LOBE-GS:分块致密化效率提升

参考文献:https://arxiv.org/abs/2510.01767
abstract
3D高斯散射(3DGS)已成为实现实时高保真3D场景重建的高效表征方法。然而,将该技术扩展到城市街区等大规模无边界场景时仍面临挑战。现有分治方法通过场景分块虽缓解了内存压力,却引入了新的瓶颈:(i)均匀划分或启发式分割无法反映实际计算需求,导致分区负载严重失衡;(ii)粗-精处理流水线未能有效利用粗阶段成果,往往需要重新加载完整模型并产生高昂开销。
本研究提出LoBE-GS——一个经重新设计的大规模3DGS框架,通过负载均衡与效能优化机制突破现有局限。该框架包含三大创新:深度感知分区方法将预处理时间从数小时缩短至分钟级;基于优化的策略实现可见高斯点(计算负载的有效代理指标)在分区间均衡分布;以及通过可见性裁剪与选择性密化两项轻量技术进一步降低训练成本。在大规模城市与户外数据集上的评估表明,LoBE-GS在保持重建质量的前提下,持续实现较现有最优基线方法提升2倍的端到端训练速度,并能成功扩展到原始3DGS无法处理的超大规模场景。
1 INTRODUCTION
场景从封闭的小范围扩展至城市级等大规模、无边界环境时,3DGS 面临新的挑战:其内存与计算成本随高斯数量线性增长,优化时间和 GPU 资源消耗迅速变得难以承受。为了解决这一问题,近期方法如 CityGaussian (CityGS, 2025)、VastGaussian (VastGS, 2024)、DOGS (2024) 等采用了“分而治之(divide-and-conquer)”策略:将大场景划分为空间块,并进行并行训练。尽管这种策略降低了显存压力,但也引入了新的瓶颈:
- 负载不均衡(Load Imbalance):现有划分策略(如均匀网格或基于块大小的启发式)无法平衡各子块的计算负载。部分区域优化难度大,导致整体训练被“最慢的块”拖慢。
- 粗到细(coarse-to-fine)流程低效:一些方法(如 CityGS)虽然使用粗模型引导细化阶段,但在细阶段需完整重新加载粗模型,造成计算浪费。
本文提出 LoBE-GS(Load-Balanced and Efficient Gaussian Splatting),一种针对大规模 3DGS 优化的全新框架。LoBE-GS 通过负载均衡与并行高效训练重新设计了 3DGS 流程,显著提升了效率与扩展性。主要创新如下:
- 快速分块与相机分配:传统方法需要解决复杂的 O(M×N)投影问题(M 为块数,N 为相机数),耗时数小时。LoBE-GS 借助粗模型的深度信息,仅需每个相机一次高效投影操作,将复杂度降为 O(N),使预处理时间从“数小时”缩短到“数分钟”。
- 基于负载感知的场景划分(Load-balanced Partitioning):实验发现,块中可见高斯数量与训练时间强相关。因此 LoBE-GS 以“可见高斯数”作为负载代理指标,通过在划分时平衡该指标,实现各子块训练时间一致,消除长尾瓶颈。
- 两项计算负载优化技术
- 可见性裁剪(Visibility Cropping):在划分后剔除与当前子块无关的高斯点,加快训练且保持重建质量。
- 选择性致密化(Selective Densification):仅在必要时添加或复制高斯,避免不必要的计算膨胀。
2 RELATED WORK
2.2 大规模场景重建(Large-scale Scene Reconstruction)
在过去几十年中,大规模三维场景重建一直是计算机视觉与工程领域的重要研究方向(Snavely et al., 2006; Agarwal et al., 2011)。在城市或区域尺度上,尤其是航空视角重建(Jiang et al., 2025; Tang et al., 2025),其面临的主要挑战是巨大的内存需求与计算负担,因而需要高可扩展的训练与渲染策略。
(1)分布式训练方法(Distributed Training)
这类方法在多 GPU 间共享统一模型的参数与激活,实现全局一致的体渲染与损失计算。
- NeRF-XL (Li et al., 2024) 通过多 GPU 协作渲染与低通信机制维持统一模型;
- DOGS (Chen & Lee, 2024) 与 Grendel-GS (Zhao et al., 2024) 采用高斯原语分布式路由与共识机制。
然而,这些方法通常依赖定制化的多 GPU 通信基础设施,难以在标准硬件上部署。
(2)分而治之方法(Divide-and-Conquer)
另一类方法将大场景划分为空间子区块,并在多 GPU 上并行训练子模型。
- Block-NeRF (Tancik et al., 2022) 根据相机位置划分城市为空间块;
- Mega-NeRF (Turki et al., 2022a) 将空间划分为网格,并基于射线与网格的交叉分配像素;
- Switch-NeRF (Mi & Xu, 2023) 使用混合专家模型(mixture-of-experts)学习划分与路由策略。
在 3DGS 表示中:
- VastGS (Lin et al., 2024) 提出渐进式空间划分策略,基于可见性准则将相机与点云分配给不同块并并行优化;
- CityGS (Liu et al., 2025) 利用粗 3DGS 先验指导场景划分与并行训练,通过将无界场景映射到单位立方体后进行均匀网格划分,以提升一致性与重建质量。
然而,大多数现有工作忽略了子模型间的负载均衡问题,导致并行效率受限;此外,CityGS 在并行阶段需加载整个粗模型,计算效率低。
LoBE-GS 针对此问题提出改进,通过在各子区域内平衡 3DGS 先验并实现高效并行训练。
2.3 高效的 Gaussian Splatting 重建
随着 3DGS 技术的快速发展,研究者们也在探索其在重建与渲染效率方面的改进。
- 压缩方向:3DGS compression (Navaneet et al., 2024; Papantonakis et al., 2024) 降低模型存储成本;
- 预算约束优化:Taming 3DGS (Mallick et al., 2024) 通过引导式致密化策略在有限计算预算下实现高效训练与渲染;
- 层次细节(LoD)渲染:Ren et al. (2024), Kerbl et al. (2024) 提出了多层级 3DGS 表示以提升大场景渲染效率。
进一步的工作包括:
- CityGaussianV2 (Liu et al., 2024) 在 CityGS 基础上引入并行优化管线与 2DGS 辅助几何建模;
- Momentum-GS (Fan et al., 2024) 基于 Scaffold-GS 引入动量自蒸馏与基于重建的块加权,实现可扩展并行训练;
- CityGS-X (Gao et al., 2025) 提出混合层次化表示与多任务批处理训练,实现无缝合并与高效几何重建。
在本研究中,我们聚焦于基于粗 3DGS 先验与负载均衡并行训练的高效大规模 3DGS 重建。
| 方向 | 代表方法 | 核心思想 | 局限性 / 待改进点 |
|---|---|---|---|
| 新视角合成 (NVS) | NeRF, 3DGS | 从多视图生成逼真新视角;NeRF 精度高但慢,3DGS 实时但有混叠与内存问题 | 需要兼顾真实感与效率 |
| 大规模场景重建 | Block-NeRF, Mega-NeRF, CityGS, VastGS | 分而治之并行优化大场景 | 子块负载不均衡、粗模型加载低效 |
| 高效 3DGS 重建 | Taming 3DGS, CityGaussianV2, Momentum-GS, CityGS-X | 压缩、分层、并行与自蒸馏优化 | 仍需更好的负载均衡与可扩展性 |
| 本研究(LoBE-GS) | – | 引入基于可见高斯的负载均衡划分与快速并行训练 | 实现高效、可扩展的大规模重建 |
3 ANALYSIS OF SCENE PARTITIONING AND LOAD BALANCING
3.1 IMPACT OF SCENE PARTITION ON LOAD BALANCING
大规模 3DGS 系统通常采用“划分–合并(partition–and–merge)”范式:场景被划分为 B 个空间子块(spatial blocks),每个子块独立并行优化,最终再合并为完整模型。
部分方法进一步采用coarse-to-fine策略:先训练粗模型,再进行场景划分与并行细训练,最后执行合并阶段。
设:

若假设有足够的计算资源可并行运行所有子块,则整体端到端训练时间为:
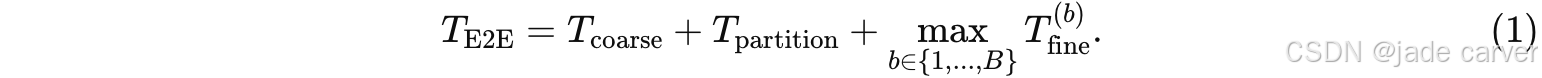
因此,一个有效的划分策略应当:
- 平衡各子块的计算负载,最小化最慢块的运行时间;
- 同时保持重建质量不下降。
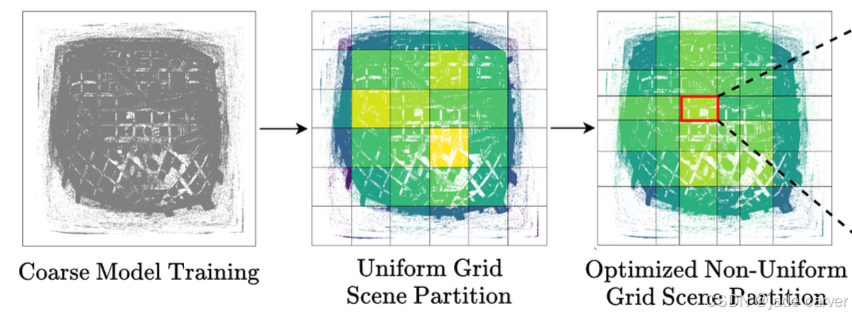
以往方法多采用启发式指标(如:划分面积相等(citygaussian)、相机数量均衡或点数均衡(blockgaussian)),但这些指标与实际细阶段运行时间的相关性缺乏系统研究。
以 CityGS 为例,它在收缩空间中通过“等面积划分”方式进行场景分块。
图 1 展示了 Building 数据集的每块细阶段运行时间:
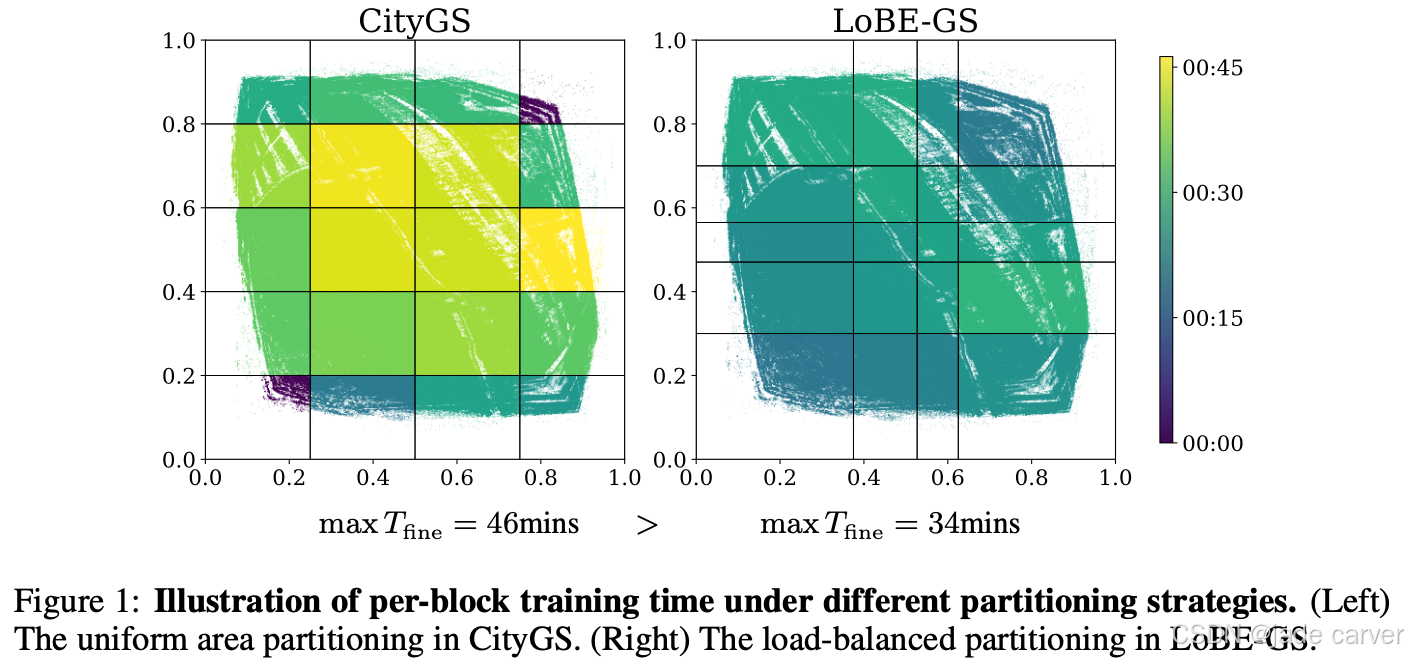
图 1(a):CityGS 的策略导致训练负载严重不均衡;图 1(b):LoBE-GS 使用不同代理指标后,显著提升了运行时间分布的均衡性。
在其他数据集上也观察到类似趋势(见附录 A.2),表明传统启发式指标往往无法有效反映真实计算负载,从而导致长尾块拖慢整体端到端训练时间。
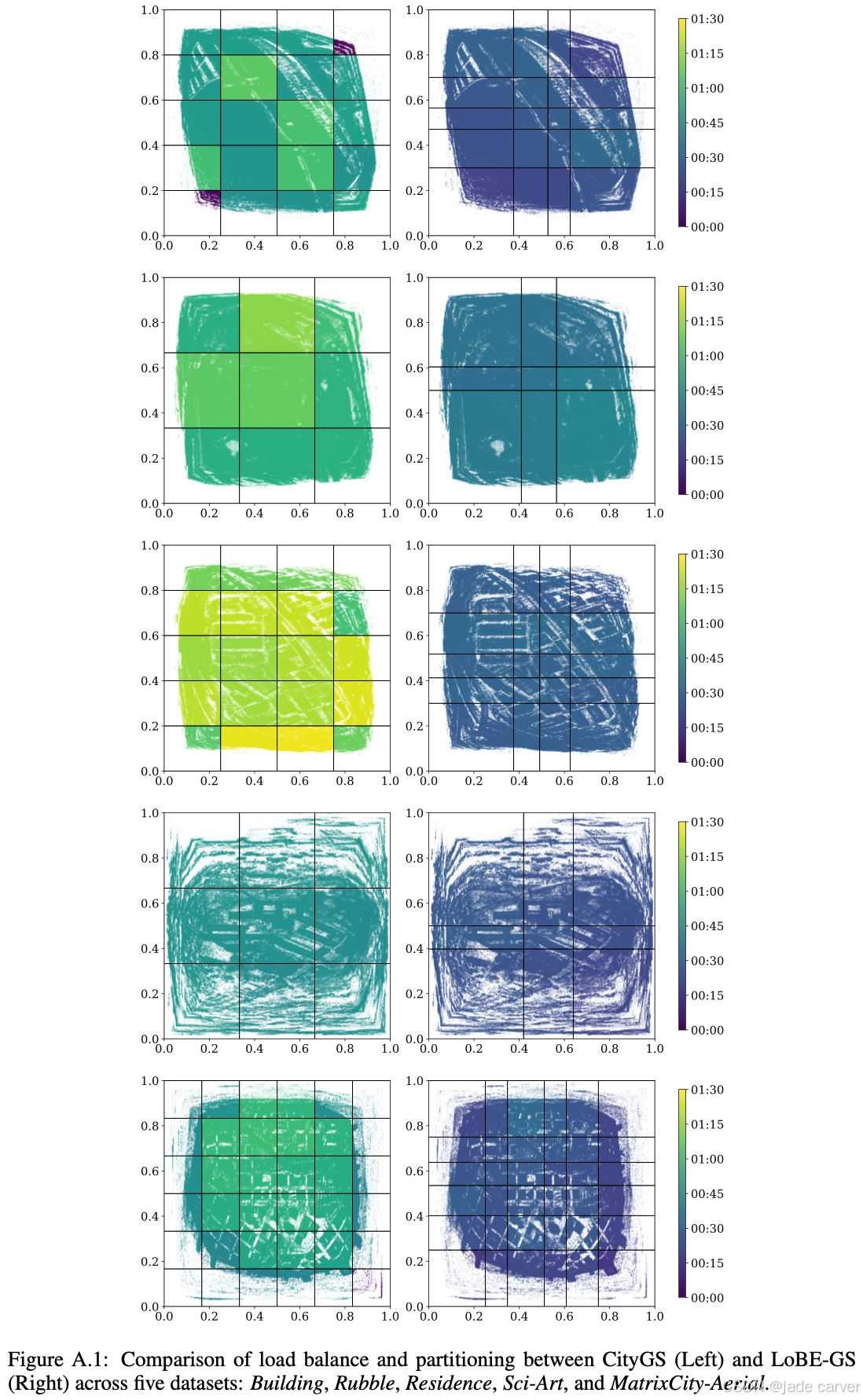
3.2 RUNTIME CORRELATION WITH PER-BLOCK PREDICTORS

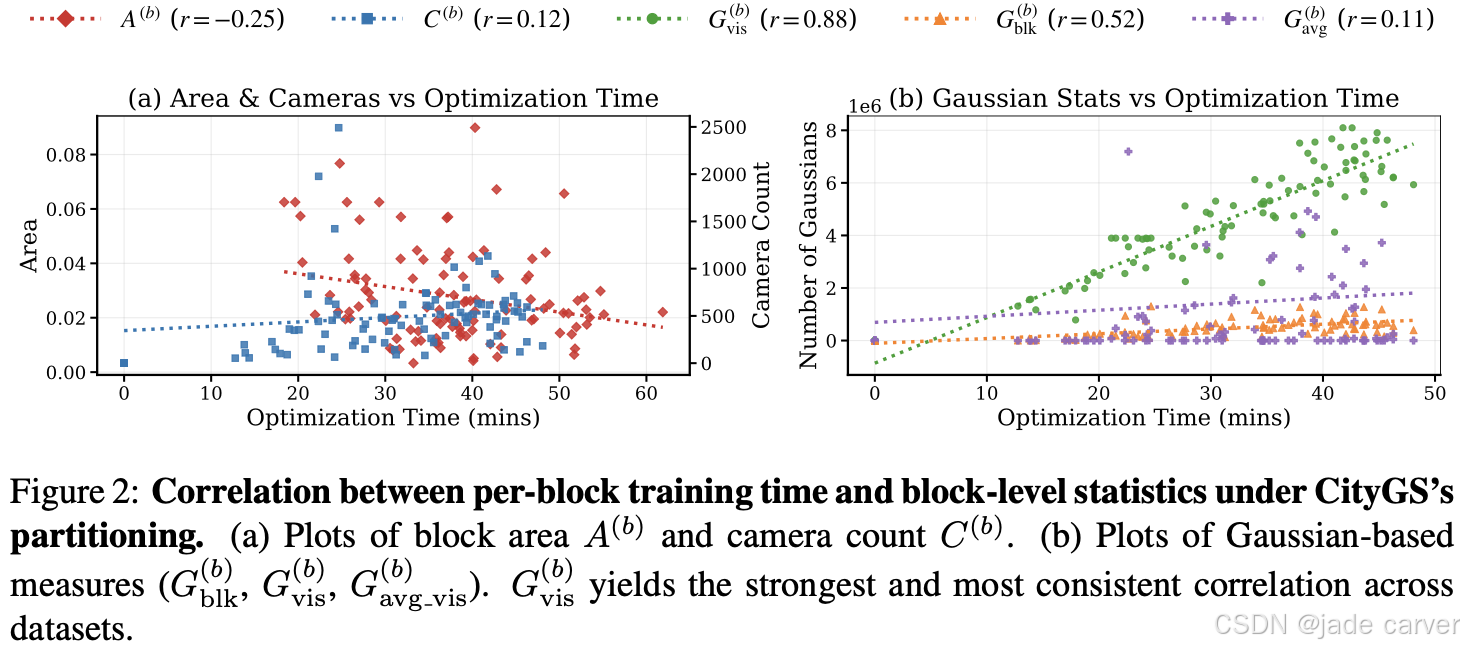
实验结果表明:
- 面积 A(b)(被多篇工作采用,如CityGaus-sian, Momentum-GS)与运行时间的相关性较弱;
- 块内高斯数
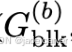 也几乎无相关,说明仅考虑空间中包含的高斯数低估了实际计算负载;
也几乎无相关,说明仅考虑空间中包含的高斯数低估了实际计算负载; - 可见高斯数
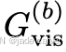 表现出最强且最稳定的相关性,是最可靠的运行时间预测指标;将其归一化为平均可见高斯数
表现出最强且最稳定的相关性,是最可靠的运行时间预测指标;将其归一化为平均可见高斯数 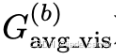 反而削弱相关性;
反而削弱相关性; - 相机数量 C(b)(被 DOGS、Yuan et al., 2025 等方法采用)同样仅表现出弱相关。
| 研究目标 | 方法 | 主要发现 | 结论 |
|---|---|---|---|
| 评估场景划分对负载均衡的影响 | 分析 CityGS 与 LoBE-GS 在不同划分指标下的性能 | 传统等面积/等相机策略导致显著负载不均 | LoBE-GS 通过基于可见高斯数的划分实现更均衡训练 |
| 寻找细阶段运行时间的可靠预测指标 | 比较面积、相机数、块内高斯数、可见高斯数等指标 | 可见高斯数与运行时间的 Pearson 相关最高 | (G_{\text{vis}}^{(b)}) 是最有效的负载代理指标 |
4 METHODOLOGY
在以往的大规模 3D Gaussian Splatting (3DGS) 系统中,常采用 coarse-to-fine 的训练流程:
- Coarse 阶段:先训练一个粗模型 GcoarseGcoarse;
- Fine 阶段:将场景划分为多个 block(区域),每个 block 独立 fine-tune;
- 最后再 merge 成完整场景。
但问题是:
各 block 的训练负载(fine-stage runtime)差异很大,导致整体训练时间被最慢的 block 限制。
因此,LoBE-GS 提出了一种负载均衡感知的划分策略,希望通过合理分区,使得所有 block 的 fine-training 时间尽量相近,从而缩短整体训练时间。
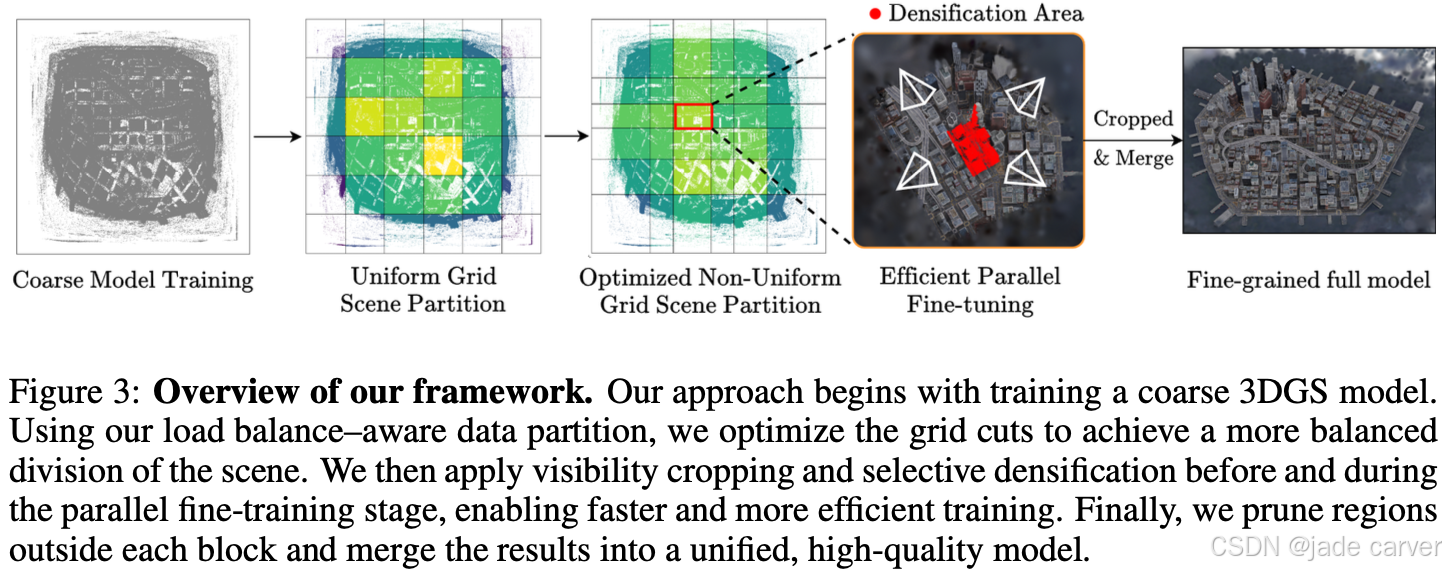
4.1 LOAD BALANCE-AWARE SCENE PARTITION
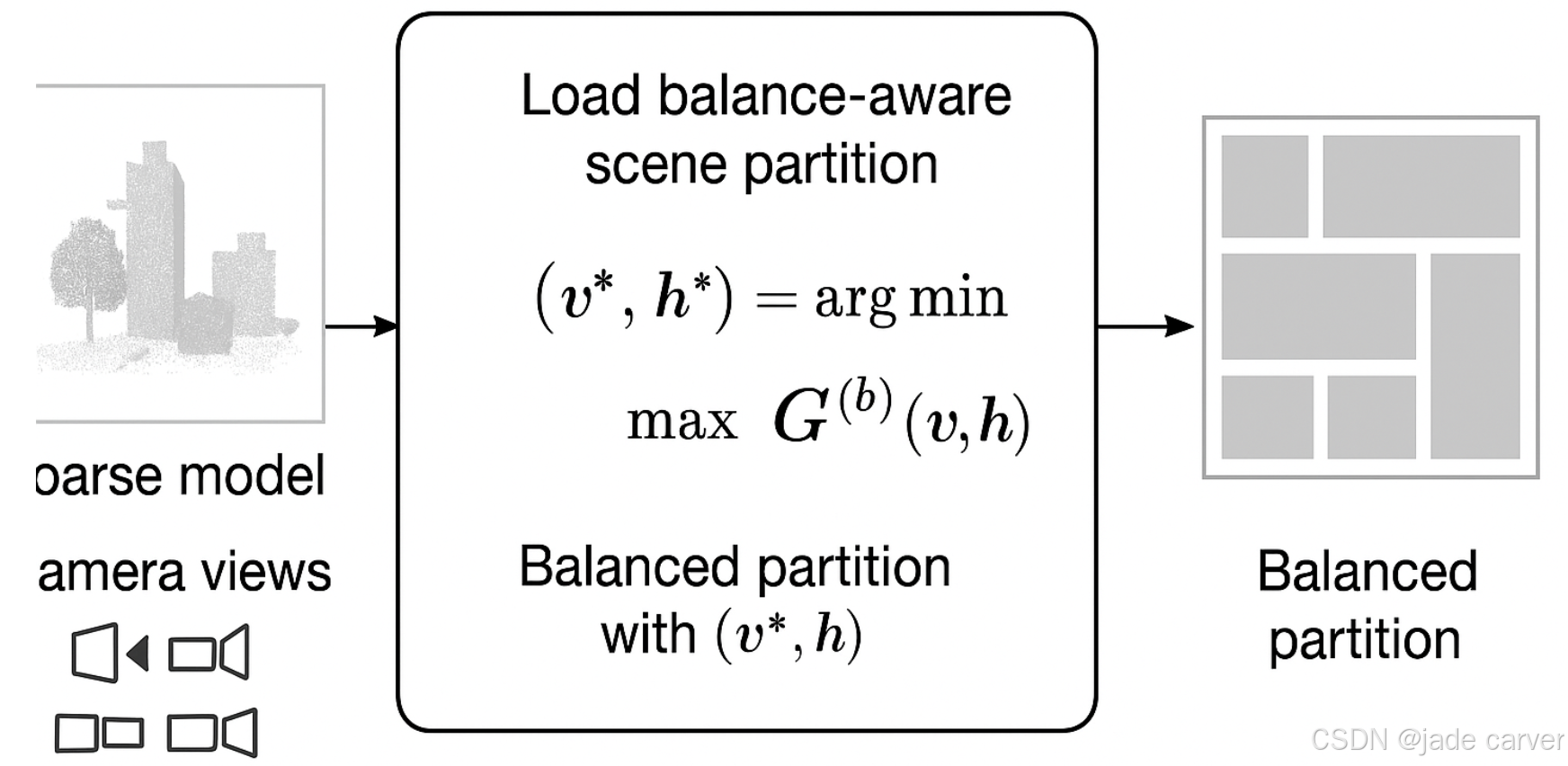
LoBE-GS 的划分目标是最小化所有 block 的最大 fine 阶段负载:


换句话说:
通过调整划分边界(v,h),让各 block 的 visible Gaussians 数目尽量接近,以此实现训练负载的平衡。
符号 含义 ( v, h ) 待优化的切割线位置(垂直和水平) ( b ) block 编号 在该划分下,第 b 个 block 的可见高斯数 当前划分下最“重”的 block 的负载 找到切割线配置,使最“重”的 block 尽量轻
一句话概括/:我们要移动这些切割线,让“最重的块”尽量变轻,最终所有块的负载趋于均衡。
由于 ![]() 是非可微的(涉及 visibility 判断),LoBE-GS 采用Bayesian Optimization (BO) + Gaussian Process (GP) 作为黑箱优化手段。这是常用于“非可微目标函数全局优化”的方法。
是非可微的(涉及 visibility 判断),LoBE-GS 采用Bayesian Optimization (BO) + Gaussian Process (GP) 作为黑箱优化手段。这是常用于“非可微目标函数全局优化”的方法。


| 步骤 | 内容 |
|---|---|
| Step 1 | 输入 coarse 模型 ( |
| Step 2 | 初始化均匀切割线 ( |
| Step 3 | 设定可移动范围,防止切割线错乱 |
| Step 4 | 使用 BO 反复迭代:提出候选划分 → 计算 ( |
| Step 5 | 输出最佳划分 ( |
| Step 6 | 进入 fine-tuning 阶段,每个 block 独立训练 |
| 优点 | 说明 |
|---|---|
| ✅ 负载更平衡 | 基于实际负载代理(visible Gaussians),而非几何面积或摄像机数 |
| ✅ 优化自动化 | 通过 BO 自动调整划分,无需手工经验参数 |
| ✅ 提升并行效率 | fine 阶段每个 block 所需时间更接近,总体训练更快 |
4.2 FAST CAMERA SELECTION
4.2.1常规分块做法
以前的系统(如 CityGS)做法如下:
- 场景划分成 M 个 blocks;
- 每个相机有 N 个视角;
- 对每个 block:
- 过滤掉不在 block 内的高斯;
- 渲染这个 block 的图像;
- 与全景图(coarse render)计算结构相似度 SSIM;
- 判断该相机是否覆盖这个 block。
这就需要 (M + 1) × N 次投影渲染,极其耗时。实验中,camera selection 本身就占了总训练时间的一半!
4.2.2本文做法
LoBE-GS 提出一种只需 N 次投影 的快速方法。核心思路是:
LoBE-GS 的 Fast Camera Selection 通过将相机深度图反投影成点云,并基于点的空间覆盖率选择相机,大幅减少了计算复杂度(O(M×N) → O(N)),并保持了高质量重建。
一句话说:“不用为每个 block 渲染一遍,而是先从每个相机的深度图反投影出 3D 点云,再计算这些点在每个 block 中的可见比例。”


4.3 VISIBILITY CROPPING AND SELECTIVE DENSIFICATION
LoBE-GS 框架中最后一个关键优化阶段——如何在每个 block 的细化训练(fine-training)中同时节省显存与计算时间,而不降低重建质量。它提出了两个互补的策略:visibility cropping(可见性裁剪) 和 selective densification(选择性致密化)
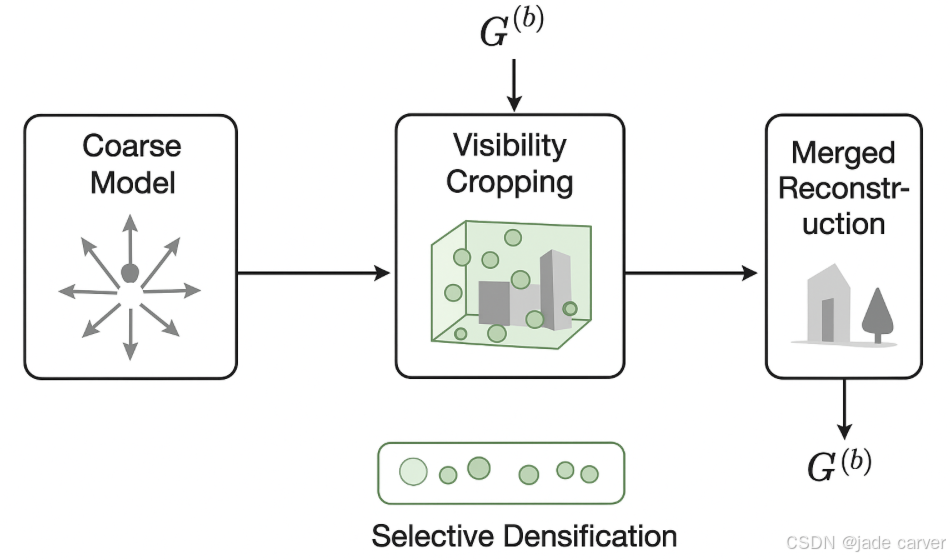
4.3.1问题提出
在大场景 coarse-to-fine 的训练流程中:
- 先训练一个全局粗模型 GcoarseGcoarse;
- 然后将场景分成多个 block;
- 对每个 block 再进行并行细化训练(fine-training)。
问题在于:
- 显存浪费:每个 block 的训练都会把整份 coarse 模型加载进 GPU(数百万个 Gaussians),即使大部分根本不属于这个 block;
- 时间浪费:虽然渲染时非可见点会被剔除(frustum culling),但 Adam 优化器依然会维护并更新它们的动量项(momentum),导致大量无用计算。
所以本文目标是:在保证重建质量的前提下,只让 必要的高斯点 参与训练与优化。
4.3.2解决
1.基于可见性的裁剪
最直接的想法是:对每个 block,只保留它空间范围内的高斯点。即:
![]()
但是这样带来的后续影响是:有些高斯虽然几何上在 block 边界之外,但在某些相机视角下仍可见,并且这些高斯被错误裁掉后,会导致边界区域出现断裂(artifact)或空洞(hole)。
解决办法就是只保留那些在该块对应的相机集合 C(b)中「至少有一个相机能看到」的高斯;这样可以在不降低重建质量的前提下,大幅减少参与训练的高斯数量;同时降低 GPU 内存占用和计算负担。也即:
![]()
在实现上,在每次贝叶斯优化(BO)迭代中,LoBE-GS 都需要重新计算![]() ;为了效率,作者用 NVIDIA Warp 实现了整个过程(Warp 是高性能 CUDA 加速框架,使得可见性计算几乎达到原生 GPU 性能);最终显著缩短了分区(partitioning)阶段的时间。
;为了效率,作者用 NVIDIA Warp 实现了整个过程(Warp 是高性能 CUDA 加速框架,使得可见性计算几乎达到原生 GPU 性能);最终显著缩短了分区(partitioning)阶段的时间。
2.选择性致密化
前面是为了解决block区域的边界因为某些相机视角可见但高斯球被裁剪导致断裂或者空洞的问题,我们把这些高斯球做了保留,现在还有另外一个问题,就是在致密化过程中,这些高斯球应不应该参与?答案是不应该!
这样显著减少新高斯的生成数量;降低 GPU 内存使用;提高优化效率;同时保持每个 block 的重建精度。
| 问题 | LoBE-GS 解决方式 | 效果 |
|---|---|---|
| 显存占用过高(加载整个 coarse model) | Visibility Cropping:仅保留可见高斯 | 显存减少 × 训练加速 |
| 边界高斯被过度裁剪导致质量下降 | 基于可见性而非几何边界筛选高斯 | 保留质量、减少误删 |
| Densification 扩散至无关区域 | Selective Densification:仅对块内部 densify | 更高效率、减少冗余增长 |
5 EXPERIMENTS
5.1 EXPERIMENTAL SETUP
在五个大规模场景上进行了实验,其中包括四个真实世界数据集(Mill19 的 Building 与 Rubble,UrbanScene3D 的 Residence 与 Sci-Art)和一个合成数据集(MatrixCity 的 Aerial)。为了保证公平性,所有真实场景图像均下采样 4 倍,MatrixCity 图像宽度统一为 1600 像素。实验对比了多种最先进的大规模 3DGS 方法,包括 CityGS、VastGS、DOGS 以及改进版 3DGS†。其中 VastGS 与 DOGS 的结果部分来自原论文报告,且 VastGS 未采用外观建模;为公平起见,文中额外使用了其非官方实现 VastGS† 进行训练效率比较。重建质量通过 PSNR、SSIM、LPIPS 指标评估,并根据不同基线方法选择是否进行颜色校正。效率评估指标包括 Tcoarse、Tpartition、max Tfine、TE2E,运行实验均在相同硬件环境下完成,各数据集的分块数量与 CityGS 保持一致(如 MatrixCity-Aerial 为 36 块,Building 与 Residence 各 20 块等)。
5.2 QUANTITATIVE RESULTS
根据表 1 和表 2,本方法在各数据集上总体达到与 CityGS 相当或更好的重建质量,PSNR/SSIM 提升约 1.0–1.02×,LPIPS 始终更低,仅在个别数据集上略有 PSNR 损失,但换来了更高的感知质量。与 3DGS† 相比,整体提升更为显著,PSNR/SSIM 提高约 1.05–1.2×,LPIPS 降低近 2×。在采用颜色校正的指标下,本方法在多数数据集上也超越 VastGS† 和 DOGS,在 C-PSNR 与 C-SSIM 上均取得领先,说明其在保证视觉质量的同时具备更好的鲁棒性。
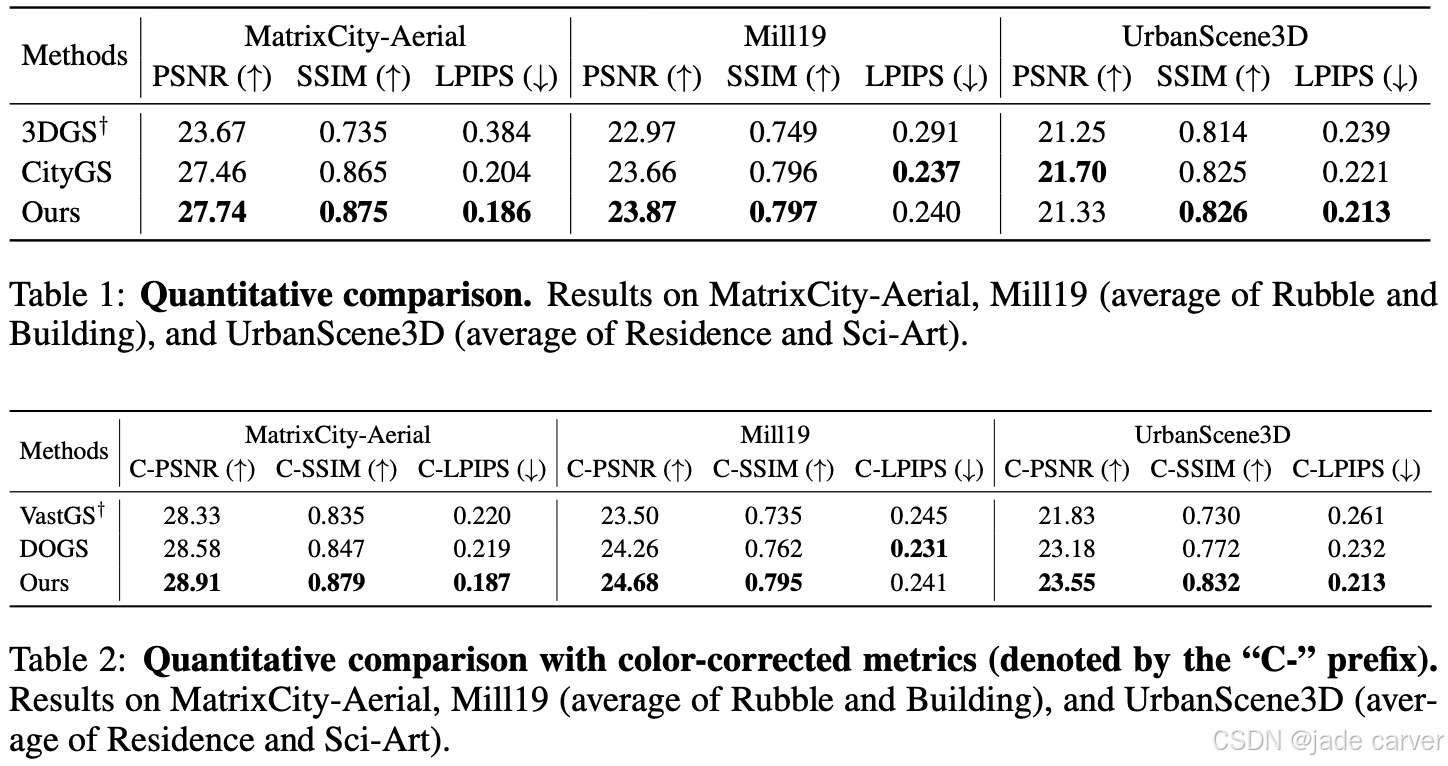
在运行时分析(表 3)中,该方法在所有数据集上都表现出最低的粗阶段(Tcoarse)耗时和最慢块的精阶段(max Tfine)耗时;在多数数据集上还实现了最优的分区时间(Tpartition)和端到端运行时间(TE2E)。尽管在 Mill19 数据集上 TE2E 略长于 VastGS†(后者未计入 Tcoarse),但本方法在 PSNR、SSIM、LPIPS 上均优于其结果,体现了更优的质量–延迟平衡。
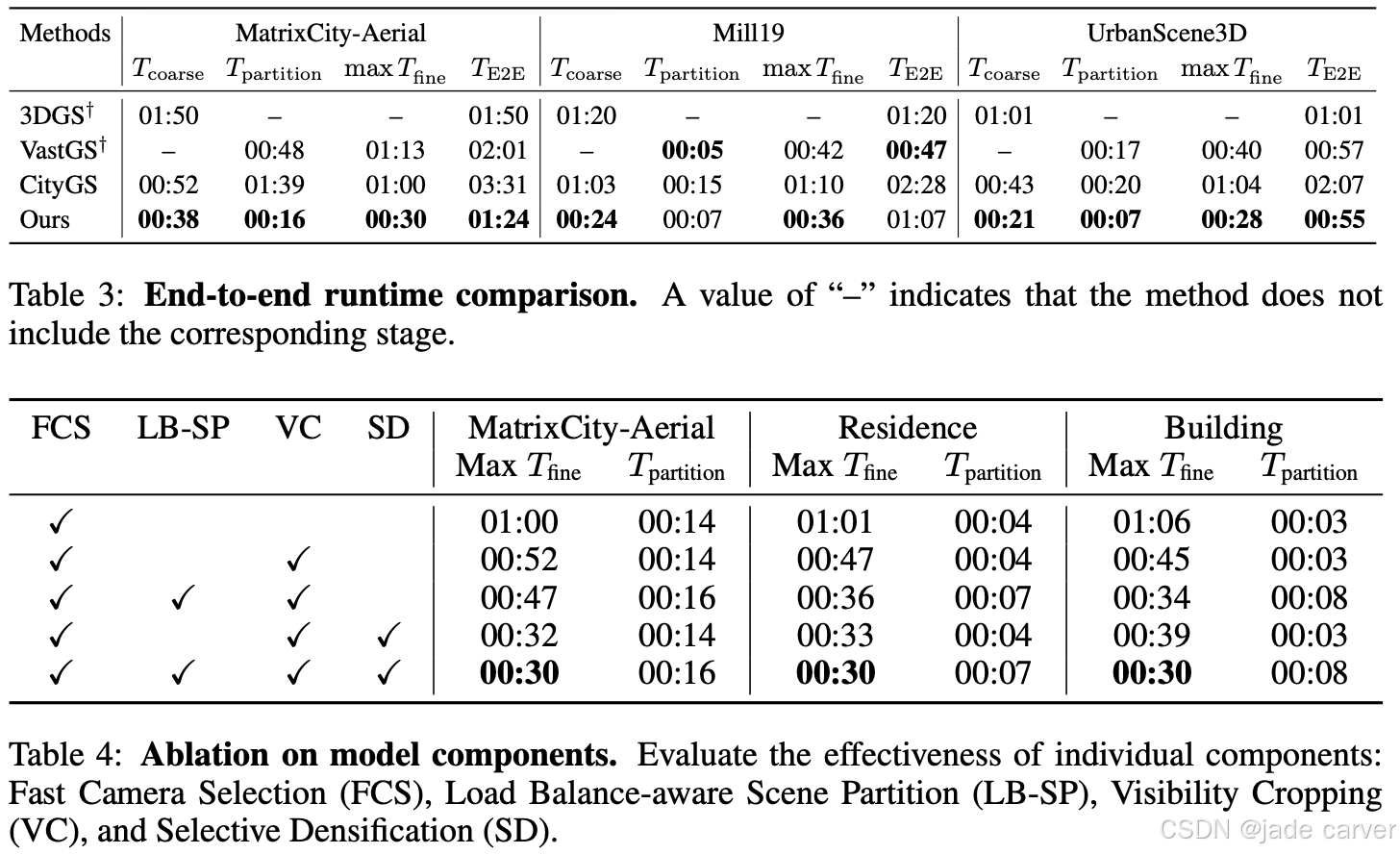
消融实验(表 4),验证了各模块的独立与协同效果。
6 CONCLUSION
LoBE-GS 的核心思想是引入一个 计算负载代理(computational-load proxy),通过该指标对粗级 3DGS 模型进行优化分区,从而在场景划分阶段实现更均衡的计算分配。
未来工作方向包括:
- 在更大、更复杂的场景中测试 LoBE-GS,以验证其在更多分块下的可扩展性;
- 探索与 层次细节(Level of Detail, LoD) 和 2DGS 表示 的融合;
- 在包含稀疏视角的多样化数据集上进行评估;
- 以及研究超越现有网格划分(grid-based)方案的 更灵活的场景分区策略。