全栈开发杂谈————JAVA微服务全套技术栈详解
🍏🍏🍏一.一个悖论引发一个探索
㊙️㊙️㊙️微服务是不是就是Spring Cloud?
如果你简单的把微服务理解为Spring Cloud那我只能说你格局小了,微服务是分布式架构的一种,而分布式架构是要把服务做拆分,而拆分的过程中有各种各样的问题需要去解决,而Spring Cloud仅仅解决了服务拆分时的服务治理问题,至于分布式架构中一些更复杂的问题,Spring Cloud并没有给出解决答案,所以微服务技术绝不仅仅包含Spring Cloud。
🍋🟩🍋🟩🍋🟩二.架构的车轮总是滚滚向前
关于架构模式的演变过程
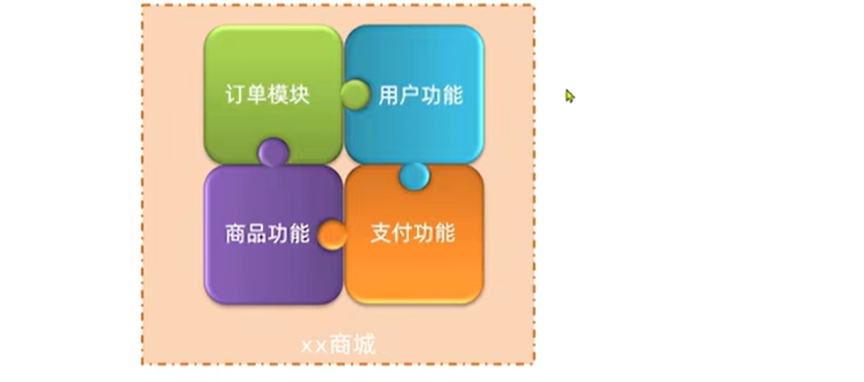
以电商商城为例
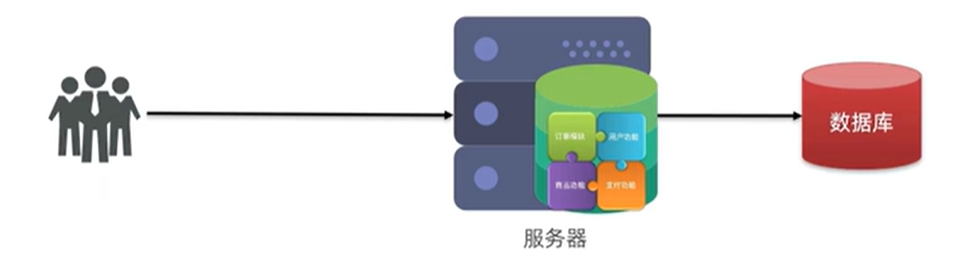
㊙️㊙️㊙️(1)单体架构
概念:将业务的所有功能集中在一个项目中开发,打成一个包部署
优点:
(1)架构简单
只需要创建一个项目,需要增加功能就往里面增加代码,不断堆积代码就可以,没有复杂的架构设计理念
(2)部署成本低
只需要打包成一个包,整一台tomcat,把项目部署上去用户就可以访问,用户多了,增加机器数量,形成负载均衡的集群
缺点:
耦合度高:
所有代码写在一个项目里,对于大型互联网项目,业务量可以达到几百上千个模块,代码量也会达到数十万行,代码的编译打包可能都得十几分钟,效率低下,而且开发过程中,代码的边界也越来越模糊,修改一个模块的代码可能导致其他几个模块的代码都收到影响,这样我们修改代码就必须更加谨慎,一招不慎就可能满盘皆输
应用领域:
面向企业内部的应用开发
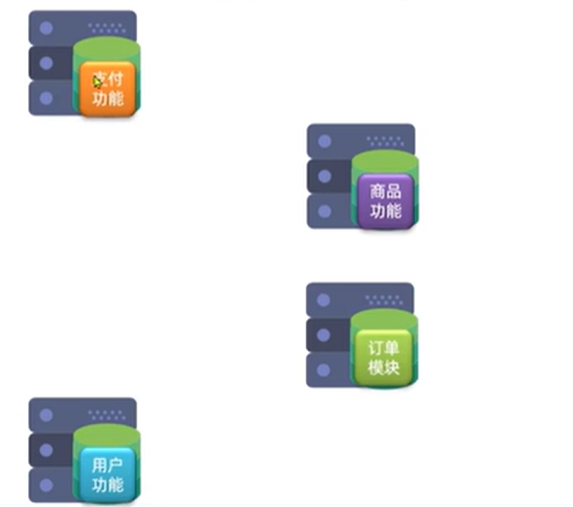
㊙️㊙️㊙️(2)分布式架构
概念:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务
优点:
(1)降低服务间的耦合度
各写各的功能,代码量会显著减少,编译效率提高,相互之间不会影响,单独对一个模块的功能进行升级和维护时不会影响到其他模块的功能,单体架构和分布式结构的区别相当于串联电路和并联电路的区别,同时用户也可以根据需要访问相应的模块
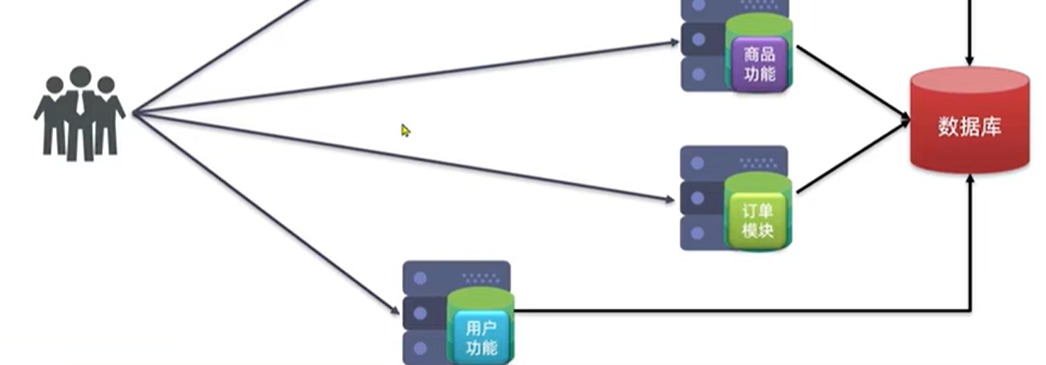
(2)有利于对服务进行升级和拓展
缺点:
(1)由于对服务做了拆分,拆分越多,将来部署难度也会越高
(2)还有一个问题是在单体架构中,所有服务都在一个项目里,可以相互调用,分散部署后服务间的调用就需要发送请求远程调用,这种跨机器调用更为复杂
🍏🍏🍏三.关于分布式架构的灵魂四连问
🍕🍕🍕第一问:服务拆分粒度如何?
即如何避免拆分过大或过小,哪些业务必须在一起
🍕🍕🍕第二问:服务集群地址如何维护?
即同一模块可能有多个不同的机器,那我们怎么知道具体调用那几台机器,如果直接把代码写死但是部署上线的时候发生变化,那显然就不合理了,所以机器的地址应该方便我们维护
🍕🍕🍕第三问:服务之间如何实现远程调用?
这就是我们刚刚提到的关键问题,跨服务的调用是一个技术难点
、
🍕🍕🍕第四问:服务健康状态如何感知?
同时调用多个服务时需要知道服务是否处于正常工作状态,万一其中一个服务挂掉了或者阻塞了,那么其他服务也会受影响,导致级联失败
🏍️🏍️🏍️四.解决灵魂四联问的杏林圣手————微服务架构方案
微服务架构
概念:一种经过良好架构的分布式架构方案
优点:
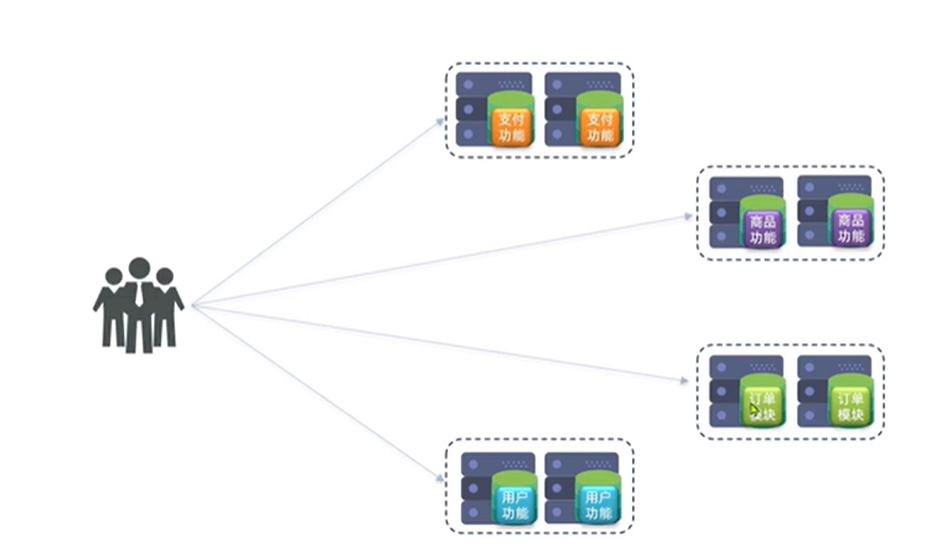
(1)单一职责:
拆分粒度更小,每一个去单位都对应唯一的业务能力,做到单一职责,避免重复业务开发
比如不同的会员等级的用户享有不同的折扣优惠,同时还能用积分兑换礼品,这就需要把用户功能拆分出更详细的会员服务和积分服务

(2)面向服务:
对外暴露业务接口,以上面的积分服务为例,由于单独拆分出来,所以用户服务要调取积分服务时就要有请求的问题,此时积分服务会设置一个对外暴露的接口以供其他服务调用,会员服务也是一样的道理,并且所有接口采用统一标准
(3)自治:
团队独立:
传统的团队划分按照前端,后端,测试等职责划分,微服务团队具体到每一个团队分配对应的前端后端等人员只负责微服务的开发,通常一个团队5-8人,团队越小,沟通协作越方便,符合敏捷开发的思想
技术独立:
由于是团队内部开发,可以针对业务选择适合的技术开发,不同的业务选用不同的技术,互不影响
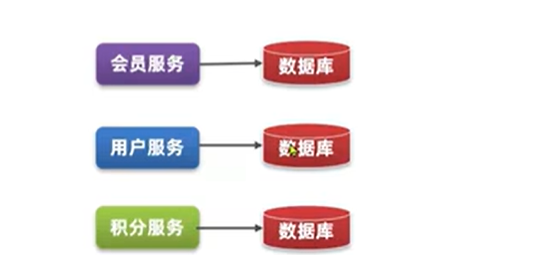
数据独立:
以前的数据全部集中在一起,都访问一个数据库,不同服务之间可能会篡改数据,微服务中每个服务有自己独立的数据库和独立的数据,实现了数据的解耦,避免了不同服务互相修改数据导致的数据污染
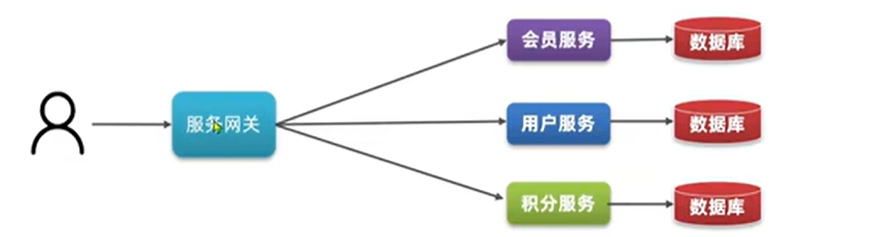
部署独立:
用户可以通过网关,根据需要访问任意一个服务,网关是统一的入口
(4)隔离性强:
服务调用做好隔离,容错,降级,避免出现级联问题,当一个服务挂掉时能及时把这些故障隔离起来不至于全部宕机
㊙️㊙️㊙️五.重磅来袭————微服务技术栈全解
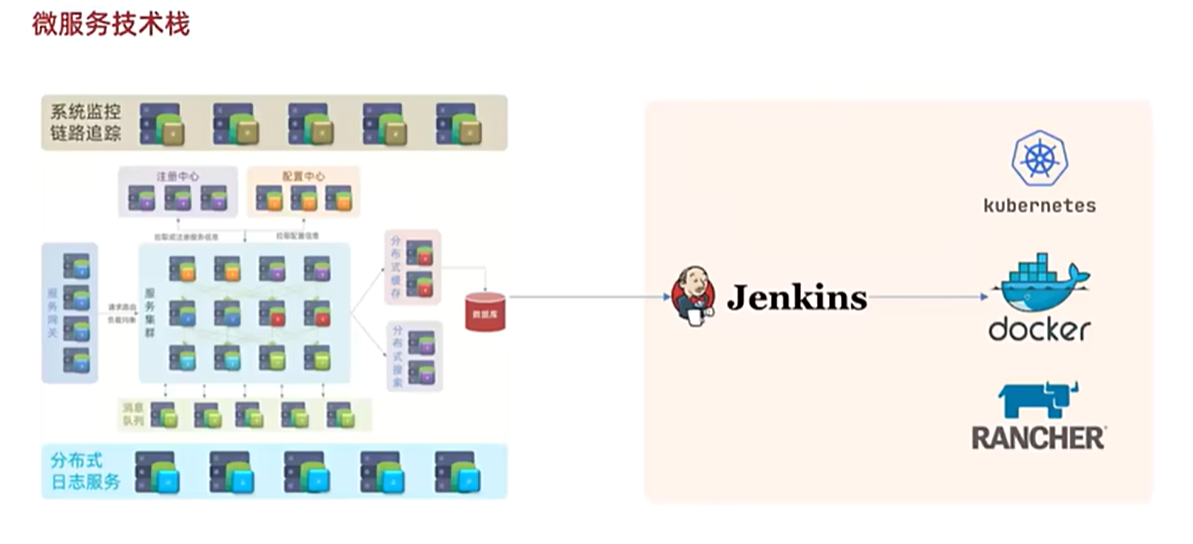
以下两张图就是微服务的所有技术栈,下面我们来介绍每个模块的详细作用
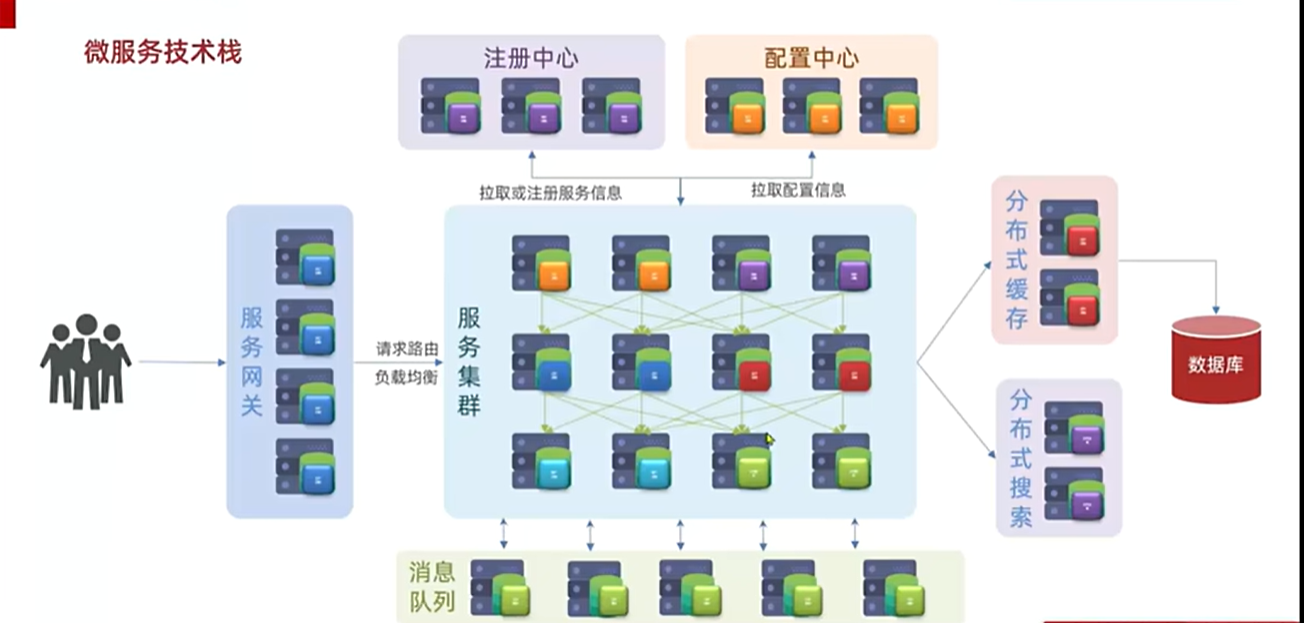
🍕🍕🍕(1)微服务架构的核心加工厂————服务集群
微服务做拆分时会根据业务功能模块把一个单体项目拆分成许多个独立的项目,每个项目完成一部分业务功能,将来独立开发和部署,我们把这独立的一个项目称为一个服务,一个大型的互联网项目会包含成百或者上千的服务,最终形成一个服务集群
🍕🍕🍕(2)微服务中的吏部———注册中心
🍬🍬🍬技术栈:Eureka,Nacos
当一个请求到来时,可能先去调用服务A,然后调用服务B和C,当业务越来越复杂时,服务之间的调用关系就会越来越复杂,这种复杂的关系靠人来记录和维护显然不可能,所以注册中心应运而生,它可以记录每一个服务的IP端口以及可以实现什么功能,当一个服务需要去调用另外一个服务时也不需要记录IP地址,只需要找注册中心拉取对应的服务信息
🍕🍕🍕(3)微服务中的户部————配置中心
🍬🍬🍬技术栈:Spring Cloud Config,Consul,Nacos,Eureka
随着服务越来越多,每一个服务都有自己的配置文件,如果要修改配置,逐一修改就会特别麻烦,所以微服务中有一个统一的配置中心,可以统一管理服务集群中成百上千的配置,如果有配置需要变更找配置中心就可以,它可以通知对应的微服务实现更新
🍕🍕🍕(4)微服务的刑部————服务网关
🍬🍬🍬技术栈:Spring Cloud Gateway
一方面对用户进行身份校验,另一方面可以把用户请求路由到对应的具体服务,路由过程中也可以做一些负载均衡
🍕🍕🍕(5)微服务的工部———数据库
🍬🍬🍬技术栈:Mysql,MongoDB
服务集群接收到请求后去处理业务,需要查询数据的时候就会去访问数据库,服务集群调取数据库,最终再把数据返回给用户
🍕🍕🍕(6)微服务的兵部————分布式缓存
技术栈:redis
随着用户量的增大,单一数据库肯定存储不了那么多的数据,所以就会出现数据库集群,但是集群再多也不可能多过用户的数量,所以我们要扛住这种高并发就需要引入缓存,缓存就是把数据库中的数据放到内存当中,相比于查询数据库访问硬盘上的数据,访问内存的查询效率当然要高很多,而且单体缓存还不足以应对高并发,也需要集群,由多个缓存构成分布式缓存,当需要查询数据时先访问内存,未命中再去访问数据库,这样就可以减轻数据库的压力,这样看来,缓存倒更像是数据库的先锋部队
🍕🍕🍕(7)微服务的分流器———分布式搜索
🍬🍬🍬技术栈:ES
简单的查询可以通过缓存来实现,那对于海量的更复杂数据的统计和分析仅仅通过缓存是无法完成的,这就需要引入分布式搜索解决复杂的搜索问题,引入分布式搜索后数据库所做的仅仅就是写操作还有对于一些数据安全要求较高的数据的存储操作,也大大减轻了数据库的压力
🍕🍕🍕(8)微服务的通讯员———消息队列
🍬🍬🍬技术栈:rabbitmq
消息队列是一种异步通信的组件,前面说过微服务的业务往往会跨越多个服务,假设一个请求先调用服务A,再调用B,再调用C,整个业务的链路就会很长,调用时长等于各个服务的执行时长总和,性能有一定的下降,异步通信就是请求来到时,先调用A,而服务A直接发消息通知服务B和C然后A结束,整个业务链路变短,响应时间变短,吞吐量也会相应增强,所以异步通信可以提高系统的并发量,在一些秒杀等高并发的场景下可以使用
🍕🍕🍕(9)微服务的哨位双雄————分布式日志服务和链路追踪
🍬🍬🍬技术栈:MDC,Spring Cloud sleuth
分布式日志服务可以统计整个集群当中成百上千的服务的运行日志,统一做一个存储统计分析,将来出现问题就比较好定位,链路追踪可以实时监控整个集群中每一个服务节点的运行状态,CPU负载,内存占用等情况,一旦出现问题,可以快速定位异常
🍕🍕🍕(10)微服务的护卫队————熔断工具
🍬🍬🍬技术栈:Hystrix,Sentinel
用于保护系统免受级联故障或高并发冲击,通过自动切断服务请求来保障核心业务稳定性
🍕🍕🍕(11)微服务的智能体————自动化部署工具
🍬🍬🍬技术栈:Jenkins,K8s,rancher,docker
业务集群将来可能达到成百上千个服务,如果还靠人为部署肯定不现实,所以就需要实现自动化部署,我们会使用Jenkins做一些自动化编译,然后通过docker去做一些打包,形成镜像,再基于K8S和rancher去做自动化部署,这一套完整的流程叫做持续集成
以上就是微服务全部的技术栈,如果更加细化可以得到如下的一张图:
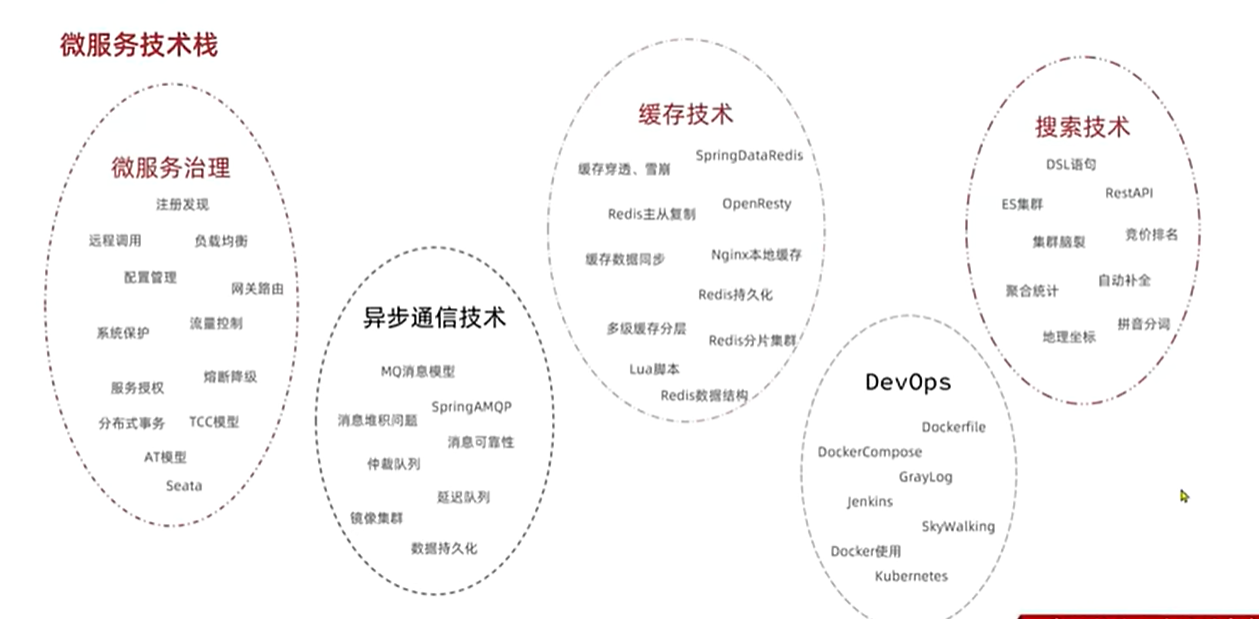
现在你还认为微服务就是SpringCloud吗?
