丹东网站推广自己公司怎样弄个网站
✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、系统视频
- 结语
一、前言
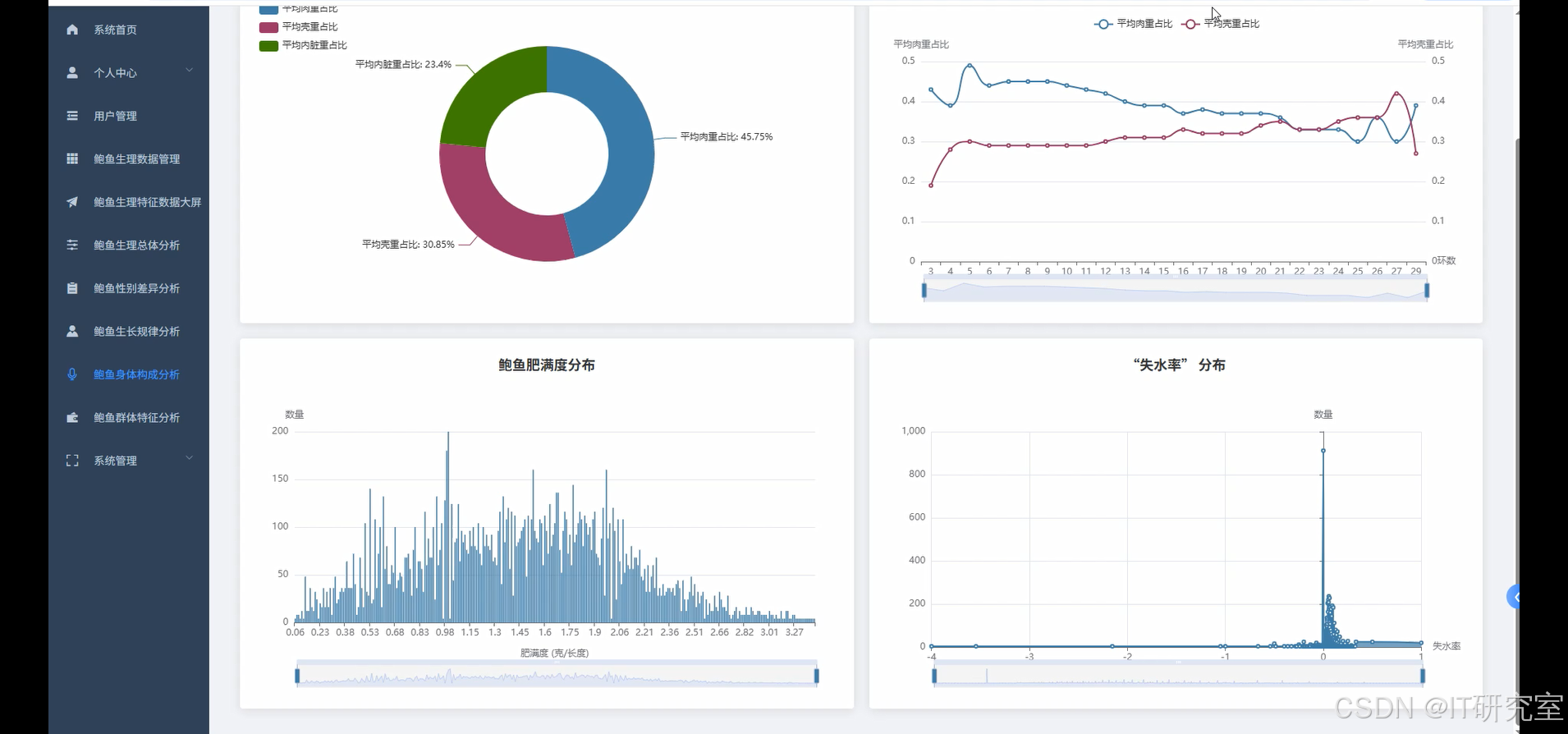
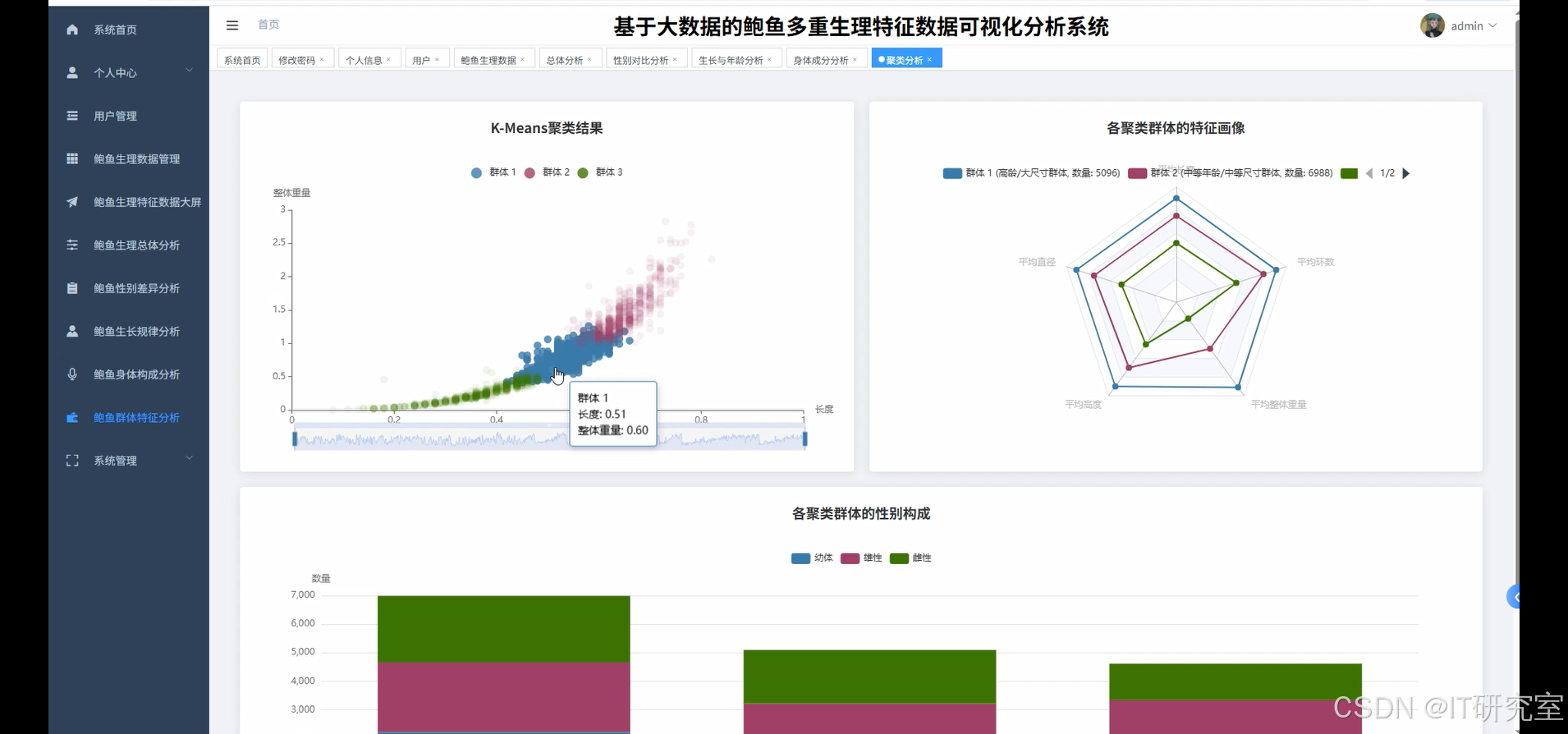
本系统以“基于大数据的鲍鱼多重生理特征数据可视化分析系统”为主题,围绕鲍鱼个体的长度、直径、高度、整体重量、去壳重量、内脏重量、外壳重量与环数等核心指标,构建从数据接入、计算分析到可视化呈现的一体化平台。数据层基于Hadoop生态与HDFS存储,Spark与Spark SQL承担批处理与交互式分析;应用层提供Python+Django/Java+Spring Boot实现(两个版本),通过RESTful API对外暴露统一的数据服务,便于灵活部署与课程或科研场景的复用;分析层结合Pandas、NumPy承接特征工程、统计汇总与算法前后处理;前端以Vue+ElementUI为基础,配合ECharts完成性别构成、年龄(环数)分布、相关性热力图、体成分占比、肥满度分布、年龄—尺寸/重量生长曲线及K-Means聚类等图表与交互;底座使用MySQL管理原始与分析结果表,并提供任务调度、指标缓存与权限控制机制,保证在中等规模数据下的响应与稳定。系统强调“数据—算法—可视化”闭环,既可用于养殖场的日常数据管理,也能作为教学或论文实验的可复现实验台。
选题背景
近年来,鲍鱼养殖逐渐走向规模化,养殖环节记录下的大量个体测量、分拣称重和出池统计,往往散落在表格或设备导出的原始文件中,难以形成对个体生长规律的整体认识。传统做法更侧重单一指标,例如只看重量或环数,忽略了多生理特征之间的耦合关系,导致在苗种筛选、饲料配方评估和出池时机判断上缺少数据支撑。随着大数据与开源框架的成熟,利用分布式存储与计算对这些记录进行汇聚、清洗、标准化并建立统一画像,已经具备较高的可行性。围绕养殖生产的真实需求,把长度、重量、环数等多源数据组织成可交互的可视化面板,辅助一线人员快速理解群体结构与阶段性变化,是本课题着力解决的问题。
选题意义
本课题的意义更偏向务实落地:一方面,它把分散在各环节的测量数据整合到统一平台,以可重复的Spark作业沉淀分析流程,减少人工统计带来的偏差,也便于后续补充新字段与新算法;同时,系统用直观图表把“年龄—尺寸—重量”的关系放在同一视角,帮助养殖端更稳妥地判断出池区间与分级策略,哪怕结论是局部性的,也能提供可操作的参考。对教学科研来说,平台提供了从HDFS到前端的完整工程样例,便于课堂与毕设复现实验与对比。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的鲍鱼多重生理特征数据可视化分析系统界面展示:
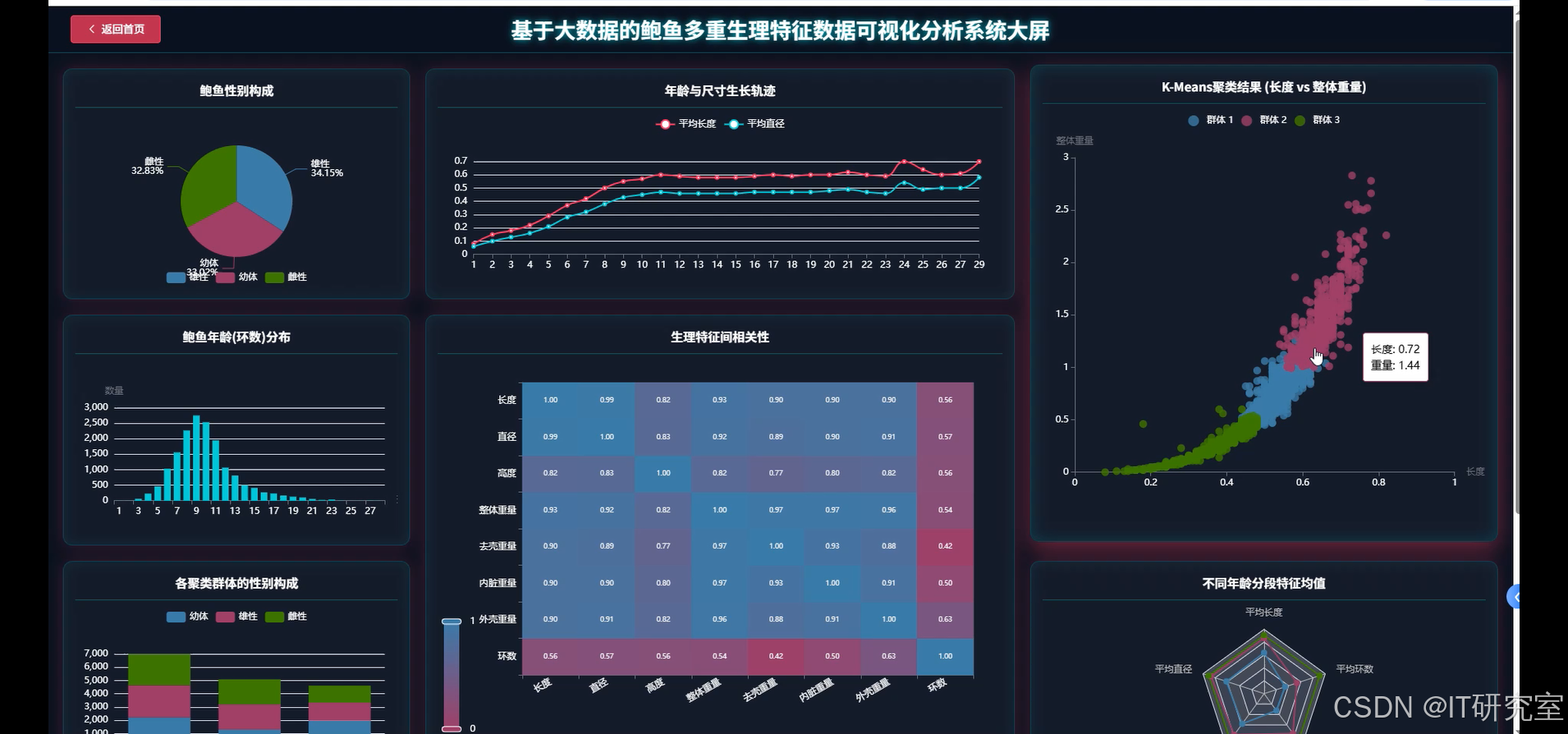
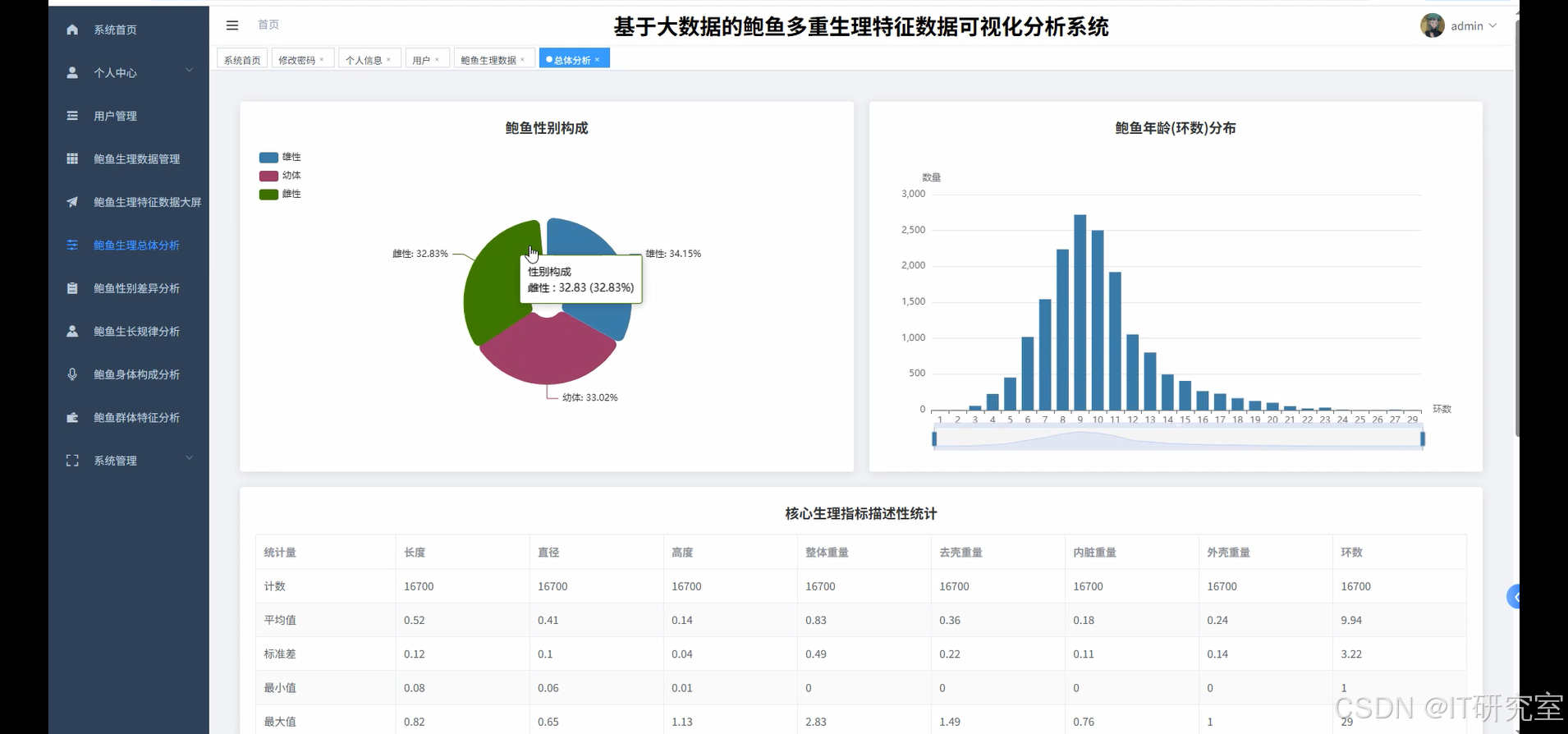
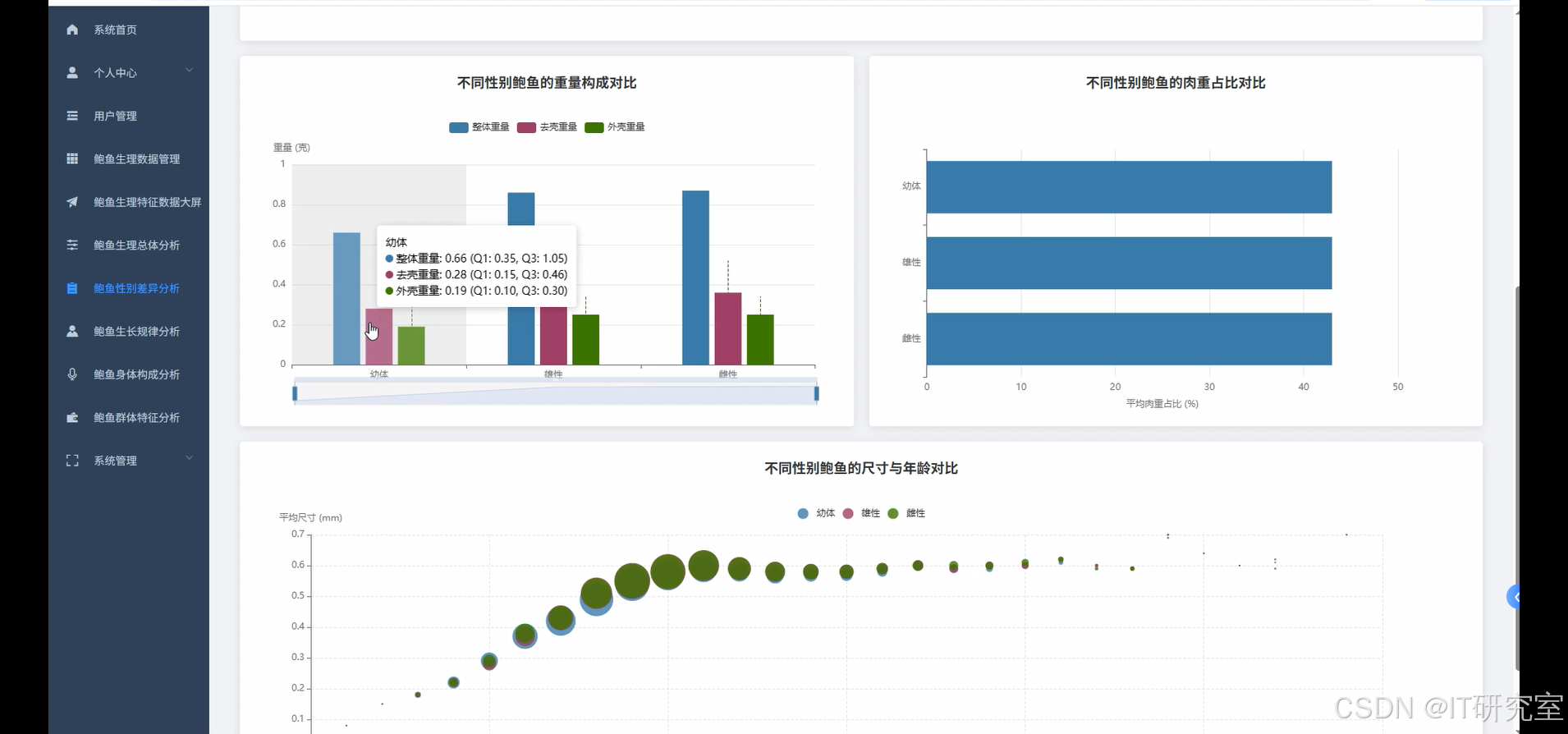
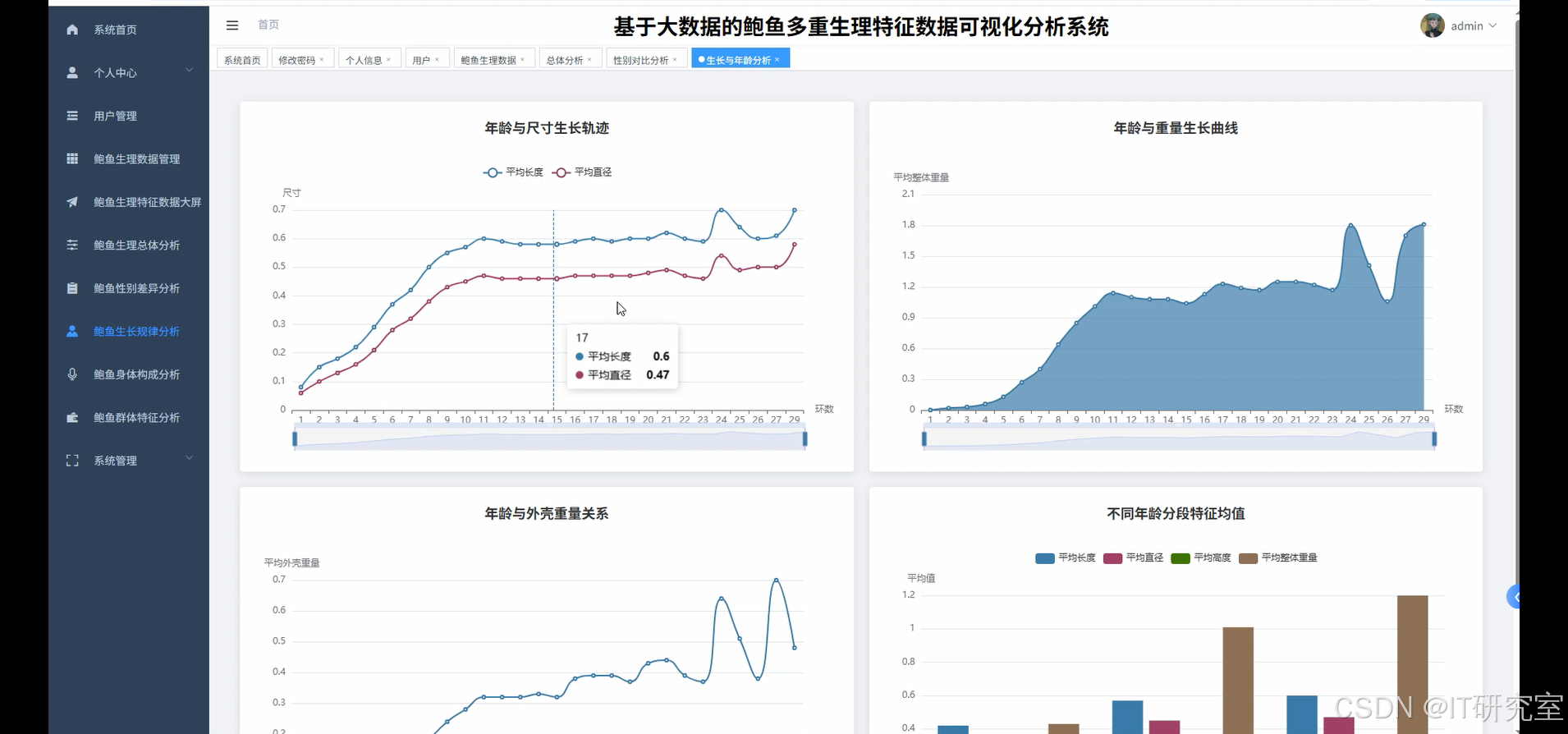
四、代码参考
- 项目实战代码参考:
from pyspark.sql import SparkSession,functions as F,Window
from pyspark.ml.feature import VectorAssembler,StandardScaler
from pyspark.ml.stat import Correlation
from pyspark.ml.clustering import KMeans
spark=SparkSession.builder.appName("AbaloneAnalytics").getOrCreate()
df=spark.read.option("header",True).option("inferSchema",True).csv("hdfs:///data/abalone.csv")
df=df.withColumnRenamed("Sex","性别").withColumnRenamed("Length","长度").withColumnRenamed("Diameter","直径").withColumnRenamed("Height","高度").withColumnRenamed("Whole_Weight","整体重量").withColumnRenamed("Shucked_Weight","去壳重量").withColumnRenamed("Viscera_Weight","内脏重量").withColumnRenamed("Shell_Weight","外壳重量").withColumnRenamed("Rings","环数")
def overview_metrics_backend(input_df):total=input_df.count()sex_ratio=input_df.groupBy("性别").count().withColumn("占比",F.round(F.col("count")/F.lit(total),4)).orderBy("性别")age_dist=input_df.groupBy("环数").count().orderBy("环数")frame=input_df.select("长度","直径","高度","整体重量","去壳重量","内脏重量","外壳重量","环数")assembler=VectorAssembler(inputCols=frame.columns,outputCol="features")vdf=assembler.transform(frame).select("features")corr_mat=Correlation.corr(vdf,"features","pearson").head()[0].toArray().tolist()ldr=input_df.withColumn("长宽比",F.col("长度")/F.col("直径")).select("长宽比")condition=input_df.withColumn("肥满度",F.when(F.col("长度")>0,F.col("整体重量")/F.col("长度")).otherwise(F.lit(None))).select("肥满度")percentiles=input_df.approxQuantile(["整体重量"],[0.25,0.5,0.75],0.01)body_ratio=input_df.withColumn("肉重比",F.col("去壳重量")/F.col("整体重量")).withColumn("壳重比",F.col("外壳重量")/F.col("整体重量")).withColumn("内脏比",F.col("内脏重量")/F.col("整体重量")).agg(F.avg("肉重比").alias("avg_meat"),F.avg("壳重比").alias("avg_shell"),F.avg("内脏比").alias("avg_viscera"))result={"sex_ratio":sex_ratio.toJSON().collect(),"age_dist":age_dist.toJSON().collect(),"corr":corr_mat,"length_diameter_ratio_sample":ldr.limit(50).toJSON().collect(),"condition_index_sample":condition.limit(50).toJSON().collect(),"ww_percentiles":percentiles,"body_ratio_avg":body_ratio.first().asDict()}return result
def growth_curves_backend(input_df):g=input_df.groupBy("环数").agg(F.avg("长度").alias("avg_len"),F.avg("直径").alias("avg_dia"),F.avg("整体重量").alias("avg_ww")).orderBy("环数")w=Window.orderBy("环数").rowsBetween(-2,2)g=g.withColumn("len_ma5",F.avg("avg_len").over(w)).withColumn("dia_ma5",F.avg("avg_dia").over(w)).withColumn("ww_ma5",F.avg("avg_ww").over(w))slope_w=Window.orderBy("环数")g=g.withColumn("len_diff",F.col("avg_len")-F.lag("avg_len",1).over(slope_w)).withColumn("ww_diff",F.col("avg_ww")-F.lag("avg_ww",1).over(slope_w))phase=g.withColumn("阶段",F.when(F.col("环数")<=7,"幼年").when((F.col("环数")>7)&(F.col("环数")<=14),"成长期").otherwise("成熟期"))turning=phase.filter((F.col("len_diff")<0.005)&(F.col("环数")>10)).select("环数").limit(1)curve_payload={"curve_points":g.select("环数","avg_len","avg_dia","avg_ww","len_ma5","dia_ma5","ww_ma5").toJSON().collect(),"phase_summary":phase.groupBy("阶段").agg(F.count("*").alias("n")).toJSON().collect(),"possible_turning_point":turning.toJSON().collect()}return curve_payload
def kmeans_cluster_backend(input_df,k=3):features_cols=["长度","直径","高度","整体重量","去壳重量","内脏重量","外壳重量","环数"]assembler=VectorAssembler(inputCols=features_cols,outputCol="raw")scaled=StandardScaler(inputCol="raw",outputCol="features",withMean=True,withStd=True)vec=assembler.transform(input_df.select(*features_cols,"性别"))vec=scaled.fit(vec).transform(vec)km=KMeans(featuresCol="features",predictionCol="cluster",k=k,seed=7)model=km.fit(vec)pred=model.transform(vec)cluster_stats=pred.groupBy("cluster").agg(F.count("*").alias("n"),F.avg("长度").alias("len"),F.avg("整体重量").alias("ww"),F.avg("环数").alias("rings")).orderBy("cluster")sex_mix=pred.groupBy("cluster").pivot("性别",["M","F","I"]).agg(F.count("*")).na.fill(0).orderBy("cluster")centers=[c.tolist() for c in model.clusterCenters()]payload={"centers":centers,"cluster_stats":cluster_stats.toJSON().collect(),"sex_mix":sex_mix.toJSON().collect()}return payload
# 调用示例(真实部署时由Django/Spring Boot的服务层调用)
overview=overview_metrics_backend(df)
growth=growth_curves_backend(df)
clusters=kmeans_cluster_backend(df,3)五、系统视频
基于大数据的鲍鱼多重生理特征数据可视化分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的鲍鱼多重生理特征数据可视化分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的鲍鱼多重生理特征数据可视化分析系统-Spark-Hadoop-Bigdata
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目