Shape-Guided Diffusion with Inside-Outside Attention
paper: WACV 2024 2403
https://arxiv.org/pdf/2212.00210
code:
https://github.com/shape-guided-diffusion/shape-guided-diffusion
Abstract
我们提出将精确的对象轮廓作为文本到图像扩散模型中的一种新约束,我们将其称为形状引导扩散(Shape-Guided Diffusion)。我们的无训练方法在反转和生成过程中使用内外注意力机制,将形状约束应用于交叉注意力图和自注意力图。该机制指定哪些空间区域是对象(内部)与背景(外部),然后将编辑与正确的区域相关联。我们在形状引导编辑任务上证明了我们方法的有效性,在该任务中,模型必须根据文本提示和对象掩码替换对象。我们基于MS-COCO构建了一个新的ShapePrompts基准,并根据自动指标和标注者评分,在形状忠实度方面取得了最先进的结果,同时没有降低文本对齐度或图像真实感。
Introduction
什么是形状?根据定义,物体的形状指的是将其与外部世界分隔开的边界、轮廓或外形。因此,形状通常承载着大量的语义信息。例如,在图1的 bottom row中,仅凭轮廓就可以看出该物体是一辆朝右的交通工具,无需颜色或纹理的提示。鉴于物体轮廓在人类视觉处理(包括物体识别和分类)中起着关键作用[26],因此形状是表示用户与生成模型交互意图的有力线索。然而,先前在局部图像编辑方面的研究[1,18]通常侧重于最粗糙形式的形状输入,这些输入往往是无定形的斑点或“用户涂鸦”,仅凭其轮廓甚至难以分辨物体类别。因此,当给定精确的形状输入时,这些方法往往会失效。相反,我们专注于精确的物体掩码,这些掩码可以很容易地从现成的分割模型中获取。因此,我们考虑形状引导编辑任务,即将真实图像、文本提示和物体掩码输入到预训练的文本到图像扩散模型中,以合成一个忠实于文本提示和掩码形状的新物体。
我们的方法源于以下观察:扩散模型通常包含虚假注意力,这些注意力会将物体像素与背景像素进行弱关联,这使得生成保留给定形状边界的编辑结果变得困难。为解决这一问题,我们划分出物体(内部)和背景(外部),并提出一种新颖的内外注意力机制,该机制对交叉注意力图和自注意力图进行修改,从而使指向物体的标记或像素被约束为仅关注形状内部的像素,反之亦然。我们不仅在生成过程中应用此机制以执行形状敏感编辑,还在反转过程中应用该机制,以便在编辑前更好地保留源物体的信息。
之,我们的贡献包括:
- 我们指出了现有图像编辑方法中原始物体形状未被保留的局限性,并对该问题存在的原因提供了实证见解。
- 与现有的基于掩码的编辑改进(例如复制背景或微调模型以使用掩码输入)不同,我们引入了一种无需训练的机制,在推理时对注意力图施加形状约束。据我们所知,我们是首个探索在反转过程中约束注意力图的研究,这使我们能够发现更好地保留真实图像形状信息的反转噪声。
- 我们的方法在MS-COCO ShapePrompts基准测试的形状忠实度方面取得了SOTA结果,并且被标注员评为最佳编辑方法的频率是最具竞争力基线方法的2.7倍。我们展示了多种编辑能力,例如物体编辑、背景编辑以及同时进行的内外编辑。
Related Work
Diffusion Models 扩散模型[29]定义了一个扩散步骤的马尔可夫链,该链缓慢地向数据中添加随机噪声,然后学习一个模型来逆转这个过程。其变体包括去噪扩散概率模型(DDPM)[9]、去噪扩散隐式模型(DDIM)[30]和基于分数的模型[31]。最近,扩散模型[20,24,25,27]在文本引导的图像合成方面表现出了令人印象深刻的性能。我们的工作重点是根据文本提示和对象掩码,使这些扩散模型适应文本引导的局部编辑。
Global and Local Image Editing 多项研究已将生成模型扩展到图像编辑领域。在文本引导的全局编辑方面,StyleCLIP [22]对 StyleGAN [11]进行了适配,DiffusionCLIP [13]则对扩散模型进行了适配,以根据文本提示编辑整个图像。Blended Diffusion [1]提出了一种局部编辑方法,该方法通过在每个扩散时间步复制源图像背景的适当噪声版本,将编辑限制在掩码区域内。虽然这种“复制背景”技术通常可以与其他方法结合,以实现扩散模型中的局部编辑,但我们证明,仅依靠该方法不足以保留对象形状,并且我们通过所提出的方法进一步提高了形状保真度。
Structure Preserving Image Editing 图像到图像翻译领域的多项研究在编辑过程中也能保留结构。为实现这一目标,部分研究采用复制随机种子[38]、微调模型权重[12,36]、复制注意力图[8]或基于源图像的部分噪声版本进行条件控制[17]等方法。同时,还有一些与我们工作独立并行开发的同期研究[2,19,35],我们在图2中展示了概念对比,并在补充材料中提供了更多示例。(a)虽然这些方法通常能够模仿源图像的整体风格和结构,但在进行不干扰背景的局部编辑时却存在困难。(b)出现这种现象的原因是,这些方法仅依赖扩散模型的文本接地能力并复制注意力图,而注意力图往往存在噪声,且会将物体和背景像素混在一起(见图5)。相比之下,我们根据形状对这些注意力图进行约束,该形状可由用户提供或从更可靠的自动接地模块(如分割模型)中获取,从而以无需训练的方式融入更准确的空间定位信息。(c)由于这种像素纠缠,像Prompt-to-Prompt(P2P)[8]这类研究在编辑真实图像时往往会出现显著偏差(见图1)。而我们提出的内外注意力机制在应用于反转过程时,能够减轻这种偏差(见图5)。

Image Inpainting 图像修复是填充图像缺失区域的任务。研究人员针对基于生成对抗网络的图像修复提出了扩张卷积[10]、部分卷积[15]、门控卷积[41]、上下文注意力[40]和共调制[43]等方法。Lugmayr等[16]最近提出了一种基于扩散的自由形式图像修复模型。已有针对文本条件修复对GLIDE[20]和Stable Diffusion[18,25]进行微调的变体。然而,这些方法都是在无语义的自由形式掩码上训练的。现有少数基于训练的方法使用对象掩码,但均未公开。Makea-Scene[6]训练了一个以场景完整分割图为条件的自回归Transformer。Shape-guided Object Inpainting[42]训练了一个生成对抗网络,Imagen Editor[37]则使用对象掩码训练Imagen[27]进行修复。相比之下,我们在推理时将模型应用于开源的文本到图像扩散模型之上。由于我们的方法无需训练,因此更加灵活,可应用于对象编辑之外的任务,如背景编辑或同时进行内外编辑,如5.2节所讨论。
Shape-Guided Diffusion
我们提出了Shape-Guided Diffusion,这是一种无需训练的方法,能够使预训练的文本到图像扩散模型遵循形状引导。我们的目标是在给定文本提示Psrc和Pedit以及可选对象掩码m(如果未提供,则从Psrc推断)的情况下,对图像xsrc进行局部编辑,使编辑后的图像xedit既忠实于Pedit,又忠实于m。我们引入了内外注意力机制(Inside-Outside Attention),以在反转(图像到噪声)和生成(噪声到图像)过程中显式约束交叉注意力图和自注意力图。我们方法的概述如图3和算法1所示。我们基于Stable Diffusion(SD)构建,后者是一种在低分辨率 latent空间中运行的潜在扩散模型(LDM)[25]。LDM latent空间是图像空间的感知等效下采样版本,这意味着我们能够通过下采样的对象掩码在 latent空间中应用内外注意力机制。在本文的其余部分中,当我们提到“像素”“图像”或“噪声”时,指的是LDM latent空间中的这些概念。

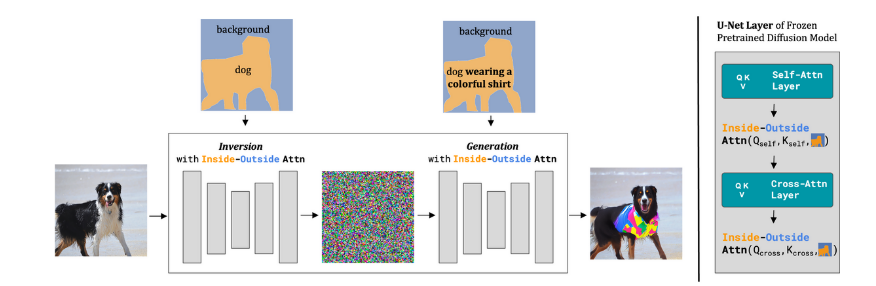
图3.形状引导扩散。我们的方法接收一张真实图像、源提示词(“狗”)、编辑提示词(“穿着彩色衬衫的狗”)以及一个可选的对象掩码,并输出一张编辑后的图像。如果未提供对象掩码,我们会使用形状推断函数(例如分割模型)从源提示词中推断出对象掩码。左侧:我们在反转和生成过程中对冻结的预训练文本到图像扩散模型进行修改。右侧:我们展示了U-Net中某一层的详细视图,其中内外注意力机制根据掩码对自注意力图和交叉注意力图进行约束。
Inside-Outside Attention
LDMs包含交叉注意力层和自注意力层,其中交叉注意力层用于为每个文本标记生成空间注意力图,自注意力层用于为每个像素生成空间注意力图。我们推测,先前的方法往往会失败,原因在于虚假注意力——试图编辑对象的注意力与试图保留背景的注意力相互竞争,因为它们的定位不够精确(见图5)。因此,我们对交叉注意力图进行操作,使得内部标记与外部标记负责编辑不同的、非重叠的空间区域(例如,“dog”“shirt”等可能只编辑狗,“background”可能只编辑剩余场景)。由于自注意力层在很大程度上影响像素如何分组以形成连贯的对象,我们对自注意力图应用类似的操作,以进一步确保目标对象包含在输入掩码的边界内。
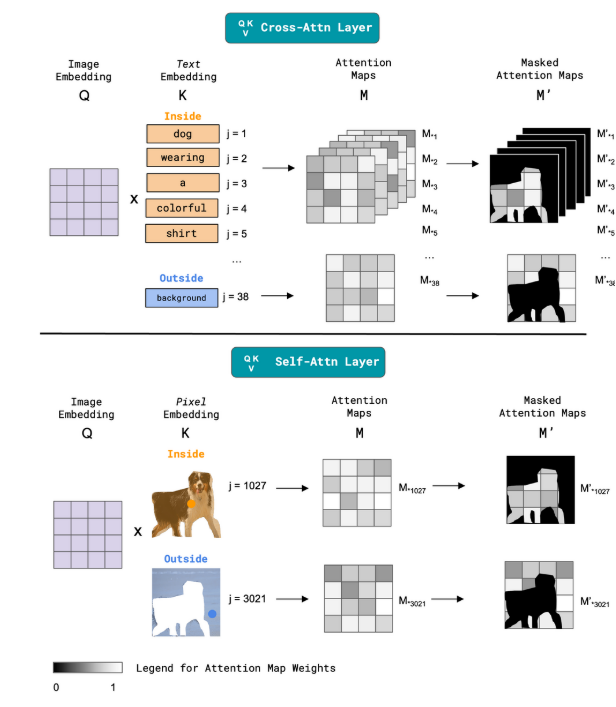
图4.内外注意力机制。我们对交叉注意力图和自注意力图均进行了修改。其中,j表示标记/像素索引,Mj∗M^*_jMj∗表示对应第j个索引的注意力图。交叉注意力层(顶部):根据文本嵌入是指向对象内部还是外部,我们依据对象掩码或反转对象掩码对注意力图M进行约束,以生成M′M'M′。自注意力层(底部):我们对内部和外部像素嵌入执行类似操作。
图4给出了Inside-Outside Attention的概述,我们的算法定义如下(另见图算法2)。在逆向或生成过程中的每个时间步长进行一次前向传播时,我们会遍历扩散模型DM的所有层,并对交叉注意力图和自注意力图M进行操作。我们将交叉注意力图和自注意力图M的维度分别表示为RHW×dτ和RHW×HW,其中H是图像高度,W是图像宽度,HW是展平图像中的像素数量,dτ是标记数量。我们还根据交叉注意力层或自注意力层的分辨率对m进行下采样。对于交叉注意力图,我们根据标记是指向对象还是背景来确定列索引Jin和Jout。对于自注意力图,我们根据掩码m定义的像素是属于对象内部还是外部来确定列索引Jin和Jout。最后,我们计算新的约束注意力图
M′∗jin={M∗jin⊙m∣∀jin∈Jin}M' * j_{\text{in}} = \{M * j_{\text{in}} \odot m \mid \forall j_{\text{in}} \in J_{\text{in}}\}M′∗jin={M∗jin⊙m∣∀jin∈Jin}
且M′∗jout={M∗jout⊙(1−m)∣∀jout∈Jout}M' * j_{\text{out}} = \{M * j_{\text{out}} \odot (1 - m) \mid \forall j_{\text{out}} \in J_{\text{out}}\}M′∗jout={M∗jout⊙(1−m)∣∀jout∈Jout}


图5.虚假注意力和无分类器引导限制形状保持。内外注意力(顶部)通过将标记与特定空间区域相关联来保持物体与背景之间的形状关系。我们在使用无分类器引导重建(左)和编辑(右)真实图像时展示了这一特性。我们还描绘了所有注意力头和时间步长平均的“dog”标记的交叉注意力图。
Inside-Outside Inversion
为了编辑真实图像,我们使用DDIM反演[20,30]将源图像转换为反演噪声。然而,我们观察到,将反演与文本到图像扩散模型结合使用时,往往会导致形状-文本忠实度的权衡问题。虽然使用完全条件或无条件模型进行生成可以重建真实图像,但使用非零水平的无分类器引导会完全偏离真实图像,如图5的 bottom row所示。我们提出应用Inside-Outside Attention来缓解这种权衡。与先前工作可将标记与整个图像关联[7,36]类似,借助Inside-Outside Attention,我们可以将标记与特定空间区域关联。如图5的 top row所示,在反演和生成过程中应用我们的机制,能够在使用无分类器引导的同时实现真实图像的重建和编辑。我们还可视化了标记“dog”的交叉注意力图,其中使用我们的机制时,其影响被限制在轮廓范围内,不会影响背景中的椅子;而不使用我们的机制时,其影响会扩散到背景中,在改变狗形态的同时移除了椅子。
Method Summary
总之,我们观察到,如果去除虚假注意力,物体形状可以得到更好的保留,为此我们提出了一种新颖的推理时机制——内外注意力。我们的方法Shape-Guided Diffusion(形状引导扩散)使用内外注意力在反转和生成过程中约束注意力图,如图3所示。Shape-Guided Diffusion算法定义如下(另见图1算法)。如果未提供掩码,我们使用形状推理函数InferShape(·)识别图像中的Psrc。在实验中,我们使用现成的分割模型[4],但任何文本接地方法也可与我们的方法结合使用。我们在提示Psrc(例如,“dog”)驱动的条件扩散模型上运行内外反转,以获得反转噪声zˉT\bar{z}_TzˉT。然后,我们将初始噪声zTz_TzT设为zˉT\bar{z}_TzˉT。对于每个采样步骤,我们使用掩码m和Pedit(例如,“dog wearing a colorful shirt”)对条件和无条件扩散模型应用内外注意力。我们使用Ho等[9]的原始公式混合两个模型的预测,该公式对条件预测应用无分类器引导(图1算法,第10行)。在早期实验中,我们发现这种设计选择在不损失其他指标的情况下实现了更高的文本对齐度。最后,我们复制反转过程中找到的真实图像背景zˉt−1⋅m\bar{z}_{t-1} \cdot mzˉt−1⋅m,形成编辑后的图像预测zt−1z_{t-1}zt−1。这确保编辑后的图像xeditx_{\text{edit}}xedit和原始图像xsrcx_{\text{src}}xsrc仅在掩码区域m内存在差异。
MS-COCO ShapePrompts
Benchmark 我们在MS-COCO图像[14]上评估我们的方法。遵循图像修复领域的先前工作[33],我们筛选出面积占图像[2%,50%]的目标掩码。我们的测试集源自MS-COCO val2017,包含1149个目标掩码,涵盖动物、交通工具、食物和运动用品等10个类别。我们以相同方式从MS-COCO train2017中构建了一个包含1000个目标掩码的验证集。针对每个类别,我们设计了一些提示词,用于添加衣物或配饰(例如,“花衬衫”或“太阳镜”)、改变颜色(例如,“彩虹色”、“带有喷漆涂鸦”)、更换材质(“乐高”、“纸张”)或指定稀有子类别(“斑点豹猫”、“玉米饼卷三明治”)。有关提示词的更多信息可参见补充材料。指标由于我们旨在合成忠实于输入形状的图像,因此使用平均交并比(mIoU)作为指标。具体而言,我们计算掩码区域内被正确合成为目标物体类别的像素比例,这由在COCO-Stuff [3]上训练的分割模型[4]确定。由于动物目标掩码特别精细,且mIoU无法全面反映退化情况(例如,如果编辑将猫的全身替换为猫头),我们还为动物类别计算了关键点加权mIoU(KW-mIoU)。具体而言,我们通过动物关键点检测模型[39]确定源图像与编辑后图像的正确关键点百分比,并以此为权重对每个样本的mIoU进行加权。我们还报告了FID分数作为图像真实感的指标,该指标使用Inception网络的特征来衡量真实图像和合成图像分布的相似度[21,34]。最后,我们报告了CLIP[23]分数作为图像-文本对齐的指标,该指标使用大型预训练图像-文本模型的特征来衡量文本提示和合成图像的相似度。有关指标的更多信息可参见补充材料。
