国家城乡建设规划部网站邢台专业网站建设价格
在讲解redis存储原理之前我们先来回答几个问题
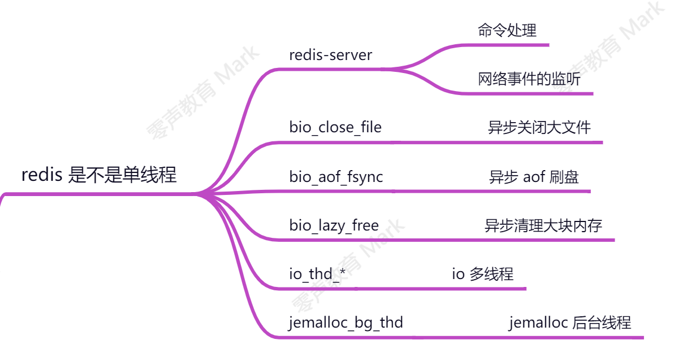
redis是不是单线程?
redis只有核心业务处理部分是单线程,即处理网络请求以及执行命令是单线程,同时也有异步和多线程的地方如下图
为什么在核心业务处理部分不使用多线程呢?
因为redis是数据结构数据库,有很多不同的数据结构,这种复杂的情况会导致加锁复杂,加锁力度不好控制。
redis存储结构
redis其实是用散列表的方式来存储key和value,具体结构如下图
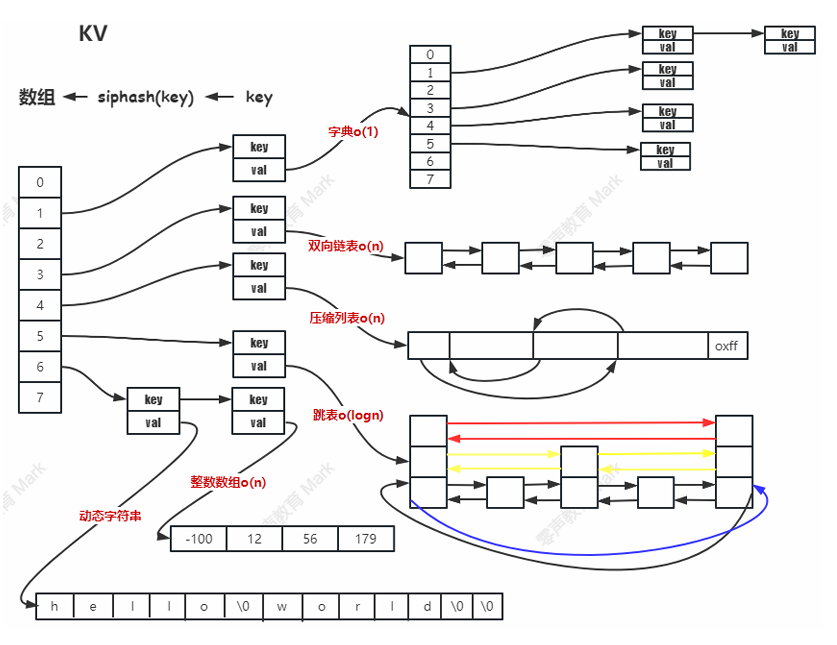
这里给大家讲一下怎么确定key的值,首先对key进行hash函数得到哈希后的key然后对散列表size取模得到key的序号,存入散列表中。
那么就有读者要问了,不同的key难道就不能得出相同的序号吗,当然是可以的,这种情况就叫做哈希冲突,
冲突
负载因子 = used / size ; used 是数组存储元素的个数, size 是数组的长度;负载因子越小,冲突越小;负载因子越大,冲突越大;
如果这种情况发生,value会像链表一样把数据链在后面,但是总不能看着散列表越来越长吧,这样查找value的时间复杂度会大大增加,所以我们要进行扩容
扩容
如果负载因子 > 1,则会发生扩容;扩容的规则是翻倍; 如果正在 size 是数组的长度; fork (在 rdb、aof 复写以及 rdb-aof 混用情况下)时,会阻止扩容;但是此时若负载 因子 > 5,索引效率大大降低, 则马上扩容;这里涉及到写时复制原理;
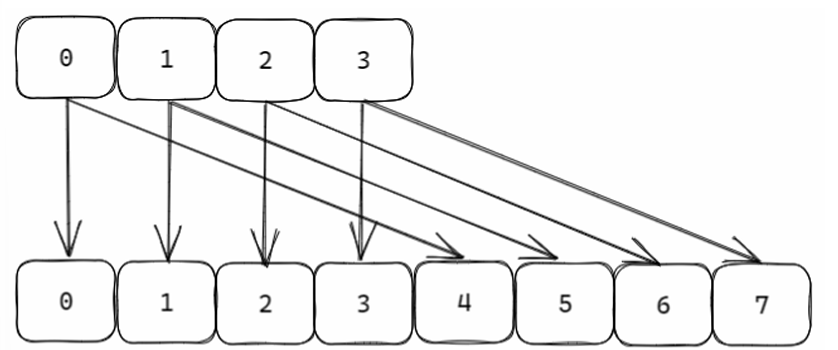
但是问题来了,如果我们原来列表中的数据很多,要是全部复制下来会很浪费时间,所以我们就有了渐进式的rehash
渐进式的rehash
当 hashtable 中的元素过多的时候,不能一次性 rehash 到 ht[1] ;这样会长期占用 redis,其他 命令得不到响应;所以需要使用渐进式 rehash;
rehash步骤: 将 ht[0] 中的元素重新经过 hash 函数生成 64 位整数,再对 ht[1] 长度进行取余,从而映射到 ht [1] ;
渐进式规则:
1. 分治的思想,将 rehash 分到之后的每步增删改查的操作当中;每执行一次增删查改带一次rehash
2. 在定时器中,最大执行一毫秒 rehash ;每次步长 100 个数组槽位;
处于渐进式 rehash 阶段时,是否会发生扩容缩容?
不会!
缩容
如果负载因子 < 0.1 ,则会发生缩容;缩容的规则是恰好包含 used 的 2的n次方; 恰好的理解:假如此时数组存储元素个数为 9,恰好包含该元素的就是 ,也就是 16;
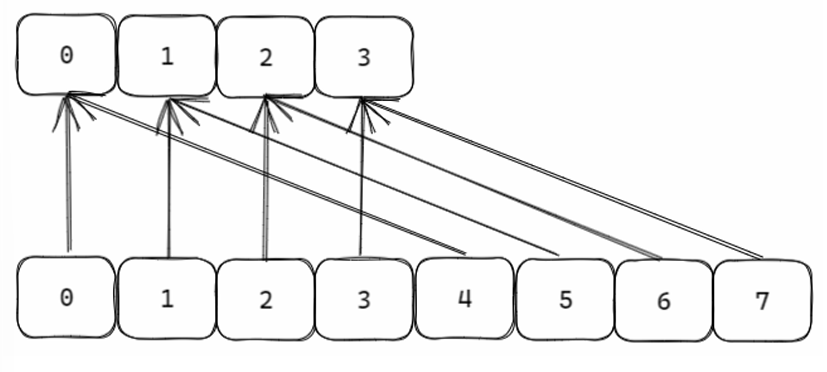
scan
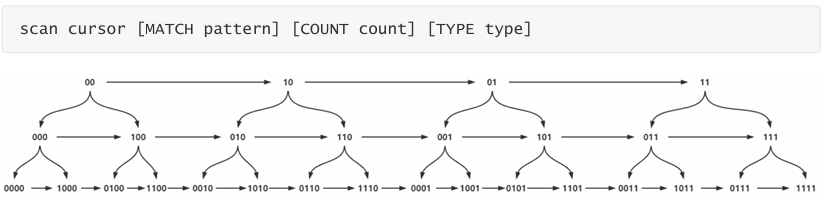
采用高位进位加法的遍历顺序,rehash 后的槽位在遍历顺序上是相邻的; 遍历目标是:不重复,不遗漏 ; 会出现一种重复的情况:在 scan 过程当中,发生两次缩容的时候,会发生数据重复;
value编码

这里需要额外讲一下跳表
跳表
跳表其实是在链表上实现类似二分的搜索
跳表(多层级有序链表)结构用来实现有序集合;鉴于 redis 需要实现 zrange 以及 zrevrange 功能;需要节点间最好能直接相连并且增加删除改操作后结构依然有序;B+ 树时间复杂度为 h * O(log₂n),鉴于 B+ 复杂的节点分裂操作;
时间复杂度:
有序数组通过二分查找能获得 O(log₂n) 时间复杂度;平衡二叉树也能获得 O(log₂n) 时间复杂度;
理想跳表:
每隔一个节点生成一个层级节点;模拟二叉树结构,以此达到搜索时间复杂度为 O(log₂n);
空间换时间的结构;
但是如果对理想跳表结构进行删除和增加操作,很有可能改变跳表结构;如果重构理想结构,将是巨大的运算;考虑用概率的方法来进行优化;从每一个节点出发,每增加一个节点都有 1/2 的概率增加一个层级,1/4 的概率增加两个层级,1/8 的概率增加 3 个层级,以此类推;经 过证明,当数据量足够大(128)时,通过概率构造的跳表趋向于理想跳表,并且此时如果删除节点,无需重构跳表结构,此时依然趋向于理想跳表;此时的时间复杂度为 (1 - 1 / nᶜ) * O(log₂n);
redis跳表
从节约内存出发,redis 考虑牺牲一点时间复杂度让跳表结构更加紧凑,就像二叉堆改成四叉堆结构;并且 redis 还限制了跳表的最高层级为 32;
节点数量大于 128 或者有一个字符串长度大于 64,则使用跳表(skiplist);
redis io多线程功能工作原理
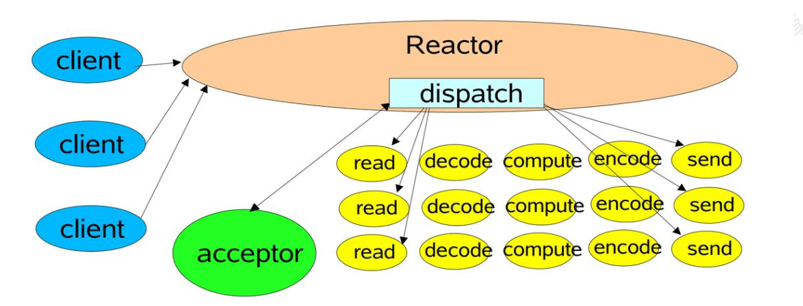
客户端给redis服务器发送具体命令,redis使用reactor模型来处理这些命令,分发给read流程来处理,如果命令过多,才会又多线程处理
为什么redis选择64字节/44字节作为字符串分界线?
1.编码选择规则
字符串长度 ≤ 44 字节:使用 embstr 编码(嵌入字符串到 redisObject 中)。
字符串长度 > 44 字节:使用 raw 编码(redisObject 中保存指针指向堆上数据)。
2.embstr 与 raw 的区别
embstr:redisObject 与字符串数据连续存储,分配一次内存。
raw:redisObject 存在栈或堆上,字符串数据单独分配在堆上。
3.选择 64 字节的原因
内存分配器一般按照 2^n(2, 4, 8, 16, 32, 64, ...)分配内存块。
CPU cache line 最小访问单位是 64 字节,这样能减少内存访问延迟。
4.内存占用计算
redisObject 占 16 字节。
64 字节限制下,字符串部分用 SDS(Simple Dynamic String) 存储:
SDS 头部(sdshdr8)占 3 字节(len 1B、alloc 1B、flags 1B)。
字符串末尾有 '\0' 占 1 字节。
可用字符串长度 = 64 - 16(redisObject) - 3(SDS 头) - 1(\0) = 44 字节。
5.最终结论
44 字节是 embstr 编码的最大字符串长度,超过则用 raw 编码。
64 字节作为分界是为了对齐内存分配块、利用 CPU cache line、减少内存分配次数。
更多资料在:https://github.com/0voice查询