IEEE内期刊论文爬取

IEEE Xplore是一个学术数据库,它涵盖了电气电子工程、计算机科学、通信等领域的大量学术文献,包括期刊论文、会议论文、标准等。本文,我来给大家分享一下IEEE Xplore数据库内期刊论文的基本爬取方法(需要源代码的可以直接点击目录中的完整代码跳转)。
注意:IEEE Xplore有IP认证,本文的爬虫环境为机构认证的校园网段IP,如果是一般用户,那么本文内的所有代码都需要使用账号或机构认证登录后携带cookie方可正常运行。
爬取思路
爬取思路很简单,完全按照下边的流程来即可。
- 输入期刊名,向该期刊名下的url发起请求
- 解析获取Current Issue内文章标题与链接,
- 向每个文章链接(Adobe pdf阅读器链接)发起请求,保存二进制数据到本地。
期刊Url获取
考虑到普适性,这里我们将IEEE xplore内所有期刊名称及其url全部爬取下来,爬取的网页链接是
https://ieeexplore.ieee.org/browse/periodicals/title?contentType=periodicals![]() https://ieeexplore.ieee.org/browse/periodicals/title?contentType=periodicals这个网页内包含了IEEE所有期刊的名称与链接
https://ieeexplore.ieee.org/browse/periodicals/title?contentType=periodicals这个网页内包含了IEEE所有期刊的名称与链接
抓包分析
在网页内按下F12打开开发者工具,点击网络-Fetch/Xhr,心存侥幸地看看有没有json数据
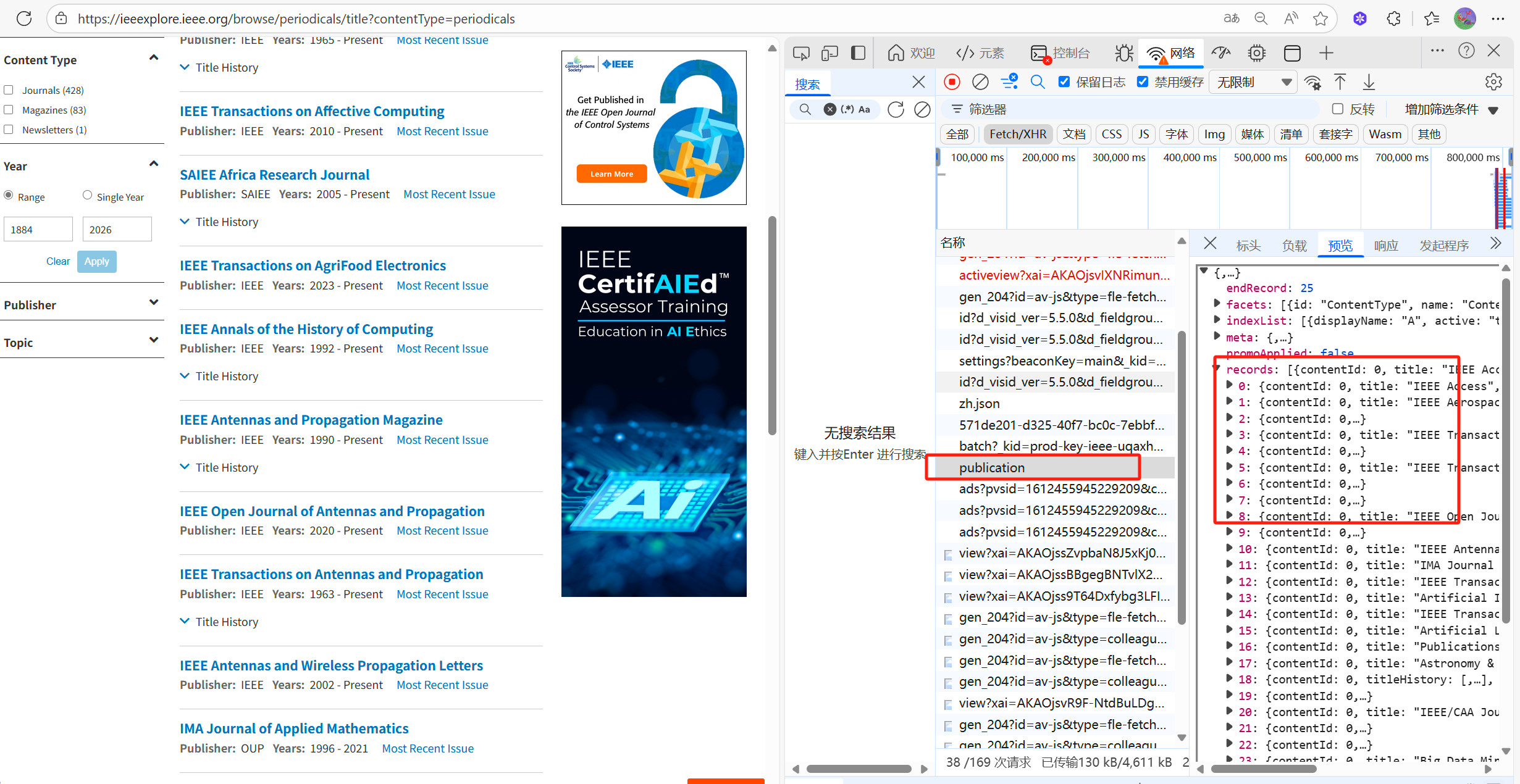
翻找一会儿,不难发现,这个名为publication的json文件便是我们需要的数据包。
进一步观察可以发现,有用的数据都在records下的列表里,列表里内的每一个字典都对应着左侧一个期刊的详细信息,而字典内其中最有用的显然是‘title’与'publicationLink'这两个键值对
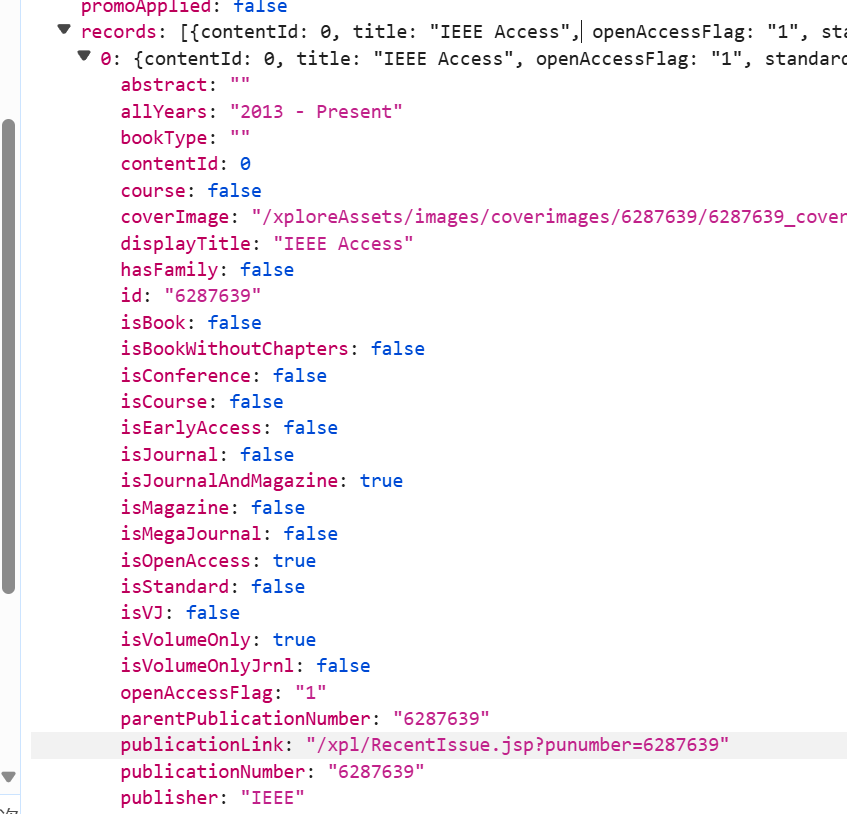
废话少说,直接上代码:
import requestsheaders={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','content-type': 'application/json','origin': 'https://ieeexplore.ieee.org','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://ieeexplore.ieee.org/browse/periodicals/title?contentType=periodicals','sec-ch-ua': '"Microsoft Edge";v="141", "Not?A_Brand";v="8", "Chromium";v="141"','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',
}payload={'contentType': 'periodicals','publisher': None,'tabId': 'title',
}response=requests.post('https://ieeexplore.ieee.org/rest/publication', headers=headers, params=payload)
titles=[dic.get('title') for dic in response.json()['records']]
publicationLinks=[dic.get('publicationLink') for dic in response.json()['records']]
print(titles)
print(publicationLinks)运行这个代码,只能获取到第一页内的期刊名称及其url,考虑到便携性,我们继续来分析一下payload参数来实现分页爬取所有内容到本地j的son中。
payload
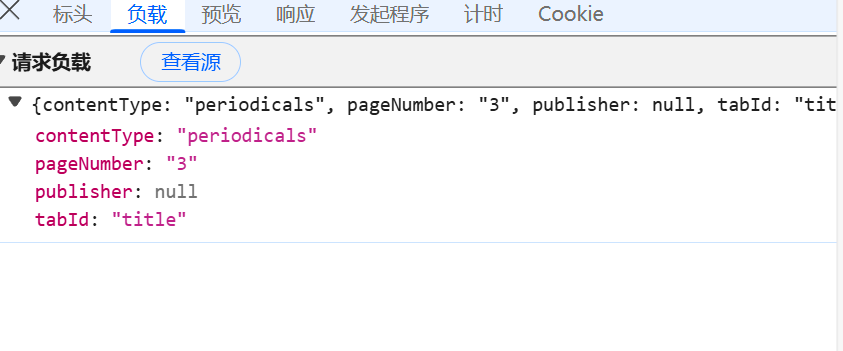
随便切换几页,发现payload内除了pageNumber会变化外(第一页没有pageNumber),其他参数固定。并且切换page到最后一页,总页数为14。
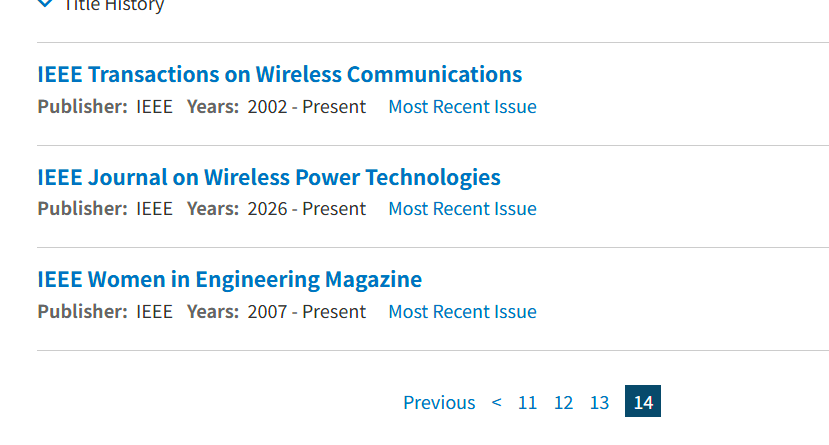
那么,显然我们只需要不带pagenumber参数将第一页内容爬取后,再使用一个2-14的for循环发起13次请求即可将所有内容爬取下来。
完整代码
运行该代码后,会自动将IEEE Xplore内所有期刊名称,url爬取下来,以字典的格式保存到本地json文件中。
import json
import requests
from requests.adapters import HTTPAdaptersession=requests.Session()
adapter=HTTPAdapter(
pool_connections=10,
pool_maxsize=35,
max_retries=3,
pool_block=False)
session.max_redirects=5
session.mount('http://', adapter)
session.mount('https://', adapter)headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','content-type': 'application/json','origin': 'https://ieeexplore.ieee.org','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://ieeexplore.ieee.org/browse/periodicals/title?contentType=periodicals','sec-ch-ua': '"Microsoft Edge";v="141", "Not?A_Brand";v="8", "Chromium";v="141"','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',
}json_data={'contentType': 'periodicals','publisher': None,'tabId': 'title',
}
IEEE_json=dict()
response=session.post('https://ieeexplore.ieee.org/rest/publication', headers=headers, json=json_data)
Pub_Ids=[dic.get('id') for dic in response.json()['records']]
Titles=[dic.get('title') for dic in response.json()['records']]
Links=['https://ieeexplore.ieee.org'+dic.get('publicationLink') for dic in response.json()['records']]
for i in range(2,15):json_data['pageNumber']=f'{i}'response=session.post('https://ieeexplore.ieee.org/rest/publication', headers=headers, json=json_data)titles=[dic.get('title') for dic in response.json()['records']]links=['https://ieeexplore.ieee.org'+dic.get('publicationLink') for dic in response.json()['records']]pub_ids=[dic.get('id') for dic in response.json()['records']]Titles.extend(titles)Links.extend(links)Pub_Ids.extend(pub_ids)
for title,url,issuenum in zip(Titles,Links,Issue_Nums):IEEE_json[title]=(issuenum,url)
with open('IEEE.json','w') as f:f.write(json.dumps(IEEE_json))爬取到本地的IEEE.json内容:
{'期刊名称':['issueNum','Link']}
论文爬取
获取到了期刊的官网,那么接下来就是查找期刊内的论文下载链接了。
抓包分析
随便找一个期刊的url,网页内按下F12打开开发者工具,点击网络-Fetch/Xhr,心存侥幸地看看有没有json数据。
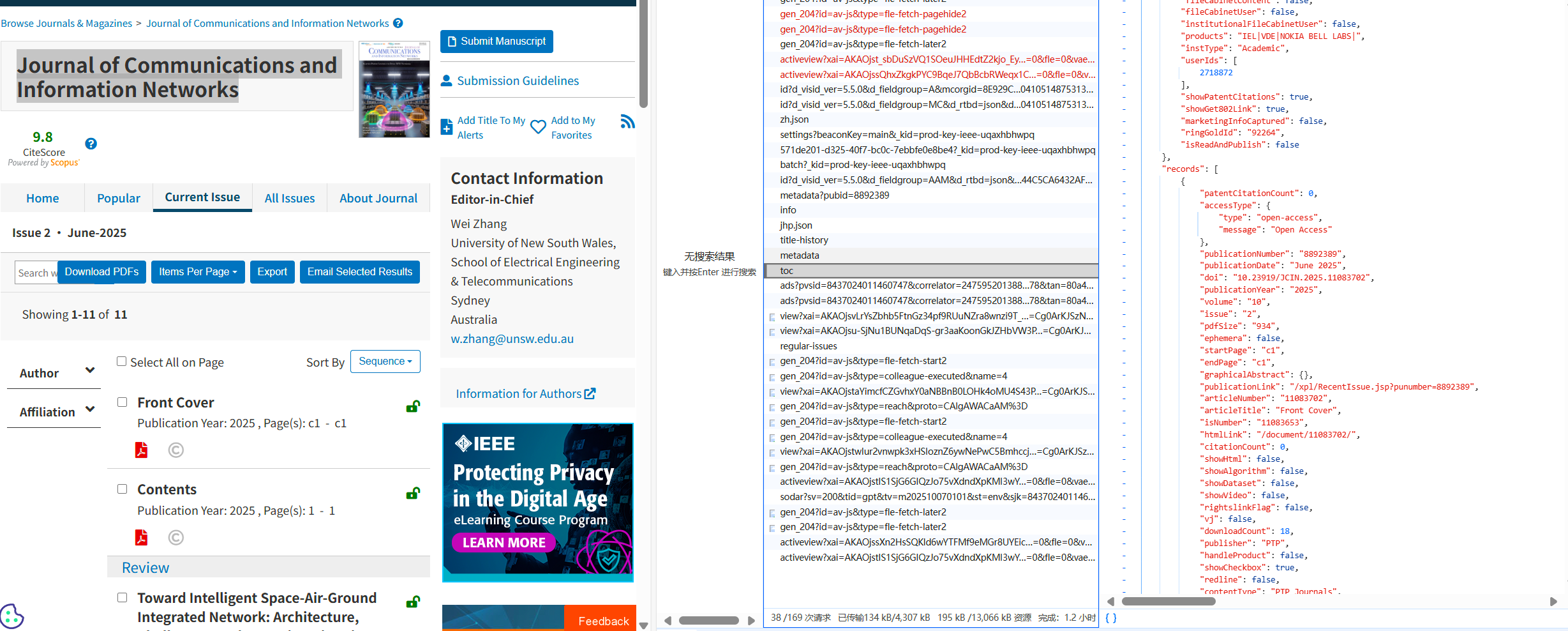
显然,这个json内便是我们需要的所有数据,解析json的代码如下:
import requestssession=requests.Session()
adapter=HTTPAdapter(pool_connections=10,pool_maxsize=35,max_retries=3,pool_block=False
)
session.max_redirects=3
session.mount('http://', adapter)
session.mount('https://', adapter)def fetch_data(pubid,issue_num):articleTitles=[]documentLinks=[]headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','content-type': 'application/json','origin': 'https://ieeexplore.ieee.org','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',}json_data={'punumber': pubid,'isnumber': issue_num,'sortType': 'vol-only-seq',}response=session.post(f'https://ieeexplore.ieee.org/rest/search/pub/{pubid}/issue/{issue_num}/toc',headers=headers,json=json_data,)for dic in response.json()['records']:if 'authors' in dic:articleTitles.append(dic.get('articleTitle'))documentLinks.append(f'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber={re.search(r'\d+',dic.get('documentLink')).group(0)}')return articleTitles,documentLinks其中pubid是刚刚爬取到的期刊编号,issue_number是另一个参数,接下来我们来分析其来源。
payload
发现名为toc的json便是我们需要的数据,查看一下负载,发现有一个参数名为isnumber
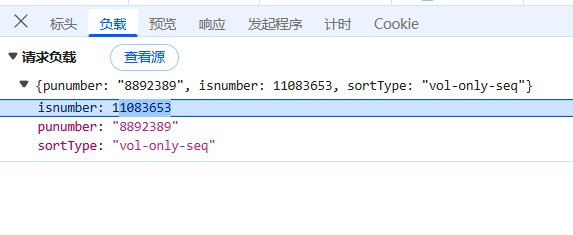
经过查找,发现名为metadata的json数据中含有该参数,所以我们需要先向这个metadata发送请求,获得issueNumber,然后再向toc发送请求
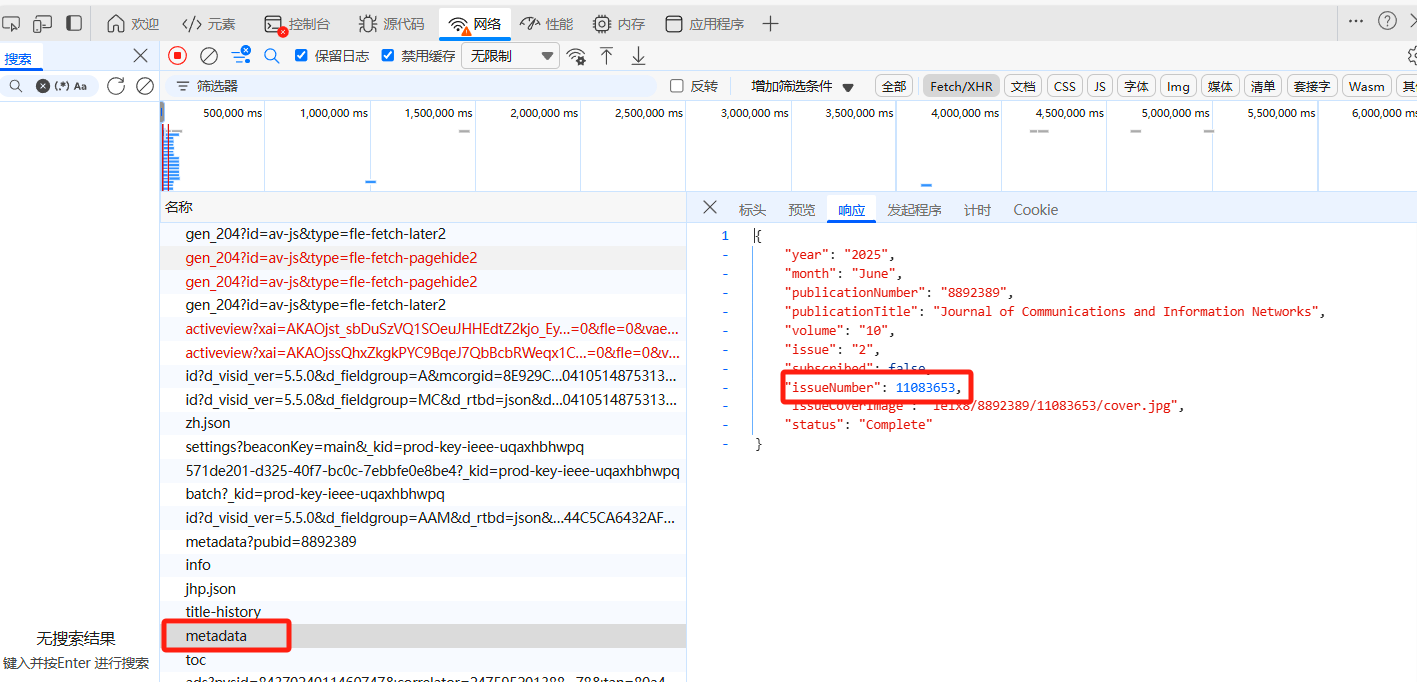
获取issueNumber完整代码
import requests
def get_issue_num(pubid):headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','cache-http-response': 'true','pragma': 'no-cache','priority': 'u=1, i','referer': f'https://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber={self.pubid}','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',}params={'pubid': pubid,}response=self.session.get('https://ieeexplore.ieee.org/rest/publication/home/metadata',headers=headers,params=params)issue_num=response.json()['currentIssue']['issueNumber']return issue_numpubid是刚刚爬取到的期刊编号,传入后即可得到issueNumber。
完整代码
#IEEE指定期刊指定年月论文查询,返回值为标题和下载链接
import os
import re
import json
import time
import requests
from requests.adapters import HTTPAdapter
from concurrent.futures import ThreadPoolExecutorclass IEEE_Journal_Downloads():def __init__(self,journal:str):self.journal=journalself.pubid,self.url=self.get_url()self.session=self.setup_session()self.issue_num=self._get_issue_num()self.total_num=self.get_total_num()def setup_session(self):"""创建session"""session=requests.Session()adapter=HTTPAdapter(pool_connections=10,pool_maxsize=35,max_retries=3,pool_block=False)session.max_redirects=3session.mount('http://', adapter)session.mount('https://', adapter)return sessiondef get_url(self):with open('IEEE_Journals.json','r') as f:data=json.loads(f.read())pubid,url=data.get(self.journal)return pubid,urldef get_total_num(self):headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','content-type': 'application/json','origin': 'https://ieeexplore.ieee.org','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp','sec-ch-ua': '"Microsoft Edge";v="141", "Not?A_Brand";v="8", "Chromium";v="141"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',}json_data={'punumber': self.pubid,'isnumber': self.issue_num,'sortType': 'vol-only-seq',}response =self.session.post(f'https://ieeexplore.ieee.org/rest/search/pub/{self.pubid}/issue/{self.issue_num}/toc',headers=headers,json=json_data,) total_num=response.json()['endRecord'] return total_numdef _get_issue_num(self):headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','cache-http-response': 'true','pragma': 'no-cache','priority': 'u=1, i','referer': f'https://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber={self.pubid}','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',}params={'pubid': self.pubid,}response=self.session.get('https://ieeexplore.ieee.org/rest/publication/home/metadata',headers=headers,params=params)issue_num=response.json()['currentIssue']['issueNumber']return issue_numdef fetch_data(self):articleTitles=[]documentLinks=[]headers={'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','content-type': 'application/json','origin': 'https://ieeexplore.ieee.org','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp','sec-ch-ua': '"Microsoft Edge";v="141", "Not?A_Brand";v="8", "Chromium";v="141"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','x-security-request': 'required',}json_data={'punumber': self.pubid,'isnumber': self.issue_num,'sortType': 'vol-only-seq',}response=self.session.post(f'https://ieeexplore.ieee.org/rest/search/pub/{self.pubid}/issue/{self.issue_num}/toc',headers=headers,json=json_data,)for dic in response.json()['records']:if 'authors' in dic:articleTitles.append(dic.get('articleTitle'))documentLinks.append(f'https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber={re.search(r'\d+',dic.get('documentLink')).group(0)}')return articleTitles,documentLinksdef download(folder:str,title:str,download_link:str):headers={'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','pragma': 'no-cache' ,'priority': 'u=0, i','referer': f'{download_link}','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0',}title=re.sub(r'[\\/*?:""<>|]',' ',title)dst=os.path.join(folder,f'{title}.pdf')if not os.path.exists(dst):#论文pdf路径不存在,没下载过才发请求arnumber=re.search(r'\d+',download_link).group(0)params={'tp': '','arnumber': f'{arnumber}','ref': '',}response=requests.get('https://ieeexplore.ieee.org/stampPDF/getPDF.jsp', params=params, headers=headers)time.sleep(2)with open(dst,'wb') as f:f.write(response.content)def auto_download(folder,titles,downloadLinks):os.makedirs(folder,exist_ok=True)folders=[folder]*len(titles)args_list=list(zip(folders,titles,downloadLinks))with ThreadPoolExecutor(max_workers=5) as executor:executor.map(lambda args:download(*args),args_list)titles,links=IEEE_Journal_Downloads('IEEE Transactions on Automation Science and Engineering').fetch_data()
print(titles)
print(links)
print(len(links))
auto_download(folder='test',titles=titles,downloadLinks=links)爬取效果:
总结

以上便是本文所有内容,如果对你有用,还请一键三连支持一下博主😀