Web 开发 26
1 MongoDB Atlas
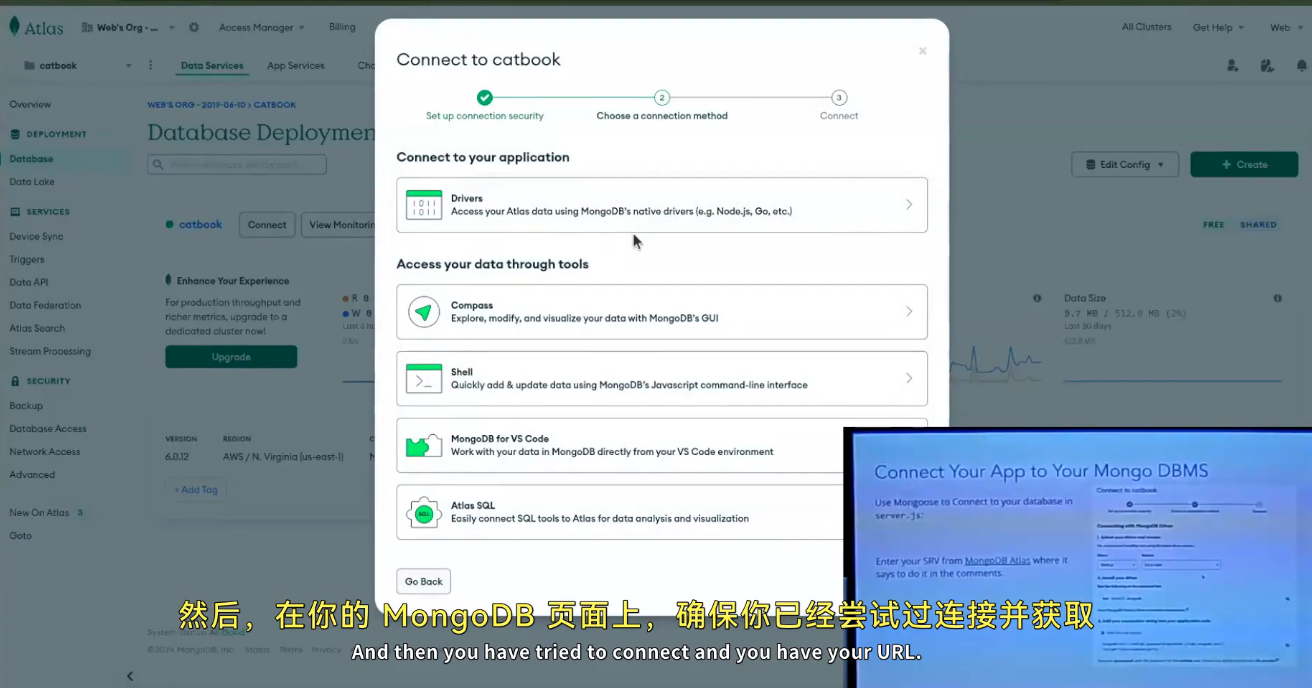
MongoDB Atlas 是 MongoDB 官方提供的云数据库服务,下面为你详细讲解如何申请和使用它来连接数据库:
一、注册 MongoDB Atlas 账号
- 打开浏览器,访问 MongoDB Atlas 的官方网站 https://www.mongodb.com/cloud/atlas。
- 点击页面上的 “Get Started Free”(免费开始)按钮。
- 按照提示填写注册信息,包括邮箱、密码等,完成账号注册。
二、创建 MongoDB Atlas 集群
- 注册完成后,登录到 MongoDB Atlas 控制台。
- 点击 “Build a Cluster”(创建集群)按钮。
- 选择集群的配置,对于学习和测试,你可以选择 “FREE TIER CLUSTER”(免费层级集群)。然后选择云服务提供商(如 AWS、Google Cloud、Azure)以及区域(选择离你较近的区域,这样连接速度会更快)。
- 为你的集群命名,然后点击 “Create Cluster”(创建集群)按钮。创建集群可能需要一些时间,等待集群状态变为 “Available”(可用)。
三、设置数据库用户和网络访问
- 创建数据库用户:
- 在集群页面,点击 “Database Access”(数据库访问)选项。
- 点击 “Add New Database User”(添加新数据库用户)按钮。
- 设置用户名和密码(请记住这个用户名和密码,后续连接数据库会用到),然后选择用户的权限(对于学习,选择 “Read and write to any database” 即可),最后点击 “Add User”(添加用户)。
- 配置网络访问:
- 点击 “Network Access”(网络访问)选项。
- 点击 “Add IP Address”(添加 IP 地址)按钮。
- 如果你是在本地开发,想要从本地连接 Atlas 集群,可以选择 “Allow access from anywhere”(允许从任何地方访问),然后点击 “Confirm”(确认)。
四、获取连接 URL
- 回到集群页面,点击集群名称旁边的 “Connect”(连接)按钮。
- 选择 “Connect your application”(连接你的应用程序)选项。
- 选择你使用的编程语言对应的驱动版本,然后会生成一个连接字符串(URL)。这个 URL 类似于
mongodb+srv://<username>:<password>@<cluster-address>/test?retryWrites=true&w=majority,其中<username>是你之前创建的数据库用户名,<password>是对应的密码,<cluster-address>是你的集群地址。
五、在应用中使用连接 URL
现在,你可以在你的应用程序(比如 Node.js 应用,使用 Mongoose 等 MongoDB 驱动)中使用这个连接 URL 来连接到 MongoDB Atlas 集群,从而操作数据库了。
通过以上步骤,你就可以完成 MongoDB Atlas 的申请和配置,进而连接到云数据库进行开发工作啦。
2 解决 MongoDB 连接的 IP 白名单问题
要解决 MongoDB 连接的 IP 白名单问题,需要找到网络访问(Network Access)的设置入口。从当前截图看,步骤如下:
-
回到 MongoDB Atlas 主界面的左侧导航栏:通常在左侧会有一个侧边栏,找到并点击 “Network Access”(网络访问)选项。
-
添加 IP 白名单:进入 “Network Access” 页面后,点击 “Add IP Address”(添加 IP 地址)按钮。
- 可以选择 “Allow Access From Anywhere”(允许所有 IP 访问,适合开发测试)。
- 或者输入你之前查到的公网 IP 地址,精确添加。
完成 IP 白名单配置后,重启应用npm start ,应该就能成功连接 MongoDB 了。
3 通过 require 机制来更新模块引入路径

这段内容是关于在 Node.js 环境下,通过 require 机制来更新模块引入路径,从而能使用导出的模型(这里以 Story 和 Comment 模型为例):
1. 背景:Node.js 的模块系统
在 Node.js 中,采用的是 CommonJS 模块规范,而 require 函数就是这个规范里用于引入模块的核心方法。通过 require,我们可以把其他文件中导出的函数、对象、类等模块成员引入到当前文件,供当前文件使用。
2. “Update require path”(更新 require 路径)的含义
要使用其他文件里的模块(比如这里的 Story 模型、Comment 模型),就得确保 require 时指定的文件路径是正确的。“更新 require 路径” 就是要确认路径能准确指向包含目标模块的文件,这样 Node.js 才能成功找到并加载模块。
3. 代码步骤解释
- 引入
Story模型:代码里有const Story = require("./models/story.js");这一行。它的作用是从./models/story.js文件中引入Story模型。这里的./表示当前文件所在的目录,models是子目录,story.js就是具体的文件,Node.js 会根据这个相对路径去找到story.js文件,然后加载其中导出的Story相关模块。 - 引入
Comment模型:按照示例,引入Comment模型的代码是const Comment = require('./models/comment');。这里的路径'./models/comment',是参照story.js的路径格式来写的。一般来说,Node.js 会自动识别.js后缀,所以写'./models/comment'和'./models/comment.js'效果是一样的(当然,具体还要看项目的配置,不过大多数常规 Node.js 项目是支持的)。通过这个require调用,就可以把comment.js文件中导出的Comment模型引入到当前文件,之后在当前文件里就能使用Comment模型相关的功能了,比如创建评论数据、查询评论等操作。
4. “This allows us to use the exported models!”(这让我们能使用导出的模型!)
当我们通过正确的 require 路径引入了 Story 和 Comment 模型后,这些模型在它们各自的源文件(story.js 和 comment.js)中肯定是通过 module.exports(或者 ES6 模块规范里的 export,不过在 CommonJS 里主要是 module.exports)导出的。
现在引入到当前文件后,当前文件就可以像使用本地定义的变量、对象一样,去使用这些模型提供的方法和属性了。比如,可能用 Story 模型来创建故事数据,用 Comment 模型来关联故事的评论数据等,实现业务逻辑中的数据操作。
扩展:模块导出与引入的配合
在 story.js 和 comment.js 文件中,需要有模块导出的代码,require 才能成功引入。例如,在 comment.js 中可能有这样的代码:
// comment.js
class Comment {constructor(content) {this.content = content;this.createdAt = new Date();}// 其他方法...
}
module.exports = Comment;
这样,当执行 const Comment = require('./models/comment'); 时,Comment 变量就会被赋值为 comment.js 中导出的 Comment 类,后续就可以用 new Comment("这是一条评论") 来创建评论实例了。
总结来说,这段内容核心是讲解如何在 Node.js 项目中,通过正确设置 require 的路径,来引入其他文件中定义的模型模块,以便在当前文件中使用这些模型实现相应的功能。
4 server.js 文件核心作用
1. 核心作用概述
server.js 是后端服务的 “核心启动文件”,类比于很多程序中的 main() 函数,它负责把后端服务运行所需的各个环节串联起来,确保服务能正常启动并处理请求。
2. 各部分作用详细解释与拓展
- Connect to the database(连接数据库)
- 解释:后端服务通常需要和数据库交互(比如存储用户数据、文章数据等),
server.js会在这里配置并建立与数据库的连接。常见的数据库有 MongoDB、MySQL 等,不同数据库有对应的 Node.js 驱动或 ORM(对象关系映射)库来实现连接。 - 拓展:以 MongoDB 为例,可能会使用
mongoose库,代码大致如下:
这里通过const mongoose = require('mongoose'); mongoose.connect('mongodb://localhost:27017/yourDatabaseName', {useNewUrlParser: true,useUnifiedTopology: true, }) .then(() => console.log('Connected to MongoDB')) .catch(err => console.error('Failed to connect to MongoDB', err));mongoose.connect方法连接到本地的 MongoDB 数据库,指定数据库名称为yourDatabaseName,然后通过 Promise 的then和catch分别处理连接成功和失败的情况。
- 解释:后端服务通常需要和数据库交互(比如存储用户数据、文章数据等),
- Sets up server middleware(设置服务器中间件)
- 解释:中间件是在请求到达路由处理函数之前或之后执行的函数,能实现很多通用功能。比如 “json parsing” 中间件可以自动把请求体中的 JSON 数据解析成 JavaScript 对象,方便后续处理。常见的中间件还有处理 CORS(跨域资源共享)、日志记录、身份验证等的中间件。
- 拓展:以 Express 框架(Node.js 常用的 Web 框架)为例,设置解析 JSON 中间件的代码是:
const express = require('express'); const app = express(); app.use(express.json());express.json()就是内置的解析 JSON 格式请求体的中间件,当客户端发送Content-Type为application/json的请求时,这个中间件会把请求体解析成对象,挂载到req.body上,后续的路由处理函数就可以直接通过req.body获取数据了。
- Hooks up all the backend routes specified in api.js(关联
api.js中指定的所有后端路由)- 解释:后端会有很多路由(即不同的接口地址,如
/api/users用于用户相关操作,/api/posts用于文章相关操作),这些路由的处理逻辑可能写在api.js里。server.js会把这些路由 “挂载” 到服务器上,使得客户端请求对应的地址时,能触发api.js中定义的处理函数。 - 拓展:在 Express 中,通常会把
api.js作为一个路由模块,然后在server.js中引入并使用,代码如下:
这里假设const apiRoutes = require('./api.js'); app.use('/api', apiRoutes);api.js中定义了一系列以/开头的路由(如/users、/posts),通过app.use('/api', apiRoutes),就把这些路由挂载到了/api路径下,客户端实际请求的地址就是/api/users、/api/posts等。
- 解释:后端会有很多路由(即不同的接口地址,如
- Forwards frontend routes that should be handled by the React router(转发应由 React 路由处理的前端路由)
- 解释:如果前端使用了单页应用框架(如 React),并且用 React Router 等前端路由库来处理页面路由(比如不同的页面路径
/home、/about等),后端需要把这些前端路由的请求转发给前端,让前端路由来渲染对应的页面组件。否则,后端可能会因为找不到对应的后端路由而返回错误。 - 拓展:在 Express 中,通常会在所有后端路由之后添加这样的配置:
假设前端代码构建后放在const path = require('path'); app.use(express.static(path.join(__dirname, 'client/build'))); app.get('*', (req, res) => {res.sendFile(path.join(__dirname, 'client/build/index.html')); });client/build目录下,express.static用于提供静态资源(如前端的 CSS、JS 文件等)。app.get('*', ...)表示对于所有未被后端路由匹配的 GET 请求,都返回前端的index.html文件,然后由 React Router 在前端根据 URL 来渲染对应的组件。
- 解释:如果前端使用了单页应用框架(如 React),并且用 React Router 等前端路由库来处理页面路由(比如不同的页面路径
- Sets up error handling in case something goes wrong when handling a request(设置错误处理,以防处理请求时出现问题)
- 解释:在处理请求的过程中,可能会出现各种错误(比如数据库操作失败、代码逻辑错误等),错误处理中间件可以统一捕获这些错误,然后返回合适的错误响应(如错误信息、状态码等),而不是让服务器崩溃或者返回不友好的错误。
- 拓展:在 Express 中,错误处理中间件的定义方式是带有四个参数的函数,通常放在所有路由和其他中间件之后:
当路由处理函数中调用app.use((err, req, res, next) => {console.error(err.stack);res.status(500).send('Something broke!'); });next(err)(把错误对象传递给下一个中间件)时,就会触发这个错误处理中间件。它会打印错误堆栈信息,并返回一个状态码为 500(表示服务器内部错误)、内容为 “Something broke!” 的响应。实际项目中,可能会根据不同的错误类型返回更详细的错误信息和对应的状态码。
- Actually starts the webserver(实际启动 Web 服务器)
- 解释:最后,
server.js会指定服务器监听的端口,然后启动服务器,使得服务器能接收客户端的请求。 - 拓展:在 Express 中,代码通常如下:
这里使用const port = process.env.PORT || 5000; app.listen(port, () => {console.log(`Server is running on port ${port}`); });process.env.PORT是为了支持在不同环境(比如生产环境可能由平台指定端口)下运行,如果没有设置环境变量PORT,则默认监听 5000 端口。app.listen启动服务器后,会在控制台打印服务器运行的端口信息,方便开发者查看。
- 解释:最后,
总结
server.js 就像后端服务的 “总指挥”,从数据库连接、中间件配置、路由关联,到前端路由转发、错误处理,再到最终启动服务器,把所有环节有序组织起来,确保后端服务能稳定、高效地处理客户端的各种请求。
5 如何在MongoDB中查看具体的数据库名称?
在不同的操作环境下,查看 MongoDB 具体数据库名称的方式有所不同,以下是几种常见的查看方式:
使用 MongoDB Shell
MongoDB Shell 是 MongoDB 自带的交互式 JavaScript shell,可用于管理和操作 MongoDB。
- 连接到 MongoDB 服务:打开终端(Linux/macOS)或命令提示符(Windows),运行
mongo命令(前提是已经配置好 MongoDB 的环境变量),这会连接到本地默认运行在27017端口的 MongoDB 服务。如果 MongoDB 运行在其他端口或者远程服务器,需要指定相应的主机地址和端口,例如mongo mongodb://localhost:27018。 - 查看所有数据库:成功连接后,在 MongoDB Shell 中输入
show dbs或show databases命令,按下回车键,就会列出当前 MongoDB 实例中存在的所有数据库名称 。例如:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
这里列出的admin、config、local是 MongoDB 默认创建的数据库,如果你自己创建了数据库,也会在这里显示出来。
用 MongoDB Shell(Windows 版)
- 打开命令提示符(CMD):按下
Win + R,输入cmd后回车,打开命令提示符窗口。 - 连接 MongoDB:如果 MongoDB 安装时配置了环境变量,直接在命令提示符里输入
mongo回车,就能连接本地默认在27017端口运行的 MongoDB 服务。要是没配置环境变量,得进入 MongoDB 的安装目录(比如C:\Program Files\MongoDB\Server\6.0\bin),再执行mongo.exe命令。 - 查看数据库:连接成功后,输入
show dbs或者show databases并回车,就能列出所有数据库名称,像admin、config、local这些默认数据库,以及你自己创建的数据库都会显示出来。
用 MongoDB Compass(Windows 版)
- 启动 MongoDB Compass:在 Windows 开始菜单里找到 MongoDB Compass 并点击启动。
- 连接 MongoDB 实例:启动后,在连接界面输入 MongoDB 的连接字符串。要是连接本地默认的 MongoDB,通常默认配置就行;如果是远程数据库或者非默认端口,要正确填写主机地址、端口、认证信息等,然后点击 “Connect” 连接。
- 查看数据库:连接成功后,左侧导航栏会显示所有数据库名称,展开数据库还能查看里面的集合等信息。
使用 MongoDB Compass
MongoDB Compass 是 MongoDB 官方提供的可视化工具,操作直观方便。
- 连接到 MongoDB 实例:打开 MongoDB Compass,在连接界面输入 MongoDB 的连接字符串。如果是连接本地默认运行的 MongoDB,一般默认配置就可以;如果是远程数据库或者非默认端口,需要正确填写主机地址、端口、认证信息等。点击 “Connect” 连接到 MongoDB 实例。
- 查看数据库:连接成功后,在左侧导航栏中,会显示所有的数据库名称。你可以展开每个数据库,进一步查看其中包含的集合等信息。
在 Node.js 应用中查看
如果你使用 Node.js 开发应用并连接了 MongoDB,借助mongodb驱动可以获取数据库列表。以下是示例代码:
const { MongoClient } = require('mongodb');async function listDatabases() {const uri = "mongodb://localhost:27017"; // 替换为你的MongoDB连接字符串const client = new MongoClient(uri);try {await client.connect();const databasesList = await client.db().admin().listDatabases();console.log("Databases:");databasesList.databases.forEach(db => console.log(db.name));} catch (e) {console.error(e);} finally {await client.close();}
}listDatabases();
上述代码先建立与 MongoDB 的连接,然后通过admin().listDatabases()方法获取数据库列表,最后打印出每个数据库的名称。记得将连接字符串mongodb://localhost:27017替换为实际的连接信息 。
如果是 Windows 系统,查看 MongoDB 具体数据库名称,同样可以用 MongoDB Shell 或者 MongoDB Compass,操作上和其他系统类似,下面再针对 Windows 系统细节补充说明:
========================
可以通过 MongoDB Atlas 面板查看数据库名称,步骤如下:
1. 登录 MongoDB Atlas 账户
打开浏览器,访问 MongoDB Atlas 官网(https://www.mongodb.com/cloud/atlas ),输入你的账户信息进行登录 。
2. 进入集群管理界面
登录成功后,在控制台中找到你要操作的集群(如你之前看到的Cluster0),点击进入该集群的管理界面。
3. 浏览数据库
- 方法一:点击 “Browse Collections” 按钮,在弹出的界面中,左侧会列出当前集群中存在的所有数据库 。你可以直接看到数据库的名称,并且可以展开数据库查看其包含的集合等详细信息。
- 方法二:在集群管理界面,还可以使用 MongoDB Shell in Atlas 功能。点击集群名称下方的 “...” 按钮,选择 “Connect”,然后在连接方式中选择 “Connect with MongoDB Shell” 。按照提示下载并配置好 MongoDB Shell 后,在 Shell 中输入
show dbs或show databases命令,即可列出当前集群中的数据库名称。 这种方式和在本地使用 MongoDB Shell 查看数据库名称的原理是一样的,只不过是通过 Atlas 提供的在线 Shell 环境来操作。
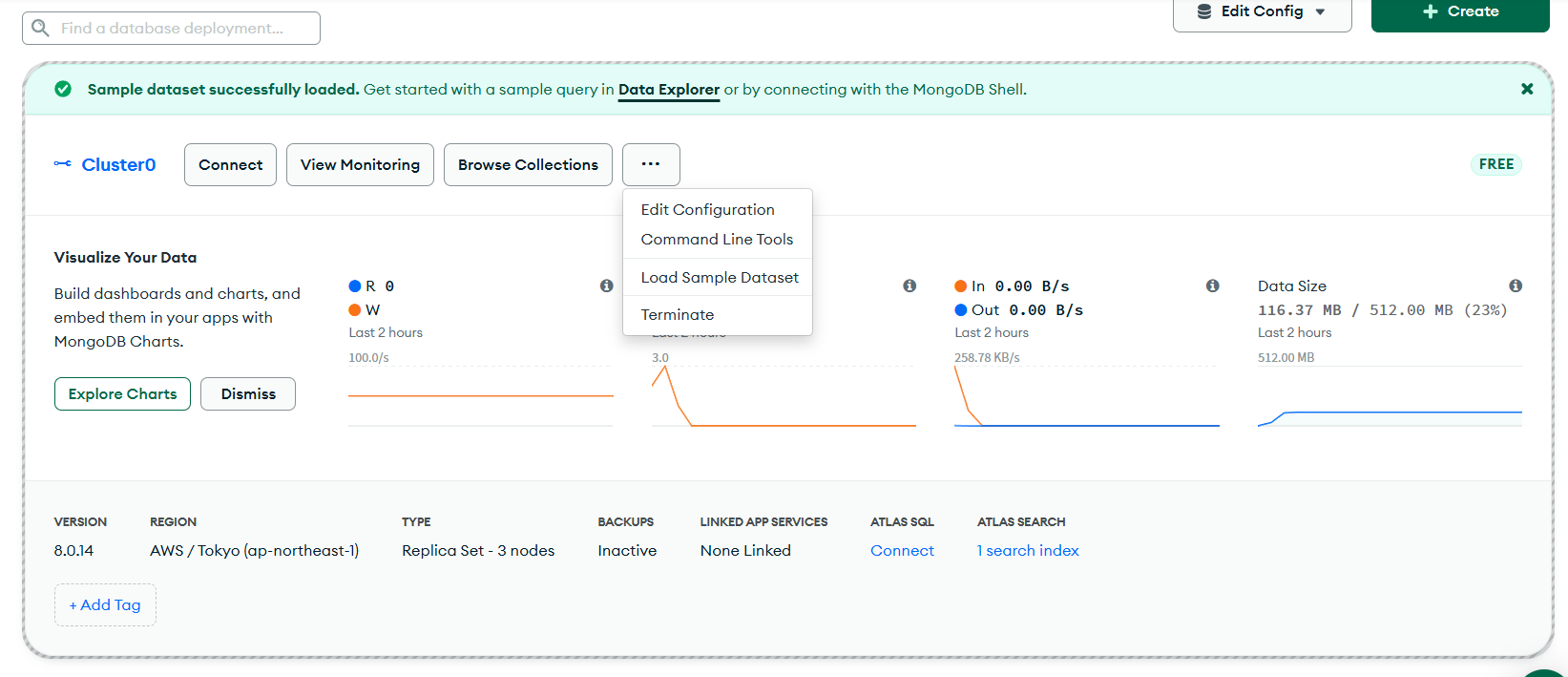
6 阅读我的MongoDB Atlas 中一个集群(Cluster)的基本信息

这张图片展示的是 MongoDB Atlas 中一个集群(Cluster)的基本信息,各列含义如下:
- Name:集群名称,这里是
Cluster0,且为免费(FREE)类型。 - Version:MongoDB 数据库的版本,这里是
8.0.14。 - Data Size:数据大小,显示为
N/A,可能表示当前没有统计或无数据。 - Nodes:节点数量,这里有
3个节点,MongoDB 副本集(Replica Set)通常会有多个节点以保证高可用性和数据冗余。 - Backup:备份状态,显示为
OFF,表示当前备份功能处于关闭状态。 - SSL:安全套接层(Secure Sockets Layer)状态,显示为
ON,说明启用了 SSL 加密,用于保障数据传输的安全性。 - Auth:认证状态,显示为
ON,表示启用了身份认证,客户端连接时需要进行身份验证。 - Alerts:警报相关,这里没有具体数值等显示,一般用于展示集群的警报情况,比如是否有异常警报等。
整体来看,这是一个 MongoDB Atlas 上的免费集群,使用的是 MongoDB 8.0.14 版本,有 3 个节点,启用了 SSL 加密和身份认证,但备份功能关闭。
7 关于在后端服务中实现 POST /story 接口

1. 核心目标:Implement POST /story
POST 是 HTTP 请求方法之一,用于向服务器提交数据,这里的目标是实现一个接口,客户端通过向 /story 路径发送 POST 请求,就能在服务器端创建一条新的故事(story)数据。
2. 数据来源:基于请求中的 content 参数创建故事
服务器会根据请求中携带的 content 参数来创建新故事。
在 Web 应用的前后端交互中,客户端(比如前端页面)会把故事的内容以数据的形式发送给服务器,服务器接收并处理这些数据,进而完成故事的创建。
3. content 的获取方式:req.body.content
在后端(通常是基于 Node.js + Express 等框架的服务端),当客户端发送 POST 请求时,请求体(request body)中会包含需要提交的数据。
req.body 是框架提供的对象,用于获取请求体中的数据,这里的 req.body.content 就是从请求体中提取 content 字段的值,这个值就是新故事的内容。
4. 前端发送请求的代码示例(NewPostInput.js 相关)
图片中展示了前端发送 POST 请求的代码片段:
const addStory = (value) => {const body = { content: value };post("/api/story", body).then((story) => {// 在屏幕上显示这个故事props.addNewStory(story);});
};
- 参数传递:
addStory函数接收一个value参数,这个value通常是用户在前端输入的故事内容。 - 构造请求体:
const body = { content: value };这行代码构造了请求体,把用户输入的内容value赋值给content字段,这样请求体就包含了{ "content": "用户输入的故事内容" }这样的结构。 - 发送
POST请求:post("/api/story", body)发送POST请求到/api/story路径,请求体为body。这里的post应该是封装好的用于发送POST请求的方法(比如基于fetch或axios封装)。 - 处理响应:
.then((story) => { ... })是处理请求成功后的回调,服务器在创建新故事后,会返回该故事的相关数据(比如包含故事 ID、创建时间等信息),前端可以用这些数据来更新页面,比如调用props.addNewStory(story)把新创建的故事显示在页面上。
5. 请求载荷示例(Request Payload)
图片右侧展示了请求载荷(Request Payload)的示例:
{"parent": 0,"content": "I don't :("
}
这表示客户端实际发送的请求体数据包含 parent 和 content 两个字段。parent 可能用于表示故事的父级关系(比如评论所属的故事主帖等场景),content 就是故事的内容。后端在处理时,会根据实际需求提取这些字段的值来进行业务逻辑处理,比如示例中主要关注 content 来创建故事,parent 可能在其他逻辑(如评论关联)中使用。
扩展:后端实现 POST /story 接口的大致流程(以 Express 为例)
假设后端使用 Express 框架,实现这个接口的代码大致如下:
const express = require('express');
const router = express.Router();
// 假设 Story 是操作故事数据的模型(比如基于 MongoDB 等数据库)
const Story = require('./models/Story');// 解析请求体中的 JSON 数据,需要配置中间件
router.use(express.json());// 实现 POST /api/story 接口
router.post('/api/story', (req, res) => {// 从请求体中获取 contentconst { content } = req.body;// 创建新故事,这里假设 Story 模型有 create 方法Story.create({ content }).then((newStory) => {// 成功创建后,返回新故事的数据res.status(201).json(newStory);}).catch((err) => {// 处理错误,返回错误响应res.status(500).json({ error: 'Failed to create story' });});
});module.exports = router;
- 中间件配置:
router.use(express.json())是 Express 的中间件,用于解析请求体中的 JSON 数据,这样才能通过req.body获取到数据。 - 创建故事逻辑:在接口的处理函数中,从
req.body提取content,然后使用Story模型的create方法(假设是基于 Mongoose 等 ORM 库操作 MongoDB)创建新故事。 - 响应处理:如果创建成功,返回状态码
201(表示资源创建成功)和新故事的 JSON 数据;如果创建过程中出现错误,返回状态码500(表示服务器内部错误)和错误信息。
总结来说,这段内容完整展示了从前端发送 POST 请求提交故事内容,到后端接收并处理请求、创建新故事的整个流程,涵盖了前后端数据交互的关键环节。
8 req.query 和 req.body

这段内容主要讲解了在 Node.js(通常结合 Express 等框架)中,req.query 和 req.body 这两个对象的使用场景,以及如何基于此实现 /story 接口,下面详细解释并适当扩展:
1. req.query 与 req.body 的区别
req.query:- 使用场景:用于 GET 请求。当客户端发送 GET 请求时,请求参数会以查询字符串的形式附加在 URL 后面,格式为
?key1=value1&key2=value2。在服务端,通过req.query可以获取这些查询参数。 - 示例:如果请求 URL 是
http://example.com/story?content=hello,那么在服务端可以通过req.query.content来获取content的值(即hello)。 - 扩展:GET 请求的参数是直接暴露在 URL 中的,所以适合传递一些非敏感、长度有限的参数。因为 URL 有长度限制(不同浏览器和服务器限制不同,一般几百到几千个字符),所以不适合传递大量数据或敏感数据(如密码)。
- 使用场景:用于 GET 请求。当客户端发送 GET 请求时,请求参数会以查询字符串的形式附加在 URL 后面,格式为
req.body:- 使用场景:用于 POST、PUT、DELETE 等请求(这些请求通常会携带请求体)。客户端会将数据放在请求体中发送给服务端,服务端通过
req.body来获取这些数据。 - 示例:当客户端发送 POST 请求创建故事时,会把故事内容等数据放在请求体中,服务端通过
req.body.content来获取内容。 - 扩展:要使用
req.body,需要在 Express 中配置中间件来解析请求体,比如express.json()(解析 JSON 格式的请求体)或express.urlencoded()(解析表单格式的请求体)。请求体可以传递大量数据,也适合传递敏感数据,因为数据不会暴露在 URL 中。
- 使用场景:用于 POST、PUT、DELETE 等请求(这些请求通常会携带请求体)。客户端会将数据放在请求体中发送给服务端,服务端通过
2. 如何实现 /story 接口
假设我们要实现一个接口,用于创建故事,结合内容中的提示,步骤如下:
(1)确定请求方法
因为是创建新的故事数据,通常会使用 POST 请求(POST 用于向服务器提交新资源),所以会通过 req.body 来获取请求体中的数据。
(2)处理创作者名称
内容中提到 “使用常量 myName 作为 creator_name,因为目前还无法获取创作者名称”。所以在创建故事数据时,创作者名称固定为 myName 的值。
(3)代码示例(基于 Express)
首先,确保配置了解析请求体的中间件:
const express = require('express');
const app = express();
// 解析 JSON 格式的请求体
app.use(express.json());
// 解析表单格式的请求体(如果有需要)
app.use(express.urlencoded({ extended: true }));
然后,实现 /story 的 POST 接口:
// 假设 myName 是预先定义的常量
const myName = "default_creator";app.post('/story', (req, res) => {// 从请求体中获取故事内容const { content } = req.body;// 构建故事数据,创作者名称使用 myNameconst newStory = {content: content,creator_name: myName,createdAt: new Date() // 可以添加创建时间等其他字段};// 这里通常会将 newStory 保存到数据库(如 MongoDB、MySQL 等)// 假设保存成功后,返回新创建的故事数据res.status(201).json(newStory);
});
(4)扩展:接口的完整流程
- 客户端请求:客户端(如前端页面、Postman 等工具)发送 POST 请求到
http://your-server.com/story,请求体为{"content": "这是一个故事"}。 - 服务端接收:服务端通过
express.json()中间件解析请求体,req.body.content获取到这是一个故事。 - 数据处理:结合
myName生成新的故事对象,然后将其保存到数据库。 - 响应客户端:保存成功后,返回状态码
201(表示资源创建成功)和新创建的故事数据,客户端可以根据响应进行后续操作(如在页面上显示新故事)。
3. 关于 “还无法获取创作者名称” 的说明
在实际应用中,创作者名称通常是通过用户认证(如登录后获取用户信息)来获取的。但在这个示例中,可能因为还没有实现用户认证功能,所以暂时使用固定的常量 myName 来模拟创作者名称,这是一种在开发初期或演示场景中常用的做法。后续如果实现了用户认证,就可以从认证信息中获取真实的创作者名称,替换掉 myName。
总结来说,这段内容清晰地划分了 req.query 和 req.body 的使用场景,并引导如何基于 req.body 实现一个创建故事的 POST 接口,同时考虑了实际开发中可能存在的限制(暂时无法获取创作者名称)并给出了临时解决方案。