AI大事记11:从 AlphaGo 到 AlphaGo Zero(上)
2016 年 3 月,一场看似普通的围棋比赛在韩国首尔举行,却在全球范围内引发了轩然大波。谷歌 DeepMind 开发的人工智能程序 AlphaGo 以4:1的比分击败了世界围棋冠军李世石,成为首个在围棋这一公认的高难度智力游戏中战胜人类顶尖选手的 AI 系统。更令人震惊的是,仅仅一年后,DeepMind 推出的 AlphaGo Zero 版本,不依靠任何人类棋谱,仅通过自我对弈就超越了人类水平,甚至击败了之前击败李世石的 AlphaGo 版本。

图 1 AlphaGo 以4:1的比分击败了世界围棋冠军李世石
这一历史性事件标志着人工智能技术在复杂博弈领域的重大突破,也引发了人们对 AI 未来发展的无限遐想。从 AlphaGo 到 AlphaGo Zero,AI 技术究竟经历了怎样的演进?它们的技术原理是什么?这一突破对 AI 领域乃至整个科技产业产生了哪些深远影响?本文将深入探讨这些问题,并展望 AI 技术的未来发展方向。
1 AlphaGo:改变围棋世界的 AI 挑战者
1.1 围棋:人类智慧的 "最后堡垒"
围棋作为一种有着数千年历史的策略游戏,一直被认为是人类智慧的 "最后堡垒" 之一。围棋的棋盘由 19×19 条线组成,形成 361 个交叉点,每个交叉点都可以放置黑子或白子。围棋的复杂度远超国际象棋,其可能的走法数量超过了宇宙中已知原子的总数(约 10^170 种),这使得传统的基于暴力搜索的 AI 算法难以在围棋领域取得突破。
围棋的这一特性使其成为测试 AI 能力的理想平台。在 AlphaGo 之前,虽然计算机在国际象棋、跳棋等策略游戏中已经击败了人类顶尖选手,但在围棋领域,人类一直保持着对 AI 的优势。围棋不仅需要计算能力,更需要直觉、创造力和战略眼光,这些被认为是人类独有的高级认知能力。
1.2 AlphaGo 的技术突破:深度学习与蒙特卡洛树搜索的结合
AlphaGo 的成功源于其创新的技术架构,主要基于深度学习和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)的结合。这一技术组合使得 AlphaGo 能够在围棋的巨大搜索空间中找到最优解,同时具备类似人类的直觉判断能力。
1)深度学习:AlphaGo 的 "直觉"
AlphaGo 使用了两种深度神经网络来模仿人类棋手的直觉:
策略网络(Policy Network):这是一个较深的神经网络,其优化目标是准确率而非预测速度。它使用人类棋谱进行监督学习,从而初步掌握下棋的策略。策略网络可以根据当前棋盘状态预测下一步的落子位置概率分布。
价值网络(Value Network):这是 AlphaGo 走向巅峰的关键。它的作用是快速评估当前棋盘状态的获胜率。通过强化学习,价值网络能够学习到在不同棋盘状态下,哪种走法更有可能获胜。与人类相比,AlphaGo 对于每种状态都有尽可能准确的赢率判断,这使其在比赛中占据优势。
2)蒙特卡洛树搜索:AlphaGo 的 "决策大脑"
蒙特卡洛树搜索(MCTS)是 AlphaGo 的总框架,它负责将策略网络和价值网络的结果结合起来,以找到最优的走法。MCTS 通过以下四个步骤来模拟对弈过程:
选择(Selection):从根节点开始,沿着一条路径向下寻找叶子节点。在选择过程中,AlphaGo 会优先考虑那些胜率较高的走法。
扩展(Expansion):在找到的叶子节点下增加子节点,以表示可能的下一步走法。
模拟(Simulation):从叶子节点状态开始,与对手模拟对弈。模拟过程可以使用快速走子网络或随机走子等方法进行。
反传(Backpropagation):将模拟对弈的结果反传到根节点,以更新节点的胜率等统计数据。
通过不断重复这四个步骤,MCTS 能够在有限的计算时间内找到最优的走法。同时,AlphaGo 还会根据价值网络和策略网络的结果对 MCTS 的搜索过程进行调整,以进一步提高搜索效率。
1.3 AlphaGo 与李世石的历史性对决
2016 年 3 月 9 日至 15 日,AlphaGo 与韩国围棋九段李世石在韩国首尔进行了五局三胜制的比赛,采用中国围棋规则,每方 2 小时思考时间,外加 3 次 60 秒读秒。这场比赛吸引了全球数亿人关注,成为人工智能发展史上的里程碑事件。
比赛结果震惊了全世界:AlphaGo 以4:1的比分击败了李世石。具体比赛过程如下:
第一局:AlphaGo 获胜,李世石未能适应其风格。
第二局:AlphaGo 再胜,第 37 手被誉为 "神之一手",展现非人类思维。
第三局:AlphaGo 锁定胜局,3:0 领先。
第四局:李世石扳回一局,第 78 手出人意料,抓住 AlphaGo 失误。
第五局:AlphaGo 调整策略,再次获胜。
这场比赛的第二局尤为引人注目。在这一局中,AlphaGo 在左上角的第 37 手选择了一个在人类职业棋手看来非常冒险的走法,这一手被围棋界称为 "神之一手"。这步棋完全超出了人类的直觉和理解,甚至让职业棋手感到困惑。然而,后续的发展证明这是一步极具前瞻性的妙手,彻底改变了整个棋局的走向。
图 2 AlphaGo 在左上角的第 37 手选择了一个在人类职业棋手看来非常冒险的走法,这一手被围棋界称为 "神之一手"
李世石在赛后表示,AlphaGo 的风格 "像神一样",挑战了人类对围棋的传统理解。他坦言,在比赛中他感受到了来自 AI 的巨大压力,这种压力不仅来自于 AlphaGo 的实力,更来自于它所展现出的非人类思维方式。
2 AlphaGo Zero:从零开始的自我超越
2.1 超越人类知识:AlphaGo Zero 的技术突破
2017 年 10 月,DeepMind 推出了 AlphaGo 的进化版本 ——AlphaGo Zero。与之前的 AlphaGo 版本相比,AlphaGo Zero 最显著的特点是完全摒弃了人类棋谱的输入,仅通过与自己对弈来学习围棋策略。这一版本的出现,标志着 AI 技术从 "依赖人类知识" 向 "自主探索学习" 的重大转变。
AlphaGo Zero 的技术突破主要体现在以下几个方面:
完全自我对弈训练:AlphaGo Zero 完全摒弃了人类棋谱的输入,仅通过与自己对弈来学习围棋策略。它通过不断地自我对弈,积累大量的棋局数据,并从中学习和优化神经网络模型,从而逐渐提升自己的棋力。
更强的神经网络架构:AlphaGo Zero 采用了更强大的神经网络架构,能够更好地处理围棋复杂的局面和大量的可能走法。其神经网络不仅可以预测下一步的走法,还可以评估整个棋局的胜负概率,从而在决策过程中做出更优的选择。
高效的强化学习算法:AlphaGo Zero 使用了更高效的强化学习算法,能够更快地收敛到最优策略。它通过策略梯度算法来调整神经网络的参数,使得网络能够在自我对弈的过程中不断优化策略,提高胜率。
快速的学习速度:由于采用了自我对弈和高效的强化学习算法,AlphaGo Zero 能够在相对较短的时间内达到超越人类的水平。据 DeepMind 报告,AlphaGo Zero 仅用了三天的自我对弈训练,就击败了之前击败李世石的 AlphaGo 版本;经过40 天的训练,它甚至超越了 AlphaGo Master(曾在线上击败 60 位顶尖人类棋手的版本)。
2.2 AlphaGo Zero 的训练机制:自我博弈的学习闭环
AlphaGo Zero 的核心训练机制是自我对弈强化学习(Self-play Reinforcement Learning)。这一机制的基本思想是:系统从一个完全随机的策略开始,通过不断与自己对弈,利用蒙特卡洛树搜索(MCTS)来探索可能的走法,并根据对弈结果更新神经网络参数,从而逐渐提高自己的棋力。
AlphaGo Zero 的训练过程可以分为以下几个步骤:
初始化神经网络:AlphaGo Zero 的神经网络被初始化为随机权重 θ0,这意味着它对围棋规则一无所知。
MCTS 搜索:在每个棋盘状态 s,执行 MCTS 搜索,由当前的神经网络 fθ 指导。MCTS 搜索输出每次移动的概率 π。这些搜索概率通常比神经网络 fθ(s) 的原始移动概率 p 更强,因此 MCTS 可以被视为强大的策略改进提供者。
自我对弈:使用基于 MCTS 的策略来选择每个动作,然后使用游戏赢家 z 作为价值的样本。这一过程可以被视为强大的策略评估运算符。
参数更新:通过最小化损失函数来更新神经网络的参数 θ,使得移动概率和值 (p, v)=fθ(s) 更接近匹配改进的搜索概率和自我对弈胜者 (π, z)。损失函数定义为:l = (z-v)² - πTlogp + cθ²,其中 c 是控制 L2 权重正则化水平的参数。
迭代优化:将更新后的神经网络参数用于下一次自我对弈,重复上述过程,形成一个闭环的学习系统。
通过不断重复这一过程,AlphaGo Zero 能够在没有任何人类知识输入的情况下,从完全随机的状态开始,逐步掌握围棋策略,并最终达到超越人类的水平。这一训练机制的关键在于,它能够利用系统自身的经验来不断改进,而不需要依赖外部的专家知识。
2.3 AlphaGo Zero 的成就与意义
AlphaGo Zero 在训练过程中展现出了惊人的学习速度和能力。据 DeepMind 报告,在经过三天的自我对弈训练后,AlphaGo Zero 就击败了之前击败李世石的 AlphaGo 版本;经过40 天的训练,它的表现已经超过了 AlphaGo Master(曾在线上击败 60 位顶尖人类棋手的版本)。
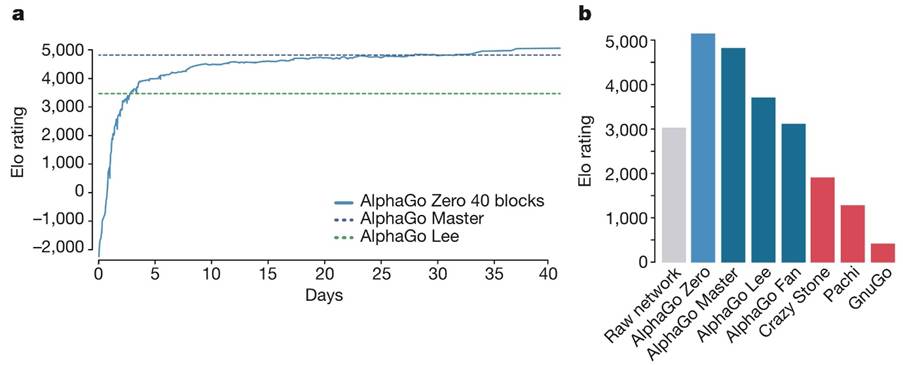
图 3 AlphaGo Zero 在训练过程中展现出了惊人的学习速度和能力
为了验证 AlphaGo Zero 的实力,DeepMind 组织了一场内部比赛,将 AlphaGo Zero 与 AlphaGo Master 进行了 100 局对决。结果令人震惊:AlphaGo Zero 以89:11的悬殊比分完胜 AlphaGo Master。这一结果不仅证明了 AlphaGo Zero 的强大实力,也表明完全摒弃人类知识的自主学习方法比依赖人类经验的学习方法更有效。
AlphaGo Zero 的成就具有深远的意义:
证明了无监督学习的潜力:AlphaGo Zero 的成功表明,AI 系统可以在没有人类指导的情况下,通过自我探索和学习达到超人类水平。这为解决那些缺乏人类专业知识或人类知识不可靠的领域提供了新思路。
打破了人类知识的局限性:传统的 AI 系统通常依赖于人类提供的训练数据和知识,这限制了它们的发展潜力。AlphaGo Zero 突破了这一限制,证明了 AI 系统可以超越人类的认知边界,发现人类未曾想到的策略和方法。
展示了强化学习的强大能力:AlphaGo Zero 的成功是强化学习的重大胜利。它表明,通过适当的算法设计和计算资源,强化学习可以解决极其复杂的决策问题。
为通用人工智能提供了新思路:AlphaGo Zero 的训练方法为开发能够在多种领域自主学习和适应的通用人工智能系统提供了重要启示。