Prompt-tuning、Prefix-tuning、P-tuning/v2
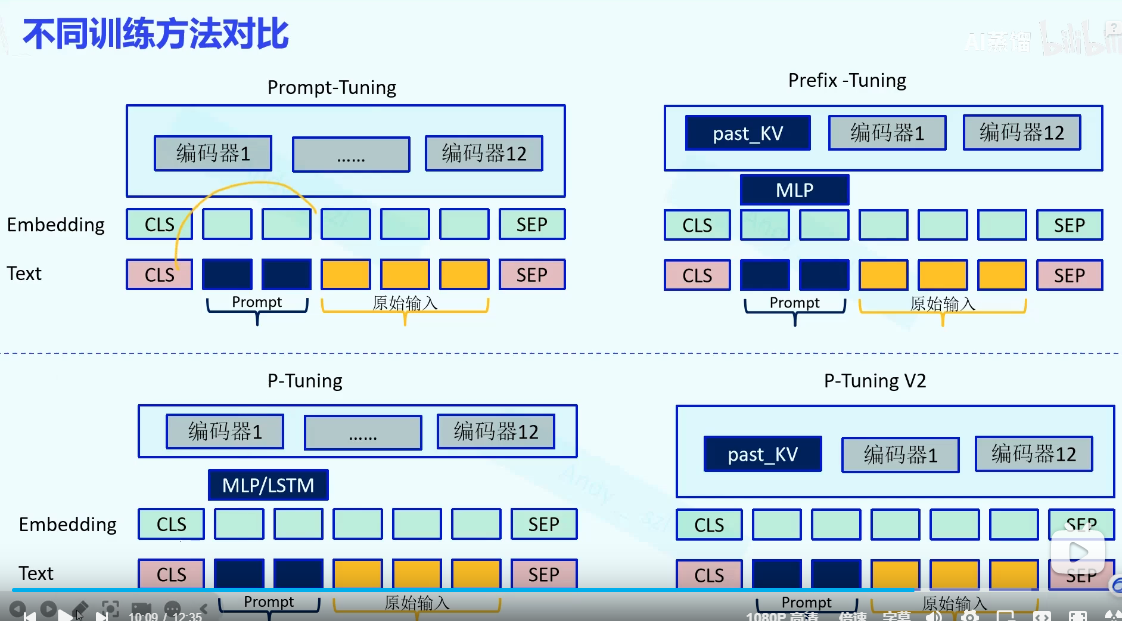
Prompt-tuning
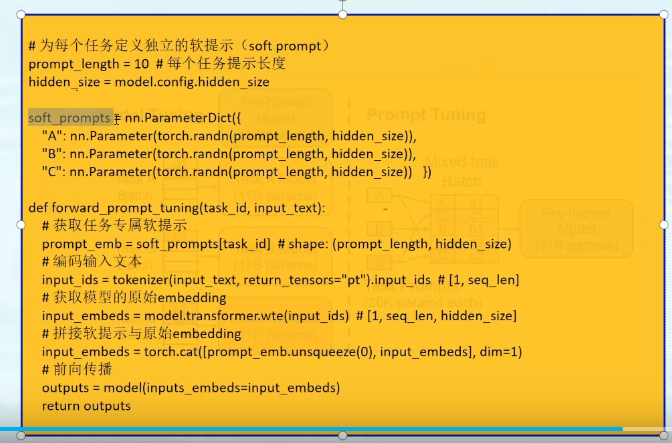
在输入端人工的加入硬提示或者,在模型中加入软提示
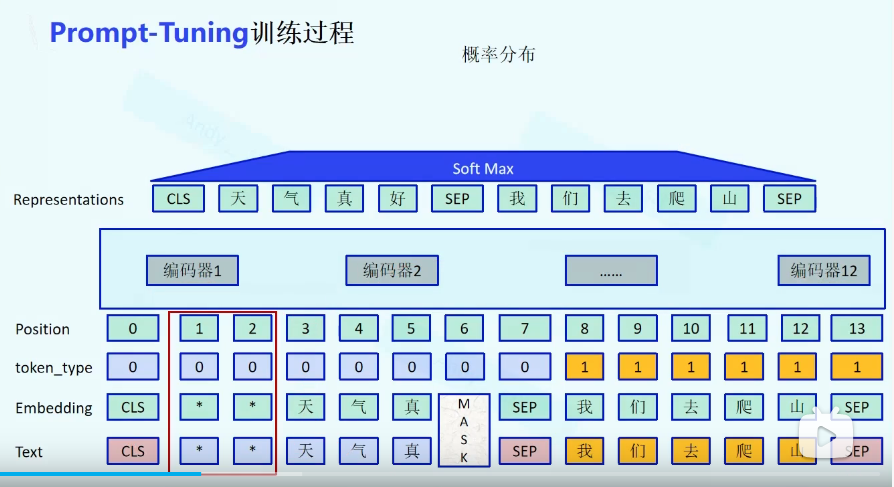

软提示伪代码
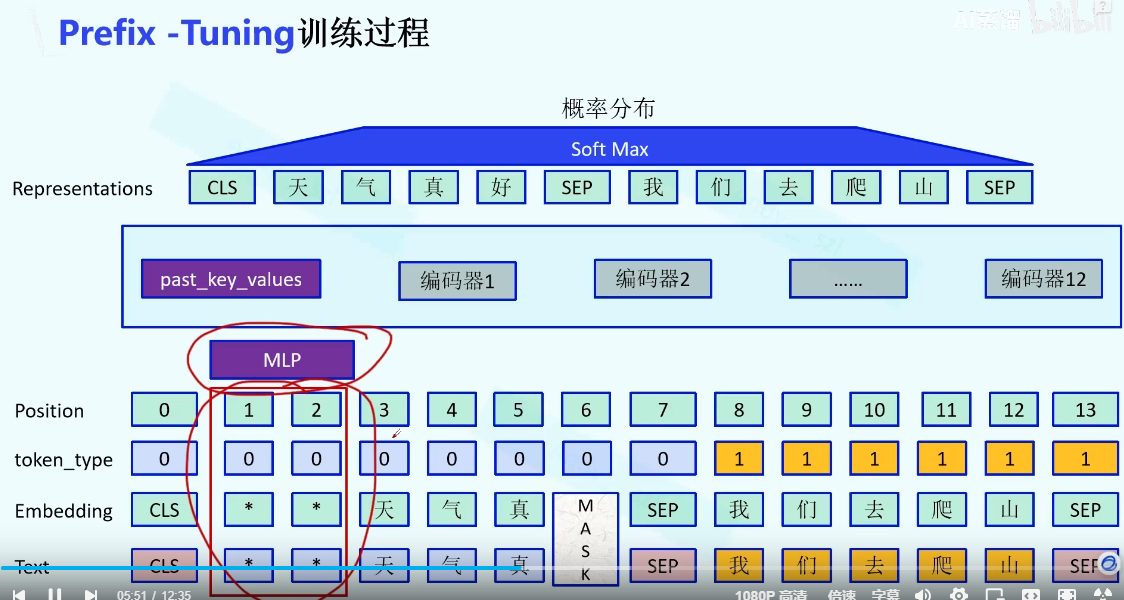
Prefix-tuning
在Prompt-tunning的基础上,embeding之后加入一个MLP层,在编码器部分加上一个Past_KV
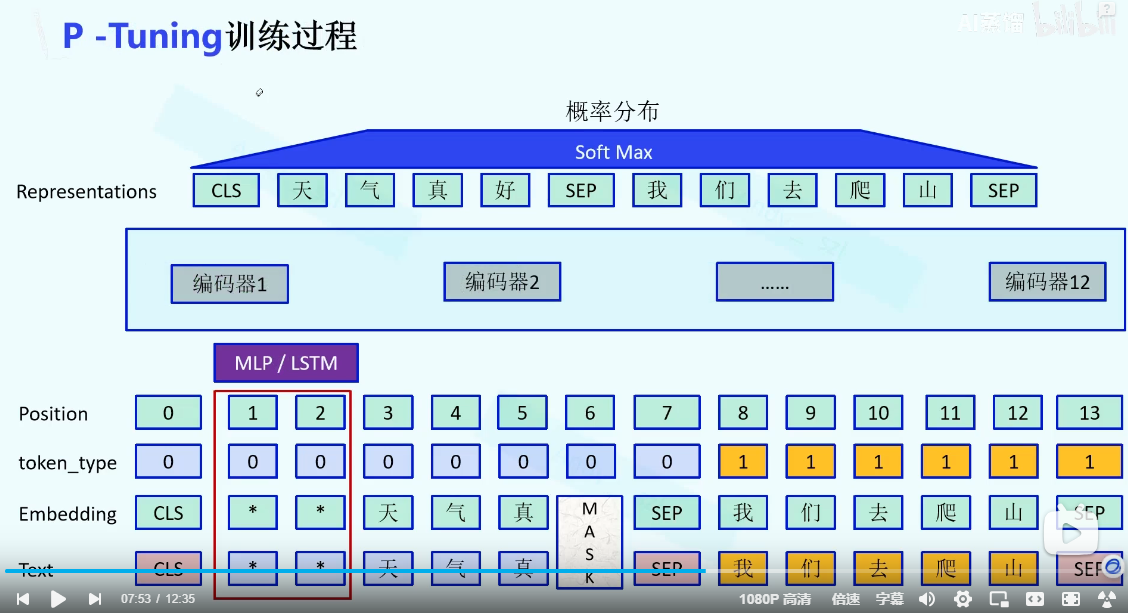
P-tuning
在Prompt-tunning的基础上,embeding之后加入一个MLP层或者LSTM
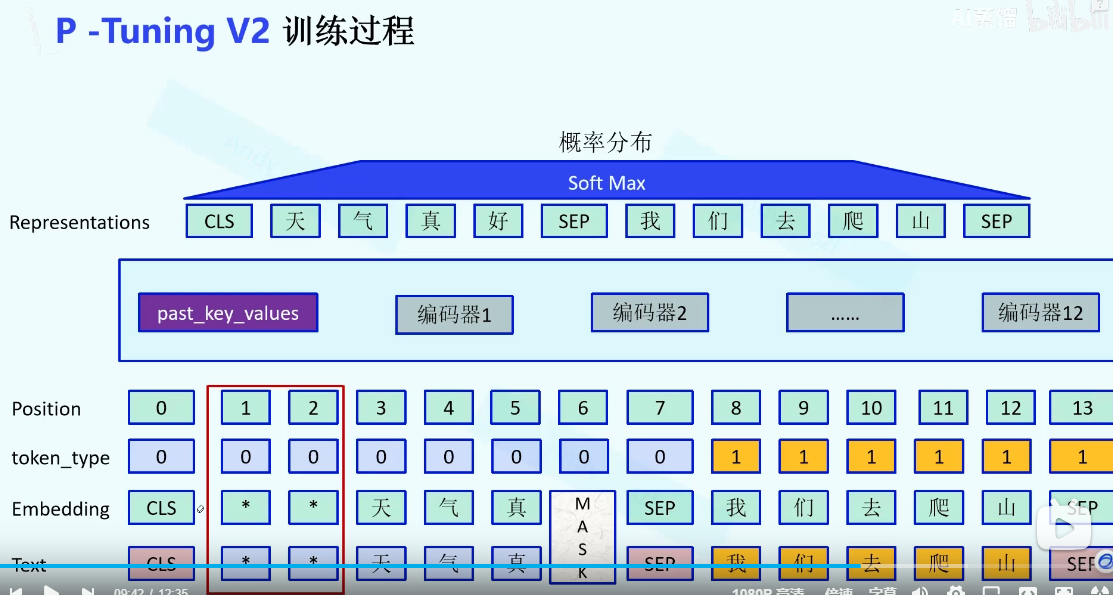
P-tuning V2
在Prompt-tunning的基础上,在编码器部分加上一个Past_KV
MLP
多个linear 提高模型的非线性能力
# 伪代码表示
class MLP(nn.Module):def __init__(self, hidden_size):super().__init__()# 第一个Linear层:上投影,扩大维度self.linear1 = nn.Linear(hidden_size, 4 * hidden_size)# 激活函数,引入非线性self.activation = nn.GELU()# 第二个Linear层:下投影,恢复维度self.linear2 = nn.Linear(4 * hidden_size, hidden_size)def forward(self, x):x = self.linear1(x) # 第一次线性变换x = self.activation(x) # 非线性变换x = self.linear2(x) # 第二次线性变换return x# 伪代码表示
class MLP(nn.Module):def __init__(self, hidden_size):super().__init__()# 第一个Linear层:上投影,扩大维度self.linear1 = nn.Linear(hidden_size, 4 * hidden_size)# 激活函数,引入非线性self.activation = nn.GELU()# 第二个Linear层:下投影,恢复维度self.linear2 = nn.Linear(4 * hidden_size, hidden_size)def forward(self, x):x = self.linear1(x) # 第一次线性变换x = self.activation(x) # 非线性变换x = self.linear2(x) # 第二次线性变换return xPast Key Values == KVCatch
这是一个非常好的问题,它触及了同一个概念在不同语境下的术语使用。
简单直接的回答是:Past Key Values 和 KVCache 指的是同一个东西,但它们是从略微不同的角度来描述它的。
我们可以把它们看作是 “内容”和“容器” 的关系。
详细解释
1. Past Key Values(过去的键值对)
视角:内容导向。这个术语描述了缓存里存储的是什么。
是什么:它指的是在自回归生成过程中,为之前所有时间步(tokens)计算并保存下来的 Key 向量和 Value 向量。
强调重点:数据的本质和用途。这些保存下来的Key和Value是来自“过去”的,用于与“当前”的Query计算注意力。
2. KV Cache(KV 缓存)
视角:机制/结构导向。这个术语描述了实现加速的技术和存储结构。
是什么:它是为了存储
Past Key Values而分配的一块内存空间或一个数据结构(在代码中通常是一个张量元组或一个特定的缓存对象)。强调重点:实现的机制和性能优化。“缓存”这个词本身就暗示了其功能——通过暂存计算结果来避免重复计算,从而提升速度。