数据库--联合查询
前言
在上节的博客中,我们讲解了数据库约束和表的设计,在了解和掌握这两节的知识点后,我们就可以开始更复杂的查询操作,在面试的时候,HR问到就不怕了。废话不多说,开始我们的讲解。
1.聚合查询
MySQL中内置的一些函数,
聚合函数本质上是针对数据表中的行和列进行运算。
| 函数 | 说明 |
| COUNT | 返回查询到的数据的数量(统计记录的行数) |
| SUM | 返回查询到的数据的总和,不是数字没有意义 |
| AVG | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN | 返回查询到的数据的最小值,不是数字没有意义 |
1.1COUNT():统计所有的行
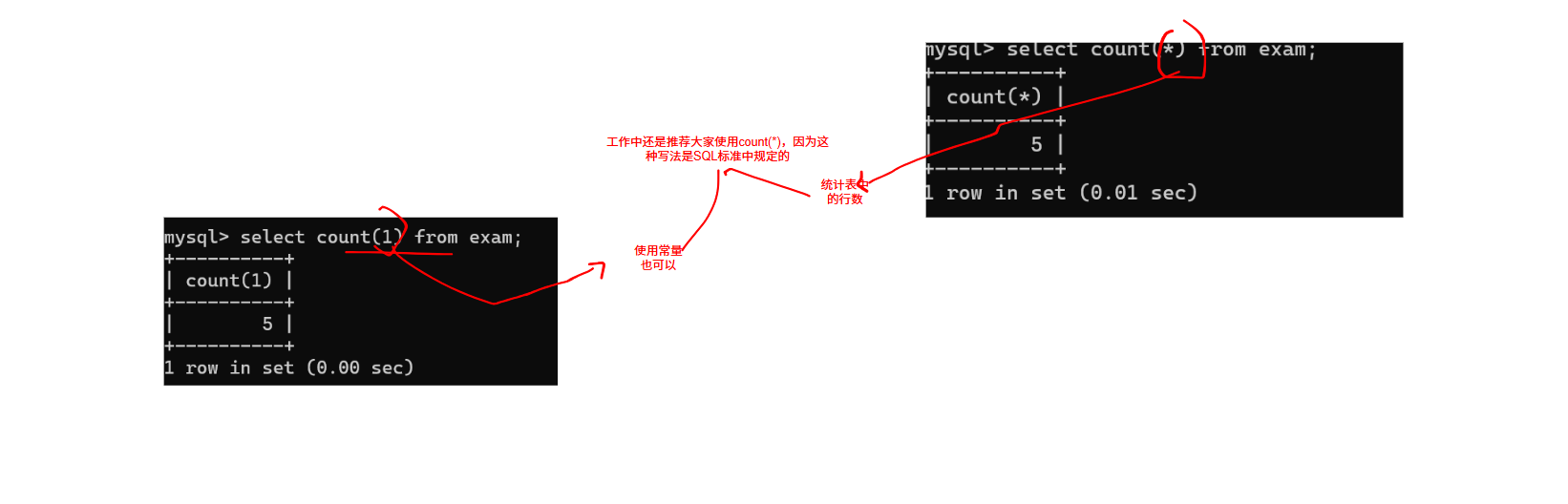
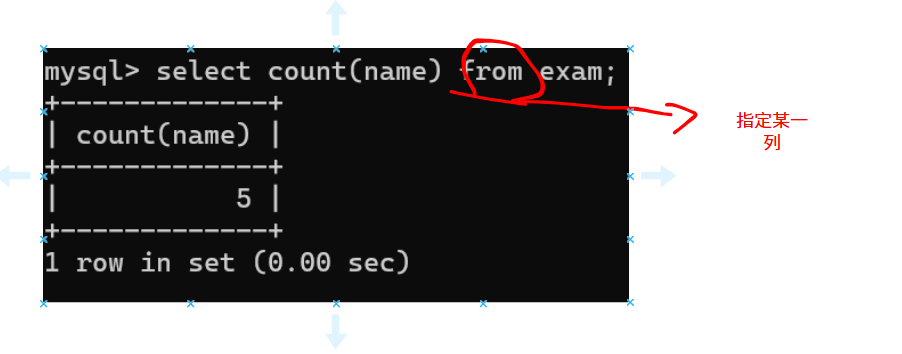
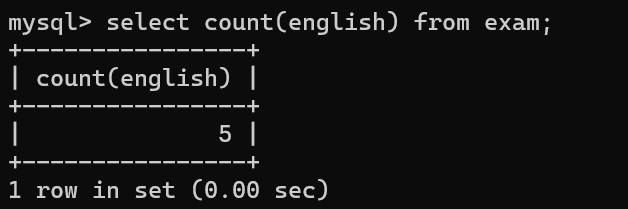
count(列名),如果说列中有null值,则不会被统计在内。
2.SUM(列名) 求和
把查询结果中所有行中的指定列进行相加,
注意:列的数据类型必须是数值型,不能是字符或日期……
示例:计算所有同学的语文成绩
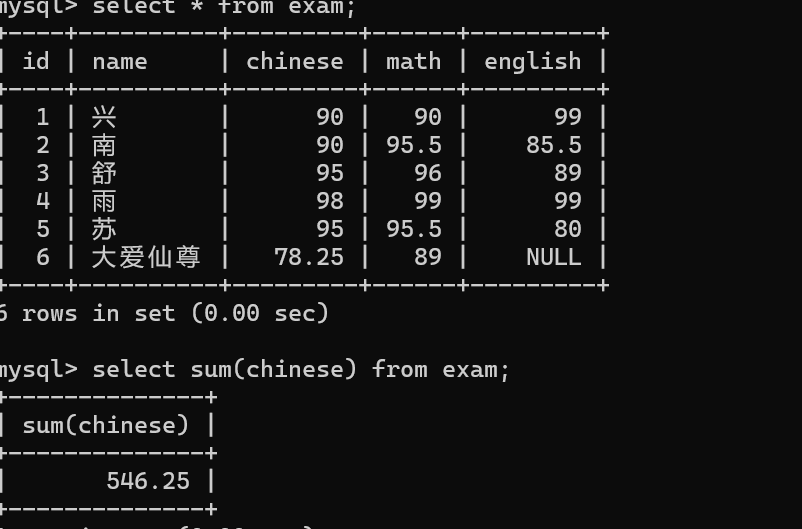
sum(chinese)结果在一个临时表中,结果不受表中字段长度约束。
在SUM()求和时,NULL值不参与运算。
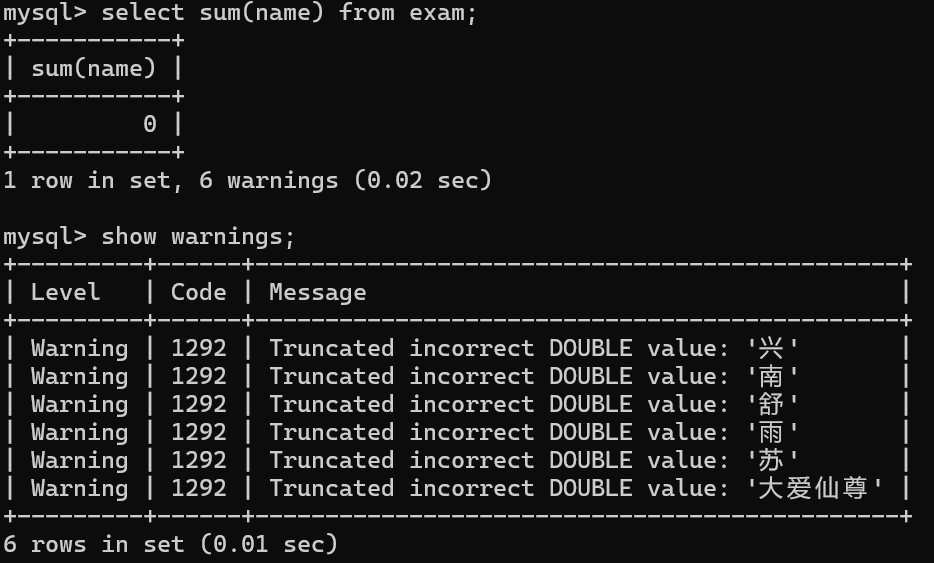
如果对非数值类型的列进行运算,会得到一些警告信息。
3. AVG()
对所有行的指定列进行平均值运算。
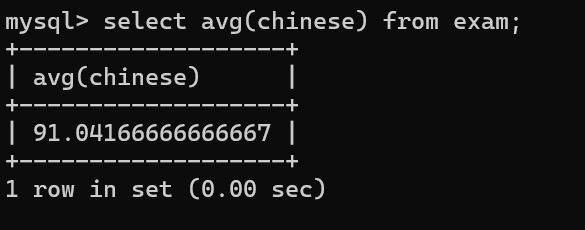
1.对所有同学的语文成绩求平均值。
2.求语文、数学、英语三门课的总分的平均值。
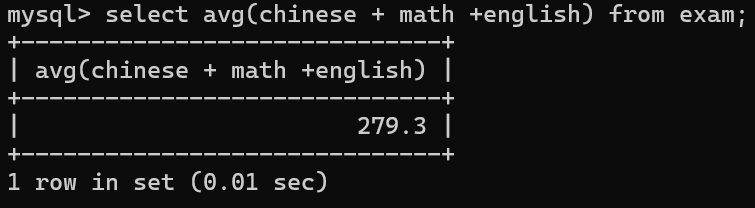
avg()括号中的参数可以是表达式。也可以使用别名

4.MAX()、MIN()
求所有行中指定列的最大值、与最小值
1.找出语文成绩的最高分段和英语成绩的最低分
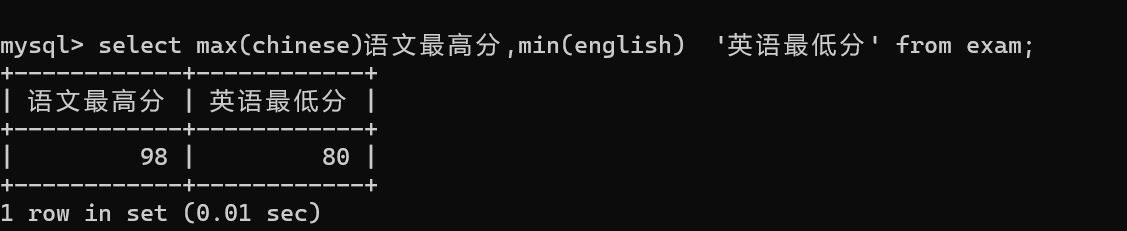
多个聚合函数可以同时使用
2.查找出语文成绩的最高分和最低分
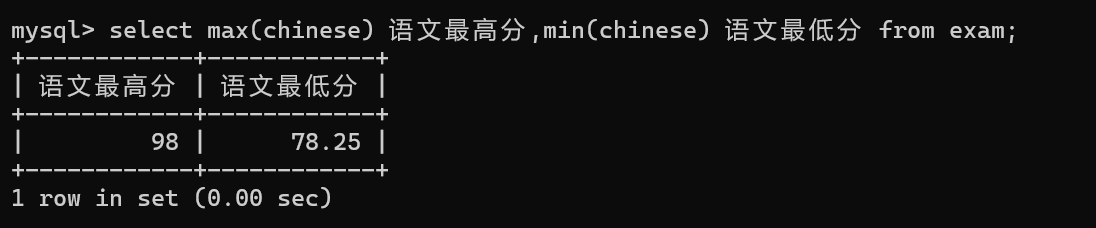
在使用关于运算的聚合函数时,不要用在非数值列上,比如说sum(),avg(),max(),min()。
5.GROUP BY
分组查询
SELECT 中使用GROUP BY 子句可以对指定列进行分组查询,需要满足:使用GROUP BY 进行分组查询时,SELECT指定的字段必须时“分组依据字段”,其他字段若想出现在SELECT中必须包含在聚合函数中。
没有指定分组的字段,呈现时要通过聚合函数 比如求和、平均。
语法: select colum1(分组的别名),sum(colum2)(没有被分组的列(需要运算的列),但是要显示结果,那么就要用到聚合函数)
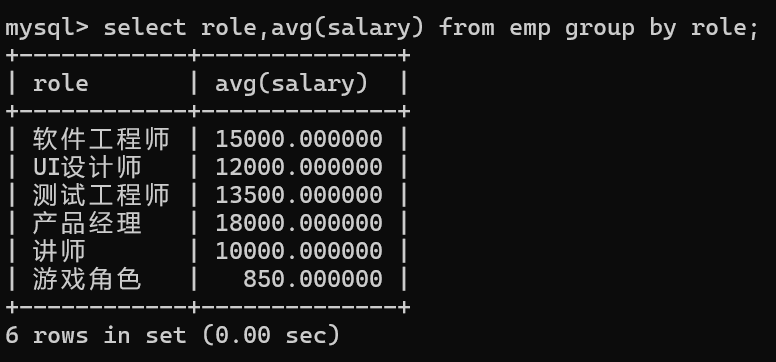
1.计算不同角色工资的平均值
要分组的时role列
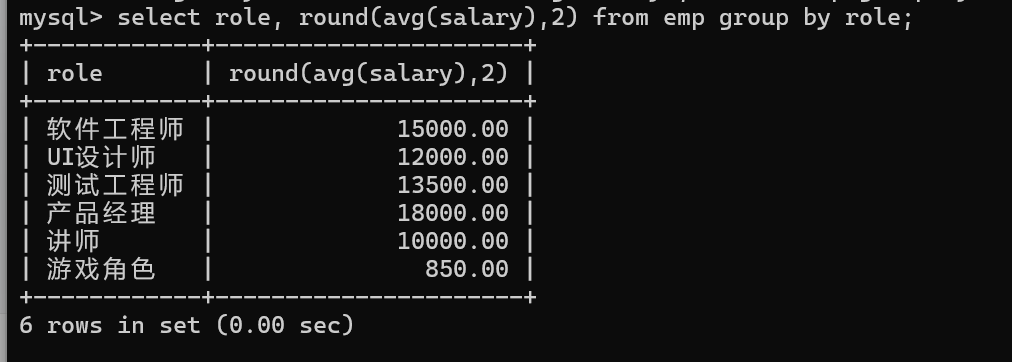
ROUND(数值,小数点位数)
group by之后可以跟 order by子句
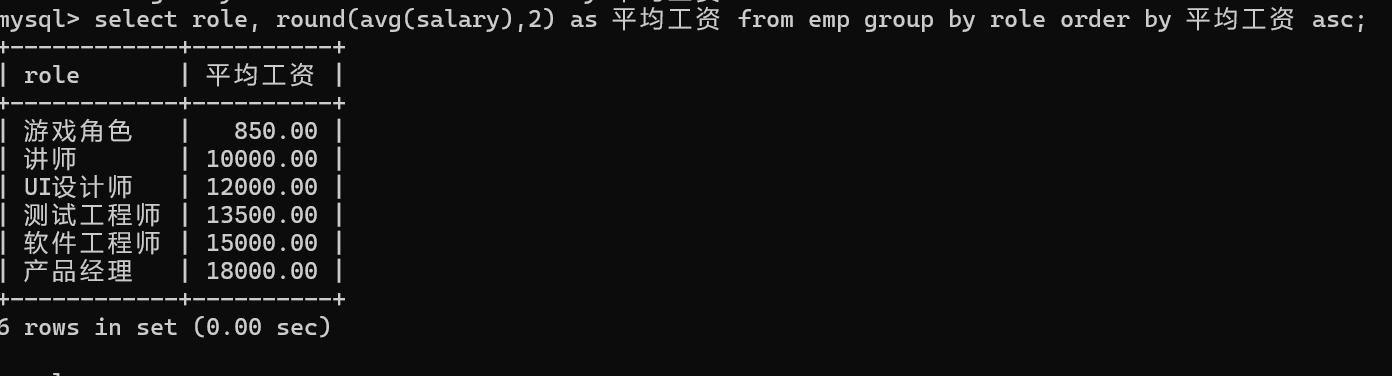
问题:对分组之后的结果进行过滤,比如说 找出平均工资大于1万,小于3万的角色
HAVING
GROUP BY 子句在进行分组以后,需要对分组结果进行条件过滤时,不能使用WHERE语句,而需要用HAVING。
where 是对表中每一行的真实数据进行过滤的。
having 时对group by之后,计算出来的结果进行过滤的。
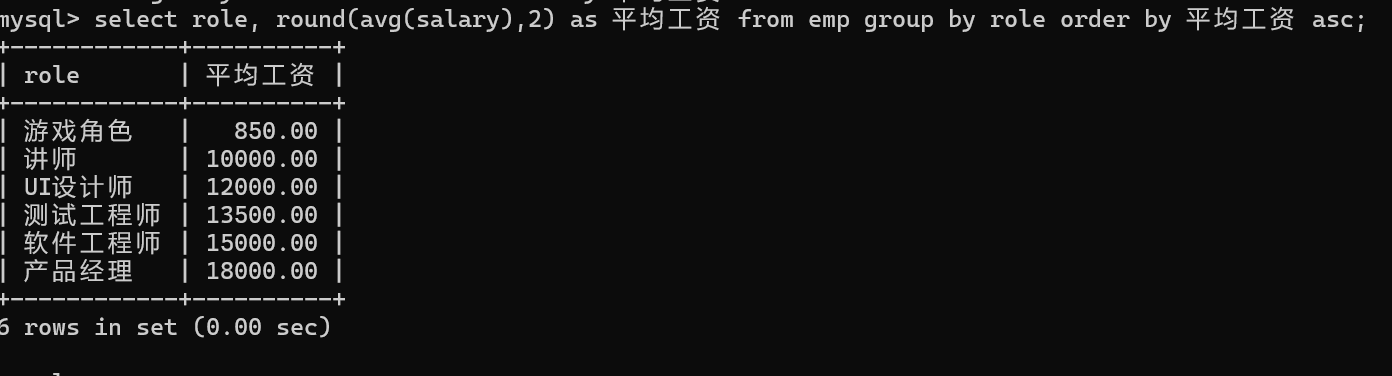
having可以把这个结果集中的数据进行过滤操作,平均工资这些数据并不是表中整正记录,
而是通过聚合函数计算的出来的。
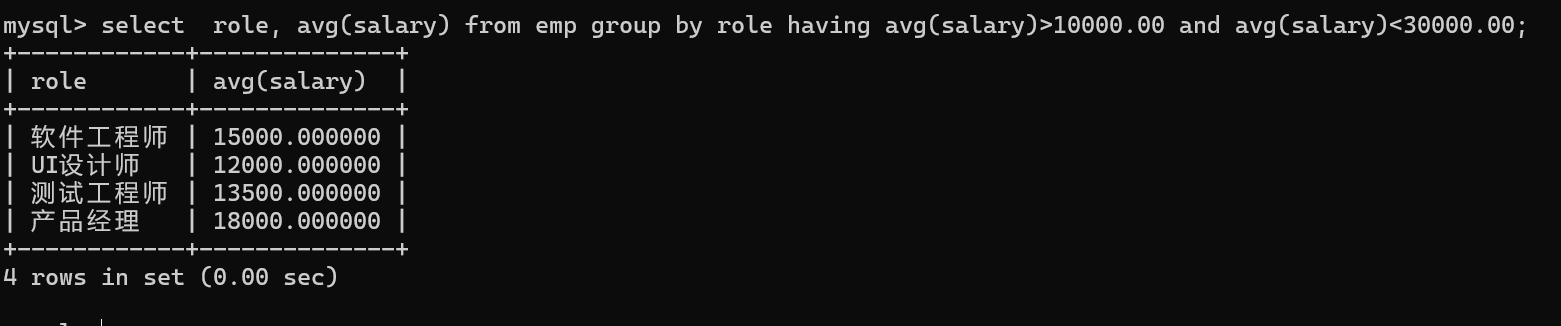
having是跟在group by 子句之后,对分组后的结果进行过滤。
where 用在from表名之后,也就是分组之前,
having跟在group by子句之后。
如果需要对真实数据进行过滤,同时也需要对分组的结果进行过滤,
那么在合适的位置写入where和having即可。
查询每个角色的最高工资、最低工资和平均工资
1.按角色分组
2.使用相应的聚合函数
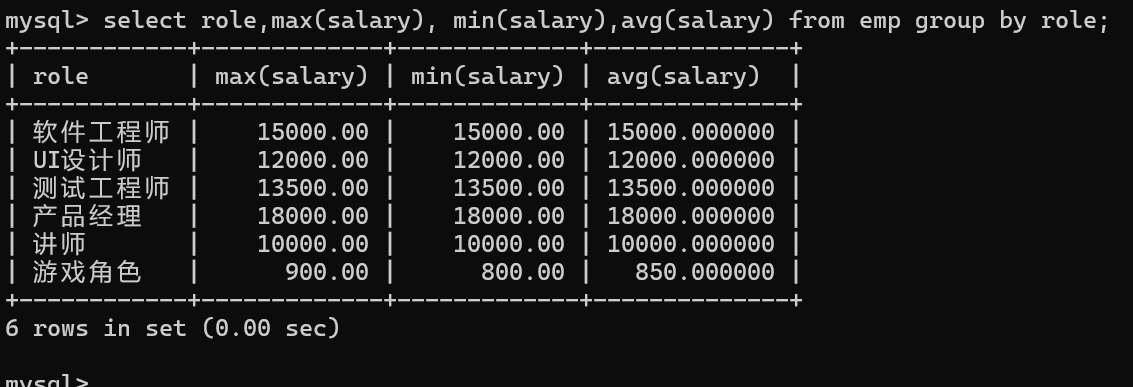
显示平均工资低于12000.00的角色和它的平均工资
1.按角色分组,
2.使用相应的聚合函数,
3使用having子句对分组的结果进行过滤。

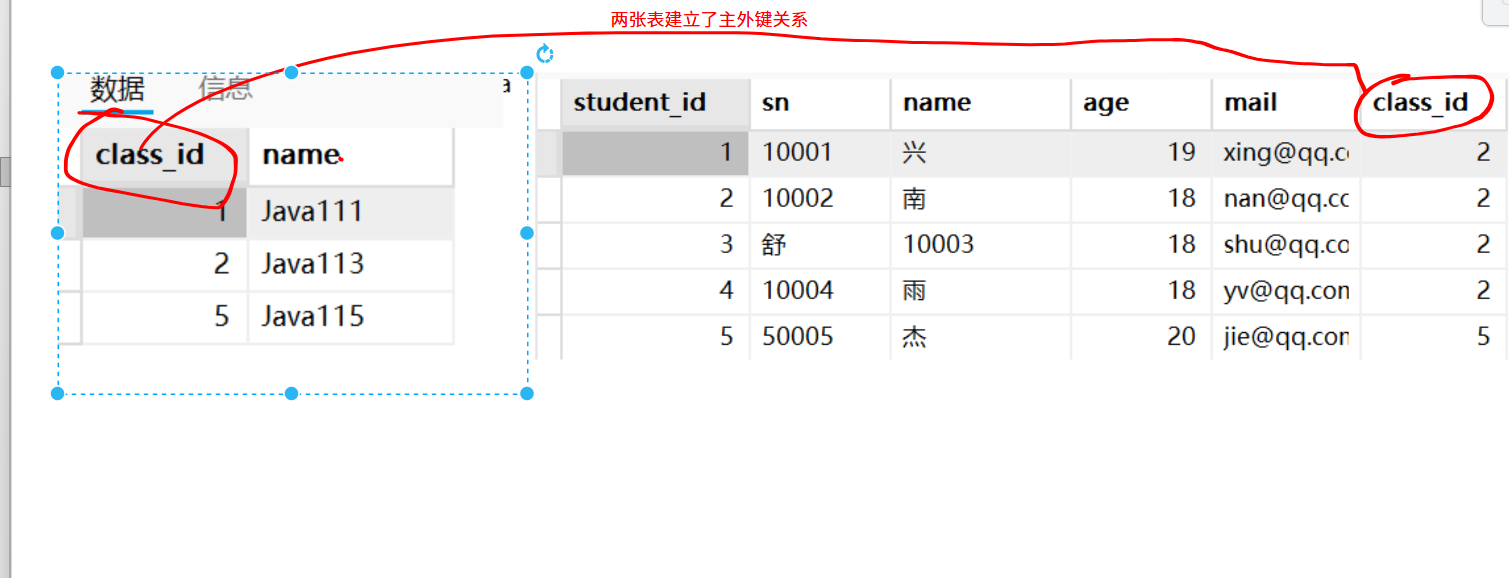
联合查询
工作中用的最多的查询,而且面试的时候也非常爱考,因为MySQL没啥考的难点,联合查询在SQL中稍微复杂。
联合多个表进行查询
设计数据时把表进行拆分,为了消除表中的字段的依赖关系,比如部分函数依赖、传递依赖,
这时会导致一条SQL查出来的数据,对于业务来说是不完整的,我们就可以使用联合查询把关系中的数据全部查出来,在一个数据行中显示详细信息。
联合查询时MySQL是如何执行的?
1.取多张表的笛卡尔积
对多张表进行笛卡尔积的工程:
1.先从第一张表中取一条记录,然后再与第二张表中的第一条记录进行组合,生成一条新的记录。
2.先从第一张表中取一条记录,然后再与第二张表中的第一条记录进行组合,生成一条新的记录。
……
最后得到的结果就是一个全排列结果集。
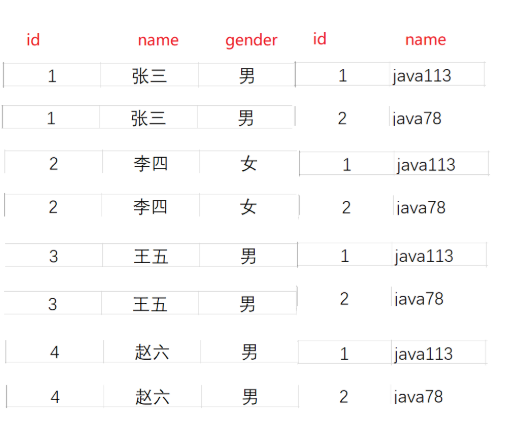
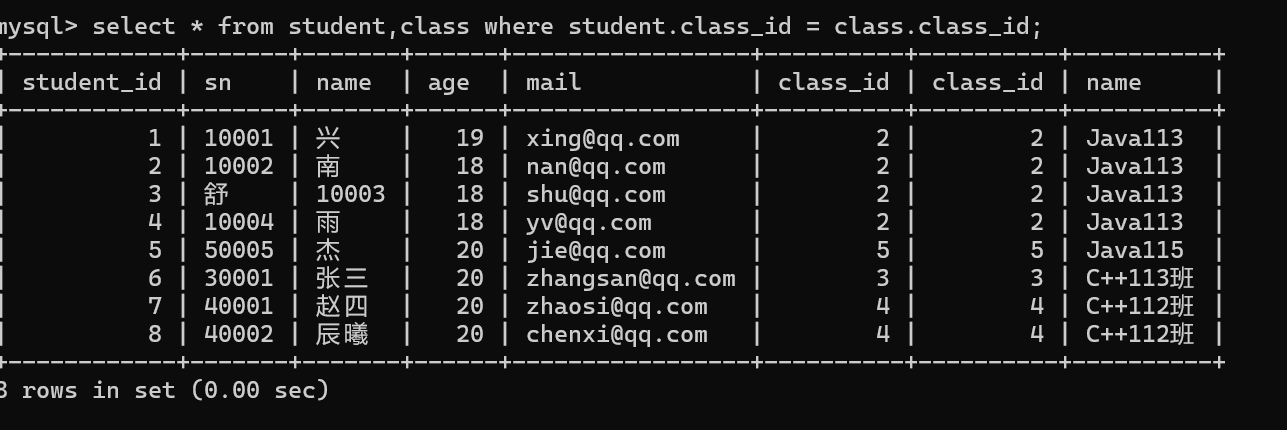
语法:select * from 表名,表名;
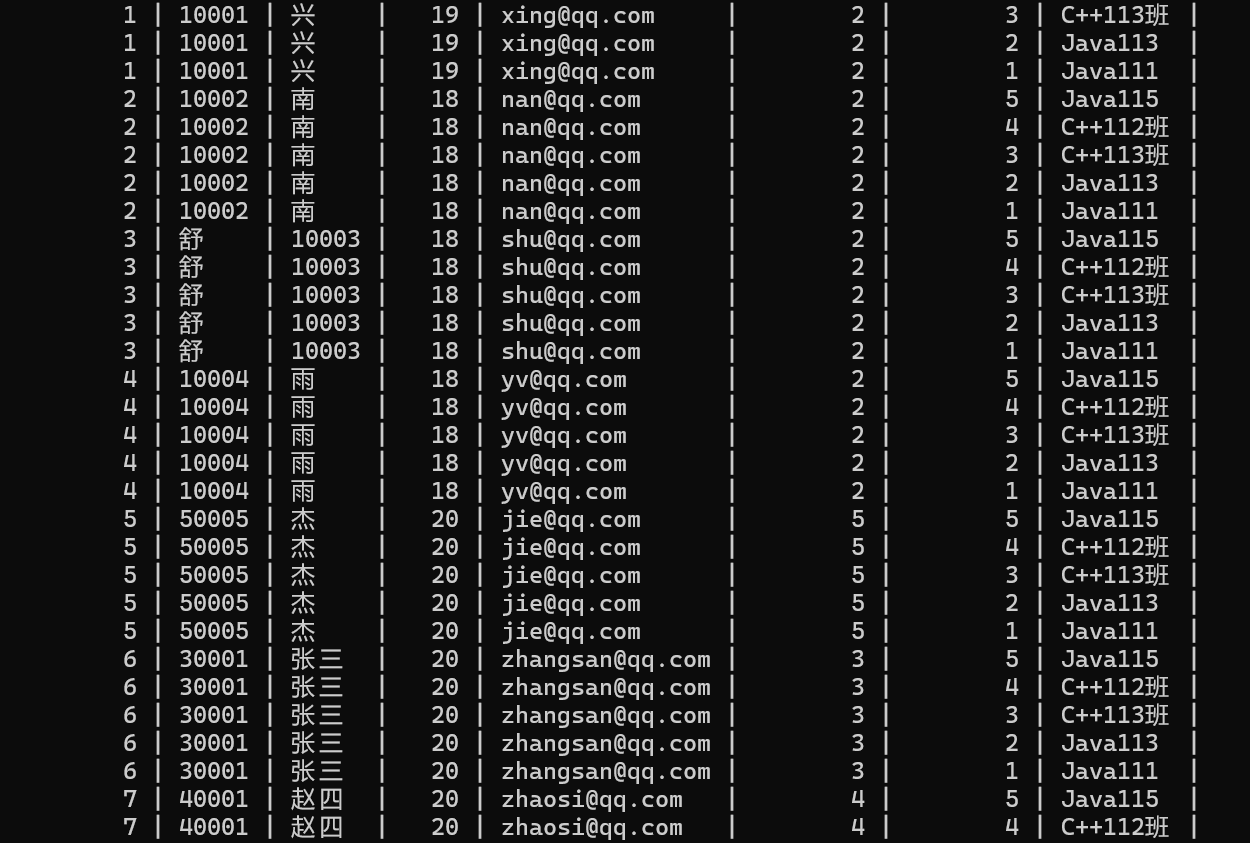
通过观察,两张表取笛卡儿积之后,有些数据是无效数据。
如何去过滤掉这些无效数据?
2.通过连接条件过滤掉无效数据
两个表之间是有主外键关系,只需要判断两个表中主外键字段是否相同即可。

出错的原因是class_id 在两张表中都存在,MySQL分不清当前语句中的class_id应该来自哪张表
可以通过表名.列名的方式来解决这个问题。
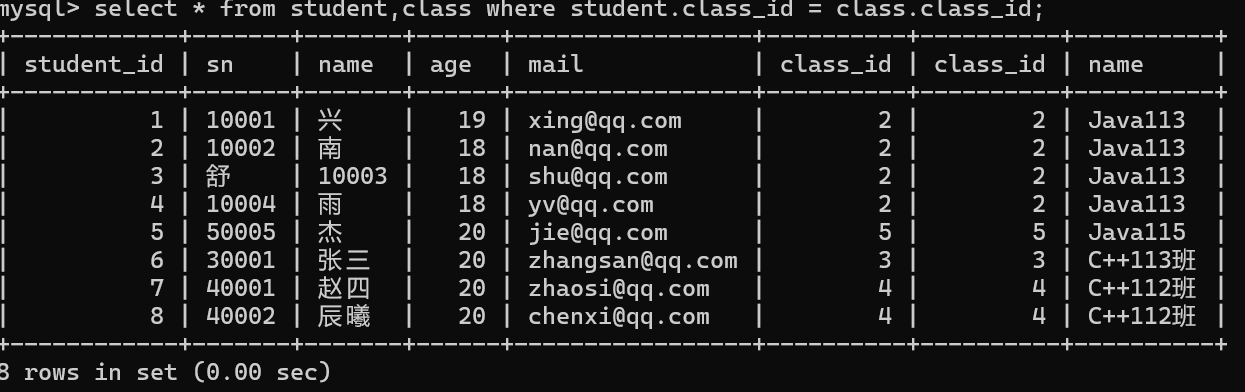
3.通过指定列查询,来精简结果集
查询列表通过表名.列名的方式指定要查询字段。
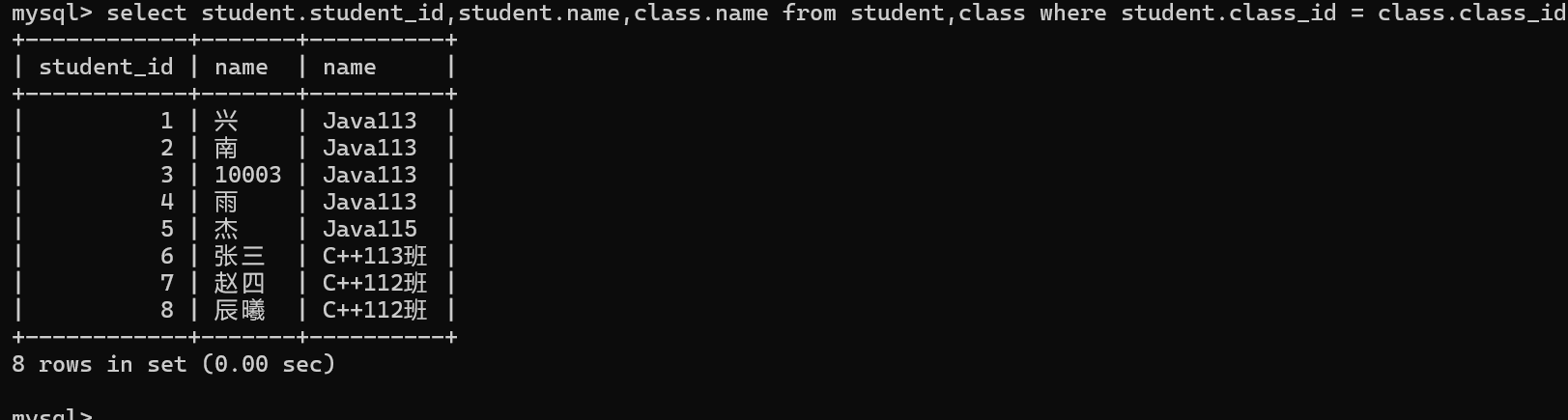
通过个给表名起别名的方式来简化SQL语句。
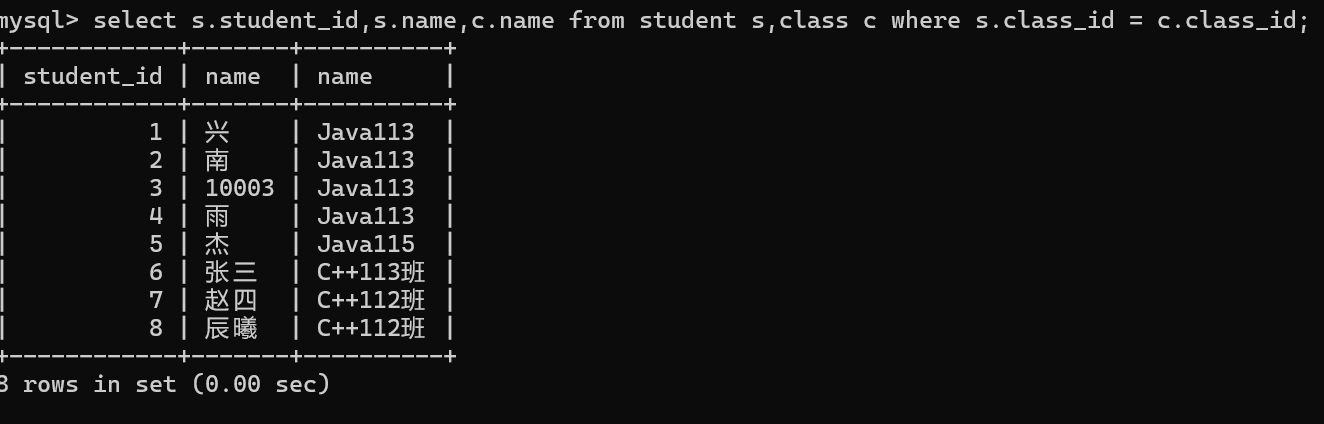
联合查询也叫表连接查询
1.首先确定哪几张表要参与查询。
2.根据表与表之间的主外键关系,确定过滤条件。
3.精简查询字段,得到想要的结果。
在工作中尽量使用联合查询。
内连接
语法:
1.select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;(标准内连接的写法)
2.select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
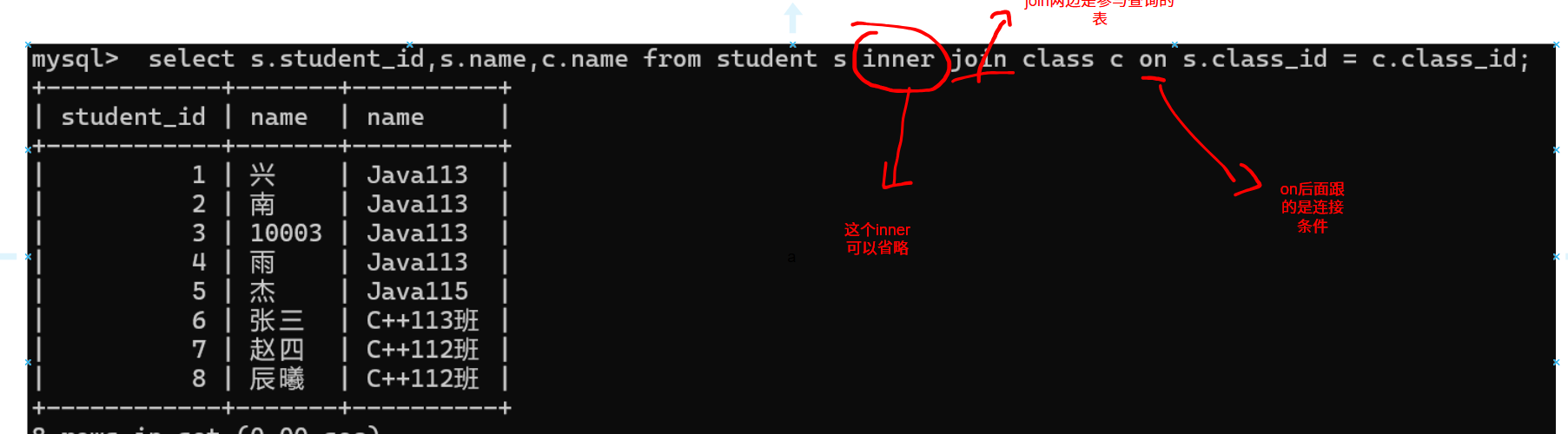
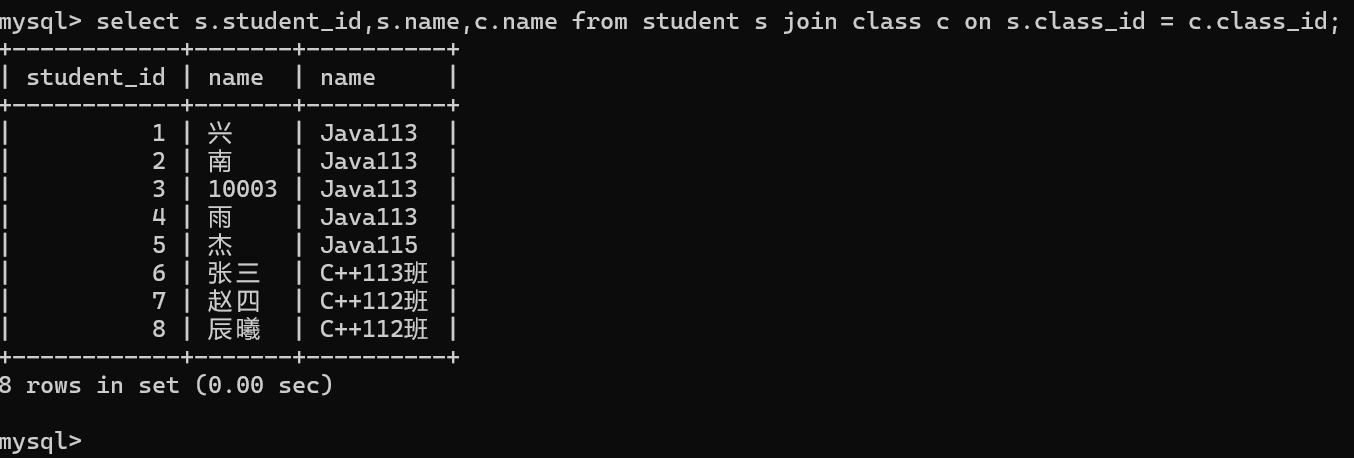
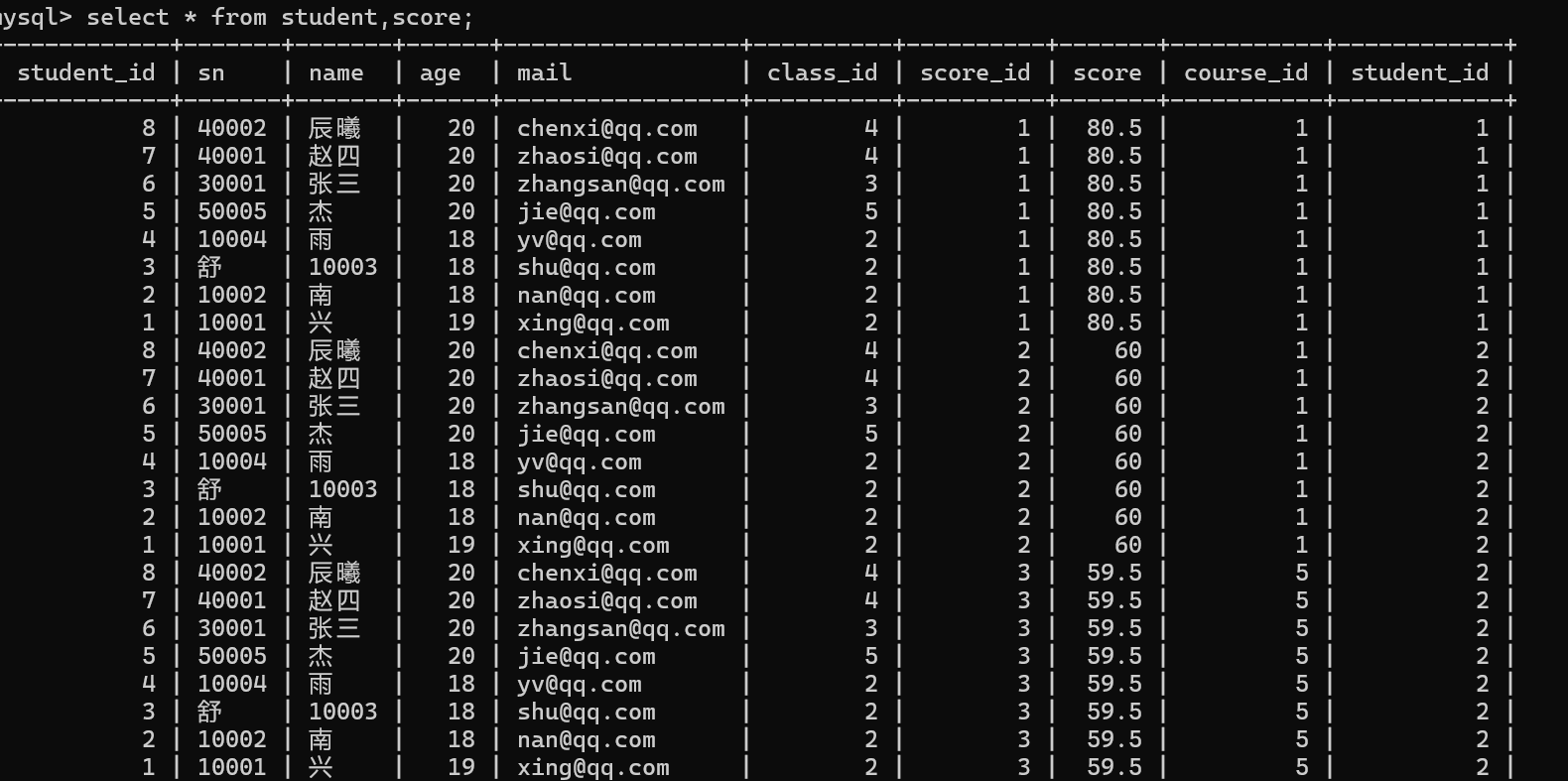
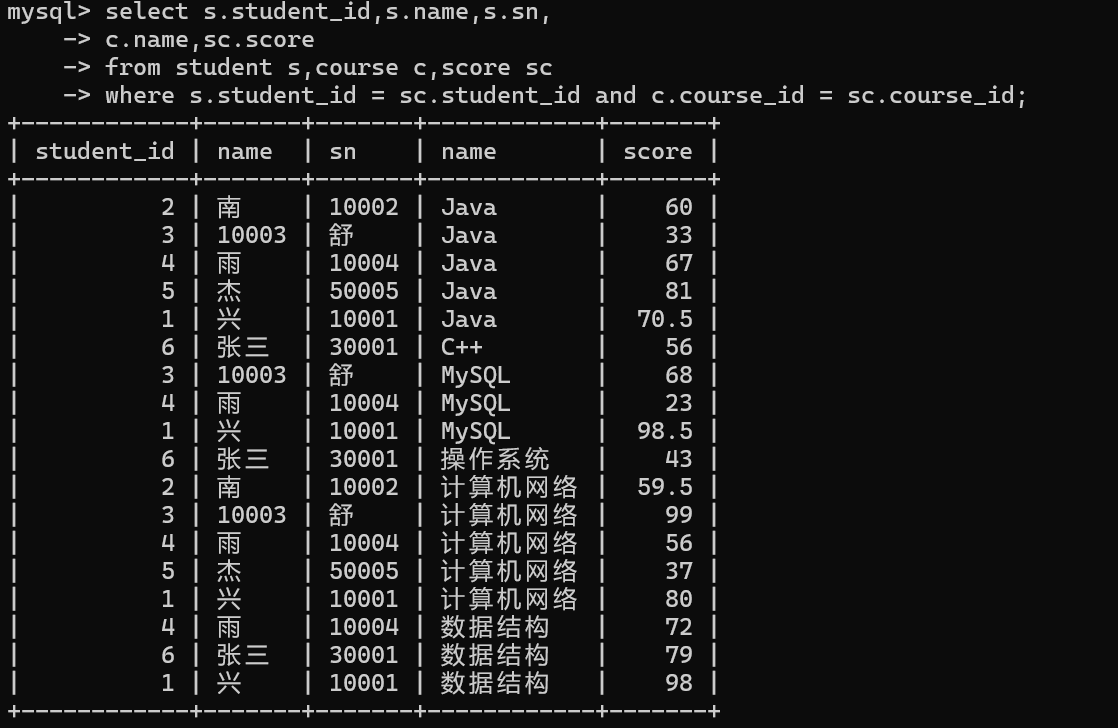
1.查询兴同学的成绩
1.首先确定那几张表要参与查询
成绩表,学生表
取这两张表的笛卡尔积
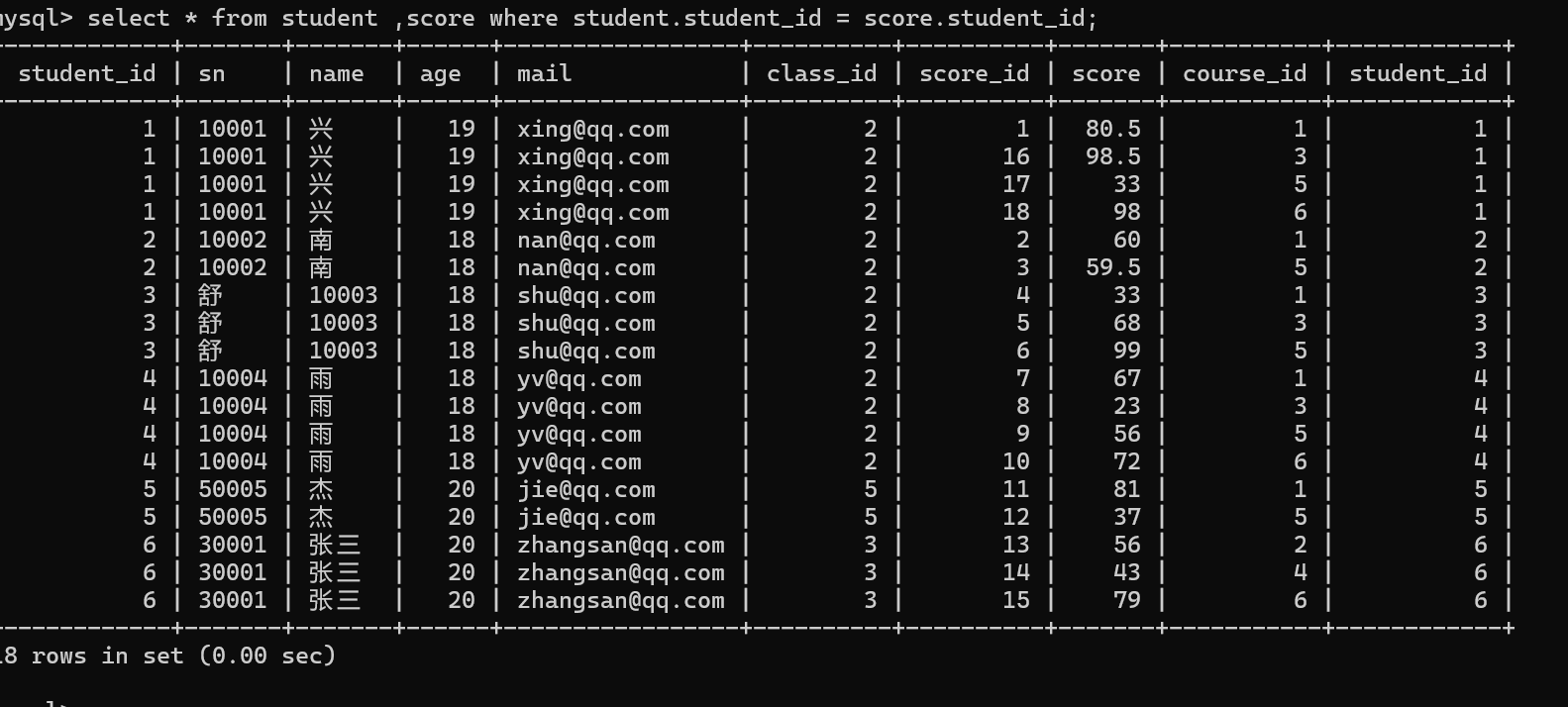
2.根据表与表之间的主外键关系,确定过滤条件
两张表中通过student_id 作为主外键关联字段
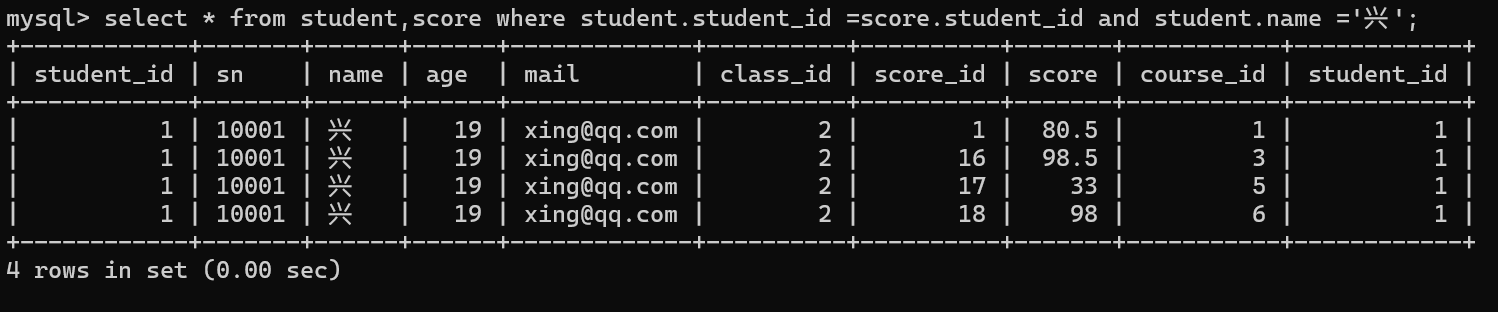
确定结果集的过滤条件
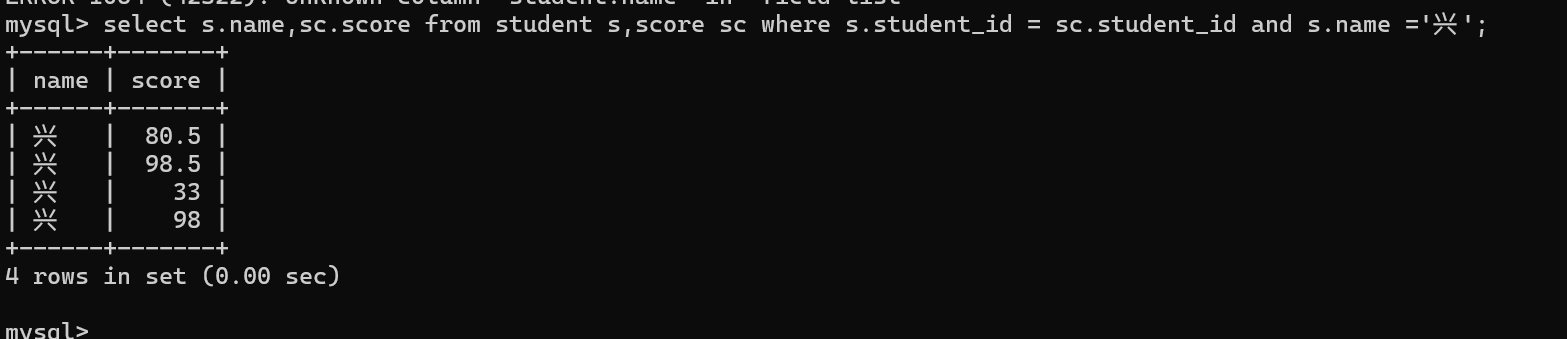
3.精减列表中的字段
联合查询步骤
1.确定查询中涉及到哪些表
2.对目标表取笛卡尔积(到后面熟练后,课跳过这一步)
3.确定连接条件
4.确定对整个结果集的过滤条件
5.精减查询字段
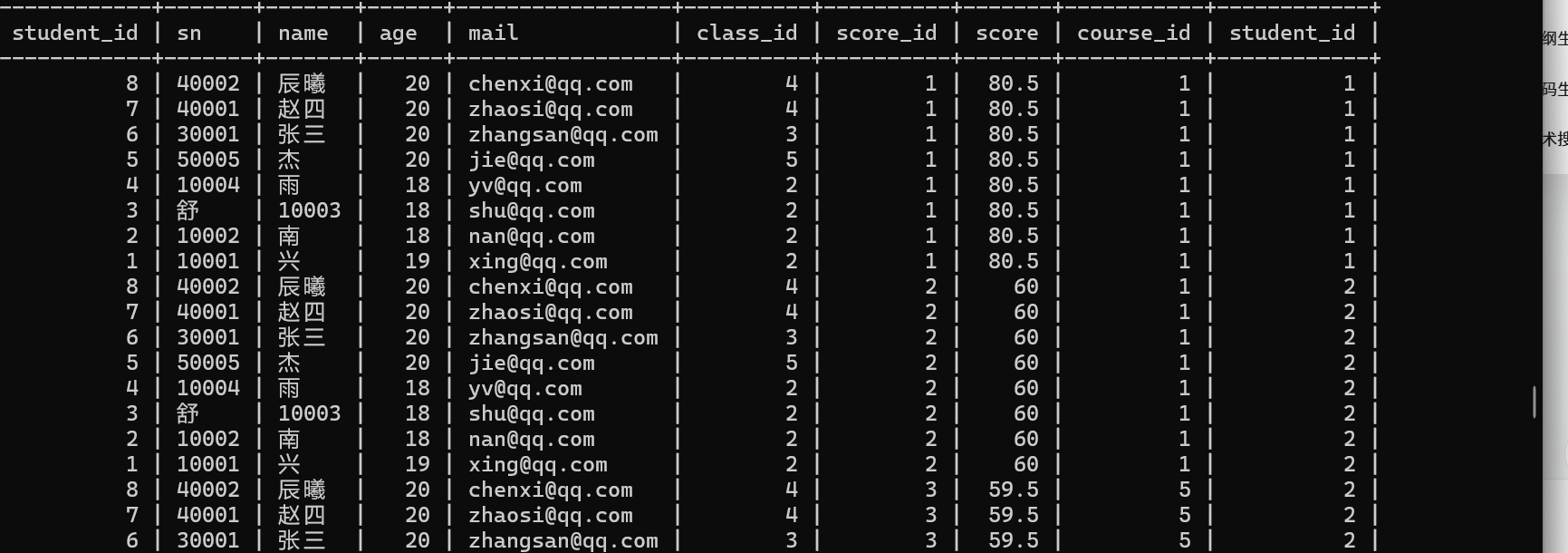
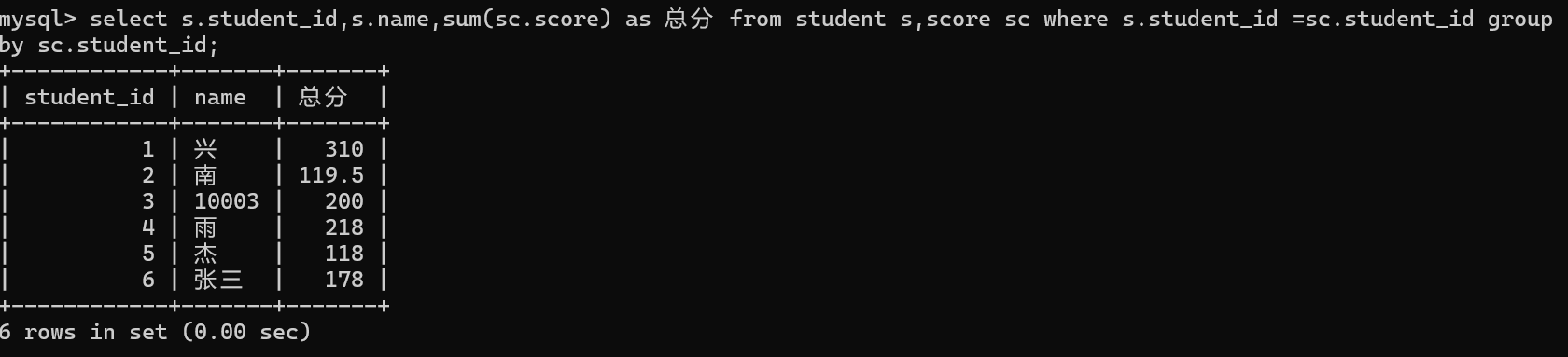
(2)查询所有同学的总成绩
1.确定查询中涉及到哪些表
学生表和成绩表
总成绩要用分组查询 group by
2.对目标表取笛卡尔积
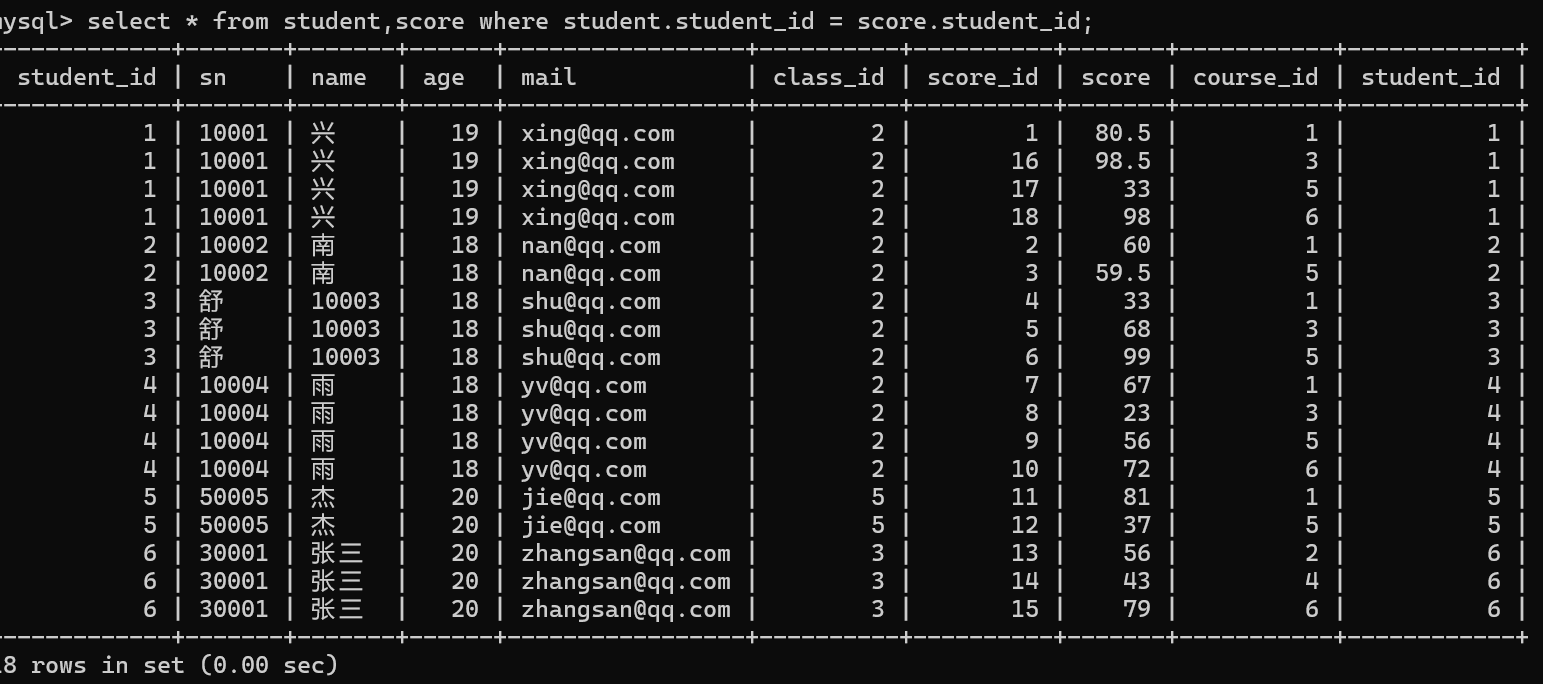
3.确定连接条件
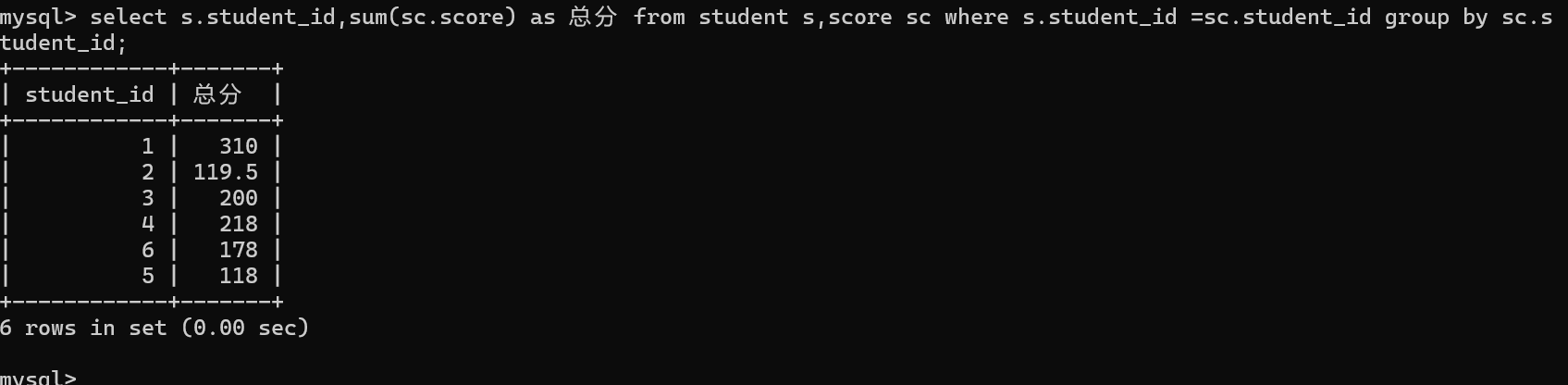
4.确定对整个结果集的过滤条件
5.精减查询字段
外连接
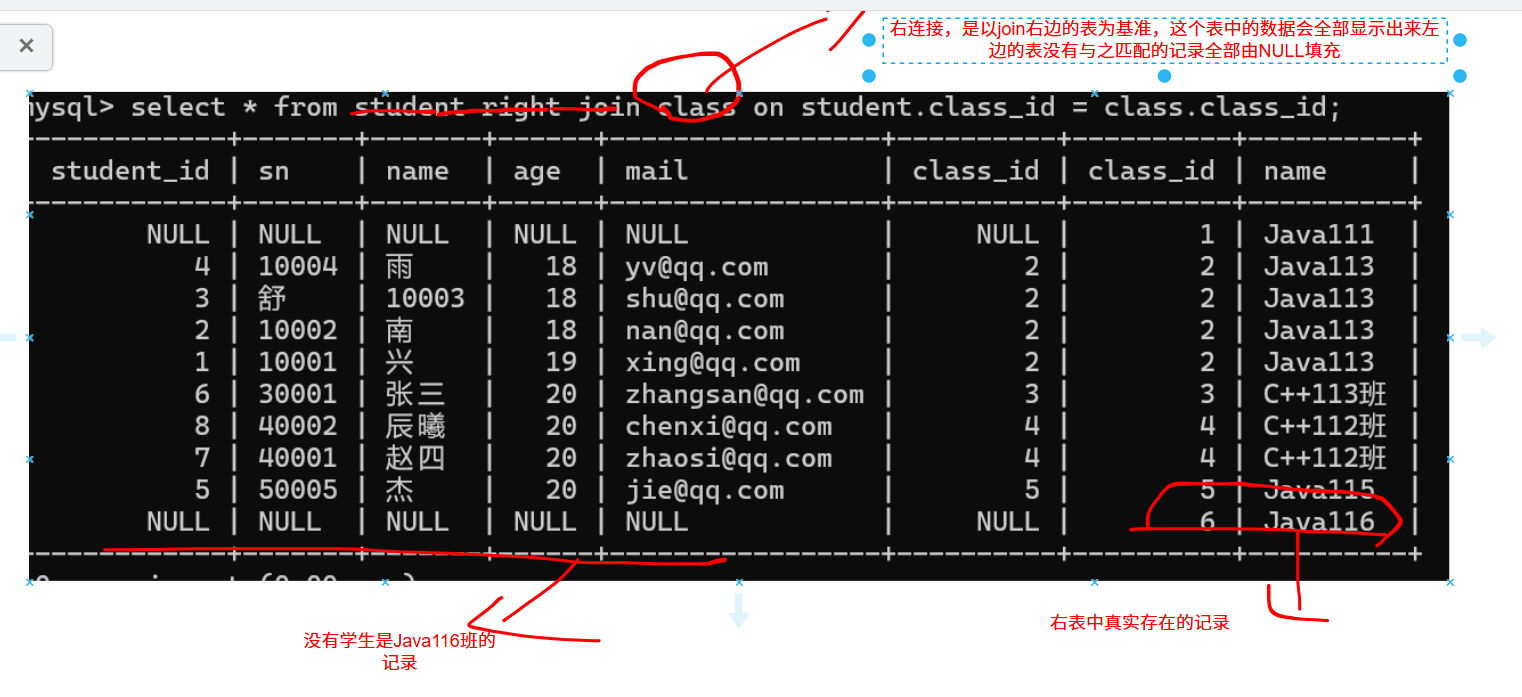
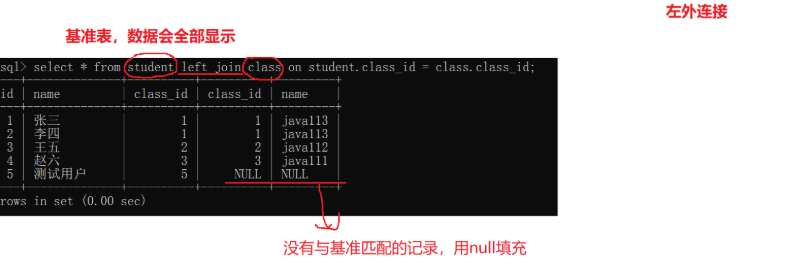
外联接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
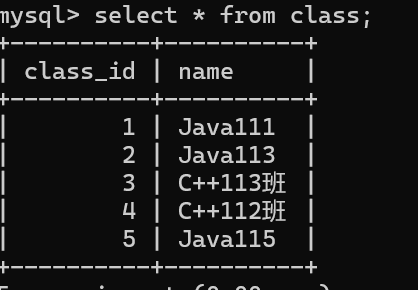
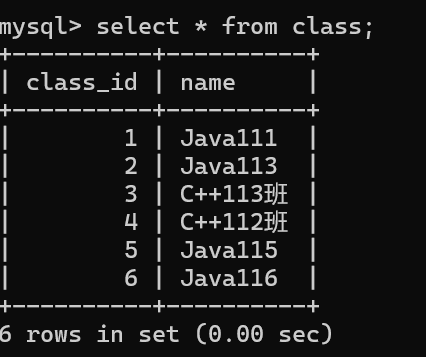
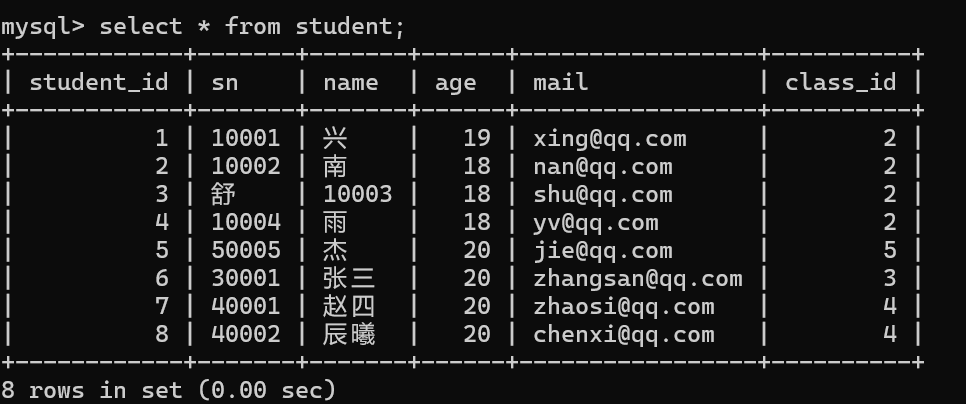
当前学生表中的记录,并没有一个学生的班级是Java116班
使用内连接时并没有Java116班的数据。
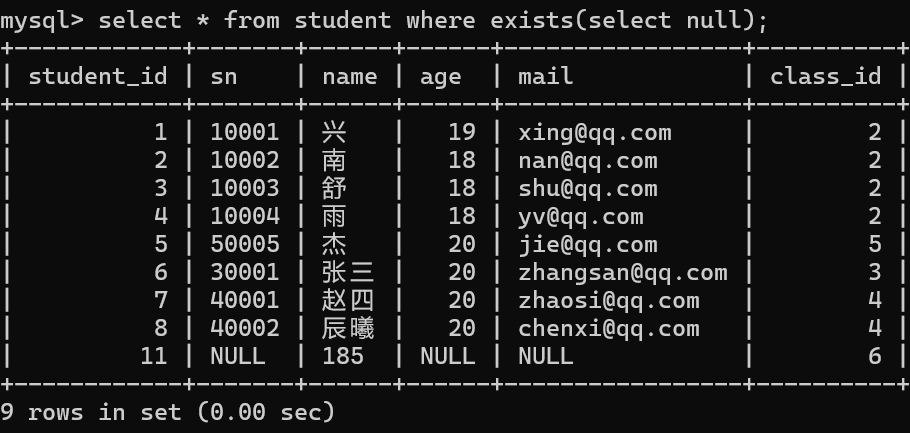
查询哪位同学没有成绩
1. 在同学表中有记录
2.在分数表中没有该同学对应的记录
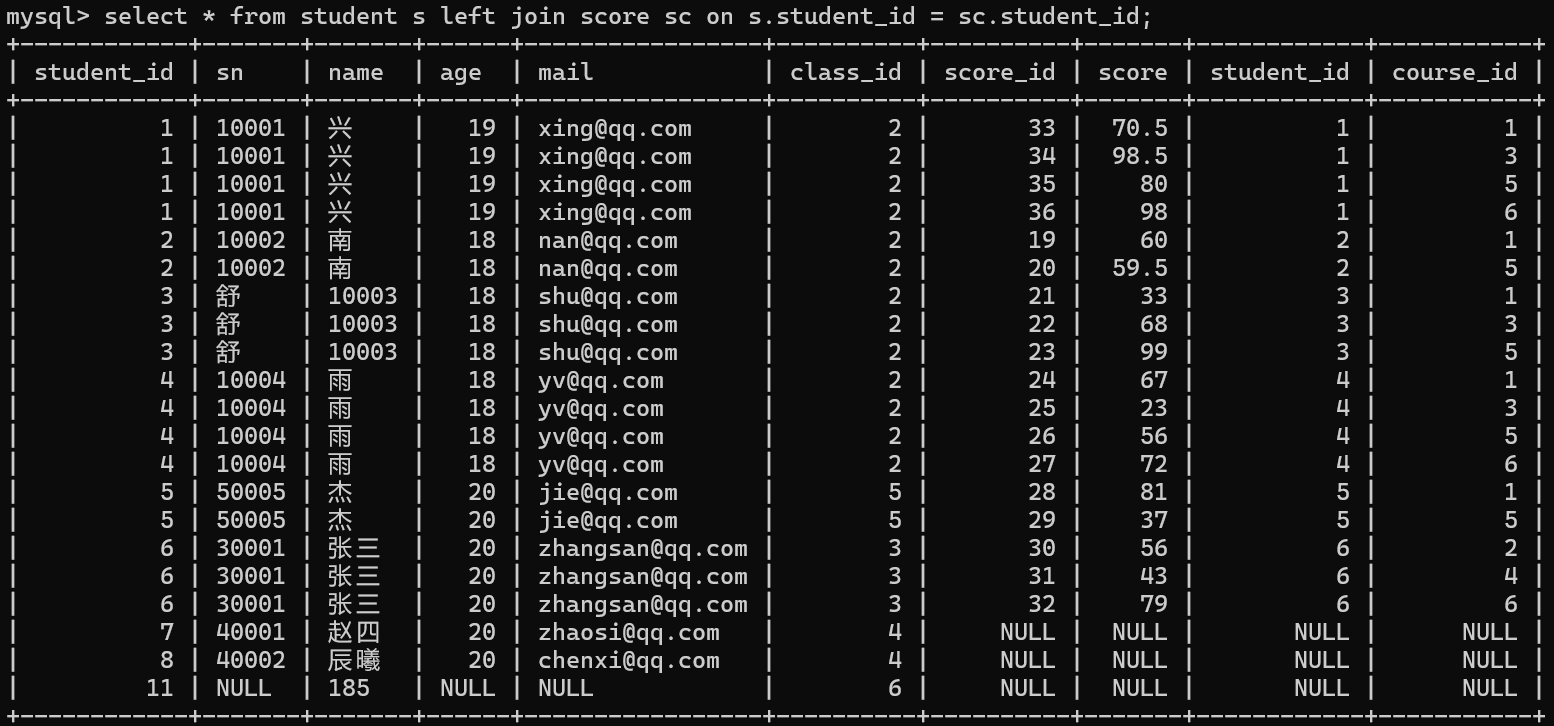
可以看出赵四、辰曦、185是没有成绩的

MySQL中不支持全外连接 FULL JOIN,
不同厂商的数据库,在SQL的使用上略有差别
MySQL ->分页查询 limit s,n;
SQL Server,Oracle, 是用这样的语法来进行分页查询:select top N from……
自连接
自己与自己进行表连接
可以把行转化在列,在查询的时候可以使用where条件进行过滤,
也就是说可以实现行与行之间的比较功能。
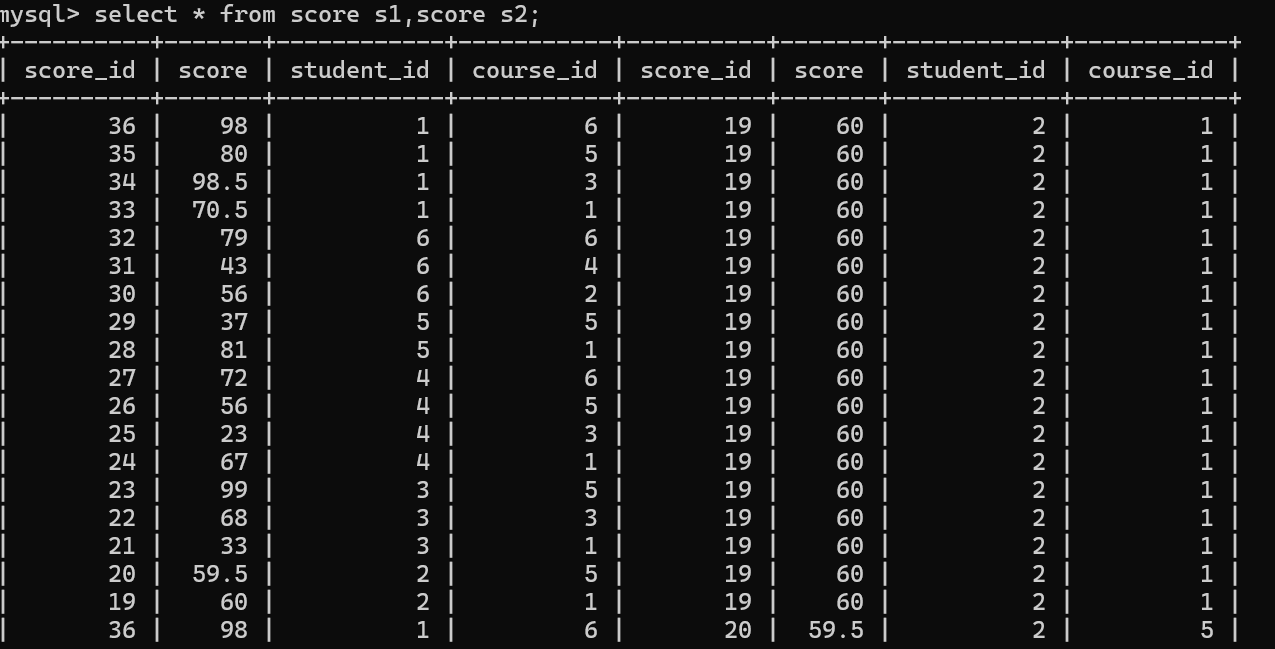
显示所有“计算机网络成绩比“Java"成绩高的成绩信息
1.确定涉及的表
课程表,成绩表
2.取笛卡尔积

两个表名重复了,可以为每个表名起一个别名
连接条件是student_id必须相等。
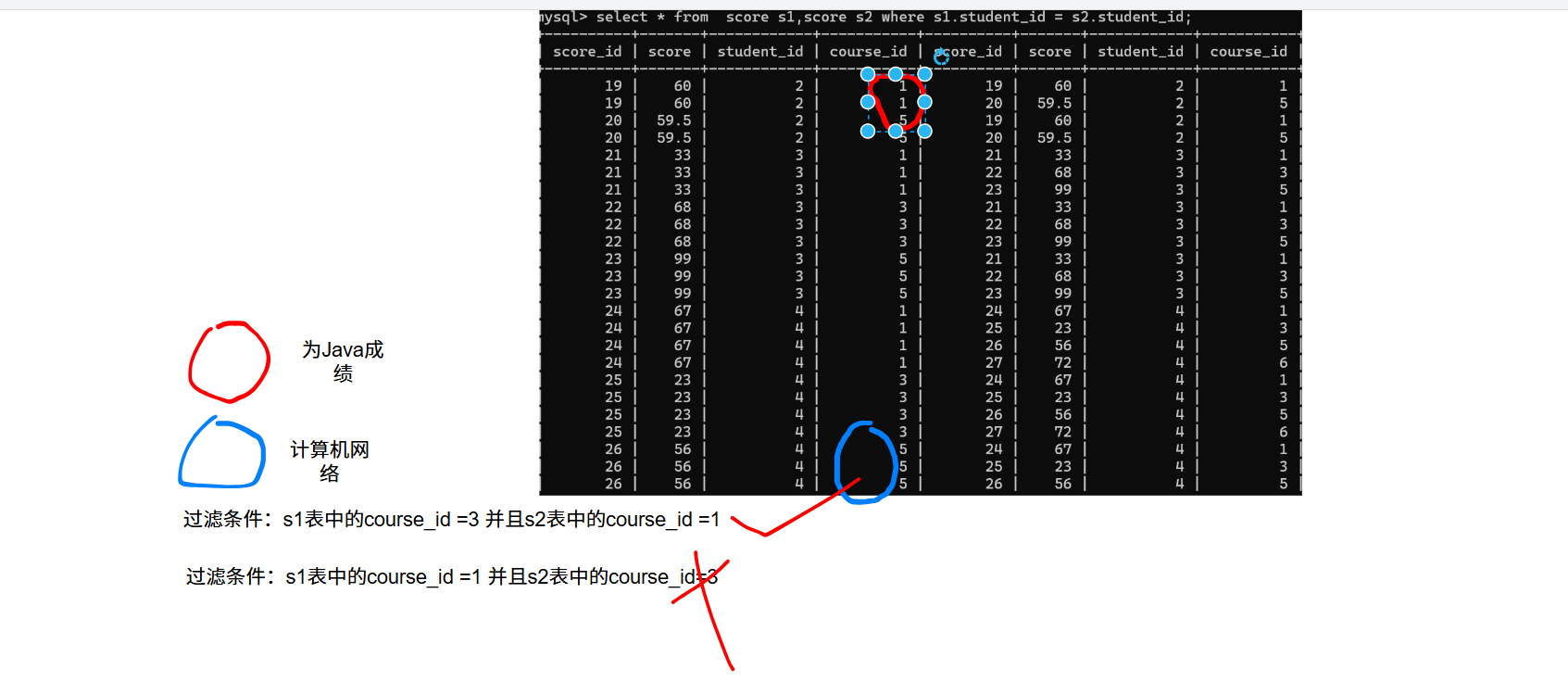

加入最后的条件,查出计算机网络大于Java成绩的记录;

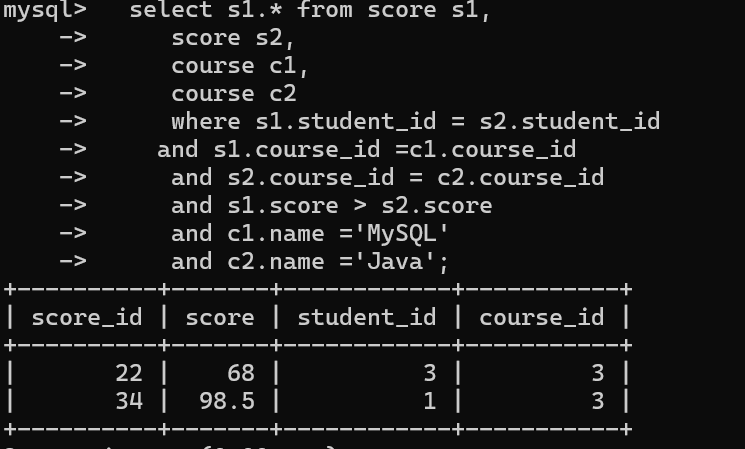
显示所有”MySQL“成绩比”Java“成绩高的信息
1⾸先分两步进⾏,先查出JAVA和MySQL的课程Id,分别为1和3

子查询
也叫嵌套查询
子查询是把一条SQL的查询结果,当做另一条SQL的查询条件,可以嵌套很多很多层。
select * from table1 where table.id = (select id from table2 where name =...)
name = (select name from table3 where xxx=...)
括号里的是子查询,由上面可以看出子查询是由很多条SQL语句组成的,也可以把子查询拆分成一条一条单独的语句去执行,最后再把结果和条件拼装在一起,得到查询结果。
由于嵌套的层级没有固定的限制,如果多层嵌套查询效率是不可控的,工作谨慎使用。
查询与“南”同学的同班同学。
1.参与查询的表
学生表
2.先查出南这位同学的班级编号
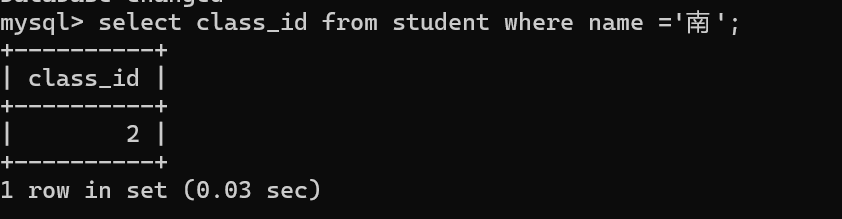
3.在学生表中查出与“南”的同班同学,条件是与“南”这条记录中class_id 相同的所有学生信息。
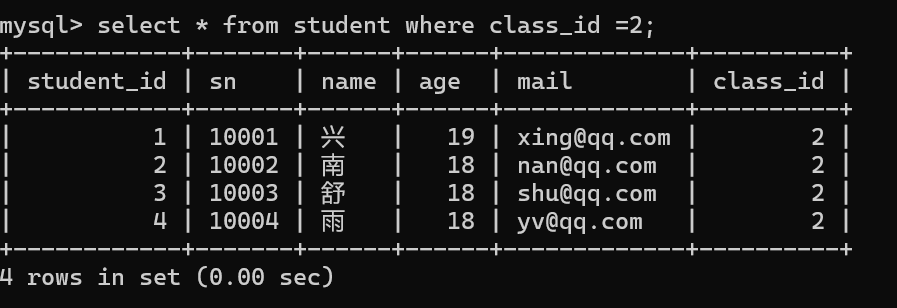
把查询条件中1用子查询的方式去处理。
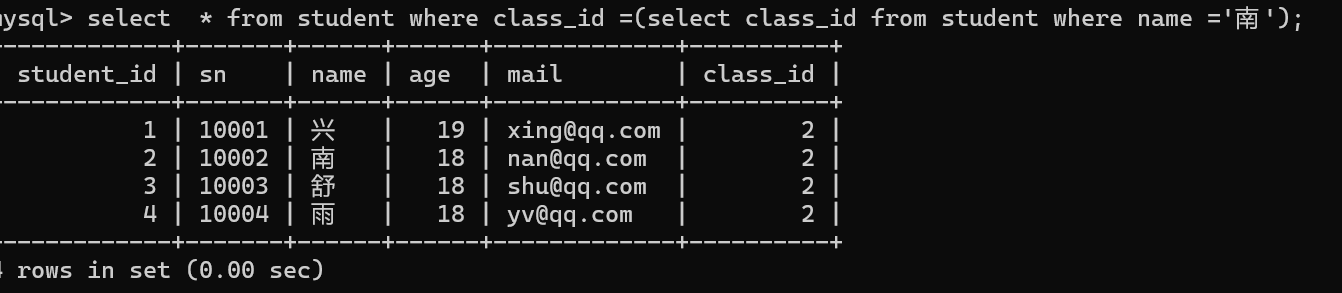
外层的条件的列,与同层查询列表中的列必须匹配。

子查询只是把单独的SQL拼装在一起而已
单行子查询:返回一行记录的子查询(返回的是一个对象)。
多行子查询:返回多行记录的子查询(返回的是一个集合,集合中包含多个对象)。
select * from table1 where table1.id IN(select id from table2 where xxx=...);
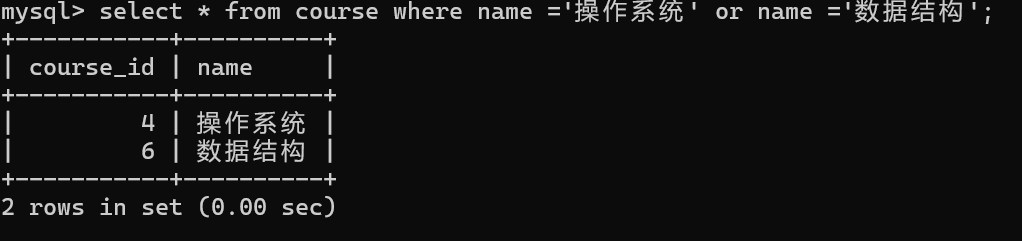
示例: 查询“操作系统”或“数据结构”课程的成绩信息
1.涉及那些表
课程表、成绩表。
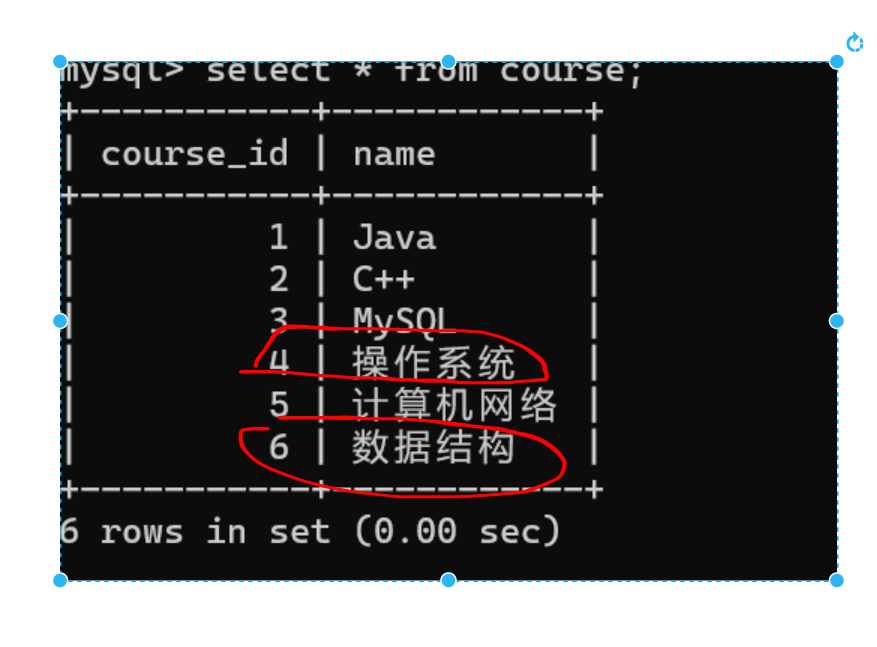
2.在课程表中获取“操作系统”和“数据结构”的编号
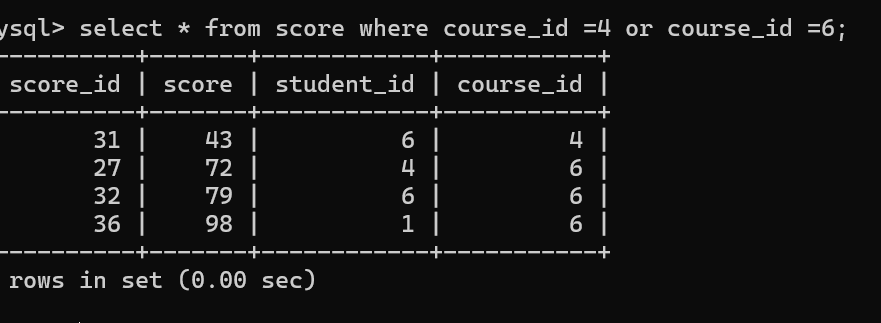
根据获取到的课程id,在成绩表中查询相应课程的分数
4.把以上分步查询的SQL,变成子查询

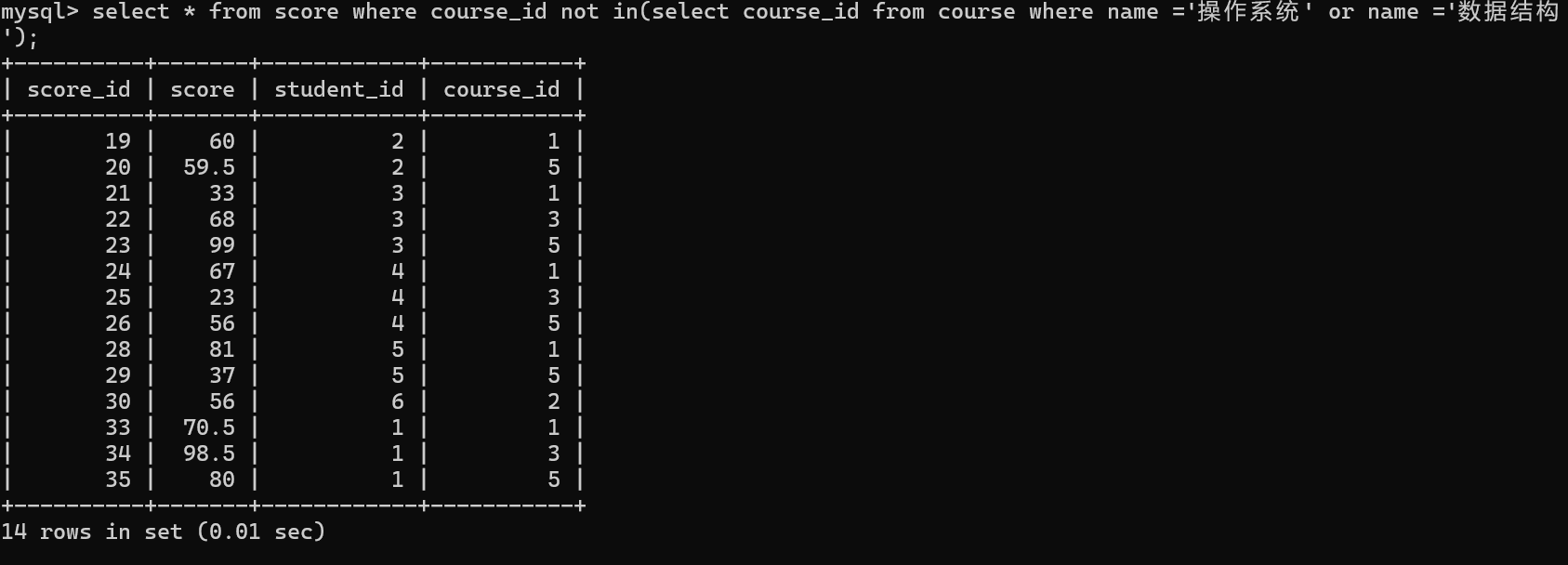
不包含操作系统和数据结构的所有成绩。
可以使用多列包含:
查询重复的分数
可以使用分组查询的方式
1.同一个学生,同一门课程,同样的成绩,按这三个列同时去分组
2.分组之后再having子句中,用count(*)判断分组中的记录数。
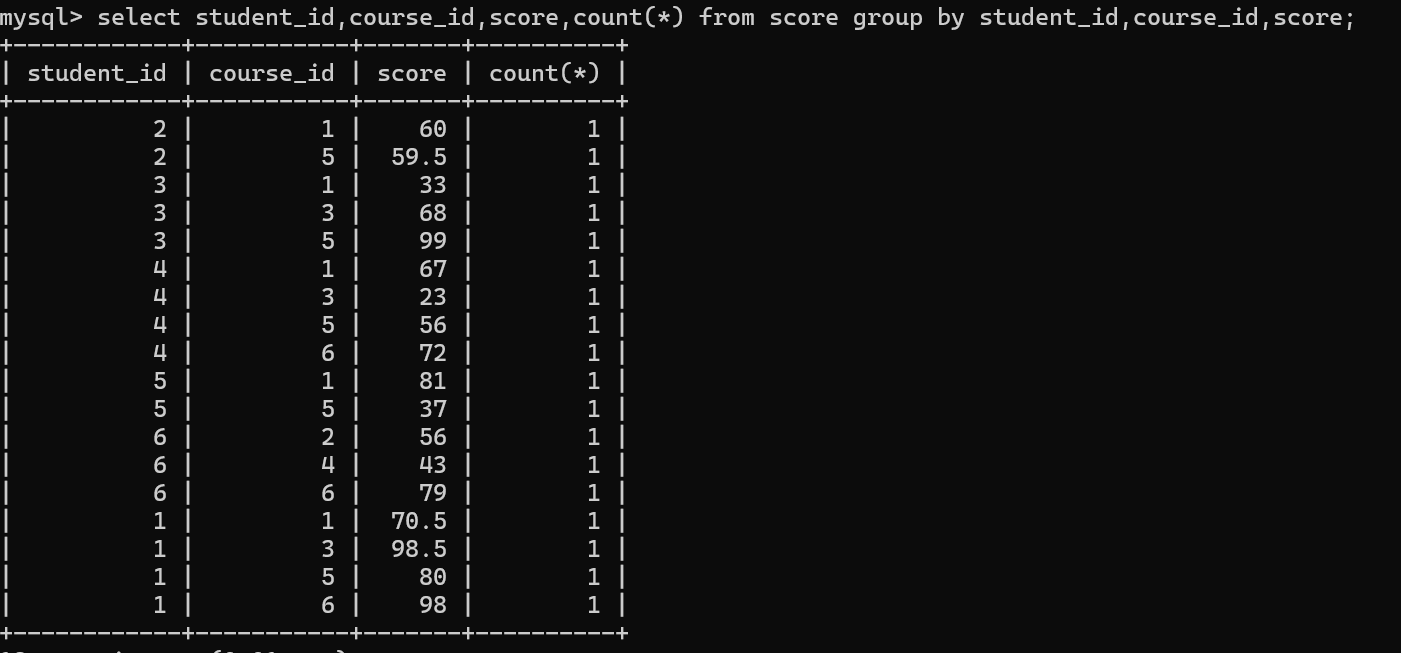

说明我没有相同的学生及他的成绩信息。
加入外层查询

外层查询中的条件字段,与内层查询中结果,一一作比较,如果相等则满足条件,其中只要有一个不相等则不满足条件。
我显示的是empty则是因为我没有插入相同的是数据,我们这只是向大家展示怎么书写这行代码。
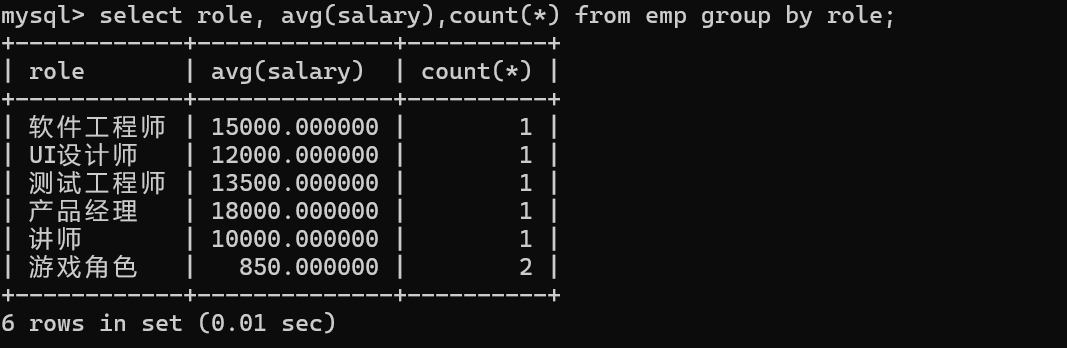
分组后可以使用count(*)来获取当前分组中的记录的条数。
[NOT] EXISTS 关键字
语法 select * from 表名 where exists(select * from 表名1);
exists 后面括号中的查询语句,如果有结果返回,则执行外层的查询,如果返回的是一个空结果即,则不执行外层的查询。
内层查询返回非空结果集
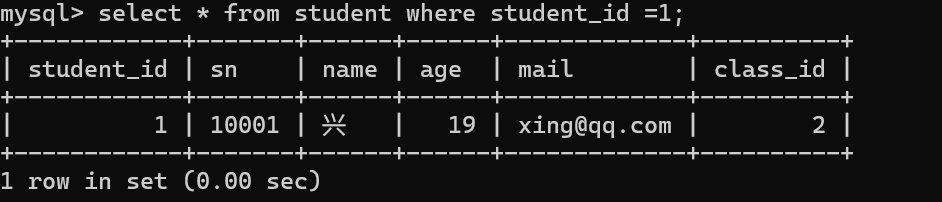
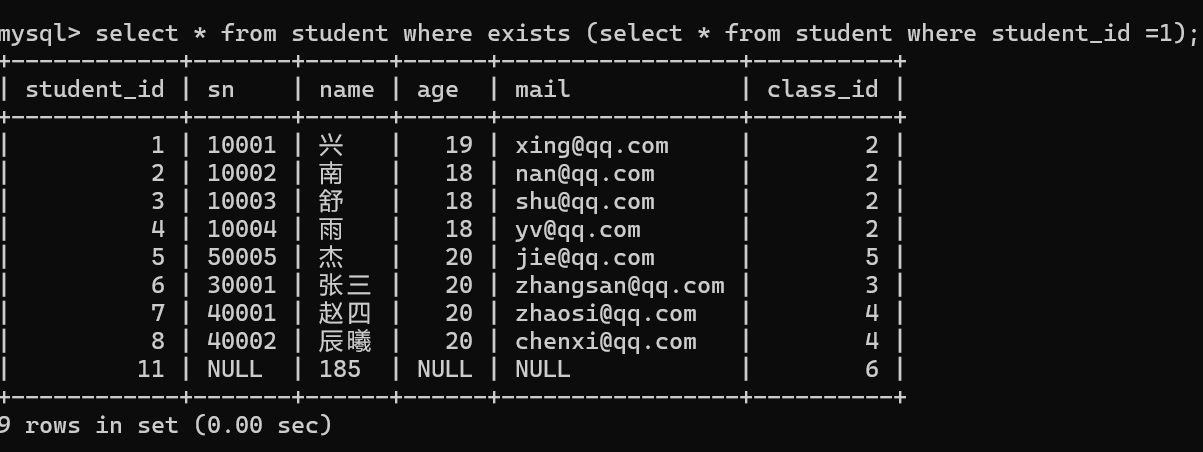
exists相当于if语句的判断条件,有结果返回true,没有结果就返回false。
内层查询返回空结果集


外层也返回空结果集,也可以说是外层查询没有执行。
返回的结果集是一个非空的,只不过列名为null,值也为null而已。
在from子句中使用子查询:子查询语句出现在from子句中。这里要用数据查询的技巧,把一个子查询当做一个临时表使用。
这个结果集在临时表中,是由学生表和课程表组合而成的。
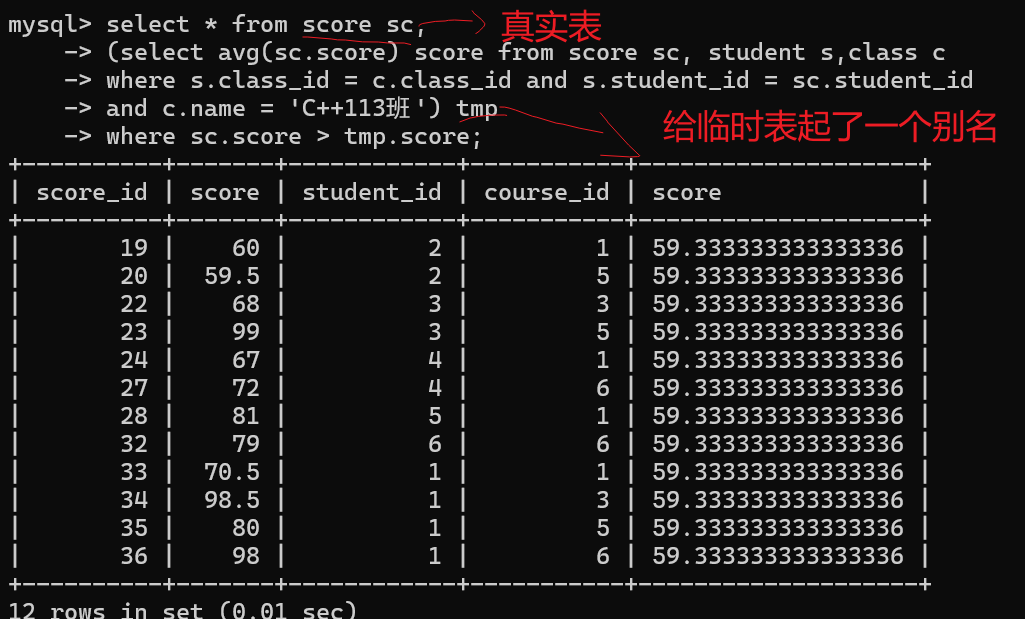
查询所有比“C++113班”平均分高的成绩信息。
1. 先算出C++113班的平均分;
2.先从班级表中根据班级名找到班级编号;
3.根据学生的编号在分数表中计算平均分

4.再用表中学生的真实成绩和以上平均分作比较。
合并查询
作用: 合并多个查询结果到一个结果集中
union,union all
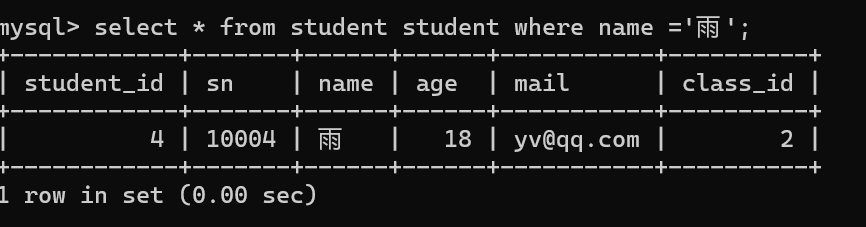
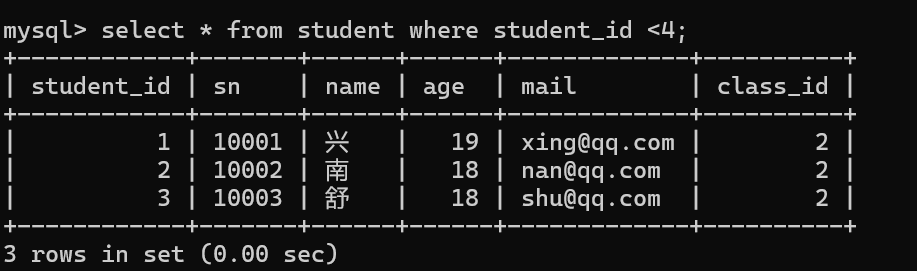
可以使用union把结果集合并在一起。
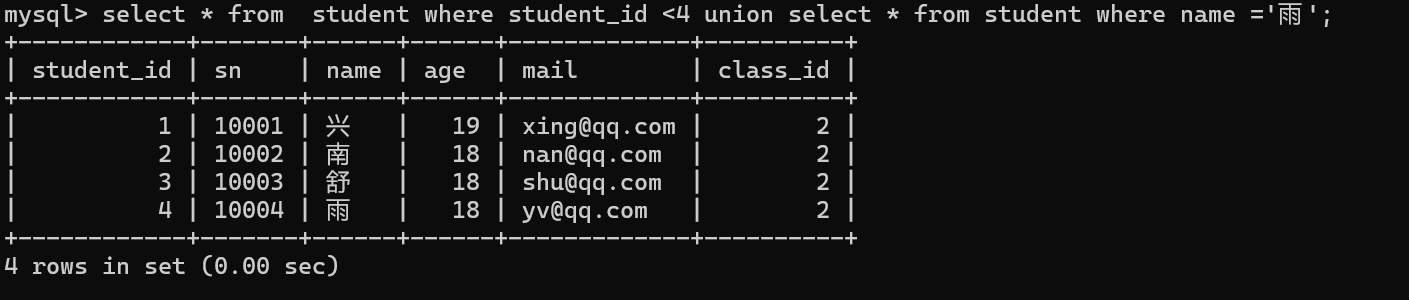
在单表中还是推荐使用or 去连接不同的查询条件,
在多表中,就没办法用or,如果最终的结果是从多个表中获取到的,必须要用到union来进行合并。
根据一张表的结构,创建新表。
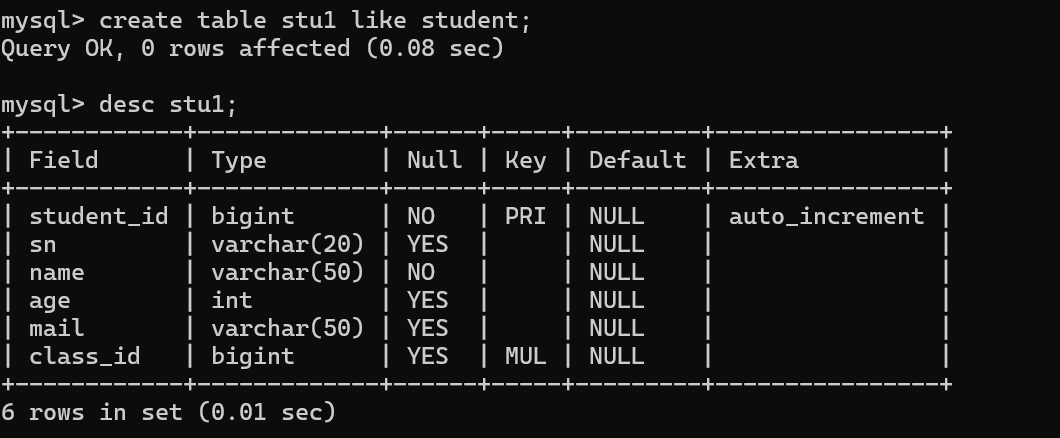
通过union把两张表中的数据显示在一个结果集中
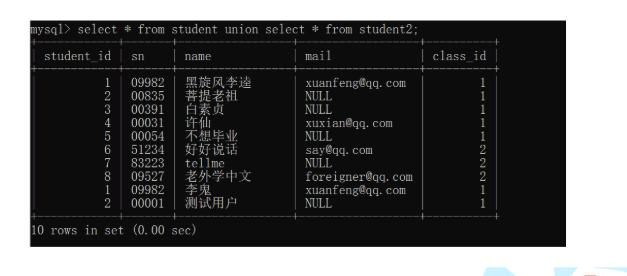
列名步匹配返回的结果集是错误的的结果集,
这个结果是没有意义的,需要人工去规避。
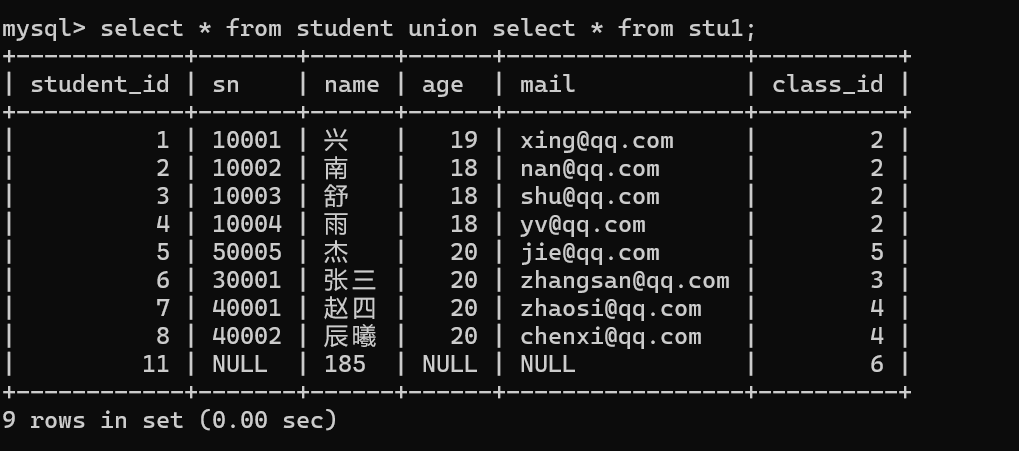
union 该操作符作用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
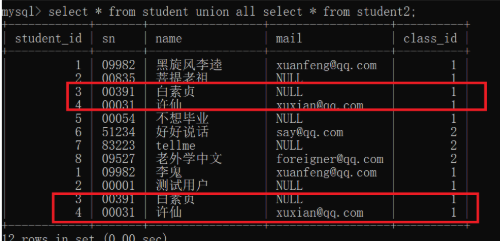
union all 该操作符 用于取得两个结果集的并集。 当使用该操作符时,不会去掉结果集中的重复行。
到这里我们的联合查询就结束了,感谢大家的喜欢和支持。