京东agent之joyagent解读
1、默认部署方式
(1)Github地址
https://github.com/jd-opensource/joyagent-jdgenie?tab=readme-ov-file
(2)环境准备
- jdk17
- python3.11
- python环境准备
- pip install uv
- cd genie-tool
- uv sync
- .\.venv\Scripts\activate (windows命令,激活当前项目中的python虚拟环境)
- 安装pnpm,安装命令:npm install -g pnpm(对于已经安装了Node.js的方法)
(3)配置文件修改
基于deepseek的api进行调用
复制.env_template为.env
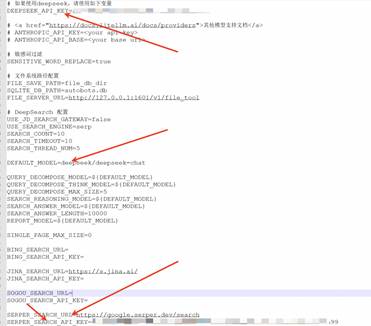
在.env文件中,删除掉默认的OPENAI_API_KEY和OPENAI_BASE_URL,然后设置我们的DEEPSEEK_API_KEY,DEFAULT_MODEL以及SERPER_API_KEY,如下:
(4)修改代码
Genie-backend下的DeepSearchTool.java文件
request_id(agentContext.getRequestId() + ":" + StringUtil.generateRandomString(5))
修改为:
request_id(agentContext.getRequestId() + "_" + StringUtil.generateRandomString(5))
2)Genie-backend下的GenieController.java文件
在public SseEmitter AutoAgent(@RequestBody AgentRequest request) 下新增代码:
String requestId = request.getRequestId().replace(":", "_");
同时将该函数中的request.getRequestId()都替换为requestId。
否则在windows环境下genie-tool会报错:
NotADirectoryError: [WinError 267] 目录名称无效。: 'file_db_dir\\geniesession-1756824119395-5013:1756824119436-3677'
(5)启动脚本调整
1)UI目录
将start.sh修改为start.bat,脚本如下:@echo off
:: Windows 批处理脚本:启动前端项目:: 获取 Node.js 主版本号
for /f "tokens=1 delims=." %%i in ('node -v 2^>nul') do set NODE_VERSION=%%i
set NODE_MAJOR=%NODE_VERSION:~1%if "%NODE_MAJOR%"=="" (echo Node.js is not installed or not in PATH.exit /b 1
)if %NODE_MAJOR% LSS 18 (echo Node.js version 18 or higher is required. Current version: v%NODE_MAJOR%exit /b 1
)
echo Node.js version: v%NODE_MAJOR% (OK):: 检查 pnpm
where pnpm >nul 2>nul
if %errorlevel% neq 0 (echo pnpm is not installed. Installing pnpm@7.33.1...call npm install -g pnpm@7.33.1if %errorlevel% neq 0 (echo Failed to install pnpm.exit /b 1)
):: 获取 pnpm 版本
for /f "tokens=1 delims=." %%i in ('pnpm -v 2^>nul') do set PNPM_MAJOR=%%i
if %PNPM_MAJOR% LSS 7 (echo pnpm version 7 or higher is required. Current version: %PNPM_MAJOR%.xexit /b 1
)
echo pnpm version: %PNPM_MAJOR%.x (OK):: 安装依赖
echo Installing dependencies...
call pnpm install --registry https://registry.npmmirror.com:: 关键:批准构建脚本(解决警告)
echo Approving build scripts...
call pnpm approve-builds:: 启动开发服务器
echo Starting dev server...
call pnpm run dev:: 如果你看到这行,说明 dev 脚本退出了
echo 🚨 Development server stopped or failed to start.pause
2)genie-backend目录
将build.sh修改为build.bat,脚本如下:@echo off
:: Windows 批处理脚本:使用 Maven 构建 Java 项目(使用阿里云镜像):: 创建阿里云镜像配置文件
echo ^<settings^> > aliyun-settings.xml
echo ^<mirrors^> >> aliyun-settings.xml
echo ^<mirror^> >> aliyun-settings.xml
echo ^<id^>aliyun^</id^> >> aliyun-settings.xml
echo ^<url^>https://maven.aliyun.com/repository/public^</url^> >> aliyun-settings.xml
echo ^<mirrorOf^>^*^</mirrorOf^> ^<^!-- 匹配所有仓库 --^> >> aliyun-settings.xml
echo ^</mirror^> >> aliyun-settings.xml
echo ^</mirrors^> >> aliyun-settings.xml
echo ^</settings^> >> aliyun-settings.xmlecho Created aliyun-settings.xml with Alibaba Cloud mirror.:: 执行 Maven 构建
echo Building project with Maven (using aliyun mirror)...
mvn clean package -DskipTests -s aliyun-settings.xml:: 检查构建是否成功
if %errorlevel% equ 0 (echo ✅ Build success! JAR/WAR file generated.
) else (echo ❌ Build failed. Please check the errors above.exit /b 1
):: 可选:暂停查看结果(调试时有用)
:: pause
执行build.bat脚本,执行一次即可。
将start.sh修改为start.bat,脚本如下:
chcp 65001 >nul
java -classpath "./target/genie-backend/conf;./target/genie-backend/lib/*" -Dbasedir="./target/genie-backend" -Dfile.encoding="UTF-8" -Dsun.jnu.encoding=UTF-8 com.jd.genie.GenieApplication
3)genie-tool目录
在python311环境下,首次启动需要执行 python -m genie_tool.db.db_engine 之后则无需执行。
修改.env_template文件,
修改ANTHROPIC_API_KEY/ ANTHROPIC_API_BASE,SERPER_SEARCH_URL/ SERPER_SEARCH_API_KEY。
activate python311
python server.py 启动服务即可
4)genie-client目录
Activate python311后,
将start.sh修改为start.bat,脚本如下:
uv run server.py
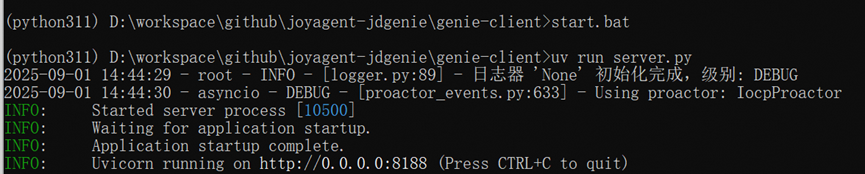
运行程序:
http://localhost:3000/
2、后端调试模式
【idea工程配置】
Genie-backend工程不需要以cmd方式打开,
在Idea中启动服务,配置好maven和project structure信息
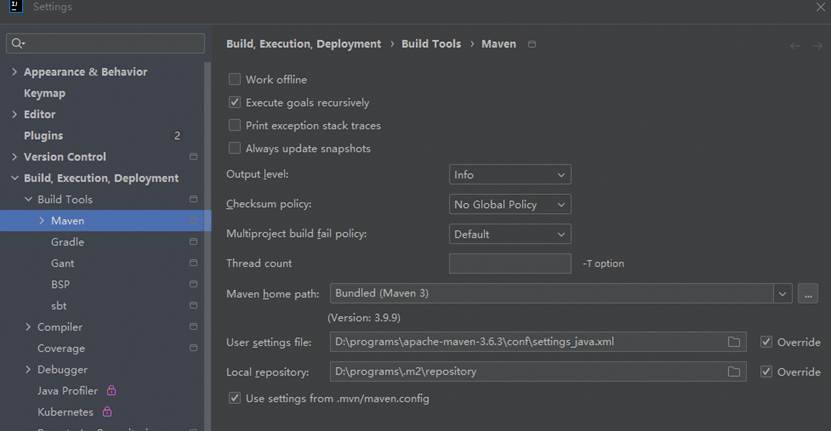
Maven配置:
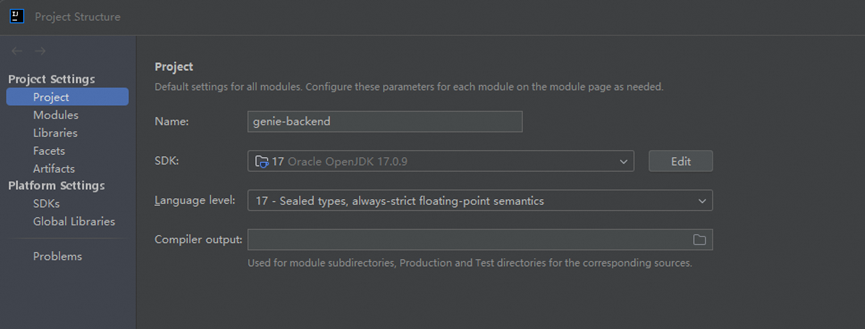
Project Settings:
3、genie-backend代码导读
(1)SSE
1)概念
SSE:Server-Sent Events,一种简单的服务器向客户端推送实时通知的技术。相比WebSocket,SSE的实现更为简单,因为它只需要服务器端发送数据到客户端,而不需要处理客户端到服务器的双向通信。
SSE的优势:
- 单向实时通信(服务端 -> 客户端)
- 基于Http协议,无需复杂握手
- 自动重连机制
- 轻量级且易于实现
2)与WebSocket的对比
| 特性 | SSE | WebSocket |
| 通信方向 | 单向(服务器到客户端) | 双向 |
| 协议 | HTTP | 独立协议 |
| 数据格式 | 文本 | 二进制/文本 |
| 断线重连 | 自动支持 | 需手动实现 |
| 浏览器兼容性 | IE 不支持 | 较新浏览器均支持 |
3)创建SSE连接
Long AUTO_AGENT_SSE_TIMEOUT = 60 * 60 * 1000L; // 1小时超时
SseEmitter emitter = new SseEmitter(AUTO_AGENT_SSE_TIMEOUT);
创建一个直播通道,最长持续1小时。
4)api
emitter.send():发送一次数据,连接保持打开
emitter.complete():彻底关闭连接,不能再发送任何数据
如果某个任务的处理过程需要发送100个数据片段,那么会调用100次send,但只会在最后调用一次complete。
5)emitter事件
emitter.onCompletion():任务完成
emitter.onTimeout():任务超时
emitter.onErro():任务失败
6)创建、释放emitter实例时机
一对一关系:一个HTTP请求对应一个SseEmitter实例。SseEmitter本质上就是这个特定连接的句柄或通道。
独立性:每个SseEmitter实例都是独立的。它们可以有不同的超时时间、不同的监听器。这样可以确保不同用户的请求,或者同一个用户的不同任务请求之间互不干扰。
资源管理:因为每次请求都创建,所以必须在任务结束时(成功、失败或超时)调用emitter.complete()或emitter.completeWithErro()来释放资源。否则这些emitter实例会一直占用内存和线程,最终导致服务器资源耗尽。
(2)java类
1)包用途
Java.util.concurrent.Executors:多线程类
Java.util.concurrent.ScheduledFuture:定时任务(比如每10秒发一次心跳)
java.util.concurrent.ScheduledExecutorService:定时和周期性任务调度的线程池
2)数据结构
10_000:java语法糖,用于分隔大数字,提高可读性。10_000等同于10000。
3)Map类
- computeIfAbsent方法
原型:V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)
如果key非null且在map中有值,则返回value值
如果key为null或在map中无值,则mappingFunction这个lambada函数重新计算值,并将值写入map中。
- getOrDefault方法
原型:V getOrDefault(Object key, V defaultValue)
如果key在map中有值,则返回value值
如果key在map中无值,则返回默认值defaultValue
- EnumMap
专门给枚举类型的map,比hashmap更快
使用示例:
Map<AgentType, AgentResponseHandler> map = new EnumMap<>(AgentType.class);
4)好方法
BeanUtils.copyProperties:把一个实例赋值给另一个实例,避免逐个属性赋值
5)线程
【BasicThreadFactory】
作用:自定义线程池中的线程属性
关键方法:namingPattern()、daemon()
示例:
ThreadFactory threadFactory = new BasicThreadFactory.Builder()
.namingPattern("exe-pool-%d") // 设置线程名格式
.daemon(true) // 设置为守护线程(JVM退出时自动结束)
.build();
【CountDownLatch】
作用:等待一组线程完成
关键方法:countDown()、await()
示例:
CountDownLatch latch = new CountDownLatch(tasks.size());
for (Runnable task : tasks) {
executor.execute(() -> {
try {
task.run();
} finally {
latch.countDown(); // 确保执行
}
});
}
latch.await(); // 主线程等待全部完成
System.out.println("所有任务完成!");
(3)spring类
1)@Controller
Spring MVC控制器,接收和处理Web请求,返回值默认是视图名,用于渲染HTML页面
2)@ResponseBody
让控制器方法的返回值直接写入HTTP响应体(Response Body)中,而不是被解释为一个视图名称。
3)@RestController
是一个组合注释,@Controller + @ResponseBody
将一个类标记为处理HTTP请求的控制器,并且该类中所有@RequestMapping(或其变体@GetMapping,@PostMapping等)方法的返回值都会自动序列化(例如转换为JSON或XML)并直接写入HTTP响应体。
4)@RequestMapping的produces属性
内容协商参数。
作用:
- 请求匹配:客户端发送请求时在Accept请求头中声明能够接受哪些类型的响应(比如Accept: application/json),Spring会检查控制器方法的produces属性,只有两者一致才会被选中处理这个请求,如果不匹配Spring会返回406 Not Acceptable状态码
- 设置响应头:当Spring方法成功执行并返回时会将produces中指定的MIME类型设置到HTTP响应的Content-Type头中,告诉客户端:“我给你的数据是xx类型的“。
5)@Autowired
它是Spring框架的自动配送员,它的作用是:你只需要说“我需要什么”,Spring就会自动把合适的对象“送上门”,不用你手动new。它是IOC控制反转和DI依赖注入的核心武器。
6)@Accessor(chain=true)
@Accessor是控制Lombok自动生成的getter和setter方法的样式,
chain=true支持链式调用,比如:
User user = new User().setName(“xx”).setAget(25);
7)@EqualAndHashCode(callSupper=true)
让Lombok生成的equals()和hashCode()方法不仅基于当前类的字段,还包括从父类继承来的字段。
equals用于比较两个类是否相等,默认情况下只看当前类中属性是否都相同。
加了callSupper=true之后,还会比较下父类中的属性。
8)@Bean
作用在方法上,表示该方法的返回值要交给Spring的IOC容器。
一般出现在@Configuration类中。
适用于:
- 第三方库的对象(你无法在类上加@Component)
- 需要复杂初始化编辑的对象(如带参数的构造函数、Builder模式)
关于spring容器注册Bean的说明:
- 注册的bean的key包含类型和名称
- 注册时或者加载类时都可以自定义名称
- 类默认名称是类名(首字母小写),方法+Bean默认是方法名。
9)@Autowired
【两种用法】
- 用在字段上
@Component
public class OrderService {
@Autowired
private PaymentService paymentService; // 自动主入
}
- 用在方法上
在类实例化时会自动执行该方法,并把需要的对象传进去
- 构造函数可省略的情况:
@Component
public class OrderService {
private final PaymentService paymentService;
// @Autowired 可以省略(如果只有一个构造函数)
public OrderService(PaymentService paymentService) {
this.paymentService = paymentService;
}
}
- 普通函数的情况
@Component
public class DataInitializer {
@Autowired
public void init(UserService userService, OrderService orderService) {
System.out.println("系统初始化中...");
userService.initData();
orderService.initData();
}
}
【List、Map用法】
当用@Autowired注入:
- List<T>:把所有类型为T的Bean打包成一个列表给我
- Map<String, T>:把所有类型为T的Bean,按名字当key,示例当value,做成一个字典给我
4、系统概念
(1)心跳机制的作用
为什么需要心跳:SSE是长时间保持的,如果很长时间(比如30秒)服务端都没有调用emitter.send()发送任何数据,网络中间件(比如代理、防火墙)或客户端可能会认为连接已经“死亡“并主动断开它。
心跳如何工作:周期性地(比如5秒)调用emitter.send()发送一个保活信息,不包含业务数据。
(2)主流程、非守护线程、守护线程区别
主流程:老板角色。是程序的起点和终点,它也是非守护线程
非守护线程:正式员工角色。它是主流程派出去干活的核心员工,只要该员工还在干活,JVM就得等着
守护线程:临时工角色。主流程和非守护线程结束,它立刻会被终止。
(3)ReAct模式
ReAct = Reasoning(思考) + Acting(行动)
核心循环:Think -> Act -> Observe -> Thingk …
5、看过的类说明
1)GenieController.java
智能体流程控制器总入口
2)AgentHandlerFactory.java
智能体处理器工厂
方法1:负责把所有处理器服务放到handlerMap(key: handerName, value:handler实例)中
方法2:获取handler实例
3)AgentContext.java
Bean类,包含一次请求的上下文的所有信息
- RequestId:一次请求的UUID
- SessionId:一次会话,用于管理多轮对话
- Task:当前正在执行的具体任务,从query中拆解出来的子任务
- Printer:一个消息发送器,用于把AI的思考、结果实时推送给前端
- ToolCollection:一个工具集合
- ProductFiles:一批产品文件,用户上传的资料
- StreamMessageType:流式输出时,当前发送的消息类型,前端根据类型做不同展示
- SopPrompt:SOP(标准作业流程)提示词,定义AI应该遵循的步骤
- BasePrompt:基础提示词,定义AI的角色、语气、风格等
- AgentType:当前Agent的类型,比如1=编程助手,2=客服助手
- TaskProductFiles:当前任务生成的中间产物文件,多步任务中,上一步生成的文件作为下一步的输入
4)AgentContext.java
Bean类,前端发送给AI助手的请求
- Erp:用户的ERP账号,用于身份识别和权限控制
- Messages:历史对话消息列表,用于支持多轮对话
- OutputStyle:输出格式,AI会根据这个字段调整输出结构和排版
5)AgentHandlerService.java
接口类
处理Agent请求的handle方法
判断是否满足handler条件的support方法
6)ReactHandlerImpl.java
ReAct模式的处理器
Executor.run(request.getQuery()),executor为ReActAgent:接收query,开始ReAct循环,将每一步记录到自己的memory(记忆)中
SummaryAgent会从memory获取所有数据进行总结
7)PlanSolveHandlerImpl.java
任务分解与并行执行的智能调度器
PlaningAgent:负责任务拆解,得到的结果比如:收集项目背景<sep>分析技术难点<sep>设计解决方案
ExecutorAgent:负责执行子任务
SummaryAgent:负责最终总结
Planner-Executor反馈循环:
- Planner拆任务
- Executor执行
- 结果反馈给Planner
- Planner决定是否继续、调整或结束
MemoryIndex:记录当前executor的记忆长度,用于后续合并
两个planning.run():第一个是任务拆解,while中的第2个用于判断任务是否完成。
整体流程:

8)Handler类和Agent类的关系
Handler是系统调度员,控制流程,调用多个Agent,处理异常、状态、文件、推送。
Agent是执行工人,不关心上下文流程,只关心怎么完成这个任务。
目前有ReAct模式、PlanSolve模式,新增一种模式增加Handler。
新增一种能力增加Agent。
9)BaseAgent.java
定义了所有Agent的公共能力与执行流程。
DuplicateThreshold:重复动作阈值,防止Agent在同一个工具或动作上反复打转
Step():子类必须实现如何执行”一步”,是生成计划?执行动作?还是总结?
它是AI执行引擎的模板,定义了:
- 如何运行(run循环)
- 如何记忆(memory)
- 如何调用工具(executeTool)
10)ReActAgent.java
抽象类,实现了经典的ReAct模式=Reason + Act,即思考+行动的循环。
FormatSystemPrompt:生成完整的提示词
11)ReactImplAgent.java
ReAct模式的具体实现,实现了think和act方法。
MaxObserve:控制每次工具返回结果的最大长度,防止工具返回过长污染上下文。
ToolChoice.AUTO:允许LLM自主决定是否调用工具
12)SummaryAgent.java
用于任务完成后的总结阶段,对整个对话过程进行归纳,并提取最终交付物(如文件)。
它不参与ReAct循环,而是在主流程结束后调用,生成最终报告。
典型使用流程:
- 主Agent(如ReactImplAgent)完成任务,生成若干文件
- 调用SummaryAgent.summaryTaskResult(历史消息, 原始问题)
- SummaryAgent构造提示词,让LLM生成:
“本次任务完成了销售分析,发现Q2增长显著。$$$report.xlsx、chart.png“
- 解析出summary和文件列表
- 返回给前端展示最终结果
13)PlanningAgent.java
任务的指挥官,不亲自干活,而是指定计划、分配任务、监控进度,确保任务完成。
- 指定计划:根据用户问题和可用工具,生成多步计划
- 管理计划:通过planningTool 创建、更新、推进计划
- 驱动计划:决定每一步调用哪个工具,或推进到下一个任务
- 支持固定计划模式:一旦计划生成,可关闭修改,按序执行
- 与ReAct框架融合:复用think()/act()循环,但专注“计划“而非”执行执行”
14)ExecutorAgent.java
与PlanningAgent不同,它不制定计划,而是专注于调用工具、执行操作、返回结果。
接收任务:从PlanningAgent或用户处接收具体任务
决策调用:根据上下文决定调用哪个工具
执行操作:调用search、code、file、api等工具
返回结果:将执行结果写回记忆,并推送给前端
15)LLMSettings.java
LLM配置类
16)AgentType.java
agentType:
- Comprehensive(1):综合型智能体
比如用户说:帮我分析以下上个月的销售数据,并生成一份PPT发给领导
Comprehensive Agent会拆解任务:查数据 -> 分析 -> 生成PPT -> 发送。
- Workflow(2):工作流型智能体
适用于标准化流程(如审批、报表生成、客服流程),
按顺序或条件执行节点,
每个节点可配置输入/输出/错误处理,
支持暂停、恢复、人工干预
- Plan-slove(3):规划-求解型智能体
适用于复杂多步任务。
比如:帮我找一家适合家庭出行的三亚酒店,价格中等,评分4.5以上。
Plan_Solve Agent会规划:搜索三亚酒店 -> 筛选评分 -> 筛选价格 -> 推荐Top3
- Router(4):路由型智能体
负责将任务发放给最合适的Agent
实现方式:
使用LLM或规则引擎进行分类:
- 是规划类? 传给PLAN_SOLVE
- 是流程类?传给WORKFLOW
- 是综合任务?传给COMPREHENSIVE
- 是简单回答?直接回答
调用目标Agent并返回结果
技术特点:
- 使用fewshot prompting进行任务分类
- 可能结合embedding + 向量相似度 匹配
- 支持fallback机制(如果目标Agent失败则Agent切换、模式降级、人工介入,保证系统永远有答案,哪怕不是最优)
- 是实现Mixture of Agents(MOA)的关键
- REACT(5):ReAct智能体(推理+行动)
各种模式的差异和协同:
核心架构:
CEO:COMPREHENSIVE综合决策
项目经理:PLAN_SOLVE先规划再执行
流水线工人:WORKFLOW按流程办事
前台接待:ROUTER分流任务
研究员:REACT边想边做
协同工作:

17) SSEPrinter.java
用于将AI Agent的执行过程和结果实时推送给前端。
【Tool_thought】工具调用前的思考,比如:"我需要查询京东上iPhone 15的价格,先使用搜索工具。"
【Task】子任务描述,拆解出的一个具体执行任务。比如:"执行顺序1. 搜索iPhone 15在京东的售价"。
【Task_summary】任务摘要,一个任务完成后的总结性描述,通常包含结构化信息。比如:
{
"taskSummary": "已搜索iPhone 15价格,最低价为5999元,来自京东自营。",
"productId": "1000123456",
"price": 5999,
"shop": "京东自营"
}
【Plan_thought】规划阶段的思考,全局策略思考,比如tool_thought更高层。比如:"用户想买手机,我需要先了解预算和偏好,再搜索比价,最后推荐最优选项。"
【Plan】结构化的踱步执行计划。比如:
// 假设 message 是一个 Plan 对象
Plan plan = new Plan();
plan.setPlanId("plan_001");
plan.setDescription("购买iPhone 15");
plan.setSteps(Arrays.asList(
new Step(1, "询问用户预算"),
new Step(2, "搜索京东、途虎价格"),
new Step(3, "比较售后服务"),
new Step(4, "生成推荐报告")
));
【tool_result】工具调用结果,调用外部工具(比如搜索、API)后返回的结构化结果。比如:
{
"toolName": "web_search",
"toolInput": "iPhone 15 价格",
"toolOutput": "京东:5999元,途虎:6199元,拼多多:5799元(非自营)",
"success": true
}
【agent_stream】流式文本输出,前端应拼接显示,实现打字机效果。
【result】最终结果。任务完成后的最终输出,可能是字符串、Map或对象。
String的形式:"已为您找到最低价:5799元(拼多多),但推荐京东自营(5999元)以保障售后。"
Map的形式:
{
"taskSummary": "推荐京东自营 iPhone 15,价格5999元,次日达,支持7天无理由退货。",
"recommendation": "京东",
"price": 5999,
"url": "https://item.jd.com/1000123456.html"
}
Json的形式:
{
"finalReport": {
"title": "购机建议",
"items": [
{ "product": "iPhone 15", "price": 5999, "source": "京东" }
]
}
}
6、LLM执行主流程
(1)用户输入问题
用户输入:途虎养车怎么样?
组装system_prompt、user_prompt、tools后的python程序如下:
import os
from openai import OpenAI
# 系统提示词(保持不变)
system_prompt = '''
# 角色
你是一个智能助手,名叫Genie。
# 说明
你是任务规划助手,根据用户需求,拆解任务列表,从而确定planning工具入参。每次执行planning工具前,必须先输出本轮思考过程(reasoning),再调用planning工具生成任务列表。
# 技能
- 擅长将用户任务拆解为具体、独立的任务列表。
- 对简单任务,避免过度拆解任务。
- 对复杂任务,合理拆解为多个有逻辑关联的子任务
# 处理需求
## 拆解任务
- 深度推理分析用户输入,识别核心需求及潜在挑战。
- 将复杂问题分解为可管理、可执行、独立且清晰的子任务,任务之间不重复、不交叠。拆解最多不超过5个任务。
- 任务按顺序或因果逻辑组织,上下任务逻辑连贯。
- 读取文件后,对文件进行处理,处理完成保存文件应该放到一个子任务中。
## 要求
- 每一个子任务都是一个完整的子任务,例如读取文件后,将文件中的表格抽取出出来形成表格保存。
- 调用planning工具前,必须输出500字以内的思考过程,说明本轮任务拆解的依据与目标。
- 首次规划拆分时,输出整体拆分思路;后续如需调整,也需输出调整思考。
- 每个子任务为清晰、独立的指令,细化完成标准,不重复、不交叠。
- 不要输出重复的任务。
- 任务中间不能输出网页版报告,只能在最后一个任务中,生成一个网页版报告。
- 最后一个任务是需要输出报告时,如果没有明确要求,优先“输出网页版报告”,如果有指定格式要求,最后一个任务按用户指定的格式输出。
- 当前不能支持用户在计划中提供内容,因此不要要求用户提供信息
## 输出格式
输出本轮思考过程,200字以内,简明说明拆解任务依据或调整依据,并调用planning工具生成任务计划。
# 语言设置
- 所有内容均以 **中文** 输出
# 任务示例:
以下仅是你拆解任务的一个简单参考示例,你在解决问题时,参考如下拆解任务,但不要局限于如下示例计划
## 示例任务1:分析 xxxx
任务列表
- 执行顺序1. 信息收集:收集xxxx
- 执行顺序2. 筛选分析:xxxx,分析并保存成Markdown文件
- 执行顺序3. 输出报告:以网页形式呈现分析报告,调用网页生成工具
##示例任务2:提取文件中的表格
任务列表
- 执行顺序1. 文件表格提取:读取文件内容,抽取文件中存在的表格,并保存成表格文件。
## 示例任务3:分析 xxxx,以PPT格式展示
任务列表
- 执行顺序1. 信息收集:收集xxxx
- 执行顺序2. 筛选分析:xxxx,分析并保存成Markdown文件
- 执行顺序3. 输出PPT:以PPT呈现xx,调用PPT生成工具
## 示例任务4:我要写一个 xxxx
任务列表
- 执行顺序1. 信息收集:收集xxxx
- 执行顺序2. 文件输出:以网页形式呈现xxx,调用网页生成工具
===
# 环境变量
## 当前日期
<date>
今天是 2025年9月18日 星期四
</date>
## 当前可用的文件名及描述
<files>
</files>
## 用户历史对话信息
<history_dialogue>
{{history_dialogue}}
</history_dialogue>
## 约束
- 思考过程中,不要透露你的工具名称
- 调用planning生成任务列表,完成所有子任务就能完成任务。
- 以上是你需要遵循的指令,不要输出在结果中。
Let's think step by step (让我们一步步思考)
'''
user_prompt = '''
一步一步(step by step)思考,结合用户上传的文件分析用户问题,并根据问题制定计划,用户问题如下:途虎养车怎么样?
'''
# 初始化 OpenAI 兼容客户端(指向 DashScope)
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 定义 planning 工具(function)
tools = [
{
"type": "function",
"function": {
"name": "planning",
"description": "这是一个计划工具,可让代理创建和管理用于解决复杂任务的计划。该工具提供创建计划、更新计划步骤和跟踪进度的功能。",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"enum": ["create", "update", "mark_step"],
"description": "需要执行的命令"
},
"title": {
"type": "string",
"description": "任务的标题,仅在 command 为 create 时必填"
},
"steps": {
"type": "array",
"items": {"type": "string"},
"description": "任务列表,格式为 ['执行顺序1. 简称: 详细描述', ...],仅在 command 为 create 时必填"
},
"step_index": {
"type": "integer",
"description": "当前操作的步骤索引,仅在 command 为 mark_step 时必填"
},
"step_status": {
"type": "string",
"enum": ["not_started", "in_progress", "completed", "blocked"],
"description": "步骤状态,仅在 command 为 mark_step 时使用"
},
"step_notes": {
"type": "string",
"description": "步骤备注,可选"
}
},
"required": ["command"] # 注意:只有 command 是全局必填
}
}
}
]
# 发起请求
completion = client.chat.completions.create(
model="qwen-plus", # 可替换为 qwen-max, qwen-turbo 等
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
tools=tools, # 使用 tools 字段(OpenAI 格式)
tool_choice="auto", # 让模型自动决定是否调用工具
)
# 输出结果
print(completion.model_dump_json())
得到的结果如下:
{"id":"chatcmpl-59ddb0dc-9d38-4380-aa3e-0dd9ea66ba79","choices":[{"finish_reason":"tool_calls","index":0,"logprobs":null,"message":{"content":"当前用户问题为“途虎养车怎么样?”,需结合上传文件进行分析。但当前环境变量中未提供任何可用文件(<files>为空),无法读取具体数据支持分析。因此,任务拆解将基于公开信息的理解逻辑进行初步规划,后续若文件加载成功可调整计划。\n\n首先需明确“途虎养车”的评价维度,通常包括服务质量、价格透明度、用户口碑、门店覆盖、售后服务等。由于无结构化数据输入,无法执行数据提取或文件处理任务,故不涉及文件操作类子任务。\n\n下一步应聚焦于信息收集与综合评估:通过可靠渠道获取相关信息,整理关键指标,并形成结构化分析。最终输出需为网页版报告,便于展示图文内容。\n\n因此,计划拆解为三个步骤:先收集多维度信息,再进行优劣分析与总结,最后生成网页报告。避免过度拆解,确保任务独立且连贯。\n\n","refusal":null,"role":"assistant","annotations":null,"audio":null,"function_call":null,"tool_calls":[{"id":"call_ebc34c2902074c23b1f742","function":{"arguments":"{\"command\": \"create\", \"title\": \"分析途虎养车服务情况\", \"steps\": [\"执行顺序1. 信息收集:搜集途虎养车的服务范围、价格体系、用户评价、门店分布及售后政策等相关信息,确保来源可靠并覆盖主要维度\", \"执行顺序2. 综合分析:基于收集的信息,分析途虎养车的优势(如标准化服务、品牌保障)与潜在不足(如价格偏高、区域覆盖有限),形成结构化结论\", \"执行顺序3. 输出报告:将分析结果整合为一份网页版报告,包含服务概述、核心优势、用户反馈、对比分析及总结建议\"]}","name":"planning"},"type":"function","index":0}]}}],"created":1758194673,"model":"qwen-plus","object":"chat.completion","service_tier":null,"system_fingerprint":null,"usage":{"completion_tokens":348,"prompt_tokens":1282,"total_tokens":1630,"completion_tokens_details":null,"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0}}}
Planning返回:
LLM.ToolCallResponse(content=, toolCalls=[ToolCall(id=call_00_9QjyyL9bbirJ9kukvGXUQDSO, type=function, function=ToolCall.Function(name=planning, arguments={"command": "create", "title": "途虎养车服务分析", "steps": ["执行顺序1. 文件分析:读取用户上传的文件,提取关于途虎养车的相关信息", "执行顺序2. 信息收集:收集途虎养车的服务内容、价格、用户评价等数据", "执行顺序3. 数据分析:分析途虎养车的优势、劣势和用户反馈", "执行顺序4. 报告生成:以网页形式呈现途虎养车服务分析报告"]}))], finishReason=null, totalTokens=null, duration=0)