网站开发师是属于IT主体职业网站美工如何做
1. pytorch手写数字预测
- 1.背景
- 2.准备数据集
- 2.定义模型
- 3.dataloader和训练
- 4.训练模型
- 5.测试模型
- 6.保存模型
1.背景
因为自身的研究方向是多模态目标跟踪,突然对其他的视觉方向产生了兴趣,所以心血来潮的回到最经典的视觉任务手写数字预测上来,所以这份教程并不是一份非常详尽的教程,是在一部分pytorch,深度学习基础上的教程,如果需要的是非常保姆级的教程建议看别的文章
2.准备数据集
这里我才用了直接导torchvision中的dataset包来下载Mnist数据集,也算是一个非常经典的数据集了
# 导入数据集
from torchvision.datasets import MNIST
import torch# 设置随机种子
torch.manual_seed(3306)# 数据预处理
from torchvision import transforms
# 定义数据转换
transform = transforms.Compose([transforms.ToTensor(), # 转换为 Tensortransforms.Normalize((0.1307,), (0.3081,)) # 标准化
])# 下载 MNIST 数据集
mnist_train = MNIST(root='./dataset_file/mnist_raw', train=True, download=True,transform=transform)
mnist_test = MNIST(root='./dataset_file/mnist_raw', train=False, download=True,transform=transform)
# 查看数据集大小
print(f"MNIST train dataset size: {len(mnist_train)}")
print(f"MNIST test dataset size: {len(mnist_test)}")
其中,MNIST()中的root代表的是数据集存放的位置,download代表是如果当前位置没有数据集是否需要下载。
transformer则是对数据的处理方式,我这里采用了简单地转成tensor和简单地标准化。
不过这样子下载下来的数据集是二进制格式的,无法直接查看图片,当然,如果你需要查看图片,也有办法。
# 查看图片
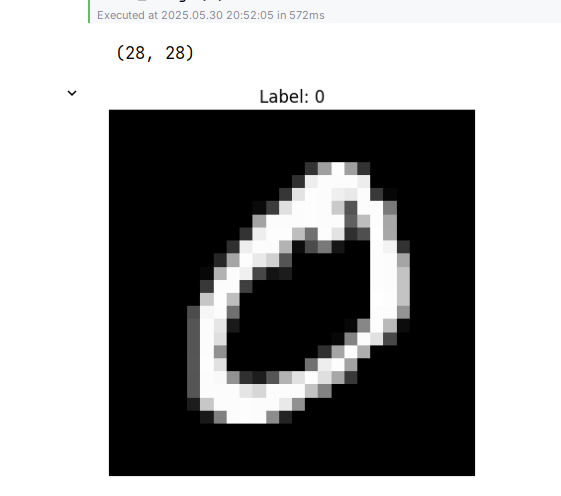
import matplotlib.pyplot as pltdef show_image(id):img, label = mnist_train[id]img = img.squeeze().numpy() # 去掉通道维度print(img.shape)# print(img)plt.imshow(img, cmap='gray')plt.title(f"Label: {label}")plt.axis('off')plt.show()show_image(1)
效果
又或者你想要下载的数据集是图片格式,我这里也准备了代码
代码是在别人的基础上改的,其中数据集存放路径是dataset_dir,如果需要修改自行打印然后修改位置就好了。
#!/usr/bin/env python3
# -*- encoding utf-8 -*-'''
@File: save_mnist_to_jpg.py
@Date: 2024-08-23
@Author: KRISNAT
@Version: 0.0.0
@Email: ****
@Copyright: (C)Copyright 2024, KRISNAT
@Desc:1. 通过 torchvision.datasets.MNIST 下载、解压和读取 MNIST 数据集;2. 使用 PIL.Image.save 将 MNIST 数据集中的灰度图片以 JPEG 格式保存。
'''import sys, os
sys.path.insert(0, os.getcwd())from torchvision.datasets import MNIST
import PIL
from tqdm import tqdmif __name__ == "__main__":home_dir = os.path.abspath('.')root = os.path.abspath(os.path.join(home_dir, '../dataset_file'))print(root)# exit(0)# 图片保存路径dataset_dir = os.path.join(root, 'mnist_jpg')if not os.path.exists(dataset_dir):os.makedirs(dataset_dir)# 从网络上下载或从本地加载MNIST数据集# 训练集60K、测试集10K# torchvision.datasets.MNIST接口下载的数据一组元组# 每个元组的结构是: (PIL.Image.Image image model=L size=28x28, 标签数字 int)training_dataset = MNIST(root='mnist',train=True,download=True,)test_dataset = MNIST(root='mnist',train=False,download=True,)# 保存训练集图片with tqdm(total=len(training_dataset), ncols=150) as pro_bar:for idx, (X, y) in enumerate(training_dataset):f = dataset_dir + "/" + "training_" + str(idx) + \"_" + str(training_dataset[idx][1] ) + ".jpg" # 文件路径training_dataset[idx][0].save(f)pro_bar.update(n=1)# 保存测试集图片with tqdm(total=len(test_dataset), ncols=150) as pro_bar:for idx, (X, y) in enumerate(test_dataset):f = dataset_dir + "/" + "test_" + str(idx) + \"_" + str(test_dataset[idx][1] ) + ".jpg" # 文件路径test_dataset[idx][0].save(f)pro_bar.update(n=1)2.定义模型
这里我准备了两个模型,一个MLP模型和一个简单地CNN模型,其中MLP模型参数量1M,CNN模型参数量大概8M,当然这俩模型也没有很仔细的规划
import torch
import torch.nn as nnclass DigitLinear(nn.Module):def __init__(self):super(DigitLinear, self).__init__()self.fc1 = nn.Linear(28 * 28, 1000)self.fc2 = nn.Linear(1000, 500)self.dropout = nn.Dropout(0.3)self.fc3 = nn.Linear(500, 10)def forward(self, x):x = x.view(-1, 28 * 28)x = self.fc1(x)x = torch.relu(x)x = self.dropout(x)x = self.fc2(x)x = torch.relu(x)x = self.fc3(x)return xclass DigitCNN(nn.Module):def __init__(self):super(DigitCNN,self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.fc1 = nn.Linear(64*28*28, 128)self.dropout = nn.Dropout(0.1)self.fc2 = nn.Linear(128, 10)def forward(self, x):# print("x.shape:", x.shape)B,N,H,W = x.shapex = self.conv1(x)x = torch.relu(x)x = self.conv2(x)x = torch.relu(x)x = x.view(B, -1) # 展平x = self.fc1(x)x = torch.relu(x)x = self.dropout(x)x = self.fc2(x)return x
3.dataloader和训练
这里的代码就很简单了,就是一些参数的选择,例如epoch,batchsize。其中的训练函数我写的买有很全面,只是勉强满足了训练功能,还有好多可以优化的点,比如打印fps,断点续训练啥的,不过这个任务提不起劲去干这事,大家可以自行优化。
# 数据加载器
from torch.utils.data import DataLoader
from lib.model.DigitModel import DigitLinear,DigitCNN
# 定义数据加载器
batch_size = 256
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=False)epoch = 50
# 训练模型
net = DigitLinear() # 参数量1M 97.50%
# net = DigitCNN() # 参数量8M 98.81%
net.cuda()# 定义损失函数和优化器
import torch.optim as optim
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练函数def train_model(model, train_loader, criterion, optimizer, num_epochs=10):model.train() # 设置模型为训练模式for epoch in range(num_epochs):running_loss = 0.0correct = 0total = 0for i, (inputs, labels) in enumerate(train_loader):inputs= inputs.cuda()y = torch.tensor(torch.zeros((inputs.shape[0],10), dtype=torch.float)).cuda()y[torch.arange(inputs.shape[0]), labels] = 1optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, y)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels.cuda()).sum().item()epoch_loss = running_loss / len(train_loader)epoch_acc = 100. * correct / totalprint(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%')# 训练模型
train_model(net, train_loader, criterion, optimizer, num_epochs=epoch)
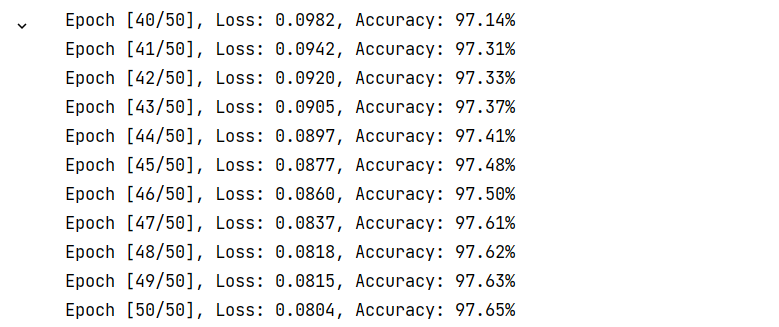
4.训练模型
有了上面的代码就可以开始训练了,我这里训练的截图是我的MLP模型,效果不是很好,CNN的效果稍微好一点,比MLP高1%,但是图忘记截了。反正够用了,因为本身MNIST的数据就不是很完美,有很多类似于噪声的数据例如:

这些数字我人眼都分不出是什么玩意。
训练效果如下
5.测试模型
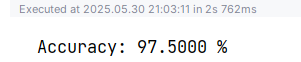
训练完当然是测试了
最后我的MLP模型跑了97.50%的准确率
代码如下
# 测试模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.eval()
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device).float(), labels.to(device).float()outputs = net(inputs)_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels.cuda()).sum().item()# print(f"Predicted: {predicted}, Ground Truth: {targets}")print(f"Accuracy: {correct / total * 100:.4f} %")
6.保存模型
保存模型代码就更简单了
# 保存模型
torch.save(net.state_dict(), './digit_model.pth')