Linux的Ext文件系统:硬盘理解和inode及软硬链接
文章目录
- 前言
- 理解硬件——磁盘
- 磁盘的物理结构
- 基本结构
- 磁盘的存储构成
- 磁盘的逻辑结构
- 文件系统
- Ext2文件系统
- 块组的内部结构
- 文件操作,文件系统要做什么?
- 现在如何理解“目录” ?
- 软硬链接
- 如何理解硬链接?
- 硬链接应用场景
- 如何理解软链接?
- 软链接应用场景
前言
通过对基础IO的学习,我们已经掌握Linux操作系统是如何管理被打开的文件了,那么更多的未打开文件呢?它们是如何在磁盘中被分门别类的被管理起来的呢?
我们知道,文件 = 文件内容+文件属性,那么磁盘上存储文件 = 存文件内容+ 存文件属性。
对于操作系统来说:
- 文件内容:数据块
- 文件属性:inode
也就意味着:Linux的文件在磁盘中存储,属性和内容是分开存储的!
理解硬件——磁盘
在计算机中,没有被打开的文件都是存储在磁盘中,当需要对文件进行操作时,会通过 inode 对文件进行访问。
通过以下指令查看当前目录中文件的详细信息及 inode 值
ls -li
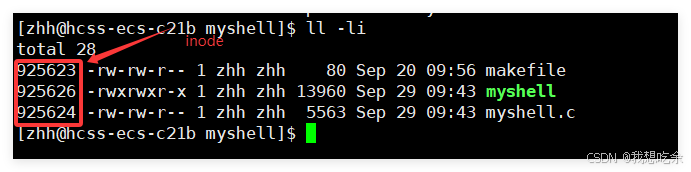
inode与文件的关系与进程与pid一样(文件未被硬链接的情况下),都是唯一对应的。
磁盘的物理结构
现在市面上的磁盘主要分为
- 机械硬盘:一种永久存储介质,读取速度慢,但便宜、稳定、容量更大
- 固态硬盘:非永久存储介质,读取速度快,价格较高且数据易损
像我们日常使用的笔记本电脑一般用的就是固态硬盘,因为笔记本电脑经常移动,如果使用机械硬盘很容易因为磕磕碰碰干扰机械磁盘的机械运动(非常精细的运动,很容易被影响),导致磁盘损坏,数据丢失。
机械硬盘一般用于公司级的数据存储,因为他们需要永久存储数据且几乎不会去移动机械磁盘。
本文主要探究机械磁盘。
基本结构
机械磁盘是计算机唯一的一个机械设备。
结构主要包括以下几种:
- 盘片:一片两面,每一面都可以存储数据,有一摞盘片
- 磁头:一面配备一个磁头,专门用于读取盘面中的数据
- 主轴:用于控制整块盘的转动
- 音圈马达:控制磁头的进退
- 磁头臂:链接磁头与音圈马达
- 伺服电路板:控制读取数据的流向及各种结构的运行
- ……

机械磁盘的工作原理:
机械磁盘工作原理
磁盘的存储构成
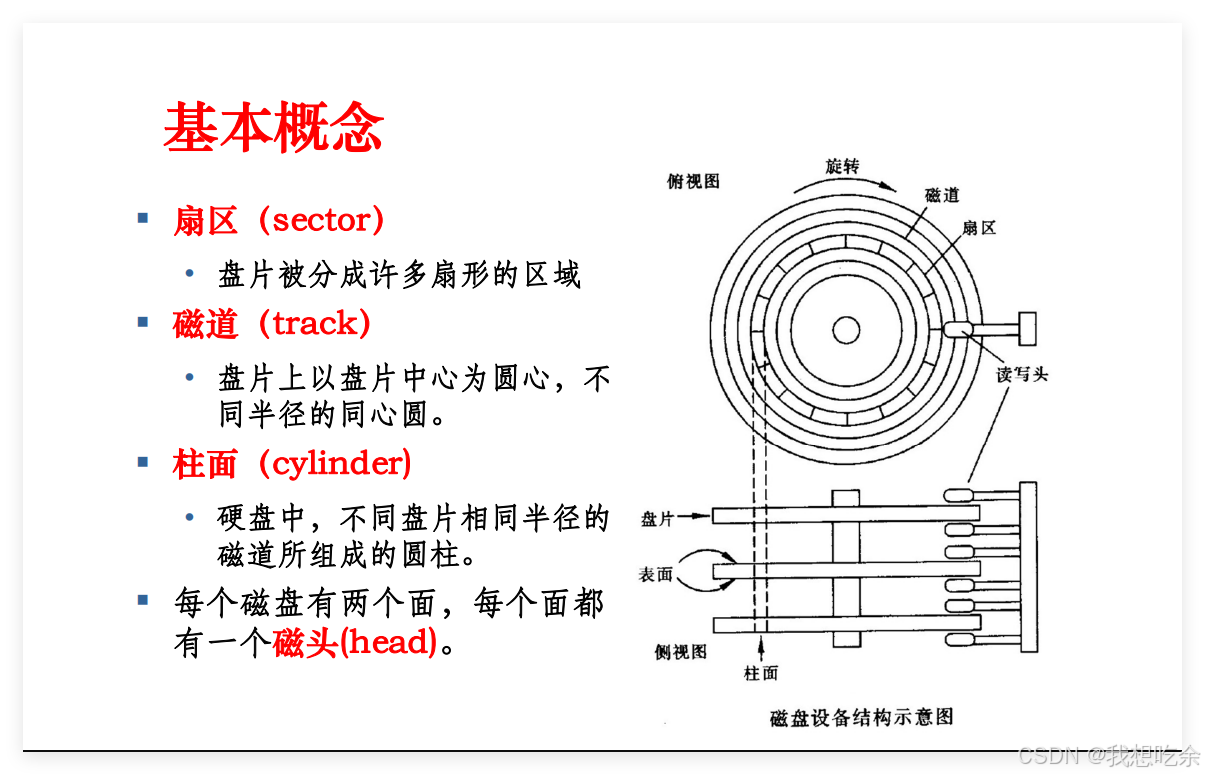
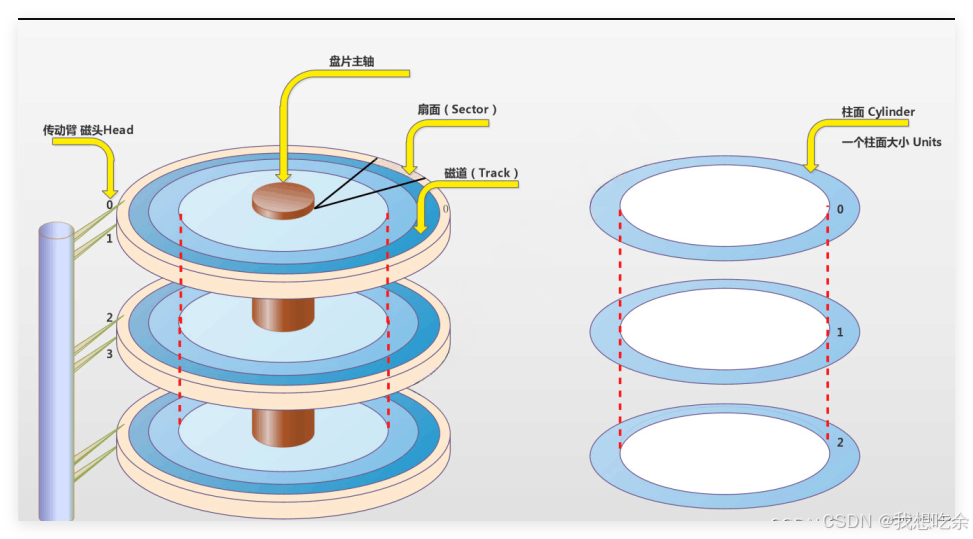
在盘面设计上,一个盘面被切割若干个扇区,单个扇区大小为 512 字节/4 kb,这些扇区用来存储数据,同一半径中的所有扇区组成扇面;而半径相同的扇区组成磁道(柱面)。
CHS(cylinder柱面 head磁头 sector扇区)寻址法:
可以先根据磁头(head)确定盘面,再根据半径定位磁道(柱面 cylinder),最后根据块号确定扇区(sector)
磁盘的逻辑结构
线性存储
磁带大家见过吧?你有没有把磁带扯出来玩过呢?

磁带上⾯可以存储数据,我们可以把磁带“拉直”,形成线性结构

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种逻辑扇区地址叫做LBA地址
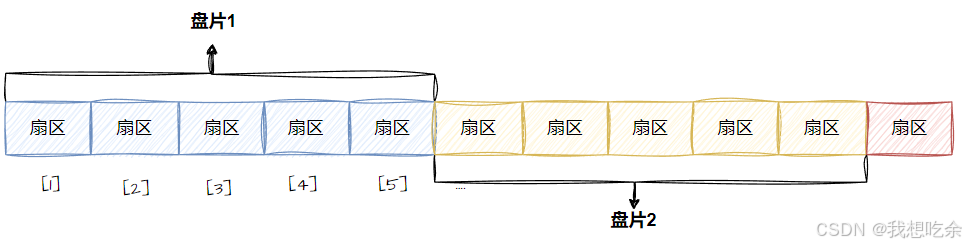
真实过程
⼀个细节:传动臂上的磁头是共进退的
所以,磁盘的真实情况是:
-
磁道

即一维数组 -
柱面
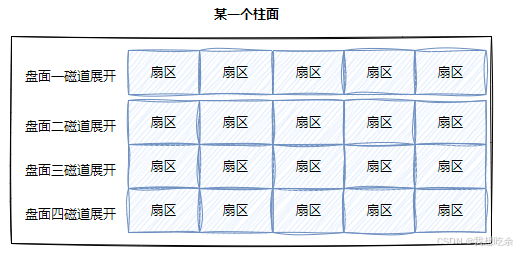
柱面上的每个磁道,扇区个数都是一样的
即⼆维数组 -
整盘
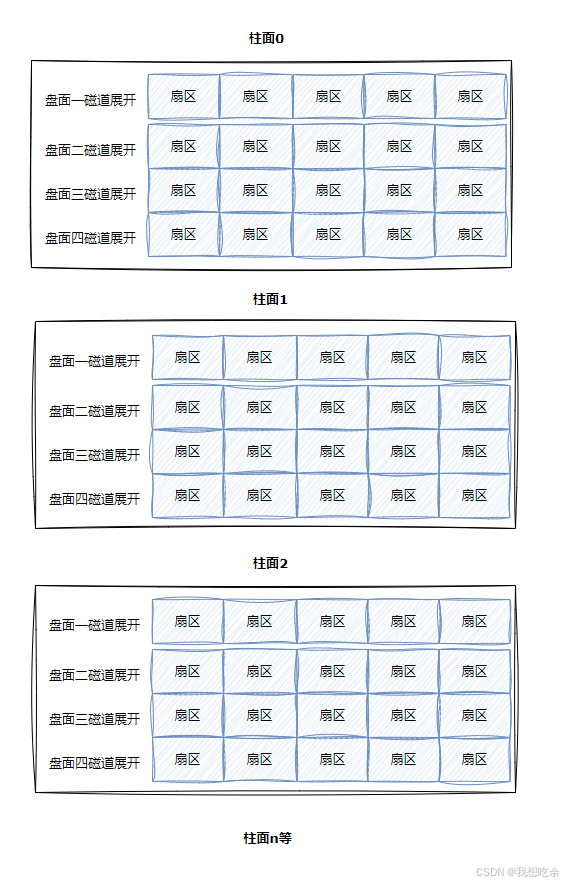
整个磁盘就是多张⼆维的扇区数组表,即三维数组。
所以,OS只需要使⽤LBA就可以了!!LBA地址可以转成CHS地址,CHS又可以转换成为LBA地址。谁做啊??磁盘自己来做!
扩展知识:其实不仅仅CPU有“寄存器”,其他设备(外设)也有,包括磁盘。
磁盘大致包括这几类寄存器:
- 控制寄存器:负责控制磁盘的r/w(IO的方向)
- 数据寄存器:负责运输磁盘的数据
- 地址寄存器:负责存储LBA地址
- 状态寄存器:负责存储磁盘的结果
文件系统
磁盘分区
磁盘容量通常都是非常大的,若我们以512G的磁盘为例,一个扇区的大小通常为512字节,那么该磁盘可被分为十亿多个扇区。
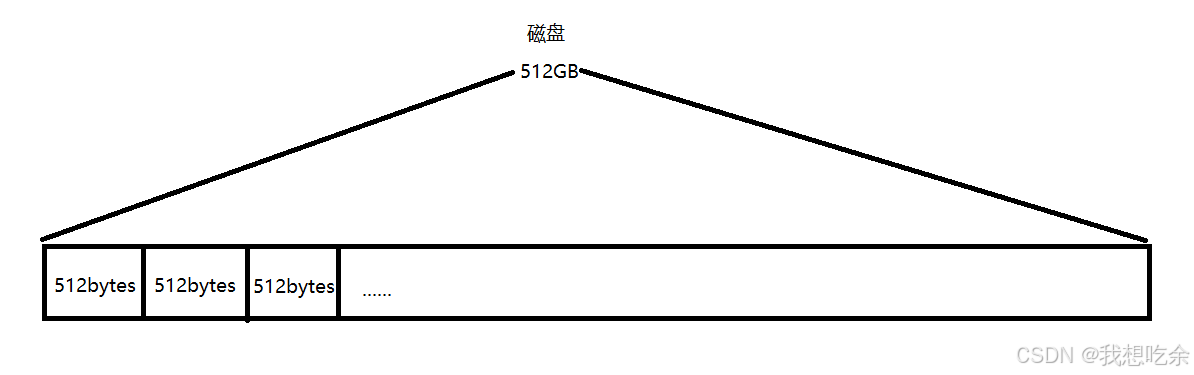
计算机为了降低OS的管理成本,对磁盘进行了分区,在现实生活中这种管理方法比比皆是,如学校需要将不同专业的学生及老师分为不同学院,比如管理学院、信息工程学院等。如此,上层管理者更好的调用管理资源,这种方法被称为分治
像window下,磁盘一般就被分为C盘和D盘两个区:
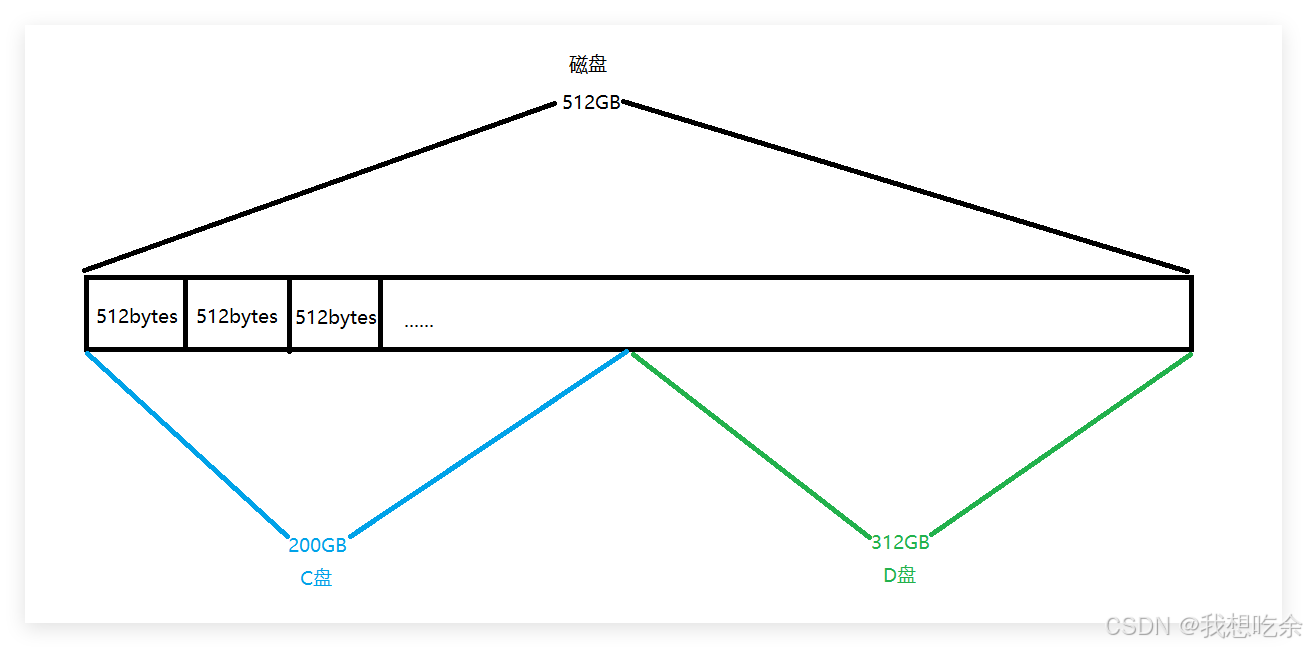
在文件系统中,OS 先将整个大文件系统分为不同的区,存入 struct disk 数组中进行管理:
struct disk
{struct part[2];//……
};可以通过 ll /dev/vda* -i 查看当前系统中的分区详细信息:

磁盘格式化
系统在分区后,需要对区块进行格式化 。
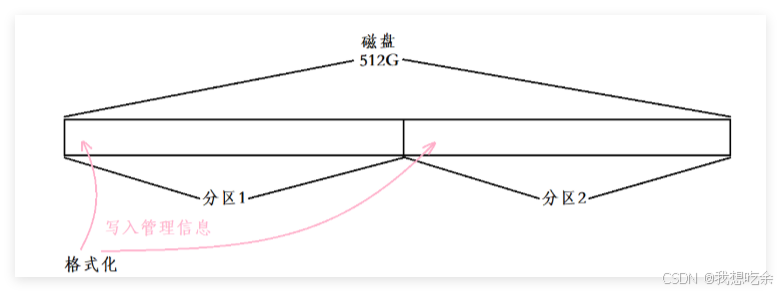
一句话:每一个分区在被使用之前,都必须提前先将部分文件系统的属性信息提前设置到对应的分区中,方便我们后续使用这个分区
其中,写入的管理信息是什么是由文件系统决定的,不同的文件系统格式化时写入的管理信息是不同的,常见的文件系统有EXT2、EXT3、XFS、NTFS等。本文研究的是Ext2文件系统。
那写入的Ext2文件系统信息具体是啥呢?有什么用呢?这是本文重点研究的内容。
Ext2文件系统
为了更高效的管理,对于每一个分区来说,分区的头部会有一个启动块(Boot Block),然后对于其他区域,文件系统将其全部划分为一个一个的块组(Block Group)。如下图所示:
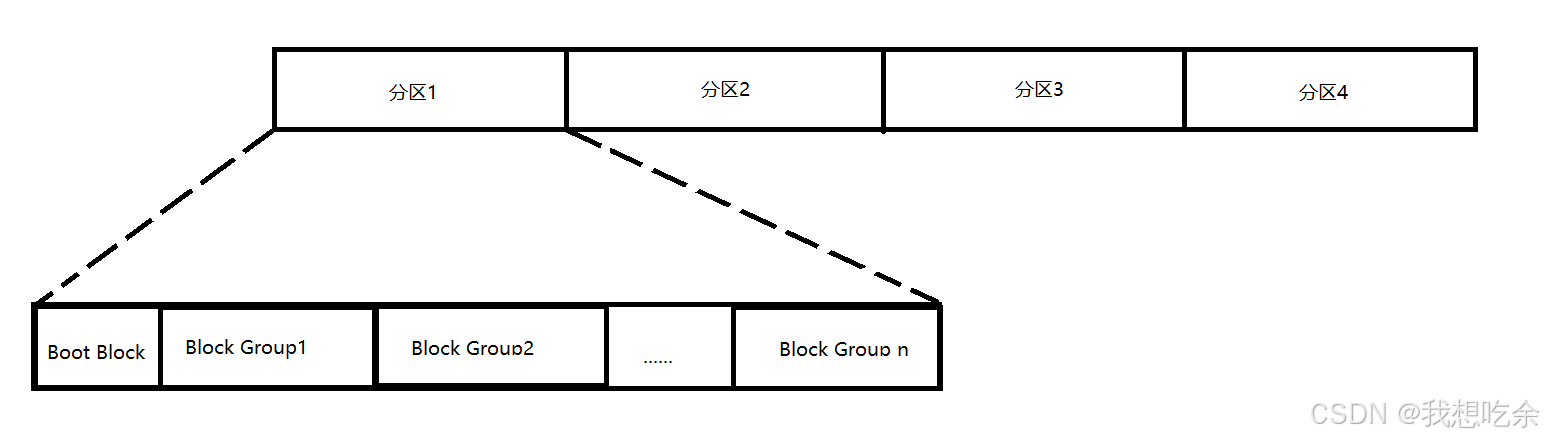
注意:启动块的大小是确定的,而块组的大小是由格式化的时候确定的,并且不可被修改 。
块组的内部结构
每个块组都有着相同的组成结构,它们按照先后顺序分别为:超级块(Super Block)、块组描述符表(Group Descriptor Table)、块位图(Block Bitmap)、inode位图(inode Bitmap)、inode表(inode Table)以及数据表(Data Block)组成。
如图:
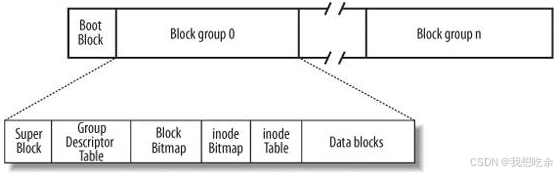
下面一一介绍它们的功能:
- Data blocks:存储文件内容的区域,以块(一般是4kb大小)为基本单位。
注意:一般而言,一个块只存储一个文件的内容 - inode Table:存储文件的属性inode,这个块大小为128字节
这里重点介绍一下inode:一个文件的所有属性,它是以结构体的形式存在的,大致内容如下:
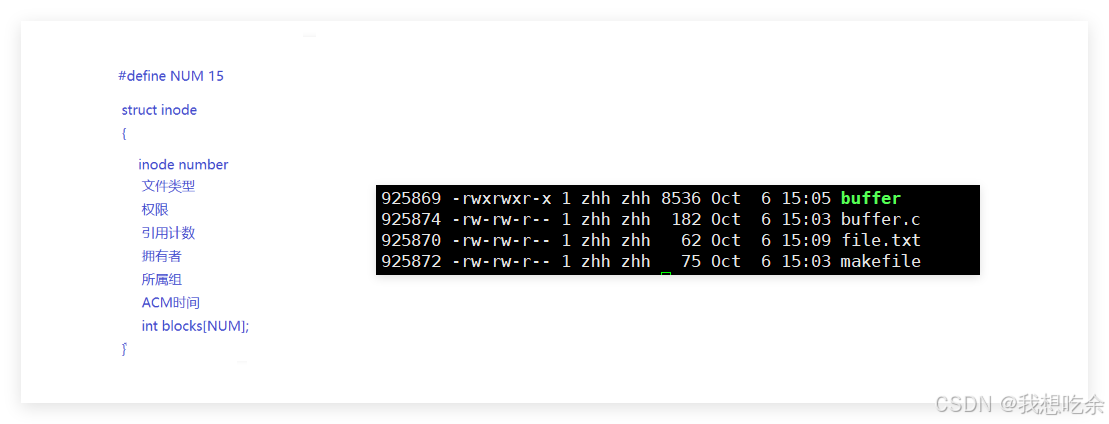
这里的引用计数是硬链接数,后文会讲解。
那这里的blocks整型数组是什么呢?
它代表的是文件内容在Data blocks所占用的块的块号!
看图:
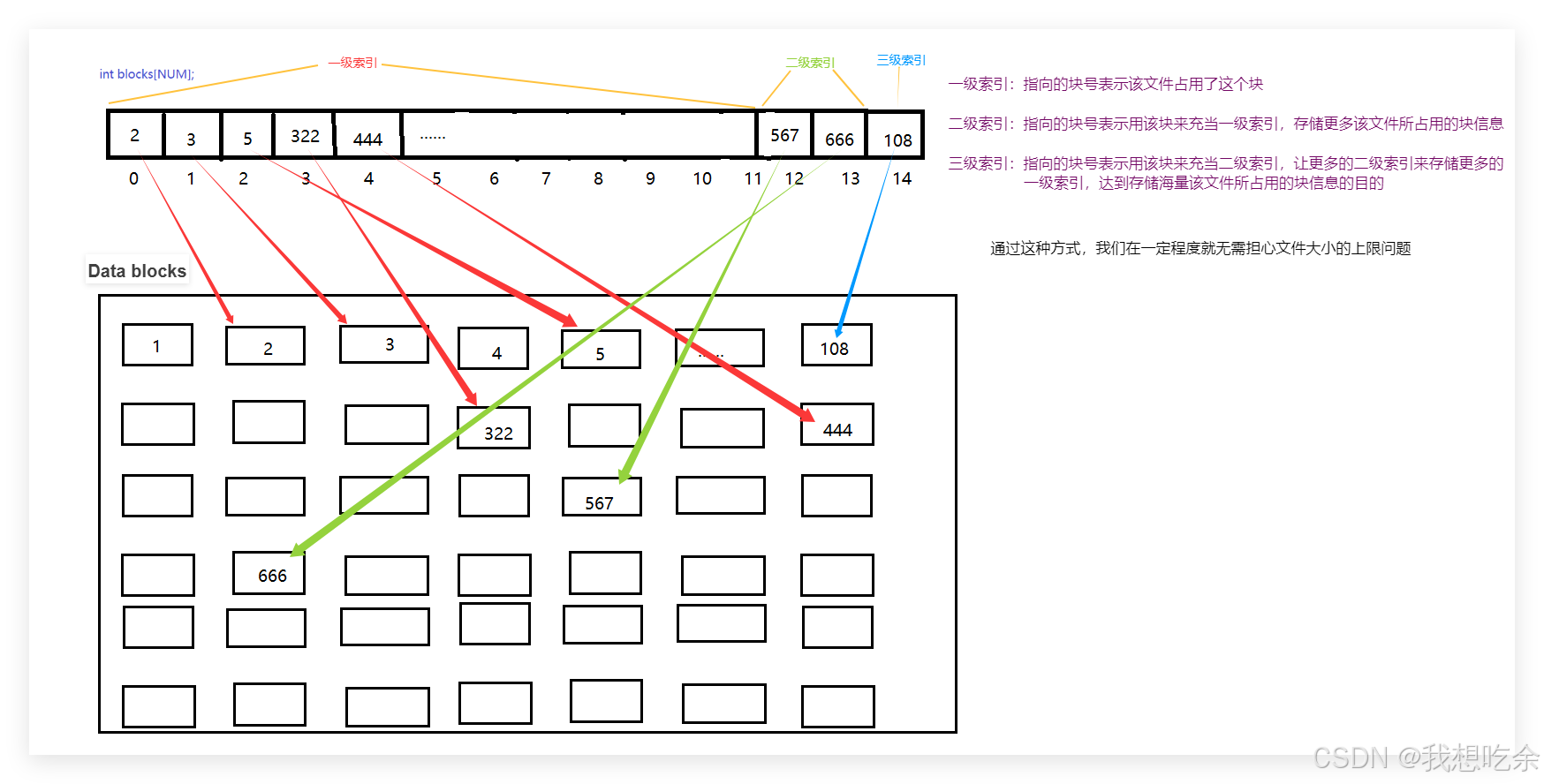
注意:二级三级索引指向的块不是文件内容,该块用来继续存储我们的文件内容所需的块号。 - inode Bitmap:采用的是位图的思想,将比特位的位置和inode编号映射起来,比特位的内容表示对应的inode是否有效。
- Block Bitmap:采用的也是位图的思想,将比特位的位置和块号映射起来,比特位的内容表示对应的块是否被使用。
- 有了Block Bitmap,我们删文件的时候就不需要真的去清除数据了,只需要将这个文件所占用的块号所对应的比特位均改为0即可,表示为可覆盖的块。
- Group Descriptor Table:块组描述附表,用来存储块组的详细信息。
- Super Block:存放文件系统的基本信息,包含的是整个分区的基本使用情况,比如:
- 一共有多少组
- 每个组的大小
- 每个组的inode数量
- 每个组的block数量
- 每个组的起始inode
- 文件系统的类型与名称
- ……
计算机是通过Super Block来获取分区的使用情况的,因此并不是每个块组都存在Super Block,只要存在几个块组存在即可。
原因如下:
我们无法保证磁盘一定不会数据丢失,如果一个分区丢失了一个块组的Super Block,计算机会寻找该分区的下一个块组的Super Block用来获取分区的使用情况,如果只有一个,该分区就报废了。
这里有个细节:文件属性和文件内容是挨着存储的,为什么呢?
因为机械磁盘的CHS寻址法本质是以磁头与盘面的运动来完成的。众所周知,运动越少,效率越高,所有在软件设计上,设计者一定是有意识的将相关数据存放在一起。
文件操作,文件系统要做什么?
在Linux系统中,一个文件对应一个inode。每一个inode都有自己的inode编号
谨记:
- inode的设置,是以分区为单位的,不能跨分区。也就是说,不同分区可能出现相同inode的文件。
- 文件名并不属于inode的属性。文件名是给用户看的,系统只看文件inode。
新建一个文件,系统要做什么?
- 系统会在inode Table中创建一个新的inode,描述该新文件的全部属性
- 然后再inode Bitmap中将该新文件inode对应的比特位设置为1,示为有效inode。
删除一个文件,系统要做什么?
- 系统会在Block Bitmap中将该文件所有占用的块所对应的比特位设置为0.
这些块号从inode中的blocks数组中获取 - 然后再inode Bitmap中将该文件inode对应的比特位设置为0,示为无效inode。
查找一个文件,系统要做什么?
利用inode编号在inode Table中查找相应的inode即可。
修改一个文件,系统要做什么?
- 利用inode编号在inode Table中查找相应的inode
- 根据更改了数据的编号,在Data Blocks中修改
- 若块不足,在Block Bitmap更改比特位即可(申请空间),反之块多余也亦如此。
- 最后在inode中的blocks更新块的信息
现在有个问题:用户可从来没有关心过inode编号,用的都是文件名呀!文件系统怎么知道文件名对应的inode编号呢?
这个问题目录帮我们解决了!
现在如何理解“目录” ?
我们知道,目录也是文件,也有自己的inode,也有属于自己的属性。
那目录有内容吗?
只要是文件,就一定有内容,也有相应的数据块,那这些数据块存放什么呢?
目录下,存放文件名和对应文件inode编号的映射表!
注意:这个映射表是KV结构,文件名是键(Key),inode编号是值(Value)。也就是说,文件名是唯一的,而inode编号不一定唯一。
原来,系统就是通过目录与用户之间进行文件名与相应inode编号的转化的。
那目录的inode编号与目录名的映射存放在哪呢??
在上级目录的数据块中。
也就是说,系统只需要知道根目录/的inode编号即可推出所有目录的inode编号。
现在,我们可以从本质上理解目录的一些规则了:
- 为什么同一个目录下不能有同名文件?
因为文件名与inode编号是KV关系。 - 目录下,没有w,我们就无法创建文件
没有w,就无法在目录文件写入文件名与inode编号的映射关系,所以无法创建文件。 - 目录下,没有r,我们就无法查看文件
没有r,就无法读取目录文件本身的数据内容——即存储在内的“文件名到 inode 编号”的映射表,系统就不知道文件相应的inode编号,因此无法查看文件。 - 目录下,没有x,我们就无法进入这个目录
没有x,就无法通过该目录的 inode 来访问其存储的内容(即那张“文件名到 inode 编号”的映射表),系统就无法将你的工作目录切换到该目录,也无法将其作为路径解析的一部分来遍历。

软硬链接
我们可以通过ln指令对某个文件进行链接,而链接方式分为软硬链接,ln指令默认为硬链接,加上-s选项可完成软链接,具体如下:
语法:
ln -s [目标文件] [自定义链接文件]
- 硬链接
ln myfile1 my_hard
- 软链接
ln -s myfile2 my_soft
效果如图:
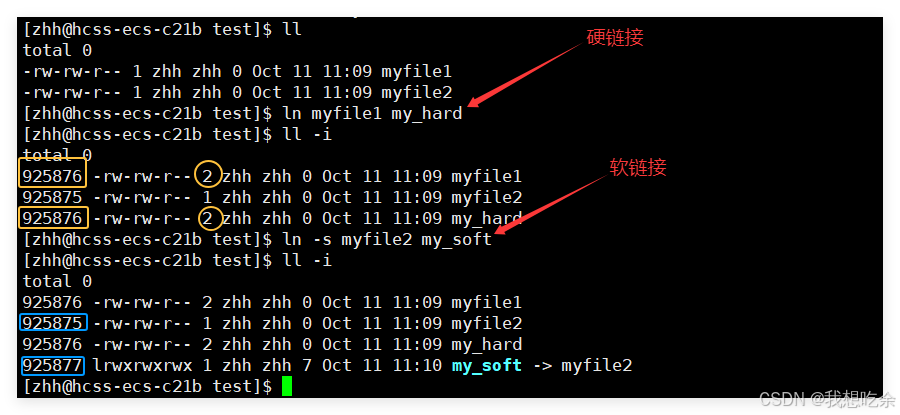
可以发现:
- 软链接是一个独立的文件,具有独立的inode
- 硬链接不是应该独立的文件,因为它没有独立的inode
如何理解硬链接?
所谓建立硬链接,本质其实就是在特定目录的数据块新增文件名和指向文件的inode编号的映射关系。
每一个inode的内部,都有一个叫做引用计数的计数器,它表示有多少个文件名指向这个inode。
如图,硬链接后,引用计数+1:

硬链接应用场景
硬链接通常用来进行路径定位,可以进行目录间的切换。
比如,我们每个目录下都有的隐藏文件.和..,它们就是采用硬链接创建的。有了它们,我们就可以使用相对路径,比如运行可执行程序,我们只需./即可,不用再从根目录开始描述绝对路径来运行程序了。
注意:Linux系统不允许用户对目录建立硬链接。因为这样做非常不安全,比如说我们随意建立了一个返回根目录的硬链接,这样会使得目录这颗树结构被破坏,形成环,这样一来一个文件的路径可能就不再是唯一路径了。这种可以破坏操作系统内部结构的行为,是被杜绝的。
如何理解软链接?
软链接是一个独立的文件,有独立的inode,也就有独立的数据块,它的数据块中保存的是指向文件的路径。
软链接应用场景
软链接主要被用来作快捷方式。
相当于windows的快捷方式,在桌面上可以通过点击快捷方式,快速启动某目录下的可执行程序。
Linux系统也是如此,我们在根目录下建立一个其他目录下的可执行程序的软链接,这样我们在根目录下,也可以快速启动其他目录下的可执行程序了。