Pulsar存储计算分离架构设计之存储层BookKeeper(下)
六、Bookie的数据读取流程
我们继续跟着上一篇的server端的源码分析上来,直接看 org.apache.bookkeeper.proto.BookieRequestProcessor#processRequest 这个方法,在最新版本的Bookie代码中,读取操作的核心逻辑基于READ_ENTRY操作码(opCode)实现,同时读取处理器(read processor)已迭代升级至V3版本,优化了数据处理的性能和可靠性。我们这里直接跟写入流程一样,读取流程也来分析V3版本的源码。
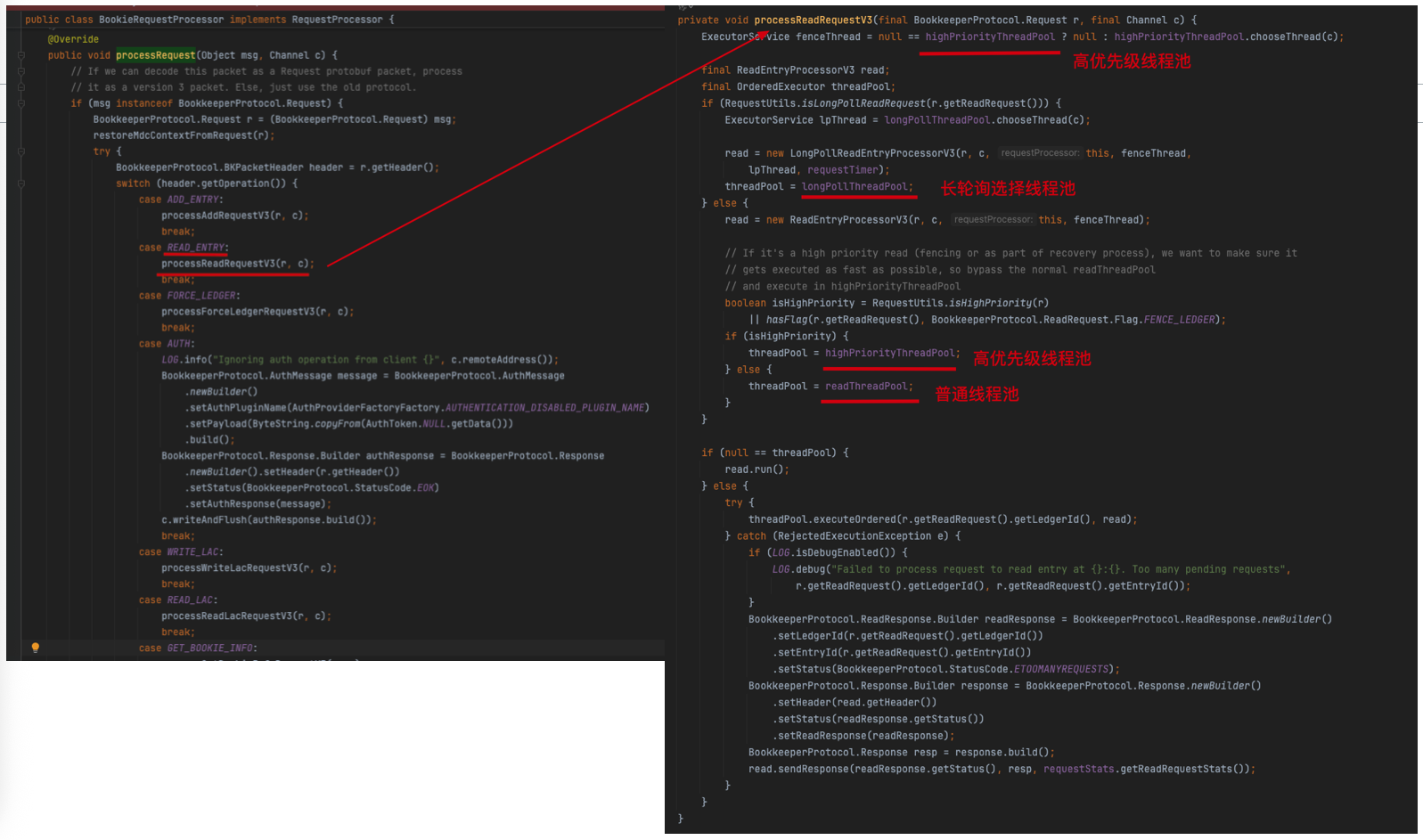
processReadRequestV3 方法的核心逻辑见下:
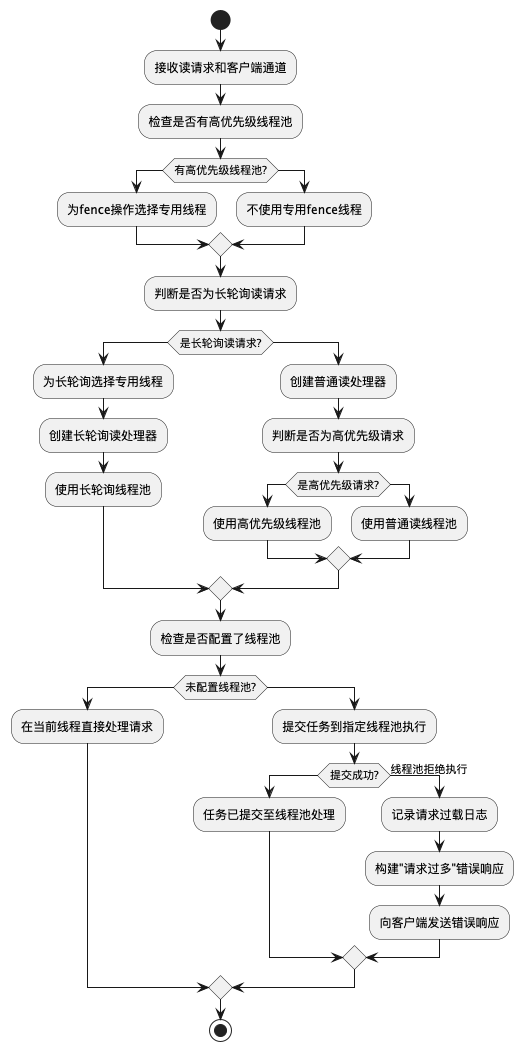
上面代码跟进来,在 org.apache.bookkeeper.bookie.Bookie#readEntry:
这段代码的读取流程通过多层委托实现:首先根据LedgerId找到LedgerDescriptor,随后其readEntry方法将请求转交给LedgerStorage接口的getEntry方法,最终由SingleDirectoryDbLedgerStorage#getEntry实际执行(与写入流程共用同一实现类)。整个过程体现了接口抽象与分层解耦的设计思想。
SingleDirectoryDbLedgerStorage#getEntry
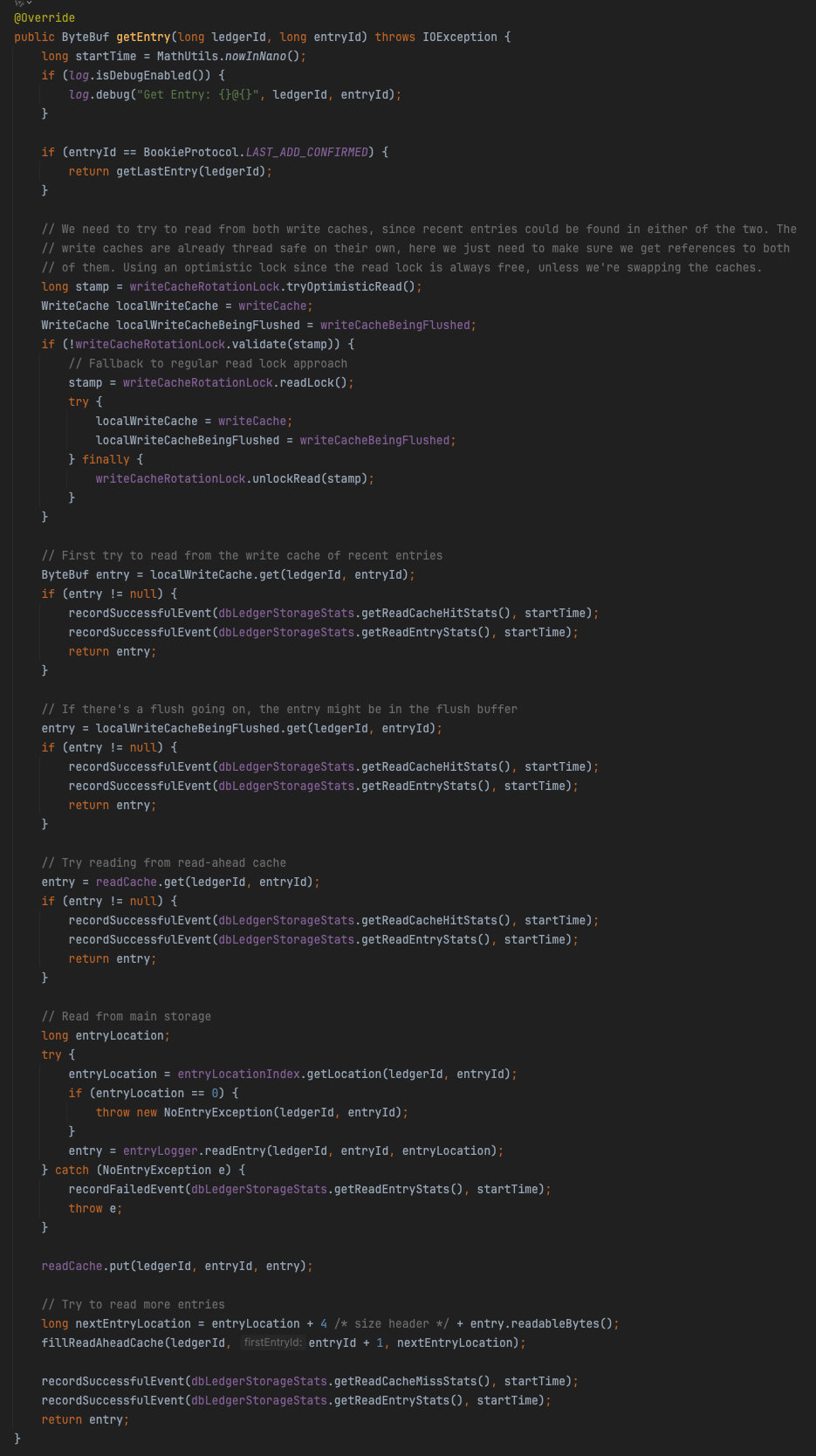
以下是getEntry方法核心要点总结:
- 特殊处理
- 当 entryId 为 LAST_ADD_CONFIRMED 时,调用 getLastEntry(ledgerId) 获取最新确认的条目
- 写缓存访问机制
- 使用乐观读锁获取当前写缓存引用,避免阻塞写操作
- 双重检查机制:
- 首先检查 writeCache(当前写入缓存)
- 然后检查 writeCacheBeingFlushed(正在刷盘的缓存)
- 缓存命中时立即返回并记录统计信息
- 读缓存检查
- 检查 readCache(读取缓存)是否存在目标条目
- 命中时记录缓存命中统计并返回结果
- 主存储读取流程
- 通过索引 entryLocationIndex 查找条目在日志中的位置
- 位置为0时表示条目不存在,抛出 NoEntryException
- 调用 entryLogger.readEntry 从磁盘读取实际数据
- 缓存更新策略
- 将从磁盘读取的条目放入 readCache 供后续访问使用
- 执行预读操作 fillReadAheadCache 加载后续条目到缓存中
- 性能统计记录
- 缓存命中:记录 readCacheHitStats
- 缓存未命中:记录 readCacheMissStats
- 读取操作成功/失败:记录 readEntryStats
EntryLogger如何读取entry
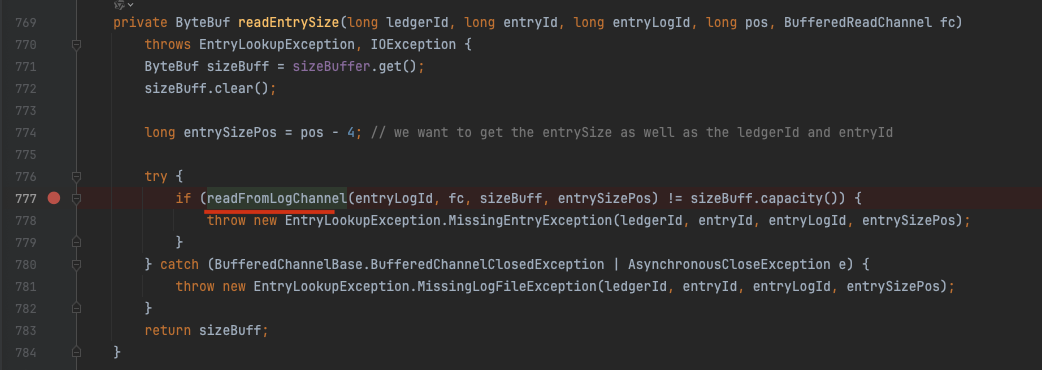
org.apache.bookkeeper.bookie.EntryLogger#internalReadEntry
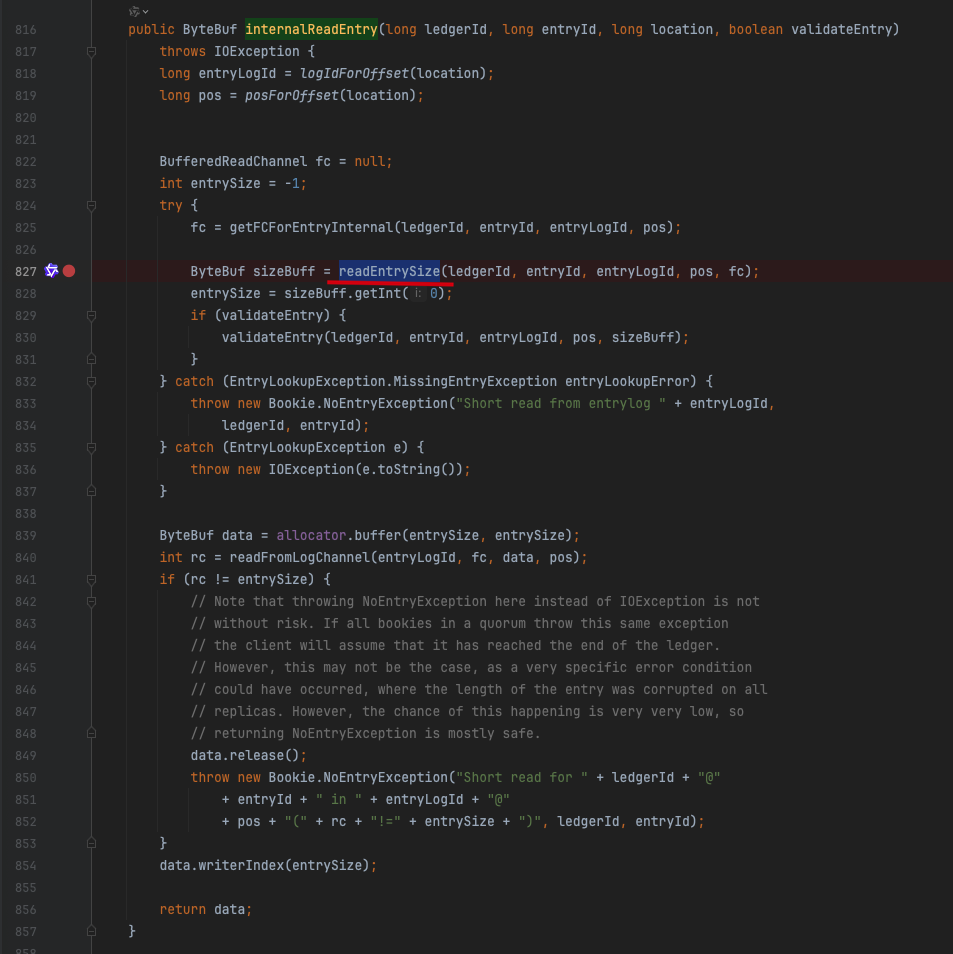
主要的逻辑点:
- 位置解析
- 从 location 参数中提取 entryLogId(日志文件ID)和 pos(文件内位置)
- 用于定位具体在哪个日志文件的哪个位置读取数据
- 文件通道获取与大小读取
- 调用 getFCForEntryInternal 获取对应的文件读取通道
- 通过 readEntrySize 方法读取条目大小信息:
- 从位置 pos - 4 处读取4字节的大小信息
- 这4字节包含了条目的长度信息
- 数据读取核心逻辑
- 根据读取到的条目大小分配 ByteBuf 缓冲区
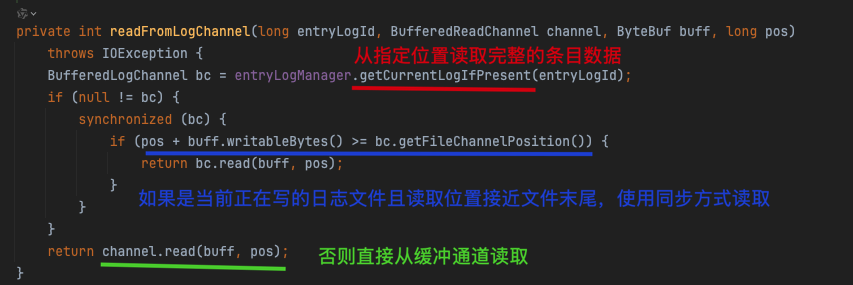
- 调用 readFromLogChannel 从指定位置读取完整的条目数据
- 读取逻辑优化:
- 如果是当前正在写的日志文件且读取位置接近文件末尾,使用同步方式读取
- 否则直接从缓冲通道读取
- 异常处理与完整性检查
- 如果读取的字节数与预期大小不匹配,抛出 NoEntryException
- 处理多种异常情况:
- MissingEntryException:条目不存在
- MissingLogFileException:日志文件不存在
- 其他 IO 异常
- 资源管理
- 正确设置 ByteBuf 的写索引到数据末尾
- 读取失败时及时释放已分配的缓冲区资源
七、Bookie的数据读取流程总结
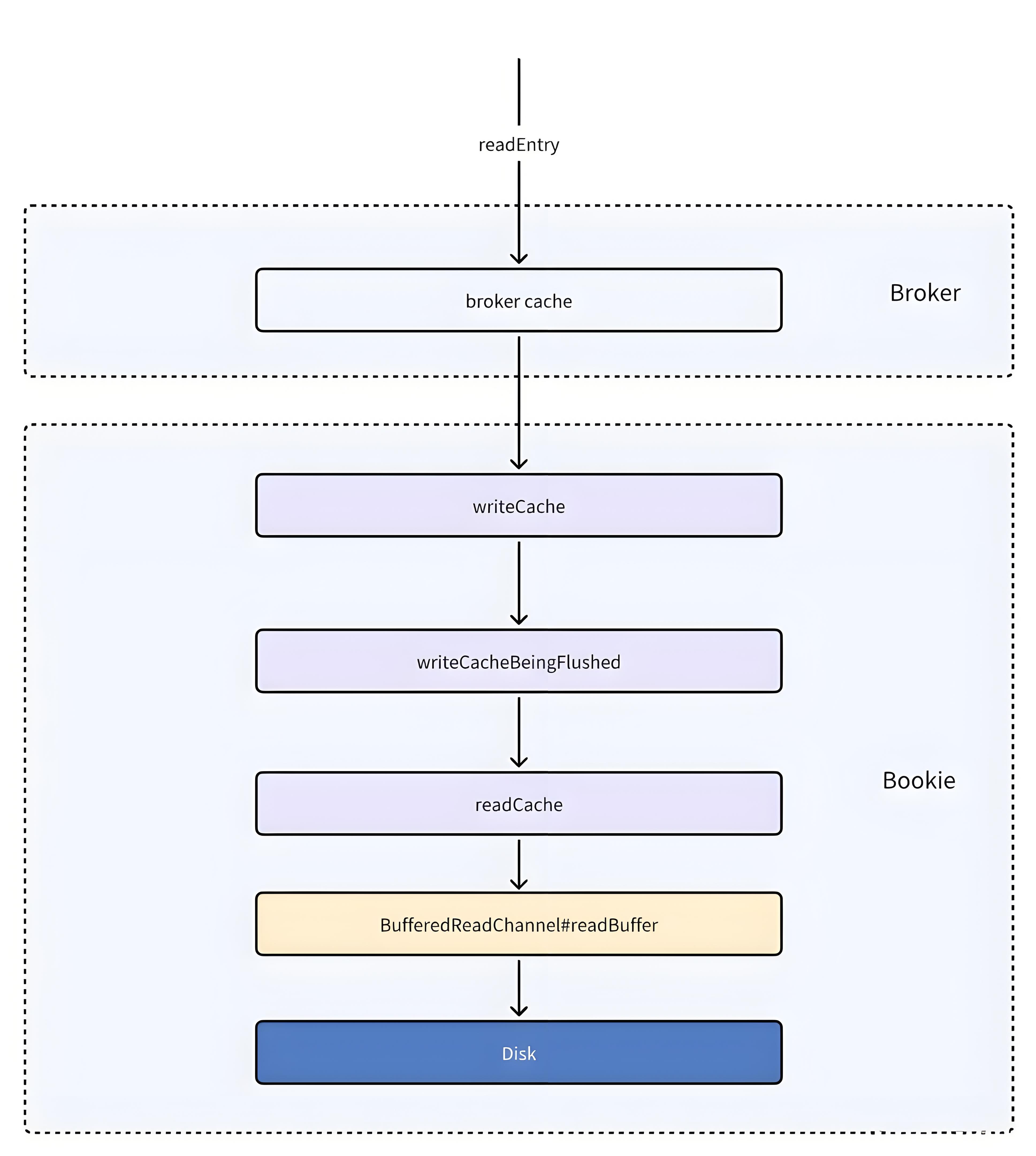
7.1 Bookie的数据读取流程整体架构
读取流程相对于上一篇写入流程来说简单些
在整体架构中,数据读取需依次穿透三级缓存:首先访问最上层缓存,未命中则逐级下沉至次级缓存,若三级缓存均未命中,最终触发磁盘访问。值得注意的是,Broker组件内部还存在独立的内存缓存层,用于拦截高频请求。整个消息获取流程如下图所示:
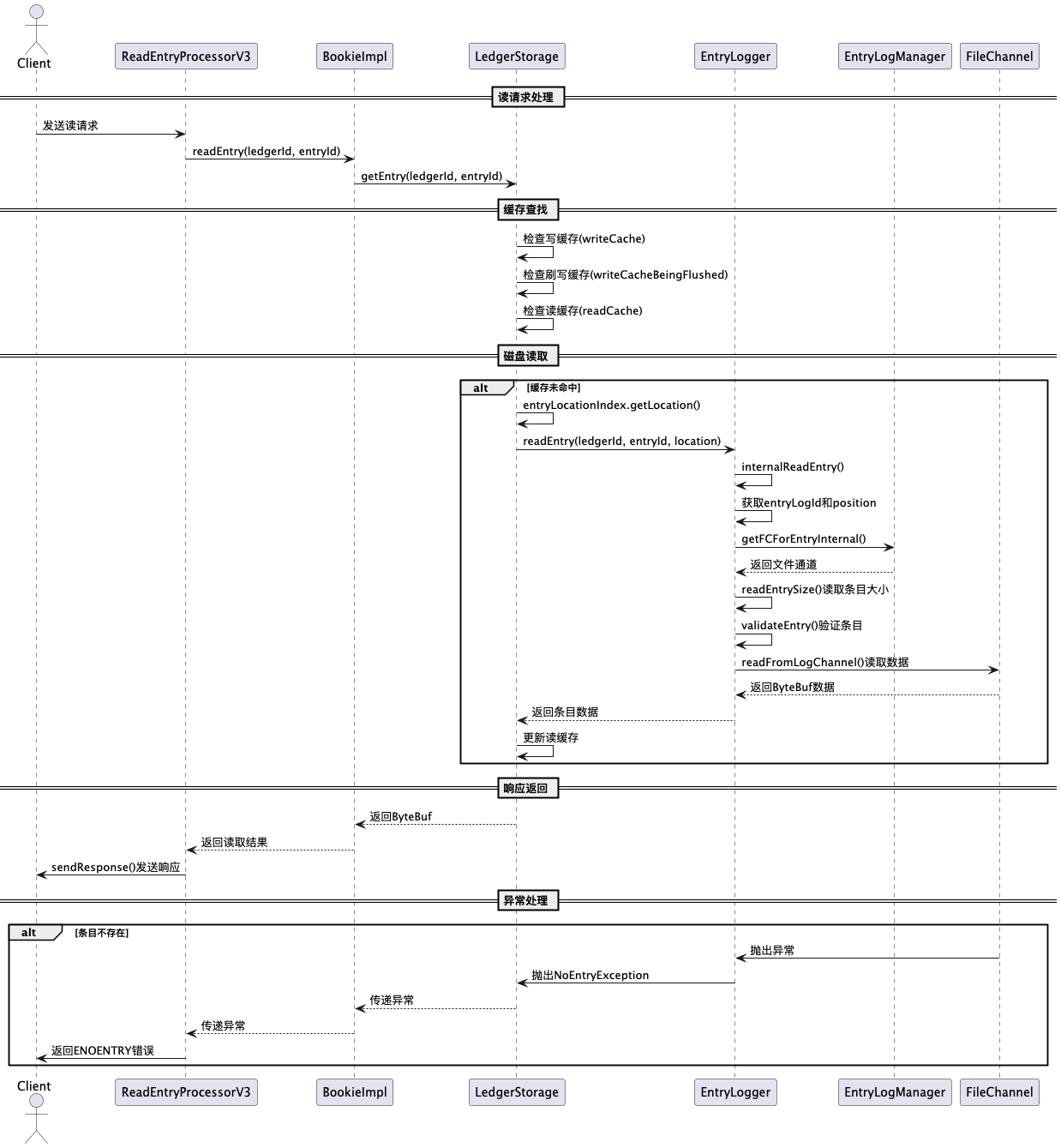
7.2 Bookie的数据读取流程核心时序图
7.3 组件模块分析
BufferedChannel
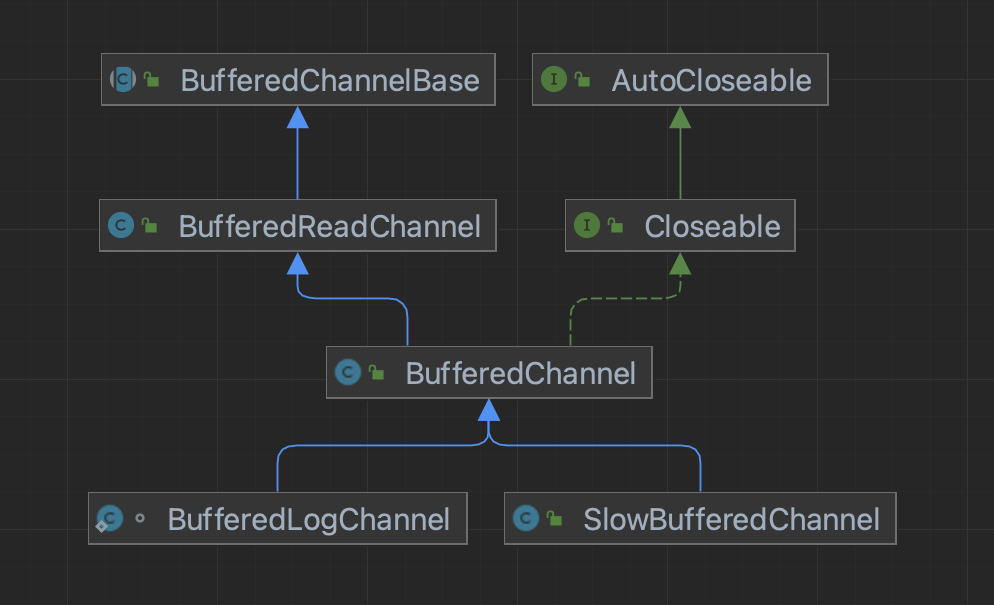
这几个Channel类在BookKeeper中构成了一个层次化的缓冲I/O通道体系,各自有不同的用途和特点:
- BufferedChannelBase(基础类)
- 含义:所有缓冲通道的基类,提供基本的缓冲功能
- 使用场景:作为其他缓冲通道类的共同基类,提供通用功能
- BufferedChannel(通用缓冲通道)
- 含义:标准的缓冲读写通道,支持读写操作
- 使用场景:
- 用于一般的文件读写操作
- 作为其他专用通道的基础实现
- SlowBufferedChannel(慢速缓冲通道)
- 含义:专门用于模拟慢速存储设备的通道,主要用于测试
- 使用场景:
- 测试环境中的故障模拟
- 性能基准测试
- 验证系统在慢速存储下的行为
- BufferedReadChannel(缓冲读通道)
- 含义:专门优化用于读操作的缓冲通道
- 使用场景:
- Bookie读取日志文件条目
- 优化读密集型操作的性能
- BufferedLogChannel(日志缓冲通道)
- 含义:专门用于BookKeeper日志文件的缓冲通道
- 使用场景:
- Bookie写入entry日志文件
- 管理journal日志文件
- 处理日志文件的生命周期
EntryLogger
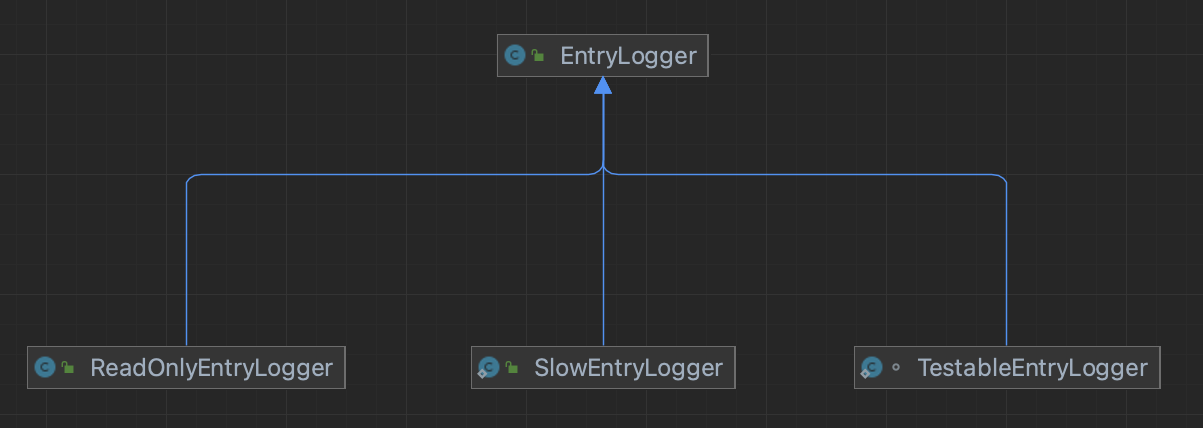
- EntryLogger(条目日志记录器)
- 含义:标准的条目日志管理器,负责条目的读写操作
- 使用场景:
- Bookie正常运行时的条目读写
- Journal和EntryLogger的日常操作
- ReadOnlyEntryLogger(只读条目日志记录器)
- 含义:专门用于只读操作的条目日志记录器
- 使用场景:
- 数据恢复过程
- 备份和归档操作
- 只读副本或镜像节点
- 垃圾回收(Garbage Collection)过程中的日志扫描
- SlowEntryLogger(慢速条目日志记录器)
- 含义:用于模拟慢速日志操作的记录器,主要用于测试和调试
LedgerStorage
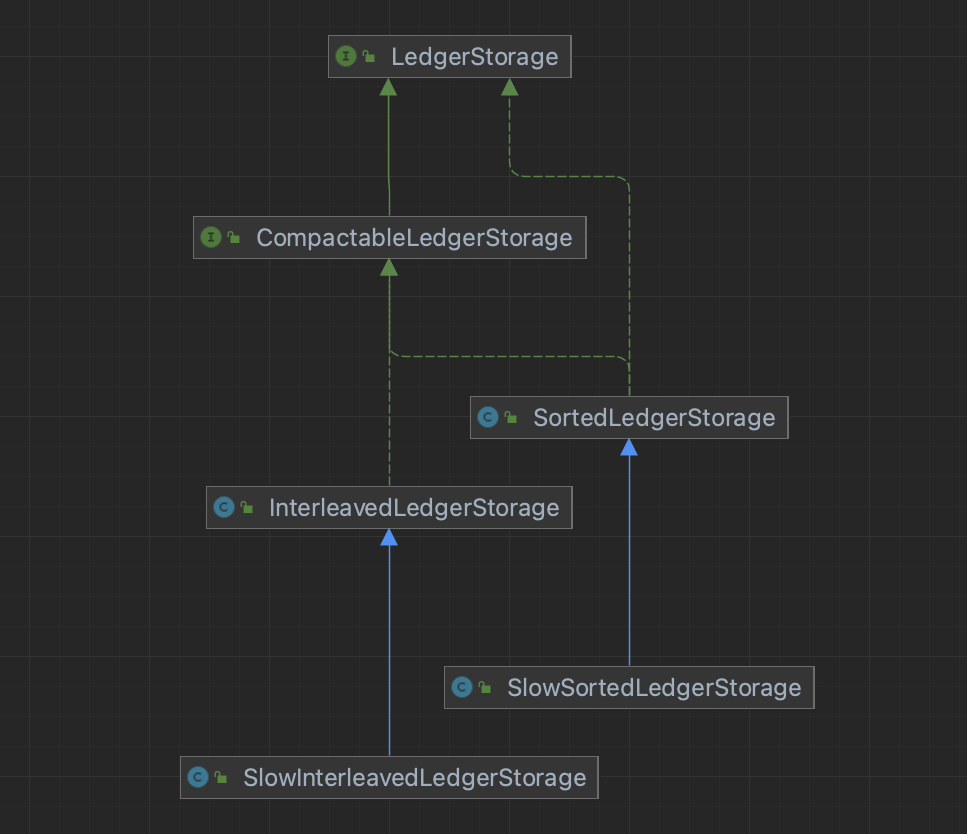
- LedgerStorage(账本存储接口)
- 含义:账本存储的顶层接口,定义了所有账本存储实现必须提供的基本操作
- 使用场景:作为所有账本存储实现的统一接口
- CompactableLedgerStorage(可压缩账本存储)
- 含义:支持垃圾回收和压缩操作的账本存储抽象类
- 使用场景:需要定期清理过期数据的存储场景
- SortedLedgerStorage(排序账本存储)
- 含义:基于排序索引的账本存储实现
- 使用场景:需要有序访问条目或范围查询的场景
- InterleavedLedgerStorage(交错账本存储)
- 含义:交错存储多个账本条目的实现,是BookKeeper最常用的存储格式
- 使用场景:BookKeeper默认的生产环境存储实现
- SlowInterleavedLedgerStorage(慢速交错账本存储)
- 含义:模拟慢速存储的交错账本存储实现,用于测试
- 使用场景:系统性能测试、容错能力验证、慢速存储环境模拟
- SlowSortedLedgerStorage(慢速排序账本存储)
- 含义:模拟慢速存储的排序账本存储实现,用于测试
- 使用场景:排序存储相关的性能测试、系统稳定性和容错性验证
八、存储层BookKeeper架构总结
Bookie的存储架构设计围绕高性能读写优化展开,通过三级存储结构实现吞吐量与延迟的平衡。
Journal层作为第一道屏障,采用顺序混合写入模式,不同Topic的消息被交织写入独立挂载的磁盘,以此实现低延迟写入(写完即返回)。但混合存储的特性导致其难以支持单个Topic的顺序读取和消息回溯,存在显著的读放大问题。
EntryLog层通过二次转储解决Journal的读取缺陷:写入时按LedgerId+EntryId排序,使同一Ledger的数据物理相邻,提升局部性读取效率。每条消息写入后会记录其物理偏移量(Offset),但该Offset缺乏业务语义——无法直接反映消息在Topic中的逻辑顺序,而消费端恰恰依赖这种逻辑序列进行位点管理。
为此引入索引层构建LedgerId+EntryId到物理Offset的映射关系。Bookie同时支持RocksDB(Pulsar默认选用)和自研KV引擎存储该映射,通过用户态缓存(优于PageCache)降低容器化环境中多POD间的IO干扰,确保读写性能稳定。
整个架构通过分层设计实现写入高吞吐与读取低延时的统一:Journal保障写入速度,EntryLog优化数据局部性,索引层弥合物理存储与逻辑消费的鸿沟,配合用户态缓存减少抖动。