfloat
作用:
将 key 对应的 string 表⽰的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是⼀个浮点数,则报错。允许采⽤科学计数法表⽰浮点数。语法:
INCRBYFLOAT key increment返回值:
加/减完后的数值。
其他命令,对字符串操作
append
作用:
如果 key 已经存在并且是⼀个 string,命令会将 value 追加到原有 string 的后边。如果 key 不存在,则效果等同于 SET 命令。语法:
APPEND KEY VALUE返回值:
追加完成之后 string 的⻓度。
getrange
作用:
返回 key 对应的 string 的⼦串,由 start 和 end 确定(左闭右闭)。可以使⽤负数表⽰倒数。-1 代表倒数第⼀个字符,-2 代表倒数第⼆个,其他的与此类似。超过范围的偏移量会根据 string 的⻓度调整成正确的值。语法:
GETRANGE key start end返回值:
string 类型的⼦串
setrange
作用:
覆盖字符串的⼀部分,从指定的偏移开始。
语法:
SETRANGE key offset value返回值:
替换后的 string 的⻓度。
strlen
作用:
获取 key 对应的 string 的⻓度。当 key 存放的类型不是 string 时,报错。
语法:
STRLEN key返回值:
string 的⻓度。或者当 key 不存在时,返回 0。
3.hash
hset
作用:
设置 hash 中指定的字段(field)的值(value)。
语法:
HSET key field value [field value ...]返回值:
添加的字段的个数。
hget
作用:
获取 hash 中指定字段的值。语法:
HGET key field返回值:
字段对应的值或者 nil。
hexists
作用:
判断 hash 中是否有指定的字段。语法:
HEXISTS key field返回值:
1 表⽰存在,0 表⽰不存在。
hdel
作用:
删除 hash 中指定的字段。
语法:
HDEL key field [field ...]返回值:
本次操作删除的字段个数。
hkeys
作用:
获取 hash 中的所有字段。语法:
HKEYS key返回值:
字段列表。
hvals
作用:
获取 hash 中的所有的值。语法:
HVALS key返回值:
所有的值。
hgetall
作用:
获取 hash 中的所有字段以及对应的值。语法:
HGETALL key返回值:
所有字段和对应的值。
hmget
作用:
⼀次获取 hash 中多个字段的值。
语法:
HMGET key field [field ...]返回值:
字段对应的值或者 nil。
hlen
作用:
获取 hash 中的所有字段的个数。
语法:
HLEN key返回值:
字段个数。
hsetnx
作用:
在字段不存在的情况下,设置 hash 中的字段和值。语法:
HSETNX key field value返回值:
1 表⽰设置成功,0 表⽰失败。
hincrby
作用:
将 hash 中字段对应的数值添加指定的值。语法:
HINCRBY key field increment返回值:
该字段变化之后的值。
hincrbyfloat
作用:
HINCRBY 的浮点数版本。语法:
HINCRBYFLOAT key field increment返回值:
该字段变化之后的值。
4.list
| 操作类型 | 命令 | 时间复杂度 |
|---|---|---|
| 添加 | rpush key value [value ...] | O(k),k 是元素个数 |
| 添加 | lpush key value [value ...] | O(k),k 是元素个数 |
| 添加 | linsert key before | after pivot value | O(n),n 是 pivot 距离头尾的距离 |
| 查找 | lrange key start end | O(s+n),s 是 start 偏移量,n 是 start 到 end 的范围 |
| 查找 | lindex key index | O(n),n 是索引的偏移量 |
| 查找 | llen key | O(1) |
| 删除 | lpop key | O(1) |
| 删除 | rpop key | O(1) |
| 删除 | lrem key count value | O(k),k 是元素个数 |
| 删除 | ltrim key start end | O(k),k 是元素个数 |
| 修改 | lset key index value | O(n),n 是索引的偏移量 |
| 阻塞操作 | blpop brpop | O(1) |
5.set
普通命令
sadd
作用:
将⼀个或者多个元素添加到 set 中。注意,重复的元素⽆法添加到 set 中。语法:
SADD key member [member ...]返回值:
本次添加成功的元素个数。
smembers
作用:
获取⼀个 set 中的所有元素,注意,元素间的顺序是⽆序的。语法:
SMEMBERS key返回值:
所有元素的列表。
sismember
作用:
判断⼀个元素在不在 set 中。
语法:
SISMEMBER key member返回值:
1 表⽰元素在 set 中。0 表⽰元素不在 set 中或者 key 不存在。
scard
作用:
获取⼀个 set 的元素个数。
语法:
SCARD key返回值:
set 内的元素个数。
spop
作用:
从 set 中删除并返回⼀个或者多个元素。注意,由于 set 内的元素是⽆序的,所以取出哪个元素实际是未定义⾏为,即可以看作随机的。所以感觉不实用语法:
SPOP key [count]返回值:
取出的元素。
smove
作用:
将⼀个元素从源 set 取出并放⼊⽬标 set 中。
语法:
SMOVE source destination member返回值:
1 表⽰移动成功,0 表⽰失败。
srem
作用:
将指定的元素从 set 中删除。
语法:
SREM key member [member ...]返回值:
本次操作删除的元素个数。
集合命令:交集,并集,差集
sinter
作用:
获取给定 set 的交集中的元素。
语法:
SINTER key [key ...]返回值:
交集的元素。
sinterstore
作用:
获取给定 set 的交集中的元素并保存到⽬标 set 中。
语法:
SINTERSTORE destination key [key ...]返回值:
交集的元素个数。
sunion
作用:
获取给定 set 的并集中的元素。
语法:
SUNION key [key ...]返回值:
并集的元素。
sunionstore
作用:
获取给定 set 的并集中的元素并保存到⽬标 set 中。
语法:
SUNIONSTORE destination key [key ...]返回值:
并集的元素个数。
sdiff
作用:
获取给定 set 的差集中的元素。
语法:
SDIFF key [key ...]返回值:
差集的元素。

sdiffstore
作用:
获取给定 set 的差集中的元素并保存到⽬标 set 中。
语法:
SDIFFSTORE destination key [key ...]返回值:
差集的元素个数。
6.zset
普通命令
zadd
作用:
添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的。语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]• XX:仅仅⽤于更新已经存在的元素,不会添加新元素。• NX:仅⽤于添加新元素,不会更新已经存在的元素。• CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。• INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数。返回值:
本次添加成功的元素个数。
zcard
作用:
获取⼀个 zset 的基数(cardinality),即 zset 中的元素个数。
语法:
ZCARD key返回值:
zset 内的元素个数。
zcount:min和max表示分数
作用:
返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。语法:
ZCOUNT key min max返回值:
满⾜条件的元素列表个数。
zrange:start和stop表示下标
作用:
返回指定区间⾥的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
语法:
ZRANGE key start stop [WITHSCORES]返回值:
区间内的元素列表。
zrevrange
作用:
返回指定区间⾥的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。语法:
ZREVRANGE key start stop [WITHSCORES]返回值:
区间内的元素列表。
zrangebyscore
作用:
返回分数在 min 和 max 之间的元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。语法:
ZRANGEBYSCORE key min max [WITHSCORES]返回值:
区间内的元素列表。
zpopmax
作用:
删除并返回分数最⾼的 count 个元素。语法:
ZPOPMAX key [count]返回值:
分数和元素列表。
bzpopmax
作用:
ZPOPMAX 的阻塞版本。
语法:
BZPOPMAX key [key ...] timeout返回值:
元素列表。
zpopmin
作用:
删除并返回分数最低的 count 个元素。
语法:
ZPOPMIN key [count]返回值:
分数和元素列表。
bzpopmin
作用:
ZPOPMIN 的阻塞版本。
语法:
BZPOPMIN key [key ...] timeout返回值:
元素列表。
zrank
作用:
返回指定元素的排名,升序。
语法:
ZRANK key member返回值:
排名。
zrevrank
作用:
返回指定元素的排名,降序。
语法:
ZREVRANK key member返回值:
排名。
zscore
作用:
返回指定元素的分数。语法:
ZSCORE key member返回值:
分数。
zrem
作用:
删除指定的元素。
语法:
ZREM key member [member ...]返回值:
本次操作删除的元素个数。
zremrangebyrank
作用:
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop返回值:
本次操作删除的元素个数。ZINCRBY key increment member
zremrangebyscore
作用:
按照分数删除指定范围的元素,左闭右闭。语法:
ZREMRANGEBYSCORE key min max返回值:
本次操作删除的元素个数。
zincrby
作用:
为指定的元素的关联分数添加指定的分数值。语法:
ZINCRBY key increment member返回值:
增加后元素的分数。
集合间操作
zinterstore:交集
作用:
语法:
返回值:
zunionstore:并集
作用:
语法:
返回值:
二.其他数据类型
stream
使用redis作为消息队列
geospatial
用来存储坐标 (经纬度)
存储一些点之后,就可以让用户给定一个坐标,去从刚才存储的点里进行查找. (按照半径,矩形区域...)
这个功能在 "地图" 应用中非常重要~~
自增id
string 中 使用 incr 指令让string自增
bitfield
bitmap
使用String,位图的思想,更少的空间存储更多的内容,只能存储整数
修改bit位上的数据
set key offset value
- offset:要修改第几个bit位的数据
- value:0或1bitfield key GET encoding offset
- key:就是BitMap的key
- GET:代表查询
- encoding:返回结果的编码方式,BitMap中是二进制保存,而返回结果会转为10进制,但需要一个转换规则,也就是这里的编码方式- u:无符号整数,例如 u2,代表读2个bit位,转为无符号整数返回- i:又符号整数,例如 i2,代表读2个bit位,转为有符号整数返回
- offset:从第几个bit位开始读取,例如0:代表从第一个bit位开始Hyperloglog
估算集合中元素(整数或字符串都可以)的个数:用来计数统计有多少个不同的元素,但是不能告诉你元素是啥
可以统计用户访问数量,使用set的话内存占用会非常大,使用Hyperloglog内存小很多
三.底层编码类型
1.动态字符串SDS
和c++中讲的vector一样不过这里是字符串数组

2.IntSet
存储整数
① Redis会确保Intset中的元素唯一、有序
② 具备类型升级机制,可以节省内存空间
③ 底层采用二分查找方式来查询,里面的数据是有序的
3.Dict
字典,Hash表
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2ⁿ
- 收缩大小为第一个大于等于used的2ⁿ
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
4.ZipList
“双端链表”,不是链表
内存是连续的
和链表性能类似,不过更节省内存
因为存储数据算法的原因,会导致连锁更新的问题导致性能很慢,但是出现的概率极低
ZipList特性:
① 压缩列表的可以看做一种连续内存空间的"双向链表"
② 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
③ 如果列表数据过多,导致链表过长,可能影响查询性能
④ 增或删较大数据时有可能发生连续更新问题
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
√ 为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
√ 我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
√ Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
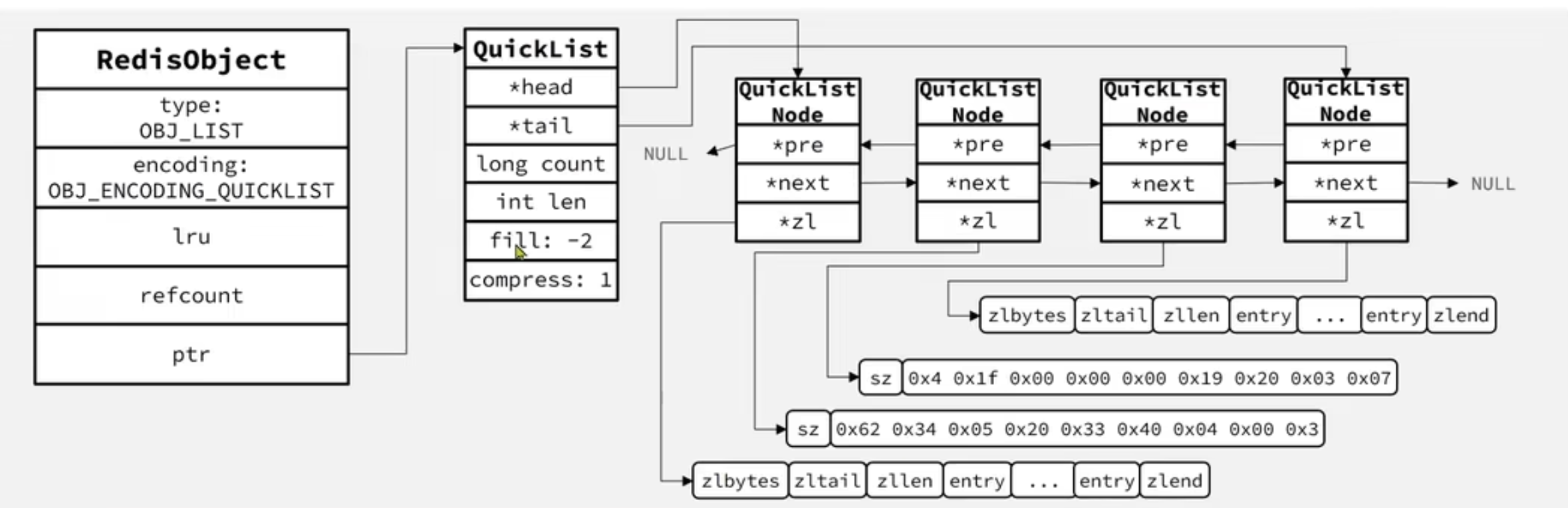
5.QuickList
QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
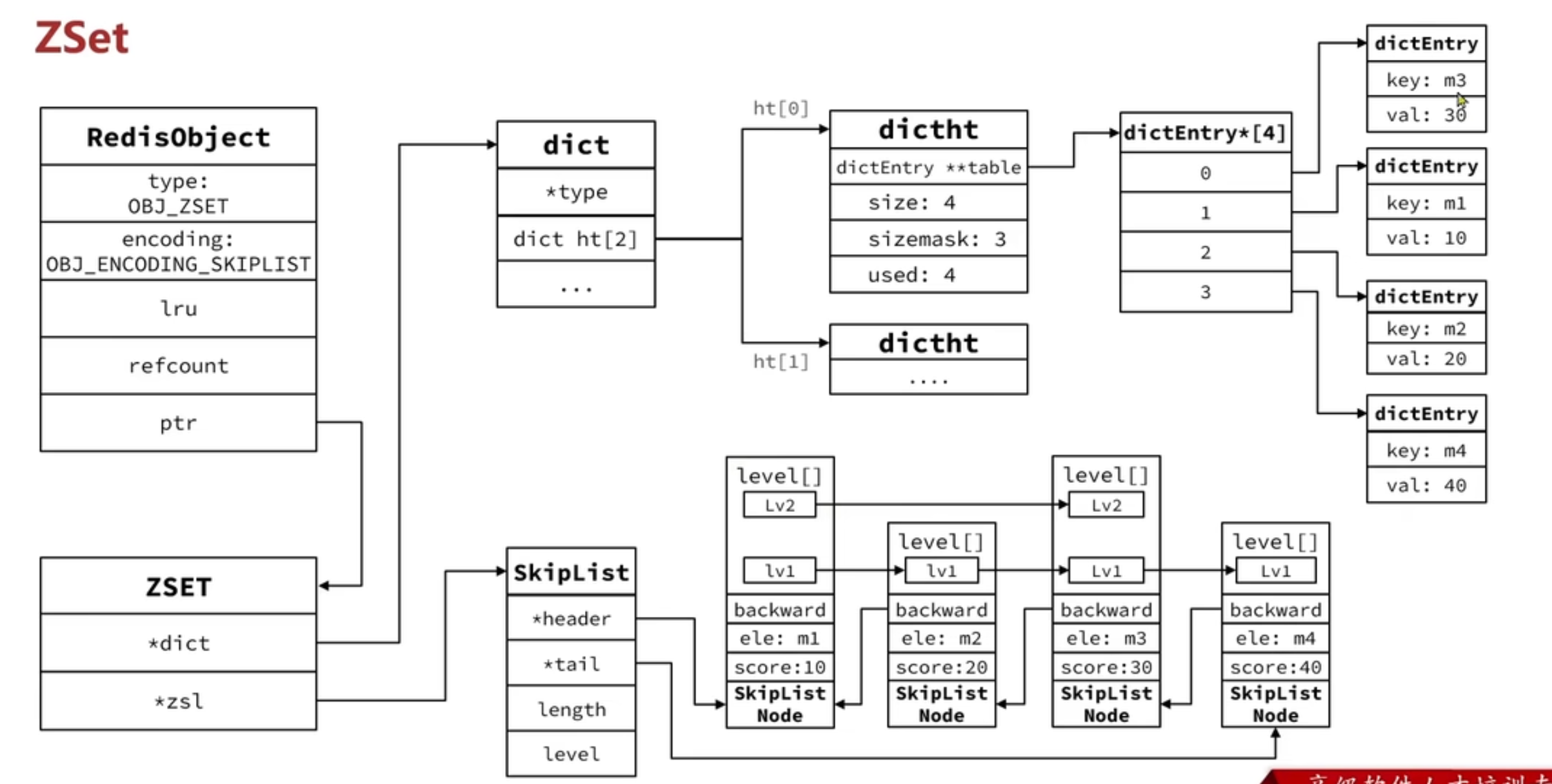
6.SkipList
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
四.数据结构的编码类型
| 数据类型 | 内部编码 |
|---|---|
| string | raw, int, embstr |
| hash | hashtable(dict), ziplist |
| list | quicklist |
| set | hashtable(dict), intset |
| zset | skiplist+dict, ziplist |
String
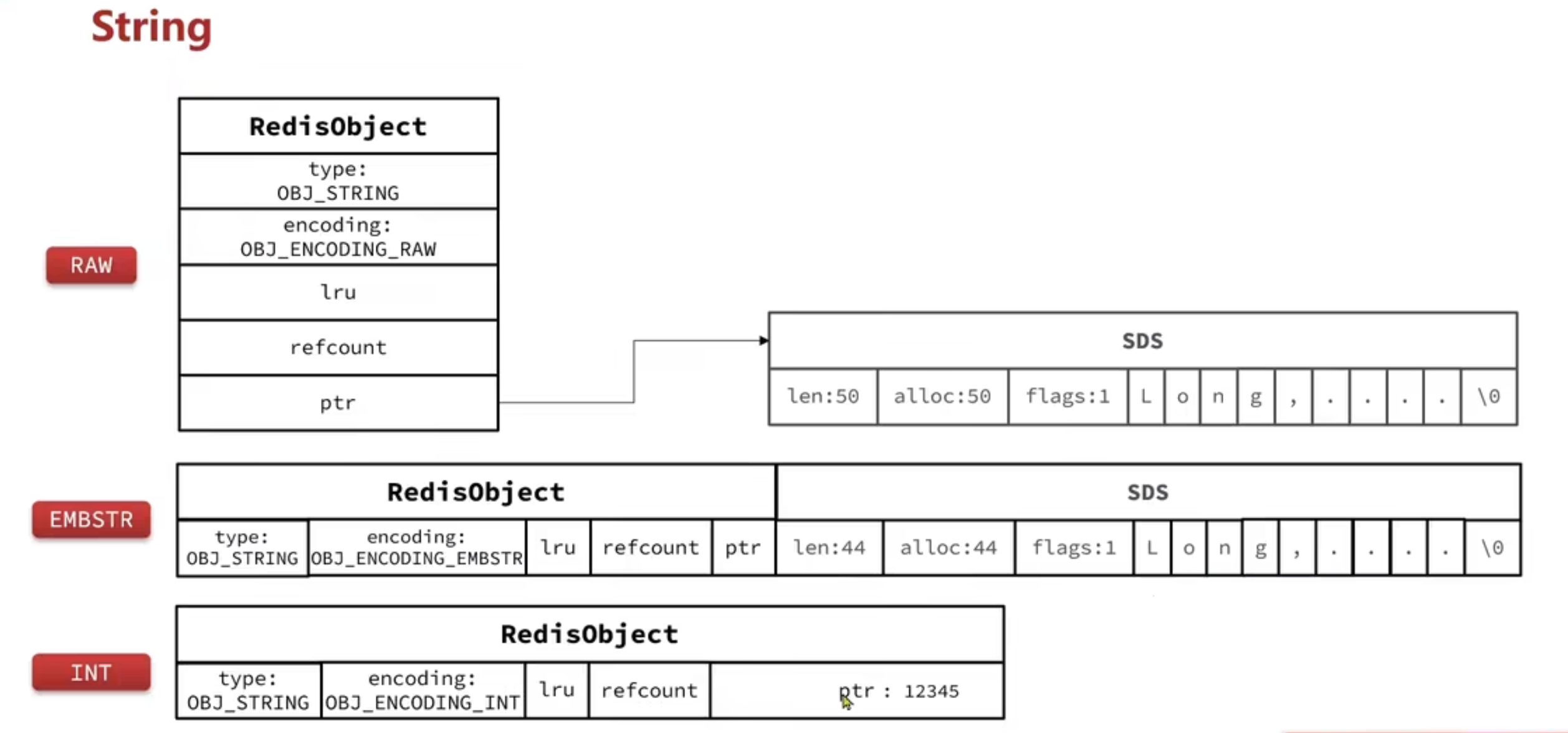
value如果是纯数字使用int
value短字符串是embstr,长字符串是raw
List
Set
如果底层都是整数且不能超过设置的最大值使用intset
其他使用Dict
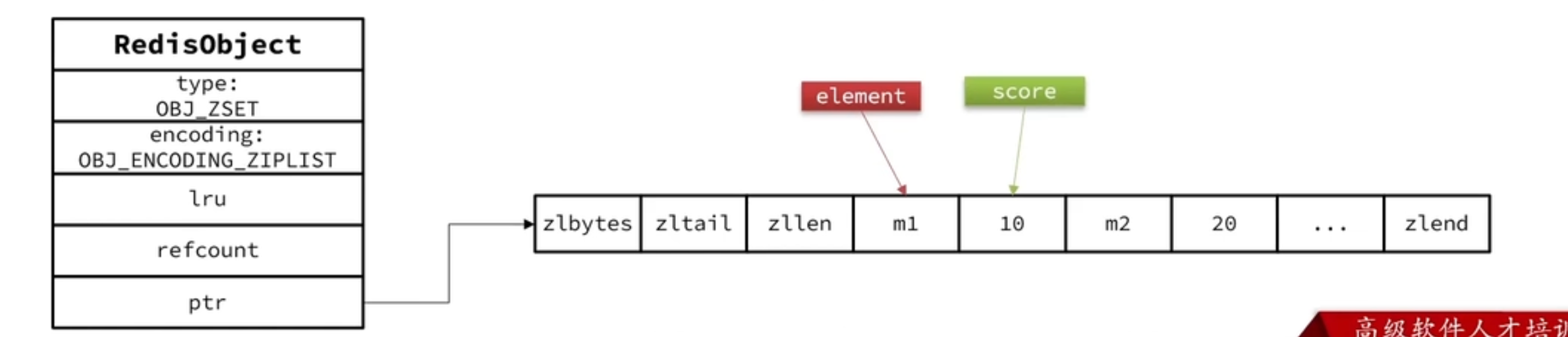
ZSet
元素少的时候使用ZipList
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry,element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
多的时候使用 skiplist+dict
Hash
没啥好总结的
五.Redis的网络模型
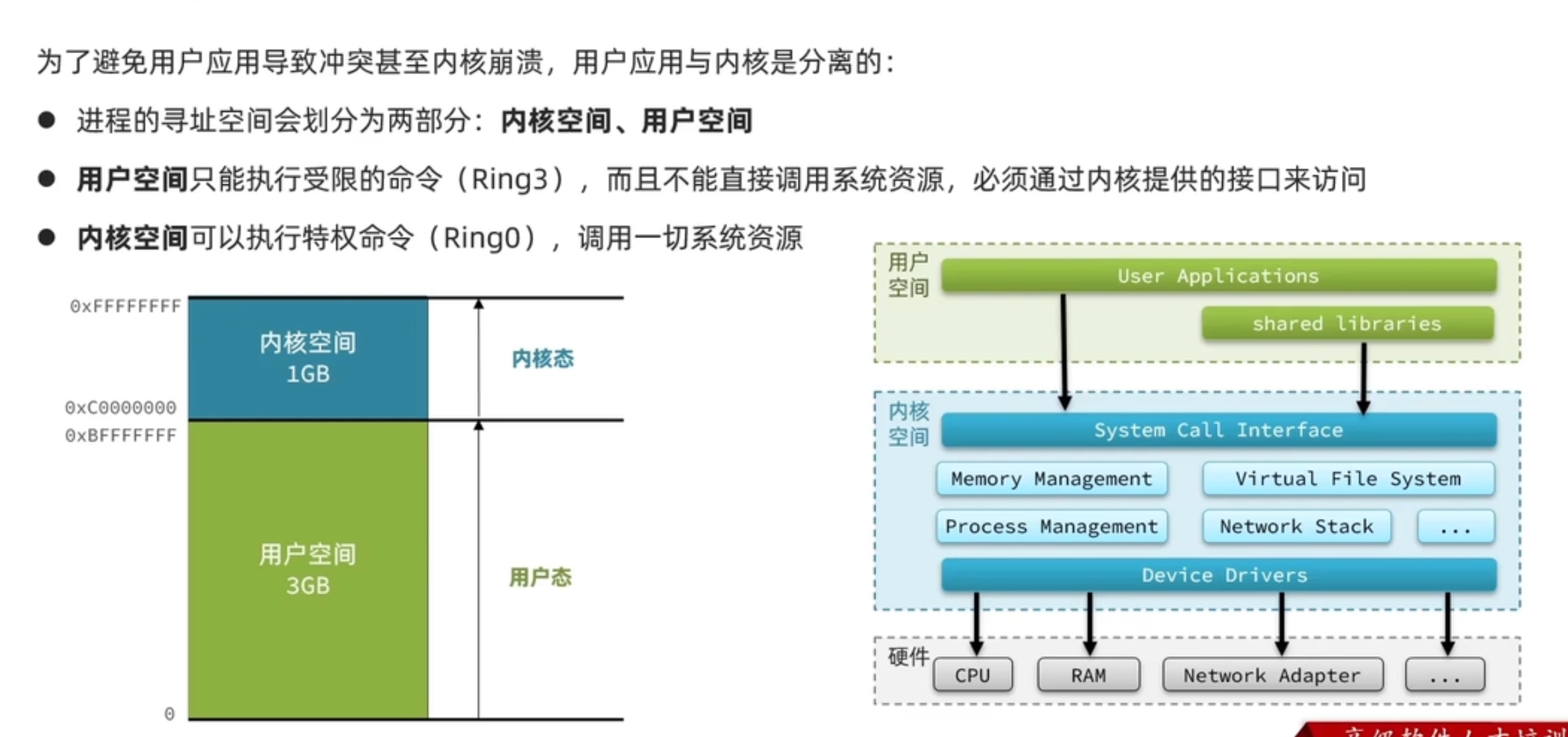
1.用户空间和内核空间
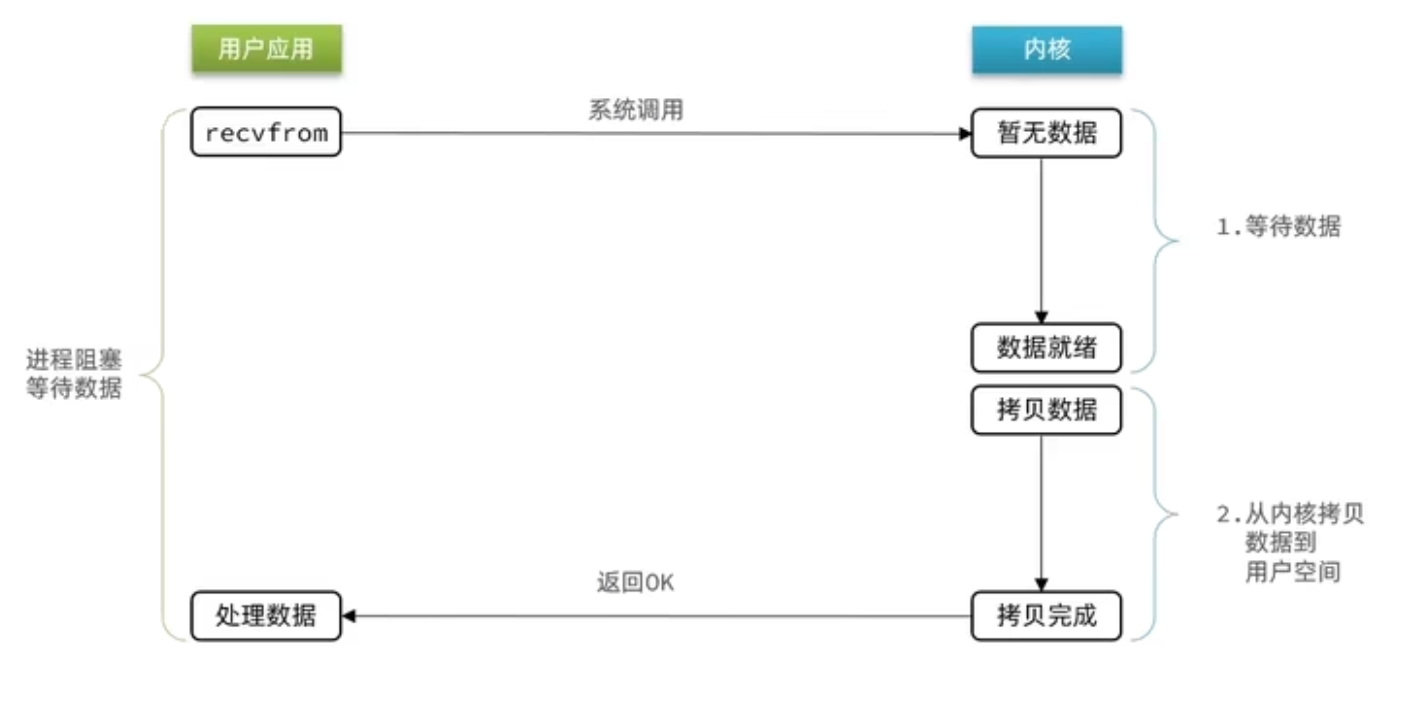
2.IO模型
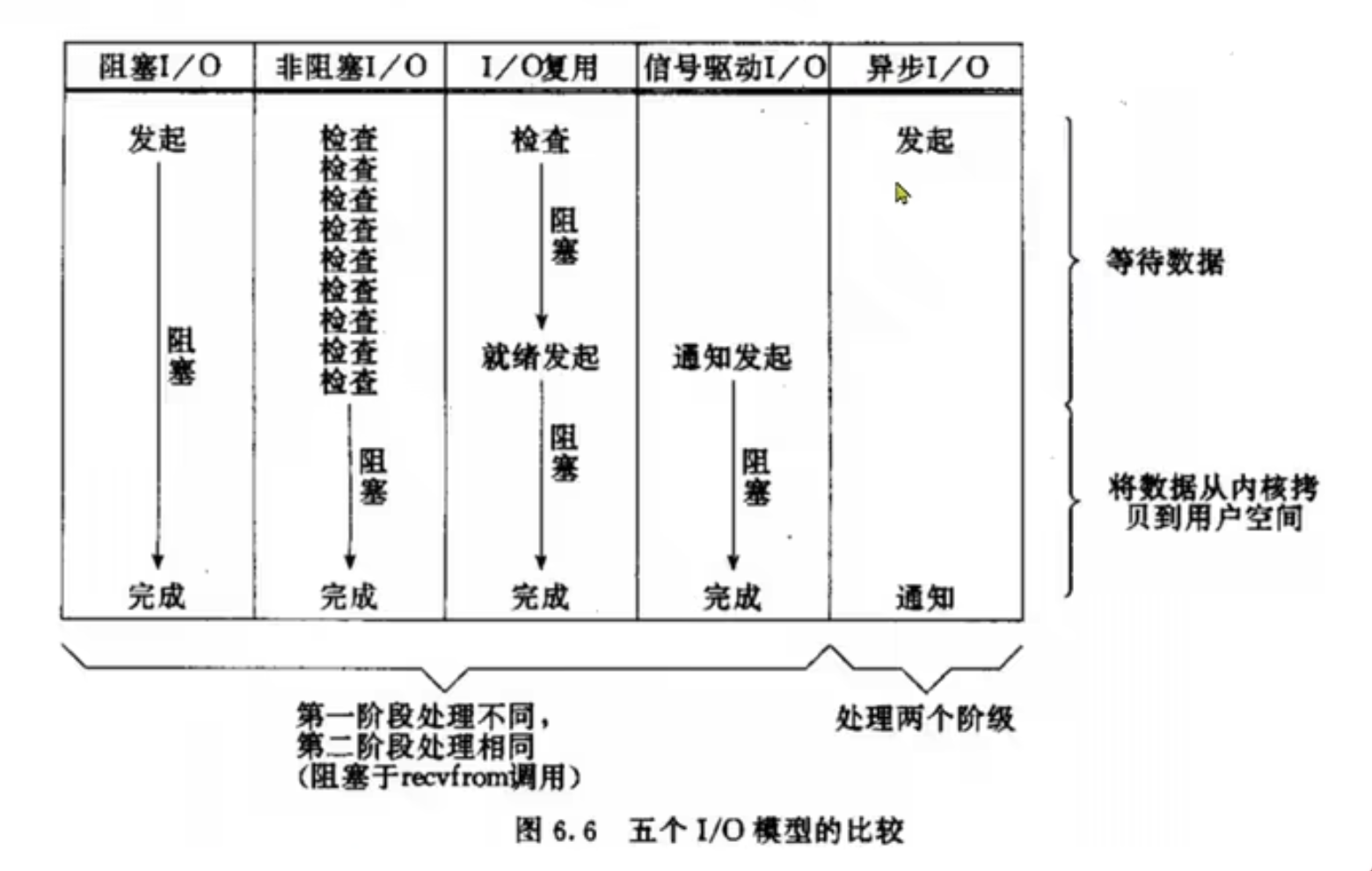
①阻塞IO
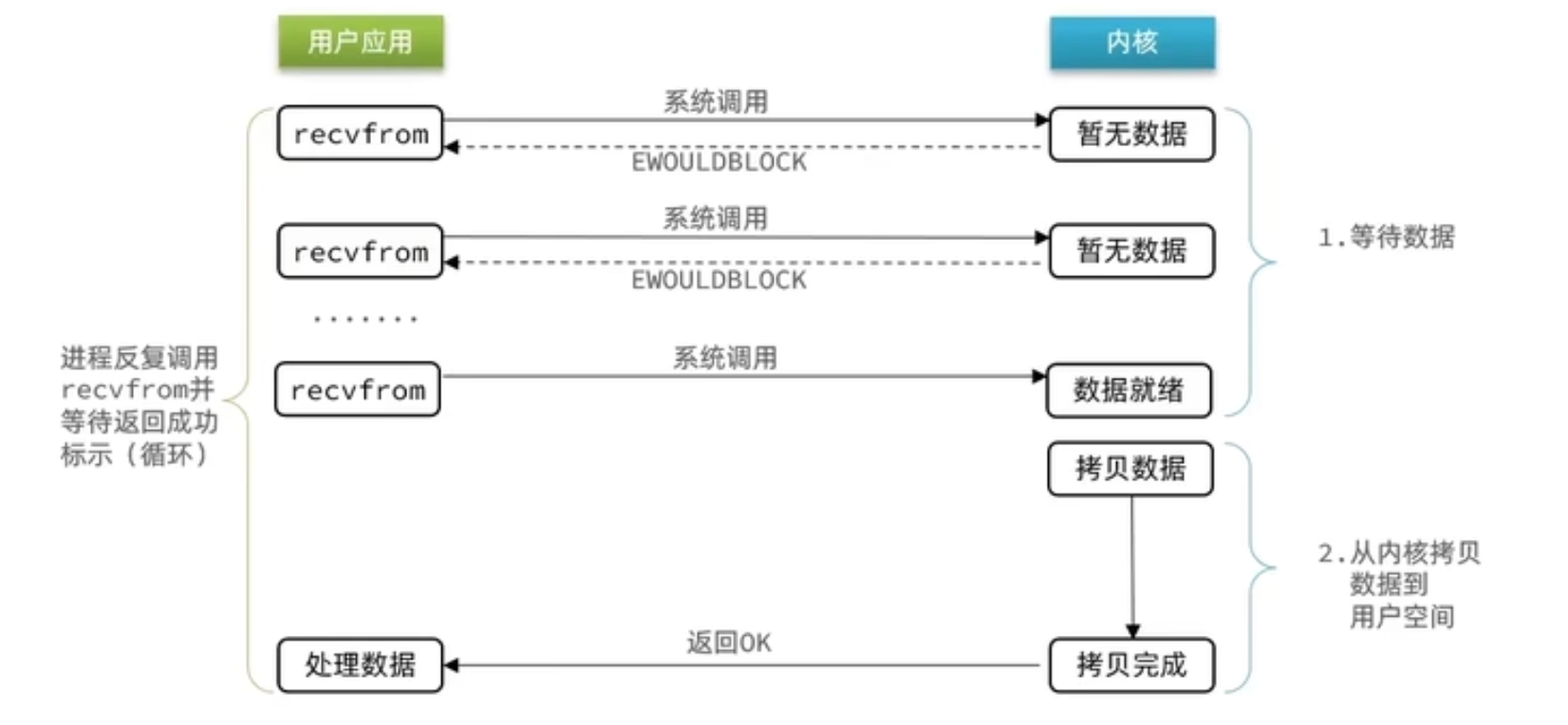
②非阻塞IO
③IO多路复用
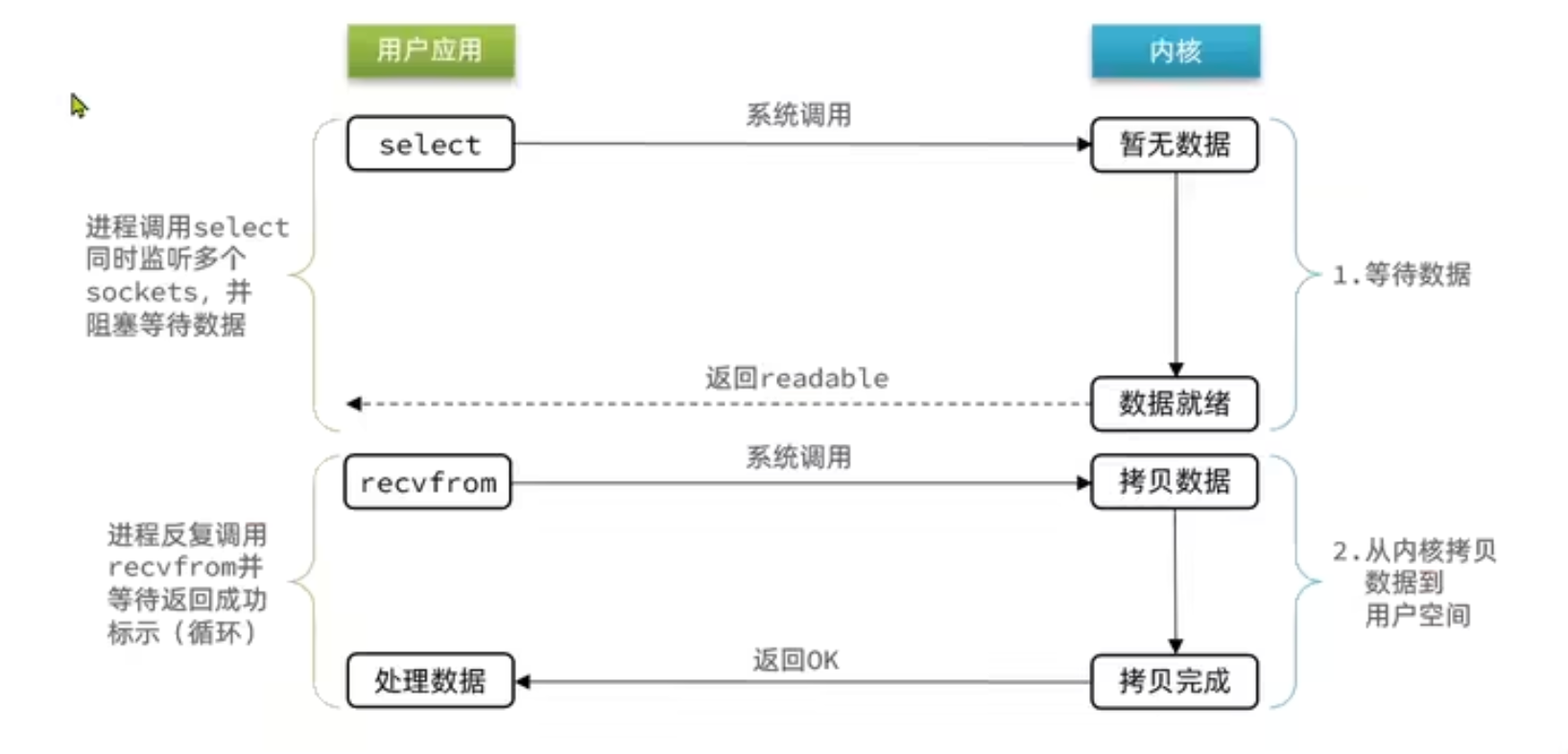
select模式:
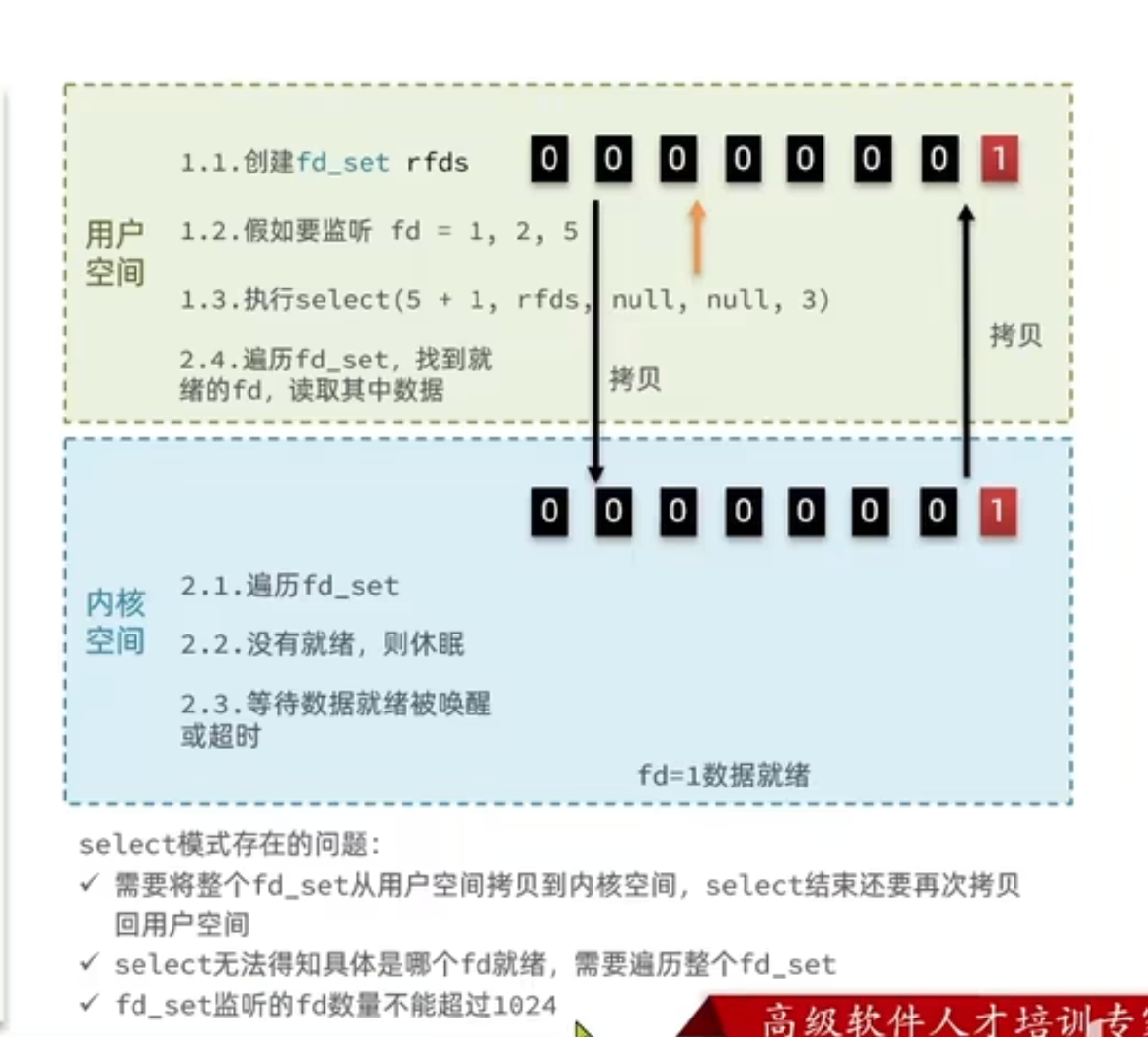
poll模式:
IO流程:
① 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
② 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
③ 内核遍历fd,判断是否就绪
④ 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
⑤ 用户进程判断n是否大于0
⑥ 大于0则遍历pollfd数组,找到就绪的fd
与select对比:
- select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限
- 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
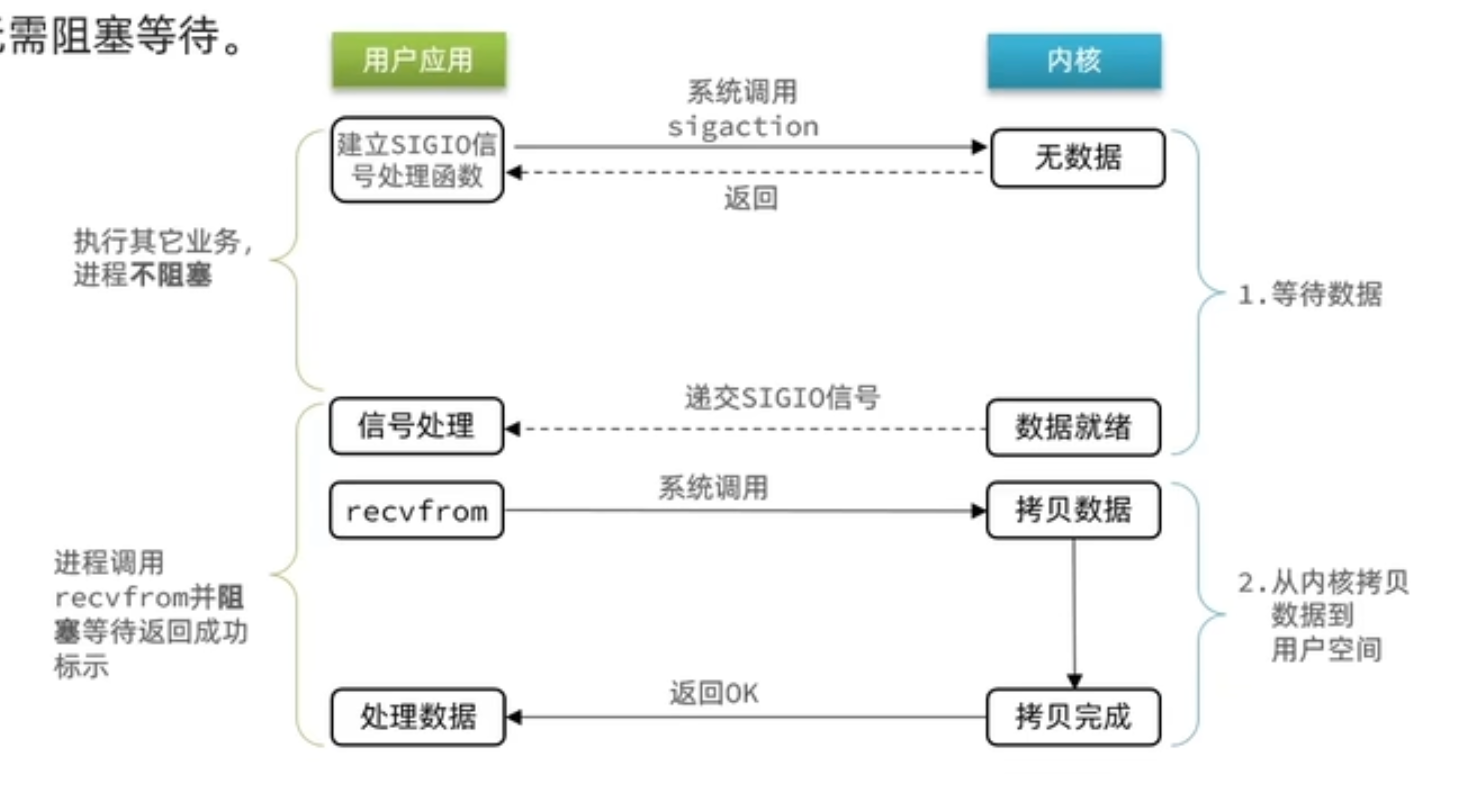
④信号驱动IO
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致信号队列溢出
而且内核空间与用户空间的频繁信号交互性能也较低。
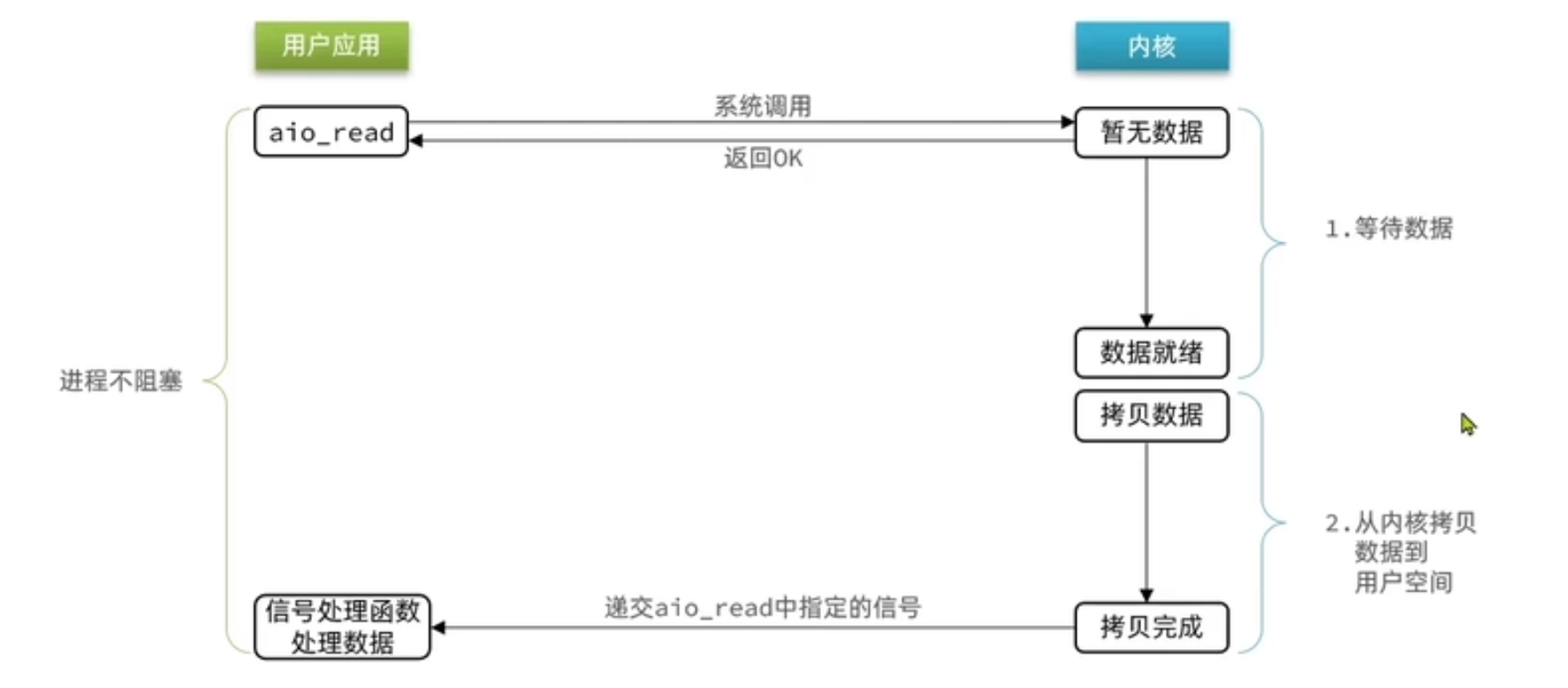
⑤异步IO
异步可能导致发送的消息过多,需要做到限流处理。
总结
3.redis网络模型
太难了看不懂。
4.redis的通信协议
RESP协议