大模型激活值相关公式说明(114)
激活值相关公式说明
若您好奇内存分配公式的来源,可参考以下补充内容:这些公式源自 Korthikanti 等人发表的论文《Reducing Activation Recomputation in Large Transformer Models》(《减少大型 Transformer 模型中的激活值重计算》)。
对于一个典型的 Transformer 模型(包含隐藏层维度 h、L 个 “层”(即 Transformer 块)、n_heads 个注意力头),模型自身的总参数量,以及针对一个 “包含 b 条长度为 s 的序列” 的迷你批次(mini-batch)所计算出的激活值总数,可由以下公式表示:
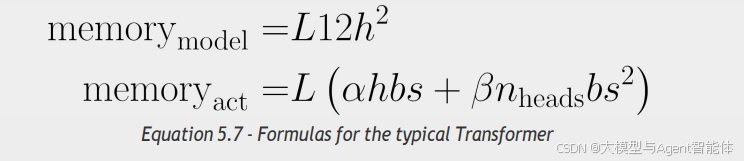
看到公式末尾的“序列长度平方”项了吗?这正是“即时注意力机制(eager attention)”成本高昂的关键原因。
“等等,你还没提alpha(α)和beta(β)这两个参数呢……”
观察得很细致!对于采用即时注意力机制的“标准Transformer模型(plain-vanilla Transformer)”而言,α值为34,β值为5。但关键亮点在于:若我们采用Flash Attention(或SDPA,即“缩放点积注意力”),β值会直接降至0!届时,公式中就不再存在“序列长度平方”这一项了!