超参数优化利器:GridSearchCV 详解与实战指南
在机器学习模型构建过程中,超参数的选择直接影响模型性能。GridSearchCV(网格搜索交叉验证)作为 scikit-learn 库中最常用的超参数优化工具,通过穷举搜索指定的参数组合并结合交叉验证,帮助开发者找到最优参数配置。本文将从定义、作用和应用场景三个维度深入解析 GridSearchCV,并通过完整代码示例展示其在分类和回归任务中的实际应用,帮助读者掌握这一提升模型性能的关键技术。
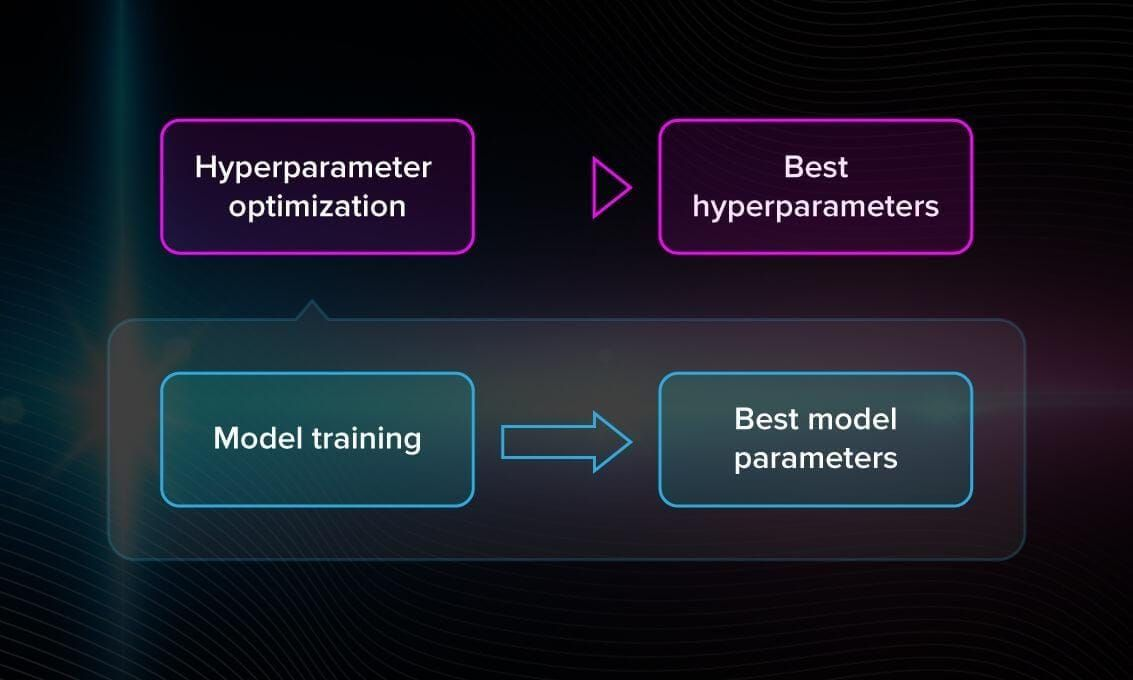
一、GridSearchCV 定义
GridSearchCV 是 scikit-learn 库中实现网格搜索(Grid Search)与交叉验证(Cross Validation)相结合的类,全称为 Grid Search Cross Validation。它的核心思想是:
- 定义一个待搜索的超参数网格(参数及其可能取值的集合)
- 对网格中的每个参数组合,使用交叉验证评估模型性能
- 选择性能最优的参数组合作为最终结果
GridSearchCV 本质上是一种暴力搜索方法,通过系统性地尝试所有可能的参数组合,确保不会错过潜在的最优解,是机器学习模型调优的基础工具之一。
二、GridSearchCV 的核心作用
- 自动化超参数优化:取代手动调整超参数的繁琐过程,减少人为因素影响
- 提升模型性能:通过系统性搜索找到更优参数组合,提高模型准确率或降低误差
- 降低过拟合风险:结合交叉验证,确保找到的参数组合具有更好的泛化能力
- 参数敏感性分析:通过搜索结果可以了解不同参数对模型性能的影响程度
三、GridSearchCV 应用场景
GridSearchCV 适用于大多数需要超参数调优的机器学习场景,特别是以下情况:
- 模型选择初期:当你不确定哪个参数组合效果更好时
- 关键模型优化:对核心模型进行精细调优以达到最佳性能
- 小到中型数据集:数据量不宜过大,否则计算成本会显著增加
- 参数空间较小:当待调参数数量和取值范围有限时效率较高
- 学术研究与实验:需要严格对比不同参数设置下的模型表现
四、GridSearchCV 工作原理
GridSearchCV 的工作流程可以概括为以下步骤:
- 将训练数据按照指定的折数(cv 参数)进行划分
- 遍历参数网格中的所有可能组合
- 对每个参数组合,使用交叉验证计算模型性能指标(如准确率)
- 计算每个参数组合的平均性能指标
- 选择平均性能最佳的参数组合作为最优解
- 使用最优参数组合在全部训练数据上重新训练模型
五、实战示例:使用 GridSearchCV 优化分类模型
下面以决策树分类器为例,展示如何使用 GridSearchCV 进行超参数优化:
5.1 分类任务完整代码
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 1. 加载数据集
data = load_iris()
X = data.data # 特征数据
y = data.target # 标签数据# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42
)# 3. 定义要搜索的参数网格
param_grid = {'max_depth': [3, 5, 7, 10, None], # 树的最大深度,None表示不限制'min_samples_split': [2, 5, 10, 15], # 分裂内部节点所需的最小样本数'min_samples_leaf': [1, 2, 4, 8], # 叶节点所需的最小样本数'criterion': ['gini', 'entropy'] # 分裂标准
}# 4. 初始化决策树分类器
dtc = DecisionTreeClassifier(random_state=42)# 5. 初始化GridSearchCV对象
grid_search = GridSearchCV(estimator=dtc, # 要优化的模型param_grid=param_grid, # 参数网格cv=5, # 5折交叉验证n_jobs=-1, # 使用所有可用的CPU核心verbose=1, # 输出搜索过程信息scoring='accuracy' # 评估指标
)# 6. 执行网格搜索
print("开始网格搜索...")
grid_search.fit(X_train, y_train)# 7. 输出搜索结果
print("\n最佳参数组合:", grid_search.best_params_)
print("最佳交叉验证得分:", grid_search.best_score_)# 8. 使用最佳模型进行预测
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)# 9. 评估最佳模型在测试集上的表现
print("\n测试集准确率:", accuracy_score(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred))# 10. 查看所有参数组合的结果(前5个和后5个)
results = pd.DataFrame(grid_search.cv_results_)
print("\n参数组合及其性能(部分):")
print(results[['params', 'mean_test_score', 'rank_test_score']].sort_values('rank_test_score').head())5.2 代码解析
- 数据准备:使用鸢尾花数据集,这是一个经典的多类别分类数据集
- 参数网格定义:
max_depth:控制树的深度,防止过拟合min_samples_split:控制节点分裂的阈值min_samples_leaf:控制叶节点的最小样本数criterion:决策树分裂的标准(基尼不纯度或熵)
- GridSearchCV 参数说明:
estimator:指定要优化的基础模型param_grid:定义超参数搜索空间cv:交叉验证的折数,这里使用 5 折交叉验证n_jobs=-1:利用所有可用 CPU 进行并行计算,加速搜索过程verbose=1:输出搜索过程信息,便于监控进度scoring:指定评估指标,这里使用准确率(accuracy)
- 结果分析:
best_params_:返回性能最佳的参数组合best_score_:返回最佳参数组合的交叉验证平均得分best_estimator_:返回使用最佳参数训练好的模型
六、实战示例:使用 GridSearchCV 优化回归模型
除了分类任务,GridSearchCV 同样适用于回归任务。以下是使用 GridSearchCV 优化随机森林回归器的示例:
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score# 注意:新版本sklearn中boston数据集已移除,这里提供替代方案
try:from sklearn.datasets import load_bostondata = load_boston()
except ImportError:# 使用替代数据集data = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv")X = data.drop('medv', axis=1).valuesy = data['medv'].values# 确保数据格式正确
if 'data' in locals() and hasattr(data, 'data'):X = data.datay = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42
)# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200], # 树的数量'max_depth': [None, 10, 20, 30], # 每棵树的最大深度'min_samples_split': [2, 5, 10], # 分裂内部节点所需的最小样本数'min_samples_leaf': [1, 2, 4], # 叶节点所需的最小样本数'max_features': ['auto', 'sqrt'] # 每棵树使用的特征数量
}# 初始化随机森林回归器
rf = RandomForestRegressor(random_state=42)# 初始化GridSearchCV对象
grid_search = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5,n_jobs=-1,verbose=1,scoring='neg_mean_squared_error' # 回归任务使用负均方误差
)# 执行网格搜索
print("开始网格搜索...")
grid_search.fit(X_train, y_train)# 输出搜索结果
print("\n最佳参数组合:", grid_search.best_params_)
print("最佳交叉验证负均方误差:", grid_search.best_score_)
print("最佳交叉验证均方误差:", -grid_search.best_score_)# 使用最佳模型进行预测
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)# 评估最佳模型在测试集上的表现
print("\n测试集均方误差:", mean_squared_error(y_test, y_pred))
print("测试集R²得分:", r2_score(y_test, y_pred))七、GridSearchCV 的优缺点
优点
- 全面性:遍历所有参数组合,不会遗漏潜在的最优解
- 易用性:scikit-learn 中接口统一,易于集成到现有工作流
- 自动化:自动完成参数搜索和模型评估的全过程
- 可靠性:结合交叉验证,结果更加稳健
缺点
- 计算成本高:参数数量和取值增加时,计算量呈指数增长
- 时间消耗大:对于大型数据集或复杂模型,可能需要很长时间
- 维度灾难:当参数数量过多时,搜索空间急剧扩大
- 缺乏灵活性:无法根据前序结果调整后续搜索策略
八、使用 GridSearchCV 的注意事项
- 参数网格设计:
- 初期可以使用较粗的网格进行探索
- 根据初步结果,在最优区域进行更精细的搜索
- 避免设置过大的参数空间,平衡探索性和计算成本
- 计算资源:
- 合理设置
n_jobs参数,充分利用多核 CPU - 大型搜索任务可以考虑在 GPU 或分布式环境中运行
- 使用
verbose参数监控搜索进度
- 合理设置
- 交叉验证策略:
- 根据数据特点选择合适的交叉验证折数(通常 5-10 折)
- 对于不平衡数据,考虑使用分层交叉验证(Stratified CV)
- 时间序列数据应使用时序交叉验证
- 评估指标:
- 根据任务类型选择合适的评估指标(scoring 参数)
- 分类任务常用:accuracy, precision, recall, f1, roc_auc
- 回归任务常用:neg_mean_squared_error, r2, neg_mean_absolute_error
九、GridSearchCV 的替代方案
当 GridSearchCV 的计算成本过高时,可以考虑以下替代方案:
- RandomizedSearchCV:随机搜索参数空间,通常能在较少迭代中找到接近最优的解
- BayesianOptimization:基于贝叶斯优化的参数搜索,智能探索参数空间
- Optuna/Hyperopt:专门的超参数优化框架,支持更复杂的搜索策略
- 模型特定优化器:某些模型(如 XGBoost, LightGBM)提供了内置的参数优化工具
总结
GridSearchCV 作为一种经典的超参数优化方法,通过穷举搜索与交叉验证的结合,为机器学习模型调优提供了系统化解决方案。它的优势在于使用简单、结果可靠,特别适合参数空间较小的场景或需要全面探索参数影响的情况。
在实际应用中,我们需要根据数据集大小、模型复杂度和计算资源情况,合理设计参数网格,并在必要时结合其他优化方法,以达到最佳的模型性能和计算效率平衡。掌握 GridSearchCV 的使用,是每个数据科学家和机器学习工程师提升模型质量的必备技能。
无论是分类任务还是回归任务,GridSearchCV 都能帮助我们摆脱凭经验调参的困境,让模型性能提升建立在系统化实验的基础上,从而构建更加稳健和可靠的机器学习系统。