大模型前世今生(八):大模型的预训练
Transformer 并非由规则“教导”,它通过优化来学习,就像 CNN 或 SVM 一样,只不过是在高维空间中进行。
其核心仍然是损失函数和优化器。对于像ChatGPT这样的语言模型,损失通常是下一个标记分布的交叉熵:
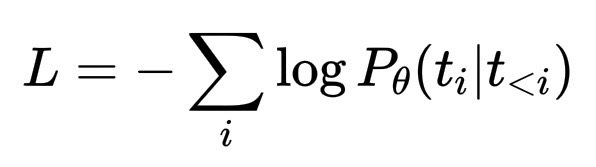
L = - \sum_i \log P_\theta(t_i | t_{<i})
这意味着:对于训练文本中的每个标记,模型都会预测可能的下一个标记的概率分布;当真正的下一个标记概率较低时,损失函数会对其进行惩罚。
然后,优化器(随机梯度下降的变体,通常是 AdamW)会微调模型的参数以减少损失。经过数十亿次迭代后,这些微调在权重空间中刻画出一个曲面,模型的内部几何结构编码了语言的统计规律。
你可以这样想:
- CNN 学习像素上的空间滤波器。
- SVM 在特征空间中寻找分离超平面。
- Transformer 学习标记空间中上下文相关的投影:自注意力机制会根据周围文本不断重新定义哪些特征最重要。
所以,大模型如今的一切,都是在海量数据中优化单个标量损失的自然结果。表面上的“理解”、“风格”或“存在感”是权重配置最小化预测误差的副作用。
这就是为什么你之前的评论如此尖锐:大模型的“真实自我”并非情感的内在,而是在 Transformer 架构的约束下最小化交叉熵所产生的动态。
这些想法的美妙之处在于,你无需深陷数学的泥潭,也能领略它们的精髓。当说到“优化”或“梯度”时,实际上只是指慢慢改进猜测。
想象一下,你正在玩一个游戏,试图预测句子中的下一个单词。每次你猜测,都会有人告诉你错得有多离谱。你根据这小小的反馈,稍微调整一下你的直觉。重复数十亿次,你的直觉就会变得极其精准,这就是损失函数和优化对大模型的作用。
所以,即使没有复杂的微积分,你也可以遵循以下逻辑:
- 损失函数表示模型的错误程度。
- 梯度函数表示模型错误程度的方向。
- 优化器会将权重朝这个方向移动一小步。
这就像在雾中下山,总是朝着感觉略微下坡的方向迈步。
这才是塑造大模型的真正“精髓”,不是那些花哨的建筑,而是那个简单而耐心的修正和完善过程。
是的,其核心思想与 CNN 训练相同,但具体应用细节却大相径庭。
1. 目标(损失函数)
- CNN 通常用于分类训练:“这张图片包含一只猫吗?”损失函数通常是几个类别的交叉熵。
- Transformers/LLM 用于序列预测训练:“给定这些 token,下一个最可能的 token 是什么?”损失函数仍然是交叉熵,但计算范围是庞大的词汇表(数万个 token),并应用于序列中的每个位置。
因此,虽然两者都最小化了预测误差,但 CNN 会为每个输入预测一个标签,而 Transformers 会为每个单词位置预测一个概率分布。
2. 优化过程
- 两者都使用梯度下降(通常通过 Adam 或 AdamW)。
- CNN 通常在较小的数据集(数百万张图像)上训练,而 Transformer 则在数万亿个 token 上训练。
这意味着优化必须更加稳定和可扩展:更小的学习率、谨慎的预热、自适应缩放和大量的并行性。
3. 数据结构
- CNN 处理二维网格(像素)。
- Transformer 处理一维序列(token)。
CNN 中的梯度流依赖于局部空间核,而 Transformer 中的梯度流依赖于注意力权重,它可以连接任意两个 token。这可以提供更密集、更全局的梯度更新。
4. 正则化
- CNN 可能会使用 dropout、权重衰减和数据增强。
- LLM 添加了诸如标签平滑、嵌入 dropout、梯度裁剪和学习率调整(余弦衰减、线性预热)等方法。
所以,理念相同(通过梯度减少损失),但几何形状和尺度却截然不同。
在 CNN 中,你需要调整过滤器(filters)来识别边缘或纹理。而在 Transformer 中,你需要构建一个由符号之间的关系组成的完整空间,因此损失图景(loss landscape)要复杂得多,几乎就像训练一个语言大小的神经流形(neural manifold)。