【YOLO 模型入门】(1)一文读懂 YOLO:从核心概念到检测原理
一、YOLO 是什么?—— 从名称到本质
提到目标检测领域的 “明星算法”,YOLO 绝对是绕不开的存在。它的全称是 You Only Look Once(你只看一次),光从名字就能感受到它的核心优势 —— 快。这款由 Joseph Redmon 团队在 2016 年提出的深度学习算法,彻底改变了传统目标检测的 “分步思维”,至今仍是实时检测场景的首选方案之一。

1. 核心思想:把检测变成 “回归问题”
传统目标检测往往需要分步骤处理(比如先找候选框、再分类),而 YOLO 的突破在于 将 “目标分类” 和 “位置定位” 两个任务,通过一个神经网络一次性完成—— 本质上是把目标检测转化为 “端到端的回归问题”。
简单理解:给模型输入一张图,它不需要 “分步思考”,直接输出所有目标的类别概率(比如 “这是猫”“这是车”)和位置坐标(比如目标在图像的左上角和右下角坐标),整个过程像人类 “一眼看清物体” 一样直接。
2. 核心原理:网格划分 + 多尺度检测
YOLO 的检测逻辑可以拆解为 3 个关键步骤,用 “网格化思维” 就能轻松理解:
步骤 1:图像网格化划分
模型会先将输入图像均匀分成 S×S 个网格(比如经典 YOLO v1 用 7×7 网格)。每个网格有一个 “职责”—— 负责检测 “目标中心落在该网格内” 的物体。举个例子:如果一只狗的中心位置在图像的第 3 行第 5 列网格里,那么就由这个网格来预测这只狗的类别和位置。
步骤 2:预测目标关键信息
每个网格会输出两组核心信息:
- 类别概率:判断该网格内的目标属于哪个类别(比如 “狗” 的概率是 98%,“猫” 的概率是 1%);
- 边界框(Bbox)参数:包括边界框的中心坐标(相对于网格的偏移量)、宽高(相对于整个图像的比例),以及一个 “置信度”(表示这个边界框里有目标的概率,越接近 1 越可信)。
步骤 3:多尺度特征融合
为了兼顾 “大目标” 和 “小目标” 的检测效果(比如同时检测图像里的汽车和路边的行人),YOLO 会融合不同层级的特征图:
- 深层特征图:感受野大,适合检测大目标;
- 浅层特征图:细节丰富,适合检测小目标。通过这种方式,YOLO 既能 “看全” 大物体,也能 “看清” 小物体,解决了早期目标检测算法 “漏检小目标” 的痛点。
检测过程:输入一张图片,直接得到一张图片并且候选框框选出物体。

3. YOLO 的优势:为什么它能火这么久?
对比传统目标检测算法(比如 R-CNN 系列),YOLO 的核心优势集中在两点:
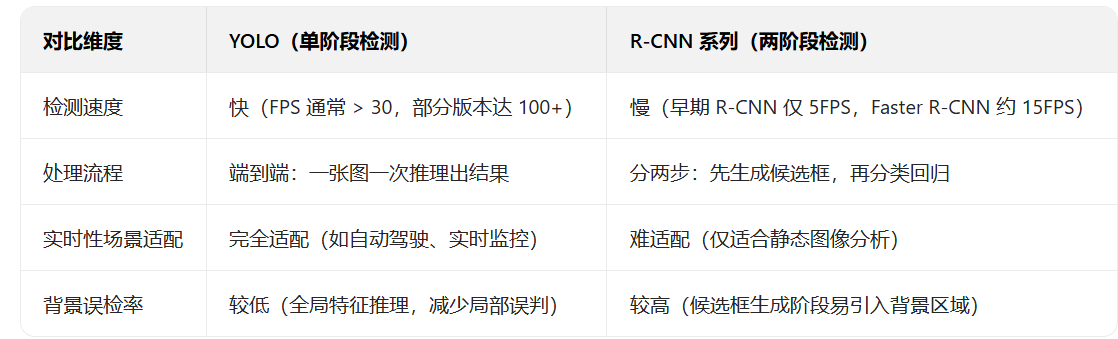
正是这些优势,让 YOLO 在自动驾驶、实时监控、无人机巡检、工业质检等场景中成为 “刚需算法”—— 比如自动驾驶需要每秒处理 30 帧以上的图像,YOLO 能轻松满足;而传统两阶段算法则会因为速度不够导致 “延迟误判”。
二、目标检测的两大流派:单阶段 vs 两阶段
要理解 YOLO 的定位,就必须先搞清楚目标检测的两大技术路线 ——单阶段检测(One-Stage) 和 两阶段检测(Two-Stage)。YOLO 是单阶段检测的 “开山鼻祖” 之一,而 R-CNN 系列则是两阶段的代表。
1. 单阶段检测(One-Stage):直接出结果
核心逻辑
跳过 “候选框生成” 步骤,直接通过神经网络对图像进行全局推理,一次性输出目标的类别和位置。相当于 “一步到位”,直接给答案。
优缺点
- 优点:速度极快(FPS 高),适合实时场景;流程简单,易部署;
- 缺点:早期版本准确率略低于两阶段算法(但 YOLO v5/v7/v8 已大幅追赶,部分场景反超);小目标检测精度在早期版本中较弱(后续版本通过多尺度融合优化)。
代表算法
YOLO 系列(v1~v8)、SSD(Single Shot MultiBox Detector)、RetinaNet 等。
2. 两阶段检测(Two-Stage):分步精细化
核心逻辑
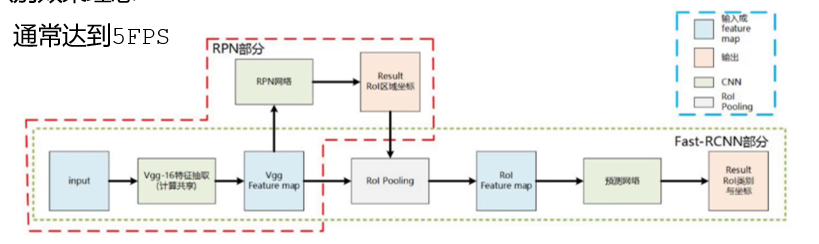
分两步处理,先 “找可能有目标的区域”,再 “判断区域里是什么”:
- 第一阶段(候选框生成):用 Selective Search、RPN(Region Proposal Network)等算法,从图像中生成几百到几千个 “可能有目标的候选框”(比如 “这个区域像猫”“那个区域像车”);
- 第二阶段(分类与回归):对每个候选框进行精细处理 —— 用 CNN 提取特征,然后判断候选框内的目标类别,并修正边界框的位置(让框更精准地框住目标)。
优缺点
- 优点:准确率高(分步优化,减少误判);小目标检测效果早期优于单阶段;
- 缺点:速度慢(两步推理,计算量高);流程复杂,部署成本高;
代表算法
R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN(在检测基础上增加了实例分割)。
3. 一句话总结:选单阶段还是两阶段?
- 若需求是实时性(如自动驾驶、直播特效):优先选 YOLO 等单阶段算法;
- 若需求是极致准确率(如医学影像分析、静态图像精细检测):可考虑 Faster R-CNN、Mask R-CNN 等两阶段算法。
三、如何评估 YOLO 的性能?—— 核心指标 mAP
训练完 YOLO 模型后,怎么判断它的检测效果好不好?不能只靠 “肉眼看几张图”,需要一个量化指标 ——mAP(mean Average Precision,平均精度均值),这是目标检测领域的 “通用评分标准”。
1. mAP 的本质:兼顾 “准” 和 “全”
目标检测需要同时满足两个要求:
- 准:预测的目标不能错(比如把 “狗” 说成 “猫”),边界框不能偏(比如框住了狗的一半);
- 全:图像里的目标不能漏(比如图像里有 3 只猫,不能只检测出 2 只)。
mAP 正是结合了 “精确率(Precision)” 和 “召回率(Recall)” 两个指标,同时衡量 “准度” 和 “全度”,最终给出一个综合分数。
2. 计算 mAP 的 4 个关键步骤
要理解 mAP,需要先从基础概念 “TP/FP/FN” 开始,再一步步推导到 AP 和 mAP。
步骤 1:定义 TP、FP、FN(判断预测结果的 “对与错”)
首先需要一个 “标准答案”——GT(Ground Truth,真值框),即人工标注的目标位置和类别(比如标注 “这是猫,位置在 (100,200,300,400)”)。然后对比模型预测的边界框(Pred Bbox)和 GT,用IoU(交并比) 来判断预测是否正确:
- IoU:预测框和真值框的 “交集面积” 除以 “并集面积”,值越大表示重合度越高(通常设定 IoU≥0.5 为 “重合”)。
基于 IoU,定义 4 种结果:
- TP(True Positive,真正例):预测框与某个 GT 的 IoU≥0.5,且类别预测正确(比如预测 “猫”,GT 也是 “猫”);
- FP(False Positive,假正例):两种情况 ——①IoU<0.5(框错了);②类别预测错(比如把 “狗” 预测成 “猫”);
- FN(False Negative,假负例):GT 存在,但模型没检测出来(漏检);
- TN(True Negative,真负例):图像里没有目标,模型也没预测出目标(对目标检测意义不大,通常不关注)。
步骤 2:计算精确率(Precision)和召回率(Recall)
精确率(Precision):预测对的正例占所有预测正例的比例 → 衡量 “准不准”。公式:Precision = TP / (TP + FP)例:模型预测了 10 个 “猫”,其中 8 个是对的(TP=8),2 个是错的(FP=2),则 Precision=8/(8+2)=80%。
召回率(Recall):预测对的正例占所有真实正例的比例 → 衡量 “全不全”。公式:Recall = TP / (TP + FN)例:图像里实际有 10 只猫(TP+FN=10),模型只检测出 8 只(TP=8),则 Recall=8/10=80%。
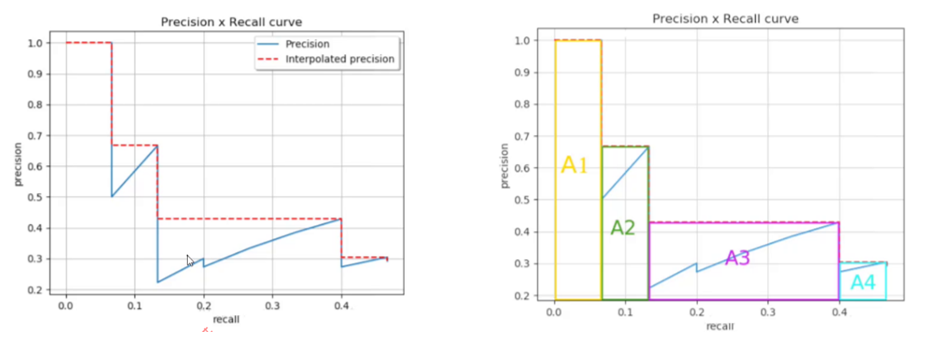
步骤 3:绘制 PR 曲线并计算 AP(单类别精度)
AP(Average Precision)是单个类别的 “精度评分”,计算过程如下:
- 对模型预测的所有边界框,按 “置信度” 从高到低排序(置信度越高,模型越确定这个框里有目标);
- 依次取前 1 个、前 2 个、…、前 N 个预测框,计算对应的 Precision 和 Recall;
- 以 Recall 为横轴、Precision 为纵轴,绘制PR 曲线(曲线越靠右上角,性能越好);
- 计算 PR 曲线下的面积(AUC-PR),这个面积就是该类别的 AP 值。
步骤 4:计算 mAP(所有类别平均精度)
mAP 是所有类别的 AP 值的平均值。比如检测任务包含 “猫、狗、车”3 个类别,它们的 AP 分别是 90%、85%、88%,则 mAP=(90%+85%+88%)/3≈87.7%。
关键结论:mAP 值越高(最高 100%),模型的检测性能越好。实际应用中,YOLO v8 在 COCO 数据集(包含 80 个类别)上的 mAP@0.5(IoU 阈值 0.5)可达到 90% 以上,足以满足大部分工业场景需求。
四、总结:YOLO 的核心知识点
1. 本质定位:YOLO 是单阶段目标检测算法,核心是 “端到端回归”,一次推理出目标的类别和位置;
2. 核心原理:通过网格划分、边界框预测、多尺度特征融合,兼顾检测速度和精度;
3. 流派对比:单阶段(快,适合实时)vs 两阶段(准,适合静态),YOLO 是单阶段的代表;
4. 性能评估:用 mAP 衡量,兼顾 “准度(Precision)” 和 “全度(Recall)”,mAP 越高效果越好。
下一篇文章,我们将深入 YOLO 的演进史(从 v1 到 v8 的核心改进),看看这款算法是如何一步步从 “快但不准” 迭代到 “又快又准” 的。感兴趣的同学可以收藏关注,后续持续更新!