【RAG】召回增强
多路召回和上下文丰富窗口
多路召回
将基于向量的相似性检索与基于关键词的BM25检索相结合。
def fusion_retrieval(vectorstore, bm25, query: str, k: int = 5, alpha: float = 0.5) -> List[Document]:"""Perform fusion retrieval combining keyword-based (BM25) and vector-based search.Args:vectorstore (VectorStore): The vectorstore containing the documents.bm25 (BM25Okapi): Pre-computed BM25 index.query (str): The query string.k (int): The number of documents to retrieve.alpha (float): The weight for vector search scores (1-alpha will be the weight for BM25 scores).Returns:List[Document]: The top k documents based on the combined scores."""epsilon = 1e-8# Step 1: Get all documents from the vectorstoreall_docs = vectorstore.similarity_search("", k=vectorstore.index.ntotal)# Step 2: Perform BM25 searchbm25_scores = bm25.get_scores(query.split())# Step 3: Perform vector searchvector_results = vectorstore.similarity_search_with_score(query, k=len(all_docs))# Step 4: Normalize scoresvector_scores = np.array([score for _, score in vector_results])vector_scores = 1 - (vector_scores - np.min(vector_scores)) / (np.max(vector_scores) - np.min(vector_scores) + epsilon)bm25_scores = (bm25_scores - np.min(bm25_scores)) / (np.max(bm25_scores) - np.min(bm25_scores) + epsilon)# Step 5: Combine scorescombined_scores = alpha * vector_scores + (1 - alpha) * bm25_scores # Step 6: Rank documentssorted_indices = np.argsort(combined_scores)[::-1]# Step 7: Return top k documentsreturn [all_docs[i] for i in sorted_indices[:k]]
上下文丰富窗口
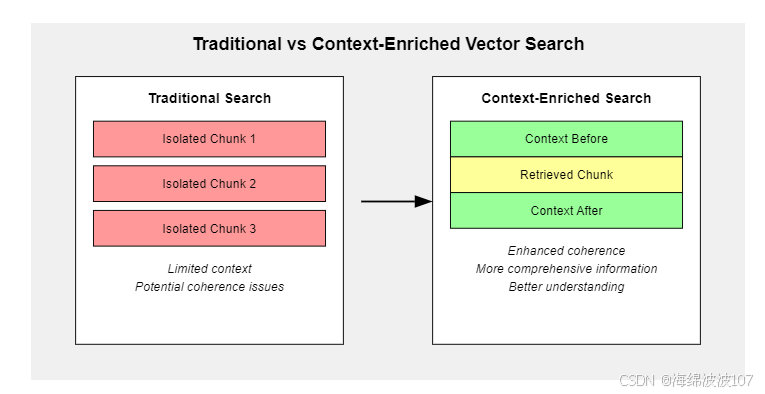
通过为每次检索到的片段添加周围的相关上下文,对标准检索流程进行了改进,从而提高了返回信息的连贯性和完整性。传统的向量搜索通常只会返回孤立的文本片段,这些片段可能缺乏理解完整内容所必需的上下文信息。而这种新方法旨在通过纳入相邻的文本片段来提供对检索到的信息更全面的了解【1】。
检索重排序
重排序是检索增强生成(RAG)系统中的一个关键步骤,其目的是提高相关性和生成内容的质量。检索到的文档,这包括重新评估和重新排列最初检索到的文档,以确保选出的都是最相关的文档。
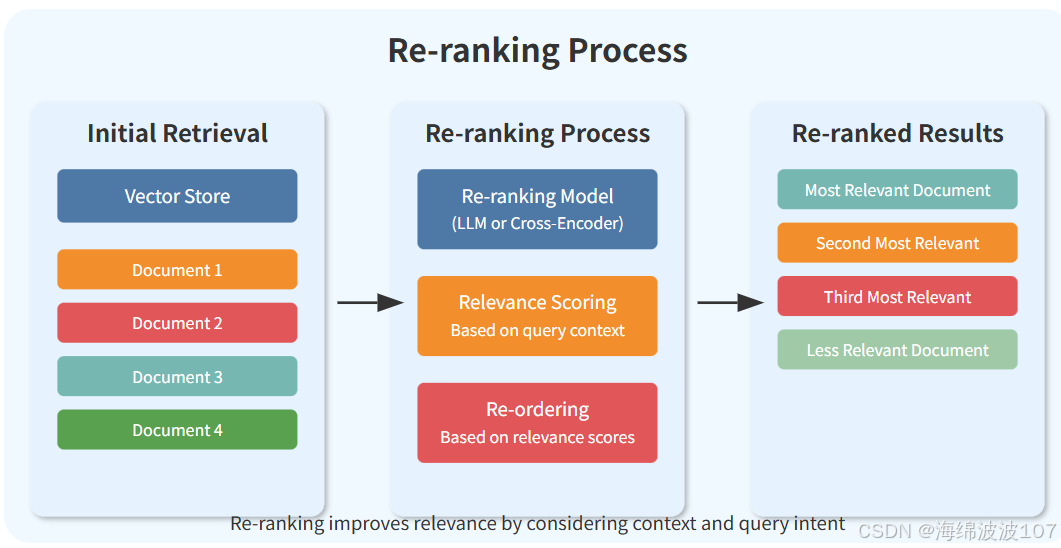
如果用大模型来进行rerank的话,提示词如下
class RatingScore(BaseModel):relevance_score: float = Field(..., description="The relevance score of a document to a query.")def rerank_documents(query: str, docs: List[Document], top_n: int = 3) -> List[Document]:prompt_template = PromptTemplate(input_variables=["query", "doc"],template="""On a scale of 1-10, rate the relevance of the following document to the query. Consider the specific context and intent of the query, not just keyword matches.Query: {query}Document: {doc}Relevance Score:""")llm = ChatOpenAI(temperature=0, model_name="gpt-4o", max_tokens=4000)llm_chain = prompt_template | llm.with_structured_output(RatingScore)scored_docs = []for doc in docs:input_data = {"query": query, "doc": doc.page_content}score = llm_chain.invoke(input_data).relevance_scoretry:score = float(score)except ValueError:score = 0 # Default score if parsing failsscored_docs.append((doc, score))reranked_docs = sorted(scored_docs, key=lambda x: x[1], reverse=True)return [doc for doc, _ in reranked_docs[:top_n]]
参考文献
1
https://github.com/NirDiamant/RAG_Techniques