大语言模型核心技术解析:从 Transformer 架构到下词预测的完整工作原理与编码器、解码器及注意力机制的运作流程
概述
本文以通俗易懂的方式阐释大语言模型(Large Language Model, LLM)的核心技术原理。ChatGPT、DeepSeek等主流大语言模型均基于Transformer(变换器)神经网络架构构建,其核心能力在于理解句子中词语的上下文关系并预测输出序列的下一个词语,这也是此类模型能够逐词生成内容的本质原因。例如,当输入"谢谢你"时,模型会依次预测"不"“客”"气"以形成完整回应。本文将系统解析Transformer的工作机制,带您深入理解这一革命性技术的内在逻辑。
Transformer预测下一个词语的逻辑原理
Transformer模型由编码器(Encoder)和解码器(Decoder)两部分构成。编码器负责处理并编码输入句子,解码器则基于编码结果生成并解码输出句子,最终实现下一个词语的预测。在训练过程中,模型通过输入句子与对应输出句子的配对数据进行学习,从而掌握输入到输出的映射规律。
以英日翻译任务为例:若要将英语"Thank you"翻译为日语"Arigato",训练阶段会将英语句子输入编码器,日语句子输入解码器,使模型学习两者的对应关系。这一过程类似人类学习外语时的翻译练习——通过大量双语对照样本,逐步掌握不同语言间的转换规则。
Transformer的核心处理步骤
编码器与解码器均需执行以下基础操作,后续将详细解析各环节的具体实现:
- 词嵌入(Word Embedding):将句子中的每个词语转换为实数向量,实现自然语言到数值表示的转换。
- 位置编码(Positional Encoding):通过数学方法标记词语在句子中的位置信息,解决词语顺序对语义的影响(如"蝙蝠吃了猫"与"猫吃了蝙蝠"的语义差异)。
- 自注意力机制(Self-Attention):计算句子中每个词语与其他词语的关联程度,生成注意力分数,为模型提供上下文理解能力。
- 残差连接(Residual Connection):将位置编码值与自注意力结果相加,随后进行归一化处理,缓解深层网络的梯度消失问题。
- 前馈层(Feed-Forward Network):通过标准神经网络对归一化结果进行非线性变换,生成前馈输出。
- 二次残差连接:将前馈输出与归一化后的自注意力结果相加并再次归一化,增强特征传播能力。
注:上述步骤适用于编码器与解码器,但解码器结构更复杂,包含额外的交互机制(详见下文"解码器的特殊步骤")。
解码器的特殊步骤
- 编码器-解码器注意力机制(Encoder-Decoder Attention):计算输入句子与输出句子中词语的跨序列关联,强化上下文信息的融合。
- 残差连接:将解码器的归一化输出与编码器-解码器注意力分数相加并归一化。
- 前馈网络层:对上述结果进行非线性变换。
- 最终残差连接:将归一化后的编码器-解码器注意力值与前馈输出相加。
- SoftMax激活:将最终输出转换为词汇表上的概率分布,概率最高的词语即为预测结果,该结果将与历史序列结合用于下一次预测。
关键细节:自注意力、编码器-解码器注意力及前馈网络层后均需添加残差连接。本文基于《Attention Is All You Need》论文框架展开,但简化了部分实现细节。需注意,ChatGPT仅采用解码器架构,而本文将完整解析原始Transformer的工作原理。
编码器部分
编码器是输入句子的处理入口。例如,当输入"Hello there"时,该语句会被送入编码器,同时在训练阶段,预期回应"Hi there, how can I help you?"会被输入解码器,以教导模型学习输入与输出的对应关系。
输入句子会被特殊标记包裹:<SOS>(序列开始符)和<EOS>(序列结束符),用于明确句子的边界。在实际交互中(如使用ChatGPT时),用户输入会被自动添加这些标记,解码器的输入同样遵循此规则(训练阶段)。
编码器处理步骤
1. 词嵌入
词嵌入是将词语转化为数字向量的过程,使计算机能够处理自然语言。向量维度根据模型复杂度可设置为2维、4维甚至512维,维度越高,理论上可表示的语义信息越丰富。例如,"Hi"可能被表示为[0.1, 3.2, -1.7, 2.1](4维向量),"there"可能表示为[0.9, -3.2, 1.8, 0.4]。
以"Thank"、"you"和<EOS>为例,其词嵌入计算过程如下:
- 为每个词语分配专属神经元,通过独热向量(One-Hot Vector)表示(如"Thank"对应[1, 0, 0, 0],"you"对应[0, 0, 1, 0])。
- 独热向量与权重矩阵相乘并求和,得到词嵌入值。例如,"Thank"的神经元值[1]与权重[1.2, 2.9]相乘后,得到词嵌入值[1.2, 2.9]。
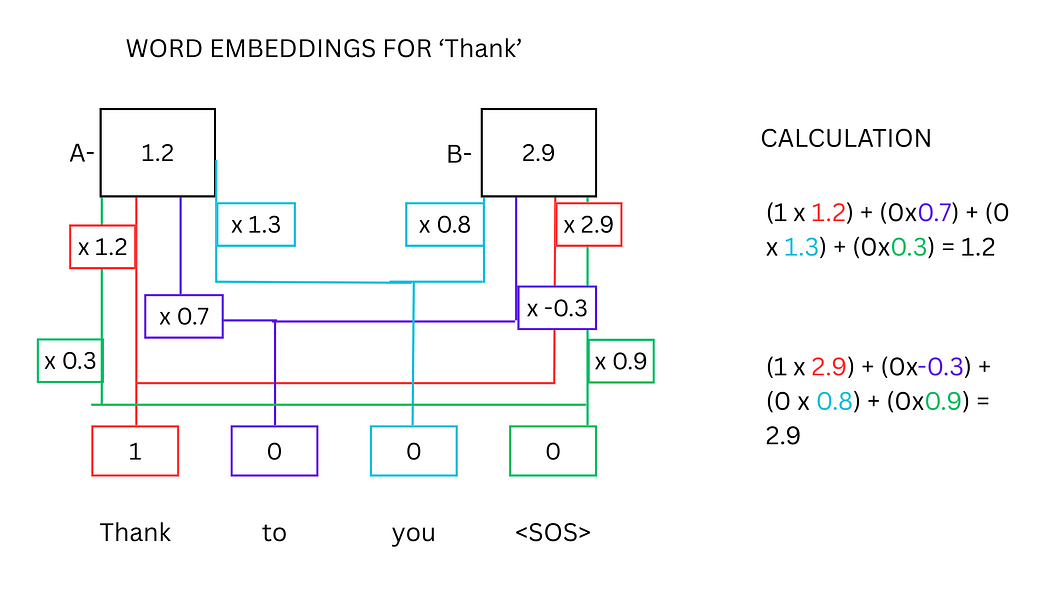
图1:单个单词词嵌入值的神经网络计算示意图
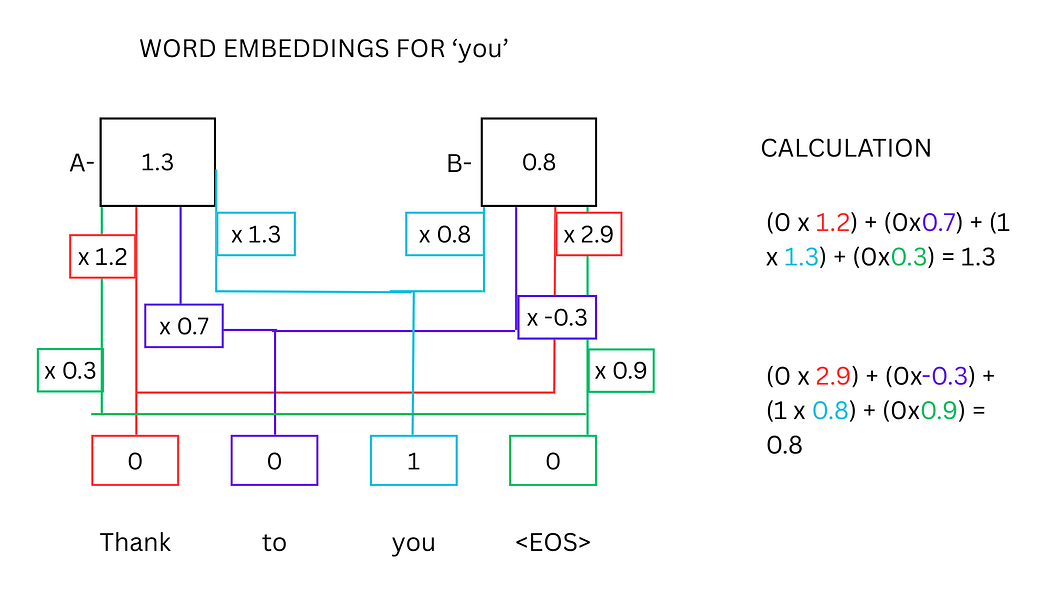
图2:"you"的词嵌入计算示意图
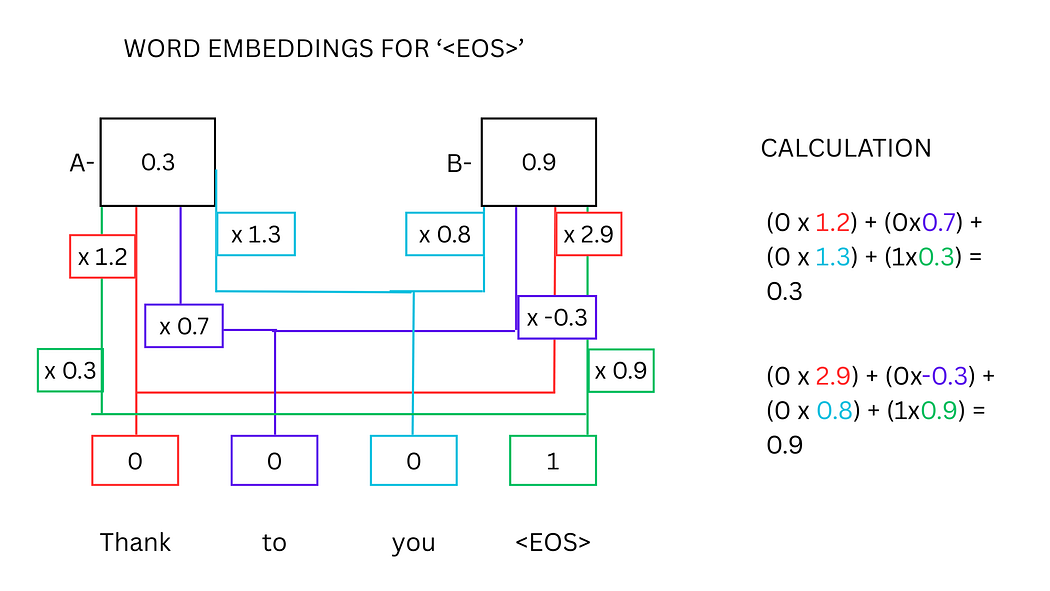
图3:<EOS>标记的词嵌入计算示意图
数学本质:词嵌入的计算本质是矩阵乘法。独热向量(行向量)与权重矩阵(列向量)相乘,结果即为该词语的嵌入向量。
2. 位置编码
为解决词语顺序对语义的影响,位置编码通过正弦波和余弦波的坐标点与词嵌入值相加,生成包含位置信息的向量。具体公式如下:
- 偶数维度:PE(pos,2i)=sin(pos/100002i/dmodel)PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{\text{model}}})PE(pos,2i)=sin(pos/100002i/dmodel)
- 奇数维度:PE(pos,2i+1)=cos(pos/100002i/dmodel)PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}})PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中,pospospos为词语在句子中的位置,iii为维度索引,dmodeld_{\text{model}}dmodel为词嵌入维度。
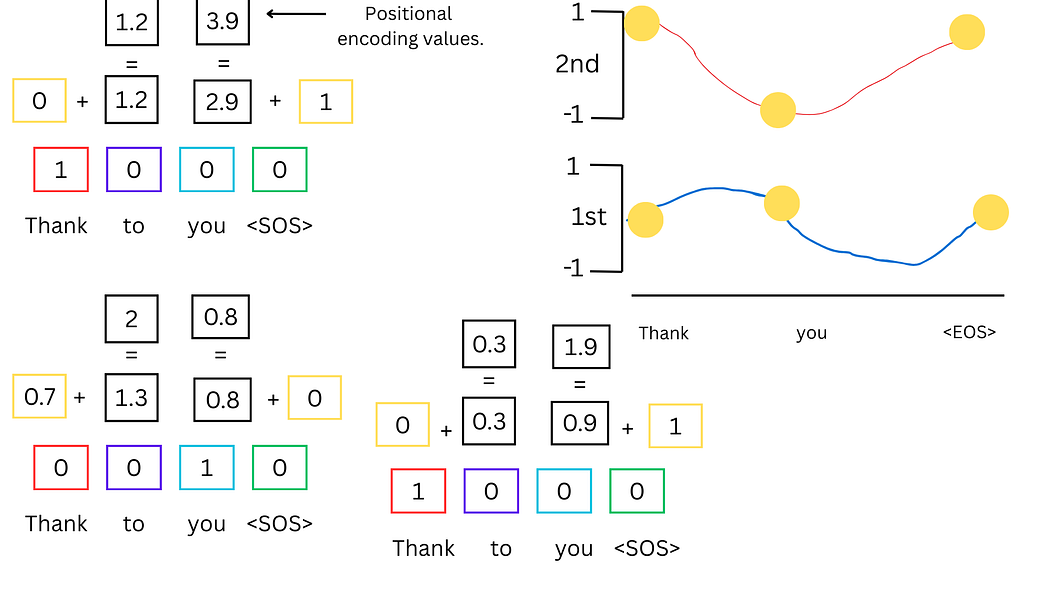
图4:位置编码计算示意图(黄色方块为正弦/余弦波点,与词嵌入值相加生成位置编码)
3. 自注意力机制
自注意力机制通过计算词语间的关联强度(注意力分数),帮助模型理解上下文。以"海盗轰击了船只,它沉入了海底"为例,模型需识别"船只"与"它"的指代关系,这一过程通过以下步骤实现:
i. 生成查询、键、值向量
为每个词语生成查询(Query, Q)、键(Key, K)和值(Value, V)向量,这些向量通过位置编码值与权重矩阵相乘得到。例如,"Thank"的Q向量为[4.47, 2.28],K向量为[9.54, 8.22],V向量为[2.1, 6.3]。
ii. 计算相似度分数
通过点积运算计算词语间的相似度:$ \text{相似度} = Q \cdot K^T $。例如:
- "Thank"与自身的相似度:(4.47×9.54)+(2.28×8.22)=61.3(4.47 \times 9.54) + (2.28 \times 8.22) = 61.3(4.47×9.54)+(2.28×8.22)=61.3
- "Thank"与"you"的相似度:(4.47×5.64)+(2.28×5.72)=38.2(4.47 \times 5.64) + (2.28 \times 5.72) = 38.2(4.47×5.64)+(2.28×5.72)=38.2
iii. 缩放与SoftMax
为避免梯度消失,将相似度分数除以键向量维度的平方根($ \sqrt{d_k} ,,,d_k$为键向量维度),再通过SoftMax函数将结果转换为概率分布(总和为1)。例如,61.3和38.2经处理后可能变为0.62和0.38,表明"Thank"与自身的关联更强。
iv. 计算自注意力分数
将SoftMax概率与值向量相乘并求和,得到最终自注意力分数。例如,"Thank"的自注意力分数为:
(2.1×1)+(6.3×1)+(2.36×0)+(4.8×0)=[2.1,6.3](2.1 \times 1) + (6.3 \times 1) + (2.36 \times 0) + (4.8 \times 0) = [2.1, 6.3](2.1×1)+(6.3×1)+(2.36×0)+(4.8×0)=[2.1,6.3]
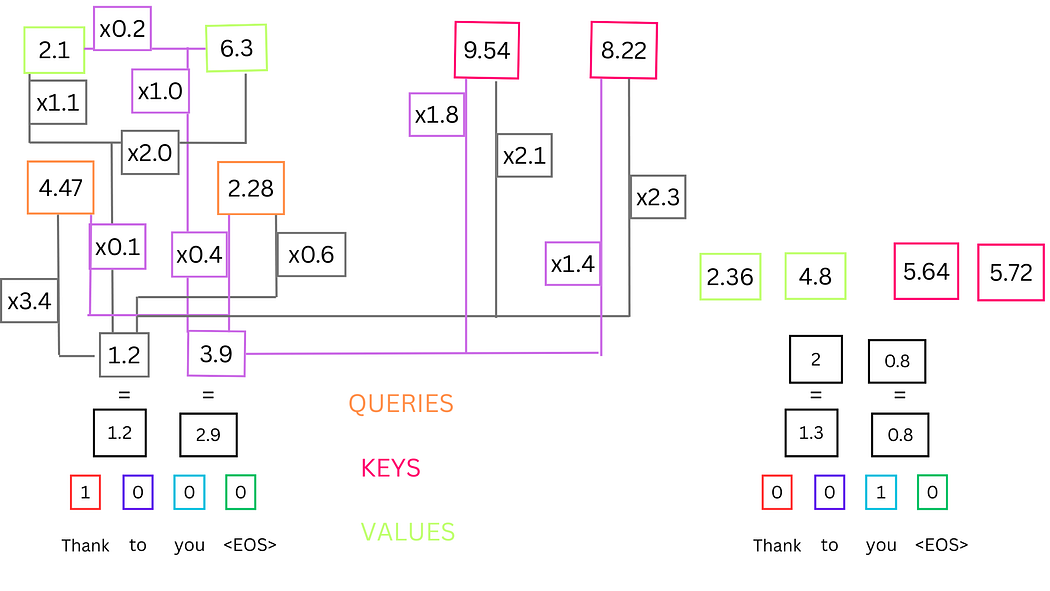
图5:"Thank"与"you"的相似度计算示意图
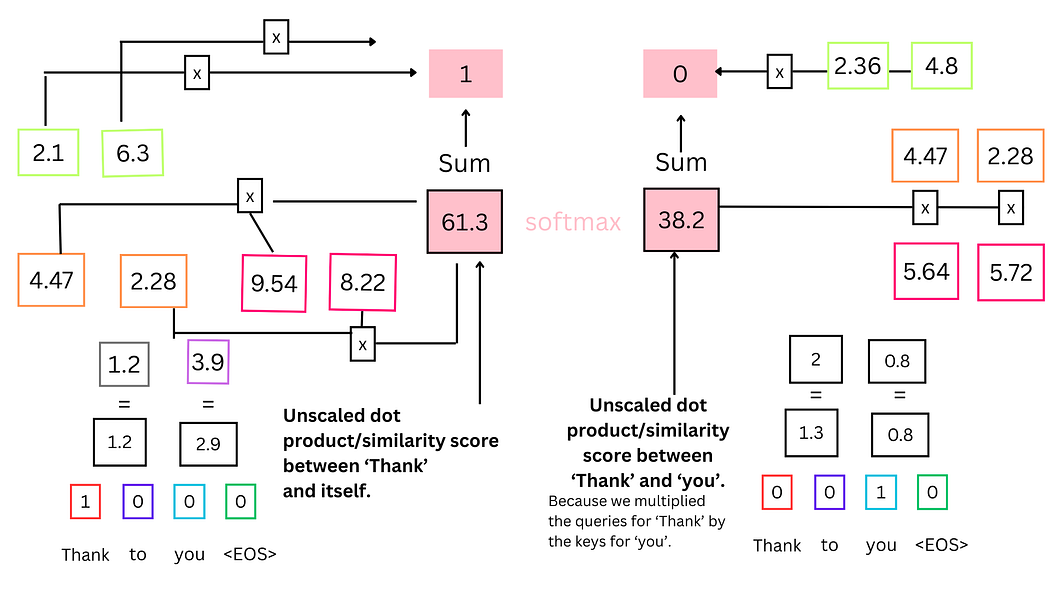
图6:相似度分数的SoftMax处理示意图
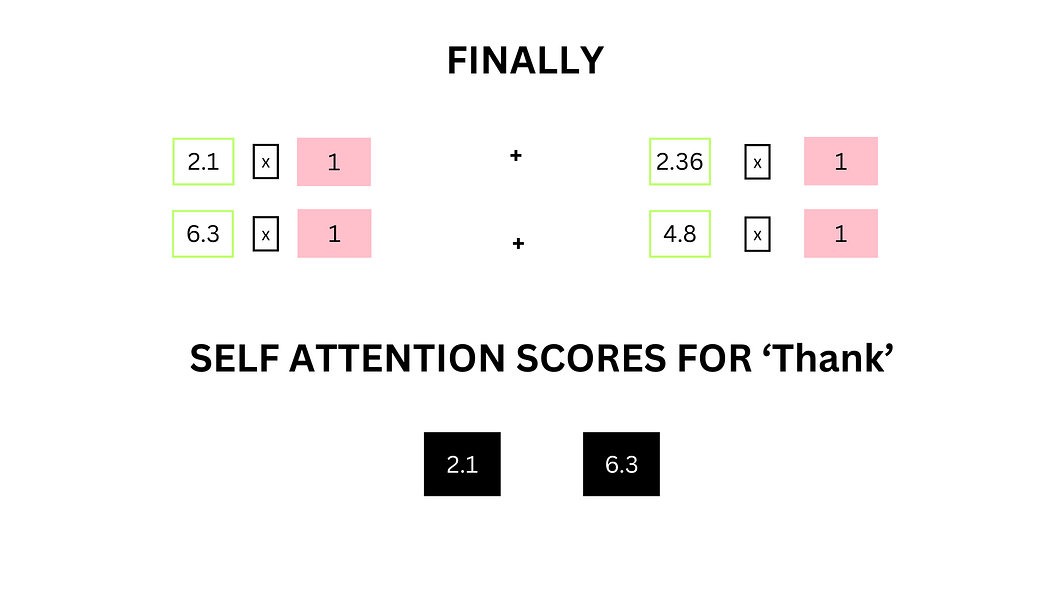
图7:自注意力分数的矩阵计算示例
多注意力头机制:实际模型(如ChatGPT)通常包含多个自注意力层(如8层),每层有独立的Q、K、V权重矩阵,以捕捉不同维度的上下文关系。
4. 残差连接与归一化
自注意力分数与位置编码值相加(残差连接),随后通过Layer Normalization处理,公式为:
LayerNorm(x+SelfAttention(x))\text{LayerNorm}(x + \text{SelfAttention}(x)) LayerNorm(x+SelfAttention(x))
该操作增强了模型的稳定性和训练效率。
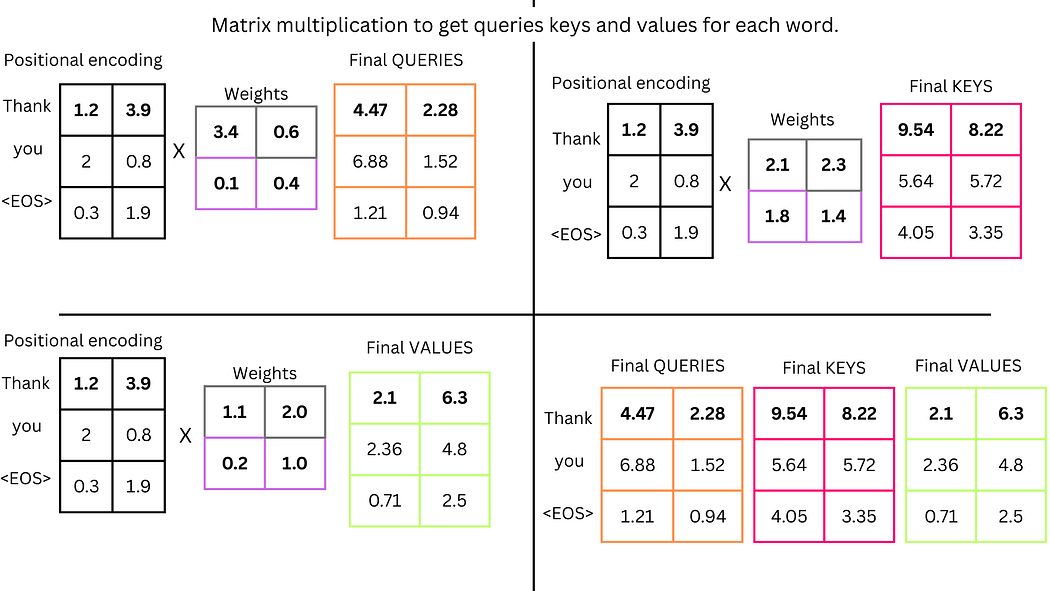
图8:查询、键、值向量的矩阵计算过程
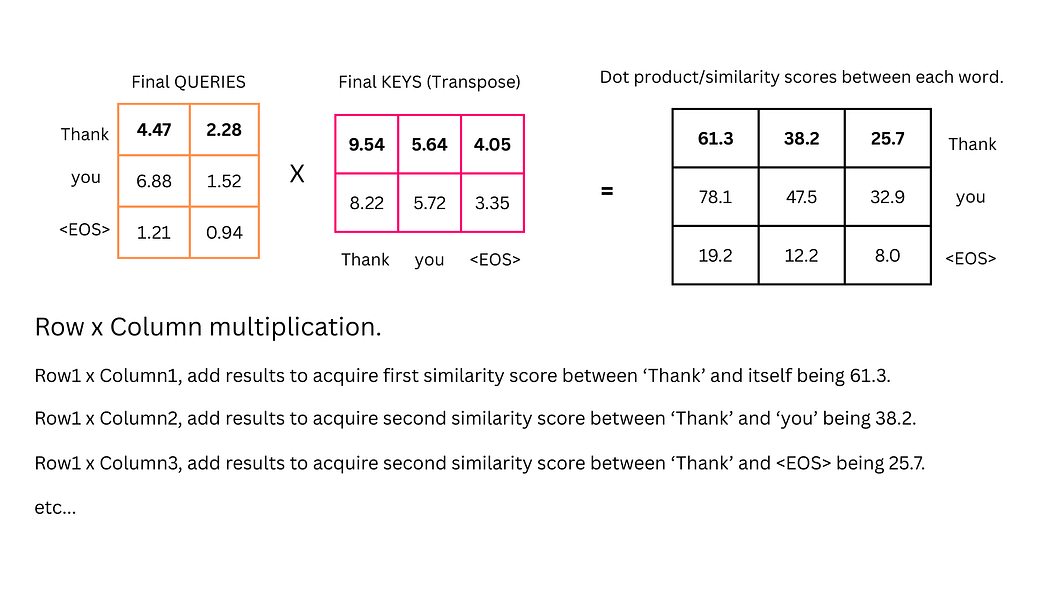
图9:键向量的转置操作(确保矩阵乘法维度匹配)
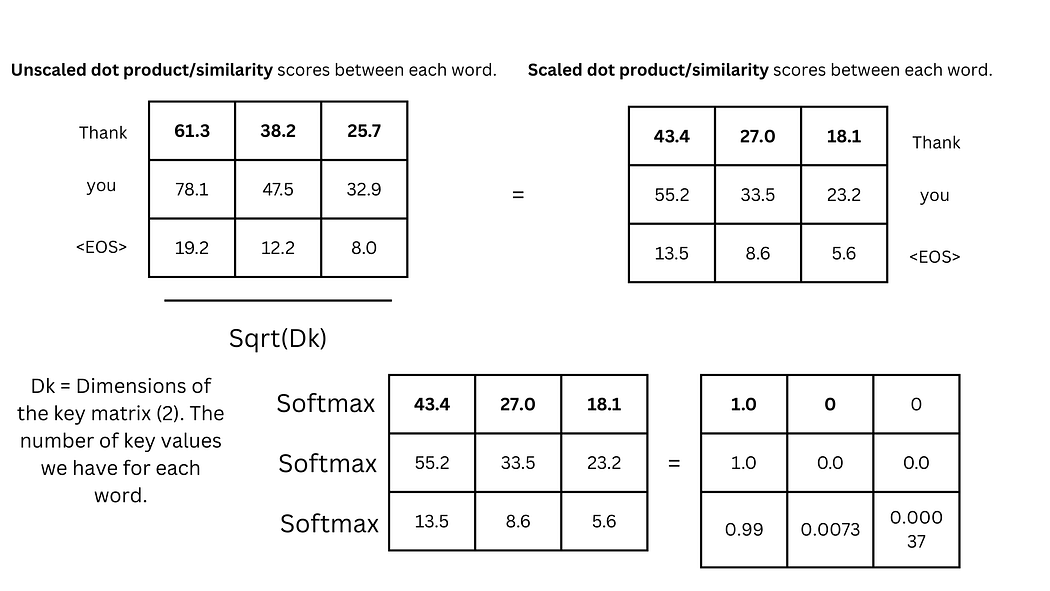
图10:缩放点积注意力的完整计算流程
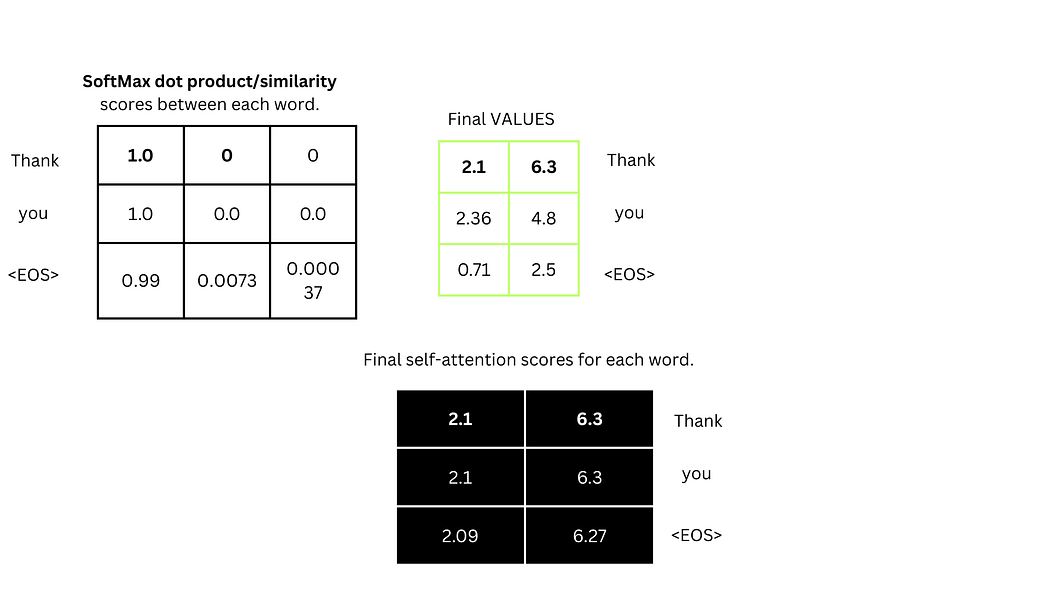
图11:自注意力分数与值向量的乘法运算
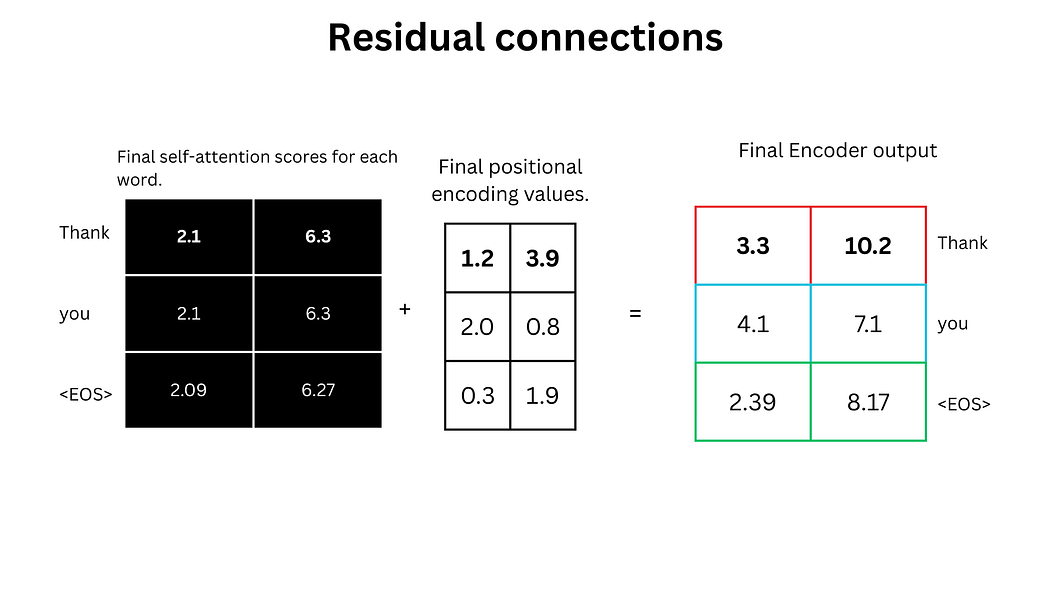
图12:残差连接与归一化操作示意图
编码器流程总结
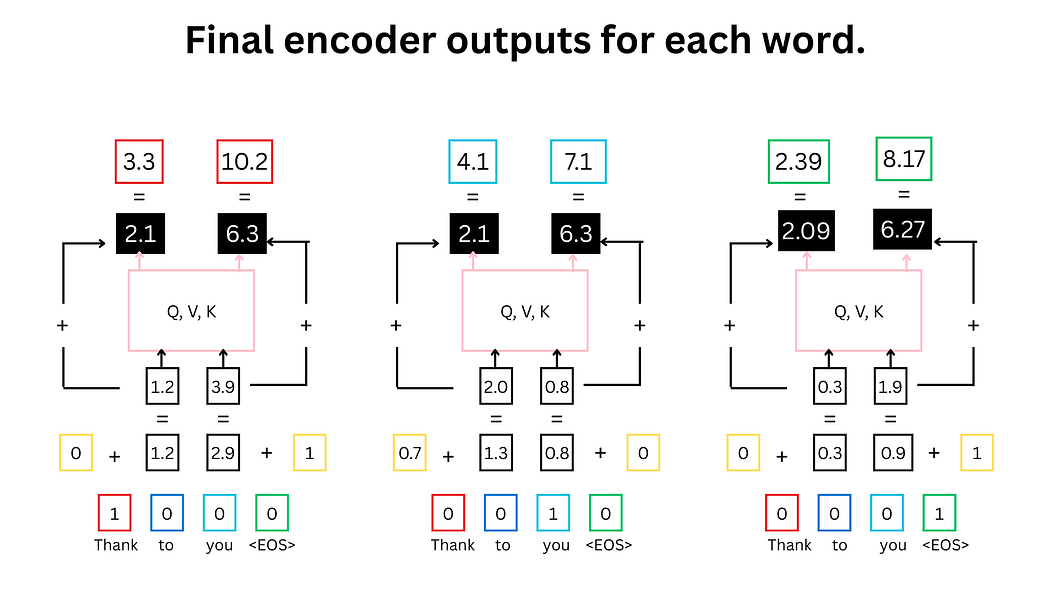
图13:编码器完整流程示意图
- 红色:输入标记"Thank";青色:输入标记"you";绿色:输入标记
<EOS> - 黄色:正弦/余弦波形点,与词嵌入值相加生成位置编码
- 粉色:缩放点积相似度与SoftMax计算区域
- 黑色:自注意力分数与位置编码的残差连接结果(最终编码器输出)
解码器部分
解码器负责生成输出序列,其流程与编码器类似,但增加了与编码器的交互机制,并通过掩码(Mask)防止训练时"窥视"未来词语。在训练阶段,解码器输入为预期输出序列(如"Arigato");在推理阶段,仅输入<SOS>标记,模型逐词生成后续内容。
解码器处理步骤
1. 词嵌入与位置编码
与编码器相同,解码器首先将输入词语(如<SOS>和"Arigato")转换为词嵌入向量,并添加位置编码。
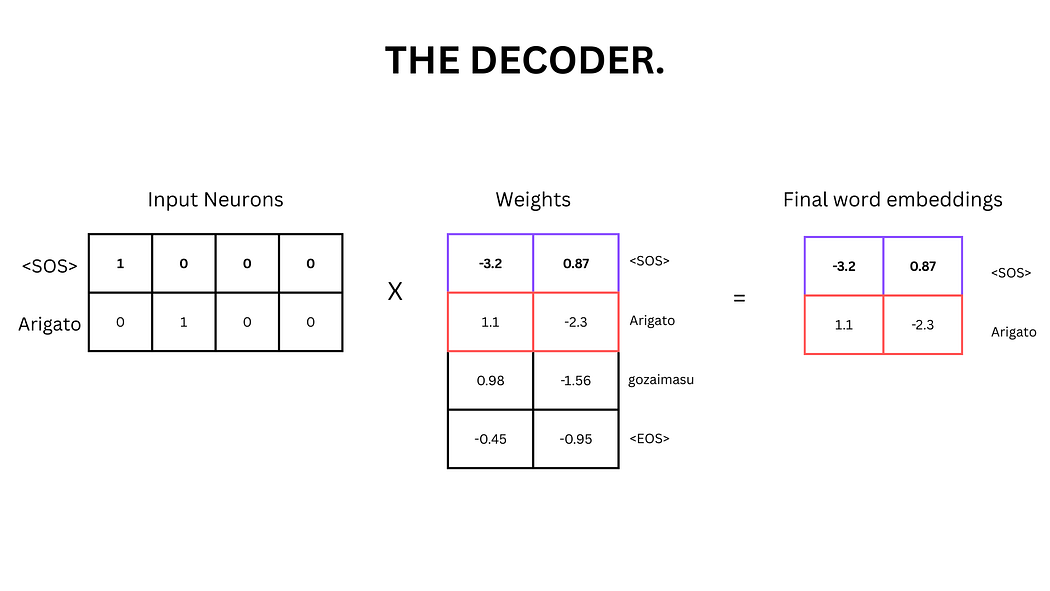
图14:解码器词嵌入的矩阵计算
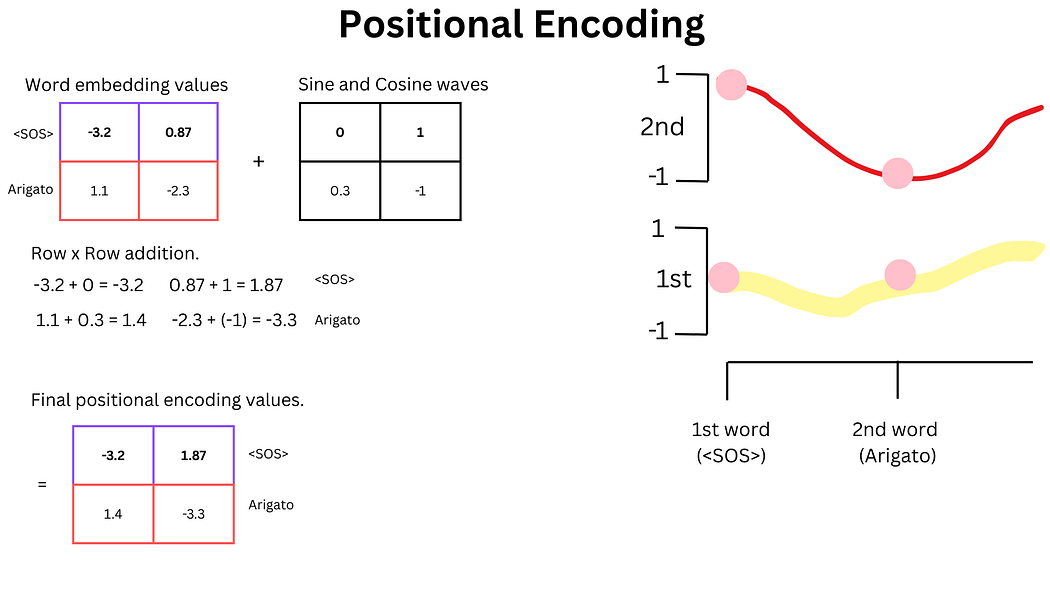
图15:解码器位置编码的计算(正弦/余弦波与词嵌入相加)
2. 自注意力机制(带掩码)
解码器的自注意力计算与编码器类似,但需通过前瞻掩码(Look-Ahead Mask) 屏蔽未来词语的信息。例如,计算<SOS>的注意力时,需忽略与"Arigato"的关联(将相似度分数设为负无穷),防止模型在训练时利用未来信息"作弊"。

图16:解码器查询、键、值向量的生成
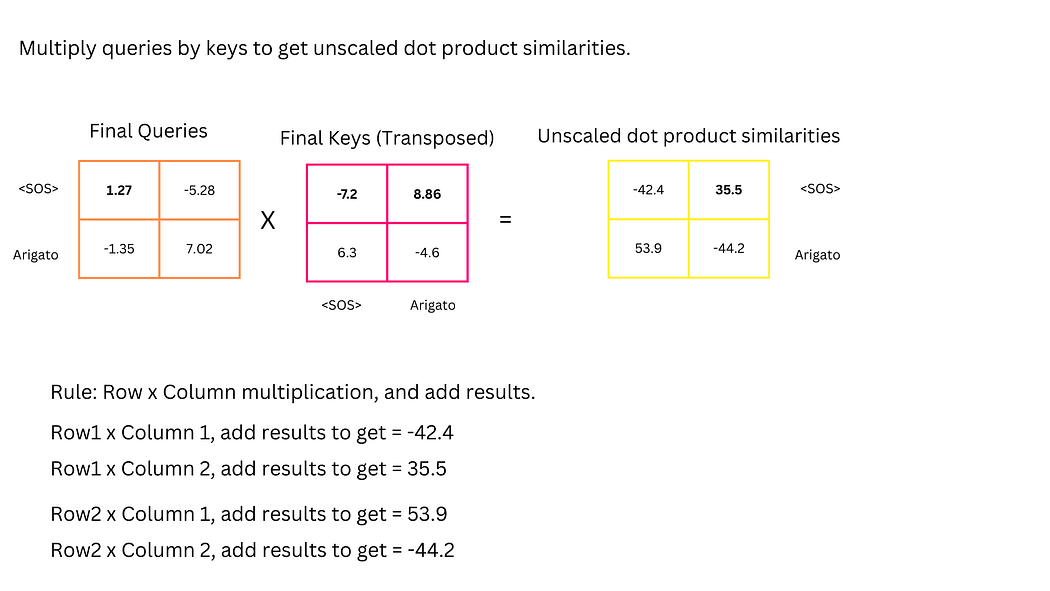
图17:解码器未缩放点积相似度的计算(含掩码区域)
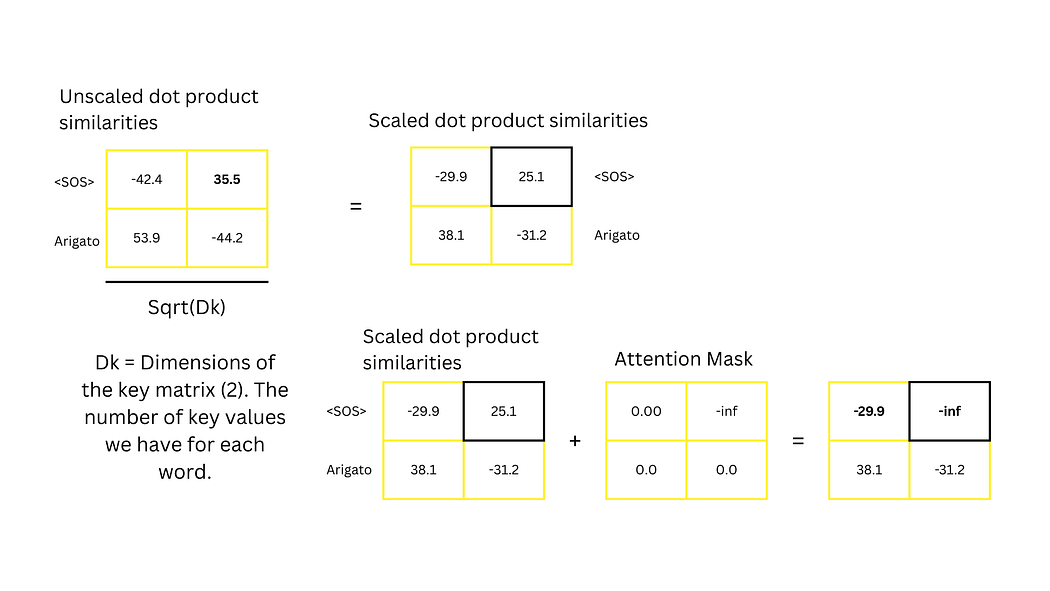
图18:缩放点积相似度的计算(除以键维度的平方根)
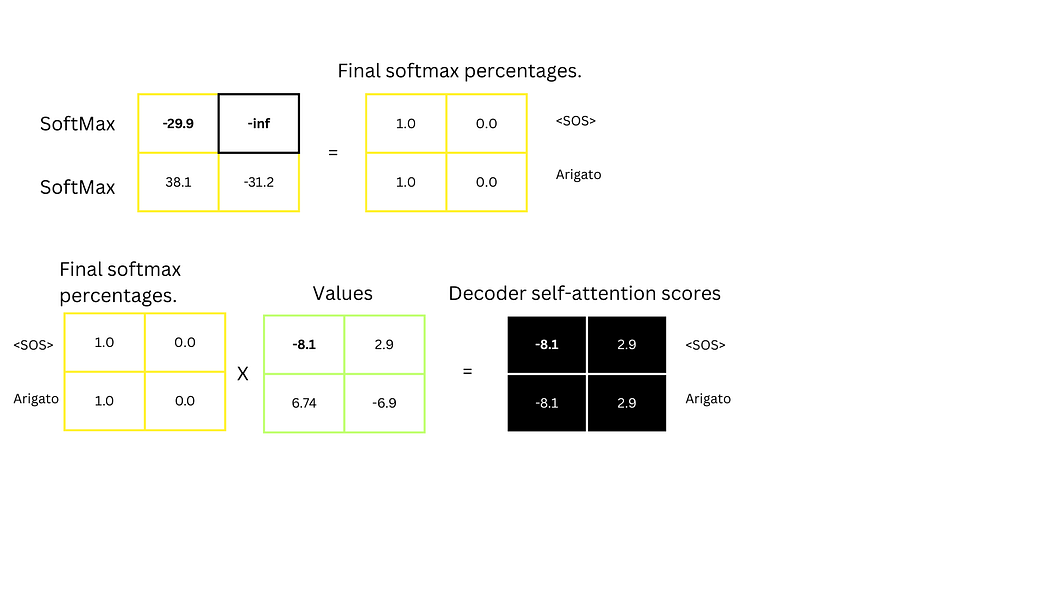
图19:解码器自注意力分数的计算(含SoftMax与值向量乘法)
3. 残差连接
与编码器一致,解码器的自注意力分数与位置编码值相加并归一化,形成解码器的中间输出。
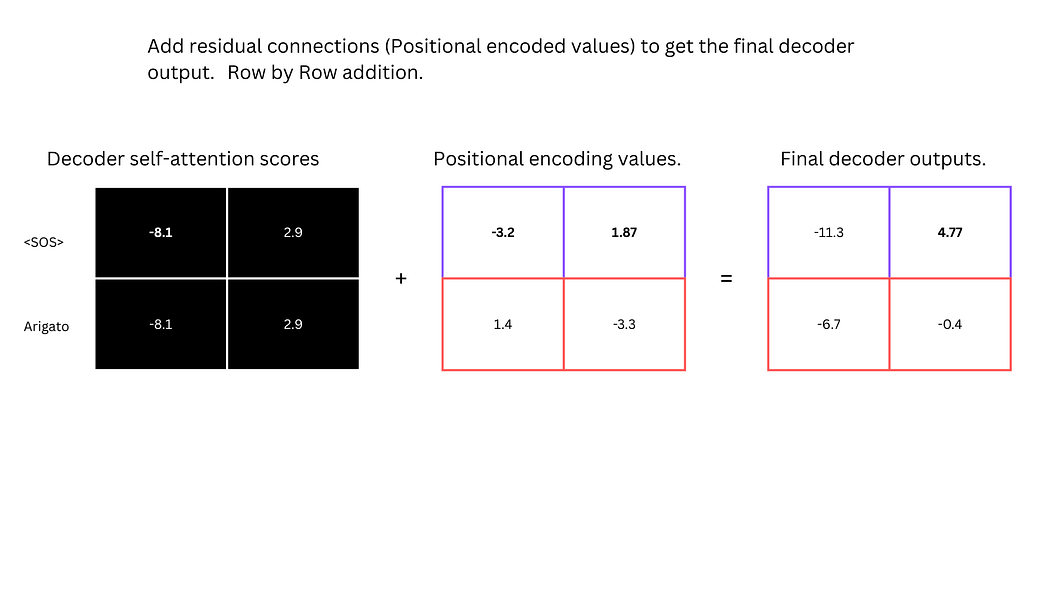
图20:解码器自注意力分数与位置编码的残差连接
解码器流程总结
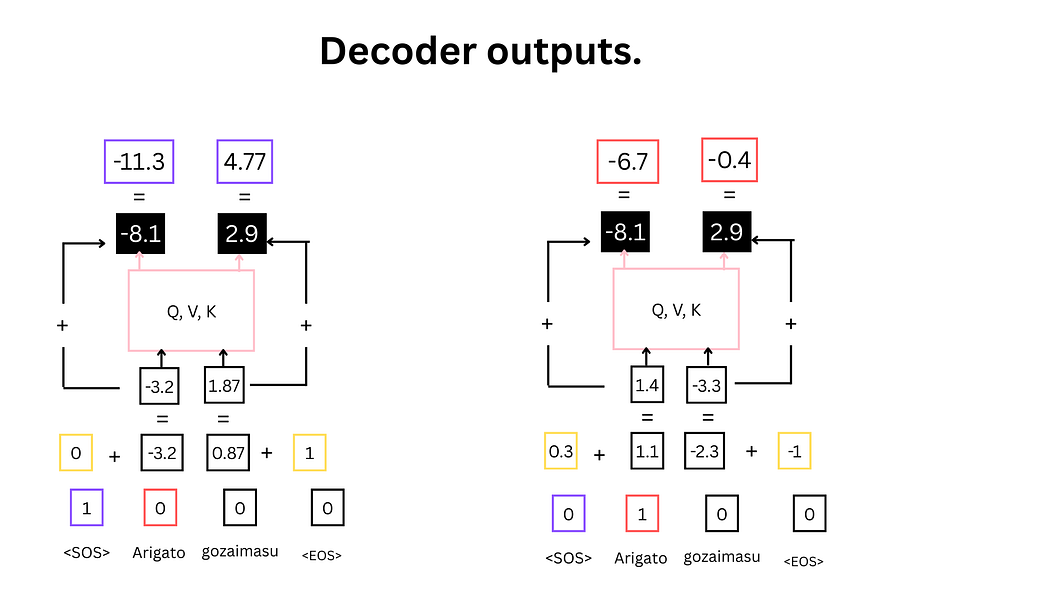
图21:解码器完整流程示意图
- 紫色:输入标记
<SOS>;红色:输入标记"Arigato" - 黄色:正弦/余弦波形点,用于生成位置编码
- 粉色:自注意力计算区域(含Q、K、V)
- 黑色:自注意力分数与位置编码的残差连接结果(解码器中间输出)
编码器-解码器注意力机制
该机制用于建立输入序列与输出序列的跨关联,具体步骤如下:
- 生成向量:从解码器中间输出生成查询向量(Q),从编码器输出生成键向量(K)和值向量(V)。
- 计算相似度:通过$ Q \cdot K^T / \sqrt{d_k} $计算缩放点积相似度。
- SoftMax与值乘法:将相似度转换为概率分布,与值向量相乘得到编码器-解码器注意力分数。
- 残差连接:将注意力分数与解码器中间输出相加并归一化,形成解码器的最终输出。
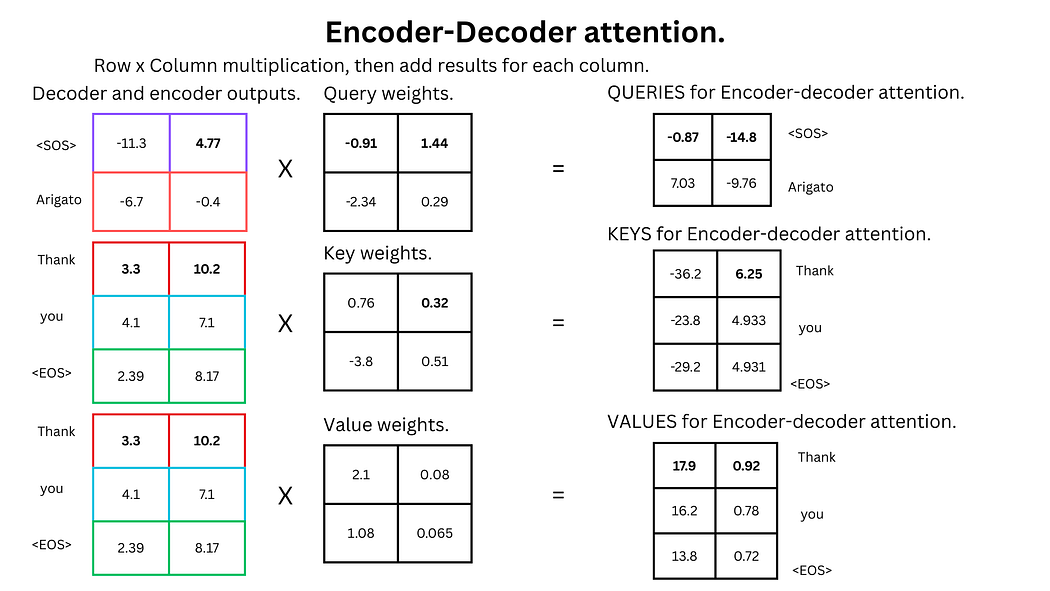
图22:编码器-解码器注意力的Q、K、V生成
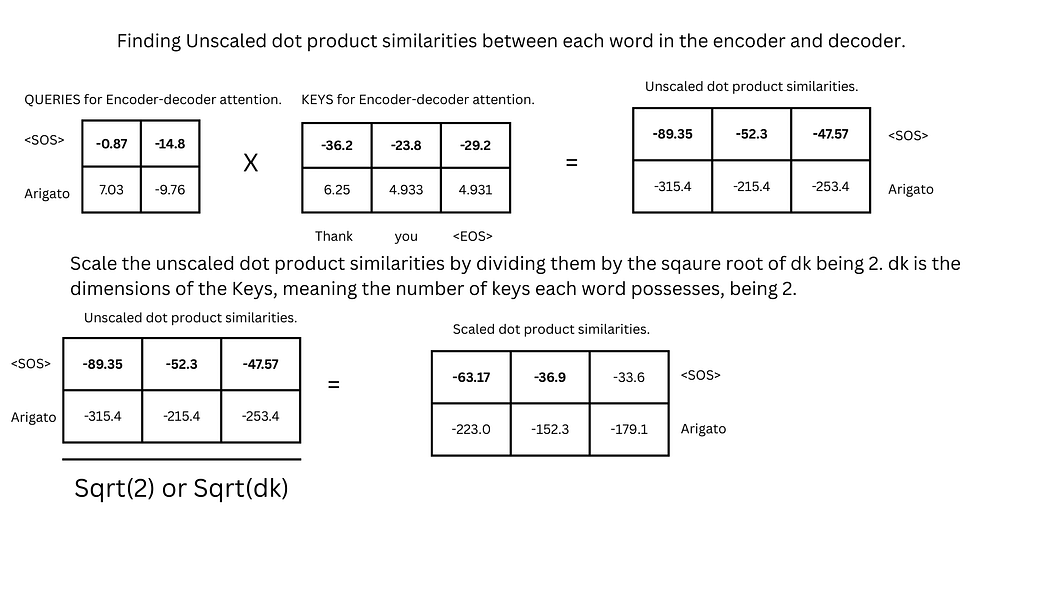
图23:编码器-解码器缩放点积相似度的计算
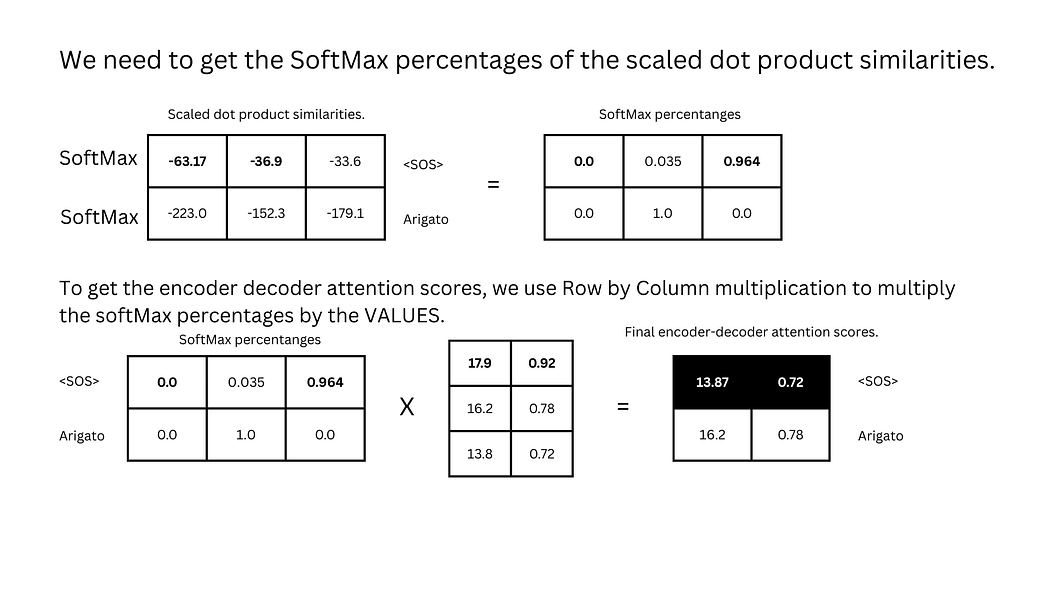
图24:编码器-解码器注意力分数的计算
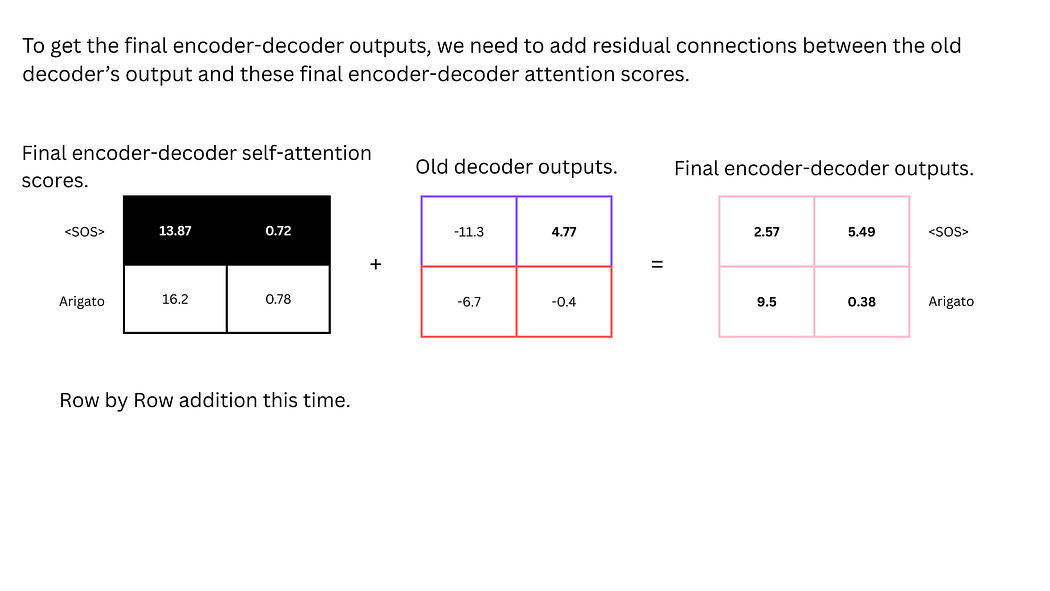
图25:编码器-解码器注意力分数与解码器中间输出的残差连接
编码器-解码器交互流程总结
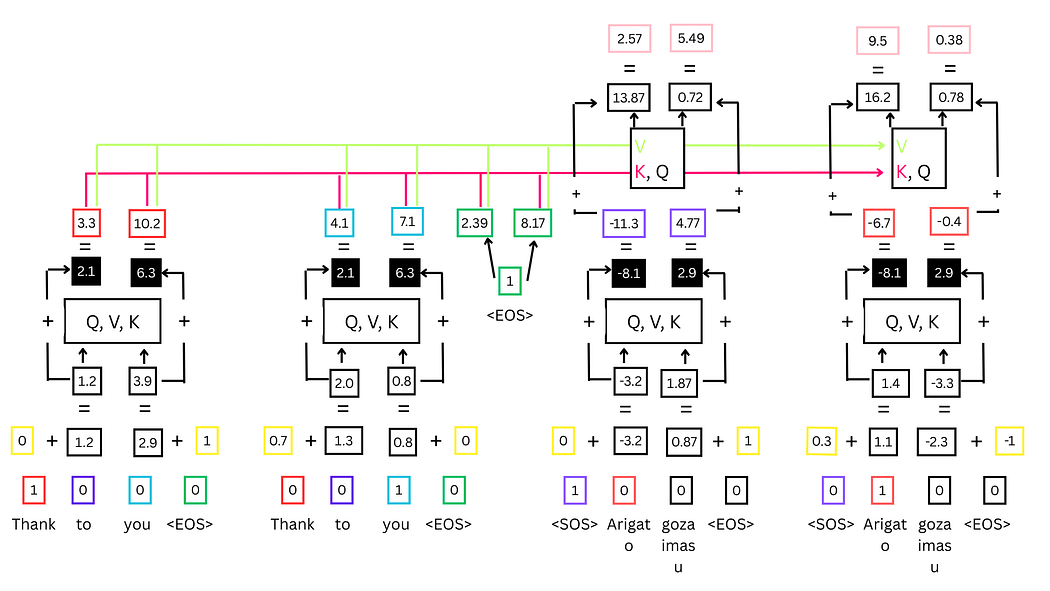
图26:编码器-解码器完整交互流程
- 左侧为编码器输出,右侧为解码器中间输出
- 黑色标注为编码器-解码器注意力分数与解码器输出的残差连接结果
最终预测过程
解码器的最终输出通过前馈神经网络映射到词汇表维度,经SoftMax函数得到概率分布,概率最高的词语即为预测结果。例如,在翻译任务中,模型最终预测"Arigato"作为"Thank you"的对应输出,并在后续步骤中预测<EOS>标记以终止序列生成。
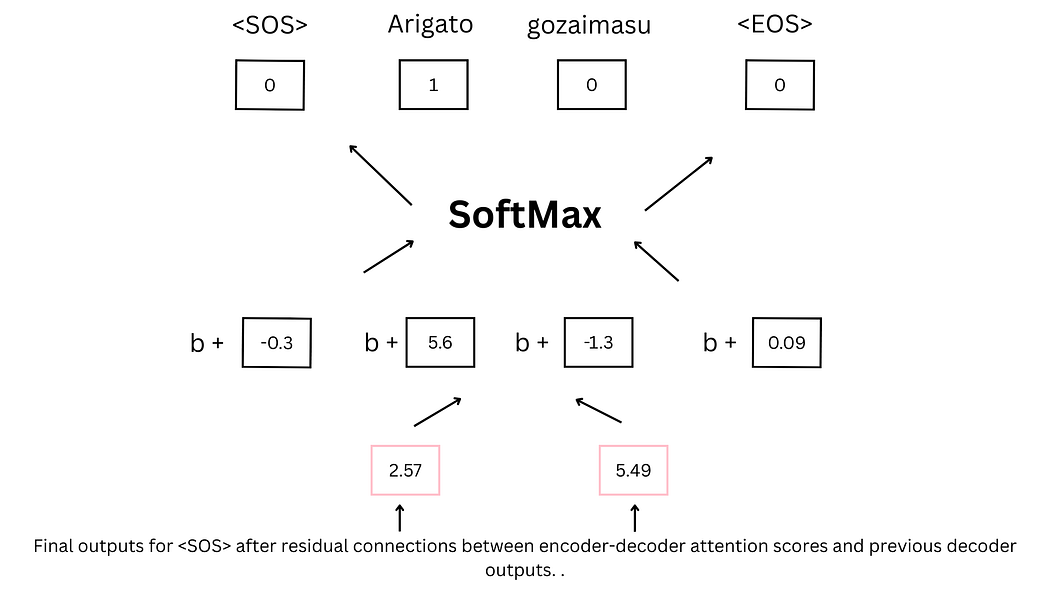
图27:前馈神经网络与SoftMax预测过程
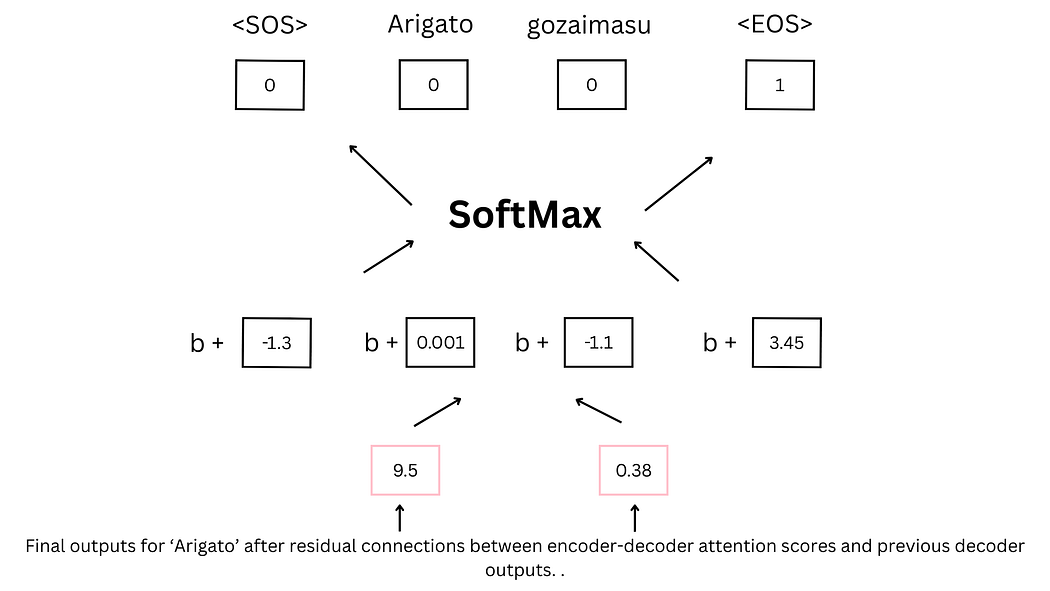
图28:<EOS>标记的预测(终止序列生成)
解码器预测流程总览
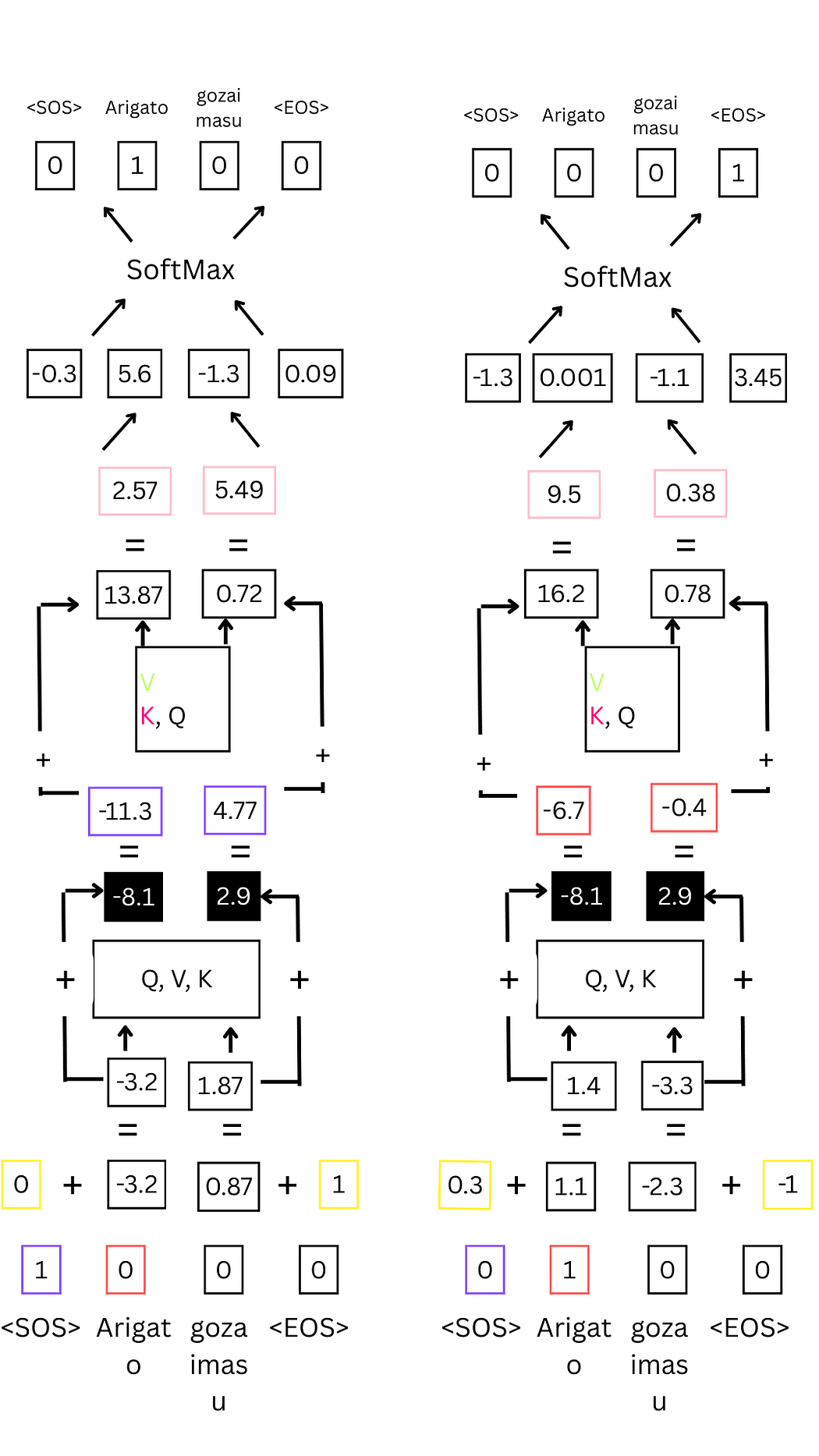
图29:解码器预测下一个词语的完整流程
- 输入标记(独热向量)→ 2. 词嵌入 → 3. 位置编码 → 4. 自注意力层 → 5. 自注意力值 → 6. 解码器中间输出(残差连接)→ 7. 编码器-解码器注意力层 → 8. 编码器-解码器注意力分数 → 9. 解码器最终输出(残差连接)→ 10. 前馈网络 → 11. SoftMax概率 → 12. 预测结果
总结
Transformer通过编码器与解码器的协同工作实现序列转换,其核心创新在于自注意力机制与编码器-解码器注意力机制,使模型能够捕捉长距离上下文关联。训练过程中,模型通过调整权重优化预测结果;推理时,基于<SOS>标记逐词生成输出,直至预测<EOS>终止。这一架构为现代大语言模型提供了强大的语义理解与生成能力,推动了自然语言处理领域的革命性进展。
原本地址:https://medium.com/@joshuaanang783/the-math-and-logic-behind-chatgpt-this-paper-is-all-you-need-57b82a0527f9