从多模态数据到强化学习闭环:选址智能体框架技术剖析
在数字AI化的大背景下,山东移动推出的“慧选店”(AI智能选址工具)代表了运营商向AI驱动的空间决策工具转型的一个典范。该系统并非简单的选址辅助工具,而是构建于多模态数据融合与混合模型架构之上的端到端智能体框架,强调国产化硬件与自主算法的深度集成。以下从底层数据管道、模型编排、算法优化到部署机制进行拆解,聚焦其技术内核,探讨如何通过强化学习闭环与知识图谱推理实现高精度时空预测。
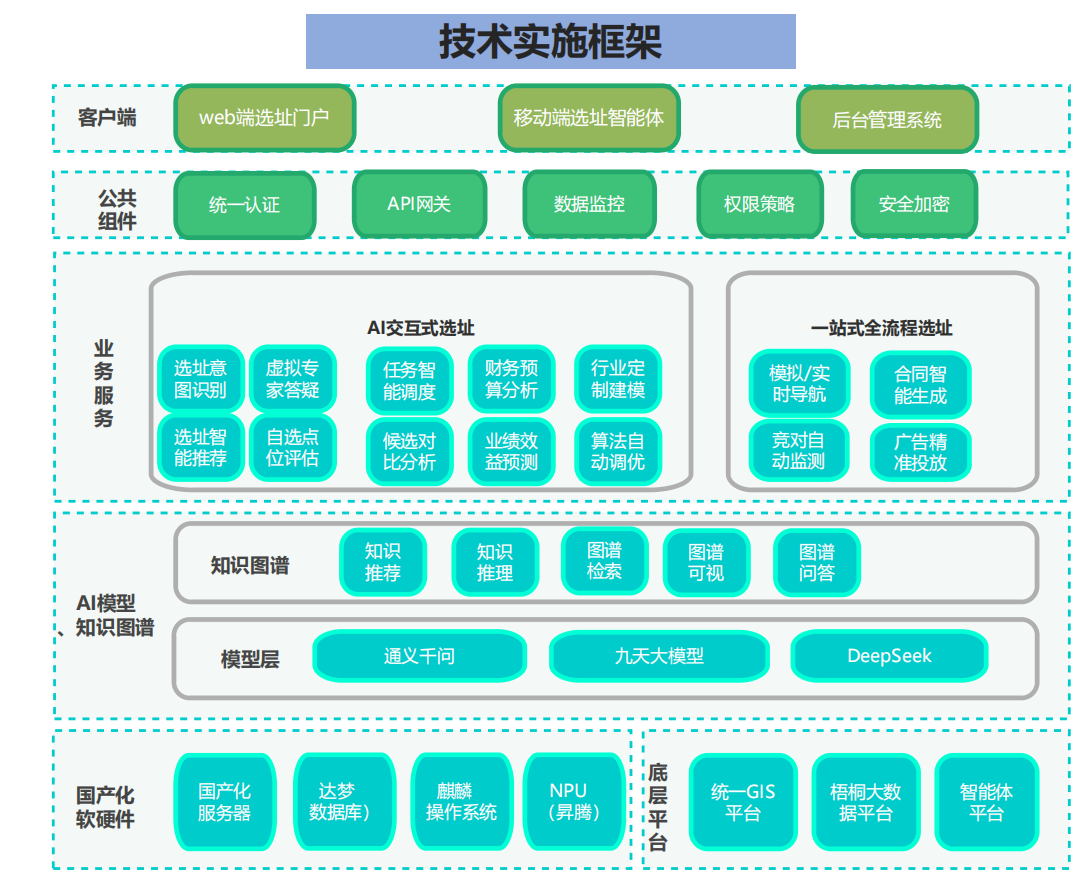
数据层:多源时空数据的异构融合与实时索引
慧选店的核心在于其数据底座的规模与多样性,依托山东移动的10亿+用户信令资源、梧桐大数据平台,以及统一GIS引擎,形成一个覆盖人口热力、客流密度、POI(兴趣点)与工商注册的超大规模时空知识库。具体而言:
- 数据规模与来源:系统聚合1亿+地址数据、1000万+POI、300万+店铺租金记录,以及500万+工商实体。移动用户行为信令提供动态客群画像(年龄、消费水平、轨迹热力),而高德生态补充静态GIS层(如交通网络与商圈边界)。这些数据通过国产达梦数据库(DMDB)存储,确保查询延迟<100ms。
- 融合机制:采用ETL管道(Extract-Transform-Load)结合Kafka流式处理,实现实时增量同步。关键创新是多源对齐:例如,使用时空网格(GeoHash编码,分辨率~10m)将信令轨迹与POI锚点统一投影,避免坐标系偏差(WGS84 vs. GCJ-02)。这使得系统能处理546个选址因子,包括人口密度、交通可达性(Accessibility via 5A选址法)和竞争强度。
从极客视角看,这种数据层类似于一个分布式时空图数据库(GraphDB),其中节点为POI/地址,边为客流迁移路径,支持Cypher-like查询如“MATCH (p:POI)-[:COMPETES_WITH]->(c:Competitor) WHERE distance(p, target) < 500m RETURN avg(rent)”。国产麒麟OS与昇腾NPU加速的索引构建,确保在国产服务器上实现TB级数据的高吞吐。

模型层:大小模型异构编排与IPA代理调度
慧选店摒弃单一LLM范式,转而采用混合模型栈:九天大模型(阿里通义千问变体)处理NLP意图识别,DeepSeek开源模型负责结构化预测,辅以IPA(Intelligent Process Automation)数字员工作为代理层。
- 大模型组件:九天模型嵌入知识图谱(KG),用于多模态交互。输入为用户对话(如“餐饮店,预算5万/月,济南市中区”),输出意图向量(e.g., [行业:餐饮, 预算:5e4, 区域:lat=36.65,lon=117.0,r=5km])。KG增强解释性:实体(如“商圈”)链接关系(如“has_competitor”→“火锅店密度>3/km²”),通过SPARQL查询注入上下文,降低幻觉率至<5%。
- 小模型集成:DeepSeek微调于行业特定数据集(e.g., 餐饮营收历史),输出点位评分。IPA Agent作为Orchestrator,使用ReAct框架(Reason-Act)调度:先意图解析(BERT变体),再调用小模型生成候选(Top-5推荐区),最后大模型合成报告。分层建模是亮点:一级(餐饮/零售),二级(中餐/西餐),三级(粤菜/火锅),参数化微调(LoRA适配器)实现85%行业精准匹配,15%兜底通用模型。
这种编排类似于LangChain的工具链,但优化为国产环境:昇腾NPU加速Transformer推理,峰值FLOPS达数百TF,推理时延<2s。极客们会欣赏其代理自治:IPA支持端到端自动化,如从调研到合同生成的全链路思维链(Chain-of-Thought)。
算法层:因子提取、调优与知识图谱驱动决策
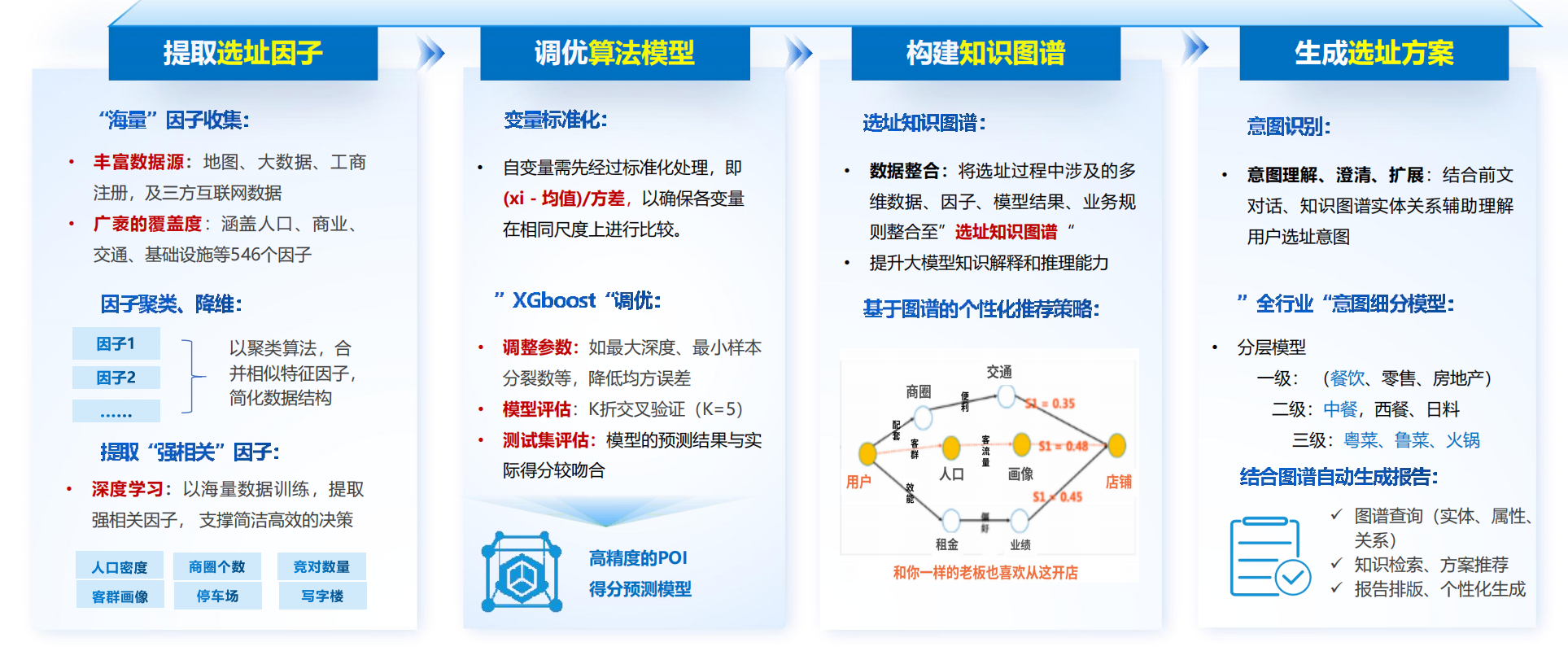
算法设计是慧选店的“黑箱”灵魂,融合聚类、深度学习与强化学习,形成闭环优化。
- 因子提取与聚类:从546维原始特征中,使用PCA降维+DBSCAN聚类合并相似因子(e.g., “步行距离”与“公交密度”聚为“可达性簇”)。深度学习骨干(CNN on 热力图)提取非线性相关,如客流峰值与租金的交互效应。标准化预处理(z-score: (x - μ)/σ)确保尺度一致。
- 预测与调优:核心是XGBoost回归模型,目标为POI得分(y = f(客流, 竞争, 潜力))。超参优化采用GridSearchCV,K=5折交叉验证最小化MSE(<0.05)。5A选址法嵌入作为业务约束:Accessibility (交通分>80),Attractiveness (商圈成熟度)等。
- 知识图谱推理:KG构建于Neo4j-like国产图引擎,节点/边从多源数据注入。推理链:意图→KG检索(实体链接)→小模型生成方案→大模型解释(e.g., “推荐区A得分92,因客流+15% vs. 竞对-20%”)。强化学习闭环(PPO算法)基于历史反馈迭代:奖励函数R = α精度 + β召回 - γ*延迟,动态调优参数。
雷达图可视化(六边形指标:潜力/商业/客群/竞争/交通/成本)使用D3.js渲染,量化多维权衡。测试显示,模型与实地得分吻合率>85%,远超基准(如随机森林的75%)。
部署与可扩展性:国产化全栈与API/SaaS弹性
架构采用微服务(Spring Cloud on 麒麟OS),公共组件(统一认证、API网关)确保安全(加密传输,权限RBAC)。任务调度用Airflow-like国产工具,端到端自动化:从周边调研(地图锁定→报告生成)到点位评估(自选AOI→打分雷达)。
- 国产化栈:昇腾910 NPU for AI加速,达梦DB for OLAP,统信UOS for 容器化(Kubernetes变体)。全链路自主可控,支持边缘部署(5G低时延场景)。
- 接口层:RESTful API暴露核心能力(e.g., /recommend?industry=catering&lat=36.65&lon=117.0),SaaS门户web/移动端。弹性扩展:Docker镜像,水平缩放至100+节点,QPS>1000。
从DevOps角度,CI/CD管道集成SonarQube静态分析与昇腾ModelArts训练,确保代码覆盖>90%。未来扩展潜力:融入联邦学习,跨运营商数据隐私共享。
技术优势:从时空感知到决策自治的跃迁
慧选店的技术魅力在于其对时空复杂性的建模:非静态地图,而是动态代理系统,能模拟“如果开店于此,客流衰减率?”(蒙特卡洛模拟)。相比开源GIS(如QGIS+MLflow),其优势显而易见——国产闭环(零依赖海外栈)、混合规模模型(大模型解释+小模型速度)、KG增强可解释性(黑箱变白箱)。在极客社区,这相当于一个“时空Transformer”:输入对话,输出优化路径,奖励函数驱动演化。
挑战犹存,如小微数据噪声与实时性瓶颈,但通过RLHF(人类反馈强化)迭代,已趋成熟。作为数字中国生态一环,它预示着电信数据向通用AI工具的迁移——不止选址,更是任意空间优化的原型。开源爱好者可从其API入手,复现行业微调,探索更多边界。慧选店目前已开发小程序端免费体验,欢迎各位大神指点~