Linux的设备驱动模型
一、设备驱动编写流程
-
实现入口函数xxx_init()和卸载函数xxx_exit()
-
申请设备号 register_chrdev_region()
-
初始化字符设备,cdev_init函数、cdev_add函数
-
硬件初始化,如时钟寄存器配置使能,GPIO设置为输入输出模式等。
-
构建file_operation结构体内容,实现硬件各个相关的操作
-
在终端上使用mknod根据设备号来进行创建设备文件(节点) (也可以在驱动使用class_create创建设备类、在类的下面device_create创建设备节点)
在内核源码的drivers中存放了大量的设备驱动代码, 在我们写驱动之前先查看这里的内容,说不定可以在这些目录找到想要的驱动代码。
二、设备驱动模型
这里有个问题,根据某个硬件编写的驱动只要修改了一下引脚接口,这个驱动代码就得重新修改才能使用,这显然是不合理的。
Linux引入了设备驱动模型分层的概念, 将我们编写的驱动代码分成了两块:设备与驱动。设备负责提供硬件资源而驱动代码负责去使用这些设备提供的硬件资源。 并由总线将它们联系起来。这样子就构成以下图形中的关系。
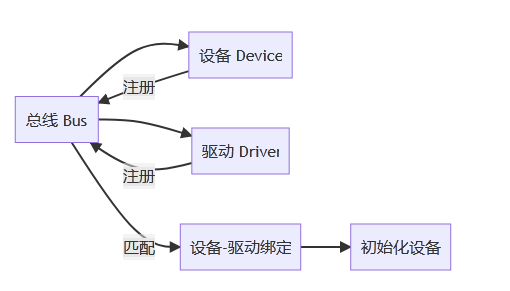
设备模型通过几个数据结构来反映当前系统中总线、设备以及驱动的工作状况,提出了以下几个重要概念:
设备(device) :挂载在某个总线的物理设备;
驱动(driver) :与特定设备相关的软件,负责初始化该设备以及提供一些操作该设备的操作方式;
总线(bus) :负责管理挂载对应总线的设备以及驱动;
类(class) :对于具有相同功能的设备,归结到一种类别,进行分类管理;
我们知道在Linux中一切皆“文件”,在根文件系统中有个/sys文件目录,里面记录各个设备之间的关系。
“总线-设备-驱动”它们之间是如何相互配合工作的呢?
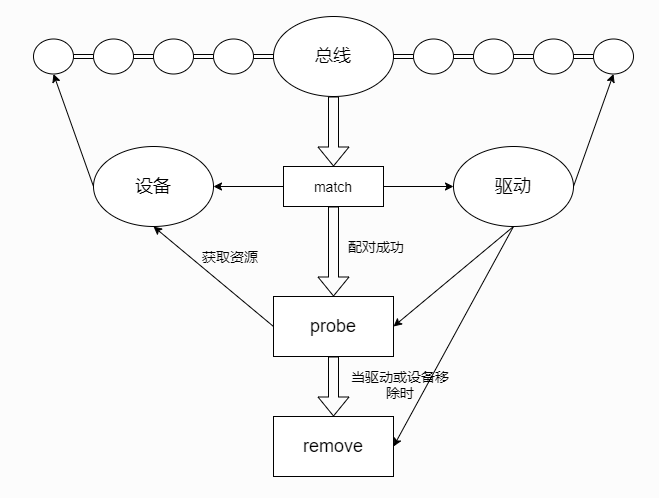
在总线上管理着两个链表,分别管理着设备和驱动,当我们向系统注册一个驱动时,便会向驱动的管理链表插入我们的新驱动, 同样当我们向系统注册一个设备时,便会向设备的管理链表插入我们的新设备。
在插入的同时总线会执行一个bus_type结构体中match的方法对新插入的设备/驱动进行匹配。 (它们之间最简单的匹配方式则是对比名字,存在名字相同的设备/驱动便成功匹配)。
在匹配成功的时候会调用驱动device_driver结构体中probe方法(通常在probe中获取设备资源,具体的功能可由驱动编写人员自定义), 并且在移除设备或驱动时,会调用device_driver结构体中remove方法。
三、实现
/* 设备ID表 (驱动侧) */
static struct usb_device_id myusb_table[] = {{ USB_DEVICE(0x1234, 0x5678) }, // 厂商ID+产品ID{}
};/* 驱动结构 */
static struct usb_driver myusb_driver = {.name = "my_usb_drv",.id_table = myusb_table, // 绑定依据.probe = myusb_probe, // 设备连接时调用.disconnect = myusb_disconnect, // 设备断开时调用
};/* 设备连接初始化 */
static int myusb_probe(struct usb_interface *intf, const struct usb_device_id *id)
{// 1. 获取设备信息struct usb_device *udev = interface_to_usbdev(intf);// 2. 分配设备私有数据struct myusb_dev *dev = kzalloc(sizeof(*dev), GFP_KERNEL);// 3. 设置端点通信usb_find_bulk_in_endpoint(..., &dev->bulk_in_ep);// 4. 注册设备节点usb_register_dev(intf, &myusb_class);
}
参考:
https://blog.csdn.net/qq_38061020/article/details/149645494
https://doc.embedfire.com/linux/imx6/base/zh/latest/linux_driver/linux_device_model.html