鸟哥的Linux私房菜 第三部分: 学习shell与shell script
一. 第9章: vim程序编辑器
9.1 vi与vim
vi(Visual Editor):Unix 系统的经典文本编辑器(1976年由 Bill Joy 开发)
vim(Vi IMproved):vi 的增强版,由 Bram Moolenaar 于1991年发布,完全兼容 vi 的操作,并新增大量功能
i插入、ESC命令模式、:wq保存退出
掌握 vim 的分屏(:sp)、多标签(:tabnew)和插件管理
分屏、寄存器、插件管理
9.2 vi的使用
一、vi 的三种模式
关键:任何模式下按
模式
进入方式
作用
提示符/状态
命令模式
启动时默认或按
ESC执行复制、删除、搜索等操作
屏幕底部无提示
插入模式
按
i、a、o等编辑文本内容
显示
-- INSERT --末行模式
按
:(命令模式下)保存、退出、搜索替换等
显示
:输入框ESC均可返回命令模式(避免卡在编辑状态)二、基础操作速查表
1. 启动与退出
命令
说明
vi filename打开/新建文件
:w保存文件
:q退出(未修改时)
:q!强制退出(不保存修改)
:wq或ZZ(命令模式)保存并退出
2. 光标移动(命令模式下) 左下上右
按键
功能
记忆技巧
h左移
←
j下移
↓
k上移
↑
l右移
→
0跳到行首
数字零
$跳到行尾
gg跳到文件第一行
"go to start"
G跳到文件最后一行
"Go"(大写)
20G跳到第20行
数字+G
3. 文本编辑
命令
功能
i在光标前插入
a在光标后插入
o在下一行插入新行
O(大写)在上一行插入新行
x删除光标处字符
dd删除当前行
5dd删除从当前行开始的5行
yy复制当前行
p粘贴到光标后
P(大写)粘贴到光标前
u撤销上一次操作
Ctrl + r重做(仅部分 vi 支持)
三、高效技巧
1. 搜索与替换
命令
功能
/keyword向下搜索关键词(按
n跳下一个)
?keyword向上搜索
:%s/old/new/g全局替换 old 为 new
:20,30s/old/new/g替换第20-30行的 old 为 new
2. 文本块操作
复制多行:
5yy→ 复制5行粘贴:移动光标到目标位置按
p删除到行尾:
d$(命令模式)删除单词:
dw(从光标处删到词尾)
9.2.4 vim的缓存,恢复与打开时的警告信息
当你用Vim编辑文件时,Vim通常会在原文件所在目录下自动生成一个名为.文件名.swp的隐藏文件(例如,编辑example.txt会生成.example.txt.swp),用于记录你的编辑操作和缓冲区内容。当Vim正常保存文件并退出后,这个.swp文件会被自动删除
⚠️ 处理警告信息
如果Vim打开文件时发现已存在对应的
.swp文件(通常会提示类似E325: ATTENTION的警告信息),这通常意味着上次的编辑会话可能未正常结束。请根据你的具体需求选择操作:
只想查看文件内容,不做修改:选择
O(Open Read-Only)。确认没有其他Vim实例在编辑该文件,且不需要恢复未保存内容:选择
D(Delete it) 删除缓存文件后正常编辑。希望恢复上次未保存的编辑内容:选择
R(Recover)。恢复成功后,务必保存文件,并建议手动删除对应的.swp文件,否则下次打开仍会提示。确定要在忽略缓存内容的情况下编辑原文件:选择
E(Edit anyway)。请注意,如果确实存在多个编辑实例,此操作可能导致更改冲突
9.3 vim的额外功能
功能类别
核心命令/操作
主要用途
可视区块 (Visual Block)
v(字符选择),V(行选择),Ctrl+v(区块选择)对文本进行非连续列或矩形区域操作,如批量注释、列编辑
多文件编辑
vim file1 file2,:n(下一个),:N(上一个),:files(列表)在单个 Vim 会话中依次编辑多个文件,支持文件间复制粘贴
多窗口功能
:sp(水平分割),:vsp(垂直分割),Ctrl+w hjkl(切换窗口)同时查看和编辑多个文件或同一文件的不同部分
关键词补全
Ctrl+x Ctrl+n(文件内容),Ctrl+x Ctrl-f(文件名)输入时自动补全单词或文件名,减少击键并避免拼写错误
环境设置与记录
~/.vimrc(配置文件),~/.viminfo(操作历史)定制 Vim 行为(如行号、语法高亮)和恢复上次编辑状态
宏录制与回放
q(开始/停止录制),@(回放宏)录制并重复一系列操作,自动化重复性编辑任务
标签页
:tabnew,gt(下一个),gT(上一个)像现代浏览器一样,以标签页形式组织多个文件
代码折叠
zf(创建折叠),zo(打开),zc(关闭)折叠代码块,专注于当前正在处理的部分,提升代码阅读体验
可视区块的妙用:使用
Ctrl+v进入区块选择模式后,选中一列,按I(大写i)进入插入模式,输入内容后按ESC,你输入的内容会应用到选中的每一行。这在批量添加行注释(如//或#)时特别方便 。多窗口的协同工作:你可以使用
:sp或:vsp分割窗口后,通过Ctrl+w配合方向键(或h/j/k/l)在窗口间快速跳转。需要对照修改代码或文档时,这个功能非常实用
9.3.4 vim的关键词补全功能
触发命令
补全类型
适用场景
Ctrl + n当前文件关键字补全
补全当前文件中出现过的单词
Ctrl + x Ctrl + f文件名补全
输入文件路径时自动提示目录和文件
Ctrl + x Ctrl + i包含文件补全
补全
#include或import的库文件提示:
先按
Ctrl + x进入补全模式,再按第二键(如Ctrl + f)。用
Ctrl + n/Ctrl + p在补全列表中上下切换关键字补全 (
Ctrl + n/Ctrl + p)
补全当前文件或打开缓冲区中出现过的单词(变量名、函数名等)
文件名补全 (Ctrl + x Ctrl + f)
快速输入文件路径。
9.3.5 vim环境设置与记录:~/.vimrc, ~/.viminfo
文件
路径
作用
生效方式
~/.vimrc用户家目录
配置文件:定制 Vim 行为(界面、快捷键、插件等)
启动 Vim 时自动加载
~/.viminfo用户家目录
历史记录:保存编辑状态(光标位置、命令历史、寄存器内容等)
退出 Vim 时自动更新
linux中$使用方法1.变量取值,边界问题
name="Alice" echo $name # 输出:Alice echo ${name} # 明确边界(推荐)echo "$name_01" # 错误!尝试读取 name_01 变量 echo "${name}_01" # 正确:Alice_012.命令替换(捕获命令输出)
echo "Today is $(date)" # 输出:Today is Wed Oct 9 14:30:00 CST 2025 files=`ls` # 旧式语法(与 $() 等效)disk_usage=$(df -h | grep '/dev/sda1') # 获取磁盘使用信息三. 算术运算
result=$(( 10 + 5 * 2 )) # 输出:20 count=5 echo $(( count++ )) # 输出:5(后置递增)四.特殊变量
变量
含义
示例
$?上条命令退出状态
ls; echo $?(0 表示成功)
$$当前 Shell 进程 ID
echo $$→ 输出 1234
$0当前脚本名称
echo "$0"→myscript.sh
$1-$9脚本参数
./script.sh foo bar→$1="foo"
$#参数个数
echo $#→ 2
$@所有参数列表
for arg in "$@"; do ...
$*所有参数合并为单字符串
echo "$*"→ "foo bar"五.默认值处理
# 空值时使用默认值 echo ${NAME:-"Guest"} # 若 $NAME 为空,输出 Guest# 空值时赋值并输出 echo ${NAME:="Admin"} # 若 $NAME 为空,将其设为 Admin# 空值时报错退出 ${VAR:?Error message} # 若 $VAR 为空,显示错误并终止脚本六.字符串处理
path="/home/user/docs/file.txt"echo ${#path} # 长度:26 echo ${path:6} # 截取:/user/docs/file.txt echo ${path:6:4} # 截取:/use echo ${path%.*} # 删后缀:/home/user/docs/file echo ${path%%.*} # 贪婪删后缀:/home/user/docs/file echo ${path#*/} # 删前缀:home/user/docs/file.txt echo ${path##*/} # 贪婪删前缀:file.txt echo ${path/docs/logs} # 替换:/home/user/logs/file.txt
七:进程信息echo $PPID # 父进程 ID(Parent Process ID) echo $BASHPID # 当前 Bash 进程 ID(与 $$ 可能不同)与正则表达式的区别:
Shell 中
$表示变量取值正则中
$表示行尾锚点(如grep "end$" file)
语法
用途
经典场景
$var变量取值
获取配置参数
$(cmd)命令替换
动态生成文件名
$(( 10+5 ))算术运算
循环计数器
$?上条命令退出状态
错误处理
$$当前进程 ID
生成临时文件名
${var:-default}空值默认值
安全使用未定义变量
${str:start:length}字符串截取
路径处理
9.4 其他vim使用注意事项
编码问题GBK与UTF-8,换行符在DOS与Linux不同,学不会,下次再学
二. 第10章: 认识与学习BASH
10.1 认识BASH这个shell
10.1.1 硬件,内核与Shell
三层协作流程示例
场景:用户执行
cat /home/user/file.txt步骤分解:
Shell 层:
接收命令
cat /home/user/file.txt解析命令,找到
/bin/cat程序内核层:
为
cat进程分配内存和 CPU 时间通过文件系统调用读取
/home/user/file.txt检查文件权限(是否可读)
硬件层:
硬盘控制器定位文件物理位置
从磁盘读取数据到内存
通过网络/显示硬件输出结果
返回流程:
硬件返回数据 → 内核处理 → Shell 显示到终端
10.1.3 系统的合法shell与/etc/shells功能
合法 Shell:被系统明确允许作为用户登录环境的解释器程序核心要求:
必须是可执行二进制文件(如
/bin/bash)必须在
/etc/shells文件中明确列出典型合法 Shell
Shell 路径
名称
特点
/bin/bashBash
Linux 默认 Shell,功能强大
/bin/shBourne Shell
兼容性高,脚本标准
/bin/zshZ Shell
高级交互功能,插件丰富
/bin/fishFriendly Shell
用户友好,语法高亮
/sbin/nologin伪 Shell
禁止登录(系统账户专用)
/etc/shells文件详解文件作用
白名单机制:定义系统允许的所有合法 Shell
权限控制:限制用户只能使用列表中指定的 Shell
10.1.4 Bash shell的功能
Bash(Bourne-Again Shell)是 Linux 系统中最主流的 Shell,它不仅是命令解释器,更是强大的脚本引擎和用户交互环境
1.命令历史 永久记录:~/.bash_history文件保存所有执行过的命令#快捷调用 !! # 上一条命令 !$ # 上条命令的最后一个参数 !vim # 执行最近以 vim 开头的命令历史搜索:
Ctrl+R:反向搜索历史命令
history | grep "关键词"2.命令补全
类型
触发键
示例
命令补全
Tab输入
sys+Tab→systemctl文件路径补全
Tab输入
/et+Tab→/etc/参数补全
Tab两次
ls --+Tab→ 显示所有选项3.命令别名
alias ll='ls -alF' # 详细列表 alias rm='rm -i' # 删除前确认 alias update='sudo apt update && sudo apt upgrade'4.作业控制-多任务调度
命令
功能
示例
&后台运行
sleep 10 &
jobs查看后台任务
jobs -l
fg %n前台恢复任务
fg %1
bg %n后台暂停任务
bg %2
Ctrl+Z暂停前台任务
Ctrl+C终止任务
tar -czf backup.tar.gz /data & # 后台压缩 jobs # 查看任务ID fg %1 # 切回前台监控5.Shell脚本编程--自动化利器
功能
语法示例
用途
变量
name="Alice"; echo $name存储数据
条件判断
if [ -f file.txt ]; then ... fi文件检查
循环
for i in {1..5}; do ... done批量操作
函数
myfunc() { echo "Hello"; }代码复用
数组
arr=(a b c); echo ${arr[1]}存储集合
6.环境配置
件
生效范围
典型用途
/etc/profile全局用户
系统级 PATH、环境变量
~/.bash_profile登录 Shell
用户级环境初始化
~/.bashrc交互式 Shell
别名、函数、提示符
~/.bash_logout退出登录
清理临时文件
7.重定向与管道-数据流控制
ls > file.txt # 输出重定向(覆盖) ls >> file.txt # 输出重定向(追加) grep "error" < log.txt # 输入重定向
10.1.5 查询命令是否为Bash shell的内置命令:type
type命令是识别命令类型的神器,它能精准判断一个命令是内置命令、外部程序还是别名/函数
输出示例
含义
ls 是 /usr/bin/ls外部程序(磁盘上的可执行文件)
cd 是 shell 内建内置命令(Bash 自带功能)
ll 是ls -l' 的别名`别名(用户定义的快捷方式)
myfunc 是一个函数Shell 函数(自定义代码块)
1.
-t:精简类型标识type -t 命令名$ type -t cd builtin$ type -t ls file$ type -t ll alias输出单关键词:
file:外部程序
builtin:内置命令
alias:别名
function:函数2.
-a:显示所有匹配项 作用:按优先级列出所有同名实体(别名→函数→内置→外部程序)type -a 命令名$ type -a echo echo 是 shell 内建 # 内置命令优先 echo 是 /usr/bin/echo # 外部程序$ type -a ls ls 是 `ls --color=auto' 的别名 # 别名优先 ls 是 /usr/bin/ls # 实际程序3.
-f:禁止别名和函数查找 作用:跳过别名和函数,只检查内置命令和外部程序type -f 命令名# 假设定义了别名:alias ls='ls -F' $ type ls ls 是 `ls -F' 的别名$ type -f ls ls 是 /usr/bin/ls # 忽略别名4.
-P:强制搜索 PATH 路径 仅显示外部程序的完整路径(找不到则不输出)type -P 命令名$ type -P python /usr/bin/python$ type -P notexist (无输出)
命令
功能
局限
type识别所有类型(内置/别名/函数/外部)
Bash 专属
which只查外部程序路径
忽略内置命令
whereis查二进制+源码+手册
不识别别名/函数
10.1.6 命令的执行与快速编辑按钮
命令的执行之旅
当你在终端按下回车键后,一个精密的流程便开始了:
Shell解析:Shell(如Bash)首先会解析你输入的命令行,将其拆分为命令名、选项和参数。它还会处理特殊符号,比如管道
|和重定向>。判断命令类型:Shell接着判断命令是内部命令(如
cd,echo)还是外部命令。内部命令由Shell自身直接执行,而外部命令对应着磁盘上的一个可执行文件 。查找外部命令:对于外部命令,Shell会在由
PATH环境变量定义的一系列目录中查找对应的可执行文件 。创建进程执行:找到命令后,Shell通过
fork()系统调用创建一个子进程,然后在这个子进程中通过exec()系列系统调用加载并执行目标程序。程序运行后的输出会显示在终端上,运行结束后则会返回一个退出状态码(0通常表示成功)
功能类别
快捷键
作用
当你需要时...
光标移动
Ctrl + A/Ctrl + E光标瞬间跳转到行首 / 行尾
想快速在长命令的开头或结尾添加内容时
Ctrl + F/Ctrl + B光标向前(右)或向后(左)移动一个字符
进行精细的光标定位,相当于键盘方向键
Alt + F/Alt + B光标向前或向后移动一个单词
需要快速跳过多个字符时,效率远超单字符移动
文本编辑
Ctrl + U/Ctrl + K删除从光标处到行首 / 行尾的所有内容
输错了大半命令,想快速清空重来时
Ctrl + W删除光标之前的一个单词
想快速删除一个参数或路径中的一段时
Ctrl + Y粘贴之前用
Ctrl+U/K/W删除的文本误删了内容,或者想复用刚才删除的文本时
历史命令
Ctrl + R反向搜索历史命令,输入关键词即可模糊匹配
想执行一个几天前用过但记不清全名的复杂命令时
Ctrl + P/Ctrl + N切换到上一条 / 下一条历史命令
等同于按
↑和↓方向键,但手不用离开主键盘区
Alt + .快速插入上一条命令的最后一个参数
尤其有用!例如刚操作完一个长路径文件,现在要对它进行其他操作
场景一:快速修正历史命令
你想把昨天执行的
cp /very/long/path/to/file.txt /another/long/destination中的cp改为cat来查看内容。
操作:按
Ctrl + R,输入 "file.txt" 找到该命令。然后按Ctrl + A跳到行首,用Ctrl + W删除 "cp",输入 "cat"。最后按Ctrl + E跳到行尾执行。场景二:优雅地输入长路径
你需要输入
tar -czf backup.tar.gz /home/user/projects/very_important_code/。
操作:在输入到
/home/user/后,可以按Tab尝试自动补全。如果目录唯一,它会自动补全;如果不唯一,连按两下Tab会列出所有可能选项。结合Alt + B和Alt + F在路径组件间快速移动校正。进程控制快捷键
Ctrl + C:强制终止当前正在前台运行的命令 。
Ctrl + Z:将当前任务挂起(暂停),放到后台。之后可以用fg命令将其恢复到前台继续运行,或用bg命令让其在后台运行 。
Ctrl + L:清空当前屏幕,效果等同于clear命令,让你的终端瞬间整洁
10.2 shell的变量功能
10.2.2 变量的使用与设置:echo,变量设置规则,unset
一、echo命令:变量输出工具name="Alice" echo $name # 输出:Alice echo "Hello $name" # 输出:Hello Alice
引号类型
示例
效果
双引号
echo "$name"解析变量 → 输出
Alice单引号
echo '$name'原样输出 → 输出
$name无引号
echo $name解析变量,但不保留空格(易出错)
转义特殊字符
echo "价格:\$100" # 输出:价格:$100(\$ 转义美元符) echo -e "第一行\n第二行" # -e 启用转义符(\n 换行)二、变量设置规则(6大核心原则)
1. 命名规则 合法命名:字母/数字/下划线,首字符不能为数字var1="正确" # ✅ 1var="错误" # ❌ 报错:command not found2. 赋值操作 等号两侧无空格
name="Alice" # ✅ name = "Alice" # ❌ 报错:name: command not found3.值引用
$变量名或${变量名}(后者明确边界)file="document" echo "${file}_backup.txt" # 输出:document_backup.txt4.默认数据类型 一切为字符串:即使赋值数字,也视为文本
count=10 echo $((count + 1)) # 需用 $(( )) 做算术运算 → 输出 115.命令结果赋值 用
$()或 ``now=$(date +%F) # 获取当前日期(YYYY-MM-DD) files=`ls /tmp` # 旧式写法(建议用 $())6.只读变量
readonly防止修改readonly PI=3.14 PI=3.14159 # ❌ 报错:PI: readonly variable三、
unset:删除变量
释放变量:清除变量名及其值
恢复未定义状态:后续引用会报错(若开启
set -u)user="admin" echo $user # 输出:admin unset user echo $user # 输出:(空)或报错(若 set -u)
场景
说明
删除函数
unset -f 函数名删除数组
unset 数组名或unset 数组名[下标]环境变量
unset只删当前 Shell 的变量,不影响父进程
10.2.3 环境变量的功能1. 定义系统行为
变量名
功能
示例值
PATH命令搜索路径
/usr/bin:/bin:/usr/local/bin
LANG系统语言/编码
en_US.UTF-8
HOME用户家目录
/home/alice
SHELL默认Shell路径
/bin/bash
USER当前用户名
root作用:
PATH决定了输入ls时系统去哪里找/bin/ls这个程序
LANG让date命令输出英文或中文格式的时间env命令 观察环境变量与常用环境变量说明
set命令 观察所有变量(包含环境变量与自定义变量)
export命令 自定义变量转成环境变量
特性
环境变量
普通变量
作用域
当前Shell + 所有子进程
仅当前Shell
创建方式
export VAR=value
VAR=value查看命令
env,printenv
set持久化
写入
~/.bashrc等配置文件仅当前会话有效
在 Bash 中,PS1 是控制命令行提示符显示内容的环境变量。通过自定义 PS1,你可以创建既美观又实用的命令行界面,提升工作效率和用户体验
PS1="[前缀][内容][后缀]提示符"
序列
含义
示例输出
\u用户名
john
\h主机名(短)
server01
\H主机名(全)
server01.example.com
\w当前目录(完整路径)
/home/john/docs
\W当前目录(仅末级)
docs
\$用户标识符(
$或#)
$
\d日期
Tue Oct 9
\t时间(24h)
14:30:00
\n换行
多行提示符
\\反斜杠
``
\[\e[属性;前景色;背景色m\]
代码
前景色
背景色
30/40黑色
黑背景
31/41红色
红背景
32/42绿色
绿背景
33/43黄色
黄背景
34/44蓝色
蓝背景
35/45洋红
洋红背景
36/46青色
青背景
37/47白色
白背景
代码
效果
0重置
1粗体
4下划线
5闪烁
7反显
ubuntu系统改终端颜色在设置里面
10.2.4 影响显示结果的语系变量locale
语系变量(locale) 是控制系统语言、字符编码和区域格式的核心环境变量。它们直接影响命令输出、日期格式、货币符号等本地化显示效果
变量
功能
LC_CTYPE字符分类与大小写转换
LC_COLLATE字符串排序规则
LC_MESSAGES程序界面语言(如错误提示)
LC_NUMERIC非货币数字格式
LC_MONETARY货币格式
LC_TIME日期时间格式
LC_PAPER纸张尺寸(A4/Letter)
LC_NAME姓名格式(姓在前/名在前)
locale # 显示所有当前生效的 locale 变量 locale -a # 列出系统支持的所有 locale locale -k LC_TIME # 查看 LC_TIME 的详细定义临时设置(当前会话有效)
export LC_TIME=fr_FR.UTF-8 # 时间格式改为法语 date # 输出:jeu. sept. 16 14:30:00 CEST 2025永久设置(用户级)编辑
~/.bashrc或~/.profile:# 设置中文界面+UTF-8编码 export LANG=zh_CN.UTF-8 export LC_ALL= # 清空 LC_ALL 避免覆盖
10.2.6 变量键盘读取,数组与声明:read,array,declare
一、read:读取用户输入read [-options] [变量名]
项
功能
示例
-p "提示"显示提示信息
read -p "姓名:" name
-s静默输入(密码)
read -s -p "密码:" pass
-t 秒数超时等待
read -t 10 -p "10秒内输入:"
-n 字数限制输入长度
read -n 1 -p "按Y继续:"
-a 数组名输入存为数组
read -a arr
-d 分隔符自定义结束符
read -d ":" data(输入到冒号结束)#!/bin/bash # 用户登录验证 read -p "用户名:" username read -s -p "密码:" password echo # 换行(-s 不输出回车)if [ "$username" = "admin" ] && [ "$password" = "123456" ]; thenecho "登录成功!" elseecho "认证失败" fi二、数组(Array):存储数据集合
1. 普通数组(索引数组)
# 定义数组 fruits=("苹果" "香蕉" "橙子")# 访问元素 echo ${fruits[0]} # 输出:苹果 echo ${fruits[-1]} # 输出:橙子(倒数第一个)# 获取所有元素 echo ${fruits[@]} # 输出:苹果 香蕉 橙子# 数组长度 echo ${#fruits[@]} # 输出:32. 关联数组(键值对)
# 声明关联数组(必须提前声明) declare -A user user=([name]="Alice" [age]=25 [job]="工程师")# 访问值 echo ${user[name]} # 输出:Alice# 遍历所有键 for key in ${!user[@]}; doecho "$key: ${user[$key]}" done3. 数组操作技巧
操作
语法
示例
追加元素
arr+=("新元素")
fruits+=("葡萄")删除元素
unset arr[下标]
unset fruits[1](删香蕉)切片
${arr[@]:起点:长度}
${fruits[@]:1:2}→ 香蕉 橙子合并数组
new=("${arr1[@]}" "${arr2[@]}")
all=("${fruits[@]}" "${veggies[@]}")三、
declare:精细控制变量属性declare [选项] 变量名=值
选项
作用
示例
-i整数类型
declare -i num=10+20(自动计算)
-r只读变量
declare -r PI=3.14(不可修改)
-a普通数组
declare -a list=("a" "b")
-A关联数组
declare -A dict=([key]="value")
-x导出为环境变量
declare -x PATH(等效export)
-l小写转换
declare -l name="ALICE"→alice
-u大写转换
declare -u city="paris"→PARIS作用域控制
# 函数内声明局部变量(避免污染全局) myfunc() {declare -l local_var="LocalValue" # 局部+小写global_var="Global" }10.2.7 与文件系统及程序的限制关系:ulimit
ulimit是 Linux 中控制进程资源限制的核心命令,它直接关联文件系统、内存、CPU 等关键资源的使用上限常用限制项(查看所有:
ulimit -a)
选项
含义
默认值
场景
-n打开文件数
1024
Web服务器(需数万)
-u用户进程数
63225
防
fork炸弹
-v虚拟内存 (KB)
unlimited
内存密集型程序
-m物理内存 (KB)
unlimited
容器资源限制
-tCPU时间 (秒)
unlimited
计算任务超时控制
-cCore文件大小
0 (禁止生成)
调试程序崩溃
-d数据段内存 (KB)
unlimited
进程堆内存限制
ulimit -n 65535 # 当前会话打开文件数改为65535 ulimit -t 300 # 进程最长运行5分钟(300秒) ulimit -c unlimited # 允许生成core文件(调试用)
Too many open files# 临时 ulimit -n 65535# 永久(/etc/security/limits.conf) * soft nofile 65535 * hard nofile 65535Fork炸弹防护
# 限制用户进程数 * hard nproc 500 # 普通用户最多500进程 root soft nproc unlimited # root不受限容器环境特殊处理
Docker:通过--ulimit参数设置docker run --ulimit nofile=65535:65535 nginx10.2.8 变量内容的删除,取代和替换
一、删除操作(从首尾移除匹配内容)1. 从开头删除(Shortest/Longest Match)
语法
匹配模式
示例
结果
${var#pattern}最短匹配
file="dir/file.txt"echo ${file#*/}
file.txt
${var##pattern}最长匹配
file="/usr/local/bin/app"echo ${file##*/}
app
#像剪刀 → 从开头剪掉匹配项
##是贪婪模式 → 剪到最后一个匹配2. 从结尾删除(Shortest/Longest Match)
语法
匹配模式
示例
结果
${var%pattern}最短匹配
file="backup.tar.gz"echo ${file%.*}
backup.tar
${var%%pattern}最长匹配
file="project.min.js"echo ${file%%.*}
project
%像剪刀 → 从结尾剪掉匹配项
%%是贪婪模式 → 剪到最前一个匹配二、替换操作(子串替换)
1. 单次替换
语法
功能
示例
结果
${var/old/new}替换第一个匹配
str="a-b-a-b"echo ${str/-/@}
a@b-a-b
${var//old/new}替换所有匹配
str="a-b-a-b"echo ${str//-/@}
a@b@a@b2. 锚定替换
语法
功能
示例
结果
${var/#old/new}开头匹配才替换
str="error:404"echo ${str/#error/warn}
warn:404
${var/%old/new}结尾匹配才替换
str="file.bak"echo ${str/%.bak/.tmp}
file.tmp三、默认值替换
1. 空值处理
语法
功能
示例
结果
${var:-default}空时用默认值
unset var; echo ${var:-100}
100
${var:=default}空时赋值+用默认值
unset var; echo ${var:=200}; echo $var
200→2002. 非空处理
语法
功能
示例
结果
${var:+replacement}非空时替换
var="A"; echo ${var:+B}
B
${var:?error_msg}空时报错退出
unset var; echo ${var:?未定义}
报错退出
删除操作:#开头,%结尾替换操作:
/单次,//全局锚定操作:
/#锚头,/%锚尾
*匹配任意字符
?匹配单个字符
[...]字符组(如[a-z])
10.3 命令别名与历史命令
10.3.1 命令别名设置: alias ,unalias
一、alias:创建命令别名alias 别名='原命令 [选项]'二、unalias:删除别名
unalias 别名 # 删除单个别名 unalias -a # 删除所有别名三、永久生效配置
用户级配置(推荐) 编辑~/.bashrc文件:# 添加别名 echo "alias ll='ls -alF'" >> ~/.bashrc# 立即生效 source ~/.bashrc全局配置(所有用户生效) 编辑
/etc/bash.bashrc或/etc/profile.d/alias.sh:sudo vim /etc/bash.bashrc # 添加:alias update='sudo apt update'10.3.2 历史命令:history
history # 显示所有历史记录(带编号) history 10 # 显示最近10条命令
语法
功能
示例
!!上一条命令
sudo !!→ 用sudo重跑上条命令
!n执行第n条命令
!1003→ 执行vim report.txt
!-n执行倒数第n条
!-2→ 执行上上条命令
!string执行以string开头的最近命令
!git→ 执行最近的git命令# 反向搜索(最常用) Ctrl + R # 输入关键词实时搜索 # 按Ctrl+R继续向前搜索# 显示所有匹配项 history | grep "git" # 过滤含git的命令
10.4 Bash shell的操作环境
10.4.1 路径与命令查找顺序
1.以相对/绝对路径执行命令,例如/bin/ls或./ls2.由alias找到该命令并执行
3.由bash内置的builtin命令来执行
4.通过¥PATH这个变量的顺序查找到的第一个命令来执行
10.4.2 bash的登录与欢迎信息: /etc/issue /etc/motd
一、登录信息配置文件
文件
生效时机
显示位置
核心用途
/etc/issue登录前(认证界面)
本地终端、SSH(默认)
显示系统信息/登录提示
/etc/motd登录后(成功认证)
所有会话(本地+SSH)
显示系统公告/重要通知
1.
/etc/issue- 登录前欢迎信息转义符:
转义符
作用
示例输出
\n主机名
server01
\l当前TTY编号
tty1
\d当前日期
Tue Oct 9 2024
\t当前时间
14:30:00
\m硬件架构
x86_64
\o域名
example.com
\sOS名称
Linux
\r内核版本
5.4.0-80-generic# 编辑文件 sudo nano /etc/issue# 内容: \e[32;1m ========================================== = 欢迎登录 \s \r 服务器 (\m) = = 主机名: \n | 日期: \d \t = = 请使用授权账号登录! = ========================================== \e[0m2.
/etc/motd- 登录后公告默认状态:空文件
经典用途:
系统维护通知
安全策略提醒
每日运维语录
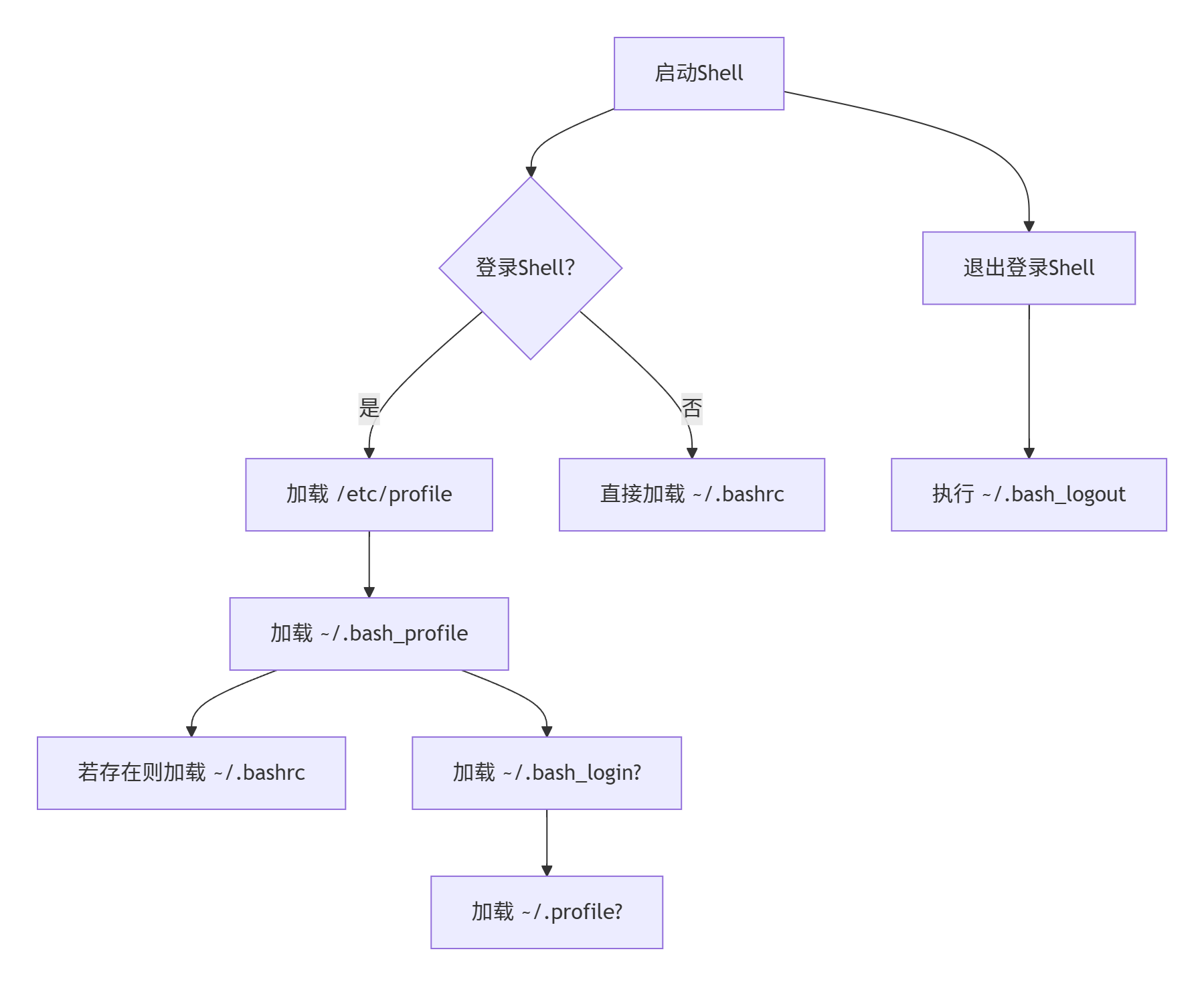
sudo nano /etc/motd10.4.3 bash的环境配置文件
全局配置(所有用户生效)
文件
加载时机
典型用途
/etc/profile登录Shell
系统级环境变量、PATH设置
/etc/profile.d/*.sh被
/etc/profile调用模块化配置(推荐)
/etc/bash.bashrc非登录Shell(部分系统)
全局别名、函数
/etc/environment所有Shell(PAM读取)
基础环境变量(如JAVA_HOME)
用户级配置(单用户生效)
文件
加载时机
优先级
经典用途
~/.bash_profile登录Shell
1️⃣
用户级初始化、PATH扩展
~/.bash_login登录Shell(.bash_profile 不存在时)
2️⃣
备用登录配置
~/.profile登录Shell(前两者不存在时)
3️⃣
通用登录配置(Debian系默认)
~/.bashrc非登录Shell
-
别名、函数、提示符定制
~/.bash_logout退出登录Shell
-
清理任务(如清屏、备份历史)
souce命令 读入环境配置文件命令
.bashrc文件是 Linux 系统中用户级 Bash Shell 的核心配置文件,专为交互式非登录 Shell 设计
在 Bash Shell 中,提示字符(Prompt) 是命令行界面中等待用户输入命令时显示的符号。它由环境变量PS1(Primary Prompt String 1)控制,是高度可定制的
10.4.4 终端的环境设置: stty, set
用
stty来告诉终端如何解释你的按键(比如退格键应该删除字符)以及如何显示输出(比如是否显示你输入的密码)。用
set来告诉Shell如何运行(比如遇到错误是否停止、是否打印正在执行的命令)stty命令 设置终端行规程
控制 终端设备本身 的输入/输出行为。它操作的是内核中的“行规程”设置,这些设置决定了字符如何从键盘传输到程序(输入),以及程序的输出如何显示在屏幕上(输出)
特殊字符的含义(例如:^C(中断),^Z(挂起),^D(EOF),^?或^H(擦除/退格),^U(删除行),^W(删除词))#查看当前设置 stty -a#将退格键设置为擦除字符(解决某些终端按退格出 ^?的问题) stty erase ^H # 通常对应键盘上的 Backspace 键 # 或 stty erase ^? # 通常对应键盘上的 Delete 键 (具体看终端模拟器设置)#切换回熟悉的“熟”模式(带行编辑和回显) stty saneset命令 设置Shell选项
#查看当前设置 set -o # 显示所有选项及其开启/关闭状态#启用选项 set -o option_name # 长格式 set -letter # 短格式 (如果存在)#禁用选项 set +o option_name # 长格式 set +letter # 短格式
10.4.5 通配符与特殊符号
路径名扩展
当你输入一个包含通配符的命令(如ls *.txt)并按回车后,Shell 会在执行命令之前,将这些通配符模式扩展为匹配该模式的实际文件或目录名列表。这个过程称为 路径名扩展 或 通配
*(星号)
含义: 匹配任意数量(包括零个)的任意字符。
示例:
ls *.txt:列出当前目录下所有以.txt结尾的文件。
ls a*:列出当前目录下所有以字母a开头的文件。
ls *log*:列出当前目录下所有文件名中包含log的文件。
cp /path/to/source/*.jpg /path/to/destination/:复制源目录下所有.jpg文件到目标目录。注意: 在 Unix/Linux 中,以
.开头的文件是隐藏文件。*默认不匹配 这些隐藏文件。要匹配隐藏文件,模式必须显式包含.,例如.*或.*.txt。
?(问号)
含义: 匹配恰好一个的任意字符。
示例:
ls file?.txt:列出类似file1.txt,file2.txt,fileA.txt的文件,但不会匹配file.txt(缺少一个字符) 或file10.txt(多了一个字符)。
ls image-??.png:列出类似image-01.png,image-AB.png的文件(两个字符)
[...](方括号 - 字符集)
含义: 匹配方括号内列出的任意一个字符。
示例:
ls [abc]*.txt:列出以a,b或c开头,并以.txt结尾的文件。
ls report[0-9].doc:列出report0.doc,report1.doc, ...,report9.doc。
ls [a-zA-Z]*:列出所有以字母(无论大小写)开头的文件。特殊用法:
范围: 使用连字符
-指定一个连续的范围(如[0-9],[a-z],[A-Z])。排除: 在左括号
[后紧跟一个!或^表示不匹配括号内的字符。
ls [!0-9]*:列出所有不以数字开头的文件。
ls [^a-z]*:列出所有不以小写字母开头的文件(注意:^在方括号内才表示排除,在方括号外是锚定行首)。预定义字符类 (Bash 扩展): 某些 Shell(如 Bash)支持更简洁的写法:
[[:digit:]]等价于[0-9]
[[:lower:]]等价于[a-z]
[[:upper:]]等价于[A-Z]
[[:alpha:]]等价于[a-zA-Z]
[[:alnum:]]等价于[a-zA-Z0-9]
[[:space:]]匹配任何空白字符(空格、制表符等)
[[:punct:]]匹配标点符号示例:
ls file[[:digit:]][[:digit:]].txt匹配file00.txt到file99.txt
{...}(花括号 - 大括号扩展 / Brace Expansion)
含义: 生成由逗号分隔的字符串列表。不是模式匹配文件系统对象,而是由 Shell 直接生成字符串组合。发生在路径名扩展之前。
示例:
echo file.{txt,log,md}输出file.txt file.log file.md
mkdir -p dir/{src,bin,doc}创建目录dir/src,dir/bin,dir/doc
cp /path/to/config.{bak,orig}尝试复制/path/to/config.bak到/path/to/config.orig(等价于cp /path/to/config.bak /path/to/config.orig)
echo {1..5}输出1 2 3 4 5
echo {a..e}输出a b c d e
echo {01..10}输出01 02 03 04 05 06 07 08 09 10(填充零)
echo file{1,2}{a,b}输出file1a file1b file2a file2b(组合)与通配符的区别: 大括号扩展是无条件地生成所有组合,不管对应的文件或目录是否存在。通配符 (
*,?,[]) 则需要匹配实际存在的文件系统对象。
**(双星号 - 递归匹配 - Bash 4.0+)
含义: 当与
globstarShell 选项一起使用时 (shopt -s globstar),**匹配零个或多个目录,实现递归查找。示例:
ls **/*.log:列出当前目录及其所有子目录中的.log文件。
find . -name "*.log"命令的功能类似,但**是 Shell 内置的扩展。
~(波浪号 - Tilde)
含义: 代表当前用户的家目录。
示例:
cd ~:切换到当前用户的家目录(等价于cd $HOME或cd)。
ls ~/Documents:列出当前用户家目录下Documents子目录的内容。扩展:
~username代表用户username的家目录(如果你有权限访问)。例如ls ~john/music
;(分号)
含义: 用于在一行中分隔多个命令。Shell 会按顺序执行它们。
示例:
cd /tmp; ls; pwd:先切换到/tmp,然后列出其内容,最后显示当前工作目录(/tmp)
&(与号)
含义:
放在命令末尾:让命令在后台运行。Shell 会立即返回提示符,你可以继续输入其他命令。
放在命令中间(较少见):控制命令的输入输出文件描述符。
示例:
sleep 60 &:启动一个睡眠 60 秒的进程,但立即返回 Shell 提示符。
|(管道符)
含义: 将前一个命令的标准输出 (stdout) 连接到后一个命令的标准输入 (stdin)。
示例:
ls -l | grep "Oct":列出详细目录信息,然后筛选出包含字符串 "Oct" 的行(常用于查找特定日期修改的文件)。
>(大于号 - 输出重定向)
含义: 将命令的标准输出 (stdout) 覆盖写入到指定文件。
示例:
ls > filelist.txt:将ls的输出写入filelist.txt文件(如果文件存在则覆盖)。
>>(两个大于号): 追加写入到指定文件末尾。ls >> existing_list.txt。
<(小于号 - 输入重定向)
含义: 将指定文件的内容作为命令的标准输入 (stdin)。
示例:
sort < unsorted.txt > sorted.txt:从unsorted.txt读取内容进行排序,然后将排序结果写入sorted.txt。
$(美元符号)
含义:
变量扩展: 获取变量的值。
echo $HOME。命令替换:
$(command)或`command`(反引号,旧式) 将命令的输出作为字符串插入。echo "Today is $(date)"。算术运算:
$((expression))进行整数运算。echo $((10 + 5))输出15。``(反斜杠 - 转义字符)
含义: 去除紧随其后的单个字符的特殊含义,使其成为字面字符。
示例:
echo "This costs \$5":输出This costs $5(防止$被解释为变量)。
touch file\ with\ spaces.txt:创建一个名为file with spaces.txt的文件(转义空格)。
echo *:列出文件(*被扩展)。
echo \*:输出*(字面星号)。
' '(单引号)
含义: 强引用。引号内的所有字符都失去特殊含义,被视为普通字符。无法在单引号内包含单引号本身(即使转义也不行)。
示例:
echo '$HOME *':输出$HOME *($HOME和*都不被扩展)。
echo 'It\'s sunny':错误! Shell 会尝试寻找匹配的结束引号。正确做法是使用双引号或转义单引号:echo "It's sunny"或echo It\'s sunny。
" "(双引号)
含义: 弱引用。引号内的大部分特殊字符(如
*,?,~,;,&,|,>,<,(,))失去特殊含义,被视为普通字符。但以下字符仍然保留特殊含义:
$(变量扩展、命令替换、算术扩展)
`(命令替换,旧式)
\` (但只用于转义$, `````,",\` 和换行符本身。转义其他字符时,`通常被保留)。示例:
echo "Your home is $HOME":输出Your home is /home/yourusername($HOME被扩展)。
echo "Files: *":输出Files: *(*不被扩展)。
echo "Price: \$100":输出Price: $100(转义$)。
echo "He said, \"Hello!\"":输出He said, "Hello!"(转义双引号)。
#(井号)
含义: 在 Shell 脚本中,用于表示注释。从
#开始到行尾的内容都会被 Shell 忽略。示例:
# This is a comment explaining the next command ls -l # This comment explains the ls command
( )(圆括号)
含义:
子 Shell: 在子 Shell 中执行一组命令。
(cd /tmp; ls):在子 Shell 中切换目录并列出内容,然后返回父 Shell(当前目录不变)。命令分组: 结合
&&或||控制逻辑流。(command1 && command2) || command3。数组: 定义数组
array=(element1 element2 ...)。算术运算:
$(( ... ))内部使用。
{ }(花括号 - 命令分组)
含义: 在当前 Shell 中执行一组命令。命令必须用分号
;或换行符分隔。示例:
{ cd /tmp; ls; }:在当前 Shell 中切换到/tmp并列出内容(当前目录会改变)。常用于函数定义:
myfunc() { echo "Hello"; }。与大括号扩展的区别: 用于命令分组时,
{和}周围必须有空格,并且命令列表末尾必须有分号;或换行符。大括号扩展则不需要空格,且内部是逗号分隔的字符串列表。
&&(逻辑与)
含义: 只有前一个命令成功执行(退出状态码为 0),才执行后一个命令。
示例:
mkdir newdir && cd newdir:如果成功创建newdir目录,则进入该目录。
||(逻辑或)
含义: 只有前一个命令执行失败(退出状态码非 0),才执行后一个命令。
示例:
command || echo "Command failed":如果command执行失败,则显示错误信息。
引用和转义是关键: 当你想让 Shell 将特殊字符视为普通字符时,必须使用单引号
' '、双引号" "或反斜杠 ``进行引用或转义。顺序很重要: 扩展发生的顺序是:大括号扩展 (
{}) -> 波浪号扩展 (~) -> 参数/变量扩展 ($) -> 命令替换 ($()/) -> 算术扩展 ($(())) -> 单词拆分 -> 路径名扩展 (*,?,[])。理解这个顺序有助于解释复杂命令的行为。
10.5 数据流重定向
10.5.1 什么是数据流重定向
数据流
文件描述符
默认目标
作用
标准输入
0
键盘
程序用来读取输入数据。
标准输出
1
终端(屏幕)
程序将正常的运行结果输出到这里。
标准错误
2
终端(屏幕)
程序将错误信息、警告信息输出到这里。
重定向标准输出 (stdout)
>(覆盖重定向)
命令
ls -l > file.txt作用: 将
ls -l命令的正常输出结果覆盖写入到file.txt文件中。如果file.txt不存在,则会创建它;如果已存在,则清空原有内容再写入。
>>(追加重定向)
命令
ls -l >> file.txt作用: 将
ls -l命令的正常输出结果追加到file.txt文件的末尾。不会清空原文件内容重定向标准错误 (
stderr) 标准错误对应的文件描述符是2,所以重定向时需要指明
2>(覆盖重定向错误)
命令
ls no_such_file 2> error.log作用: 尝试列出一个不存在的文件,必然会产生错误信息。这个错误信息不会被打印到屏幕,而是被覆盖写入到
error.log文件中。
2>>(追加重定向错误)
命令
ls no_such_file 2>> error.log作用: 将错误信息追加到
error.log文件的末尾重定向标准输入 (
stdin)
<(输入重定向)
命令
sort < list.txt作用:
sort命令默认会从标准输入(键盘)读取数据。通过<,我们让它改为从list.txt文件中读取数据,然后进行排序,最后将结果输出到屏幕将标准输出和标准错误重定向到同一个地方
2>&1(经典写法)
命令
ls no_such_file real_file > output.log 2>&1作用: 与上一条等价。
2>&1的意思是“将标准错误(2)重定向到标准输出(1)所在的地方”。因为前面已经先把标准输出重定向到了output.log,所以标准错误也会跟着去那里
管道|
管道是重定向的一种高级形式,它把一个命令的标准输出直接作为另一个命令的标准输入。
命令
ls -l | grep "\.txt"作用:
ls -l的输出结果不会显示在屏幕上,而是直接传递给grep命令作为输入,由grep来过滤出包含.txt的行
10.5.2 命令执行的判断根据: ;,&&, ||于前一个命令的执行结果(退出状态码)来决定是否执行以及如何执行下一个命令
1.;(分号) - 命令分隔符
功能: 最简单的连接方式。它只是将多个命令分隔开,按顺序依次执行,完全不关心前一个命令是成功还是失败。
逻辑:
命令A ; 命令B
无论
命令A执行成功(退出状态码为 0)还是失败(退出状态码非 0),命令B都会无条件地接着执行。用途: 当你需要依次执行一系列命令,并且每个命令的执行不依赖于前一个命令的成功与否时使用。
echo "Hello" ; ls -l ; date2.
&&(逻辑与) - 成功才执行下一个
功能: 表示逻辑与(AND)。只有当前一个命令执行成功(退出状态码为 0)时,才会执行下一个命令。如果前一个命令失败,则后面的命令不会执行。
逻辑:
命令A && 命令B
如果
命令A成功 (exit code 0),则执行命令B。如果
命令A失败 (exit code != 0),则不执行命令B。用途: 当你需要确保前一个步骤成功完成后,才进行下一个步骤时使用。常用于构建依赖链。
mkdir new_dir && cd new_dir
先尝试创建目录
new_dir。如果创建成功 (
mkdir返回 0),则执行cd new_dir进入该目录。如果创建失败(例如目录已存在或无权限),则
cd命令不会执行3.
||(逻辑或) - 失败才执行下一个
功能: 表示逻辑或(OR)。只有当前一个命令执行失败(退出状态码非 0)时,才会执行下一个命令。如果前一个命令成功,则后面的命令不会执行。
逻辑:
命令A || 命令B
如果
命令A失败 (exit code != 0),则执行命令B。如果
命令A成功 (exit code 0),则不执行命令B。用途: 常用于提供错误处理或备用方案。当主命令失败时,执行一个替代命令或错误处理命令。
ping -c 1 example.com || echo "Ping failed!"
尝试 ping
example.com一次 (ping -c 1 example.com)。如果 ping 失败(主机不可达),则执行
echo "Ping failed!"打印错误信息。如果 ping 成功,则不打印错误信息。
组合使用
命令A && 命令B || 命令C
如果
命令A成功,则执行命令B。如果
命令A失败,则执行命令C。注意:如果
命令A成功但命令B失败,命令C也会被执行!因为命令B的失败使得||的条件满足。这种组合常用于模拟简单的if-then-else,但要小心命令B失败的情况
命令A ; 命令B && 命令C || 命令D
先执行
命令A(无论成败)。然后执行
命令B(无论命令A成败)。如果
命令B成功,则执行命令C。如果
命令B失败,则执行命令D。
关于$$
$$ 是一个特殊的 Shell 变量,它代表当前 Shell 进程的进程 ID (PID)。功能: 它不是用于命令执行判断的操作符(如
;,&&,||)。它的作用是提供当前脚本或 Shell 会话的唯一标识符。用途:
创建唯一的临时文件名(例如
/tmp/mytempfile.$$)。在脚本中记录日志时包含 PID。
用于进程管理(如
kill $$会杀死当前 Shell 进程本身)echo "The PID of this shell is: $$" touch /tmp/report.$$.txt # 创建一个唯一的临时文件,如 /tmp/report.12345.txt
10.6 管道命令
允许你将一个命令的标准输出(stdout) 直接作为另一个命令的标准输入(stdin)
command1 | command2 | command3 | ... | commandN工作原理:
执行
command1:Shell 首先执行管道符 (|) 左边的第一个命令 (command1)。重定向输出:
command1产生的标准输出(stdout) 不会像默认那样显示在屏幕上,而是被重定向到一个特殊的、临时的内存区域(通常称为“管道缓冲区”)。连接输入:管道符 (
|) 右边的下一个命令 (command2) 的标准输入(stdin) 被设置为从这个“管道缓冲区”读取数据。执行
command2:command2开始执行,它处理的数据来源就是command1的输出。链式传递:
command2处理后的标准输出(stdout)又可以被下一个管道符 (|) 传递给command3,依此类推。最终输出:管道链中最后一个命令 (
commandN) 的标准输出(stdout)会默认显示在终端屏幕上(除非它也被重定向了)关键特性:
单向流动: 数据只能从左向右流动,通过管道传递。
内存缓冲: 数据通常通过内存缓冲区传递,效率很高。
并行执行: 命令是并行执行的!Shell 会同时启动管道中的所有命令。
command2不需要等待command1完全结束才开始;它会在command1产生第一行输出时就开始处理。这大大提高了效率。只处理标准输出 (stdout): 默认情况下,管道只传递标准输出(stdout)。命令的标准错误(stderr) 仍然会直接输出到屏幕(或终端),不会被传递到下一个命令。如果需要传递标准错误,通常需要先用
2>&1将其合并到标准输出。命令要求:
管道左边的命令必须能产生标准输出(例如
ls,cat,grep,echo)。管道右边的命令必须能够从标准输入读取数据(例如
grep,sort,wc,less,awk,sed,head,tail)。有些命令如果后面跟了文件名参数,可能会忽略标准输入,这点需要注意
10.6.1 选取命令: cut , grep
cut: 主要根据位置(列) 来提取文本。它擅长处理具有固定结构或明确分隔符的数据(如 CSV、TSV、/etc/passwd)。
grep: 主要根据内容(模式匹配) 来过滤文本行。它擅长搜索包含特定字符串或正则表达式模式的行
1.cut命令:按列切割提取
cut命令用于从文本文件的每一行或输入流中剪切(提取)指定的部分(字节、字符或字段)cut OPTION... [FILE]...
选项
含义
-d DELIM指定字段分隔符。默认是制表符 (Tab)。例如
-d ','指定逗号为分隔符。
-f FIELDS指定要提取的字段(列)。这是最常用的选项。
-c CHARACTERS指定要提取的字符位置(按字符数,而不是字段)。
-b BYTES指定要提取的字节位置(在纯 ASCII 文本中通常等同于
-c)。
-f FIELDS详解:
FIELDS可以是单个数字(如-f 3表示第 3 个字段)、逗号分隔的列表(如-f 1,3表示第 1 和第 3 个字段)、范围(如-f 2-5表示第 2 到第 5 个字段)、或组合(如-f 1,3-5,7)。
-f 1-表示从第 1 个字段到行尾的所有字段。
-f -3表示从行首到第 3 个字段的所有字段。Name,Age,City,Occupation Alice,30,New York,Engineer Bob,25,London,Designer Charlie,35,Paris,Manager#提取第1个和第3个字段 cut -d ',' -f 1,3 data.txt#输出 Name,City Alice,New York Bob,London Charlie,ParisABCDEFG HIJKLMN OPQRSTU#按字符位置提取 cut -c 2-4 letters.txt#输出每行的第2,3,4个字符 BCD IJK PQR2.
grep命令:按模式搜索过滤行
grep(Global Regular Expression Print) 命令用于在文本文件或输入流中搜索匹配指定模式(字符串或正则表达式) 的行,并将匹配的行打印出来grep [OPTIONS] PATTERN [FILE...]
选项
含义
-i忽略大小写进行匹配。
-v反向选择,只显示不包含匹配模式的行。
-w单词匹配,只匹配整个单词,而不是字符串的一部分。
-n显示行号,在输出行前加上它在文件中的行号。
-c计数,只显示匹配模式的行数,而不是行本身。
-l列出文件名,只显示包含匹配模式的文件名(当搜索多个文件时有用)。
-r或-R递归搜索,在指定目录及其子目录下的所有文件中搜索。
-E扩展正则表达式,允许使用更强大的正则表达式语法(等同于
egrep)。
-A NUM显示匹配行及其后 NUM 行 (After Context)。
-B NUM显示匹配行及其前 NUM 行 (Before Context)。
-C NUM显示匹配行及其前后各 NUM 行 (Context)。
10.6.2 排序命令: sort, wc, uniq
1.sort命令:排序文本行
sort命令用于对文本文件或输入流中的行进行排序(默认按字典序升序)sort [OPTION]... [FILE]...
选项
作用
-n数字排序 (按数值大小,而非字符串)
-r反向排序 (降序)
-k POS指定排序键(列) (POS 格式为
起始字段[.起始字符][,结束字段[.结束字符]])
-t DELIM指定字段分隔符 (默认为空格/制表符)
-u去重 (等同于 `sort ...
-f忽略大小写
-M按月份名称排序 (JAN, FEB, ..., DEC)
-V自然版本号排序 (如 1.2.10 > 1.2.9)
-o FILE将结果输出到文件 (而非屏幕)
2.
uniq命令:报告或忽略重复行
uniq命令用于过滤或报告输入中相邻的重复行。它通常需要输入是已排序的,因为只检查相邻行是否重复,uniq几乎总是与sort结合使用uniq [OPTION]... [INPUT [OUTPUT]]
选项
作用
-c计数:在每行前显示该行重复出现的次数
-d仅显示重复行 (每组重复行只显示一次)
-u仅显示不重复行 (唯一行)
-i忽略大小写
sort [file] | uniq [options]3.
wc命令:统计行数、单词数、字节数
wc(Word Count) 命令用于统计文件或输入流中的行数、单词数、字节数/字符数wc [OPTION]... [FILE]...
选项
作用
-l仅统计行数 (Line count)
-w仅统计单词数 (Word count)
-c仅统计字节数 (Byte count)
-m仅统计字符数 (Character count) (注意:在多字节字符如 UTF-8 中,
-m和-c可能不同)(无选项)
同时显示行数、单词数、字节数和文件名
10.6.3 双向重定向:tee
双向重定向——既能将数据流显示在终端(标准输出),又能同时保存到文件。其名称来源于管道工程中的 T 型三通管(一个入口,两个出口)command | tee [OPTION]... [FILE]...
选项
作用
-a追加到文件(默认覆盖原文件)
-i忽略中断信号(如 Ctrl+C)
-p诊断写入错误(非标准选项,部分系统支持)
保存命令输出到文件并同时显示
ls -l /etc | tee directory_list.txt
10.6.4 字符转换命令:tr,col,join,paste,expand
1.tr:字符替换/删除功能:逐字符转换或删除(不支持正则表达式,仅处理单个字符)
语法:
tr [OPTION] SET1 [SET2]常用选项:
-d:删除 SET1 中的字符
-s:压缩重复字符(将连续重复字符缩为单字符)
-c:对 SET1 的补集操作# 小写转大写 echo "hello" | tr 'a-z' 'A-Z' # 输出:HELLO# 删除所有数字 echo "Phone: 123-456" | tr -d '0-9' # 输出:Phone: -# 压缩连续空格 echo "Too many spaces" | tr -s ' ' # 输出:Too many spaces# 替换换行符为空格(合并多行) cat file.txt | tr '\n' ' '2.
col:过滤控制字符功能:处理
man页等包含退格符(^H)和回车符的特殊文本语法:
col [OPTIONS]关键选项:
-x:将制表符(Tab)转为空格
-b:过滤所有控制字符(包括退格符)# 查看 man 页并过滤控制符 man ls | col -bx > ls_manual.txt # 生成可读的纯文本手册3.
join:按列合并文件(类似 SQL JOIN)功能:基于共同字段(主键)合并两个文件的行
语法:
join [OPTION] FILE1 FILE2前提:输入文件必须按连接字段排序
常用选项:
-t CHAR:指定字段分隔符(默认空格)
-1 FIELD:指定 FILE1 的连接字段
-2 FIELD:指定 FILE2 的连接字段
-a FILENUM:输出未匹配行(1=FILE1, 2=FILE2)# 文件1: employees.txt 1 Alice 2 Bob 3 Charlie# 文件2: departments.txt 1 Sales 2 Engineering 3 Marketing# 按第一列合并 join -1 1 -2 1 employees.txt departments.txt#输出 1 Alice Sales 2 Bob Engineering 3 Charlie Marketing4.
paste:并行合并文件(列拼接)功能:水平合并文件内容(无需排序,按行拼接)
语法:
paste [OPTION] FILE1 FILE2选项:
-d DELIM:指定分隔符(默认制表符)
-s:串行合并(转置为单列)# 文件1: names.txt Alice Bob Charlie# 文件2: ages.txt 30 25 35# 默认制表符分隔合并 paste names.txt ages.txt#输出 Alice 30 Bob 25 Charlie 355.
expand:制表符转空格功能:将 Tab 符(
\t)转换为空格(解决空格/Tab 混用问题)语法:
expand [OPTION] FILE选项:
-t NUM:指定 Tab 宽度(默认 8 空格)
-i:仅转换行首 Tab# 转换文件中的 Tab 为 4 空格 expand -t 4 input.txt > output.txt# 与代码检查工具配合 cat script.py | expand -t 4 | grep " " # 查找剩余空格10.6.5 划分命令:split
将大文件分割成多个小文件的实用命令,尤其适合处理日志归档、数据分片或绕过文件大小限制的场景split [OPTION]... [INPUT [PREFIX]]
选项
作用
-l NUM按行数分割(每 NUM 行一个文件)
-b SIZE按大小分割(支持单位:K, M, G)
-d使用数字后缀(默认字母后缀 aa, ab...)
-a NUM设置后缀长度(默认 2 位)
--additional-suffix=SUF添加额外后缀(如
.log)
-n NUM生成指定数量的文件(均分)
10.6.6 参数代换:xargs
xargs是 Linux 中解决「参数列表过长」的核心工具,它将标准输入(stdin)转换为命令行参数,尤其擅长处理管道传递的数据和批量操作command1 | xargs [OPTION] command2 [command2_args]
选项
作用
典型场景
-n NUM每组传递 NUM 个参数
xargs -n 2→ 每行执行一次命令,带2个参数
-I {}占位符替换(默认
{})
find ... -print0 \| xargs -0 -I{} cp {} /backup
-0处理 NULL 分隔的输入(防空格问题)
配合
find -print0
-P NUM并行执行(多进程加速)
xargs -P 4→ 启动4个并行进程
-t打印实际执行的命令(调试用)
-p交互确认每次执行
危险操作前确认
-d DELIM自定义分隔符(默认空格/换行)
xargs -d ','按逗号分割
10.6.7 关于减号 - 的用途
减号- 是一个特殊符号,主要用来表示标准输入(stdin)或标准输出(stdout)。
1. 代表标准输入(stdin)# 将前一个命令的输出作为当前命令的输入 echo "Hello World" | cat - # 等效于:echo "Hello World" | cat# 从标准输入读取并排序 sort - <<EOF banana apple orange EOF # 输出: # apple # banana # orange2. 代表标准输出(stdout)
# 解压文件到标准输出(而非生成文件) gzip -d -c file.gz > output.txt # 等效于:gzip -dc file.gz > output.txt# 将 tar 打包结果输出到 stdout tar czf - /path/to/dir | ssh user@host "tar xzf - -C /backup" # 将本地目录打包后通过管道传输到远程主机解压3. 同时表示输入和输出
# 转换图片格式:从 stdin 读入 PNG,输出 JPEG 到 stdout convert png:- jpeg:- < input.png > output.jpg1. 管道中间处理
# 解压日志 -> 过滤错误 -> 重新压缩 gzip -d -c log.gz | grep "ERROR" | gzip > errors.gz2. 跨主机数据传输
# 本地打包 -> 传输 -> 远程解压 tar czf - /data | ssh user@remote "tar xzf - -C /backup"
3. 加密/解密流# 加密文件并输出到 stdout openssl enc -aes-256-cbc -in file.txt -pass pass:secret | gzip > encrypted.gz# 解密:从 stdin 读取加密数据 gzip -d -c encrypted.gz | openssl enc -d -aes-256-cbc -pass pass:secret4. 配合
dd克隆磁盘# 磁盘克隆(无需中间镜像文件) dd if=/dev/sda | gzip -c | ssh user@backup "gzip -d | dd of=/dev/sdb"
1. 命令参数分隔符# 删除名为 "-f" 的文件(避免被误认为选项) rm -- -f # -- 表示后续内容不是选项
2. 表示上一步目录cd - # 切换到上一次的工作目录3. 算术运算负号
echo $((5 - 10)) # 输出 -5
三. 第11章: 正则表达式与文件格式化处理
11.1 开始之前:什么是正则表达式
通过特定的元字符和语法规则,实现对字符串的高效搜索、替换、验证和提取
普通字符(如a、1、@)直接匹配自身
元字符
作用
示例
.匹配任意单个字符(除换行符)
a.c→ "abc", "aac"
^匹配行开始位置
^Hello→ "Hello world"
$匹配行结束位置
world$→ "Hello world"
*前一个字符出现 0 次或多次
ab*c→ "ac", "abbc"
+前一个字符出现 1 次或多次
ab+c→ "abc", "abbc" (不匹配 "ac")
?前一个字符出现 0 次或 1 次
ab?c→ "ac", "abc"``
转义字符
\.匹配真正的点号(非元字符)
[ ]字符集合
[aeiou]匹配任意元音字母
[^ ]排除字符集合
[^0-9]匹配非数字字符`
`
或逻辑
( )分组
(ab)+匹配 "ab", "abab"
表达式
等价形式
含义
\d
[0-9]数字字符
\w
[a-zA-Z0-9_]单词字符(字母、数字、下划线)
\s
[ \t\r\n\f]空白字符(空格、制表符等)
\D
[^0-9]非数字字符
\W
[^a-zA-Z0-9_]非单词字符
\S
[^ \t\r\n\f]非空白字符
特性
基础正则表达式(BRE)
扩展正则表达式(ERE)
支持工具
grep(默认)
grep -E,sed -r,awk元字符
需转义:
\+\?\|\(\)直接使用:
+?`示例差异
`echo "aab"
grep "a+b"` → 匹配
11.2 基础正则表达式
BRE 核心元字符表
元字符
作用
示例
匹配结果
.匹配任意单个字符(除换行符)
a.c"abc", "aac", "a1c"
^匹配行开始位置
^start"start..."(行首为 "start")
$匹配行结束位置
end$"...end"(行尾为 "end")
*前一个字符出现 0 次或多次
ab*c"ac", "abc", "abbc"
[ ]匹配字符集合中的任意一个
[aeiou]"a", "e", "i", "o", "u"
[^ ]匹配不在集合中的字符
[^0-9]"a", "@", " "(非数字)
``
转义特殊字符
\.匹配真正的点号(如 "file.txt")
\{m,n\}前一个字符出现 m 到 n 次
a\{2,4\}"aa", "aaa", "aaaa"
\( \)分组(需转义)
\(ab\)\{2\}"abab"
关键特性详解
1. 锚点定位:
^和$# 匹配以 "Error" 开头的行 grep '^Error' log.txt# 匹配以 ".png" 结尾的文件名 ls | grep '\.png$'2. 重复匹配:
*和\{m,n\}# 匹配 "co" 后跟任意数量 "l",再跟 "r"(如 "color", "cooler") grep 'col*r' words.txt# 匹配 3~5 位数字(需转义花括号) grep '[0-9]\{3,5\}' data.txt3. 字符集合:
[ ]和[^ ]# 匹配所有元音字母 grep '[aeiou]' poem.txt# 匹配不含数字的行 grep '^[^0-9]*$' config.ini4. 分组引用:
\( \)和\n# 交换 "last, first" 为 "first last" echo "Doe, John" | sed 's/\(.*\), \(.*\)/\2 \1/' # 输出:John Doe
\(.*\)捕获逗号前的部分("Doe")
\(.*\)捕获逗号后的部分("John")
\2 \1交换位置经典实战案例
1. 提取日志中的 IP 地址grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' access.log
[0-9]\{1,3\}:匹配 1~3 位数字
\.:转义点号2. 验证简单日期格式(YYYY-MM-DD)
grep '^[0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}$' dates.txt
[0-9]\{4\}:4 位年份
-:分隔符
[0-9]\{2\}:2 位月/日3. 删除空行和注释行
# 删除空行(^$)和以 # 开头的行(^#) grep -v '^$\|^#' config.conf # 注意:BRE 中 \| 需转义
-v:反向选择(不匹配的行)
^$:空行(开始后立即结束)
^#:以#开头的行4. 批量重命名文件(
sed+rename)# 将 "file_001.txt" 改为 "doc_001.txt" rename 's/file\([0-9]\{3\}\)\.txt/doc\1.txt/' *.txt
\([0-9]\{3\}\):捕获 3 位数字
\1:引用捕获组//的意思
命令
解释
s/old/new/将每行的第一个 "old" 替换为 "new"
s/old/new/g将行中所有 "old" 替换为 "new"(
g是全局标志)
s@old@new@使用
@代替/作为分隔符(处理含/的路径时常用)`s
old
常见分隔符替代方案:
符号
示例
适用场景
/
s/old/new/通用场景
@
s@old@new@处理文件路径
`
`
`s
:
s:old:new:兼容性最佳
#
s#old#new#模式含斜杠时
11.2.5 sed工具
sed(Stream Editor)是Linux中功能强大的流式文本编辑器,它逐行处理输入流(文件或管道),执行编辑命令,并将结果输出到标准输出。sed特别适合批量编辑文本文件、执行查找替换操作和处理数据流。sed [选项] '命令' 输入文件 sed [选项] -f 脚本文件 输入文件
选项
作用
-n静默模式(只输出处理过的行)
-i[后缀]直接修改文件(加后缀则备份)
-e指定多个编辑命令
-r使用扩展正则表达式(ERE)
-f从文件读取sed脚本
1. 替换命令(最常用)
s/正则表达式/替换内容/标志标志说明:
g:全局替换(一行内所有匹配)
p:打印替换后的行
w 文件:将结果写入文件
数字:仅替换第N次出现的匹配# 将每行第一个apple替换为orange sed 's/apple/orange/' fruits.txt# 全局替换(所有apple) sed 's/apple/orange/g' fruits.txt# 只替换每行第二个apple sed 's/apple/orange/2' fruits.txt# 替换并保存修改(备份原文件) sed -i.bak 's/apple/orange/g' fruits.txt2. 删除命令
# 删除第3行 sed '3d' file.txt# 删除第2-4行 sed '2,4d' file.txt# 删除空行 sed '/^$/d' file.txt# 删除包含error的行 sed '/error/d' log.txt3. 打印命令
# 打印第5行(需配合-n) sed -n '5p' file.txt# 打印包含warning的行 sed -n '/warning/p' log.txt# 打印第10-15行 sed -n '10,15p' file.txt4. 插入/追加命令
# 在第3行前插入 sed '3i\插入内容' file.txt# 在第3行后追加 sed '3a\追加内容' file.txt# 在文件开头插入 sed '1i\标题行' file.txt# 在文件末尾追加 sed '$a\结束行' file.txt5. 行替换命令
# 替换第3行内容 sed '3c\新内容' file.txt# 替换匹配行 sed '/old/c\new' file.txt
11.3 扩展正则表达式
ERE核心语法
1. 量词简化# BRE写法 echo "aaa" | grep 'a\+' # 匹配1个或多个a echo "ab" | grep 'a\?b' # 匹配0个或1个a后跟b echo "aaa" | grep 'a\{3\}' # 匹配3个a# ERE等效写法(更简洁) echo "aaa" | grep -E 'a+' # + 不需要转义 echo "ab" | grep -E 'a?b' # ? 不需要转义 echo "aaa" | grep -E 'a{3}' # {} 不需要转义2. 逻辑或操作符
# 匹配多种错误类型 grep -E 'error|warning|critical' log.txt# 匹配多种文件扩展名 ls | grep -E '\.(txt|pdf|doc)$'# 匹配日期格式(YYYY-MM-DD 或 DD/MM/YYYY) grep -E '([0-9]{4}-[0-9]{2}-[0-9]{2}|[0-9]{2}/[0-9]{2}/[0-9]{4})' dates.txt3. 分组简化
# 匹配重复单词(如"hello hello") echo "hello hello world" | grep -E '(\b\w+\b) \1'# 交换姓名格式 echo "Doe, John" | sed -E 's/(.*), (.*)/\2 \1/' # 输出:John Doe# 匹配ab重复2-3次 echo "abab" | grep -E '(ab){2,3}'4. 精确重复次数
# 匹配2-4位数字 grep -E '[0-9]{2,4}' data.txt# 匹配正好5个字母的单词 grep -E '\b[a-zA-Z]{5}\b' text.txt# 匹配至少3个数字 grep -E '[0-9]{3,}' numbers.txt
11.4 文件的格式化与相关处理
工具
主要功能
典型应用
pr分页格式化
打印准备、分栏显示
fmt文本重新格式化
段落重排、行宽调整
fold固定宽度折行
文本换行控制
nl添加行号
代码显示、行号标注
column列对齐
表格格式化
paste列合并
数据合并
expand/unexpand制表符处理
空格/Tab转换
11.4.1 格式化打印:printfprintf "格式字符串" [参数1 参数2 ...]
说明符
含义
示例
输出
%s字符串
printf "%s" "Hello"
Hello
%d十进制整数
printf "%d" 42
42
%f浮点数
printf "%f" 3.14159
3.141590
%x十六进制整数(小写)
printf "%x" 255
ff
%X十六进制整数(大写)
printf "%X" 255
FF
%o八进制整数
printf "%o" 64
100
%c单个字符
printf "%c" 65
A
%%百分号本身
printf "100%%"
100%
序列
含义
示例
输出
\n换行
printf "Line1\nLine2"两行文本
\t水平制表符
printf "Name:\tJohn"
Name: John
\v垂直制表符
printf "A\vB"A和B垂直对齐
\\反斜杠
printf "C:\\Windows"
C:\Windows
\"双引号
printf "\"Quote\""
"Quote"
\a警报(响铃)
printf "\a"系统提示音
%8.2f:00000.00
11.4.2 awk:好用的数据处理工具awk 'pattern { action }' input_file
变量
含义
示例
$0整行内容
{print $0}
$1-$n第n个字段
{print $1, $3}
NF当前行字段数
{print NF, $NF}
NR当前行号
NR>10 {print}
FNR当前文件行号
{print FNR, $0}
FS输入字段分隔符
BEGIN{FS=":"}
OFS输出字段分隔符
BEGIN{OFS="-"}
RS输入记录分隔符
BEGIN{RS="\n\n"}
ORS输出记录分隔符
BEGIN{ORS="\n---\n"}
FILENAME当前文件名
{print FILENAME}
模式
含义
BEGIN处理前执行
END处理后执行
/regex/正则匹配
条件表达式如
NR>10
选项
作用
示例
-F:设置字段分隔符为
:
awk -F: '{print $1}' file
-F","设置字段分隔符为逗号
awk -F, '{print $2}' data.csv
-F"[ ]+"设置分隔符为一个或多个空格
awk -F"[ ]+" '{print $3}' log.txt1. 字段处理
# 打印用户名和UID(/etc/passwd) awk -F: '{print $1, $3}' /etc/passwd# 交换前两个字段 awk '{tmp=$1; $1=$2; $2=tmp; print}' file.txt# 计算行平均(第3列) awk '{sum+=$3} END {print "Avg:", sum/NR}' data.txt2. 条件过滤
# 筛选第3列大于100的行 awk '$3 > 100' data.csv# 匹配包含"error"的行(不区分大小写) awk '/error/i {print}' log.txt# 复杂条件(AND/OR) awk '$1=="admin" && $3>90 || $4=="urgent"' access.log3. 数学运算
# 计算总和 awk '{sum+=$2} END {print sum}' sales.txt# 统计不同状态码数量 awk '{status[$9]++} END {for(s in status) print s, status[s]}' access.log# 百分比计算 awk '{total+=$3} {percent=$3/total*100; printf "%s: %.1f%%\n", $1, percent}' data.txt4. 字符串处理
# 连接字符串 awk '{print $1 "-" $2}' names.txt# 子串提取 awk '{print substr($1, 1, 3)}' words.txt# 替换文本 awk '{gsub("old", "new"); print}' file.txt# 长度计算 awk '{print length($0)}' text.txt5. 数组应用
# 词频统计 awk '{for(i=1;i<=NF;i++) words[$i]++} END {for(w in words) print w, words[w]}' text.txt# 分组求和 awk '{sum[$1]+=$2} END {for(k in sum) print k, sum[k]}' sales.txt# 去重 awk '!seen[$0]++' duplicates.txt11.4.3 文件比对工具
1.diff- 逐行比对文本文件
功能: 逐行比较两个文本文件,显示差异。
语法:
diff [选项] 文件1 文件2关键选项:
-c/--context:输出上下文格式(显示差异行附近的若干行)。
-u/--unified:输出统一格式 (更简洁的上下文格式,最常用)。
-i:忽略大小写差异。
-w:忽略所有空白字符(空格、制表符)的差异。
-B:忽略空白行的差异。
-r:递归比较目录(比较目录中所有同名文件)。
-q/--brief:仅报告文件是否不同,不显示具体差异。输出符号含义:
<:表示第一个文件独有的行(或旧版本)。
>:表示第二个文件独有的行(或新版本)。
---:分隔两个文件的内容。# 基本比较 diff file1.txt file2.txt# 使用统一格式输出 (推荐) diff -u file1.txt file2.txt# 比较两个目录 diff -ur dir1/ dir2/# 忽略空白差异 diff -w file1.c file2.c2.
cmp- 逐字节比对任意文件
功能: 逐字节比较两个文件(文本或二进制),报告第一个差异的位置。
语法:
cmp [选项] 文件1 文件2关键选项:
-l:打印所有不同的字节(显示字节位置和值)。
-s/--quiet/--silent:不输出任何信息,仅通过退出状态码表示结果(相同为 0,不同为非 0)。适用场景: 检查二进制文件(如程序、图片)是否完全相同,或快速判断两个文件是否有任何差异。
# 基本比较 (报告第一个差异位置) cmp image1.jpg image2.jpg# 列出所有不同的字节 cmp -l binary1.bin binary2.bin# 静默模式 (用于脚本判断) cmp -s backup.tar.gz archive.tar.gz && echo "Files are identical"
patch命令是 Linux/Unix 系统中用于将差异文件(补丁)应用到原始文件的工具。它通常与diff命令结合使用,实现文件的版本更新或代码修复。patch [选项] [原始文件 [补丁文件]]
选项
说明
-pNUM剥离路径层级(最常用!)
例如-p1会忽略补丁中路径的第1层目录。
-i PATCHFILE指定补丁文件路径(默认从 stdin 读取)。
-R反向还原(撤销已应用的补丁)。
--dry-run模拟应用补丁(不修改文件,仅检查补丁能否成功应用)。
-b/--backup备份原始文件(生成
.orig后缀的备份)。
-E如果补丁后文件为空,则删除该文件。
-v显示详细操作信息。
11.4.4 文件打印设置:pr
pr命令是 Linux/Unix 系统中用于格式化文本文件以便打印的工具。它会为文本添加分页、页眉、页脚、多列布局等打印所需的格式,但本身不执行打印操作(需配合lpr等打印命令使用)pr [选项] [文件...]
四. 学习shell脚本
12.1 什么是shell脚本
Shell脚本(Shell Script)是一种用Shell命令编写的、可执行的文本文件,用于自动化执行一系列Linux/Unix命令。它本质上是将手动在终端输入的命令组合成程序,由Shell解释器(如Bash)逐行执行
1. 本质
文本文件:纯文本格式,可用任何编辑器创建(如
vim,nano)。解释执行:无需编译,由Shell环境(如
/bin/bash)动态解释运行。自动化工具:替代重复的手动命令操作,提升效率
Shell脚本的技术特点
12.1.3 建立shell脚本的良好编写习惯
特点
说明
依赖Shell环境
必须在Shell解释器(如Bash、Zsh)中运行
直接调用系统命令
可执行
ls,grep,awk等所有终端命令支持编程结构
变量、条件判断(
if)、循环(for/while)、函数灵活处理文本
结合
sed、awk实现文本解析和转换轻量级
适合快速开发小型工具,无需编译环境
1. 声明解释器
2. 添加元信息注3. 缩进与空格
使用 4个空格 缩进(避免Tab混用)
运算符两侧加空格
4. 命名规范
用绝对路径:避免依赖当前目录
类型
规范
示例
变量/函数
小写+下划线
backup_dir,calc_size()常量/配置项
大写+下划线
MAX_RETRIES=5脚本文件
小写+下划线,带
.sh
deploy_app.sh
一、PATH 环境变量的本质
继承性:
脚本默认继承当前 Shell 的
PATH设置。若你的终端中
PATH已包含所需命令路径(如/usr/local/bin),脚本可直接调用命令。潜在风险:
不同用户/环境下的
PATH可能不同(如cron任务的环境极其精简)。依赖继承的
PATH会导致脚本在新环境中失败(如command not found)二、何时必须设置
export PATH?
场景
必要性
示例
使用非标准路径的命令
必须
自定义安装的
/opt/app/bin脚本在受限环境运行
必须
cron、systemd服务确保可移植性
强烈推荐
共享给团队或部署到多台服务器
避免路径劫持安全风险
强烈推荐
防止恶意程序覆盖
$PATH#!/bin/bash # ✅ 最佳实践:设置确定的PATH export PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
在每个脚本都要记录:
脚本的功能
脚本的版本信息
脚本的作者与联络方式
脚本的版权声明方式
脚本的History(历史记录)
脚本内特殊的命令,使用【绝对路径】的方式来执行
脚本运行时需要的环境变量预先声明与设置
12.2 简单的shell脚本练习
脚本练习以后再说
12.2.2 脚本的执行方式差异(source,sh script, ./script)
执行Shell脚本有三种主要方式,它们在执行环境、权限要求和作用范围上有显著差异
1.source script.sh或. script.sh特点
在当前Shell环境中执行:不创建子进程
无需执行权限:只需读权限
变量和函数会保留:脚本中定义的变量/函数影响当前Shell
source script.sh # 或 . script.sh # 注意点和脚本名之间有空格# 定义脚本 demo.sh echo "当前PID: $$" export VAR="source_value"# 执行 $ source demo.sh 当前PID: 1234 # 与当前终端PID相同$ echo $VAR source_value # 变量保留在当前环境
2.sh script.sh或bash script.sh特点
在子Shell中执行:创建新进程
无需执行权限:只需读权限
隔离环境:变量/函数不影响当前Shell
可指定解释器:如
bash、zsh、dashsh script.sh # 或 bash script.sh$ sh demo.sh 当前PID: 5678 # 新PID(子进程)$ echo $VAR# 变量不保留3.
./script.sh特点
在子Shell中执行:创建新进程
需要执行权限:必须先
chmod +x script.sh依赖shebang:使用脚本首行指定的解释器
隔离环境:变量/函数不影响当前Shell
./script.sh$ chmod +x demo.sh $ ./demo.sh 当前PID: 9012 # 新PID(子进程)$ echo $VAR# 变量不保留当需要脚本改变当前Shell状态时用
source,当需要隔离执行环境时用
sh或./。
12.3 善用判断式
12.3.1 利用test命令的测试功能
test EXPRESSION[ EXPRESSION ]注意:方括号内两侧必须有空格!例如
[ -f file ]正确,[-f file]错误。
表达式
含义
-e FILE文件/目录是否存在
-f FILE存在且为普通文件(非目录/设备)
-d FILE存在且为目录
-L FILE存在且为符号链接
-r FILE存在且可读
-w FILE存在且可写
-x FILE存在且可执行
-s FILE存在且文件大小大于0
FILE1 -nt FILE2FILE1比FILE2新(修改时间)
FILE1 -ot FILE2FILE1比FILE2旧
表达式
含义
-z STRING字符串为空(长度为0)
-n STRING字符串非空(长度非0)
STRING1 = STRING2字符串相等(注意等号两边空格)
STRING1 != STRING2字符串不相等
STRING1 > STRING2按字典顺序STRING1在STRING2之后
STRING1 < STRING2按字典顺序STRING1在STRING2之前
表达式
含义
NUM1 -eq NUM2等于(equal)
NUM1 -ne NUM2不等于(not equal)
NUM1 -gt NUM2大于(greater than)
NUM1 -ge NUM2大于等于(greater or equal)
NUM1 -lt NUM2小于(less than)
NUM1 -le NUM2小于等于(less or equal)
表达式
含义
! EXPR非(取反)
EXPR1 -a EXPR2与(and),两个表达式都真
EXPR1 -o EXPR2或(or),至少一个表达式为真
分组组合
[ EXPR1 ] && [ EXPR2 ]与(推荐使用,避免
-a)`[ EXPR1 ]
12.3.2 利用判断符号:[]当使用
[ ]时:
始终给变量加双引号
确保所有操作符两侧有空格
优先使用
[[ ]]如果只需支持 Bash数值比较用
(( ))更安全直观12.3.3 shell脚本的默认变量($0,$1)
Shell脚本默认变量详解:$0,$1,$#,$@,$*,$?,$$,$!
一、位置参数(Positional Parameters)
1.$0- 脚本名称
2.$1,$2, ...$9- 位置参数
3.$#- 参数个数
4.$@和$*- 所有参数
变量
区别
引号行为
$@每个参数作为独立字符串
"$@"保持原样分隔
$*所有参数合并为单个字符串
"$*"合并为一个字符串二、状态变量(Status Variables)
1.$?- 上条命令退出状态
2.$$- 当前进程PID
3.$!- 后台进程PID
三、特殊变量扩展1. 默认值处理
语法
说明
${VAR:-default}VAR未定义时使用default
${VAR:=default}VAR未定义时设置并使用default
${VAR:?message}VAR未定义时显示错误并退出
2. 参数移位
shift
作用:向左移动位置参数
语法:
shift [N](默认N=1)用途:处理多个参数
while [ $# -gt 0 ]; doecho "处理参数: $1"shift # 移除$1,$2变为$1 done
12.4 条件判断式
1. if-then-fi 结构
if [ condition ]; then# 条件为真时执行的命令 fi2. if-then-else-fi 结构
if [ condition ]; then# 条件为真时执行的命令 else# 条件为假时执行的命令 fi3. case-esac 多分支选择
case "$variable" inpattern1)# 匹配pattern1时执行;;pattern2|pattern3)# 匹配pattern2或pattern3时执行;;*)# 默认情况;; esac例子暂且不表
12.4.3 利用function功能# 定义方式1(推荐) function_name() {# 函数体commands }# 定义方式2(兼容性更好) function function_name {# 函数体commands }function_name # 无参数调用 function_name "arg1" "arg2" # 带参数调用
在函数内部使用位置参数:greet() {echo "Hello, $1! Your ID is $2" }greet "Alice" 1001 # 输出: Hello, Alice! Your ID is 1001
变量
含义
$#传递给函数的参数个数
$@所有参数的列表
$*所有参数合并为单个字符串
例子暂且不表
12.5 循环(loop)
1.
for循环
遍历列表for item in item1 item2 item3; doecho "处理: $item" done遍历数字范围
# 传统方式 for i in {1..5}; doecho "数字: $i" done# C语言风格(推荐) for ((i=1; i<=5; i++)); doecho "计数: $i" done遍历文件
for file in *.log; doecho "处理日志: $file"gzip "$file" done遍历命令输出
for user in $(cut -d: -f1 /etc/passwd); doecho "用户: $user" done
2.while循环count=1 while [ $count -le 5 ]; doecho "循环次数: $count"((count++)) done3.
until循环count=1 until [ $count -gt 5 ]; doecho "直到计数大于5: $count"((count++)) done1.
break- 跳出循环for i in {1..10}; doif [ $i -eq 5 ]; thenecho "遇到5,跳出循环"breakfiecho $i done2.
continue- 跳过本次迭代for i in {1..5}; doif [ $i -eq 3 ]; thenecho "跳过3"continuefiecho $i done3. 多层循环控制for i in {1..3}; dofor j in {a..c}; doif [ $i -eq 2 ] && [ $j = "b" ]; thenecho "跳出内层循环"breakfiecho "$i$j"done done例子暂且不表
12.6 shell脚本的跟踪与调试
看不懂一点
下次再写吧