【论文精读】TextCrafter:复杂视觉场景中多文本精确渲染的革新框架
Nikai Du, Zhennan Chen 等 | Nanjing University, China Mobile, HKUST | 2025
在当前多模态生成模型飞速发展的背景下,文本到图像(Text-to-Image)生成技术已取得令人瞩目的成就。然而,尽管模型如 Stable Diffusion 3、FLUX 等能够生成高度逼真的图像,它们在处理**复杂视觉文本生成(Complex Visual Text Generation, CVTG)**任务时仍面临显著挑战:文本模糊、错位、混淆甚至完全缺失。这一问题严重限制了生成模型在广告设计、城市景观模拟、UI生成等实际场景中的应用。
为解决这一难题,南京大学、中国移动与香港科技大学联合团队提出了 TextCrafter —— 一种无需训练的、专为复杂场景中多文本精确渲染而设计的创新框架。本文将对这篇题为《TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes》的论文进行深度技术解读,全面剖析其核心思想、方法论、实验设计与未来影响。
一、研究背景与问题定义
1.1 视觉文本生成的现实挑战
视觉文本(Visual Text)广泛存在于现实世界中:街边招牌、广告海报、产品包装、电子屏幕、书籍封面等。与普通物体不同,文本具有极高的结构敏感性——一个字母的错位、一个笔画的模糊,都可能导致语义完全改变或无法识别。
当前主流的扩散模型(Diffusion Models)在生成简单文本(如单行标语)时表现尚可,但在以下复杂场景中表现不佳:
- 多区域文本:多个文本分布在不同位置(如咖啡馆的菜单、招牌、杯子标签)。
- 多样式文本:不同字体、大小、颜色混合(如海报中的标题、副标题、小字说明)。
- 小尺寸文本:远处的标识或产品说明,易被忽略。
- 数字与符号:价格、评分、日期等非字母内容。
如图1所示,现有模型(FLUX、TextDiffuser-2、3DIS)在生成包含长文本、小字号、数字符号、多风格的复杂场景时,普遍存在文本遗漏、混淆、模糊等问题。

1.2 复杂视觉文本生成(CVTG)任务定义
论文正式定义了 CVTG(Complex Visual Text Generation) 任务:
给定一个全局提示(Prompt)P,其中包含多个视觉文本描述 D={d1,d2,...,dn},每个描述 di 包含文本内容 vti 及其属性(位置、字体、颜色等),模型需生成一张图像,使得每个 vti 以正确的形式出现在其指定位置。
核心挑战:
- 文本混淆(Text Confusion):不同文本内容交织,生成错误字符。
- 文本遗漏(Text Omission):部分文本未被生成。
- 文本模糊(Text Blurriness):小尺寸文本因注意力不足而模糊。
二、相关工作与局限性
2.1 多实例生成(Multi-instance Generation)
现有方法如 GLIGEN、MIGC、3DIS 等通过边界框控制生成多个实例。然而,这些方法将每个实例视为独立对象,忽视了文本与其载体(如招牌、屏幕)的强语义绑定关系,导致文本“漂浮”在图像中。
2.2 单文本生成方法
- AnyText、TextDiffuser-2:依赖微调文本编码器或条件控制器,难以扩展到多文本场景。
- Glyph-byT5:使用字符级编码,但训练成本高,且多文本间易产生特征干扰。
2.3 现有评测基准的不足
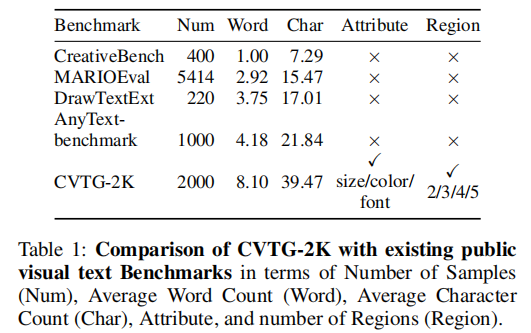
现有数据集普遍存在文本长度短、缺乏多样性、无多区域标注等问题。为此,作者构建了 CVTG-2K —— 首个专为复杂多文本生成设计的高质量基准。
三、TextCrafter:三阶段渐进式框架
TextCrafter 的核心思想是 “化繁为简,逐步聚焦”。其框架分为三个关键阶段,如图2所示:
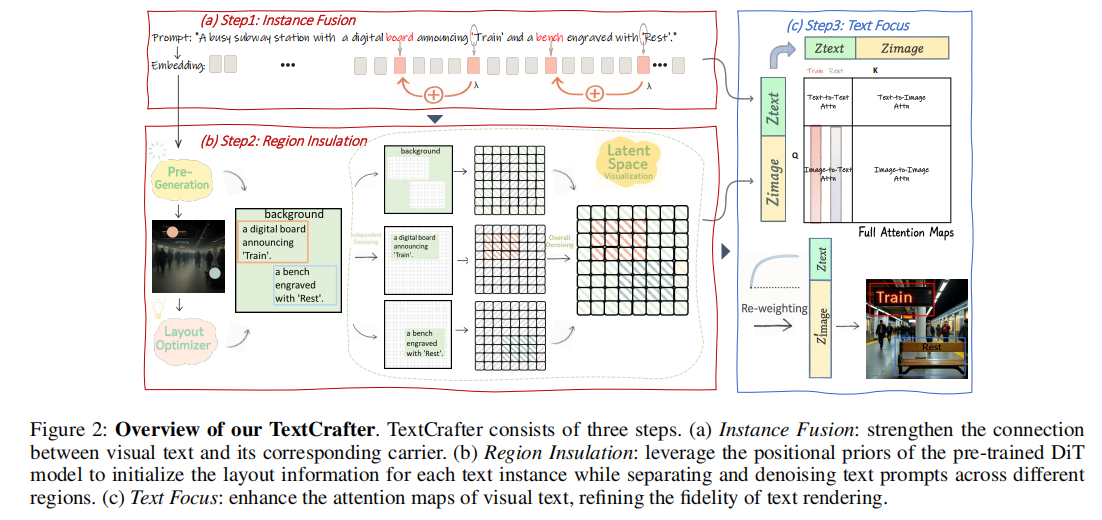
3.1 阶段一:实例融合(Instance Fusion)
目标:强化文本与其载体的语义绑定,防止文本“漂浮”。
方法:利用引号嵌入(quotation mark embedding)作为桥梁,将文本内容与载体(如“招牌”、“屏幕”)进行融合。
- 在提示词中,文本内容通常被引号包围,如:“a sign saying 'Open'”。
- 作者发现,前引号的注意力图(attention map)天然地关联了其后的文本内容。
- 通过加权融合(weighted fusion)将前引号的嵌入注入载体嵌入中,增强其空间一致性。
公式:
![]()
其中 λ 为融合比例。
下图直观呈现了引号嵌入如何强化文本-载体关系:

3.2 阶段二:区域绝缘(Region Insulation)
目标:防止多文本间的特征干扰,避免混淆与遗漏。
3.2.1 预生成布局初始化
- 利用预训练 DiT 模型的位置先验知识,在早期去噪步骤中提取注意力图。
- 定位每个文本的最大注意力点 pmax:
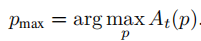
仅需8步即可逼近最终布局:

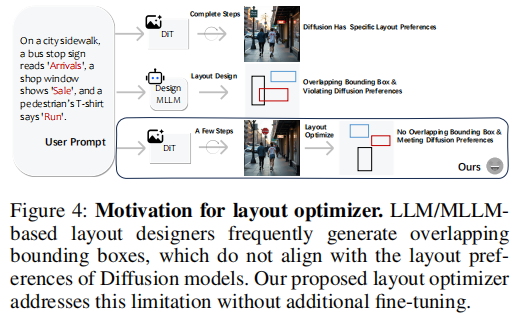
3.2.2 混合整数线性规划(MILP)优化器
- 传统方法(如MLLM生成布局)常产生重叠边界框,违背扩散模型的布局偏好。
- TextCrafter 提出 MILP 布局优化器,通过硬约束确保:
- 边界框不重叠
- 最小面积与宽高比合理
- 中心点尽可能接近注意力最大点
优化目标:

下图直观展示了MILP优化器能有效解决重叠边界框问题:
3.2.3 区域隔离去噪
- 为每个文本初始化独立潜变量
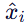 ,使用其局部提示
,使用其局部提示 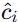 进行前 r 步去噪。
进行前 r 步去噪。 - 将去噪后的区域重新插入全局潜变量
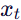 ,避免早期干扰。
,避免早期干扰。
公式:
![]()
3.3 阶段三:文本聚焦(Text Focus)
目标:增强文本区域的注意力,解决小文本模糊问题。
方法:在交叉注意力层中,放大文本与引号的注意力得分。
- 使用 tanh 函数控制增强比例,防止过增强:
其中 k 为文本token数量。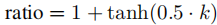
- 对图像到文本的注意力矩阵 Mt 进行重加权:
其中 F 为文本与引号的token集合。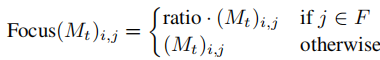
四、实验与结果分析
4.1 数据集:CVTG-2K
- 规模:2000个复杂场景提示。
- 多样性:涵盖街景、海报、书籍、广告、UI等。
- 长度:平均8.1词,39.47字符,远超现有基准。
- 区域数:2~5个文本区域,分布均衡。
- 属性:包含大小、颜色、字体等自然语言描述。
4.2 评测指标
- Word Accuracy:生成文本与目标文本的词级准确率。
- NED(Normalized Edit Distance):编辑距离归一化,值越高越好。
- CLIPScore:图文一致性。
- VQAScore:视觉问答准确率。
- Aesthetics:美学评分。
4.3 主实验结果
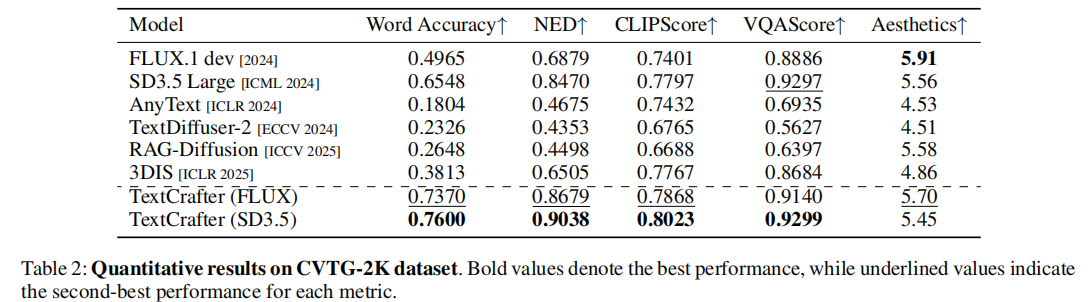
结论:
- TextCrafter 在 Word Accuracy 和 NED 上显著超越所有基线,证明其在文本精确性上的优势。
- 在 VQAScore 上接近最优,表明生成文本可被准确识别。
- 美学评分保持高水平,说明文本增强未牺牲整体质量。
下图进一步直观展示了TextCrafter 与基线模型的定性对比:

4.4 消融实验
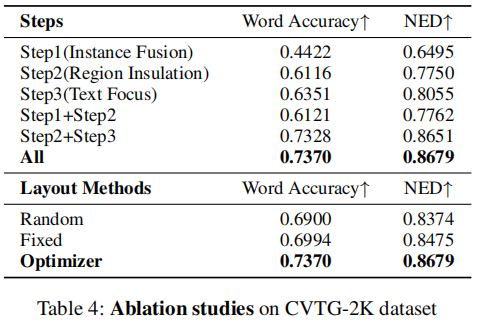
消融研究表明:
- Region Insulation 贡献最大,验证了区域隔离的重要性。
- 三阶段协同工作达到最佳效果。
五、总结与展望
5.1 核心贡献
- 提出 TextCrafter:首个无需训练、专为多文本复杂场景设计的生成框架。
- 构建 CVTG-2K:首个支持多区域、长文本、多样化属性的视觉文本基准。
- 三阶段渐进策略:从实例融合、区域绝缘到文本聚焦,系统性解决文本混淆、遗漏、模糊问题。
5.2 未来方向
- 动态布局生成:结合MLLM进行更智能的布局规划。
- 手写与艺术字体:扩展至非标准字体生成。
- 3D场景文本:在三维空间中渲染透视文本。
项目主页:https://github.com/NJU-PCALab/TextCrafter.git
TextCrafter 为复杂视觉文本生成树立了新标杆,其“无训练、可插拔”的设计理念极具实用价值,有望广泛应用于广告设计、虚拟场景构建、UI/UX原型生成等领域。