自然语言处理实战——中文BERT模型可视化工具
目录
一、引言
1. 核心架构:双向 Transformer 编码器
2. 关键预训练任务:学透语言规律
3. 核心优势:通用 + 灵活
4. 主要用途
二、中文 BERT 分词器(BertChineseTokenizer)
三、BERT 模型核心架构
1. 配置类(BertConfig)
2. 嵌入层(BertEmbeddings)
3. 多头自注意力(BertSelfAttention)
4. Transformer 层与编码器(BertLayer/BertEncoder)
5. 预训练模型与任务头(BertModel/BertPretrainingHeads/BertForPretraining)
四、预训练任务辅助功能
1. MLM 任务工具(create_mlm_mask)
2. 文本处理工具(TextProcessor)
3. 自定义数据集(TextDataset)
五、可视化工具(BertVisualizer)
六、训练函数(train_bert)
七、GUI 界面(BertGUI)
整体流程
八、中文BERT模型可视化工具的Python代码完整实现
九、程序运行部分截图
十、总结
1.中文BERT分词器(BertChineseTokenizer):
2.BERT模型架构:
3.可视化功能:
4.应用特点:
一、引言
BERT(Bidirectional Encoder Representations from Transformers)是 Google 2018 年提出的预训练语言模型,核心目标是通过 “无监督预训练” 学习通用的语言语义表示,为后续自然语言处理(NLP)任务提供基础,是 NLP 领域的里程碑模型之一,其核心特点可简单概括为:
1. 核心架构:双向 Transformer 编码器
- 基于Transformer 的编码器模块(仅用编码器,不用解码器),通过多层堆叠(原论文 12/24 层)实现 “深层语义捕捉”;
- 输入层包含三类嵌入:
- 词嵌入:将文本中的每个 token(中文场景下含字、词、子词)映射为向量;
- 位置嵌入:编码 token 在句子中的位置信息(解决 Transformer 无法感知顺序的问题);
- Segment 嵌入:区分 “句子对”(如 “句子 A + 句子 B”),用于判断句子间关系;
- 核心机制是多头自注意力:让每个 token 能 “关注” 句子中其他 token 的信息,从而理解上下文关联(比如 “他” 指代的是谁)。
2. 关键预训练任务:学透语言规律
通过两个无监督任务,让模型在海量文本上学习语言逻辑:
- MLM(掩码语言模型):随机 “掩码” 15% 的 token(中文里可能是字或词),让模型预测被掩码的内容(比如 “经济 [MASK] 球化”→预测 “全”),强制模型理解上下文语义;
- NSP(下一句预测):给模型输入 “句子 A + 句子 B”,让模型判断 B 是否是 A 的真实下一句(比如 “A = 经济全球化是趋势,B = 它推动贸易发展”→判断为 “是”),学习句子间的逻辑关系。
3. 核心优势:通用 + 灵活
- 双向语义:区别于之前的单向模型(如 ELMo 仅左→右或右→左),BERT 能同时从 “左→右” 和 “右→左” 看上下文,更贴合人类理解文本的方式;
- 预训练 + 微调模式:先在海量文本上预训练(学通用语言知识),再针对具体任务(如文本分类、命名实体识别、机器翻译)微调,大幅降低下游任务的训练难度;
- 中文适配性:可通过中文分词器(如代码中的
BertChineseTokenizer)处理汉字、词、子词,适配中文 “无空格分隔” 的特点。
4. 主要用途
是 NLP 下游任务的 “基础底座”,可适配:
- 文本分类(如情感分析、新闻分类);
- 信息抽取(如提取人名、地名、机构名);
- 问答系统(如根据上下文回答问题);
- 文本生成辅助(如给生成模型提供语义提示)等。
本文用Python代码实现了中文 BERT 模型的全流程工具链,涵盖分词器、模型架构、数据集构建、预训练、可视化分析与图形化交互界面,可支持从 “文本输入” 到 “模型训练与可视化” 的端到端操作。既适合教学演示,也可用于小规模中文预训练实验。
二、中文 BERT 分词器(BertChineseTokenizer)
负责中文文本的分词与词汇表管理,是 BERT 处理中文的核心基础:
- 词汇表构建:包含特殊符号(
[PAD]/[UNK]/[CLS]等)、常用汉字、双 / 多字词(如 “中国”“人工智能”)、子词(如##科技),覆盖中文常见表达。 - 多粒度分词:
- 基础分词:用正则匹配 URL、邮箱、数字、汉字、英文、标点,初步拆分文本。
- WordPiece 分词:对长词进行子词拆分(优先匹配完整词,否则尝试带
##的子词,未匹配则标记为[UNK]),适配中文 “字 - 词 - 子词” 的表达特点。
三、BERT 模型核心架构
复刻了 BERT 的经典组件,从 “嵌入层→注意力机制→Transformer 层→预训练头” 分层实现:
1. 配置类(BertConfig)
定义模型超参数(词汇表大小、隐藏层维度、注意力头数、层数等),统一管理模型配置,方便调整(如缩小hidden_size用于轻量实验)。
2. 嵌入层(BertEmbeddings)
将token ID、位置信息、句子 segment ID融合为向量表示:
- 词嵌入(
word_embeddings):将 token ID 映射为向量。 - 位置嵌入(
position_embeddings):编码 token 在序列中的位置信息。 - Segment 嵌入(
token_type_embeddings):区分 “句子对” 中的两个句子(用于 NSP 任务)。 - 后处理:通过
LayerNorm和Dropout增强嵌入的稳定性与泛化性。
3. 多头自注意力(BertSelfAttention)
Transformer 的核心机制,让模型 “关注” 序列中的关键位置:
- 将输入转换为
Query/Key/Value矩阵。 - 计算注意力分数(
Query与Key的相似度),并通过Softmax归一化。 - 支持
attention_mask,忽略 padding 部分对注意力的干扰。 - 输出加权融合后的
Value(即 “注意力增强的表示”)。
4. Transformer 层与编码器(BertLayer/BertEncoder)
BertLayer:单个 Transformer 层,包含自注意力子层和前馈神经网络子层,每层后接 “残差连接 + LayerNorm”,保证信息流畅通与训练稳定性。BertEncoder:由多个BertLayer堆叠而成,实现 “多层级、多粒度” 的语义编码,捕捉文本深层关系。
5. 预训练模型与任务头(BertModel/BertPretrainingHeads/BertForPretraining)
BertModel:整合 “嵌入层 + 编码器”,输出序列级嵌入(每个 token 的上下文表示)和 **[CLS]位置的 pooled 嵌入 **(整句语义的聚合表示)。BertPretrainingHeads:预训练的两个任务头:- MLM 头:预测被掩码的 token(Masked Language Model)。
- NSP 头:判断两个句子是否为连续上下文(Next Sentence Prediction)。
BertForPretraining:封装BertModel与预训练头,计算 MLM 和 NSP 的联合损失,驱动模型预训练。
四、预训练任务辅助功能
1. MLM 任务工具(create_mlm_mask)
模拟 BERT 的 “掩码语言模型” 任务:
- 随机选择 15% 的 token,其中 80% 替换为
[MASK]、10% 替换为随机 token、10% 保持原 token。 - 生成对应的 “标签序列”(仅掩码位置保留真实 token,其余位置标记为
-100,避免计算损失)。
2. 文本处理工具(TextProcessor)
为预训练准备 “句子对” 样本:
- 长文本分割:将长文本切分为多个
chunk(支持重叠,避免语义断裂)。 - 句子对生成:随机生成 “连续 / 不连续” 的句子对,用于 NSP 任务。
- 格式转换:将句子对转换为模型输入格式(添加
[CLS]/[SEP]、生成 token ID/attention mask/segment ID)。
3. 自定义数据集(TextDataset)
将原始文本转换为 PyTorch 的Dataset:
- 支持 “直接输入文本” 或 “从文件加载文本”。
- 预处理文本,生成训练样本(包含 token ID、attention mask、segment ID、NSP 标签等)。
- 为可视化准备辅助数据(如句子长度分布、NSP 标签分布)。
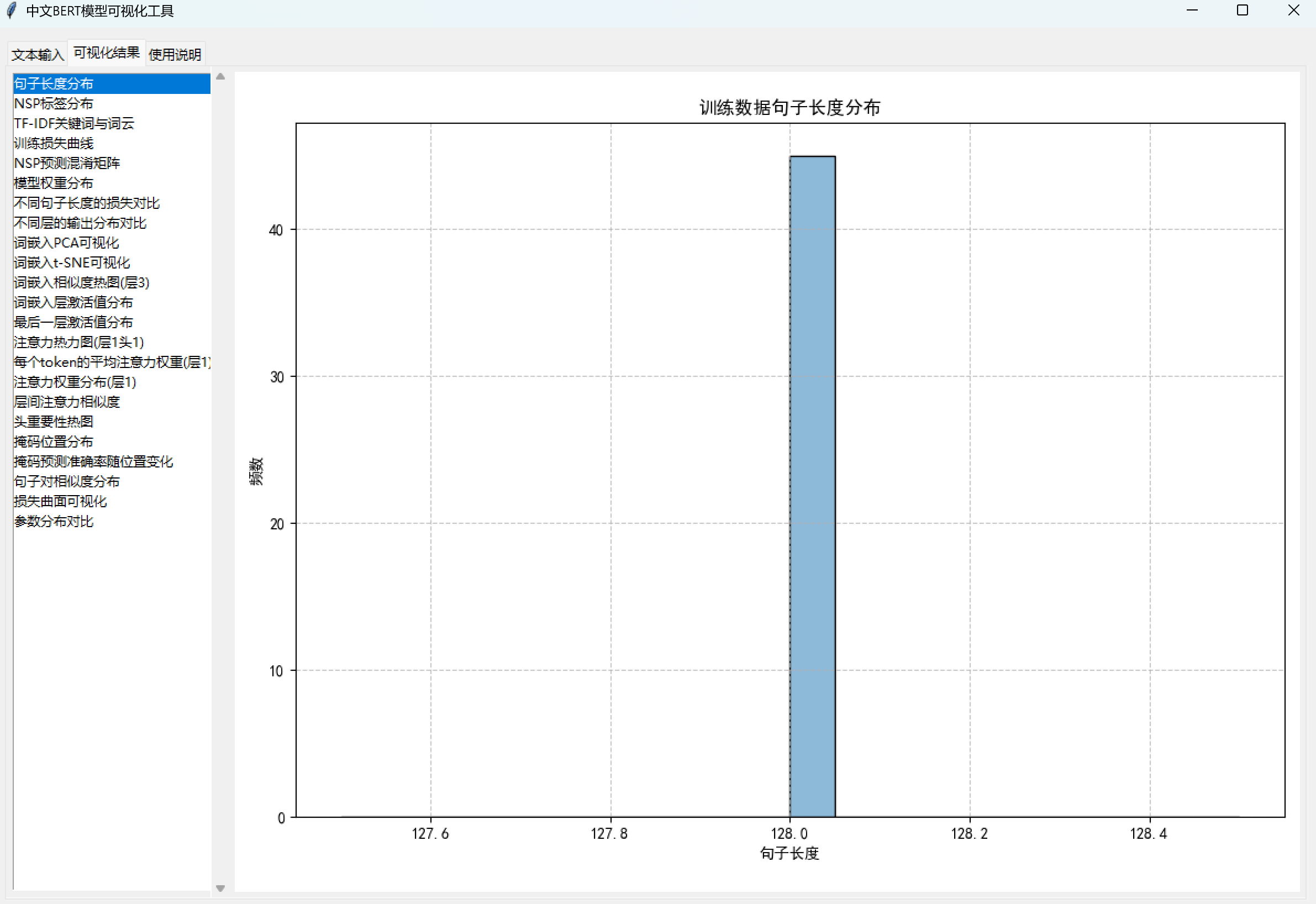
五、可视化工具(BertVisualizer)
生成22 种可视化图表,从 “训练过程、数据分布、模型内部机制、任务表现” 等维度解析 BERT:
- 训练过程:训练损失曲线、损失曲面平滑可视化。
- 数据分布:句子长度分布、NSP 标签分布、掩码位置分布。
- 模型内部机制:
- 注意力:热力图(展示 token 间的注意力关联)、权重分布(各注意力头的权重分布)、层间相似度(不同层注意力的相关性)、头重要性热图(各层注意力头的平均权重)。
- 词嵌入:PCA 降维可视化、t-SNE 降维可视化、嵌入相似度热图(token 间的语义相似性)。
- 激活与参数:激活值分布(词嵌入层 / 最后一层的激活分布)、模型权重分布(不同层参数的分布对比)。
- 任务表现:
- NSP 任务:混淆矩阵(预测与真实标签的匹配情况)、句子对相似度分布(连续 / 不连续句子对的语义相似度差异)。
- MLM 任务:掩码预测准确率(不同位置的预测准确率变化)。
- 文本分析:TF-IDF 关键词(文本中重要词汇的 TF-IDF 得分)、词云(文本词汇的直观分布)。
六、训练函数(train_bert)
驱动 BERT 预训练,并同步生成可视化:
- 配置设备(CPU/GPU)、数据加载器、优化器(AdamW)、学习率调度器(LinearLR)。
- 训练循环中,计算 MLM 和 NSP 损失,进行梯度裁剪(防止梯度爆炸)与参数更新。
- 每个 epoch 后,调用
BertVisualizer生成 “损失曲线、混淆矩阵、权重分布” 等可视化。 - 训练完成后,保存模型,并生成 “嵌入可视化、注意力可视化、参数分布” 等剩余图表。
七、GUI 界面(BertGUI)
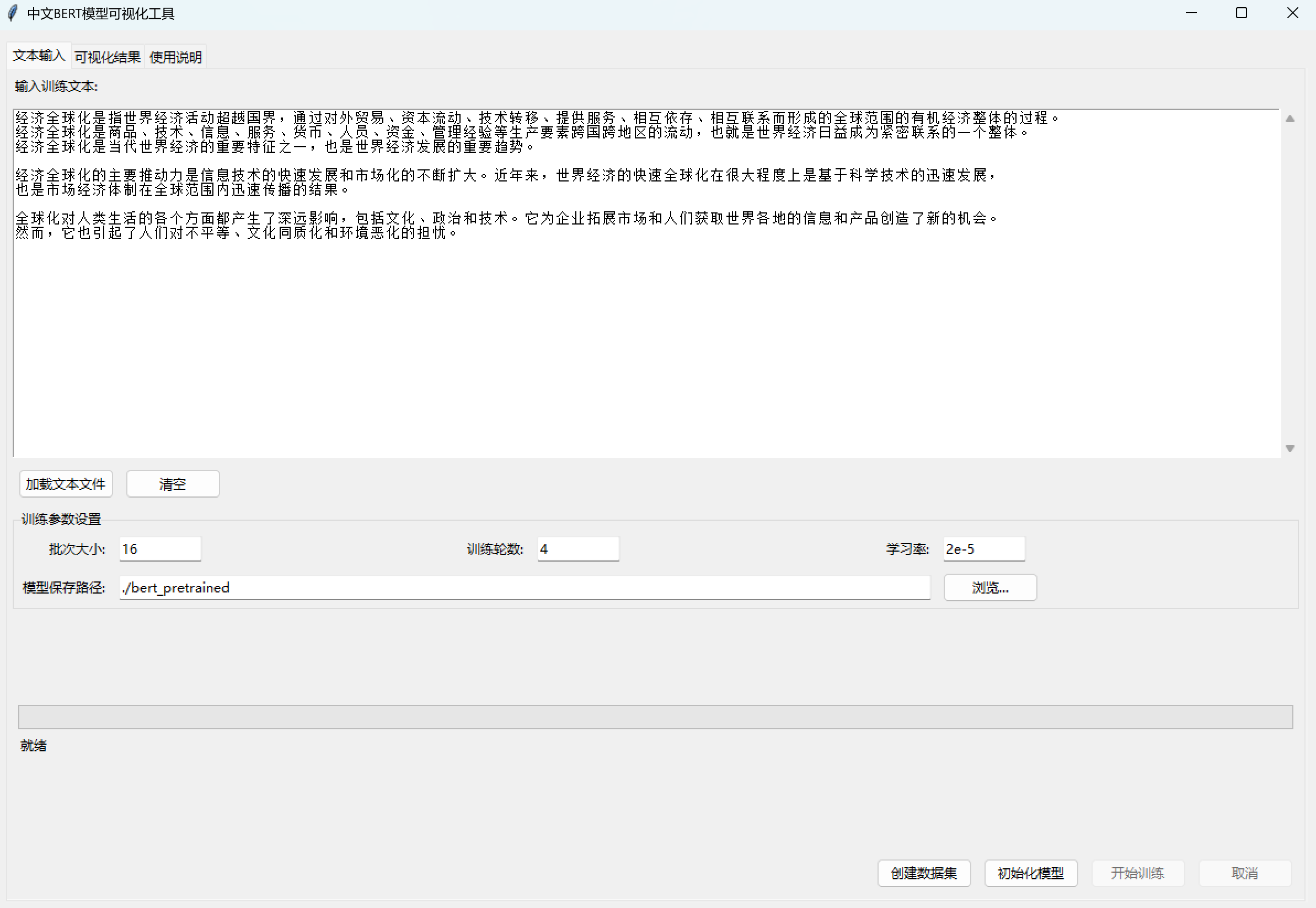
提供图形化交互界面,让非开发者也能完成 “文本输入→训练→可视化” 全流程:
- 文本输入标签页:输入训练文本、加载 TXT 文件、设置训练参数(批次大小、轮数、学习率、模型保存路径)。
- 可视化结果标签页:左侧列表显示所有生成的图表,右侧显示选中图表(支持 Matplotlib 工具栏的 “放大、保存” 等操作)。
- 使用说明标签页:指导用户完成 “创建数据集→初始化模型→开始训练” 的流程。
- 多线程与进度反馈:数据集创建、模型训练在后台线程执行(避免 GUI 卡顿),通过进度条和状态文本实时显示操作进度。
整体流程
用户通过 GUI 输入中文文本 → 点击 “创建数据集” 生成训练样本 → 点击 “初始化模型” 构建 BERT → 点击 “开始训练” 启动预训练 → 训练过程中自动生成可视化图表 → 训练完成后,在 “可视化结果” 标签页浏览所有图表,分析模型训练效果与内部机制。
八、中文BERT模型可视化工具的Python代码完整实现
import torch
import torch.nn as nn
import torch.utils.data as data
from torch.optim import AdamW
from torch.optim.lr_scheduler import LinearLR
import random
import os
import re
import math
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from sklearn.metrics import confusion_matrix
from sklearn.feature_extraction.text import TfidfVectorizer
from tqdm import tqdm
from wordcloud import WordCloud
import tkinter as tk
from tkinter import ttk, scrolledtext, messagebox, filedialog
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2Tk
import matplotlib
import threading
import queue
import time
import json
import pandas as pd# 保留TkAgg后端,适配Tkinter
matplotlib.use("TkAgg")
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
os.environ["LOKY_MAX_CPU_COUNT"] = "4"# 手动实现的中文BERT分词器
class BertChineseTokenizer:def __init__(self):self.vocab = self.create_basic_vocab()self.ids_to_tokens = {v: k for k, v in self.vocab.items()}# 特殊符号定义self.unk_token = "[UNK]"self.cls_token = "[CLS]"self.sep_token = "[SEP]"self.mask_token = "[MASK]"self.pad_token = "[PAD]"# 特殊符号IDself.unk_token_id = self.vocab[self.unk_token]self.cls_token_id = self.vocab[self.cls_token]self.sep_token_id = self.vocab[self.sep_token]self.mask_token_id = self.vocab[self.mask_token]self.pad_token_id = self.vocab[self.pad_token]self.basic_tokenizer = self._create_basic_tokenizer()def create_basic_vocab(self):vocab = {}# 特殊符号special_tokens = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]for token in special_tokens:vocab[token] = len(vocab)# 扩展常用汉字common_chars_extended = """的一是在不了有和人这中大为上个国我以要他时来用们生到作地于出就分对成会可主发年动同工也能下过子说产种面而方后多定行学法所民得经十三之进着等部度家电力里如水化高自二理起小物现实加量都两体制机当使点从业本去把性好应开它合还因由其些然前外天政四日那社义事平形相全表间样与关各重新线内数正心反你明看原又么利比或但质气第向道命此变条只没结解问意建月公无系军很情者最立代想已通并提直题党程展五果料象员革位入常文总次品式活设及管特件长求老头基资边流路级少图山统接知较将组见计别她手角期根论运农指几九区强放决西被干做必战先回则任取据处队南给色光门即保治北造百规热领七海口东导器压志世金增争济阶油思术极交受联什认六共权收证改清己美再采转更单风切打白教速花带安场身车例真务具万每目至达走积示议声报斗完类八离华名确才科张信马节话米整空元况今集温传土许步群广石记需段研界拉林律叫且究观越织装影算低持音众书布复容儿须际商非验连断深难近矿千周委素技备半办青省列习响约支般史感劳便团往酸历市克何除消构府称太准精值号率族维划选标写存候毛亲快效斯院查江型眼王按格养易置派层片始却专状育厂京识适属圆包火住调满县局照参红细引听该铁价严龙飞随着时代发展科技进步人工智能大数据机器学习自然语言处理计算机深度学习神经网络算法模型数据科学人工智能技术自然语言处理应用文本分类情感分析命名实体识别机器翻译预训练模型注意力机制Transformer架构"""for c in common_chars_extended:if c and c not in vocab:vocab[c] = len(vocab)# 扩展常用双/多字词common_bigrams_extended = ["中国", "我们", "人民", "发展", "经济", "社会", "建设", "问题", "政府", "企业","工作", "研究", "教育", "文化", "科技", "生产", "服务", "城市", "国家", "管理","系统", "理论", "实践", "安全", "环境", "健康", "信息", "时间", "空间", "质量","互联网", "人工智能", "大数据", "机器学习", "自然语言处理", "计算机", "技术", "应用","深度学习", "神经网络", "算法", "模型", "数据科学", "文本分类", "情感分析", "命名实体识别","机器翻译", "预训练模型", "注意力机制", "Transformer"]for bigram in common_bigrams_extended:if bigram not in vocab:vocab[bigram] = len(vocab)# 扩展子词subwords_extended = ["##们", "##子", "##儿", "##化", "##性", "##者", "##家", "##员", "##度", "##率","##力", "##气", "##机", "##器", "##理", "##论", "##学", "##科", "##技", "##术","##网", "##智能", "##数据", "##学习", "##处理", "##应用", "##深度", "##神经", "##算法","##模型", "##科学", "##分类", "##分析", "##识别", "##翻译", "##训练", "##注意", "##机制"]for subword in subwords_extended:vocab[subword] = len(vocab)return vocabdef _create_basic_tokenizer(self):url_pattern = r"https?|ftp://[^\s/$.?#].[^\s]*"email_pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b"number_pattern = r"\b\d+(?:\.\d+)?(?:\%\b)?"chinese_char_pattern = r"[\u4e00-\u9fff]+"english_pattern = r"[A-Za-z]+"punctuation_pattern = r"[^\w\s\u4e00-\u9fff]"pattern = f"{url_pattern}|{email_pattern}|{number_pattern}|{chinese_char_pattern}|{english_pattern}|{punctuation_pattern}"return re.compile(pattern)def basic_tokenize(self, text):text = re.sub(r"\s+", " ", text).strip()tokens = self.basic_tokenizer.findall(text)return [token for token in tokens if isinstance(token, (str, bytes))]def wordpiece_tokenize(self, token):if not isinstance(token, (str, bytes)):return [self.unk_token]sub_tokens = []start = 0token_len = len(token)if not re.search(r'[\u4e00-\u9fff]', token):return [token if token in self.vocab else self.unk_token]while start < token_len:end = min(start + 4, token_len)found = Falsewhile start < end:substr = token[start:end]if substr in self.vocab:sub_tokens.append(substr)start = endfound = Truebreakelif end - start == 1:if substr in self.vocab:sub_tokens.append(substr)start = endfound = Truebreaksubword = f"##{substr}"if subword in self.vocab:sub_tokens.append(subword)start = endfound = Truebreakend -= 1if not found:sub_tokens.append(self.unk_token)start += 1return sub_tokensdef tokenize(self, text):tokens = []for token in self.basic_tokenize(text):tokens.extend(self.wordpiece_tokenize(token))return tokensdef convert_tokens_to_ids(self, tokens):return [self.vocab.get(token, self.unk_token_id) for token in tokens]def convert_ids_to_tokens(self, ids):return [self.ids_to_tokens.get(id, self.unk_token) for id in ids]@propertydef vocab_size(self):return len(self.vocab)# 配置类定义
class BertConfig:def __init__(self, vocab_size=30522, hidden_size=128, max_position_embeddings=128,type_vocab_size=2, num_heads=2, intermediate_size=512,num_hidden_layers=3, dropout=0.1):self.vocab_size = vocab_sizeself.hidden_size = hidden_sizeself.max_position_embeddings = max_position_embeddingsself.type_vocab_size = type_vocab_sizeself.num_heads = num_headsself.intermediate_size = intermediate_sizeself.num_hidden_layers = num_hidden_layersself.dropout = dropout# 嵌入层
class BertEmbeddings(nn.Module):def __init__(self, config):super().__init__()self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12)self.dropout = nn.Dropout(config.dropout)self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))def forward(self, input_ids, token_type_ids=None):position_ids = self.position_ids[:, :input_ids.size(1)]if token_type_ids is None:token_type_ids = torch.zeros_like(input_ids)embeddings = self.word_embeddings(input_ids) + self.position_embeddings(position_ids) + self.token_type_embeddings(token_type_ids)embeddings = self.LayerNorm(embeddings)embeddings = self.dropout(embeddings)return embeddings# 多头自注意力
class BertSelfAttention(nn.Module):def __init__(self, config):super().__init__()self.num_heads = config.num_headsself.hidden_size = config.hidden_sizeself.head_size = config.hidden_size // config.num_headsassert self.head_size * self.num_heads == self.hidden_size, "hidden_size must be divisible by num_heads"self.query = nn.Linear(config.hidden_size, config.hidden_size)self.key = nn.Linear(config.hidden_size, config.hidden_size)self.value = nn.Linear(config.hidden_size, config.hidden_size)self.dense = nn.Linear(config.hidden_size, config.hidden_size)self.dropout = nn.Dropout(config.dropout)self.attention_probs = Nonedef transpose_for_scores(self, x):new_x_shape = x.size()[:-1] + (self.num_heads, self.head_size)x = x.view(new_x_shape)return x.permute(0, 2, 1, 3)def forward(self, hidden_states, attention_mask=None):mixed_query_layer = self.query(hidden_states)mixed_key_layer = self.key(hidden_states)mixed_value_layer = self.value(hidden_states)query_layer = self.transpose_for_scores(mixed_query_layer)key_layer = self.transpose_for_scores(mixed_key_layer)value_layer = self.transpose_for_scores(mixed_value_layer)device = query_layer.deviceattention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))attention_scores = attention_scores / torch.sqrt(torch.tensor(self.head_size, dtype=torch.float32, device=device))if attention_mask is not None:attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)attention_scores = attention_scores + (attention_mask * -10000.0)attention_probs = nn.Softmax(dim=-1)(attention_scores)self.attention_probs = attention_probsattention_probs = self.dropout(attention_probs)context_layer = torch.matmul(attention_probs, value_layer)context_layer = context_layer.permute(0, 2, 1, 3).contiguous()new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size,)context_layer = context_layer.view(new_context_layer_shape)output = self.dense(context_layer)return output# Transformer层与编码器
class BertLayer(nn.Module):def __init__(self, config):super().__init__()self.attention = BertSelfAttention(config)self.attention_output_layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)self.attention_dropout = nn.Dropout(config.dropout)self.intermediate = nn.Linear(config.hidden_size, config.intermediate_size)self.intermediate_act_fn = nn.GELU()self.output = nn.Linear(config.intermediate_size, config.hidden_size)self.output_layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)self.output_dropout = nn.Dropout(config.dropout)def forward(self, hidden_states, attention_mask=None):attention_output = self.attention(hidden_states, attention_mask)attention_output = self.attention_dropout(attention_output)attention_output = self.attention_output_layer_norm(hidden_states + attention_output)intermediate_output = self.intermediate(attention_output)intermediate_output = self.intermediate_act_fn(intermediate_output)layer_output = self.output(intermediate_output)layer_output = self.output_dropout(layer_output)layer_output = self.output_layer_norm(attention_output + layer_output)return layer_outputclass BertEncoder(nn.Module):def __init__(self, config):super().__init__()self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])def forward(self, hidden_states, attention_mask=None):for layer_module in self.layer:hidden_states = layer_module(hidden_states, attention_mask)return hidden_states# 完整BertModel类
class BertModel(nn.Module):def __init__(self, config):super().__init__()self.config = configself.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = nn.Linear(config.hidden_size, config.hidden_size)self.pooler_activation = nn.Tanh()def forward(self, input_ids, token_type_ids=None, attention_mask=None):embedding_output = self.embeddings(input_ids, token_type_ids)sequence_output = self.encoder(embedding_output, attention_mask)pooled_output = self.pooler(sequence_output[:, 0, :])pooled_output = self.pooler_activation(pooled_output)return sequence_output, pooled_output# 预训练头
class BertPretrainingHeads(nn.Module):def __init__(self, config):super().__init__()self.dense = nn.Linear(config.hidden_size, config.hidden_size)self.activation = nn.GELU()self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12)self.mlm_head = nn.Linear(config.hidden_size, config.vocab_size)self.nsp_head = nn.Linear(config.hidden_size, 2)def forward(self, sequence_output, pooled_output):mlm_hidden = self.dense(sequence_output)mlm_hidden = self.activation(mlm_hidden)mlm_hidden = self.LayerNorm(mlm_hidden)mlm_logits = self.mlm_head(mlm_hidden)nsp_logits = self.nsp_head(pooled_output)return mlm_logits, nsp_logits# 预训练模型
class BertForPretraining(nn.Module):def __init__(self, bert_model):super().__init__()self.bert = bert_modelself.cls = BertPretrainingHeads(bert_model.config)def forward(self, input_ids, token_type_ids=None, attention_mask=None, mlm_labels=None, nsp_labels=None):sequence_output, pooled_output = self.bert(input_ids, token_type_ids, attention_mask)mlm_logits, nsp_logits = self.cls(sequence_output, pooled_output)total_loss = Noneif mlm_labels is not None and nsp_labels is not None:mlm_loss_fct = nn.CrossEntropyLoss()nsp_loss_fct = nn.CrossEntropyLoss()mlm_loss = mlm_loss_fct(mlm_logits.view(-1, self.bert.config.vocab_size), mlm_labels.view(-1))nsp_loss = nsp_loss_fct(nsp_logits.view(-1, 2), nsp_labels.view(-1))total_loss = mlm_loss + nsp_lossreturn total_loss, mlm_logits, nsp_logits# MLM任务
def create_mlm_mask(input_ids, vocab_size, mask_token_id=103, pad_token_id=0):if not isinstance(input_ids, torch.Tensor):input_ids = torch.tensor(input_ids, dtype=torch.long)labels = input_ids.clone()probability_matrix = torch.full(labels.shape, 0.15)special_tokens_mask = (input_ids == pad_token_id)probability_matrix.masked_fill_(special_tokens_mask, value=0.0)masked_indices = torch.bernoulli(probability_matrix).bool()labels[~masked_indices] = -100indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indicesinput_ids[indices_replaced] = mask_token_idindices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replacedrandom_words = torch.randint(vocab_size, labels.shape, dtype=torch.long)input_ids[indices_random] = random_words[indices_random]return input_ids, labels# 文本处理工具类
class TextProcessor:def __init__(self, tokenizer, max_seq_len=128):self.tokenizer = tokenizerself.max_seq_len = max_seq_lenself.cls_token = tokenizer.cls_tokenself.sep_token = tokenizer.sep_tokenself.pad_token = tokenizer.pad_tokenself.mask_token = tokenizer.mask_tokendef split_long_text(self, text, chunk_size=256, overlap=50, progress_callback=None):tokens = self.tokenizer.tokenize(text)chunks = []start = 0total = len(tokens)while start < len(tokens):end = start + chunk_sizechunk_tokens = tokens[start:end]chunks.append(chunk_tokens)start = end - overlapif progress_callback and total > 0:progress = min(100, int(start / total * 100))progress_callback(progress, f"分割文本: {progress}%")return chunksdef create_sentence_pairs(self, chunks, prob_next=0.5, progress_callback=None):pairs = []total = len(chunks) - 1for i in range(len(chunks) - 1):if random.random() < prob_next:sentence1 = chunks[i]sentence2 = chunks[i + 1]label = 0else:sentence1 = chunks[i]rand_idx = random.randint(0, len(chunks) - 1)while rand_idx == i or rand_idx == i + 1:rand_idx = random.randint(0, len(chunks) - 1)sentence2 = chunks[rand_idx]label = 1pairs.append((sentence1, sentence2, label))if progress_callback and total > 0:progress = min(100, int((i + 1) / total * 100))progress_callback(progress, f"创建句子对: {progress}%")return pairsdef tokenize_pair(self, sentence1, sentence2):tokens = [self.cls_token] + sentence1 + [self.sep_token] + sentence2 + [self.sep_token]token_type_ids = [0] * (len(sentence1) + 2) + [1] * (len(sentence2) + 1)if len(tokens) > self.max_seq_len:tokens = tokens[:self.max_seq_len]token_type_ids = token_type_ids[:self.max_seq_len]input_ids = self.tokenizer.convert_tokens_to_ids(tokens)attention_mask = [1] * len(input_ids)padding_length = self.max_seq_len - len(input_ids)input_ids += [self.tokenizer.pad_token_id] * padding_lengthattention_mask += [0] * padding_lengthtoken_type_ids += [0] * padding_lengthreturn {"input_ids": torch.tensor(input_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long),"token_type_ids": torch.tensor(token_type_ids, dtype=torch.long),"tokens": tokens}def tokens_to_text(self, tokens):text = []for token in tokens:if token.startswith("##"):text.append(token[2:])elif token in [self.cls_token, self.sep_token, self.pad_token, self.mask_token]:continueelse:text.append(token)return "".join(text)# 自定义数据集
class TextDataset(data.Dataset):def __init__(self, text=None, txt_file_path=None, tokenizer=None, max_seq_len=128, min_chunk_len=50,progress_queue=None):self.tokenizer = tokenizerself.processor = TextProcessor(tokenizer, max_seq_len)self.min_chunk_len = min_chunk_lenself.progress_queue = progress_queueif text:self.data = self._preprocess_text(text)elif txt_file_path:self.data = self._load_and_preprocess(txt_file_path)else:raise ValueError("必须提供文本内容或文件路径")self.visualization_data = self._prepare_visualization_data()self.full_texts = self._get_full_texts()self.all_tokens = [sample["tokens"] for sample in self.data]def _dataset_progress_callback(self, progress, message):if self.progress_queue:try:self.progress_queue.put(("dataset", progress, message), block=False)except queue.Full:passdef _load_and_preprocess(self, txt_file_path):try:self._dataset_progress_callback(0, "正在读取文件...")with open(txt_file_path, 'r', encoding='utf-8') as f:text = f.read().replace('\n', ' ').strip()self._dataset_progress_callback(20, "文件读取完成")except Exception as e:error_msg = f"加载文件错误: {e},使用内置示例文本"self._dataset_progress_callback(-1, error_msg)text = """经济全球化是指世界经济活动超越国界,通过对外贸易、资本流动、技术转移、提供服务、相互依存、相互联系而形成的全球范围的有机经济整体的过程。经济全球化是商品、技术、信息、服务、货币、人员、资金、管理经验等生产要素跨国跨地区的流动,也就是世界经济日益成为紧密联系的一个整体。经济全球化是当代世界经济的重要特征之一,也是世界经济发展的重要趋势。经济全球化的主要推动力是信息技术的快速发展和市场化的不断扩大。近年来,世界经济的快速全球化在很大程度上是基于科学技术的迅速发展,也是市场经济体制在全球范围内迅速传播的结果。全球化对人类生活的各个方面都产生了深远影响,包括文化、政治和技术。它为企业拓展市场和人们获取世界各地的信息和产品创造了新的机会。然而,它也引起了人们对不平等、文化同质化和环境恶化的担忧。"""return self._process_text_data(text)def _preprocess_text(self, text):self._dataset_progress_callback(0, "开始处理文本...")return self._process_text_data(text)def _process_text_data(self, text):chunks = self.processor.split_long_text(text,progress_callback=self._dataset_progress_callback)chunks = [c for c in chunks if len(c) >= self.min_chunk_len]min_chunks_needed = 10while len(chunks) < min_chunks_needed:chunks.extend(chunks.copy())chunks = chunks[:50]self._dataset_progress_callback(50, "文本分割完成,开始创建句子对")pairs = self.processor.create_sentence_pairs(chunks,progress_callback=lambda p, m: self._dataset_progress_callback(50 + p // 2, m))samples = []min_samples_needed = 16total_pairs = len(pairs)while len(samples) < min_samples_needed and total_pairs > 0:for i, (s1, s2, nsp_label) in enumerate(pairs):features = self.processor.tokenize_pair(s1, s2)features["nsp_label"] = torch.tensor(nsp_label, dtype=torch.long)samples.append(features)progress = 75 + int((i + 1) / total_pairs * 25)self._dataset_progress_callback(progress, f"处理样本 {i + 1}/{total_pairs}")if len(samples) < min_samples_needed:pairs.extend(pairs.copy())total_pairs = len(pairs)self._dataset_progress_callback(100, "数据集创建完成")return samplesdef _get_full_texts(self):texts = []for sample in self.data:text = self.processor.tokens_to_text(sample["tokens"])if text.strip():texts.append(text)return textsdef _prepare_visualization_data(self):sentence_lengths = []nsp_labels = []for sample in self.data:length = sum(sample["attention_mask"].numpy())sentence_lengths.append(length)nsp_labels.append(sample["nsp_label"].item())return {"sentence_lengths": sentence_lengths,"nsp_labels": nsp_labels}def __len__(self):return len(self.data)def __getitem__(self, idx):sample = self.data[idx]input_ids = sample["input_ids"].clone()input_ids, mlm_labels = create_mlm_mask(input_ids,vocab_size=self.tokenizer.vocab_size,mask_token_id=self.tokenizer.mask_token_id,pad_token_id=self.tokenizer.pad_token_id)return {"input_ids": input_ids,"attention_mask": sample["attention_mask"],"token_type_ids": sample["token_type_ids"],"mlm_labels": mlm_labels,"nsp_labels": sample["nsp_label"],"indices": idx}# 自定义collate函数
def custom_collate_fn(batch):input_ids = [item["input_ids"] for item in batch]attention_mask = [item["attention_mask"] for item in batch]token_type_ids = [item["token_type_ids"] for item in batch]mlm_labels = [item["mlm_labels"] for item in batch]nsp_labels = [item["nsp_labels"] for item in batch]indices = [item["indices"] for item in batch]input_ids = torch.stack(input_ids)attention_mask = torch.stack(attention_mask)token_type_ids = torch.stack(token_type_ids)mlm_labels = torch.stack(mlm_labels)nsp_labels = torch.stack(nsp_labels)return {"input_ids": input_ids,"attention_mask": attention_mask,"token_type_ids": token_type_ids,"mlm_labels": mlm_labels,"nsp_labels": nsp_labels,"indices": indices}# 可视化工具类
class BertVisualizer:def __init__(self, output_dir="./visualizations"):self.output_dir = output_diros.makedirs(self.output_dir, exist_ok=True)self.train_losses = [] # 仅用于训练损失曲线和损失曲面self.figures = {} # 存储生成的图表def clear_figures(self):"""清空存储的图表,释放内存"""for fig in self.figures.values():plt.close(fig)self.figures.clear()# 1. 训练损失曲线def plot_training_loss(self, epoch):if not self.train_losses:return Nonefig, ax = plt.subplots(figsize=(10, 6))ax.plot(range(1, len(self.train_losses) + 1), self.train_losses, label='训练损失')ax.set_xlabel('步数')ax.set_ylabel('损失值')ax.set_title(f'训练过程损失曲线 (Epoch {epoch + 1})')ax.legend()ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["训练损失曲线"] = figreturn fig# 2. 句子长度分布def plot_sentence_length_distribution(self, dataset):lengths = dataset.visualization_data["sentence_lengths"]fig, ax = plt.subplots(figsize=(10, 6))sns.histplot(lengths, bins=20, kde=True, ax=ax)ax.set_xlabel('句子长度')ax.set_ylabel('频数')ax.set_title('训练数据句子长度分布')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["句子长度分布"] = figreturn fig# 3. NSP标签分布def plot_nsp_label_distribution(self, dataset):labels = dataset.visualization_data["nsp_labels"]if not labels:return Nonefig, ax = plt.subplots(figsize=(8, 6))sns.countplot(x=labels, ax=ax)ax.set_xlabel('标签')ax.set_ylabel('数量')ax.set_title('NSP任务标签分布')ax.set_xticks([0, 1])ax.set_xticklabels(['下一句', '非下一句'])for i in range(2):count = labels.count(i)ax.text(i, count + 0.1, str(count), ha='center')plt.tight_layout()self.figures["NSP标签分布"] = figreturn fig# 4. 注意力热力图def plot_attention_heatmap(self, attention_probs, tokens, layer_idx, head_idx, sample_idx=0, max_tokens=30):if not isinstance(attention_probs, torch.Tensor) or not tokens:return Nonetokens = tokens[:max_tokens]attention = attention_probs[sample_idx, head_idx, :max_tokens, :max_tokens].cpu().detach().numpy()fig, ax = plt.subplots(figsize=(12, 10))mask = np.zeros_like(attention)mask[attention == 0] = Truesns.heatmap(attention, mask=mask, cmap='YlOrRd', xticklabels=tokens, yticklabels=tokens,cbar_kws={'label': '注意力权重'}, ax=ax)ax.set_title(f'第{layer_idx + 1}层 第{head_idx + 1}个头 注意力热力图')plt.tick_params(axis='x', rotation=45)ax.set_xticklabels(ax.get_xticklabels(), ha='right')plt.tight_layout()self.figures[f"注意力热力图(层{layer_idx + 1}头{head_idx + 1})"] = figreturn fig# 5. 注意力权重分布def plot_attention_distribution(self, attention_probs, layer_idx, sample_idx=0):if not isinstance(attention_probs, torch.Tensor):return Noneattention = attention_probs[sample_idx].cpu().detach().numpy()num_heads = attention.shape[0]if num_heads < 1:return Nonefig, axes = plt.subplots(3, 4, figsize=(15, 10))axes = axes.flatten()for i in range(num_heads):sns.histplot(attention[i].flatten(), kde=True, bins=30, ax=axes[i])axes[i].set_title(f'头 {i + 1}')axes[i].set_xlim(0, 1)for i in range(num_heads, len(axes)):axes[i].axis('off')plt.suptitle(f'第{layer_idx + 1}层注意力权重分布', y=1.02)plt.tight_layout()self.figures[f"注意力权重分布(层{layer_idx + 1})"] = figreturn fig# 6. 词嵌入PCA可视化def plot_embedding_pca(self, embeddings, tokens, sample_idx=0, max_tokens=50):if not isinstance(embeddings, torch.Tensor) or not tokens:return Noneembeddings = embeddings[sample_idx, :max_tokens].cpu().detach().numpy()tokens = tokens[:max_tokens]pca = PCA(n_components=2)embeddings_2d = pca.fit_transform(embeddings)fig, ax = plt.subplots(figsize=(12, 10))ax.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], alpha=0.6)for i, token in enumerate(tokens):ax.annotate(token, (embeddings_2d[i, 0], embeddings_2d[i, 1]), fontsize=9, alpha=0.7)ax.set_title('词嵌入PCA降维可视化')ax.set_xlabel('主成分1')ax.set_ylabel('主成分2')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["词嵌入PCA可视化"] = figreturn fig# 7. 词嵌入t-SNE可视化def plot_embedding_tsne(self, embeddings, tokens, sample_idx=0, max_tokens=50):if not isinstance(embeddings, torch.Tensor) or not tokens:return Noneembeddings = embeddings[sample_idx, :max_tokens].cpu().detach().numpy()tokens = tokens[:max_tokens]tsne = TSNE(n_components=2, perplexity=10, random_state=42)embeddings_2d = tsne.fit_transform(embeddings)fig, ax = plt.subplots(figsize=(12, 10))ax.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], alpha=0.6)for i, token in enumerate(tokens):ax.annotate(token, (embeddings_2d[i, 0], embeddings_2d[i, 1]), fontsize=9, alpha=0.7)ax.set_title('词嵌入t-SNE降维可视化')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["词嵌入t-SNE可视化"] = figreturn fig# 8. 掩码位置分布def plot_mask_position_distribution(self, batch, dataset):if "input_ids" not in batch:return Nonemask_token_id = dataset.tokenizer.mask_token_idmask_positions = []for input_ids in batch["input_ids"]:if not isinstance(input_ids, torch.Tensor):input_ids = torch.tensor(input_ids)positions = torch.where(input_ids == mask_token_id)[0].cpu().numpy()mask_positions.extend(positions)fig, ax = plt.subplots(figsize=(10, 6))sns.histplot(mask_positions, bins=50, ax=ax)ax.set_xlabel('位置索引')ax.set_ylabel('掩码数量')ax.set_title('掩码位置分布')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["掩码位置分布"] = figreturn fig# 9. NSP预测混淆矩阵def plot_nsp_confusion_matrix(self, true_labels, pred_labels, epoch):if not true_labels or not pred_labels:return Noneif isinstance(true_labels, torch.Tensor):true_labels = true_labels.cpu().numpy()if isinstance(pred_labels, torch.Tensor):pred_labels = pred_labels.cpu().numpy()cm = confusion_matrix(true_labels, pred_labels)fig, ax = plt.subplots(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['下一句', '非下一句'],yticklabels=['下一句', '非下一句'], ax=ax)ax.set_xlabel('预测标签')ax.set_ylabel('真实标签')ax.set_title(f'NSP任务混淆矩阵 (Epoch {epoch + 1})')plt.tight_layout()self.figures["NSP预测混淆矩阵"] = figreturn fig# 10. 模型权重分布def plot_weight_distribution(self, model, epoch):layers_to_visualize = ['bert.embeddings.word_embeddings.weight','bert.encoder.layer.0.attention.query.weight','bert.encoder.layer.0.intermediate.weight','cls.mlm_head.weight','cls.nsp_head.weight']fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.flatten()for i, layer_name in enumerate(layers_to_visualize):if i >= len(axes):breaktry:weights = dict(model.named_parameters())[layer_name].cpu().detach().numpy()sns.histplot(weights.flatten(), bins=50, kde=True, ax=axes[i])axes[i].set_title(layer_name.split('.')[-2] if 'weight' in layer_name else layer_name)axes[i].set_xlim(-0.5, 0.5)except KeyError:axes[i].axis('off')for i in range(len(layers_to_visualize), len(axes)):axes[i].axis('off')plt.suptitle(f'模型权重分布 (Epoch {epoch + 1})', y=1.02)plt.tight_layout()self.figures["模型权重分布"] = figreturn fig# 11. 激活值分布(词嵌入层、最后一层)def plot_activation_distribution(self, activations, layer_name, epoch):if activations is None:return Noneif isinstance(activations, torch.Tensor):activations = activations.cpu().detach().numpy()fig, ax = plt.subplots(figsize=(10, 6))sns.histplot(activations.flatten(), bins=50, kde=True, ax=ax)ax.set_title(f'{layer_name} 激活值分布 (Epoch {epoch + 1})')ax.set_xlabel('激活值')ax.set_ylabel('频数')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures[f"{layer_name}激活值分布"] = figreturn fig# 12. 层间注意力相似度def plot_inter_layer_similarity(self, all_attention_probs, sample_idx=0, head_idx=0):if not all_attention_probs or not isinstance(all_attention_probs[0], torch.Tensor):return Nonenum_layers = len(all_attention_probs)similarity_matrix = np.zeros((num_layers, num_layers))for i in range(num_layers):for j in range(num_layers):attn_i = all_attention_probs[i][sample_idx, head_idx].cpu().detach().numpy().flatten()attn_j = all_attention_probs[j][sample_idx, head_idx].cpu().detach().numpy().flatten()similarity = np.corrcoef(attn_i, attn_j)[0, 1]similarity_matrix[i, j] = similarityfig, ax = plt.subplots(figsize=(10, 8))sns.heatmap(similarity_matrix, annot=True, cmap='coolwarm',xticklabels=range(1, num_layers + 1),yticklabels=range(1, num_layers + 1), ax=ax)ax.set_title(f'层间注意力相似度 (头 {head_idx + 1})')ax.set_xlabel('层索引')ax.set_ylabel('层索引')plt.tight_layout()self.figures["层间注意力相似度"] = figreturn fig# 13. 每个token的平均注意力权重def plot_token_attention(self, attention_probs, tokens, layer_idx, sample_idx=0, max_tokens=30):if not isinstance(attention_probs, torch.Tensor) or not tokens:return Noneattention = attention_probs[sample_idx].cpu().detach().numpy()avg_attention = attention.mean(axis=0).mean(axis=1)avg_attention = avg_attention[:max_tokens]tokens = tokens[:max_tokens]fig, ax = plt.subplots(figsize=(12, 6))ax.bar(range(len(tokens)), avg_attention)ax.set_xticks(range(len(tokens)))ax.set_xticklabels(tokens, rotation=90)ax.set_xticklabels(tokens, ha='right')ax.set_title(f'第{layer_idx + 1}层每个token的平均注意力权重')ax.set_xlabel('Token')ax.set_ylabel('平均注意力权重')ax.grid(True, axis='y', linestyle='--', alpha=0.7)plt.tight_layout()self.figures[f"每个token的平均注意力权重(层{layer_idx + 1})"] = figreturn fig# 14. 不同层的输出分布对比def plot_layer_output_comparison(self, layer_outputs, epoch, sample_idx=0, token_idx=0):if not layer_outputs or not isinstance(layer_outputs[0], torch.Tensor):return Nonefig, ax = plt.subplots(figsize=(10, 6))layers_to_show = min(5, len(layer_outputs))for i in range(layers_to_show):output = layer_outputs[i][sample_idx, token_idx].cpu().detach().numpy()sns.kdeplot(output, label=f'层 {i}', ax=ax)ax.set_title(f'不同层的输出分布对比 (Epoch {epoch + 1})')ax.set_xlabel('输出值')ax.set_ylabel('密度')ax.legend()ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["不同层的输出分布对比"] = figreturn fig# 15. 不同句子长度的损失对比def plot_loss_by_sentence_length(self, lengths, losses, epoch):if not lengths or not losses or len(lengths) != len(losses):return Nonelength_groups = {}for l, loss in zip(lengths, losses):group = min(50 * (l // 50 + 1), 512)if group not in length_groups:length_groups[group] = []length_groups[group].append(loss)groups = sorted(length_groups.keys())avg_losses = [np.mean(length_groups[g]) for g in groups]fig, ax = plt.subplots(figsize=(10, 6))ax.bar([str(g) for g in groups], avg_losses)ax.set_xlabel('句子长度范围')ax.set_ylabel('平均损失')ax.set_title(f'不同句子长度的损失对比 (Epoch {epoch + 1})')ax.grid(True, axis='y', linestyle='--', alpha=0.7)plt.xticks(rotation=45)plt.tight_layout()self.figures["不同句子长度的损失对比"] = figreturn fig# 16. 掩码预测准确率随位置变化def plot_mask_accuracy_by_position(self, model, dataloader, dataset, device, max_positions=512):mask_token_id = dataset.tokenizer.mask_token_idpad_token_id = dataset.tokenizer.pad_token_idposition_correct = np.zeros(max_positions)position_total = np.zeros(max_positions)model.eval()with torch.no_grad():for batch in dataloader:batch = {k: v.to(device) for k, v in batch.items() if k != 'indices'}outputs = model(** batch)mlm_logits = outputs[1]mlm_preds = torch.argmax(mlm_logits, dim=-1)mask_positions = (batch["input_ids"] == mask_token_id) & (batch["mlm_labels"] != -100)for i in range(batch["input_ids"].size(0)):positions = torch.where(mask_positions[i])[0]for pos in positions:if pos < max_positions:position_total[pos] += 1if mlm_preds[i, pos] == batch["mlm_labels"][i, pos]:position_correct[pos] += 1accuracy = np.zeros(max_positions)for i in range(max_positions):if position_total[i] > 0:accuracy[i] = position_correct[i] / position_total[i]valid_positions = np.where(position_total > 0)[0]if len(valid_positions) == 0:return Noneaccuracy = accuracy[valid_positions]fig, ax = plt.subplots(figsize=(12, 6))ax.plot(valid_positions, accuracy)ax.set_xlabel('位置索引')ax.set_ylabel('准确率')ax.set_title('掩码预测准确率随位置变化')ax.set_ylim(0, 1)ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["掩码预测准确率随位置变化"] = figmodel.train()return fig# 17. 句子对相似度分布def plot_sentence_pair_similarity(self, model, dataset, device, sample_size=50):if len(dataset) < sample_size:sample_size = len(dataset)indices = random.sample(range(len(dataset)), sample_size)samples = [dataset[i] for i in indices]cls_vectors = []nsp_labels = []model.eval()with torch.no_grad():for sample in samples:input_ids = sample["input_ids"].unsqueeze(0).to(device)attention_mask = sample["attention_mask"].unsqueeze(0).to(device)token_type_ids = sample["token_type_ids"].unsqueeze(0).to(device)_, pooled_output = model.bert(input_ids, token_type_ids, attention_mask)cls_vectors.append(pooled_output.cpu().numpy())nsp_labels.append(sample["nsp_labels"].item())similarities = []labels = []for i in range(len(cls_vectors)):for j in range(i + 1, len(cls_vectors)):sim = np.dot(cls_vectors[i].flatten(), cls_vectors[j].flatten())sim /= (np.linalg.norm(cls_vectors[i]) * np.linalg.norm(cls_vectors[j]))similarities.append(sim)labels.append(1 if nsp_labels[i] == 0 or nsp_labels[j] == 0 else 0)if not similarities:return None# ========== 列表 → DataFrame ==========import pandas as pd # 确保导入pandassim_df = pd.DataFrame({"sentence_similarity": similarities, # 定义列名,方便绘图"pair_type": labels # 定义标签列名})fig, ax = plt.subplots(figsize=(10, 6))sns.histplot(data=sim_df, # 传入DataFrame(符合seaborn要求)x="sentence_similarity", # 通过列名指定x轴hue="pair_type", # 通过列名指定分组(hue)multiple="stack",bins=30,ax=ax,hue_order=[0, 1] # 确保标签顺序与含义一致)# 调整图例标签(可选,增强可读性)ax.legend(["非下一句对", "下一句对"], title="句子对类型")ax.set_xlabel('句子对相似度 (余弦相似度)')ax.set_ylabel('数量')ax.set_title('句子对相似度分布')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["句子对相似度分布"] = figmodel.train()return fig# 18. 词嵌入相似度热图def plot_embedding_similarity(self, layer_outputs, tokens, sample_idx=0, max_tokens=20, layer_idx=-1):if not layer_outputs or not tokens:return Noneif layer_idx < 0:layer_idx = len(layer_outputs) - 1embeddings = layer_outputs[layer_idx][sample_idx, :max_tokens].cpu().detach().numpy()tokens = tokens[:max_tokens]similarity = np.zeros((max_tokens, max_tokens))for i in range(max_tokens):for j in range(max_tokens):similarity[i, j] = np.dot(embeddings[i], embeddings[j]) / (np.linalg.norm(embeddings[i]) * np.linalg.norm(embeddings[j]))fig, ax = plt.subplots(figsize=(12, 10))sns.heatmap(similarity, cmap='coolwarm', vmin=-1, vmax=1,xticklabels=tokens, yticklabels=tokens, ax=ax)ax.set_title(f'第{layer_idx + 1}层词嵌入相似度热图')plt.tick_params(axis='x', rotation=45)ax.set_xticklabels(ax.get_xticklabels(), ha='right')plt.tight_layout()self.figures[f"词嵌入相似度热图(层{layer_idx + 1})"] = figreturn fig# 19. 头重要性热图def plot_head_importance_heatmap(self, all_attention_probs, sample_idx=0):if not all_attention_probs or len(all_attention_probs) < 2:return Nonenum_layers = len(all_attention_probs)num_heads = all_attention_probs[0].shape[1] if isinstance(all_attention_probs[0], torch.Tensor) else 0if num_heads < 1:return Noneimportance_matrix = np.zeros((num_layers, num_heads))for i in range(num_layers):attention = all_attention_probs[i][sample_idx].cpu().detach().numpy()for j in range(num_heads):importance_matrix[i, j] = attention[j].mean()fig, ax = plt.subplots(figsize=(10, 8))sns.heatmap(importance_matrix, annot=True, cmap='YlGnBu',xticklabels=range(1, num_heads + 1),yticklabels=range(1, num_layers + 1), ax=ax)ax.set_title('各层注意力头的平均权重')ax.set_xlabel('头索引')ax.set_ylabel('层索引')plt.tight_layout()self.figures["头重要性热图"] = figreturn fig# 20. 损失曲面可视化def plot_loss_surface(self):if len(self.train_losses) < 10:return Nonewindow_size = min(10, len(self.train_losses) // 5)if window_size < 2:window_size = 2smoothed_losses = []for i in range(len(self.train_losses) - window_size + 1):smoothed_losses.append(np.mean(self.train_losses[i:i + window_size]))fig, ax = plt.subplots(figsize=(10, 6))ax.plot(range(len(smoothed_losses)), smoothed_losses)ax.set_xlabel('滑动窗口')ax.set_ylabel('平滑损失值')ax.set_title('损失曲面平滑可视化')ax.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()self.figures["损失曲面可视化"] = figreturn fig# 21. 参数分布对比def plot_parameter_distribution(self, model):fig, axes = plt.subplots(1, 3, figsize=(15, 5))try:# 嵌入层embed_weights = model.bert.embeddings.word_embeddings.weight.cpu().detach().numpy()sns.histplot(embed_weights.flatten(), bins=50, kde=True, ax=axes[0])axes[0].set_title('嵌入层参数')# 注意力层attn_weights = model.bert.encoder.layer[0].attention.query.weight.cpu().detach().numpy()sns.histplot(attn_weights.flatten(), bins=50, kde=True, ax=axes[1])axes[1].set_title('注意力层参数')# 输出层output_weights = model.cls.mlm_head.weight.cpu().detach().numpy()sns.histplot(output_weights.flatten(), bins=50, kde=True, ax=axes[2])axes[2].set_title('输出层参数')except AttributeError as e:print(f"绘制参数分布时出错: {e}")return Noneplt.suptitle('不同层参数分布对比', y=1.02)plt.tight_layout()self.figures["参数分布对比"] = figreturn fig# 22. TF-IDF关键词与词云def plot_tfidf_and_wordcloud(self, dataset):if not dataset.full_texts:return Nonevectorizer = TfidfVectorizer(max_features=20)tfidf_matrix = vectorizer.fit_transform(dataset.full_texts)words = vectorizer.get_feature_names_out()tfidf_scores = np.mean(tfidf_matrix.toarray(), axis=0)wordcloud_text = " ".join(dataset.full_texts)fig, axes = plt.subplots(1, 2, figsize=(15, 6))# TF-IDF条形图axes[0].barh(range(len(words)), tfidf_scores, color='skyblue')axes[0].set_yticks(range(len(words)))axes[0].set_yticklabels(words)axes[0].invert_yaxis()axes[0].set_xlabel('TF-IDF分数')axes[0].set_title('文本中重要关键词(TF-IDF)')# 词云wordcloud = WordCloud(width=800,height=400,background_color='white',font_path='C:/Windows/Fonts/msyh.ttc').generate(wordcloud_text)axes[1].imshow(wordcloud, interpolation='bilinear')axes[1].axis('off')axes[1].set_title('文本词云')plt.tight_layout()self.figures["TF-IDF关键词与词云"] = figreturn fig# 训练函数
def train_bert(model, train_dataset, batch_size=16, num_train_epochs=4, learning_rate=2e-5,output_dir="./bert_pretrained", visualizer=None, progress_queue=None):"""训练BERT模型"""if not os.path.exists(output_dir):os.makedirs(output_dir)# 设备配置device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)# 创建数据加载器train_dataloader = data.DataLoader(train_dataset,sampler=data.RandomSampler(train_dataset),batch_size=batch_size,collate_fn=custom_collate_fn)# 优化器和调度器optimizer = AdamW(model.parameters(), lr=learning_rate, eps=1e-8)total_steps = len(train_dataloader) * num_train_epochsscheduler = LinearLR(optimizer, start_factor=1.0, end_factor=0.1, total_iters=total_steps)# 记录训练过程数据nsp_true_labels = []nsp_pred_labels = []sentence_lengths_all = []losses_all = []# 初始化进度if progress_queue:try:progress_queue.put(("max", total_steps), block=False)progress_queue.put(("status", "开始训练..."), block=False)except queue.Full:passmodel.train()global_step = 0for epoch in range(num_train_epochs):print(f"\n===== 第 {epoch + 1} 轮训练 =====")epoch_loss = 0epoch_mlm_loss = 0epoch_nsp_loss = 0for step, batch in enumerate(tqdm(train_dataloader, desc="训练批次")):global_step += 1# 更新进度if progress_queue:try:progress_queue.put(("value", global_step), block=False)progress_queue.put(("status", f"Epoch {epoch + 1}/{num_train_epochs}, Step {step + 1}/{len(train_dataloader)}"), block=False)except queue.Full:pass# 过滤无关参数,执行前向传播batch_filtered = {k: v.to(device) for k, v in batch.items() if k != 'indices'}model.zero_grad()outputs = model(**batch_filtered)total_loss = outputs[0]mlm_logits = outputs[1]nsp_logits = outputs[2]# 计算损失mlm_loss_fct = nn.CrossEntropyLoss()nsp_loss_fct = nn.CrossEntropyLoss()mlm_loss = mlm_loss_fct(mlm_logits.view(-1, model.bert.config.vocab_size),batch_filtered["mlm_labels"].view(-1))nsp_loss = nsp_loss_fct(nsp_logits.view(-1, 2),batch_filtered["nsp_labels"].view(-1))# 记录关键数据epoch_loss += total_loss.item()if visualizer:visualizer.train_losses.append(total_loss.item()) # 仅用于训练损失曲线/曲面# 记录句子长度与损失关系(用于“不同句子长度的损失对比”)if 'input_ids' in batch:sentence_lengths = (batch["input_ids"] != train_dataset.tokenizer.pad_token_id).sum(dim=1).tolist()sentence_lengths_all.extend(sentence_lengths)losses_all.extend([total_loss.item()] * len(sentence_lengths))# 记录NSP预测结果(用于混淆矩阵)nsp_preds = torch.argmax(nsp_logits, dim=1).cpu().numpy()nsp_true = batch["nsp_labels"].cpu().numpy()nsp_true_labels.extend(nsp_true)nsp_pred_labels.extend(nsp_preds)# 梯度裁剪与优化torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)total_loss.backward()optimizer.step()scheduler.step()# 计算轮次平均损失avg_loss = epoch_loss / len(train_dataloader)print(f"第 {epoch + 1} 轮平均损失: {avg_loss:.4f}")# 每个epoch调用图片中存在的可视化方法if visualizer:# 数据分布类可视化(仅首次epoch生成)if epoch == 0:visualizer.plot_sentence_length_distribution(train_dataset)visualizer.plot_nsp_label_distribution(train_dataset)visualizer.plot_tfidf_and_wordcloud(train_dataset)# 训练过程类可视化visualizer.plot_training_loss(epoch) # 训练损失曲线visualizer.plot_nsp_confusion_matrix(nsp_true_labels, nsp_pred_labels, epoch) # NSP混淆矩阵visualizer.plot_weight_distribution(model, epoch) # 模型权重分布if len(sentence_lengths_all) > 0 and len(losses_all) > 0:visualizer.plot_loss_by_sentence_length(sentence_lengths_all, losses_all, epoch) # 句子长度-损失对比# 保存模型epoch_output_dir = os.path.join(output_dir, f"epoch_{epoch + 1}")os.makedirs(epoch_output_dir, exist_ok=True)torch.save(model.state_dict(), os.path.join(epoch_output_dir, "model_weights.pt"))if hasattr(train_dataset, 'tokenizer') and train_dataset.tokenizer:with open(os.path.join(epoch_output_dir, "vocab.json"), 'w', encoding='utf-8') as f:json.dump(train_dataset.tokenizer.vocab, f, ensure_ascii=False, indent=2)# 训练完成后生成剩余可视化if visualizer:if progress_queue:try:progress_queue.put(("status", "正在生成最终可视化结果..."), block=False)except queue.Full:passwith torch.no_grad():# 获取样本批次try:sample_batch = next(iter(train_dataloader))batch_indices = sample_batch["indices"]sample_tokens = [train_dataset.all_tokens[idx] for idx in batch_indices]sample_batch_device = {k: v.to(device) for k, v in sample_batch.items() if k != 'indices'}except StopIteration:sample_batch = Nonesample_tokens = []sample_batch_device = {}# 计算嵌入和层输出(用于嵌入/层输出相关可视化)embedding_output = Nonelayer_outputs = []if sample_batch_device and 'input_ids' in sample_batch_device:try:embedding_output = model.bert.embeddings(sample_batch_device["input_ids"],sample_batch_device.get("token_type_ids"))hidden_states = embedding_outputlayer_outputs.append(hidden_states)for layer in model.bert.encoder.layer:hidden_states = layer(hidden_states, sample_batch_device.get("attention_mask"))layer_outputs.append(hidden_states)except Exception as e:print(f"计算嵌入和层输出时出错: {e}")# 层输出分布对比if layer_outputs:visualizer.plot_layer_output_comparison(layer_outputs, epoch)# 嵌入相关可视化if sample_tokens and embedding_output is not None:visualizer.plot_embedding_pca(embedding_output, sample_tokens[0] if sample_tokens else [])visualizer.plot_embedding_tsne(embedding_output, sample_tokens[0] if sample_tokens else [])visualizer.plot_embedding_similarity(layer_outputs, sample_tokens[0] if sample_tokens else [])# 激活值分布(词嵌入层、最后一层)if embedding_output is not None:visualizer.plot_activation_distribution(embedding_output.cpu().detach().numpy(), "词嵌入层", epoch)if layer_outputs and len(layer_outputs) > 0:last_layer_output = layer_outputs[-1]if isinstance(last_layer_output, torch.Tensor):visualizer.plot_activation_distribution(last_layer_output.cpu().detach().numpy(), "最后一层", epoch)# 注意力相关可视化(仅第0层)if hasattr(model.bert.encoder, 'layer') and len(model.bert.encoder.layer) > 0:layer_idx = 0head_idx = 0try:layer_attention = model.bert.encoder.layer[layer_idx].attention.attention_probsif sample_tokens:visualizer.plot_attention_heatmap(layer_attention, sample_tokens[0], layer_idx, head_idx)visualizer.plot_token_attention(layer_attention, sample_tokens[0], layer_idx)visualizer.plot_attention_distribution(layer_attention, layer_idx)except AttributeError as e:print(f"无法访问注意力权重进行可视化: {e}")# 层间注意力相似度(需多层模型)if hasattr(model.bert.encoder, 'layer') and len(model.bert.encoder.layer) > 1:try:all_attention_probs = [layer.attention.attention_probs for layer in model.bert.encoder.layer]visualizer.plot_inter_layer_similarity(all_attention_probs)visualizer.plot_head_importance_heatmap(all_attention_probs)except AttributeError as e:print(f"无法收集所有层的注意力权重: {e}")# 掩码位置分布if sample_batch_device:visualizer.plot_mask_position_distribution(sample_batch_device, train_dataset)# 掩码预测准确率visualizer.plot_mask_accuracy_by_position(model, train_dataloader, train_dataset, device)# 句子对相似度分布visualizer.plot_sentence_pair_similarity(model, train_dataset, device)# 最终可视化if len(visualizer.train_losses) >= 10:visualizer.plot_loss_surface() # 损失曲面visualizer.plot_parameter_distribution(model) # 参数分布对比# 训练结束处理print("\n训练完成!")if progress_queue:try:progress_queue.put(("status", "训练完成!"), block=False)except queue.Full:pass# 保存最终模型torch.save(model.state_dict(), os.path.join(output_dir, "final_model_weights.pt"))if hasattr(train_dataset, 'tokenizer') and train_dataset.tokenizer:with open(os.path.join(output_dir, "vocab.json"), 'w', encoding='utf-8') as f:json.dump(train_dataset.tokenizer.vocab, f, ensure_ascii=False, indent=2)print(f"模型已保存至 {output_dir}")# 通知主线程生成可视化(GUI用)if progress_queue:progress_queue.put(("generate_visualizations",))return model# GUI类
class BertGUI:def __init__(self, root):self.root = rootself.root.title("中文BERT模型可视化工具")self.root.geometry("1200x800")# 窗口布局配置self.root.columnconfigure(0, weight=1)self.root.rowconfigure(0, weight=1)# 基础组件初始化self.tokenizer = Noneself.model = Noneself.dataset = Noneself.current_figure = Noneself.canvas = Noneself.toolbar = Noneself.training_thread = Noneself.dataset_thread = Noneself.progress_queue = queue.Queue(maxsize=50)self.dataset_queue = queue.Queue(maxsize=50)self.is_training = Falseself.is_creating_dataset = False# 先创建主框架和标签页容器,再初始化可视化器self.main_frame = ttk.Frame(root)self.main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)self.main_frame.columnconfigure(0, weight=1)self.main_frame.rowconfigure(0, weight=1)self.notebook = ttk.Notebook(self.main_frame)self.notebook.grid(row=0, column=0, sticky="nsew")# 初始化可视化器self.visualizer = BertVisualizer()# 创建标签页self.tab_input = ttk.Frame(self.notebook)self.tab_visualization = ttk.Frame(self.notebook)self.tab_help = ttk.Frame(self.notebook)# 标签页布局配置self.tab_input.columnconfigure(0, weight=1)self.tab_input.rowconfigure(4, weight=1)self.tab_visualization.columnconfigure(1, weight=1)self.tab_visualization.rowconfigure(0, weight=1)# 添加标签页self.notebook.add(self.tab_input, text="文本输入")self.notebook.add(self.tab_visualization, text="可视化结果")self.notebook.add(self.tab_help, text="使用说明")# 初始化各标签页内容self.init_input_tab()self.init_visualization_tab()self.init_help_tab()# 绑定事件与进度检查self.notebook.bind("<<NotebookTabChanged>>", self.on_tab_changed)self.check_progress_queue()self.check_dataset_queue()def init_input_tab(self):"""初始化文本输入标签页"""# 文本输入标题ttk.Label(self.tab_input, text="输入训练文本:").grid(row=0, column=0, sticky="w", padx=5, pady=5)# 文本输入框self.text_input = scrolledtext.ScrolledText(self.tab_input, wrap=tk.WORD)self.text_input.grid(row=1, column=0, sticky="nsew", padx=5, pady=5)# 填充示例文本self.text_input.insert(tk.END, """经济全球化是指世界经济活动超越国界,通过对外贸易、资本流动、技术转移、提供服务、相互依存、相互联系而形成的全球范围的有机经济整体的过程。
经济全球化是商品、技术、信息、服务、货币、人员、资金、管理经验等生产要素跨国跨地区的流动,也就是世界经济日益成为紧密联系的一个整体。
经济全球化是当代世界经济的重要特征之一,也是世界经济发展的重要趋势。经济全球化的主要推动力是信息技术的快速发展和市场化的不断扩大。近年来,世界经济的快速全球化在很大程度上是基于科学技术的迅速发展,
也是市场经济体制在全球范围内迅速传播的结果。全球化对人类生活的各个方面都产生了深远影响,包括文化、政治和技术。它为企业拓展市场和人们获取世界各地的信息和产品创造了新的机会。
然而,它也引起了人们对不平等、文化同质化和环境恶化的担忧。""")# 文件操作按钮file_frame = ttk.Frame(self.tab_input)file_frame.grid(row=2, column=0, sticky="w", padx=5, pady=5)ttk.Button(file_frame, text="加载文本文件", command=self.load_text_file).pack(side=tk.LEFT, padx=5)ttk.Button(file_frame, text="清空", command=lambda: self.text_input.delete(1.0, tk.END)).pack(side=tk.LEFT, padx=5)# 参数设置区域param_frame = ttk.LabelFrame(self.tab_input, text="训练参数设置")param_frame.grid(row=3, column=0, sticky="ew", padx=5, pady=5)param_frame.columnconfigure(1, weight=1)param_frame.columnconfigure(3, weight=1)param_frame.columnconfigure(5, weight=1)# 批次大小ttk.Label(param_frame, text="批次大小:").grid(row=0, column=0, sticky="e", padx=5, pady=5)self.batch_size_var = tk.StringVar(value="16")ttk.Entry(param_frame, textvariable=self.batch_size_var, width=10).grid(row=0, column=1, sticky="w", padx=5, pady=5)# 训练轮数ttk.Label(param_frame, text="训练轮数:").grid(row=0, column=2, sticky="e", padx=5, pady=5)self.epochs_var = tk.StringVar(value="4")ttk.Entry(param_frame, textvariable=self.epochs_var, width=10).grid(row=0, column=3, sticky="w", padx=5, pady=5)# 学习率ttk.Label(param_frame, text="学习率:").grid(row=0, column=4, sticky="e", padx=5, pady=5)self.lr_var = tk.StringVar(value="2e-5")ttk.Entry(param_frame, textvariable=self.lr_var, width=10).grid(row=0, column=5, sticky="w", padx=5, pady=5)# 模型保存路径ttk.Label(param_frame, text="模型保存路径:").grid(row=1, column=0, sticky="e", padx=5, pady=5)self.save_dir_var = tk.StringVar(value="./bert_pretrained")ttk.Entry(param_frame, textvariable=self.save_dir_var).grid(row=1, column=1, columnspan=4, sticky="ew", padx=5, pady=5)ttk.Button(param_frame, text="浏览...", command=self.choose_save_dir).grid(row=1, column=5, sticky="w", padx=5, pady=5)# 进度条和状态progress_frame = ttk.Frame(self.tab_input)progress_frame.grid(row=4, column=0, sticky="ew", padx=5, pady=5)progress_frame.columnconfigure(0, weight=1)self.progress_var = tk.DoubleVar()self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)self.progress_bar.grid(row=0, column=0, sticky="ew", padx=5, pady=2)self.status_var = tk.StringVar(value="就绪")ttk.Label(progress_frame, textvariable=self.status_var).grid(row=1, column=0, sticky="w", padx=5, pady=2)# 操作按钮button_frame = ttk.Frame(self.tab_input)button_frame.grid(row=5, column=0, sticky="e", padx=5, pady=10)self.create_dataset_btn = ttk.Button(button_frame, text="创建数据集", command=self.create_dataset)self.create_dataset_btn.pack(side=tk.LEFT, padx=5)self.init_model_btn = ttk.Button(button_frame, text="初始化模型", command=self.initialize_model)self.init_model_btn.pack(side=tk.LEFT, padx=5)self.train_btn = ttk.Button(button_frame, text="开始训练", command=self.start_training, state=tk.DISABLED)self.train_btn.pack(side=tk.LEFT, padx=5)self.cancel_btn = ttk.Button(button_frame, text="取消", command=self.cancel_operation, state=tk.DISABLED)self.cancel_btn.pack(side=tk.LEFT, padx=5)def init_visualization_tab(self):"""初始化可视化标签页"""# 布局配置:列表框固定宽度,图表区拉伸self.tab_visualization.columnconfigure(0, weight=0, minsize=200)self.tab_visualization.columnconfigure(1, weight=1)self.tab_visualization.rowconfigure(0, weight=1)# 左侧图表列表self.fig_listbox = tk.Listbox(self.tab_visualization, selectmode=tk.SINGLE)self.fig_listbox.grid(row=0, column=0, sticky="nsew", padx=5, pady=5)self.fig_listbox.bind('<<ListboxSelect>>', self.on_figure_selected)# 列表框滚动条scrollbar = ttk.Scrollbar(self.tab_visualization,orient=tk.VERTICAL,command=self.fig_listbox.yview)scrollbar.grid(row=0, column=0, sticky="ns", padx=(185, 0))self.fig_listbox.config(yscrollcommand=scrollbar.set)# 右侧图表显示区self.fig_frame = ttk.Frame(self.tab_visualization)self.fig_frame.grid(row=0, column=1, sticky="nsew", padx=5, pady=5)self.fig_frame.columnconfigure(0, weight=1)self.fig_frame.rowconfigure(0, weight=1)def init_help_tab(self):"""初始化帮助标签页(保留原说明文本)"""help_text = """中文BERT模型可视化工具使用说明:1. 文本输入:- 在文本框中输入中文训练文本,或通过"加载文本文件"按钮导入TXT文件- 设置训练参数(批次大小、训练轮数、学习率)和模型保存路径2. 操作流程:(1) 点击"创建数据集"按钮,将文本转换为模型可训练的格式(2) 点击"初始化模型"按钮,创建BERT模型(3) 点击"开始训练"按钮,启动模型训练过程3. 可视化结果:- 训练过程中会自动生成各类可视化图表- 在"可视化结果"标签页中,左侧列表选择图表,右侧显示选中的图表4. 注意事项:- 文本长度建议至少1000字以上,以获得较好的训练效果- 训练过程可能需要较长时间,取决于文本长度和参数设置- 训练过程中可以通过"取消"按钮终止操作
"""help_label = ttk.Label(self.tab_help, text=help_text, justify=tk.LEFT, wraplength=1000)help_label.grid(row=0, column=0, padx=20, pady=20, sticky="nsew")# 帮助页布局适配self.tab_help.columnconfigure(0, weight=1)self.tab_help.rowconfigure(0, weight=1)def load_text_file(self):"""加载文本文件"""file_path = filedialog.askopenfilename(filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")])if file_path:try:with open(file_path, 'r', encoding='utf-8') as f:content = f.read()self.text_input.delete(1.0, tk.END)self.text_input.insert(tk.END, content)self.status_var.set(f"已加载文件: {file_path}")except Exception as e:messagebox.showerror("错误", f"加载文件失败: {str(e)}")def choose_save_dir(self):"""选择模型保存目录"""dir_path = filedialog.askdirectory()if dir_path:self.save_dir_var.set(dir_path)def create_dataset(self):"""创建数据集(与模型序列长度匹配)"""if self.is_creating_dataset or self.is_training:returntext = self.text_input.get(1.0, tk.END).strip()if not text:messagebox.showwarning("警告", "请输入训练文本")returnself.tokenizer = BertChineseTokenizer()# 更新状态self.is_creating_dataset = Trueself.create_dataset_btn.config(state=tk.DISABLED)self.init_model_btn.config(state=tk.DISABLED)self.train_btn.config(state=tk.DISABLED)self.cancel_btn.config(state=tk.NORMAL)self.status_var.set("正在创建数据集...")self.progress_var.set(0)# 启动数据集创建线程(指定max_seq_len=128,与模型匹配)self.dataset_thread = threading.Thread(target=self._create_dataset_thread,args=(text, 128),daemon=True)self.dataset_thread.start()def _create_dataset_thread(self, text, max_seq_len):"""数据集创建线程"""try:self.dataset = TextDataset(text=text,tokenizer=self.tokenizer,max_seq_len=max_seq_len,progress_queue=self.dataset_queue)self.dataset_queue.put(("done", "数据集创建成功"))except Exception as e:self.dataset_queue.put(("error", f"创建数据集失败: {str(e)}"))def initialize_model(self):"""初始化BERT模型"""if not self.dataset:messagebox.showwarning("警告", "请先创建数据集")returntry:# 模型配置(维度保持一致)config = BertConfig(vocab_size=self.tokenizer.vocab_size,hidden_size=128,num_hidden_layers=2,num_heads=2,intermediate_size=512,max_position_embeddings=128)# 创建模型bert_model = BertModel(config)self.model = BertForPretraining(bert_model)# 启用训练按钮self.train_btn.config(state=tk.NORMAL)self.status_var.set("模型初始化成功")except Exception as e:messagebox.showerror("错误", f"初始化模型失败: {str(e)}")self.status_var.set("初始化模型失败")def start_training(self):"""启动训练"""if not self.dataset or not self.model or self.is_training or self.is_creating_dataset:returntry:# 获取训练参数batch_size = int(self.batch_size_var.get())num_epochs = int(self.epochs_var.get())lr = float(self.lr_var.get())save_dir = self.save_dir_var.get()# 清空历史可视化结果self.visualizer.clear_figures()self.fig_listbox.delete(0, tk.END)# 更新状态self.is_training = Trueself.create_dataset_btn.config(state=tk.DISABLED)self.init_model_btn.config(state=tk.DISABLED)self.train_btn.config(state=tk.DISABLED)self.cancel_btn.config(state=tk.NORMAL)self.status_var.set("准备开始训练...")self.progress_var.set(0)# 启动训练线程self.training_thread = threading.Thread(target=self._training_thread,args=(batch_size, num_epochs, lr, save_dir),daemon=True)self.training_thread.start()except ValueError:messagebox.showerror("错误", "请检查输入的参数是否有效")except Exception as e:messagebox.showerror("错误", f"启动训练失败: {str(e)}")def _training_thread(self, batch_size, num_epochs, lr, save_dir):"""训练线程(调用train_bert函数)"""try:train_bert(model=self.model,train_dataset=self.dataset,batch_size=batch_size,num_train_epochs=num_epochs,learning_rate=lr,output_dir=save_dir,visualizer=self.visualizer,progress_queue=self.progress_queue)self.progress_queue.put(("done", "训练完成"))except Exception as e:self.progress_queue.put(("error", f"训练失败: {str(e)}"))def cancel_operation(self):"""取消当前操作"""if self.is_training:self.is_training = Falseself.status_var.set("正在取消训练...")elif self.is_creating_dataset:self.is_creating_dataset = Falseself.status_var.set("正在取消数据集创建...")def on_figure_selected(self, event):"""选中图表并显示(保留原交互逻辑)"""selection = self.fig_listbox.curselection()if not selection:return# 清除旧图表和工具栏if hasattr(self, 'canvas') and self.canvas:self.canvas.get_tk_widget().destroy()if hasattr(self, 'toolbar') and self.toolbar:self.toolbar.destroy()# 获取选中的图表fig_name = self.fig_listbox.get(selection[0])self.current_figure = self.visualizer.figures.get(fig_name)# 主线程更新图表显示def show_figure():if self.current_figure:# 创建画布(适配保留的图表类型)self.canvas = FigureCanvasTkAgg(self.current_figure, master=self.fig_frame)self.canvas.draw()self.canvas.get_tk_widget().grid(row=0, column=0, sticky="nsew")# 工具栏布局self.toolbar = NavigationToolbar2Tk(self.canvas, self.fig_frame)self.toolbar.update()self.toolbar.grid(row=1, column=0, sticky="ew")self.root.after(0, show_figure)def on_tab_changed(self, event):"""标签页切换时更新图表列表"""current_tab = self.notebook.select()if current_tab == str(self.tab_visualization):self.fig_listbox.delete(0, tk.END)for fig_name in self.visualizer.figures.keys():self.fig_listbox.insert(tk.END, fig_name)def generate_visualizations(self):"""主线程生成可视化(仅调用保留的方法)"""if not hasattr(self, 'model') or not hasattr(self, 'dataset') or not hasattr(self, 'visualizer'):returnself.visualizer.clear_figures()try:device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.model.to(device)self.model.eval()# 数据分布类可视化self.visualizer.plot_sentence_length_distribution(self.dataset)self.visualizer.plot_nsp_label_distribution(self.dataset)self.visualizer.plot_tfidf_and_wordcloud(self.dataset)# 训练过程类可视化(仅训练损失曲线)if self.visualizer.train_losses:self.visualizer.plot_training_loss(0)# 模型内部可视化(需样本数据)sample_batch = next(iter(data.DataLoader(self.dataset,batch_size=1,collate_fn=custom_collate_fn)))batch_indices = sample_batch["indices"]sample_tokens = [self.dataset.all_tokens[idx] for idx in batch_indices]sample_batch_device = {k: v.to(device) for k, v in sample_batch.items() if k != 'indices'}# 计算嵌入和层输出embedding_output = self.model.bert.embeddings(sample_batch_device["input_ids"],sample_batch_device.get("token_type_ids"))layer_outputs = [embedding_output]hidden_states = embedding_outputfor layer in self.model.bert.encoder.layer:hidden_states = layer(hidden_states, sample_batch_device.get("attention_mask"))layer_outputs.append(hidden_states)# 嵌入相关可视化if sample_tokens:self.visualizer.plot_embedding_pca(embedding_output, sample_tokens[0])self.visualizer.plot_embedding_tsne(embedding_output, sample_tokens[0])self.visualizer.plot_embedding_similarity(layer_outputs, sample_tokens[0])# 注意力相关可视化if hasattr(self.model.bert.encoder, 'layer') and len(self.model.bert.encoder.layer) > 0:layer_attention = self.model.bert.encoder.layer[0].attention.attention_probsif sample_tokens:self.visualizer.plot_attention_heatmap(layer_attention, sample_tokens[0], 0, 0)self.visualizer.plot_token_attention(layer_attention, sample_tokens[0], 0)self.visualizer.plot_attention_distribution(layer_attention, 0)self.model.train()self.status_var.set("可视化生成完成") # 正常完成时更新状态self.on_tab_changed(None) # 同步左侧图表列表except Exception as e:import tracebackprint("可视化生成异常堆栈:\n", traceback.format_exc()) # 打印详细堆栈self.status_var.set(f"可视化生成失败: {str(e)}") # 更新错误状态messagebox.showerror("错误", f"生成可视化时出错: {str(e)}") # 弹出错误框def check_progress_queue(self):"""检查训练进度队列"""try:while not self.progress_queue.empty():item = self.progress_queue.get_nowait()if item[0] == "max":self.progress_bar.config(maximum=item[1])elif item[0] == "value":self.progress_var.set(item[1])elif item[0] == "status":self.status_var.set(item[1])elif item[0] == "done":self.status_var.set(item[1])self.is_training = Falseself.create_dataset_btn.config(state=tk.NORMAL)self.init_model_btn.config(state=tk.NORMAL)self.cancel_btn.config(state=tk.DISABLED)self.root.after(0, self.generate_visualizations)elif item[0] == "error":messagebox.showerror("错误", item[1])self.status_var.set(item[1])self.is_training = Falseself.create_dataset_btn.config(state=tk.NORMAL)self.init_model_btn.config(state=tk.NORMAL)self.cancel_btn.config(state=tk.DISABLED)elif item[0] == "generate_visualizations":self.root.after(0, self.generate_visualizations)except Exception as e:print(f"处理进度队列错误: {e}")self.root.after(100, self.check_progress_queue)def check_dataset_queue(self):"""检查数据集进度队列"""try:while not self.dataset_queue.empty():item = self.dataset_queue.get_nowait()if item[0] == "dataset":progress, message = item[1], item[2]self.progress_var.set(progress)self.status_var.set(message)elif item[0] == "done":self.status_var.set(item[1])self.is_creating_dataset = Falseself.create_dataset_btn.config(state=tk.NORMAL)self.init_model_btn.config(state=tk.NORMAL)self.cancel_btn.config(state=tk.DISABLED)elif item[0] == "error":messagebox.showerror("错误", item[1])self.status_var.set(item[1])self.is_creating_dataset = Falseself.create_dataset_btn.config(state=tk.NORMAL)self.init_model_btn.config(state=tk.NORMAL)self.cancel_btn.config(state=tk.DISABLED)except Exception as e:print(f"处理数据集队列时出错: {e}")self.root.after(100, self.check_dataset_queue)# 主程序入口
if __name__ == "__main__":root = tk.Tk()app = BertGUI(root)root.mainloop()
九、程序运行部分截图
十、总结
本文介绍了一个中文BERT模型可视化工具的实现,包含以下核心内容:
1.中文BERT分词器(BertChineseTokenizer):
- 支持多粒度分词(基础分词+WordPiece)
- 包含特殊符号、常用汉字、双/多字词和子词
- 适配中文"字-词-子词"表达特点
2.BERT模型架构:
- 完整实现嵌入层、多头自注意力、Transformer层
- 支持MLM和NSP两种预训练任务
- 可配置模型超参数(隐藏层维度、注意力头数等)
3.可视化功能:
- 22种图表类型覆盖训练过程、数据分布、模型内部机制等维度
- 支持注意力热力图、词嵌入可视化、权重分布等分析
- 提供交互式GUI界面展示可视化结果
4.应用特点:
- 面向非开发者的图形化操作流程
- 多线程处理保证界面响应
- 完整的中文文本预处理和训练功能
该工具通过可视化手段帮助用户理解BERT模型的内部工作机制,特别适合中文NLP研究和教学场景。