自回归解码-》贪心解码
一 自回归解码
当前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理阶段采用自回归采样,特点如下:
模型使用前缀作为输入,将输出结果处理+归一化成概率分布后,采样生成下一个token。
从生成第一个 Token之后,开始采用自回归方式一次生成一个 Token,即当前轮输出token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,然后解码。
重复执行2。在后续执行过程中,前后两轮的输入只相差一个 token。
直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束。
1.1 自回归采样的缺点:
因为在生成文本时,自回归采样是逐个 token 生成的,生成下一个 token 需要依赖前面已经生成的 token,这种串行的模式导致生成速度慢,效率很低。
假设输出总共有 N 个 Token,则 Decoding 阶段需要执行 N-1 次 Forward,这 N-1 次 Forward 只能串行执行。
在生成过程中,需要关注的 Token 越来越多(每个 Token 的生成都需要和之前的 Token 进行注意力计算),计算量也会随之增大。
大型模型的推理过程往往受制于访存速度。因为推理下一个token的时候,需要依赖前面的结果。所以在实际使用GPU进行计算时,需要将所有模型参数以及kv-cache移至片上内存进行运算,而一般来说片上内存带宽比计算性能要低两个数量级,这就使得大模型推理是memory-bandwidth-bound的,内存访问带宽成为严重的瓶颈。
另外,大模型的能力遵循scaling law,也就是模型的参数越多其拥有的能力越强,而越大的模型自然就需要越多的计算资源。scaling law告诉我们,我们没有办法通过直接减小模型的参数量来减小访存的访问量。
1.2 针对推理的工程优化
- 改进的计算核心实现、多卡并行计算、批处理策略等等。
其中,最朴素的做法就是增大推理时的 Batch size,比如使用 dynamic batching,将多个请求合并处理,将矩阵乘向量重新变为矩阵乘操作,在 Batch size 不大的情况下,几乎可以获得 QPS 的线性提升。然而,这些方法并没有从根本上解决LLM解码过程是受制于访存带宽的问题。- 对模型以及KV Cache进行量化,使每一个token生成过程中读取模型参数时的总比特数减小,缓解io压力。
- increasing the arithmetic intensity,即提高“浮点数计算量/数据传输量”这个比值,让数据传输不要成为瓶颈。
- reducing the number of decoding steps,即缩短解码步骤。投机解码就属于这个范畴。
二 投机解码
Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation
投机解码(Speculative Decoding)允许我们将在同一个用户请求内的多个 Token 一起运算。其目的和 dynamic batching 类似,也是为了将矩阵乘向量重新变为矩阵乘操作,这很适合无法获得更大 Batch size 或者只想降低端到端延时的场景。
投机解码一般使用两个模型:
Draft Model(草稿模型)快速生成多个候选结果,
Target Model(目标模型)并行验证和修改,最终得到满意答案。具体而言:
- draft model用来猜测。
draft model推理较快,承担了串行的工作,它以自回归的方式生成K个tokens,从而让目标模型能够并行的计算。- target model用来评估采样结果\审核修正。
target model通过并行计算多个token来从自回归模型中采样,用推理结果来决定是否使用draft model生成的这些tokens
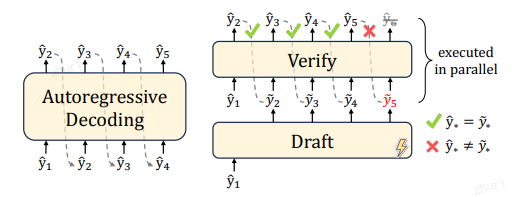
投机解码无需对输出进行任何更改,就可以保证和使用原始模型的采样分布完全相同,因此和直接用大模型解码是等价的。下图右侧,
草稿模型先生成5个预测token后,将5个token一起输入给目标模型。以该前缀作为输入时,目标模型会生成若干token,然后进行验证。
绿色表示草稿模型生成的token和目标模型生成的token一致,预测token通过了“验证”——这个token本来就是LLM自己会生成的结果。
红色token是没有通过验证的“推测”token。第一个没有通过验证的“推测”token和其后续的“推测”token都将被丢弃。因为这个红色token不是LLM自己会生成的结果,那么前缀正确性假设就被打破,这些后续token的验证都无法保证前缀输入是“正确”的了。
2.1 历史
2.1.1 Speculative Decoding
论文“Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation”是第一篇提出 Speculative Decoding 这个词的文章,也确立了使用 draft-then-verify 这一方法加速 Auto-Regressive 生成的范式。
Speculative Decoding 希望解决的是现有的 Autoregressive 模型推理过慢的问题。
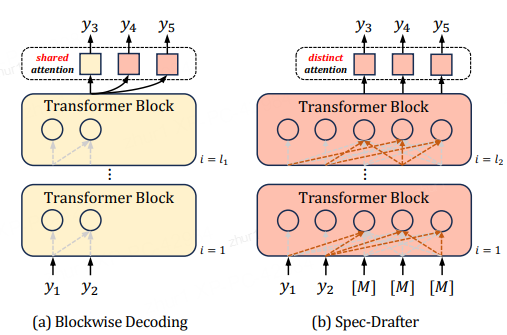
下图(a)是Blockwise Decoding,其在目标自回归模型上引入了k − 1个FFN头,这些头使用共享注意力(shared attention)来预测下面k个tokken。(b)是Spec-Drafter模型,该模型是预测草稿token的独立模型,它使用不同的query来预测每个草稿token。下图上黄色部分是自回归AR模型,红色部分是新加入的模块。
2.1.2 Speculative Sampling
论文“Fast Inference from Transformers via Speculative Decoding”最早提出了 Speculative Sampling。此文章和上一篇文章是同时期的研究,被认为是SD的开山之作,后续许多研究都是基于此来展开。本文用 target model(目标模型)指代待加速的大模型,用 approximation model(近似模型)指代用来帮助加速大模型的小模型。
后续我们统一使用speculative decoding这个术语。
接下来,我们先对本领域的先驱之作"Blockwise Parallel Decoding"做简要分析,然后再结合两篇开山之作进行学习。
2.2 Blockwise Parallel Decoding 分块并行解码
论文“Blockwise Parallel Decoding for Deep Autoregressive Models”提出的Blockwise Parallel Decoding是本领域的先行之作,或者说并行解码的第一个工作
Blockwise Parallel Decoding(BPD)使用多头的方式生成候选序列(一个串行序列),然后进行并行验证。
2.2.1 动机–串行贪心解码的低计算效率问题
BPD旨在解决Transfomer-based Decoder串行贪心解码的低计算效率问题:
在序列生成时是串行的一个一个 Token的生成,计算量和生成结果所需的时间与生成的 Token 数目成正比。
我们接下来看看BPD的出发点和思路。具体如下。
- 假设输出序列的长度为 m,那么 Autoregressive Decoding 要执行 m 步才能获得最终结果,随着模型的增大,每一步的时延也会增大,整体时延也会放大至少 m 倍。
- 因为每次进行一个token生成的计算,需要搬运全部的模型参数和激活张量,这使解码过程严重受限于内存带宽。
为了克服上述限制,BPD的改进动机如下。
- 作者期望通过 n 步就可完成整个预测,其中 n 远小于 m。
- 但是如何打破串行解码魔咒,并行产生后k个token?因为语言模型都是预测下一个token,如果我们有k-1个辅助模型,每个模型可以根据输入序列跳跃地预测后2到k个位置的token。那么,辅助模型和原始模型就有可能独立运行,从而并行生成后k个token。
2.2.2 思路–加速解码过程
该方案通过训练辅助模型(通过在原始模型的Decoder后面增添少量参数),使得模型能够预测未来位置的输出(并行地预测并验证后k个token),然后利用这些预测结果来跳过部分贪心解码步骤,从而加速解码过程。具体而言,BPD提出了使用特殊drafting heads的draft-then-verify范式,其三个阶段分别是Predict、Verify和Accept阶段。
- Predict 阶段:一个原模型 + (k-1)个辅助模型。
论文将模型原来的单 head(最后用于预测 Token 分布的 MLP)转换为多个 head,第一个 head 为保留原始模型的 head,用于预测下一个 Token,后面新增的 head 分别预测后续k-1个Token- Verify(验证)阶段: 使用原模型并行地验证这k个位置上候选词所形成的几种可能。
(由于模型计算本身是 IO bound,并行验证增加的计算几乎不会增加推理的时延)。
Verify 过程会将这些token组成batch,实现合适的attention mask,一次性获得这个k个位置的词表概率。因为第一个 head 就是原始模型的 head,所以结果肯定是对的,这样就可以保证每个 decoding step 实际生成的 Token 数是 >= 1 的,以此达到降低解码次数的目的。另外,在验证同时也可顺带生成新的需要预测的 Token。- Accept阶段: 会接受验证过的最长前缀,附加到原始序列上。
此阶段会贪心地选择概率最大的token,如果验证结果的token和Predict阶段预测的token相同则保留。如果不同,则后面的token预测都错误。
需要说明的是,这篇论文的工作只支持贪婪解码(Greedy Decoding),不适合其他的解码算法(而Speculative Sampling可以适配Beam Search),在不牺牲效果的情况下,有效 Token 数可能并不多。而且模型还需要使用训练数据进行微调。因此,Blockwise Parallel Decoding=multi-draft model +top-1 sampling+ parallel verification。受此启发,后续提出的Speculative Sampling方法也使用小模型并行预测,大模型验证的方式解决相同的问题。
2.2.3 架构 — 共享backbone, 原模型+辅助模型
原始模型 p 外,辅助模型 p2,…,pk 。
如果这些辅助模型采用和原始模型 p 同样的结构并单独训练,那么在 Predict 阶段的计算量就是生成一个 Token 的 K 倍。即使忽略 Verify 阶段,理想情况下整个训练任务的计算量也没有降低。而且这K个模型对于内存的占用将是非常惊人的。
因此,p2,…,pk 并非是独立的原始模型的副本。让这些辅助模型与原始模型 p1 共享 backbone,然后增加一个隐藏层,针对每个模型 p1,…,pk 都有独立的输出层。这样就就可以让新模型具备预测后k个token的能力,能保证 Predict 段实际的计算量与之前单个 Token 预测的计算量基本相当。
具体模型架构如下图所示,在原始模型之上一共增加了三层(从下至上):
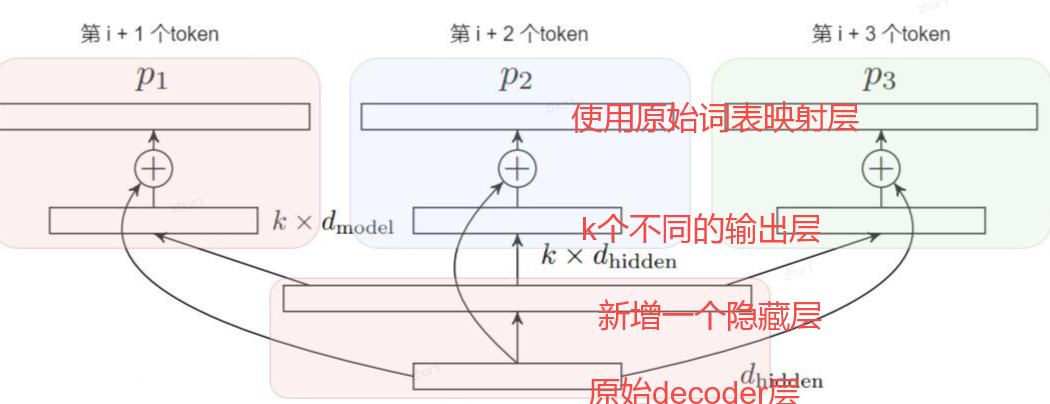
2.2.4 训练–随机均匀选择其中的一个layer输出作为loss
改造后的模型还需要使用训练数据进行训练。由于训练时的内存限制,论文无法使用对应于k个project layer输出的k个交叉熵损失的平均值作为loss。而是为每个minibatch随机均匀选择其中的一个layer输出作为loss。
假设要生成的序列长度为m ,并行Head数为 K。自回归生成方法中,总共需要 m 步执行。
BDP中,对每 个token执行一次上述三阶段过程,
predict阶段执行1步产出多个Head的输出,
verify阶段并行执行1步,accept阶段不耗时。
因此在理想情况下(每次生成的 K 个 Token 都能接受),总的解码次数从 m 降低到 2m/K。
这其中由于 Predict 阶段 p1 和 Verify 阶段都使用的原始模型,所以只使用两次原模型。
2.2.5 优化–verify和predict重叠
由于存在 Predict 和 Verify 两个阶段,因此即使理想情况下整体的解码次数也是 2m/K,而不是最理想的 m/K。事实上,由于 Predict 阶段的模型有共同的 backbone,并且 Verify 阶段使用的模型也是原始模型 p1,因此就可以利用第 n 步的 Verify 结果来直接生成第 n+1 步的 Predict 结果。
于是作者们进一步优化这个算法,在原始模型验证时同时预测后k个token。这样Predict和Verify阶段可以合并,验证同时也获得了后k个token的候选。
优化之后,
模型第一次推理只执行predict阶段( 1 步),调用一次原始模型。
然后进入verify和predict重叠的阶段,每次处理序列往前走 K 长度,直到生成终止token(共m/k步,调用m/k次原始模型)。即m/K,
除了第一次迭代,每次迭代只需调用一次模型forward,而不是两次,从而将解码所需的模型调用次数减半。进一步将模型调用次数从2m/k减少到m/k + 1。
2.2.6 收益
这种方案之所以可以加速解码,在于Verify阶段可以用基础模型 p1 并行对k个预测token进行同时解码。因为每个迭代Predict阶段产生k个token可以看成一个block,故这种方法被称为blockwise parallel decoding。这种方法推理时得到的结果和自回归方式解码的结果一样,因此没有任何生成效果的精度损失。
Blockwise Decoding的速度取决于执行模型forward的次数。
在访存受限的情况下,对”I saw a dog ride”进行forward运算的时间和对“I saw a dog ride in the car”进行forward运算的时间近似相同,因为它们都需要访问模型参数和KV Cache,多出几个tokens带来的激活访存开销显得微不足道。
2.3 投机解码
2.3.1 观察
- 困难任务包含容易子任务。
- 内存带宽和通信是大模型推理的瓶颈。LLM每个解码步所用的推理时间大部分并不是用于模型的前向计算,而是消耗在了将LLM巨量的参数从GPU显存(High-Bandwidth Memory,HBM)迁移到高速缓存(cache)上(以进行运算操作)。这意味着在某些情况下,适当增加计算量并不会影响推理速度,可以用于提高并发性。
- 大模型在做推理任务(decoding阶段)时,往往batch size为1,一次只能生成一个token,无法并行计算,导致大量算力冗余。事实上,在数量增加有限的情况下,输入多个tokens和输入一个token单轮的计算时延基本一致。如果我们能让大模型一次处理一批tokens,就能利用上算力,让大模型达到计算和访存平衡。
2.3.2 借鉴–猜测性执行
“Speculative execution”(猜测性执行)是一种在处理器(CPU)中常见的优化技术。
它的基本思想是在不确定某个任务是否真正需要执行时,提前执行该任务,然后再来验证被执行任务是否真的被需要,这样做的好处可以增加并发性和性能,一个典型的例子是分支预测(branch prediction)。在
处理器中,"speculative execution"通常用于处理分支(branch)指令。
当处理器遇到一个分支指令时,它不知道分支条件的具体结果,因此会选择一条路径来执行。
如果分支条件最终符合预期,那么一切正常,程序将继续执行。
但如果条件不符合,处理器会回滚到分支前的状态,丢弃之前的操作,然后选择正确的路径进行执行。
2.3.3 思路
投机解码使用两个模型:
一个是原始target model(目标模型)
另一个是比原始模型小得多的draft model(近似模型/草稿模型)。
draft model和target mode联合推理,draft模型生成γ个token,而target模型则去验证γ个token是否为最后需要的token。
就是使用一个小模型来生成多个草稿token,然后使用大模型对这多个草稿token做并行验证、纠正和优化。这样就可以在接近大参数模型的生成一个token的时间里面生成多个tokens。我们来做具体分析。
“投机解码"指的是用小模型的输出去投机。
先用更高效的近似小模型预测后续的若干个tokens(一些可能的推理结果,这些结果被称为"speculative prefixes”),这充分利用了小模型decoding速度快的优点。
解码过程中,某些token的解码相对容易,某些token的解码则很困难。因此,简单的token生成可以交给小型模型处理,这些小模型应该也可以获取正确的预测结果。而困难的token则交给大型模型处理。如果当前的问题比较简单,则小模型有更大的可能猜对多个token。
2.3.4 投机解码实现加速的关键
主要在于如下两点:
- “推测”的高效性和准确性:如何又快又准地“推测”LLM未来多个解码步的生成结果。
- “验证“策略的选择:如何在确保质量的同时,让尽可能多的“推测”token通过验证,提高解码并行性。
因此,研究人员通常基于这两点来对投机解码的实现和研究进行分类。当然,其分类方式也会略有差别。下图是论文“Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding”给出的投机解码技术的一个正式分类,包括:
- draft model的策略。具体涵盖如何设计模型,运行终止条件,如何管理多个模型(如果有)。
“推测”阶段的设计聚焦在“推测精度(accuracy)”和“推测耗时(latency)“的权衡上。一般来说,用以推测的模型越大,推测精度越高(即通过验证的token越多),但是推测阶段的耗时越大。如何在这两者之间达到权衡,使得推测解码总的加速比较高,是推测阶段主要关注的问题。- 验证策略。此类别涉及到验证方案和验收标准的设计。
验证模型通常是目标模型,其首要目的是保证解码结果的质量。接受标准旨在判断草稿token是否应(部分)接受,即接受的token长度是否小于k。在每个解码步骤中,验证模型会并行验证草稿token,以确保输出与目标LLM对齐。此过程还决定了每一步接受的token数量,这是影响加速的一个重要因素。采样方法具体来说也分为无损采样和有损采样。
(a)无损采样主要是说对于原始LLM来说仍然采用原先的采样方法比如贪婪采样或者温度采样等等,然后对应地检查draft中是否有符合要求的token。这种方法核心就是drafting对于原始LLM来说完全透明,不会损失模型性能。
(b)有损采样主要是说通过校验阶段对draft质量的评估,然后根据一些先验的阈值来筛选一些高质量的draft接受,这种方法的核心就是为了提高draft的接受率,在可接受的一些质量损失情况下获得更高的加速。常见验证标准包括Greedy Decoding,Speculative Sampling,Token Tree Verification等。因为,并不是所有概率最大的token都是最合适的解码结果,所以也有一些工作提出可以适当地放松“验证”要求,使得更多高质量的“推测”token被接受,进一步提升加速比。
参考:探秘Transformer系列之(30)— 投机解码