数据结构-----线性表
目录
概述
顺序表(数组)
概述
优点
缺点
时间复杂度
链表
概述
优点
缺点
时间复杂度
链表分类
单向链表
循环链表
双向链表
双向链表-按照指定下标查找节点
双向链表-添加节点
双向链表-删除节点
双向循环链表
链表vs顺序表(数组)
主要区别
开辟空间的方式
空间利用率
时间复杂度
链表例题:
单向链表
合并有序链表
反转链表
使用链表计算两数之和
判断链表是否有环
方法1:使用Set集合
方法2:快慢指针
判断链表是否相交
方法1:使用双重循环判断
方式2:使用双指针判断
概述
线性表,全名为线性存储结构。使用线性表存储数据的方式可以这样理解,即“把所有数据按照顺序(线性)的存储结构方式,存储在物理空间”。
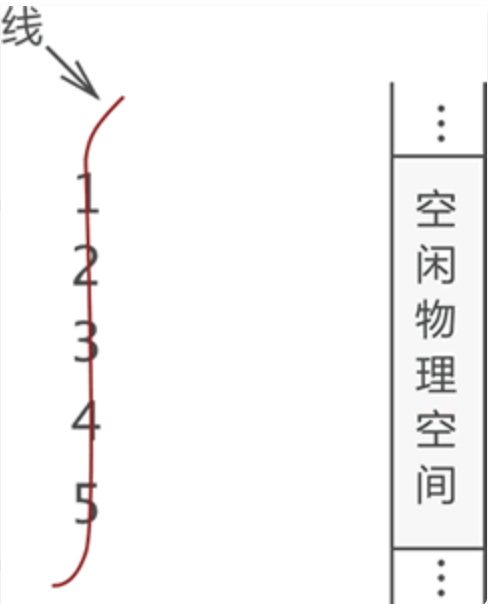
线性存储结构
- 顺序存储结构:数据依次存储在连续的物理空间中(顺序表);
- 链式存储结构:数据分散存储在不连续物理空间中,通过某种指向关系,来维持它们之间的逻辑关系(链表);
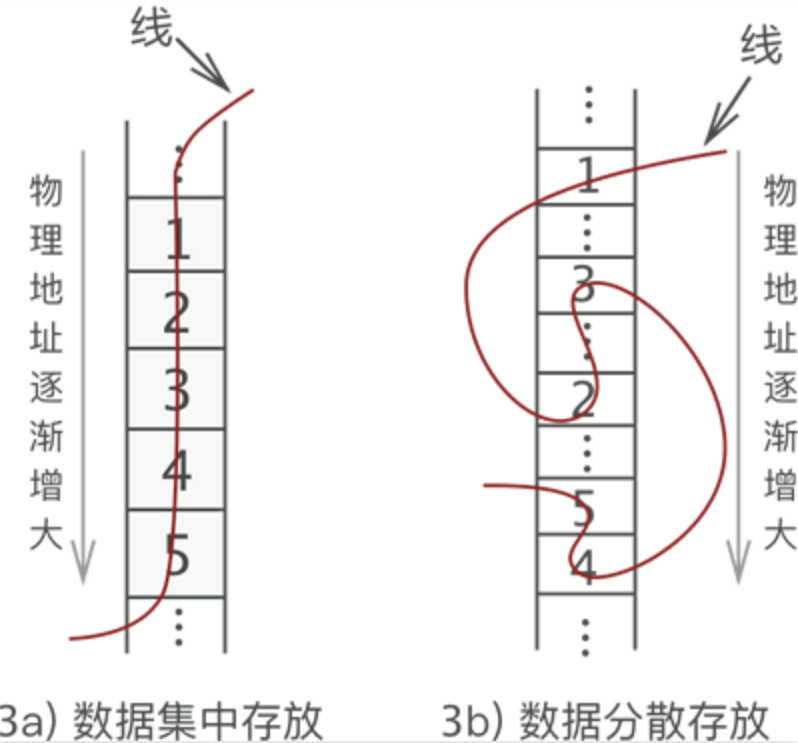
顺序表(数组)
概述
顺序表,全名顺序存储结构,是线性表的一种。顺序表对数据的物理存储结构有明确的要求:顺序表存储数据时,会提前申请一整块足够大小的内存,然后将数据依次存储起来,元素的存储空间在内存中是连续存在的。
在Java中,我们通常使用数组(Array)来定义顺序表,同时,数组也是最基本的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。使用下标来访问数组中的元素,首元素的下标从0开始,最后一个元素的下标是数组长度-1。

优点
- 内存地址连续,数组元素进行遍历时,速度快。
- 根据下标,查找指定位置的元素时,速度快。
缺点
- 长度固定,使用前需要预估长度。
- 插入删除元素时,时间复杂度相对较高。
时间复杂度
数组的长度为 n。
- 访问特定位置的元素,时间复杂度为O(1)
- 插入元素的时间复杂度为O(n) :插入元素时的最坏情况,新元素插入到数组的头部,需要移动n个元素(所有元素)。
- 删除元素的时间复杂度为O(n) : 删除元素时的最坏情况,删除数组的的头部元素,需要移动n-1个元素。
链表
概述
链表,全名链式存储结构,也是线性表的一种。与顺序表不同,链表不限制数据的物理存储位置,使用链表存储的数据元素,其物理存储位置是随机的。由于链表节点之间根本无法体现出各数据之间的逻辑关系。对此,链表的解决方案是:每个数据元素在存储时都配备一个指针,用于指向自己的直接后继元素。
所以,链表中每个数据的存储都由以下两部分组成:
- 数据元素本身,其所在的区域称为数据域;
- 指向直接后继元素的指针,所在的区域称为指针域;

在链表中,实际存储的是一个一个的节点,真正的数据元素包含在这些节点中,所以链表是一种在物理上非连续的数据结构,由若干个节点(Node)组成的一种线性存储结构。

优点
- 使用链表结构,不需要提前预估长度,可以克服数组需要预先知道数据长度的缺点
- 链表使用不连续的内存空间,可以充分利用计算机内存空间,实现灵活的内存动态管理
缺点
- 链表相比于数组会占用更多的空间,因为链表中每个节点中,除了存放元素本身,还有存放指向其他节点的指针
- 不能随机读取元素(RandomAccess)
- 遍历和查找元素的速度比较慢
时间复杂度
- 链表的插入和删除操作的复杂度为 O(1):只需要知道目标位置元素的相邻元素,就能确定插入或删除的位置;
- 查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) : 最坏情况下需要遍历链表;
链表分类
单向链表、双向链表、循环链表、双向循环链表
单向链表
单向链表的每一个节点Node中包含1个数据域和1个指针域。数据域是存放数据的变量data,指针域是指向下一个节点的指针next,所以单向链表只有一个方向。
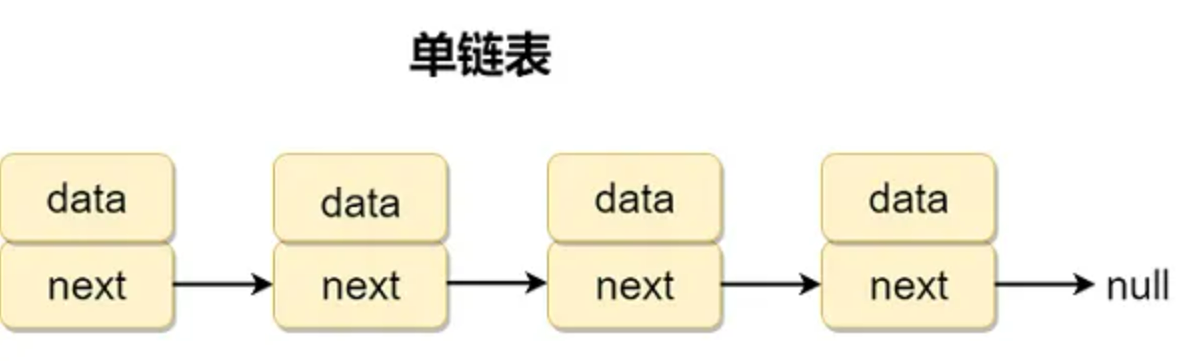
/** 单向链表的节点*/
static class Node<E>{E item; // 数据域Node<E> next; // 后继节点(指针域)public Node(E data) {this.item = data;}
}单向链表的第一个结点被称为头结点(first),最后一个节点被称为尾节点(last),通过头结点first我们可以遍历整个链表,尾结点last指向 null。
/*// 原链表为空链表,需要设置头节点first = newNode;}else {// 原链表不为空时,需要设置原尾节点与新尾节点之间的"后继关系"l.next = newNode;}}/** 添加新元素(头插法)*/public void addFirst(E item) {// 根据传入数据,创建新的Node节点对象final Node<E> newNode = new Node<E>(item);// 获取当前链表的“旧头结点”final Node<E> f = first; // “旧头结点”// 设置新头结点 first = newNode;if(f == null) {last = newNode;}else {newNode.next = f;}}/** 删除头节点*/public void removeFirst() {// 获取当前链表的“旧头结点”final Node<E> f = first;// 获取旧头结点的后继节点final Node<E> next = f.next;// 删除旧节点f.item = null;f.next = null; // help GC// 设置头节点first = next;if(next == null) {// 单向链表为空,则last指向nulllast = null;}}/** 单向链表的节点(内部类)*/static class Node<E>{E item; // 数据域Node<E> next; // 后继节点(指针域)public Node(E data) {this.item = data;}}
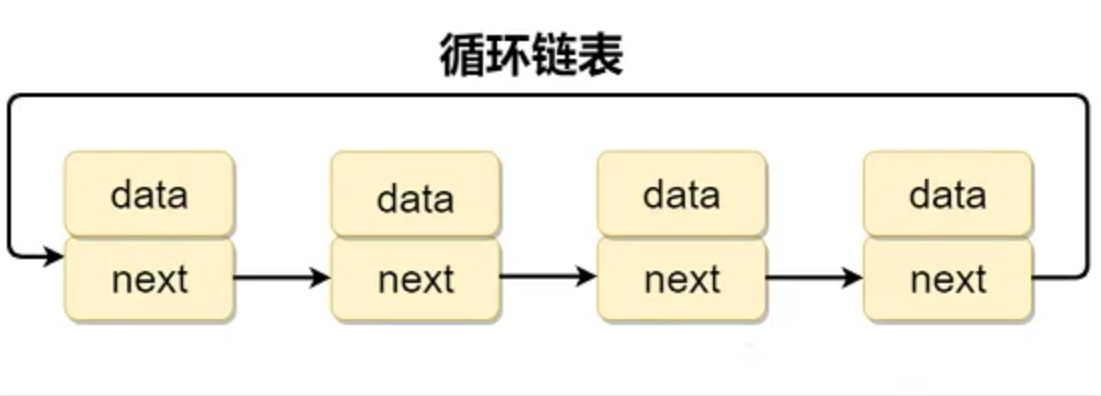
}循环链表
循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
双向链表
双向链表 的每个节点Node中包含2个指针域和1个数据域,指针域next指向后一个节点, prev 指向前一个节点,数据域item用于存储数据。
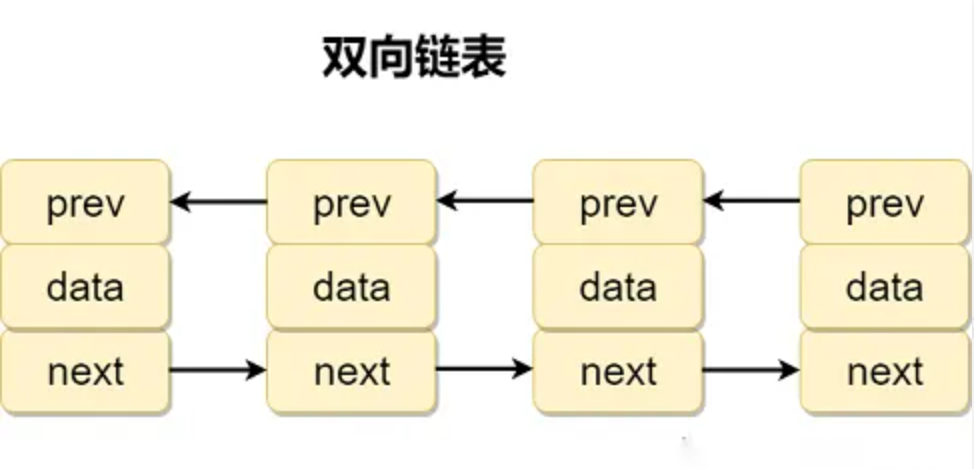
public static class Node<E> {E item; // 数据域Node<E> next; // 后继节点Node<E> prev; // 前驱节点// 构造方法// 参数1:前驱节点// 参数2:数据域// 参数3:后继节点Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}双向链表-按照指定下标查找节点
- 如果指定下标小于size>>1长度一半,则从头部节点开始顺序遍历查找
- 如果指定下标大于size>>1长度一半,则从尾部节点开始逆序遍历查找
// 根据"下标(位置)"查找节点
public Node<E> node(int index) {// 判断下标(位置)在整个链表的"上半区"或"下半区"if (index < (size >> 1)) {// 从头节点开始查找Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {// 从尾节点开始查找Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}双向链表-添加节点
头插法
采用头插法,将新节点添加至链表头部
第一步:获取原来的头结点f
第二步:将新节点的pre指向 --> null,新节点的next指向 -->原来的头结点(first)
第三步:将链表头结点first指向 --> 新节点(新节点成为链表当前的头结点)
第四步:原头结点(f)如果等于null,代表当前链表只有1个节点,则尾节点last也指向当前新节点
原头结点(f)如果不等于null,原来的头结点f的prev指向 --> 新节点(链表当前头结点)
// 插入节点至头节点(头插法)
public void linkFirst(E e) {// 获取链表的头节点final Node<E> f = first;// 创建新节点(新头节点)final Node<E> newNode = new Node<>(null, e, f);// 设置链表头节点first = newNode;if (f == null)last = newNode;elsef.prev = newNode;// 链表长度自增size++;
}尾插法
采用尾插法,将新节点添加至表尾
第一步:获取原来的尾结点(last)
第二步:将新节点的pre指向 --> 原来的尾结点(last),新节点的next指向 -->null
第三步:将链表尾结点last指向 --> 新节点(新节点成为链表当前的尾结点)
第四步:原来的尾结点(last)如果等于null,代表当前链表只有1个节点,则头节点first也指向当前新节点
原来的尾结点(last)如果不等于null,原来的尾结点(last)的next指向 --> 新节点(链表当前尾结点)
// 插入节点至链表尾部
public void linkLast(E e) {// 获取链表尾节点final Node<E> l = last;// 创建新节点final Node<E> newNode = new Node<>(l, e, null);// 设置链表尾节点last = newNode;if (l == null)first = newNode;elsel.next = newNode;// 链表长度自增size++;
}双向链表-删除节点
删除头结点
第一步:获取原来的头结点(first)
第二步:获取原来的头结点(first)的next节点
第三步:将原来的头结点(first)的item和next分别设置为null,协助GC释放该对象的堆内存
第四步:将next节点设置为当前链表的头结点(first)
第五步:如果next节点等于null,设置尾节点为null,此时链表被清空
第六步:设置next节点(当前链表的头结点)的prev为null
// 删除链表头节点
public void removeFirst() {// 获取头结点final Node<E> f = first;// 获取头结点的下一个节点final Node<E> next = f.next;// 清空头结点f.item = null;f.next = null; // help GC// 设置链表的头结点first = next;if (next == null)last = null;elsenext.prev = null;// 链表长度自减size--;
}删除尾结点
第一步:获取原来的尾结点(last)
第二步:获取原来的尾结点(last)的prev节点prev
第三步:将原来的尾结点(last)的item和next分别设置为null,协助GC释放该对象的堆内存
第四步:将prev节点设置为当前链表的尾结点(last)
第五步:如果prev节点等于null,设置头节点为null,此时链表被清空
第六步:设置prev节点(当前链表的尾结点)的next为null
// 删除链表尾节点
public void removeLast() {// 获取尾节点final Node<E> l = last;// 获取尾节点的“上一个元素”final Node<E> prev = l.prev;// 清空尾节点l.item = null;l.prev = null; // help GC// 设置链表的尾节点last = prev;if (prev == null)first = null;elseprev.next = null;// 链表长度自减size--;
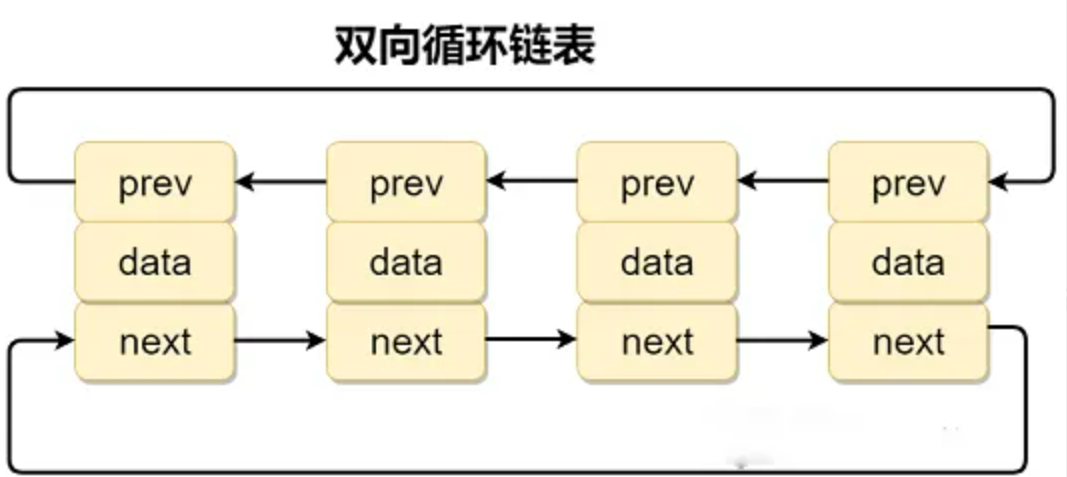
}双向循环链表
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
链表vs顺序表(数组)
主要区别
- 顺序表(数组)可以通过下标快速定位元素,而且物理内存空间连续,遍历速度快,适合读多写少的应用场景;
- 链表插入和删除元素效率高,适合读少写多的应用场景;
- 顺序表(数组)的长度固定,如果声明的数组过小,需要另外申请更大的内存空间+拷贝原数组进行扩容。而链表支持动态扩容。
开辟空间的方式
顺序表(数组)存储数据实行的是 "一次开辟,永久使用",即存储数据之前先开辟好足够的存储空间,空间一旦开辟后期无法改变大小(使用动态数组的情况除外)。
链表存储数据时一次只开辟存储一个节点的物理空间,如果后期需要,还可以再申请。
所以,若只从开辟空间方式的角度去考虑,当存储数据的个数无法提前确定,又或是物理空间使用紧张以致无法一次性申请到足够大小的空间时,使用链表更有助于问题的解决。
空间利用率
从空间利用率的角度上看,顺序表(数组)的空间利用率显然要比链表高。这是因为,链表在存储数据时,每次只申请一个节点的空间,且空间的位置是随机的,这种申请存储空间的方式会产生很多空间碎片,一定程序上造成了空间浪费。不仅如此,由于链表中每个数据元素都必须携带至少一个指针,因此,链表对所申请空间的利用率没有顺序表高。
时间复杂度

链表例题:
单向链表
/** Linked:单向链表实现类*/
public class Linked {Node first; // 头结点Node last; // 尾节点int size; // 链表长度/** Node链表中的节点*/static class Node {int val; // 数据Node next; // 下一个元素public Node(int x) {val = x;}}// 添加链表元素(尾插法)public void add(int val) {// 获取链表的尾节点final Node l = last;// 创建新节点final Node newNode = new Node(val);// 判断原来的尾节点是否等于nullif (l != null) {l.next = newNode; //让原来的尾节点的next -> 新节点} else {first = newNode; //首节点 -> 新节点}last = newNode; //尾节点 -> 新节点size++; // 链表长度递增}/** 获取链表长度*/public int size() {int size = 0;for (Node x = first; x != null; x = x.next) {size++;}return size;}/** 遍历链表所有节点*/@Overridepublic String toString() {StringBuilder sb = new StringBuilder();for (Node x = first; x != null; x = x.next) {sb.append(x.val);if(x.next != null) {sb.append("->");}}return sb.toString();}
}测试:
public static void main(String[] args) {Linked linked = new Linked();linked.add(2);linked.add(4);linked.add(6);System.out.println(linked); // 打印整条链表System.out.println(linked.first); // 打印链表头结点System.out.println(linked.last); // 打印链表尾结点System.out.println(linked.size); // 打印链表长度
}合并有序链表
思路:同时从头结点开始遍历两个链表,并将两个链表中的对应节点中的数据进行比较,按照比较规则,将数据较小的节点存入结果链表中,并移动该链表(数据较小的节点所在链表)的节点至下一个节点(后继节点),继续进行下一轮比较。需要考虑两个链表的长度不一致,所以在遍历链表的过程中,需要判断链表的当前节点是否为空,如果为空,则代表当前链表已经遍历结束,需要合并另外一个链表的剩余节点。
public static Linked meger(Linked l1, Linked l2) {// 分别使用p1和p2,记录两个链表l1和l2的移动位置,默认为“头结点”位置Node p1 = l1.first, p2 = l2.first;// 用于保存"合并结果"的链表Linked result = new Linked();while (p1 != null || p2 != null) {// p1等于null,代表链表l1中的节点合并完毕,需要合并链表l2的剩余节点if (p1 == null) {result.add(p2.val);p2 = p2.next;continue;}// p2等于null,代表链表l2中的节点合并完毕,需要合并链表l1的剩余节点if (p2 == null) {result.add(p1.val);p1 = p1.next;continue;}if (p1.val < p2.val) {// 如果p1小,则添加p1的值,并移动p1result.add(p1.val);p1 = p1.next;} else {// 如果p2小,则添加p2的值,并移动p2result.add(p2.val);p2 = p2.next;}}return result;
}反转链表
思路:遍历链表,将链表中的元素依次存入Stack中。然后根据Stack后进先出LIFO的特点,遍历Stack栈中所有元素,将元素重新存入链表,由于链表采用尾插法,所以最终链表实现反转。
public static Linked reverseLinked(Linked linked) {// 创建一个栈,用于保存链表Stack<Node> stack = new Stack<Node>();// 获取链表头结点,判断链表是否为空Node currentNode = link.first;if(currentNode == null) {return link;}// 遍历链表,将链表中的节点依次入栈while(currentNode != null) {stack.push(currentNode);currentNode = currentNode.next;}// 清空链表link = new Linked();// 遍历栈,将栈中的元素依次存入链表while(!stack.isEmpty()) {link.add(stack.pop().val);}return link;
}使用链表计算两数之和
计算两个超大数字之和
思路:两个整数相加,使用两个链表分别保存两个整数,每个节点只存储单个数字,按照逆序方式存入链表,头节点代表个位。 同时遍历两个链表,从头节点(也就是个位数字)开始计算每位之和,计算结果存入新的链表。
例如:2 -> 4 -> 3 代表 342
5 -> 6 -> 4 代表 465
两数的相加之和等于807
/** 计算两个数字之和 * 通过链表保存数字,头节点代表个位,依次类推*/
public static Linked addTwoNumbers(Linked link1, Linked link2) {// 获取头结点(个位)Node n1 = link1.first;Node n2 = link2.first;// 定义用于保存计算结果的链表Linked resultLinked = new Linked();// 保存进位值int carry = 0;// 依次取出链表节点(依次取出每一位数字)while (n1 != null || n2 != null) {// 取出当前计算位的数字,如果为空,则按0进行计算int x = n1 != null ? n1.val : 0;int y = n2 != null ? n2.val : 0;// 计算当前计算位的两个数字与进位值相加之和int sum = x + y + carry;// 进位值carry = sum / 10;// 当前位计算结果resultLinked.add(sum % 10);// 如果当前位不等于空,则进位if(n1 != null) {n1 = n1.next;}if(n2 != null) {n2 = n2.next;}}// 计算结束后,需要考虑最后一次计算(最高位计算)时,是否产生进位if(carry != 0) {resultLinked.add(carry);}return resultLinked;
}判断链表是否有环
Linked.Node node1 = new Linked.Node(1);
Linked.Node node2 = new Linked.Node(2);
Linked.Node node3 = new Linked.Node(3);
Linked.Node node4 = new Linked.Node(4);
Linked.Node node5 = new Linked.Node(5);node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
node5.next = node3; // 链表产生环方法1:使用Set集合
思路:通过Set集合记录值的方式,如果有重复的数据,就代表有环。
private static boolean hasCycle(Node node) {// 定义Set集合,保存链表中的所有节点Set<Node> nodeSet = new HashSet<Node>();// 遍历链表中的每个节点while(node != null) {// 判断Set中是否存在该节点// 如果存在,则代表该链表有环if(nodeSet.contains(node)) {return true; // 链表有环}// 如果不存在,则将节点加入Set集合,用于后续的判断nodeSet.add(node);// 移动链表节点node = node.next;}return false; // 链表无环
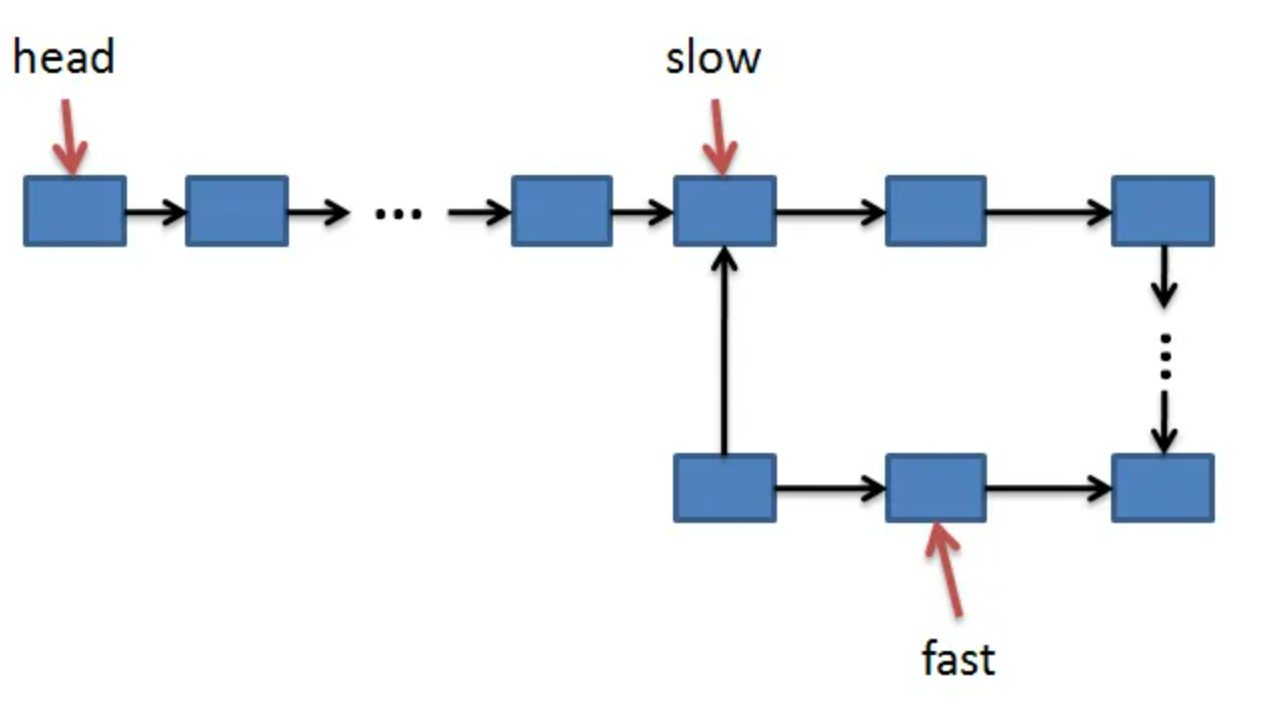
}方法2:快慢指针
思路:定义两个指针:快指针fast和慢指针slow。在开始遍历前,两个指针都指向链表头head,然后在每一次循环操作中,慢指针slow每次向前一步(即slow = slow.next),而快指针fast每次向前两步,即:fast = fast.next.next。
由于fast要比slow移动的快,如果有环,fast一定会先进入环,而slow后进入环。当两个指针都进入环之后,经过若干步的操作之后二者一定能够在环上相遇。
private static boolean hasCycle(Node head) {if (head == null) {return false;}// 定义快指针和慢指针,从head头节点开始Node fast = head;Node slow = head;while (fast != null && fast.next != null && slow != null) {fast = fast.next.next; // 快指针移动2步slow = slow.next; // 慢指针移动1步// 判断fast和slow快慢指针指向的内存地址相同,如果相同,则代表碰面相遇if (fast == slow) {// 如果碰面,就代表链表有环return true;}}return false;
}判断链表是否相交
Linked.Node node1 = new Linked.Node(1);
Linked.Node node2 = new Linked.Node(2);
Linked.Node node3 = new Linked.Node(3);
Linked.Node node4 = new Linked.Node(4);
Linked.Node node5 = new Linked.Node(5);Linked.Node nodeA = new Linked.Node(1);
Linked.Node nodeB = new Linked.Node(2);
Linked.Node nodeC = new Linked.Node(3);Linked link1 = new Linked();
link1.addNode(node1);
link1.addNode(node2);
link1.addNode(node3);
link1.addNode(node4);
link1.addNode(node5);Linked link2 = new Linked();
link2.addNode(nodeA);
link2.addNode(nodeB);
link2.addNode(nodeC);
link2.addNode(node3); // 链表产生相交System.out.println(link1);
System.out.println(link2);方法1:使用双重循环判断
思路:设置两个变量,分别遍历两个链表,双重for循环,在循环遍历过程中,如果两个变量相等,那么两个链表相交。
public static boolean isIntersect1(Linked link1, Linked link2) {for (Node p = link1.first; p != null; p = p.next) {for (Node q = link2.first; q != null; q = q.next) {if (p == q) {return true;}}}return false;
}方式2:使用双指针判断
思路:判断两个链表是否相交,该两个链表中长度必定有长有短,或者相等。如果这两个链表长度不相等,我们可以得到两个链表的长度的差值diff。同样也是设置两个变量p,q,分别遍历长链表和短链表,与方法一不同的是,p遍历长链表的时候不是从第一个结点开始遍历,而是先让p往后移动diff个结点,然后p和q同时循环往后一个结点,如果p == q,那么两个链表就相交。
public static boolean isIntersect2(Linked link1, Linked link2) {// 安全检测if (link1 == null || link2 == null) {return false;}// p 指向长链表的第一个结点// q 指向短链表的第一个结点Node p = link1.size() > link2.size() ? link1.first : link2.first;Node q = link1.size() > link2.size() ? link2.first : link1.first;// 求两个链表长度差int diff = Math.abs(link1.size() - link2.size());// p先往后移动diff个结点while (diff-- > 0) {p = p.next;}// p 和 q 同时往后移动while (p != q) {p = p.next;q = q.next;}// 如果p(q)不为null,则两个链表相交,否则不相交if (p != null) {return true;} else {return false;}
}