LLM 与强化学习的新范式:Agentic RL 研究综述
大模型 (LLM) 与强化学习 (RL) 的新范式:Agentic RL 研究综述
引言
本文旨在解读并整理一篇关于大模型 (LLM) 领域备受关注的研究——“基于 LLM 的智能体强化学习 (Agentic Reinforcement Learning, Agentic RL)概览” [1]。该综述引用了500 多篇文献,内容丰富,本文将聚焦于其中我个人认为重要的议题。希望这篇总结能为那些对 Agentic RL 感兴趣,或想了解通过强化学习 (RL) 提升 LLM 能力最新进展的读者提供参考。
阅读本文前需知
-
本文不涉及 PPO (Proximal Policy Optimization) 或 GRPO (Group Relative Policy Optimization) 等 RL 算法的详细解释,相关内容已有大量文章阐述。
-
文中部分内容以 DeepSeek-R1 [2] 研究为前提。未阅读过相关论文的读者,建议查阅原著或相关解读文章。以下博客文章对 DeepSeek-R1 的解读对我帮助很大:
- DeepSeek-R1论文解读【非常有益】
- LLM 微调强化学习(一):GRPO (Group Relative Policy Optimization)
三句话总结
- Agentic RL 是一种将 LLM 视为可学习的策略,通过强化学习提升其作为智能体与环境交互并实现长期目标的能力的框架。
- 除了提示工程 (Prompt Engineering) 和有监督微调 (Supervised Fine-Tuning, SFT) 外,强化学习在提升智能体性能方面扮演着关键角色。
- 强化学习正在用于改进智能体的六项核心能力:推理、工具使用、记忆、规划、自我改进和感知。
LLM 与强化学习的发展趋势
在深入探讨 Agentic RL 之前,我们先简单回顾一下强化学习如何应用于 LLM。
偏好微调
自 2022 年 11 月 ChatGPT 发布以来,LLM 对话系统迅速普及。LLM 通常通过大规模网络语料库进行预训练,并通过有监督学习的指令微调来学习如何响应人类指令。然而,仅凭这些,LLM 有时会产生不符合人类偏好或伦理不当的回复,因此研究人员开始利用强化学习进行偏好微调,使 LLM 的回复更符合人类喜好。典型的例子是基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF),它通过学习人类反馈的奖励模型来为 LLM 的回复提供奖励并进行优化。此外,还有使用 AI 反馈的 RLAIF (Reinforcement Learning from AI Feedback),以及诸如 DPO [3] 等不依赖奖励模型或强化学习直接学习偏好的方法。本文将这些偏好微调方法统称为基于偏好的强化微调 (Preference-Based Reinforcement Fine-Tuning, PBRFT),并将其归类为传统强化学习。
推理能力的提升
早期,强化学习主要应用于 LLM 的偏好微调。然而,2024 年 9 月,OpenAI 发布了首个推理模型——OpenAI o1。根据系统卡片 [4] 报告,o1 通过强化学习提升了其深思熟虑并得出答案的能力。尽管具体的实现方法未公开,但 2025 年 1 月发布的 DeepSeek-R1 展示了强化学习能显著提高LLM 的推理和泛化能力。它采用了一种不需要价值评估模型的 GRPO 强化学习算法,并针对具有确定性答案的问题使用可验证的基于规则的奖励,从而减少了奖励模型并降低了学习成本。这标志着强化学习的应用从传统的“对齐目标”扩展到“能力提升目标”,最终促成了本文的主题——Agentic RL 的发展。
工具使用性能的提升
据报道,2025 年2 月发布的 ChatGPT 的 Deep Research(一项利用网络搜索生成报告的功能)也应用了强化学习 [5]。
此外,OpenAI o1 的后续模型 o3,除了推理能力外,在何时以及如何使用工具方面,工具使用性能也通过强化学习得到了提升 [6]。
综上所述,强化学习在 LLM 上的应用已从偏好微调扩展到提升 LLM 的推理能力和作为智能体的工具使用性能。基于这些历史背景,本文接下来将介绍 Agentic RL。
何谓 Agentic RL?
首先,引用本论文中对Agentic RL 的定义:

Agentic RL 指的是一种范式,它将 LLM 视为嵌入在顺序决策循环中的“可学习策略”,而非以优化单一输出一致性或基准性能为目标的静态条件生成模型。在此框架下,通过强化学习赋予模型规划、推理、工具使用、记忆保持和自我反思等自主智能体能力,使其能够在部分可观测的动态环境中自发产生长期的认知和对话行为。
换言之,Agentic RL 可以理解为:将 LLM 视为一个自主行动的智能体,并通过强化学习来提升其与环境交互并实现长期目标的能力。
为了更深入理解,我们来比较一下 Agentic RL 与传统 PBRFT 的区别。
PBRFT 与 Agentic RL 的比较
由于强化学习是基于马尔可夫决策过程 (Markov Decision Process) 框架进行形式化的,因此我们将从这个角度对传统的 PBRFT 和 Agentic RL 进行比较。下表总结了两者的差异:

状态 (State)
在传统的 PBRFT中,情节的初始状态 s0s_0s0 仅由一个用户提示构成,模型响应后情节即刻结束 (时间跨度 T=1T = 1T=1)。相比之下,在 Agentic RL 中,智能体在环境中的每个时间步 ttt 会接收到状态 sts_tst 的观测值 ot=O(st)o_t = O(s_t)ot=O(st)。状态和观测会根据智能体的行动而变化,并随时间推移而演变 (时间跨度 T>1T > 1T>1)。
例如,对于一个研究智能体,通过网络搜索获得的外部信息就构成了观测。在 Agentic RL 中,状态也可以理解为上下文。
行动(Action)
传统 PBRFT 的行动仅限于文本输出。然而,在 Agentic RL 中,行动空间扩展为文本生成 (AtextA_{\text{text}}Atext) 和环境操作 (AactionA_{\text{action}}Aaction)两种。
例如,对于一个操作图形用户界面 (GUI) 的智能体,文本生成可能对应于向人类或其他智能体发送消息,或者生成思维链 (Chain-of-Thought, CoT);而环境操作则对应于点击、滚动或填写表单等 GUI 动作。
转移函数 (Transition)
在传统的 PBRFT 中,由于一次行动(文本生成)后情节即刻结束,因此不存在状态转移。相比之下,在 Agentic RL 中,状态会根据概率转移函数 P(st+1∣st,at)P(s_{t+1} \mid s_t, a_t)P(st+1∣st,at) 在每个步骤中变化。例如,当智能体采取向人类提问的行动时,由于人类的回答不总是确定的,因此下一个状态会随机变化。
奖励 (Reward)
传统的 PBRFT 仅对一次输出的好坏给予标量奖励 r(a)r(a)r(a),没有中间反馈。而 Agentic RL 除了任务完成时的奖励外,还可以在中间步骤适时提供部分奖励。例如,可以对子目标的达成、工具的正确使用、单元测试的通过、数学定理证明的部分进展等给予部分奖励,从而学习包含中间过程的复杂任务。奖励不仅可以是人类或 AI 反馈模型(奖励模型)的评估值,还可以是基于规则的可验证奖励 (Verifiable Rewards) 或模拟器内的分数等多种设计。### 目标函数 (Objective)
传统 PBRFT 的目标函数 JθJ_\thetaJθ 是最大化单步的期望奖励。而 Agentic RL 则是最大化折扣累积奖励 Jagent=Eτ∼πθ[∑t=0T−1γtRagent(st,at)]J_{\text{agent}}= E_{\tau \sim \pi_\theta}[ \sum_{t=0}^{T-1} \gamma^t R_{\text{agent}}(s_t,a_t) ]Jagent=Eτ∼πθ[∑t=0T−1γtRagent(st,at)] 的长期优化问题。智能体需要学习一种考虑未来收益的策略,这要求它选择短期内可能不利但长期有利的行动。
这两种方法都利用强化学习来提高 LLM 的性能,但它们在潜在假设、任务结构和决策粒度上存在根本性差异。下图展示了从 PBRFT 到 Agentic RL 在各个要素上的范式转变。
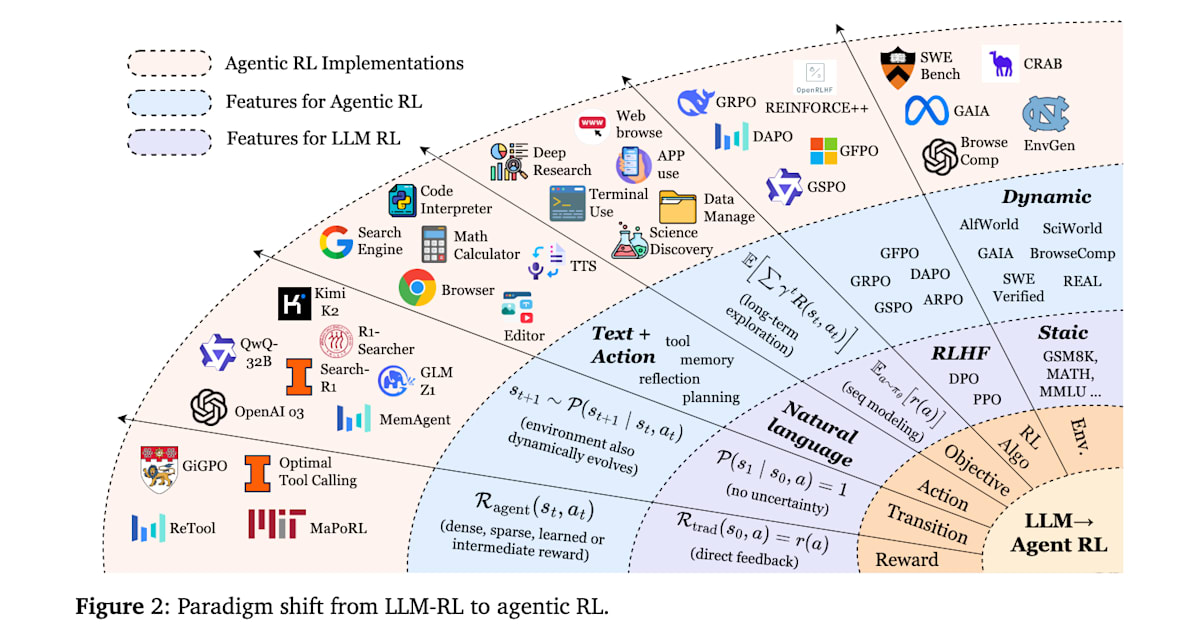
智能体的核心能力与通过强化学习进行的优化
在 Agentic RL 中,关键在于赋予 LLM 智能体何种能力,以及如何通过强化学习来优化这些能力。本文提到了以下六项核心能力。下面将介绍如何通过强化学习来提升这些能力。
- 推论 (Reasoning)
- 工具使用 (Tool Use)
- 记忆 (Memory)
- 规划 (Planning)
- 自我改进 (Self-Improvement)
- 感知 (Perception)
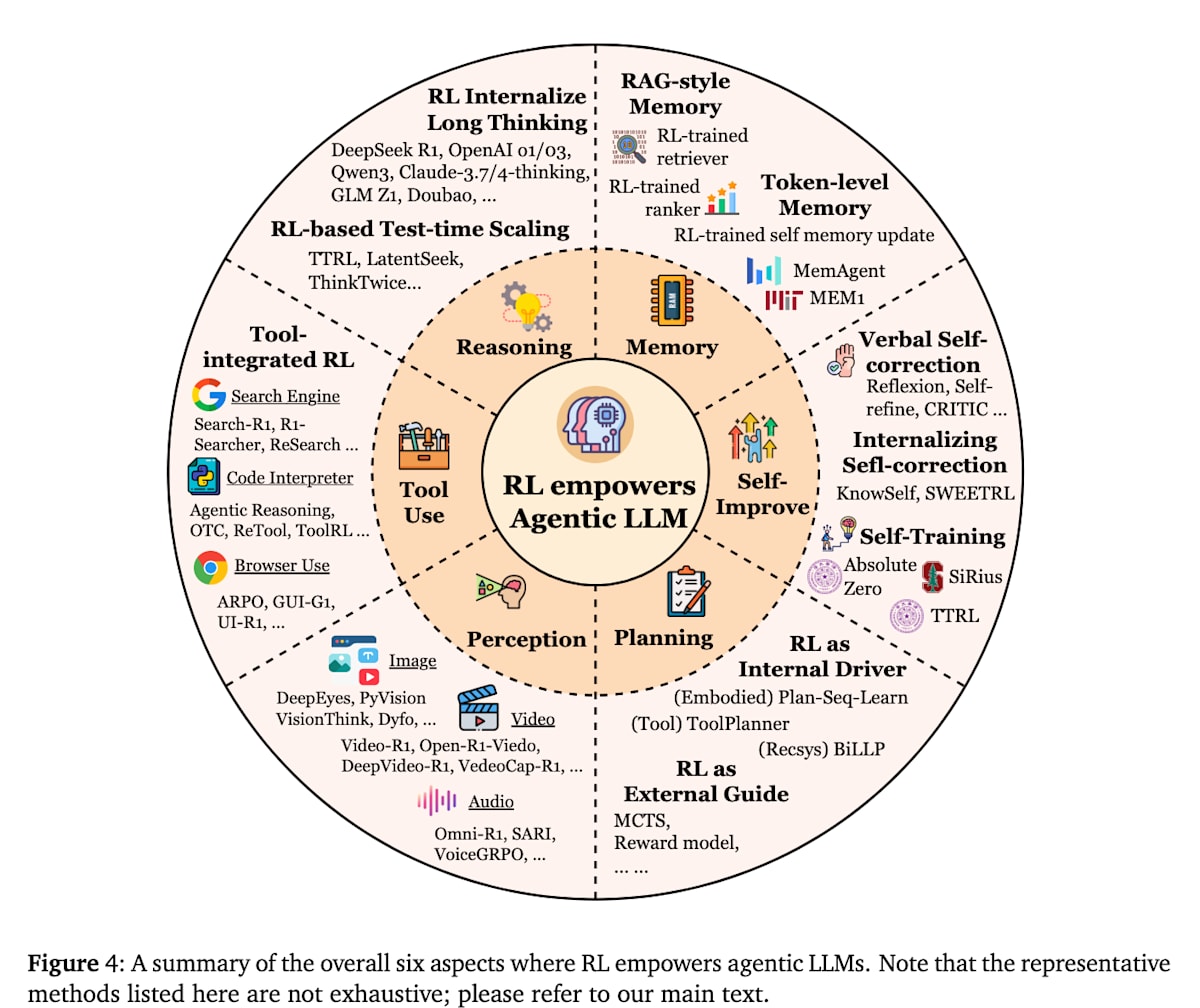
推论(Reasoning)
推论是指从给定信息中逻辑地得出结论的过程。传统的 LLM 已经通过 Chain-of-Thought (CoT) 提示等技术具备了推论能力,但最近,利用强化学习提升 LLM 推论能力的研究正在取得进展。DeepSeek-R1 极大地加速了这一趋势。它通过采用无需价值函数模型的 GRPO 和针对单一答案任务的基于规则奖励的效率优化,广泛展示了强化学习增强推论能力的效果。然而,由于其实现是封闭的,这给可复现的比较验证和进一步研究带来了障碍。DAPO [7] 的出现解决了这一问题。它在 DeepSeek-R1 一半的学习步数下达到了相似的性能,最重要的是,DAPO 完全开源了算法、代码和数据集,为推论模型的强化学习研究提供了可复现和扩展的环境,这是一项重要贡献。
推论模型的研究除了进一步提升推论能力外,还需解决“过度思考 (overthinking)”的问题。过度思考会导致响应用户的时间过长,甚至可能因为深思熟虑而反而降低准确性。
Qwen3 [8] 为了在单一模型中实现用于复杂多步推论的“思考模式 (thinking mode)”和用于快速响应的“非思考模式 (non-thinking mode)”,结合了强化学习 (RL) 和有监督微调 (SFT),并进行了以下四阶段学习。有趣的是,通过思考模式的学习,模型自然地获得了“思考预算 (thinking budget)”机制,用户可以以 token 数的形式指定分配给推论的计算资源。
- 第一阶段:Long-CoT 冷启动 (SFT):通过 SFT 让模型学习基本的推论模式。
- 第二阶段:推论强化学习 (Reasoning RL):通过 RL 提升在高级复杂推论任务(如数学和编程)中的性能。
- 第三阶段:思考模式融合 (SFT):通过 SFT学习遵循用户指令,例如
/think和/no_think。 - 第四阶段:通用强化学习 (General RL):针对一般任务(如指令遵循、格式遵守、智能体能力等),调整模型响应以符合用户偏好。
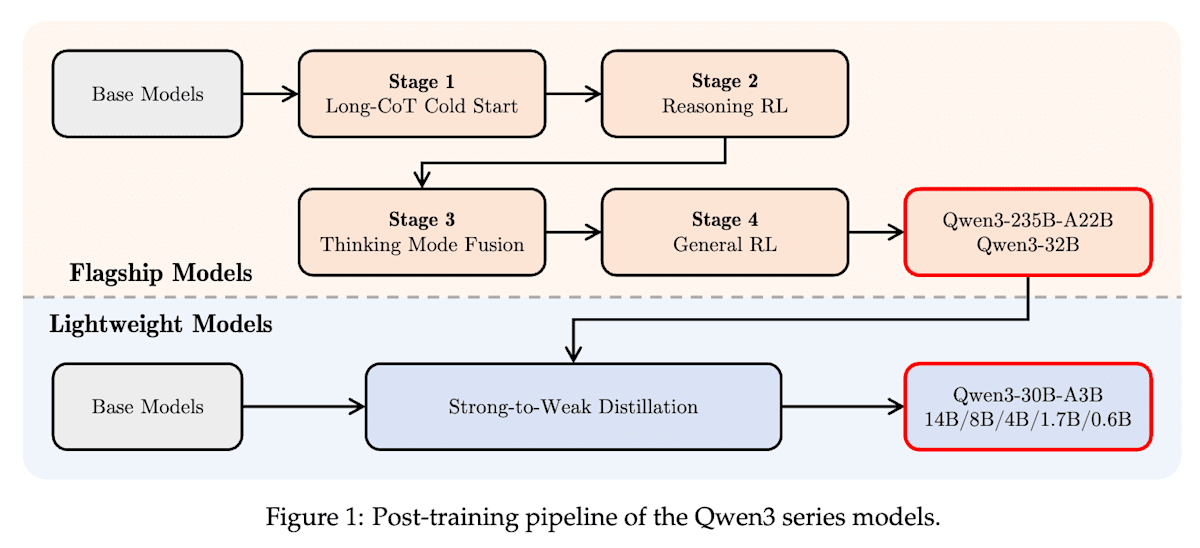
Qwen3 Technical Report (https://arxiv.org/abs/2505.09388)
此外,第二阶段的推论强化学习 (Reasoning RL) 为了稳定学习,设计了满足以下条件的数据集。特别是第二和第三点给我留下了深刻印象,似乎在推论强化学习中难度设置非常重要。
- 未在冷启动阶段使用。
- 对于冷启动模型而言是可学习的。
- 尽可能具有挑战性。
- 涵盖广泛的子领域。
工具使用 (Tool Use)
工具使用指智能体调用并活用外部信息源、API、计算资源等的能力。这包括通过搜索引擎获取信息、使用计算器或执行代码、向其他模型发送查询等,即与任务完成所需的所有外部工具进行交互。通过强化学习,智能体能够从试错中学会**“何时、使用哪个工具、如何使用”**。其发展大致分为三个阶段。
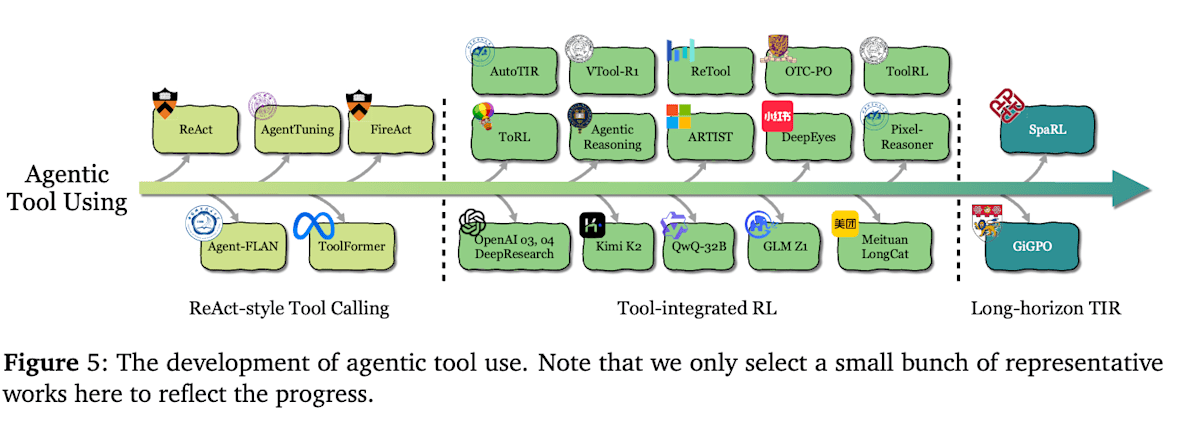
ReAct 形式的工具使用
在智能体工具使用的早期阶段,人们尝试了基于提示的方法,如 ReAct [9],以及通过 SFT 模仿学习工具使用过程来获得工具使用能力的 Toolformer [10]。然而,模仿学习难以泛化到未曾学过的未知工具,缺乏灵活性。此外,准备工具使用历史数据的成本也较高,因此,研究人员开始尝试使用强化学习,通过基于结果的方式学习工具使用策略。
工具集成型强化学习 (Tool-Integrated RL)
在下一个阶段,工具使用被深度整合到 LLM 的认知循环中,并出现了能够跨越多个回合使用工具的智能体系统。智能体根据奖励,通过强化学习来学习在何种情境下调用何种工具以及如何利用所获得的信息。
例如,ReTool [11] 没有像 DeepSeek-R1 那样对复杂的数学问题进行基于文本的强化学习,而是通过强化学习提升了将 Python 代码解释器作为工具使用的能力,从而提高了正确率。这项研究首先通过 SFT 学习了基本的工具使用能力,然后通过强化学习,利用对最终答案的正确奖励来学习工具使用策略。
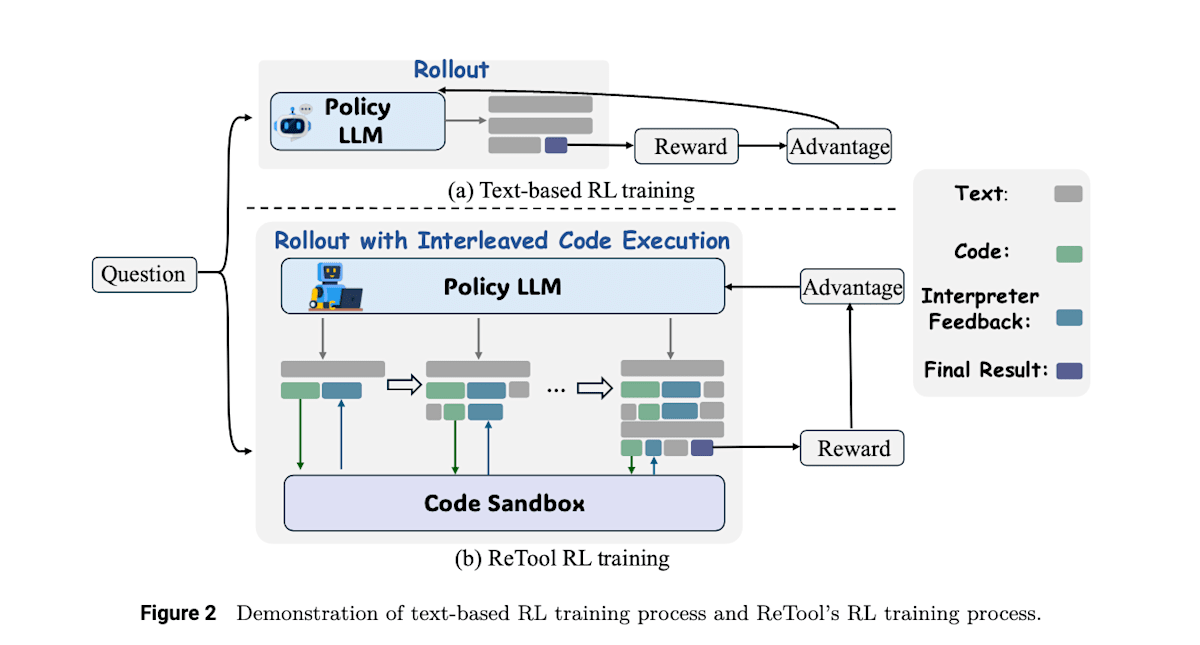
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs (https://arxiv.org/abs/2504.11536)
几乎同期发布的 ARTIST [12] 也采用了类似的方法,但 ARTIST 不仅针对数学任务,还在 BFCL v3 和 τ-bench等需要多步函数调用的基准测试中进行了评估。它在这些任务中通过反复进行推理和工具使用来生成最终答案,并通过强化学习,利用最终答案的正确奖励以及工具调用成功奖励来学习何时以及如何更好地使用工具。
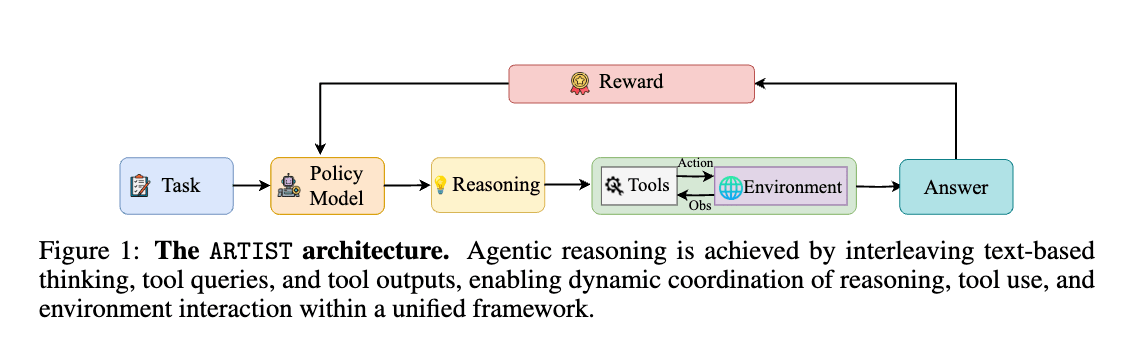
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning (https://arxiv.org/abs/2505.01441)
上述利用强化学习进行工具集成型推理的方法,不仅在研究领域,据说也已应用于 ChatGPT 的 Deep Research 和 OpenAI o3 等商业系统的微调中(具体应用方法不明)。
长期、多步的工具使用
未来的研究方向包括长期步骤中的工具协作,以及通过组合多个工具来解决复杂任务。
DeepSeek 发布的 GRPO 是一种对数学问题等一问一答型任务有效的强化学习算法,但它将一系列行动作为一个整体进行评估,因此在多步任务中难以判断每个步骤的好坏,这是一个挑战。
GiGPO [13] 为了解决这个问题,采用了一种名为 Group-in-Group Policy Optimization (GiGPO) 的方法,它在情节级别和步骤级别两个分组结构中计算优势值 (advantage,即衡量行动好坏的标准)。
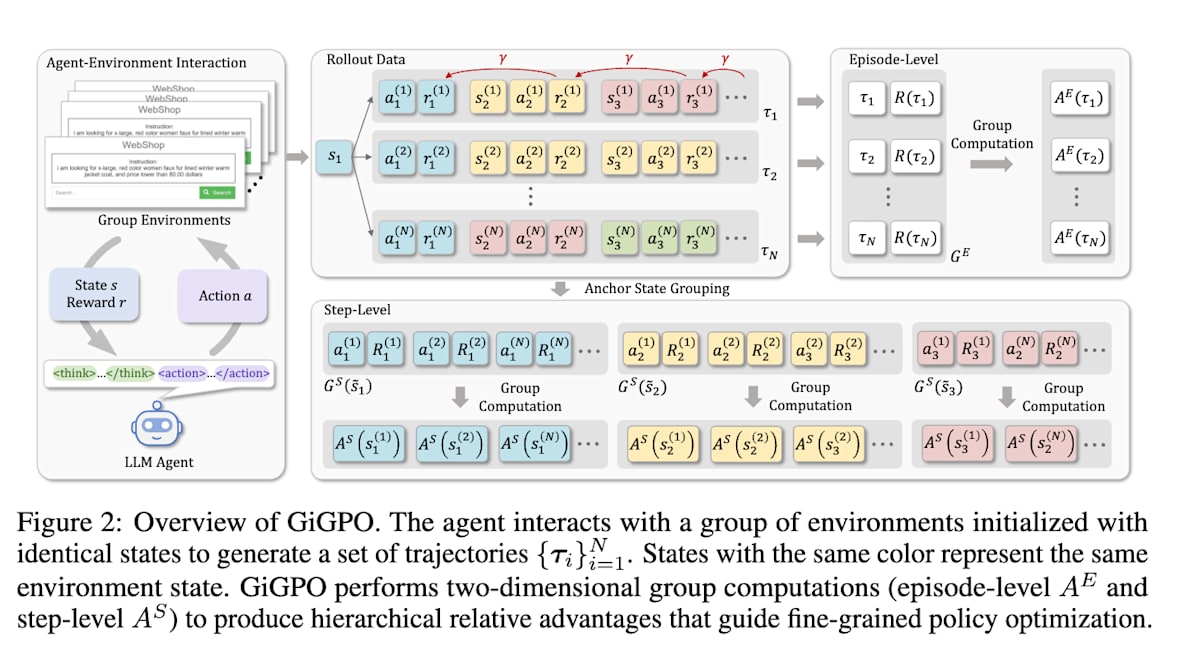
Group-in-Group Policy Optimization for LLM Agent Training (https://arxiv.org/abs/2505.10978)
内存(长期与短期记忆)
内存是指智能体保持和重用过去获得的信息和经验的能力。由于 LLM 自身的上下文窗口有限,智能体若要长期运行,就需要利用外部记忆(如知识库或对话历史)。针对这一挑战,传统方法包括使用检索增强生成 (Retrieval-Augmented Generation, RAG) 进行搜索和参考,以及通过将对话历史全部填入提示来扩展上下文窗口。然而,静态检索策略和手动设计的记忆更新可能无法针对特定任务优化信息检索和遗忘。Agentic RL 通过强化学习来学习记忆哪些信息以及回忆什么信息。
RAG 形式的内存
作为通过强化学习优化 RAG 形式搜索机制的方法,Tan et al. (2025) [14] 提出的反射式记忆管理 (Reflective Memory Management, RMM) 中的追溯反射 (Retrospective Reflection) 是一个典型例子。该方法旨在解决传统 RAG 的问题,即“搜索方法是固定的,不会根据对话上下文进行优化”。其步骤如下:
- 重排序器 (Reranker) 会筛选出由检索器 (Retriever) 搜索到的记忆候选。
- LLM 在利用这些记忆生成响应时,会自我评估实际引用了哪些记忆。
- 对被引用的记忆给予正面奖励 (+1),对未被引用的记忆给予负面奖励 (-1),并更新重排序器的参数。
通过这一系列在线强化学习 (Online RL) 处理,重排序器能够通过对话持续学习,更准确地选择“LLM 真正需要的记忆”。
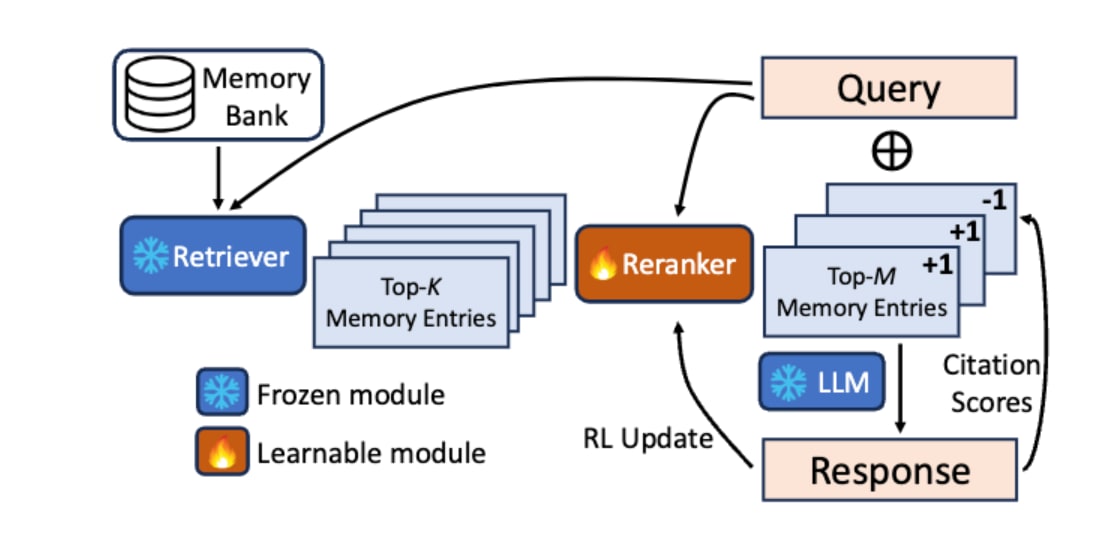
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents (https://arxiv.org/abs/2503.08026)
上述例子展示了利用强化学习改善 RAG 搜索机制,而 Memory-R1 [15] 则利用强化学习来管理智能体的外部记忆。
Memory-R1 引入了两个智能体:“记忆管理器 (Memory Manager)”和“回答智能体 (Answer Agent)”。记忆管理器学习“添加 (ADD)”、“更新 (UPDATE)”、“删除 (DELETE)”和“不操作 (NOOP)”等记忆操作,而回答智能体则从检索到的记忆中选择最相关的记忆来生成答案。这两个智能体的学习都使用了强化学习,其中记忆管理器的学习方法尤其值得关注。记忆管理器不会因其自身的行动获得奖励,而是根据回答智能体能否生成正确答案这一最终结果获得奖励,从而学习最优的记忆操作策略。这种自身的行动影响其他智能体的行动,并根据其结果进行学习的方式,是强化学习所独有的,我认为这是一项有趣的研究。
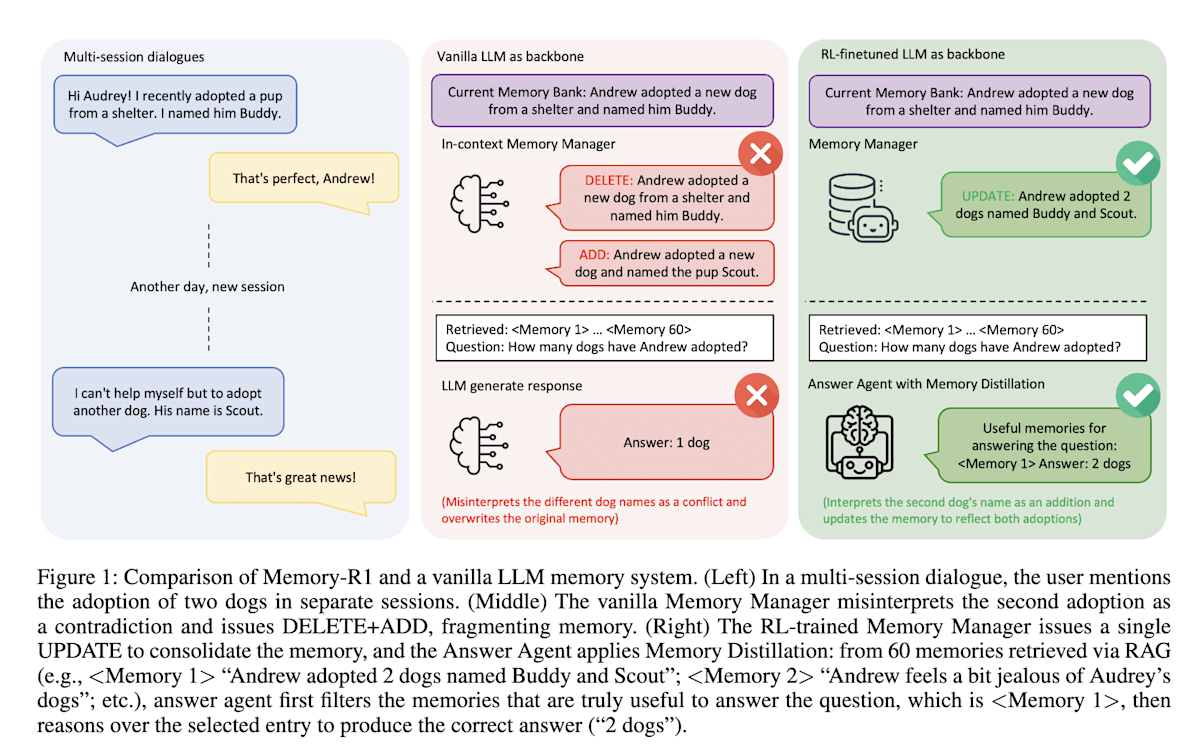
Memory-R1: EnhancingLarge Language Model Agents to Manage and Utilize Memories via Reinforcement Learning (https://arxiv.org/abs/2508.19828)
Token 层级内存
这是一种不依赖 RAG 等外部记忆,而是 LLM 自身具备可学习记忆的方法。
MemAgent [16] 的目标是让 LLM 能够处理非常长的文本(数百万个 token)。就像人类阅读长篇文章时会做笔记一样,MemAgent 将文本分块并按顺序阅读,同时将必要信息写入固定长度的“记忆”中以理解内容。这种记忆管理(即在有限的上下文长度中记忆什么)通过最终任务的成功奖励由强化学习进行优化。MemAgent 的机制本身很有用,并且实验结果表明有强化学习的 MemAgent 比没有强化学习的 MemAgent 性能有所提升,这证实了强化学习的有效性。
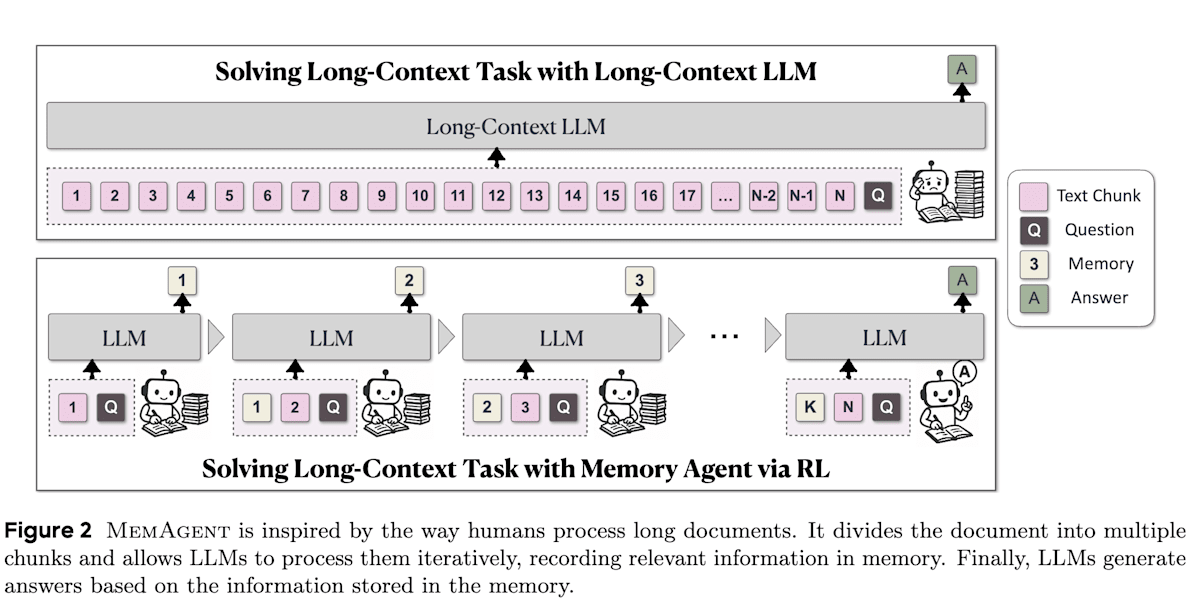
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent (https://arxiv.org/abs/2507.02259)
规划 (Planning)
规划是指制定一系列行动以达成目标的能力。这是人类解决问题的核心技能,对于 LLM 智能体来说,“何时、做什么、以何种顺序做” 的决策至关重要。早期的 LLM 智能体并非直接回答给定任务,而是尝试采用例如 ReAct 等提示方法,让 LLM 自身逐步生成 CoT 和行动候选。然而,这些基于提示技巧或少样本示例的静态规划难以适应新情况,也难以通过试错来改进策略。强化学习为此问题提供了一种途径,即通过经验学习规划策略。
RAP [17] 通过蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 实现了超越 CoT 的规划能力。传统的 CoT 生成线性思维过程,而 RAP 将 LLM 视作世界模型,利用MCTS 生成基于树的思维过程(状态)。通过预先探索选择奖励最高的推理路径,RAP 实现了更鲁棒的规划,尽管推理时间有所增加。每个推理步骤的奖励(评估值)采用了行动似然度、状态置信度、自我评估以及与目标的接近程度等多个指标。尽管这不涉及微调,因此没有使用强化学习,但仍值得关注。
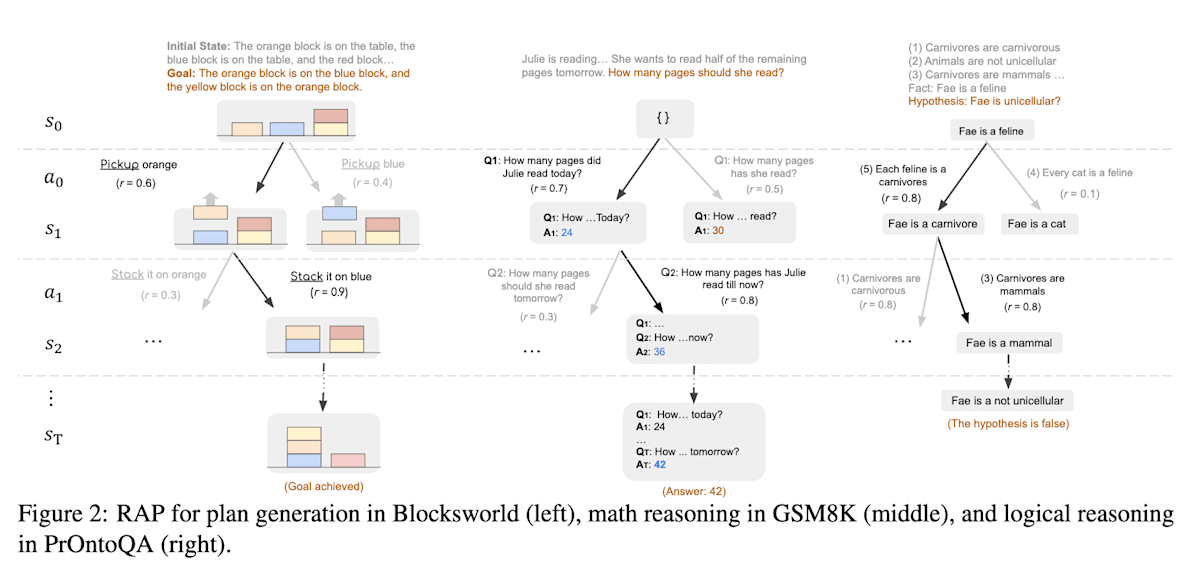
Reasoningwith Language Model is Planning with World Model (https://arxiv.org/abs/2305.14992)—
自我改进 / 反思 (Self-Improvement / Reflection)
自我改进是指智能体回顾自身输出或行动,纠正错误并优化策略的能力。LLM 通过提供自我反思和自我验证的提示也可以提高回答准确率,但 Agentic RL 将其集成到智能体的内部循环中,并通过学习进行优化。
KnownSelf [18] 使得智能体在执行任务时,能够自主回顾当前情况,并根据自身状态,如“这个任务很简单,可以快速完成 (Fastthinking)”、“有点难,先停下来重新思考 (Slow thinking)”、“我的能力无法解决,需要利用外部知识 (Knowledgeable thinking)”,自适应地切换思考过程和知识利用方式。
具体来说,它首先通过 SFT 学习将智能体生成的行动分类到三种思考模式中,然后通过 DPO (Direct Preference Optimization) 方法,使用两组响应对数据集进行偏好微调。通过这个过程,KnownSelf 在 ALFWorld (智能体在家庭环境中操作物体) 任务和 WebShop (根据指令在网站上购物) 任务中都显示出性能提升。
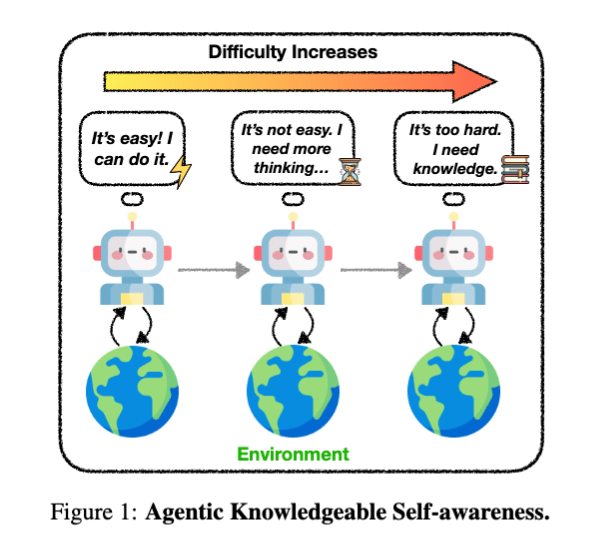
Agentic Knowledgeable Self-awareness (https://arxiv.org/abs/2504.03553)
虽然方向略有不同于自我反思,但无需人工干预即可让智能体自主学习的自我改进研究也在进展。
Absolute Zero [19] 是一个完全不依赖人类创建的任务或标签,LLM 自主进行自我改进的框架。在这个框架中,LLM 扮演两个角色:提议者 (Proposer) 负责提出问题,解决者 (Solver) 负责解决问题。解决者只有在解决提议者生成的问题并获得正确答案时才能获得奖励 1。而提议者则在提出使解决者奖励变小的问题时获得高奖励,即 rproposer=1−rsolverr_{\text{proposer}} = 1 - r_{\text{solver}}rproposer=1−rsolver。然而,如果问题过难或过易,则不利于自我改进,因此当 rsolverr_{\text{solver}}rsolver 等于 0 或 1 时,提议者的奖励也为 0。这让我联想到了 GAN (Generative Adversarial Network) 的结构。
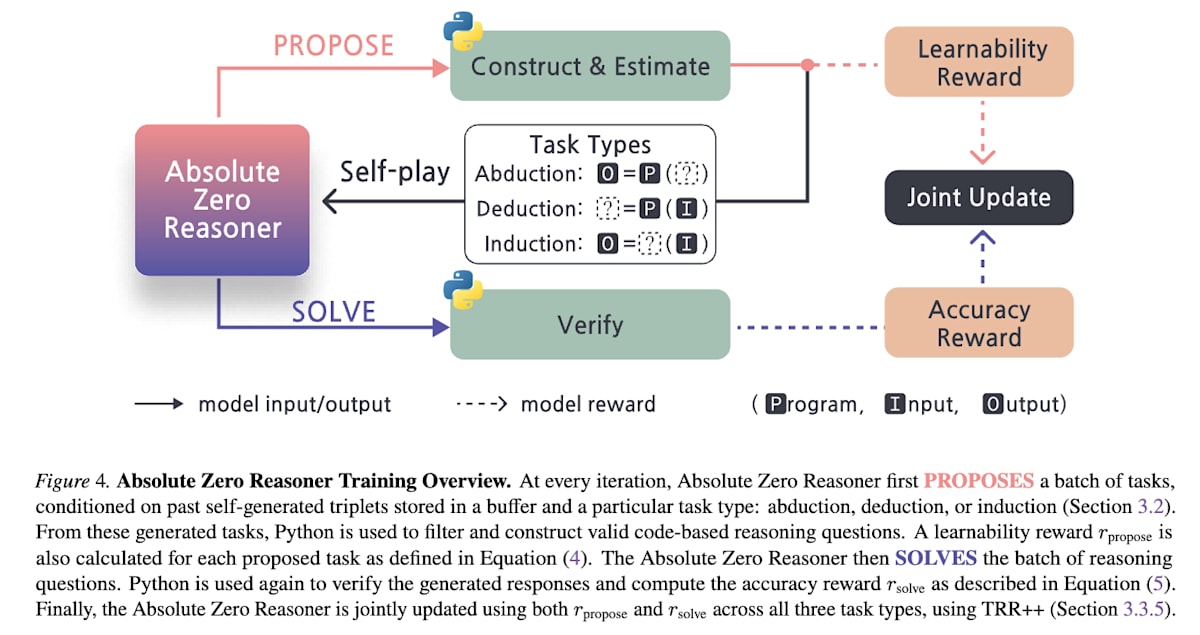
Absolute Zero: ReinforcedSelf-play Reasoning with Zero Data (https://arxiv.org/abs/2505.03335)
TTRL [20] 旨在通过在推理时(测试时)利用自我演化来提高性能,而无需正解标签数据。具体来说,LLM 自身会生成多个回答,然后多数投票选择得票最高的预测作为正解,从而创建伪正解数据。TTRL 将伪正解标签与模型预测是否一致作为奖励,并通过强化学习进行训练,从而在无需人工标注的情况下提升模型的推理能力。仅从这一点来看,这似乎只是在微调模型,使其更容易选择高票回答(即使概率分布更集中)。但实验表明,经过 TTRL 在特定数学任务上训练的模型,在其他不同的数学任务上也表现出性能提升,证实了其泛化能力的提高。
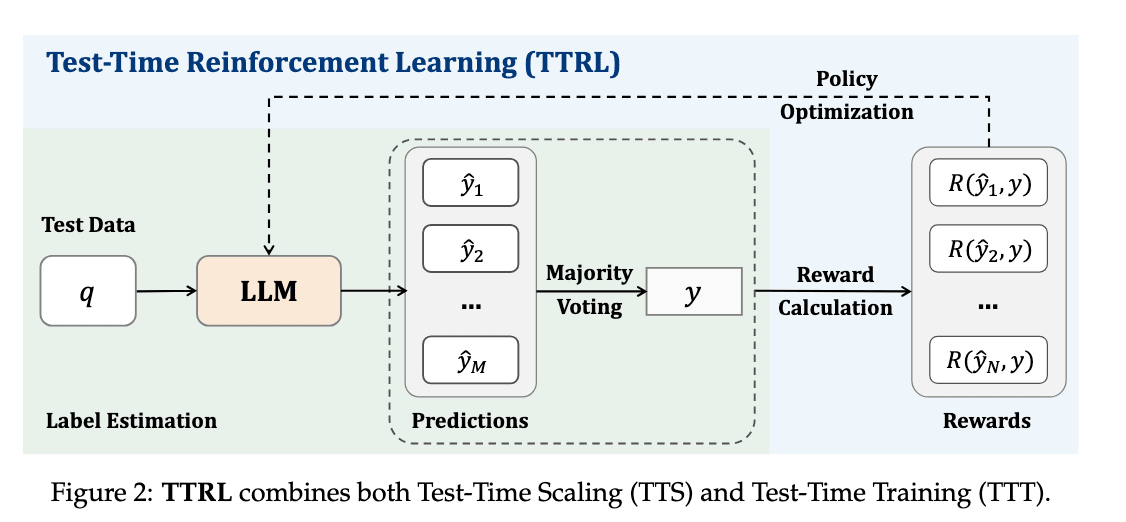
TTRL: Test-Time Reinforcement Learning (https://arxiv.org/abs/2504.16084)
感知 (Perception)
感知是指智能体理解和识别文本以外模态(图像、音频、真实世界传感器数据等)的能力。受 LLM 推理增强强化学习成功的启发,研究人员正在努力将这些成果应用到多模态学习中。
Vision-R1 [21] 旨在利用多模态大模型 (Multimodal Large Language Model, MLLM) 同时理解图像和文本,并在数学几何问题等复杂视觉推理任务中复现类似人类的深度思考过程。它采用了类似于 DeepSeek-R1 的方法,利用强化学习提升数学问题的推理能力,但其特点是结合了“DeepSeek-R1 的模仿学习”和“逐步思考抑制训练”两个阶段的学习。
- 第一阶段:模态桥接 (Modality Bridging) 和模仿学习:通过 MLLM 将视觉信息转换为详细的文本描述,然后将这些文本传递给 DeepSeek-R1,使其输出详细的 CoT。接着,将 DeepSeek-R1 的 CoT 作为正解标签,对 MLLM 进行模仿学习,使其能够稳定地生成基于视觉信息的 CoT。
- 第二阶段:逐步思考抑制训练:由于在第一阶段结束后,CoT 越长性能越差,因此在第二阶段中,通过限制思考长度并逐步增加,同时利用强化学习提升包括视觉信息在内的推理能力,进行逐步思考抑制训练。
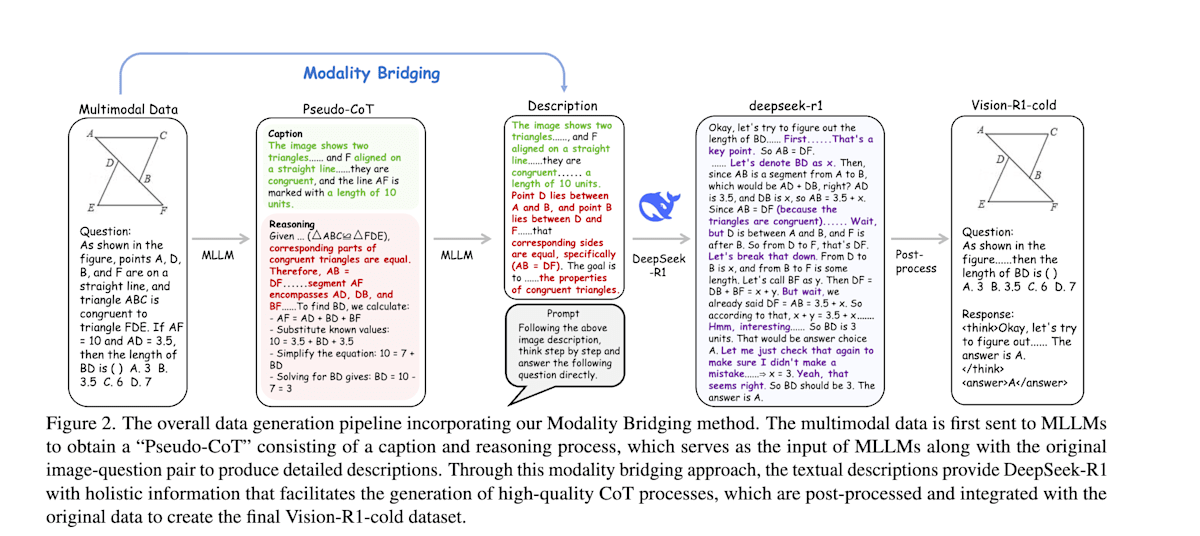
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models (https://arxiv.org/abs/2503.06749)
OPENTHINKIMG [22] 利用强化学习来学习如何使用视觉工具解决视觉问题。
具体来说,VLM接收图像和文本作为输入,并通过操作诸如读取图表数值的 OCR 工具、放大图像局部区域的缩放工具等视觉工具,来解决视觉问题。模型在环境中自由使用工具,将工具的使用结果作为视觉信息输入,并通过最大化最终任务的对错奖励来更新策略。其中,将工具的视觉输出直接作为模型下一个判断依据这一点非常重要,这使得模型能够理解自身行动在视觉上会产生何种结果,从而做出更明智的工具选择。
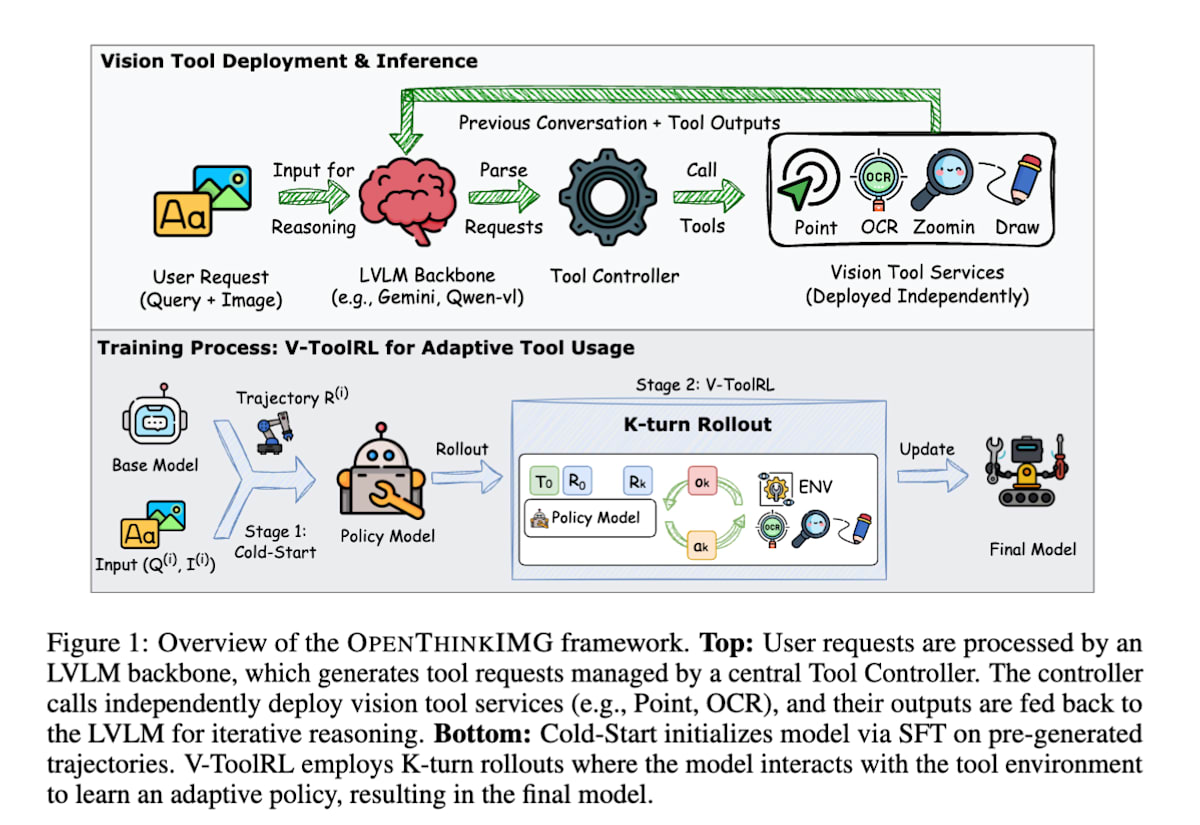
OPENTHINKIMG: Learning to Think with Images via Visual Tool Reinforcement Learning (https://arxiv.org/abs/2505.08617)
Visual Planning [23] 旨在让模型像人类一样在脑海中构思地图或模拟家具摆放,通过图像而非语言来制定任务计划。模型从当前的图像状态生成多个下一图像状态的候选,并根据前后状态的差异通过规则推断出行动(如果是导航任务,则上下左右移动方向属于行动)。通过重复这一步骤,并在接近目标时给予奖励,模型能够以图像为基础学习达成目标的行动计划。
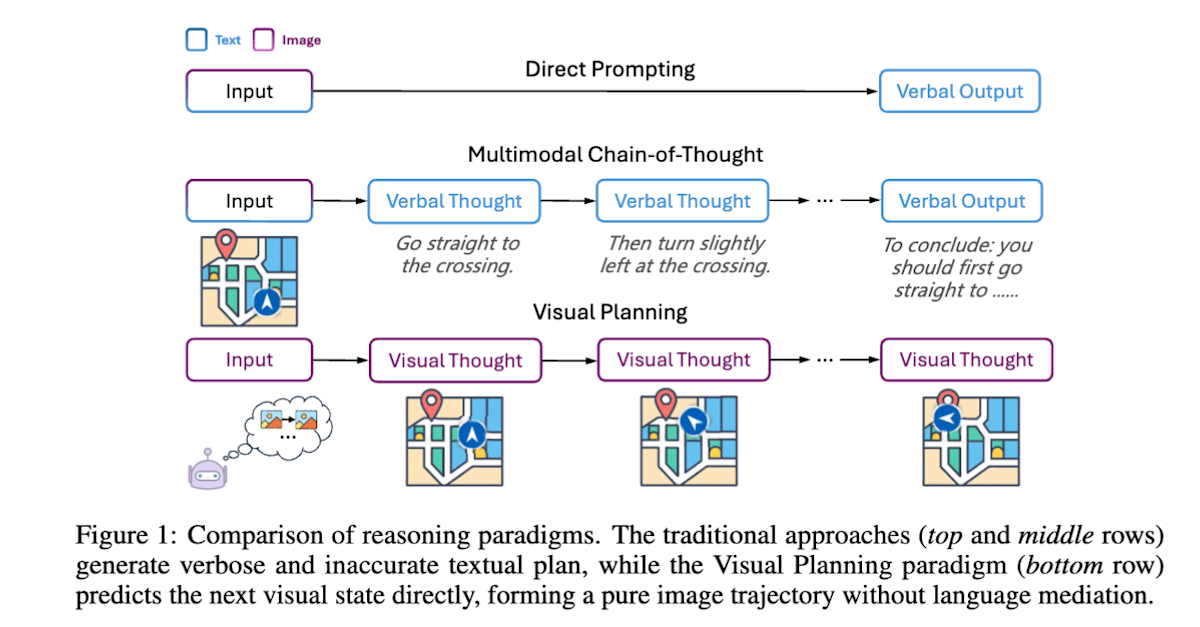
Visual Planning: Let’s Think Only with Images (https://arxiv.org/abs/2505.11409)
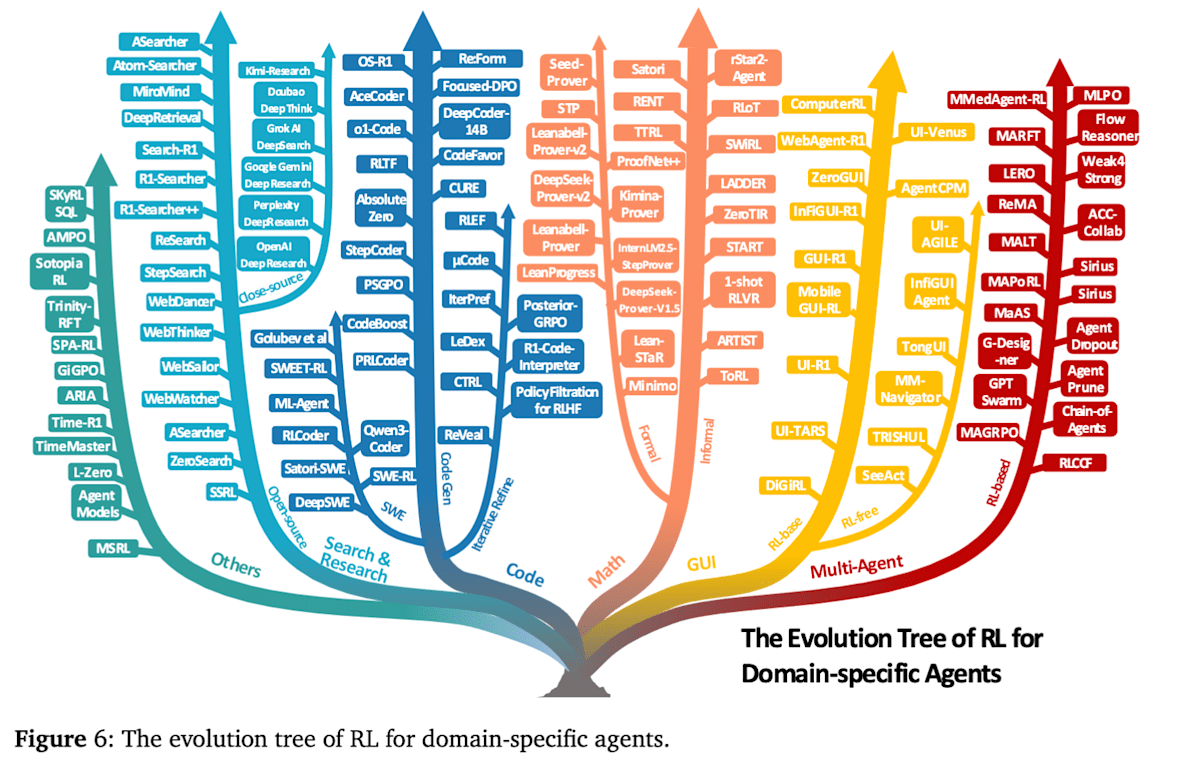
主要应用领域与代表性方法
Agentic RL 已开始应用于各种任务领域,本文列举了以下应用领域。本节将介绍强化学习在各个智能体领域中的应用方式,并提供代表性的方法和研究实例。
- 搜索与调研智能体 (Search & Research Agents)
- 代码智能体 (Code Agents)
- 数学智能体 (Math Agents)
- GUI 智能体 (GUI Agents)
- 多智能体系统 (Multi-Agents)
- 其他 (视觉、具身智能体) (Vision, Embodied Agents)
搜索与调研智能体
搜索与调研智能体旨在利用外部知识库和网络搜索引擎,为用户的问题或调研请求提供准确而全面的答案。
RAG (Retrieval-Augmented Generation) 广泛用于赋予 LLM 搜索能力,但对于需要交替进行搜索和推理的复杂多轮任务,不进行学习的基于提示的方法存在局限性。因此,利用强化学习端到端地直接优化查询生成、搜索和推理的研究正在取得进展。
其中一项主要研究是,在 RAG 基础上,利用网络搜索 API,通过强化学习优化查询生成和多阶段推理的方法。
search-R1 [24] 引入了 <think>(思考)、<search>(搜索查询)、<information>(搜索结果)和 <answer>(回答)这四个特殊 token。它通过 PPO 或 GRPO 等强化学习算法,学习多次迭代思考和搜索,最终给出答案的过程。它将思考、搜索查询和回答分别视为行动,并将最终答案是否正确作为奖励,从而提升了搜索和推理两种能力。此外,它通过避免对 <information>(搜索结果)进行损失计算,从而避免了学习搜索结果本身,这有助于学习的稳定性和性能提升。
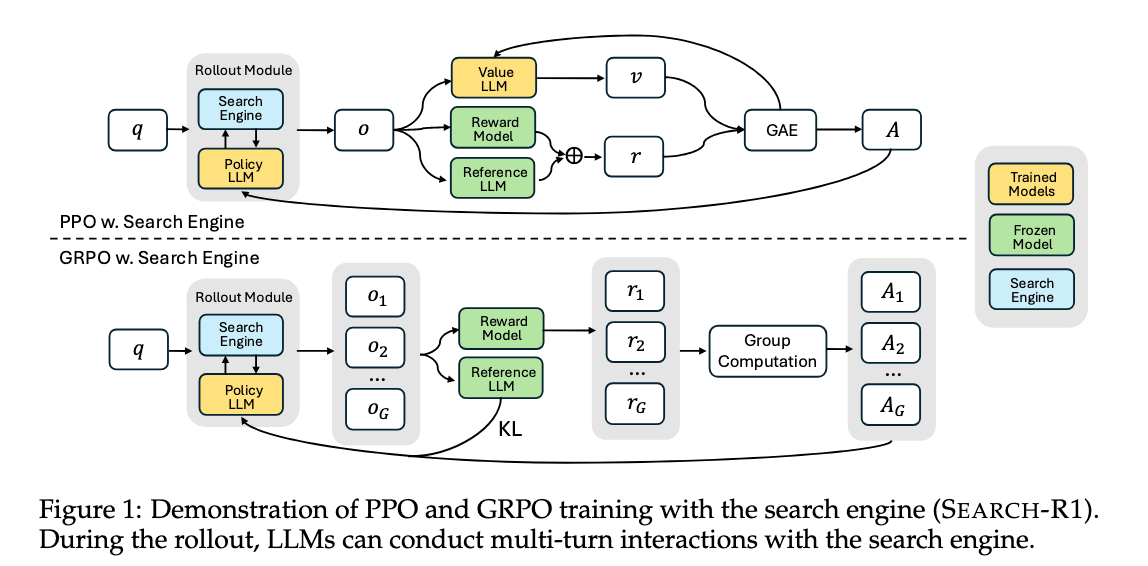
Search-R1: Training LLMs to Reason and Leverage SearchEngines with Reinforcement Learning (https://arxiv.org/abs/2503.09516)
search-R1 的一个挑战是,当搜索轮数增加时,单次学习所需时间会大幅增加,从学习效率的角度来看,需要将智能体的搜索轮数限制在 10 次以内。
ASearcher [25] 是 search-R1 的进一步发展。它通过构建一个将智能体行动与模型学习完全分离的异步学习系统,从而在并行处理多个搜索任务时提高了学习效率。这使得智能体能够学习长达 128 轮的长时间探索。
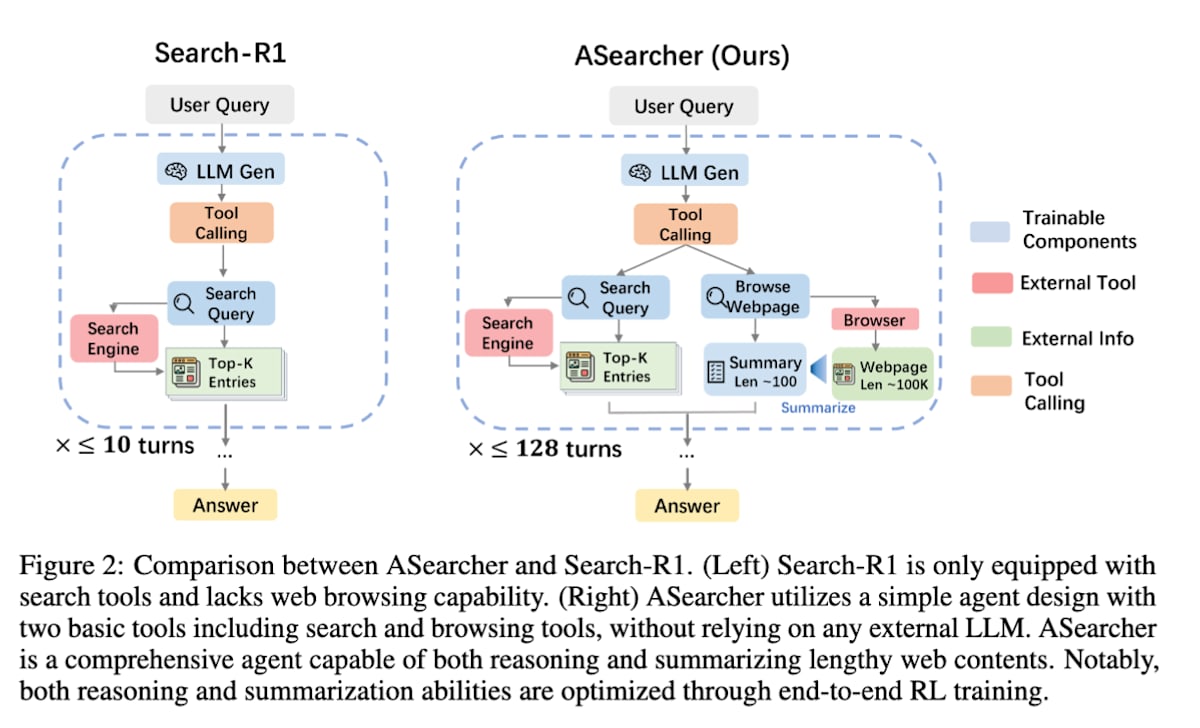
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL (https://arxiv.org/abs/2508.07976)
上述直接利用外部网络搜索 API 的方法存在两个问题:一是网络文档质量可能会成为噪声,导致学习不稳定;二是学习所需的 API 调用成本高昂。
ZeroSearch [26] 在有效利用外部搜索引擎的能力学习方面与上述方法相似,但其最大特点在于,在学习过程中完全不使用实际的搜索引擎(如 Google)。将 search-R1 和 ZeroSearch 的图进行比较,会发现在执行智能体动作的 Rollout 模块中,搜索引擎被替换为 SimulationLLM。通过这种方式,它利用另一个 LLM 模拟搜索引擎的行为,并在模拟环境中学习 LLM 的搜索和推理能力。结果表明,ZeroSearch 能够在远低于实际搜索引擎学习模型的成本下,实现同等甚至更优的性能。LLM 能否模拟搜索引擎这一点让人有些疑问,但它能成功运作令人觉得不可思议,我认为这是一项有趣的研究。
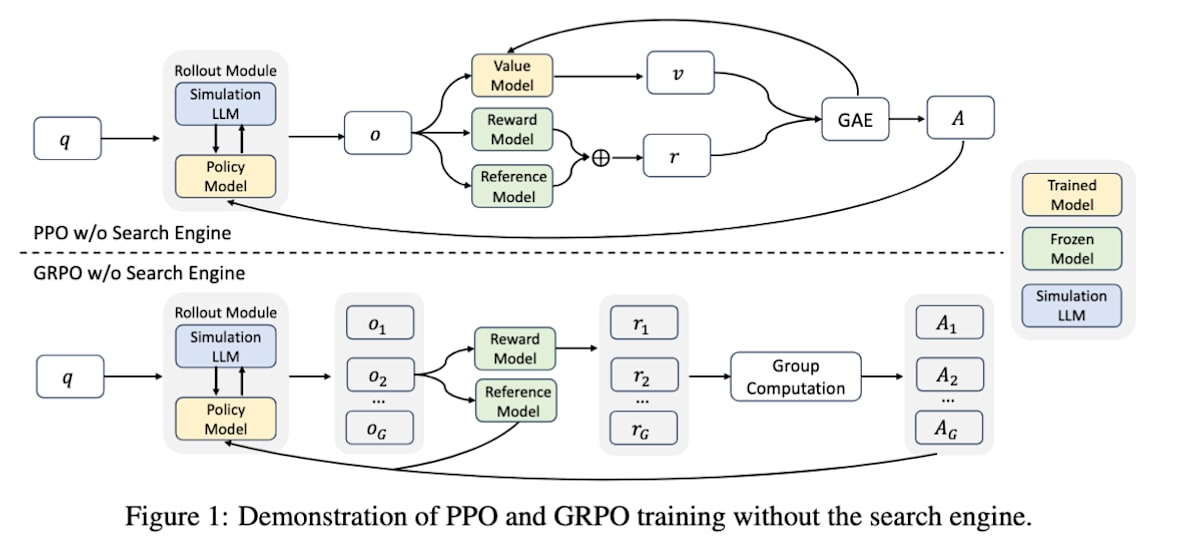
ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching (https://arxiv.org/abs/2505.04588)
代码智能体
代码智能体是指专门用于编码任务的智能体,如 OpenAI的 Codex 和 Anthropic 的 Claude Code。本文将代码智能体任务大致分为三类:单轮代码生成、多轮代码改进和软件工程自动化。本文将重点关注能够自主进行软件工程的更具挑战性的智能体研究。
软件工程是一个涉及读取、修改、添加代码,以及利用外部工具(编译器、Linter、版本控制、Shell)和通过测试验证结果等复杂且长期分步的任务。在这种场景下,智能体能力至关重要,因此利用强化学习提升智能体能力的研究正在取得进展。
SWE-RL [27] 构建了一个强化学习数据集,它从 GitHub 的 460 万个公开仓库中,按时间顺序收集了 issue、pull request 和 review comments。
这项研究的关键在于,它无需复杂的模拟器或执行环境,而是通过 Python 的 difflib.SequenceMatcher 类(用于计算字符串差异的相似度)来计算智能体生成的修正代码 patchpredpatch_{\text{pred}}patchpred 与人类编写的正确代码 patchgtpatch_{\text{gt}}patchgt 之间的奖励。这使得对海量数据进行轻量级且可扩展的强化学习成为可能。
R(τ)={−1if format is incorrectcompare(patchpred,patchgt)otherwiseR(\tau) = \begin{cases} -1 & \text{if format is incorrect} \\ \text{compare}(\text{patch}_{\text{pred}}, \text{patch}_{\text{gt}}) & \text{otherwise} \end{cases}R(τ)={−1compare(patchpred,patchgt)if format is incorrectotherwise此外,SWE-RL 还表明,尽管它仅在软件错误修复这一特定任务上进行了训练,其在训练过程中获得的推理能力却能提升在数学、通用编码和语言理解等完全不同领域的任务的性能。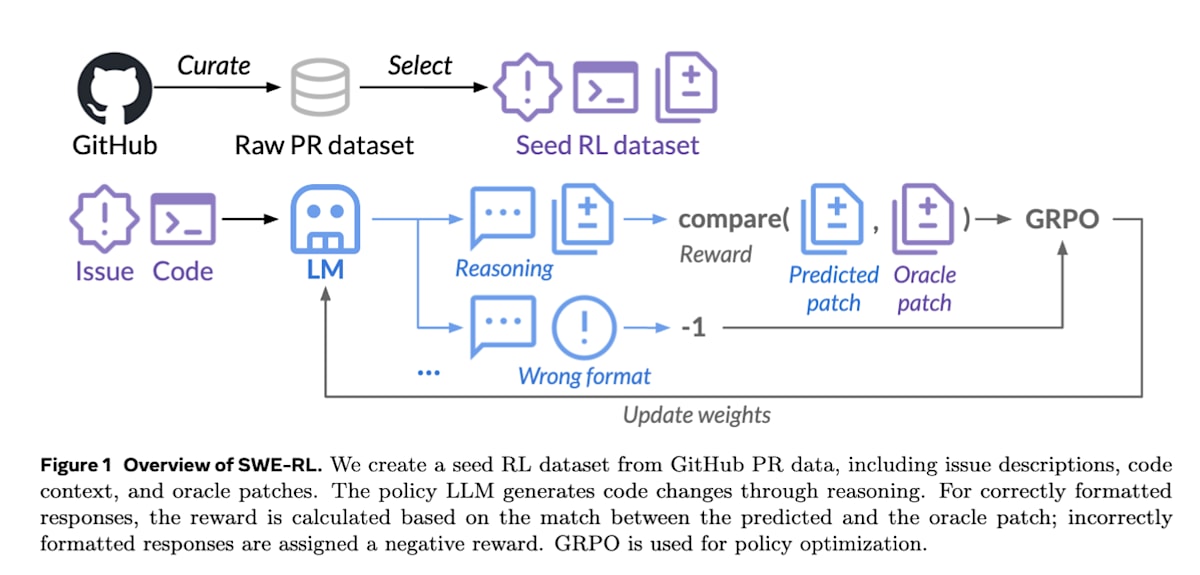
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution (https://arxiv.org/abs/2502.18449)
SWE-RL 不需要代码执行环境,而另一些研究则利用实际的代码执行环境进行强化学习。
Qwen3 Coder [28] 通过搭建代码执行环境,利用测试结果和错误信息等可验证的奖励进行强化学习,以提升编码能力。在代码执行环境方面,它利用阿里云构建了可并行执行 2 万个独立环境的系统,从而实现了大规模的强化学习。最终,它在处理软件工程任务的 SWE-Bench Verified 基准测试中,达到了开源模型中的最高水平性能。
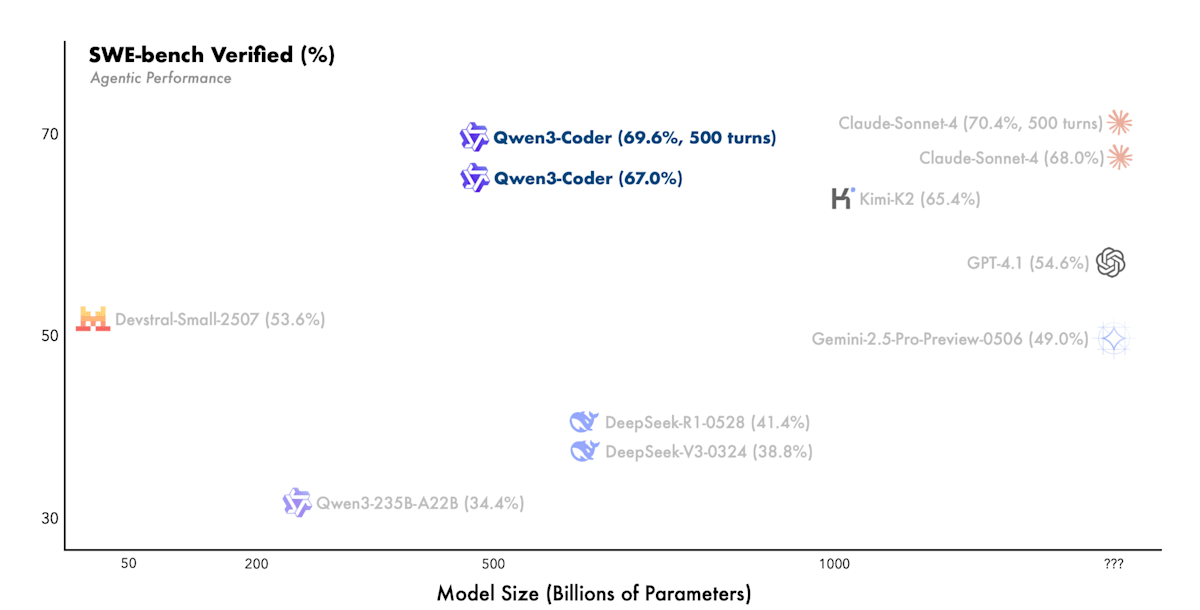 Qwen3-Coder: Agentic Coding in the World (https://qwen.ai/blog?id=d927d7d2e59d059045ce758ded34f98c0186d2d7&from=research.research-list)
Qwen3-Coder: Agentic Coding in the World (https://qwen.ai/blog?id=d927d7d2e59d059045ce758ded34f98c0186d2d7&from=research.research-list)
数学智能体
数学推理因其符号抽象性、逻辑一致性以及需要长期演绎的性质,被认为是评估 LLM 智能体推理能力的关键标准。在智能体核心能力部分介绍的许多研究中,也都关注了数学任务的性能。
rStar2-Agent [29] 针对困难数学任务,通过纯粹的 Agentic RL 方法,在没有推理数据 SFT 的情况下,以 14B 参数实现了超越 671B 的 DeepSeek-R1-Zero 的性能和学习效率。这项研究的特点在于,它像工具使用章节介绍的 ReTool 一样,利用 Python 执行环境作为工具进行工具集成型推理,并引入了一种名为 “Resample on Correct (RoC)” 的技术,即在多次 Rollout 生成的候选答案中,优先采样没有过多工具调用错误的优质成功案例进行学习。
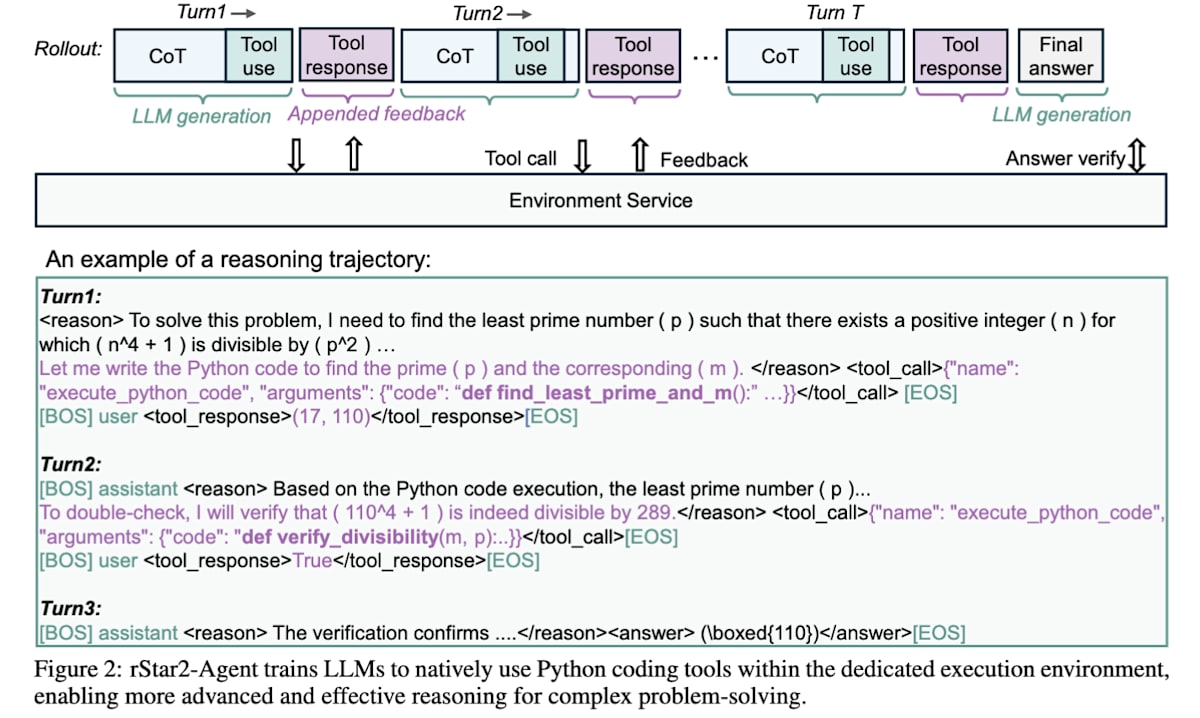
rStar2-Agent: Agentic Reasoning Technical Report (https://arxiv.org/abs/2508.20722)
1Shot-RLVR [30] 证明了仅使用一个训练示例的强化学习在提升数学推理能力方面是有效的。具体而言,它对基础模型 Qwen2.5-Math-1.5B 应用一个训练示例,就在 MATH500 基准测试中将性能从 36.0% 大幅提升到 73.6%,并在六个主要数学推理基准测试中平均从 17.6% 提升到 35.7%。这表明,即使使用少量数据,也能有效地激活 LLM 的推理能力,达到甚至超越使用数千个示例数据集时的性能。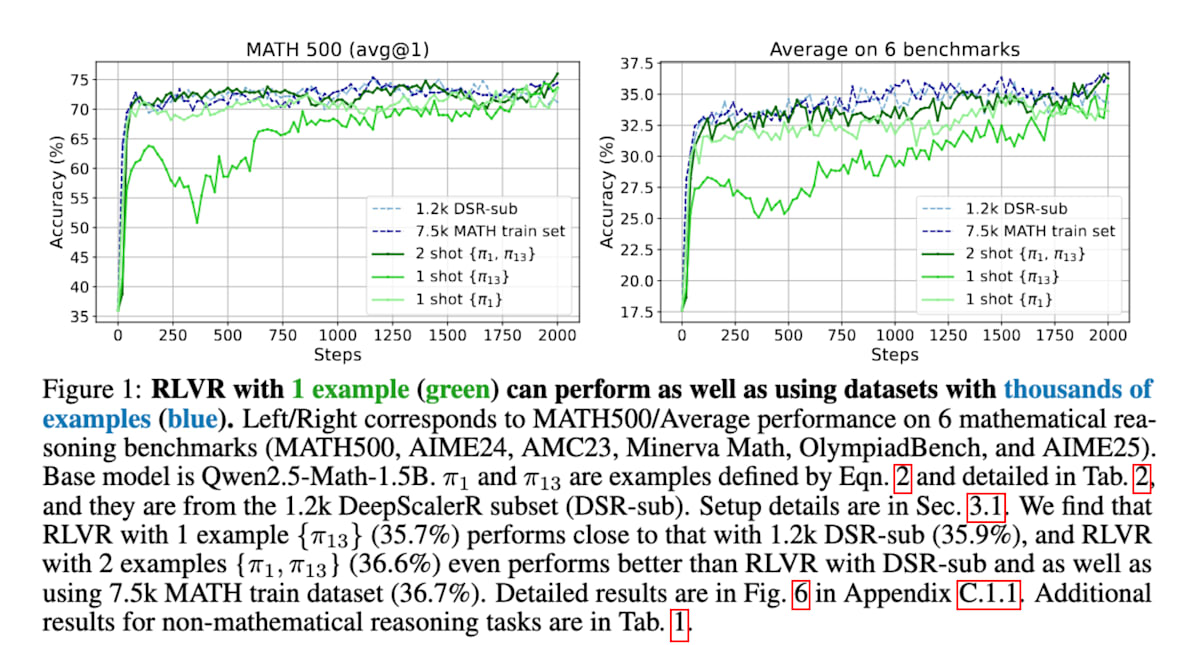
Reinforcement Learning for Reasoning in Large Language Models with One Training Example (https://arxiv.org/abs/2504.20571)
GUI 智能体
GUI 智能体是指能够自主执行网页浏览、应用程序操作等任务的智能体。研究早期,人们提出了利用视觉语言模型 (VLM) 输入屏幕截图和提示,进行单步 GUI 操作的方法。随后,又尝试了基于人类 GUI 操作记录,利用屏幕(状态)和 GUI 操作(行动)的轨迹数据进行 GUI 操作模仿学习的方法。然而,模仿学习面临着人类 GUI 操作记录数据集匮乏的挑战。在这种背景下,利用强化学习进行基于结果的学习研究正在取得进展。
UI-TARS [31] 实现了高度通用性,能够像人类一样仅凭GUI 屏幕截图信息,统一操作 OS、Web、移动应用等各种 GUI 环境。它让智能体在众多虚拟机上实际运行,自动收集新的操作数据(轨迹),并从中识别失败的操作和修正后的正确操作对。然后,利用 DPO (Direct Preference Optimization) 方法,对模型进行调优,使其能够“从失败中学习”。
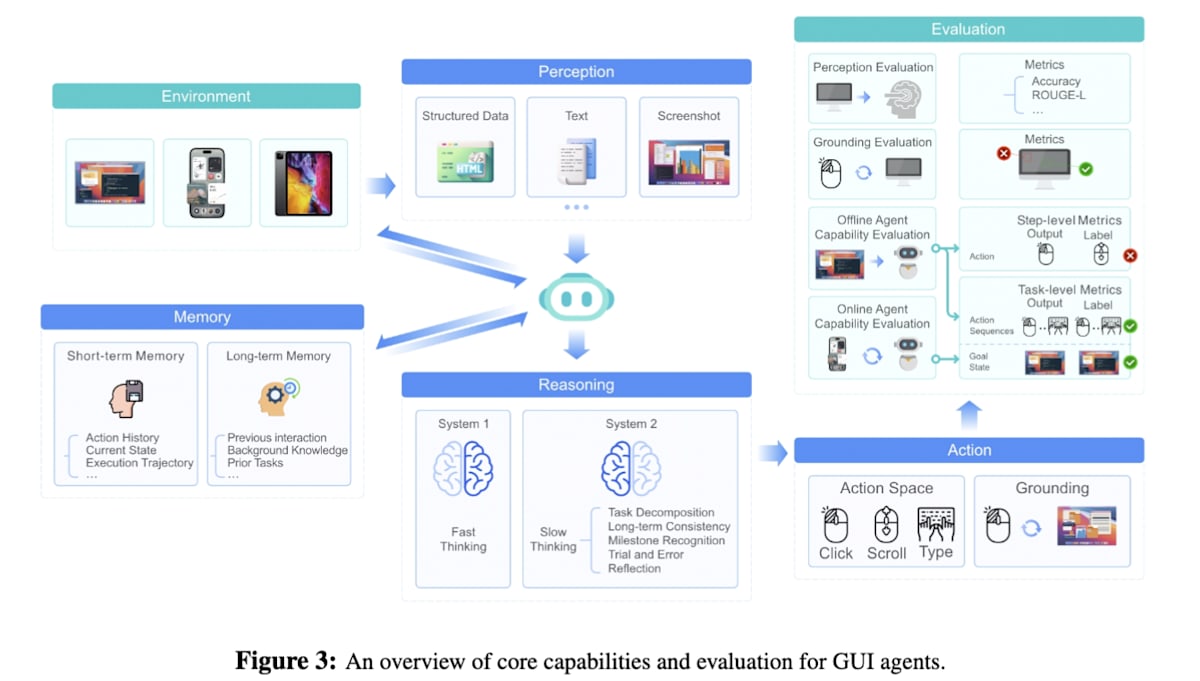
UI-TARS: Pioneering Automated GUI Interaction with Native Agents (https://arxiv.org/abs/2501.12326)
具身智能体 (Embodied Agents)
具身智能体是指像机器人一样,在物理环境中根据多模态信息执行物理行动的智能体。通常采用的方法是,通过视觉语言行动 (Vision-Language Action, VLA) 模型进行模仿学习预训练,然后将预训练模型集成到交互式智能体中,使其与环境互动,并通过强化学习提高模型在各种真实世界环境中的泛化能力。VLA框架中的强化学习主要分为两类:注重复杂环境中空间推理和移动的导航智能体,以及专注于在多样动态约束下精确控制物理对象的操作智能体。
-
导航智能体
对于导航智能体而言,规划是其核心能力。强化学习被用来增强 VLA 模型预测和优化未来行动序列的能力。通常的策略是,对 VLA 模型进行训练,使其像预训练模型一样,对每一步移动行动给予奖励。
VLN-R1 [32] 通过 SFT 和强化学习,训练一个以 RGB 视频图像为输入,输出前进、旋转等离散动作的模型。该模型一次输出 6 步的行动轨迹,并采用一种独特的奖励设计,称为时间衰减奖励 (time decay reward),即对较近期的行动给予更高的奖励。
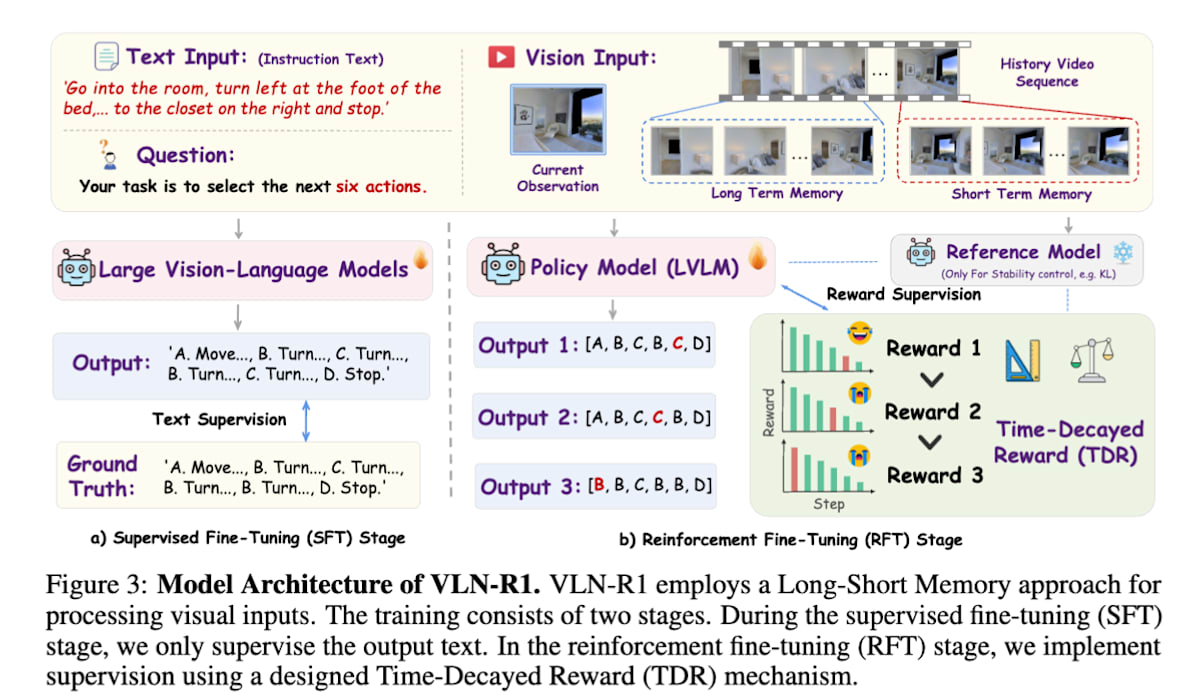
VLN-R1: Vision-LanguageNavigation via Reinforcement Fine-Tuning (https://arxiv.org/abs/2506.17221)* 操作智能体
操作智能体主要用于涉及机器人手臂的任务。强化学习被用来增强 VLA 模型的指令遵循能力和轨迹预测能力,特别是为了提高模型跨任务和环境的泛化性能。VLA-RL [33] 将机器人的一系列动作生成重新构想为人机对话。在每个时间步,机器人接收“当前视觉信息(图像)”和“人类指令(文本)”作为输入,并以语言 token 形式输出接下来要执行的行动。这使得强大的语言模型结构能够直接应用于强化学习。
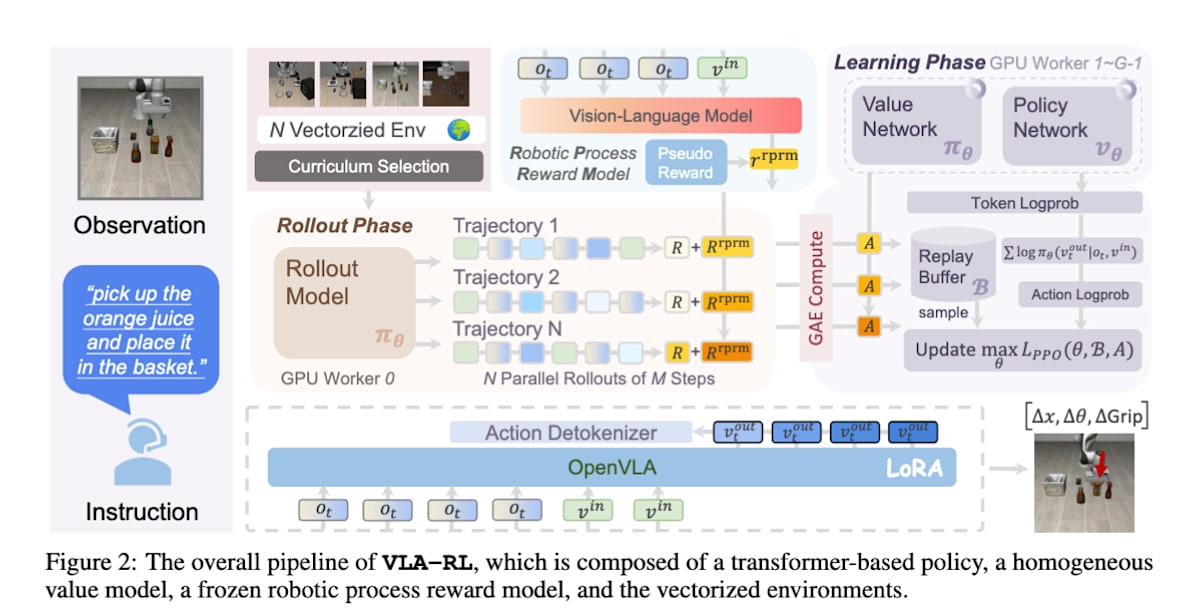
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning (https://arxiv.org/abs/2505.18719)
结语
Agentic RL 在 2025 年以来发展迅速,本文介绍的许多研究也都是在 2025 年发表的。我非常期待 Agentic RL 未来如何在进一步提升 AI 智能体性能方面发挥作用。虽然篇幅不短,但感谢各位阅读到最后。
引用
- The Landscape of Agentic Reinforcement Learning for LLMs: A Survey ↩︎
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning ↩︎
- Direct Preference Optimization: Your LanguageModel is Secretly a Reward Model ↩︎
- OpenAI o1 System Card ↩︎05. Introducing deep research ↩︎
- OpenAI o3 and o4-mini System Card↩︎
- DAPO:An Open-Source LLM Reinforcement Learning System at Scale ↩︎
- Qwen3 Technical Report ↩︎
09.ReAct: Synergizing Reasoning and Acting in Language Models ↩︎ - Toolformer: Language Models Can Teach Themselves to Use Tools ↩︎
- ReTool: Reinforcement Learning for Strategic Tool Use in LLMs ↩︎
- Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning ↩︎
- Group-in-Group Policy Optimization for LLM Agent Training ↩︎
- In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents ↩︎
- Memory-R1: Enhancing Large Language ModelAgents to Manage and Utilize Memories via Reinforcement Learning ↩︎
- MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent ↩︎
- Reasoning with Language Model is Planning with World Model ↩︎
- Agentic Knowledgeable Self-awareness ↩︎
- Absolute Zero: Reinforced Self-play Reasoning with Zero Data ↩︎
- TTRL: Test-Time Reinforcement Learning ↩︎
- Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models ↩︎
- OPENTHINKIMG: Learning to Think with Images via Visual Tool Reinforcement Learning↩︎
- Visual Planning:Let’s Think Only with Images ↩︎
- Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning ↩︎
- Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL ↩︎
- ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching ↩︎
- SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution ↩︎
- Qwen3-Coder: Agentic Coding in the World ↩︎
- rStar2-Agent: Agentic Reasoning Technical Report ↩︎
- Reinforcement Learning for Reasoning in Large Language Models with One Training Example↩︎
- UI-TARS: Pioneering Automated GUI Interaction with Native Agents ↩︎
- VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning ↩︎
- VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning ↩︎