【论文阅读】Visual Planning: Let’s Think Only with Images
https://arxiv.org/pdf/2505.11409
以下从六个维度对论文《Visual Planning: Let’s Think Only with Images》进行导读:
一、研究动机:核心问题与背景
核心问题:
当前多模态大模型(MLLMs)虽能处理图像输入,但其推理过程仍完全依赖文本模态,导致在空间、几何、物理动态等视觉主导任务中表现不佳。论文质疑:“是否必须将视觉信息转换为文本才能推理?” 并提出——能否让模型像人类一样“用图像思考”?
背景驱动:
- 模态鸿沟:视觉信息被强行压缩为文本(如物体名称、坐标)时,丢失空间关系与细节。
- 认知科学依据:双编码理论(Dual Coding Theory)指出,人类存在独立的非语言推理通道(如心理意象)。
- 现有MLLM的局限:即便生成中间图像(如Visual Sketchpad),仍以文本为决策核心,图像仅是辅助工具。
二、研究现状:领域综述与前人工作
| 研究方向 | 代表工作 | 局限性 |
|---|---|---|
| 文本推理主导 | CoT、MM-CoT、MVoT | 推理链完全依赖文本,视觉信息仅作为输入或插图,未参与决策。 |
| 工具辅助视觉 | Visual Sketchpad、o3 | 用外部工具生成图像,但图像不驱动决策,仅为文本推理的可视化注释。 |
| RL用于视觉 | Perception-R1、VLM-R1 | RL用于优化文本输出(如VQA答案),未解决视觉空间推理的模态不匹配问题。 |
| 纯视觉模型 | LVM(Large Vision Model) | 仅支持图像生成,无推理能力,需扩展至序列决策。 |
空白点:
首次提出**“完全脱离文本、仅用图像进行多步规划”**的范式,并验证其可行性。
三、创新点:思路来源与突破
| 创新维度 | 具体突破 |
|---|---|
| 范式创新 | 提出Visual Planning:用图像序列作为推理链,无需文本中介。 |
| 训练框架 | 设计VPRL(两阶段RL框架): ① 随机游走初始化(探索) ② GRPO优化(利用)。 |
| 奖励设计 | 针对高维视觉输出,提出进度奖励(Progress Reward): - 有效动作:+1(靠近目标) - 无效动作:-5(撞墙、穿模) |
| 模态纯净 | 首次用**纯视觉模型(LVM)**完成规划,完全排除语言监督的干扰。 |
四、解决方案:技术细节拆解
1. 问题形式化
- 输入:初始视觉状态 ( v_0 )(如迷宫鸟瞰图)。
- 输出:视觉规划轨迹 ( T = (\hat{v}_1, \hat{v}_2, …, \hat{v}_n) ),每帧( \hat{v}_i )为下一状态的图像(非文本动作)。
2. 两阶段训练框架(VPRL)
| 阶段 | 目标 | 方法 | 关键设计 |
|---|---|---|---|
| Stage 1 | 探索初始化 | 用随机游走轨迹监督微调(VPFT) | 避免模仿最优轨迹导致的探索塌陷 |
| Stage 2 | 策略优化 | GRPO(Group Relative Policy Optimization) | 无需价值网络,通过组内对比计算优势:( A^{(k)} = r^{(k)} - \text{mean}® ) |
3. 状态-动作解析(P函数)
- 输入:相邻两帧图像( (v_i, \hat{v}_{i+1}) )。
- 输出:离散动作(上/下/左/右/捡/放)或无效标记。
- 实现:
- 网格化+灰度化→计算IoU定位智能体坐标。
- 通过像素级MSE检测穿墙、消失等非法行为。
4. 奖励函数

五、实验设计:验证与对比
1. 任务设计
| 任务 | 核心挑战 | 动作空间 |
|---|---|---|
| FROZENLAKE | 避坑(冰洞) | 四方向移动 |
| MAZE | 避障(黑色墙体) | 四方向移动 |
| MINIBEHAVIOR | 多步操作(捡→运→放) | 四方向+捡/放 |
2. 对比基线
| 类型 | 代表模型 | 输入/输出模态 |
|---|---|---|
| 闭源 | Gemini 2.0 Flash/2.5 Pro | 图像+文本→文本 |
| 开源 | Qwen2.5-VL-Instruct-3B | 图像+文本→文本 |
| 视觉监督 | VPFT(监督微调) | 图像→图像 |
3. 评估指标
- EM(Exact Match):轨迹与最短路径完全一致(严苛)。
- PR(Progress Rate):连续正确步骤占比(宽松,反映部分能力)。
4. 关键结果
| 方法 | FROZENLAKE (EM) | MAZE (EM) | MINIBEHAVIOR (EM) | 平均提升 |
|---|---|---|---|---|
| 最佳文本(Gemini 2.5 Pro) | 72.0% | 21.5% | 37.6% | baseline |
| VPFT(视觉监督) | 75.4% | 59.0% | 33.8% | +22% |
| VPRL(视觉RL) | 91.6% | 74.5% | 75.8% | +40% |
六、研究结论:核心发现
-
视觉规划>文本规划:
在视觉主导任务中,纯视觉推理显著优于文本推理(平均EM提升40%+),且随环境复杂度增加优势扩大(见图5)。 -
RL>监督学习:
VPRL比VPFT在所有任务上提升20%+,且非法动作率下降25%-50%,表明RL能学会遵守物理约束。 -
探索初始化关键:
直接用VPFT初始化RL会导致探索塌陷(熵→0),而随机游走初始化保持高熵+低非法率(见图6)。 -
泛化性:
在更大网格(OOD)上,VPRL仍保持20%+的EM,而文本方法降至10%以下。
七、未来方向:开放问题与拓展
| 方向 | 具体建议 |
|---|---|
| 模型规模 | 将VPRL扩展至原生多模态生成模型(如Anole、Emu3),突破3B参数限制。 |
| 效率优化 | 用稀疏视觉token(如10×10网格图)替代全图生成,降低推理延迟。 |
| 状态解析 | 用分割模型(SAM 2)替代规则式IoU,支持开放世界视觉环境。 |
| 任务拓展 | 从网格导航→真实机器人视觉导航(如无人机、自动驾驶),验证物理一致性。 |
| 混合推理 | 探索**“视觉+文本”交错推理**(如人类草稿+语言解释),构建更人性化的AI系统。 |
| 理论基础 | 研究视觉推理的涌现机制:如**视觉链式思维(Visual-CoT)**是否可解释、可泛化。 |
总结一句话
这篇论文首次证明“图像可以像语言一样用于多步推理”,用纯视觉强化学习打破文本垄断,为机器人、导航、物理交互等领域开辟了无需文本的新范式。

视觉规划:让我们只用图像思考
Yi Xu 2∗^{2*}2∗ Chengzu Li 1∗^{1*}1∗ Han Zhou 1∗^{1*}1∗ Xingchen Wan 3^{3}3 Caiqi Zhang 1^{1}1
Anna Korhonen1 Ivan Vulić1
语言技术实验室,剑桥大学
2伦敦大学学院 3谷歌
y.xu.23@ucl.ac.uk, xingchenw@google.com
{cl917,hz416,cz391,alk23,iv250}@cam.ac.uk
Abstract
近年来,大型语言模型(LLMs)及其多模态扩展(MLLMs)在多种任务中的机器推理能力得到了显著提升。然而,这些模型在表达和结构化推理时主要依赖纯文本作为媒介,即使存在视觉信息也是如此。在这项工作中,我们主张语言可能并非在涉及空间和几何信息的任务中始终是最自然或最有效的模态。为此,我们提出了一种新的范式——视觉规划(Visual Planning),该范式通过纯粹的视觉表示进行规划,独立于文本。在这种范式中,规划通过一系列图像执行,这些图像编码了视觉域中的逐步推理,类似于人类绘制或可视化未来行动的方式。我们引入了一个新的强化学习框架——基于强化学习的视觉规划(Visual Planning via Reinforcement Learning,VPRL),该框架利用GRPO对大型视觉模型进行后训练,在一系列代表性视觉导航任务(FROZENLAKE、MAZE和MINIBEHAVIOR)中显著提升了规划能力。我们的视觉规划范式在仅进行纯文本推理的所有规划变体中表现最佳。我们的结果表明,视觉规划是一种可行且具有前景的语言推理替代方案,为受益于直观、基于图像的推理的任务开辟了新的途径。代码可在以下链接获取:
https://github.com/yix8/VisualPlanning。
1简介
大型语言模型 (LLMs) [6, 38, 2] 在语言理解和生成方面表现出强大的能力,并且凭借其思维链推理能力 [50] 在复杂推理方面的能力也在不断增强。基于这些进展,最近的研究将LLMs扩展到支持多种模态,产生了所谓的多模态大型语言模型 (MLLMs)[42, 22]:它们在输入中结合视觉嵌入信息,以处理更广泛的任务,例如视觉空间推理 [33, 30] 和导航 [15, 29]。然而,尽管这些方法具有多模态输入,但在推理过程中它们仍然以纯文本格式进行推理,从描述视觉内容 [19] 到生成语言推理依据 [59]。
基于这一观察,我们认为仅在文本路径上执行多模态推理可能并不总是最直观或最有效的策略,特别是对于那些高度依赖视觉信息并且/或者在设计上是“视觉优先”的任务。事实上,多模态基准测试[43, 30, 7, 8]的最新结果表明,纯语言推理在某些领域存在不足,特别是那些涉及空间、几何或物理动态[56]的领域。这种在推理前将视觉信息转化为文本的依赖引入了一个模态差距,阻碍了模型捕捉视觉特征和状态转换的能力。这突显了当前MLLMs的一个潜在缺陷:虽然它们处理图像输入,但它们并不自然地在图像中“思考”。例如,诸如在迷宫中规划路线、设计房间布局或预测机械系统下一个状态等任务,通常更适合使用视觉表示,因为口头描述可能难以准确捕捉复杂的空间推理关系。这些例子提出了一个更广泛的问题,我们旨在这项工作中解决:模型能否在非语言模态(如图像)中规划,而不受文本中介?
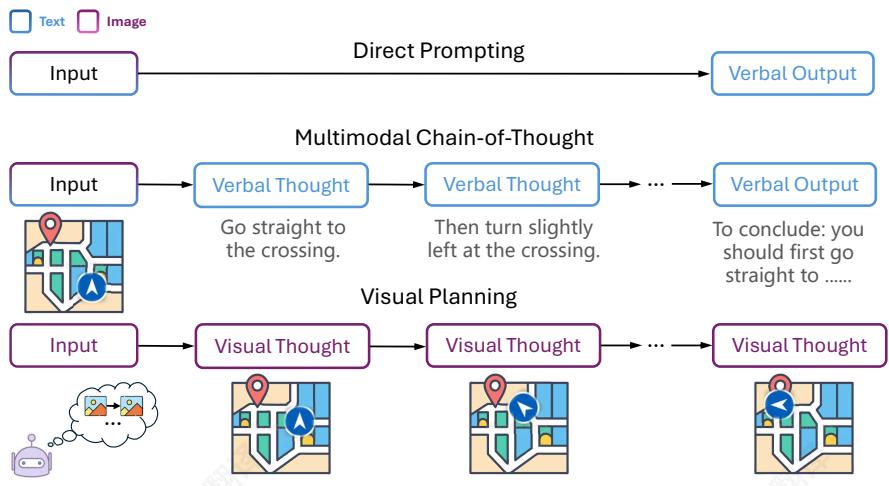
Figure 1: Comparison of reasoning paradigms. The traditional approaches (top and middle rows) generate verbose and inaccurate textual plan, while the Visual Planning paradigm (bottom row) predicts the next visual state directly, forming a pure image trajectory without language mediation.
图1:推理范式对比。传统方法(上、中两行)生成冗长且不准确的文本计划,而视觉规划范式(下一行)则直接预测下一视觉状态,形成纯粹的图像轨迹,无需语言中介。
认知科学也为这个问题提供了有力的动机 [36]。双重编码理论 [39] 提出,人类认知通过语言和非语言渠道运作,每个渠道都能独立进行表征和推理过程。最近关于MLLMs的工作将文本和图像作为推理步骤交织在一起[21, 31]。然而,它们仍然基本上是语言驱动的,并依赖基于工具的视觉化作为推理轨迹的辅助信息,推理仍然主要嵌入在语言轨迹中。例如,Visual Sketchpad [21] 使用外部工具生成草图作为视觉辅助工具,而MVoT [31]从基于语言的行动中生成每步的视觉化,但在决策时仍然使用文本进行推理。因此,一种真正避免任何基于文本的推理代理的纯视觉推理范式仍然有待探索。
在这项工作中,我们提出了一种新的范式,视觉规划,其中推理被结构化为一系列图像,但无需语言的中介。据我们所知,这是首次尝试研究模型是否能够纯粹通过视觉表示来实现规划。与生成文本推理和答案不同,我们的方法生成逐步的视觉化内容,将规划或推理步骤直接编码在图像中。作为一种开创性的探索,它绕过了当视觉问题被迫以口头形式解释时出现的模态不匹配问题,强化了状态转换,并为导航[30],和视觉问题解决[19]等任务提供了一种新的可跟踪界面。
具体来说,我们使用仅在图像和视频帧上训练且没有文本数据的超大视觉模型(LVM)[4]来探索这种范式。这种设计选择消除了由基于语言的监督引入的潜在混杂因素,并能够对模型是否能够纯粹在视觉模态内进行推理进行干净的调查。受强化学习在语言模态[16]内获取推理能力[16]的成功及其强大的泛化性能[11],的启发,我们提出了通过强化学习的视觉规划(VPRL),这是一个由GRPO[44]赋能的新型两阶段强化学习框架,用于视觉规划。它涉及一个独特的初始化阶段,用于鼓励策略模型在给定环境中进行探索,然后接着是带有进度奖励函数的强化学习。
我们在基于网格的导航上验证了我们的范式作为空间规划任务的代表,包括MAZE[23],FROZENLAKE[53],和MINIBEHAVIOR[25],,其中要求一个智能体在不违反环境约束的情况下成功导航到目标位置。
我们的实验表明,视觉规划范式通过监督微调(SFT)显著优于传统的文本推理方法,实现了超过 40%40\%40% 的平均精确匹配率。除了更好的性能外,我们提出的新方法VPRL在视觉规划范式(VPFT)中比SFT方法表现出更强的泛化能力到分布外场景。据我们所知,我们是第一个将RL应用于规划背景下的图像生成的团队;主要贡献包括以下内容:
- 我们提出了一种新的推理范式,视觉规划,并验证了无需使用任何文本和语言进行推理的视觉推理的可行性。
- 我们介绍了VPRL,一个新颖的两阶段训练框架,该框架应用RL通过序列图像生成实现视觉规划。
- 我们通过实证证明,VPRL在视觉空间规划设置中显著优于传统的文本推理范式和监督基线,在任务性能方面实现了显著提升,并表现出改进的泛化能力。
2 视觉规划通过强化学习
2.1 视觉规划范式
先前大多数视觉推理基准 [14, 1, 55] 可以被并且通常通过将视觉信息 grounding 在文本域中 [18, 40, 57], 然后进行几步文本推理来处理。然而, 一旦视觉内容被映射到文本 (例如,对象名称、属性或关系), 问题就简化为一个语言推理任务, 其中推理由语言模型执行,即使在推理过程中没有反映任何来自视觉模态的信息。
我们的视觉规划范式从根本上不同。它在纯视觉模态内执行规划。我们将视觉规划正式定义为生成一系列中间图像 T=(v^1,…,v^n)\mathcal{T} = (\hat{v}_1,\dots ,\hat{v}_n)T=(v^1,…,v^n) 的过程,其中每个 v^i\hat{v}_iv^i 表示一个视觉状态,这些状态共同构成一个视觉规划轨迹,给定输入图像 v0v_{0}v0 。具体来说,令 πθ\pi_{\theta}πθ 表示由 θ\thetaθ 参数化的生成式视觉模型。视觉规划轨迹 T\mathcal{T}T 是自回归生成的,其中每个中间视觉状态 v^i\hat{v}_iv^i 是在初始状态和先前生成状态的条件下调用的:
v^i∼πθ(vi∣v0,v^1,…,v^i−1)(1)\hat {v} _ {i} \sim \pi_ {\theta} \left(v _ {i} \mid v _ {0}, \hat {v} _ {1}, \dots , \hat {v} _ {i - 1}\right) \tag {1} v^i∼πθ(vi∣v0,v^1,…,v^i−1)(1)
2.2大型视觉模型强化学习
强化学习(RL)在通过优化使用序列级奖励(而非标记级监督信号[11])来提升自回归模型的泛化能力方面表现出显著优势。在自回归图像生成中,图像被表示为一个视觉标记序列。受RL在语言推理[16],方面成功的启发,我们引入了一种基于RL的训练框架,用于支持视觉规划的Group Relative Policy Optimization (GRPO) [44]。该框架利用视觉状态之间的转换来计算奖励信号,同时验证环境的约束。为了在RL过程中强制执行生成有效动作并具有多样化探索能力的策略模型,我们提出了一种用于视觉规划的新型两阶段强化学习框架。在第一阶段,我们首先通过在环境中通过随机游走获得的随机轨迹来训练模型[11]以初始化策略模型。然后,通过第二阶段的RL训练来优化模型的视觉规划。
第一阶段:策略初始化。在此阶段,我们通过在环境中通过随机游走获得的随机轨迹来训练模型 πθ\pi_{\theta}πθ 以初始化模型。此处的目标是为生成有效的视觉状态序列并在“模拟”环境中保留探索能力。对于训练,每个轨迹都由一系列视觉状态 (v0,…,vn)(v_{0},\ldots ,v_{n})(v0,…,vn) 组成。从每个轨迹中,我们提取 n−1n - 1n−1 图像对的形式 (v≤i,vi+1)(v_{\leq i},v_{i + 1})(v≤i,vi+1) ,其中 v≤iv_{\leq i}v≤i 表示前缀序列 (v0,…,vi)(v_0,\dots ,v_i)(v0,…,vi) 。随后,给定一个输入前缀,模型会接触到一组合理的下一个状态 {vi+1(j)}j=1K\{v^{(j)}_{i + 1}\}_{j = 1}^{K}{vi+1(j)}j=1K ,这些状态是从与相同前缀共享的有效轨迹中收集的。为了防止过度拟合特定的转换并鼓励随机性,我们在每个训练步骤中从该集合中随机采样一个候选 vi+1(ℓ)v^{(\ell)}_{i + 1}vi+1(ℓ) 作为监督目标,通过最小化以下视觉规划损失函数
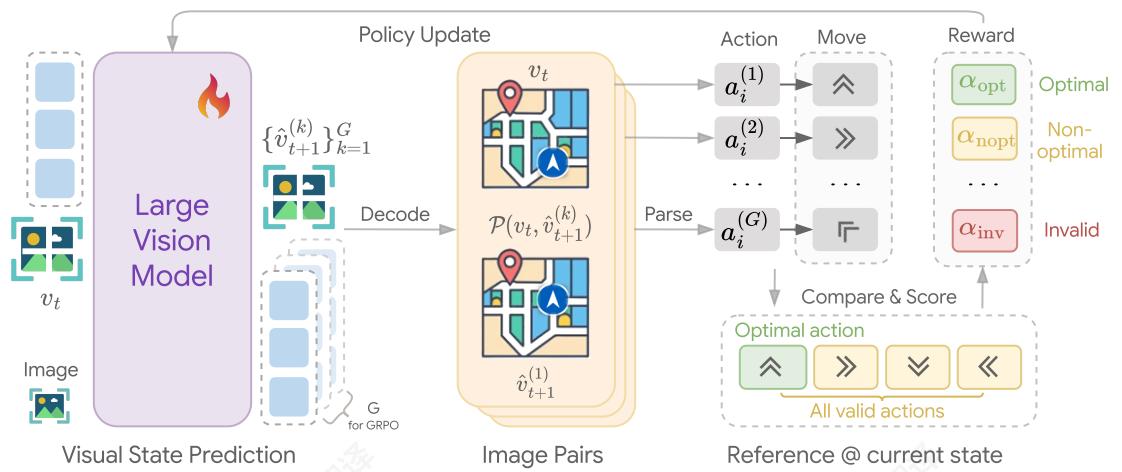
图2:所提出的VPRL框架概述,使用自回归大型视觉模型在视觉导航任务的背景下进行图像生成。我们使用GRPO训练视觉策略模型,使用进度奖励来鼓励进步动作并惩罚无效动作,从而产生与目标一致的视觉规划。
通过微调(VPFT):
LVPFT(θ)=−E(v≤i,vi+1(ℓ))[logπθ(vi+1(ℓ)∣v≤i)].(2)\mathcal {L} _ {\mathrm {V P F T}} (\theta) = - \mathbb {E} _ {(v _ {\leq i}, v _ {i + 1} ^ {(\ell)})} \left[ \log \pi_ {\theta} \left(v _ {i + 1} ^ {(\ell)} \mid v _ {\leq i}\right) \right]. \tag {2} LVPFT(θ)=−E(v≤i,vi+1(ℓ))[logπθ(vi+1(ℓ)∣v≤i)].(2)
总体而言,第一阶段作为后续优化的热身,专注于生成视觉上连贯的输出并提高生成质量。
阶段2:用于视觉规划的强化学习。在第一阶段,模型使用随机轨迹初始化,它获得了有效的探索能力。这种特性对于RL至关重要,因为它确保了对所有可能转换的覆盖,并防止崩溃到次优行为。阶段2然后利用这种能力通过生成下一个视觉状态来模拟潜在动作的结果,并指导模型有效地进行规划。在此阶段,RL算法根据模拟动作的正确性提供反馈和奖励,逐渐使模型能够学习有效的视觉规划。具体来说,给定输入前缀 v≤iv_{\leq i}v≤i ,行为模型 πθold\pi_{\theta_{\mathrm{old}}}πθold 对一组 GGG 候选响应 {v^i+1(1),…,v^i+1(G)}\{\hat{v}^{(1)}_{i+1}, \dots, \hat{v}^{(G)}_{i+1}\}{v^i+1(1),…,v^i+1(G)} 进行采样。每个响应代表一个与计划动作 ai(k)a^{(k)}_iai(k) 在时间步 iii 对应的假设视觉状态。为了解释这些转换,我们采用基于规则的解析函数,将视觉状态对 (viv^i+1(k))(v_i \hat{v}^{(k)}_{i+1})(viv^i+1(k)) 映射到离散动作。候选响应然后使用复合奖励函数 r(vi,v^i+1(k))r(v_i, \hat{v}^{(k)}_{i+1})r(vi,v^i+1(k)) 进行评分,该函数量化生成的视觉状态是否代表向目标状态的意义进展。奖励设计在下一节中详细描述。
与其依赖学习到的评价者来估计可能引入额外不确定性和复杂性的价值函数,GRPO 通过组内比较来计算相对优势,从而提供更高效计算和可解释的训练信号。在这种情况下,每个候选的相对优势是 A(k)=r(k)−r(k−1)r(1),r(2),…,r(G)A^{(k)} = \frac{r^{(k)} - r^{(k-1)}}{r^{(1)}, r^{(2)}, \ldots, r^{(G)}}A(k)=r(1),r(2),…,r(G)r(k)−r(k−1) 。
为了引导模型生成具有更高优势的响应,我们通过最大化以下目标来更新策略 πθ\pi_{\theta}πθ :
JVPRL(θ)=Ev≤i∼D,{vi+1(k)}k=1G∼πθold(⋅∣v≤i)[1G∑i=1Gmin(ρ(k)A(k),clip(ρ(k),1−ϵ,1+ϵ)A(k))−βDKL(πθ∣∣πr e f)],(3)\begin{array}{l} \mathcal {J} _ {\mathrm {V P R L}} (\theta) = \mathbb {E} _ {v _ {\leq i} \sim \mathcal {D}, \{v _ {i + 1} ^ {(k)} \} _ {k = 1} ^ {G} \sim \pi_ {\theta_ {\mathrm {o l d}}} (\cdot | v _ {\leq i})} \\ \left[ \frac {1}{G} \sum_ {i = 1} ^ {G} \min \left(\rho^ {(k)} A ^ {(k)}, \operatorname {c l i p} \left(\rho^ {(k)}, 1 - \epsilon , 1 + \epsilon\right) A ^ {(k)}\right) - \beta D _ {\mathrm {K L}} \left(\pi_ {\theta} \mid \mid \pi_ {\text {r e f}}\right) \right], \tag {3} \\ \end{array} JVPRL(θ)=Ev≤i∼D,{vi+1(k)}k=1G∼πθold(⋅∣v≤i)[G1∑i=1Gmin(ρ(k)A(k),clip(ρ(k),1−ϵ,1+ϵ)A(k))−βDKL(πθ∣∣πr e f)],(3)
其中 D\mathcal{D}D 是前缀分布, ρ(k)=πθ(v^i+1(k)∣v≤i)πθold(v^i+1(k)∣v≤i)\rho^{(k)} = \pi_{\theta}(\hat{v}^{(k)}_{i+1}|v_{\leq i})\pi_{\theta_{\mathrm{old}}}(\hat{v}^{(k)}_{i+1}|v_{\leq i})ρ(k)=πθ(v^i+1(k)∣v≤i)πθold(v^i+1(k)∣v≤i) 是重要性采样比率。
奖励设计。与离散动作或文本标记不同,视觉输出是稀疏的、高维的,并且不容易分解为可解释的单元。在我们的视觉规划框架中,挑战更加具体:生成的视觉状态是否能够正确反映预期的规划动作。因此,奖励设计专注于向目标进展的同时,通过约束来验证动作。为了解释连接当前状态 viv_{i}vi 到生成的候选状态 v^i+t(k)\hat{v}_{i + t}^{(k)}v^i+t(k) 的预期动作,我们定义了一个状态-动作解析函数 P:V×V→A∪E\mathcal{P}: \mathcal{V} \times \mathcal{V} \to \mathcal{A} \cup \mathcal{E}P:V×V→A∪E ,其中 A\mathcal{A}A 表示有效动作的集合,而 E\mathcal{E}E 是无效转换的集合,例如违反环境的物理约束。形式上,
P(vi,v^i+1(k))={ai(k),i fai(k)∈A,ei(k),i fei(k)∈E.(4)\mathcal {P} \left(v _ {i}, \hat {v} _ {i + 1} ^ {(k)}\right) = \left\{ \begin{array}{l l} a _ {i} ^ {(k)}, & \text {i f} a _ {i} ^ {(k)} \in \mathcal {A}, \\ e _ {i} ^ {(k)}, & \text {i f} e _ {i} ^ {(k)} \in \mathcal {E}. \end{array} \right. \tag {4} P(vi,v^i+1(k))={ai(k),ei(k),i fai(k)∈A,i fei(k)∈E.(4)
它有助于通过独立的分割组件 [41] 或基于规则的脚本,从像素数据解释到预期动作。一旦获得预期动作,为了系统地评估动作有效性,我们引入了进度图 D(v)∈ND(v) \in \mathbb{N}D(v)∈N ,该图估计从每个视觉状态到达目标所需的剩余步骤或努力。通过比较代理的当前状态和结果状态与进度图,我们将 A∪E\mathcal{A} \cup \mathcal{E}A∪E 分为三个不相交的子集:
Aopt={a∈A:D(v^i+1(k))<D(vi)},Anopt={a∈A:D(v^i+1(k))≥D(vi)},Einv=E.\mathcal {A} _ {\mathrm {o p t}} = \left\{a \in \mathcal {A}: D (\hat {v} _ {i + 1} ^ {(k)}) < D (v _ {i}) \right\}, \quad \mathcal {A} _ {\mathrm {n o p t}} = \left\{a \in \mathcal {A}: D (\hat {v} _ {i + 1} ^ {(k)}) \geq D (v _ {i}) \right\}, \quad \mathcal {E} _ {\mathrm {i n v}} = \mathcal {E}. Aopt={a∈A:D(v^i+1(k))<D(vi)},Anopt={a∈A:D(v^i+1(k))≥D(vi)},Einv=E.
然后,我们提出进度奖励函数 r(vi,v^i+1(k))r(v_{i},\hat{v}^{(k)}_{i + 1})r(vi,v^i+1(k)) 作为:
αopt⋅I[P(vi,v^i+1(k))∈Aopt]⏟o p t i m a l+αnopt⋅I[P(vi,v^i+1(k))∈Anopt]⏟n o n - o p t i m a l+αinv⋅I[P(vi,v^i+1(k))∈Einv]⏟i n v a l i d,(5)\underbrace {\alpha_ {\mathrm {o p t}} \cdot \mathbb {I} \left[ \mathcal {P} \left(v _ {i} , \hat {v} _ {i + 1} ^ {(k)}\right) \in \mathcal {A} _ {\mathrm {o p t}} \right]} _ {\text {o p t i m a l}} + \underbrace {\alpha_ {\mathrm {n o p t}} \cdot \mathbb {I} \left[ \mathcal {P} \left(v _ {i} , \hat {v} _ {i + 1} ^ {(k)}\right) \in \mathcal {A} _ {\mathrm {n o p t}} \right]} _ {\text {n o n - o p t i m a l}} + \underbrace {\alpha_ {\mathrm {i n v}} \cdot \mathbb {I} \left[ \mathcal {P} \left(v _ {i} , \hat {v} _ {i + 1} ^ {(k)}\right) \in \mathcal {E} _ {\mathrm {i n v}} \right]} _ {\text {i n v a l i d}}, \tag {5} o p t i m a lαopt⋅I[P(vi,v^i+1(k))∈Aopt]+n o n - o p t i m a lαnopt⋅I[P(vi,v^i+1(k))∈Anopt]+i n v a l i dαinv⋅I[P(vi,v^i+1(k))∈Einv],(5)
其中 αopt,αnopt,αinv\alpha_{\mathrm{opt}}, \alpha_{\mathrm{nopt}}, \alpha_{\mathrm{inv}}αopt,αnopt,αinv 是奖励系数。在我们的实验中,我们设置 αopt=1,αnopt=0\alpha_{\mathrm{opt}} = 1, \alpha_{\mathrm{nopt}} = 0αopt=1,αnopt=0 和 αinv=−5\alpha_{\mathrm{inv}} = -5αinv=−5 ,从而奖励进步动作,将零分配给非进步动作,并严厉惩罚无效转换。
2.3系统变体
除了VPRL,我们还包含几个作为基线的训练系统变体,它们在监督模态(语言与图像)和优化方法(SFT与RL)上有所不同,使我们能够比较基于语言和基于视觉的规划,同时评估强化学习的作用。
通过微调的视觉规划(VPFT)。我们提出通过微调的视觉规划(VPFT)作为我们框架的简化变体,它与2.2节第1阶段的相同训练架构共享,但用最优规划轨迹替换了随机轨迹。对于每个环境,我们采样一个不同的轨迹 (vopt0,v1opt,…,vnopt)(v^{\mathrm{opt}}0, v_1^{\mathrm{opt}}, \ldots, v_n^{\mathrm{opt}})(vopt0,v1opt,…,vnopt) 代表从初始状态 voptv^{\mathrm{opt}}vopt 0=v00 = v_{0}0=v0 到目标的最小步路径。在每一步,模型被训练以根据前缀 v≤ioptv_{\leq i}^{\mathrm{opt}}v≤iopt 预测下一个状态 vi+1optv_{i+1}^{\mathrm{opt}}vi+1opt 目标是与方程2相同,并从最优轨迹获得监督。
文本中的监督微调 (SFT)。在这个基线中,规划是在语言模态下进行的。不是生成动作的中期视觉结果,模型产生预期动作序列的文本描述。形式上,给定一个视觉输入状态 vvv 和一个文本提示 ppp ,它表示任务描述,模型被训练生成一个口述动作序列 t=(t1,…,tL)t = (t_1, \dots, t_L)t=(t1,…,tL) ,其中每个标记 ti∈Vtextt_i \in \mathcal{V}_{\mathrm{text}}ti∈Vtext 表示一个动作。模型的输入是提示标记和视觉标记的连接,目标是相应的动作序列。遵循先前在自回归模型中对监督微调 (SFT) [49] 的工作,我们最小化动作预测的交叉熵损失:
LSFT(θ)=−E(v,t)[∑i=1Llogπθ(ti∣t<i,v,p)].(6)\mathcal {L} _ {\mathrm {S F T}} (\theta) = - \mathbb {E} _ {(v, t)} \left[ \sum_ {i = 1} ^ {L} \log \pi_ {\theta} \left(t _ {i} \mid t _ {< i}, v, p\right) \right]. \tag {6} LSFT(θ)=−E(v,t)[i=1∑Llogπθ(ti∣t<i,v,p)].(6)
3 实验和结果
任务为了评估我们提出的视觉规划范例,我们选择了代表性任务,在这些任务中,规划可以完全在视觉模态中表达和执行。我们专注于那些状态转换是视觉上可观察的,这与以语言为中心的任务(如代码生成[27]或传统的视觉问答)相区别。这种设计使我们能够在不依赖文本推理或符号输出的情况下分析规划行为。
Table 1: Performance of the closed- and open-source models on FROZENLAKE, MAZE, and MINIBEHAVIOR. VPRL performs consistently the best (bold) across all tasks. †\dagger† denotes the post-trained model. A represents texts and Q\boxed{\mathbb{Q}}Q represents images. The last column AVG. reports the average performance across three tasks.
| 模型 | 输入 | 输出 | FROZENLAKE | MAZE | MINIBEHAVIOR | AVG. | ||||
| EM (%) | PR (%) | EM (%) | PR (%) | EM (%) | PR (%) | EM (%) | PR (%) | |||
| 闭源模型 | ||||||||||
| Gemini 2.0 Flash | ||||||||||
| -直接 | A+ | A | 21.2 | 47.6 | 8.3 | 31.4 | 0.7 | 29.8 | 10.1 | 36.3 |
| -CoT | A+ | A | 27.6 | 52.5 | 6.9 | 29.8 | 4.0 | 31.2 | 12.8 | 37.8 |
| Gemini 2.5 Pro (think) | A+ | A | 72.0 | 85.0 | 21.5 | 35.5 | 37.6 | 59.9 | 43.7 | 60.1 |
| 开源模型 | ||||||||||
| Qwen 2.5-VL-Instruct-3B | ||||||||||
| -直接 | A+ | A | 0.9 | 14.4 | 0.5 | 13.6 | 0.0 | 10.0 | 0.5 | 12.7 |
| -CoT | A+ | A | 1.3 | 13.4 | 0.8 | 8.2 | 1.2 | 12.5 | 1.1 | 11.4 |
| -SFT† | A+ | A | 59.0 | 76.3 | 33.3 | 52.7 | 10.6 | 31.0 | 34.3 | 53.3 |
| LVM-3B | ||||||||||
| -VPFT†(ours) | 75.4 | 79.5 | 59.0 | 64.0 | 33.8 | 52.2 | 56.1 | 65.2 | ||
| -VPRL†(ours) | 91.6 | 93.2 | 74.5 | 77.6 | 75.8 | 83.8 | 80.6 | 84.9 | ||
为了比较视觉规划与基于语言的推理,我们实验了3个视觉导航环境:FROZENLAKE[53], MAZE [23], 和 MINIBEHAVIOR [25]。它们都可以在两种模态下解决,这使得视觉规划与语言推理策略之间可以进行直接比较。
- FROZENLAKE:它最初由 Wu 等人 [53] 提出,并使用 Gym [5] 实现。它模拟了一个基于网格的冰冻湖,其中智能体应从指定位置出发,安全地找到通往目的地的路径,而不会掉入 ‘坑’ 中。
- MAZE:给定一个描述迷宫布局的初始图像,模型应从起点(绿色点)通过迷宫到达终点(红色旗帜)。
- MINIBEHAVIOR: 智能体首先需要从起点到达打印机并将其拾取。之后,智能体应该去桌子那里并将打印机放下。这项任务包括 2 个附加动作,包括 ‘拾取’ 和 ‘放下’。
我们为具有不同复杂程度的模式和环境的任务构建了合成数据集。数据收集和实现的详细信息在附录B.1中提供。
模型 为了探索不受任何语言影响的视觉规划,并实现干净的调查,我们选择了仅使用视觉数据训练且在预训练期间未接触任何文本数据的模型。对于我们的方法(VPFT和VPRL),我们使用大型视觉模型(LVM-3B)[4]作为骨干,它仅基于图像序列和视频进行训练。对于RL训练,我们设计和提供了基于规则的状态-动作解析函数 P\mathcal{P}P 和进度图 D(v)D(v)D(v) 的详细实现,在附录B.3中。
我们还包括用于并行比较的文本规划基线,其中规划通过语言制定,通常是动作的文本序列。具体来说,我们评估了与LVM-3B大小匹配的Qwen2.5-VL-Instruct[3],在仅推理( Direct2\mathrm{Direct}^2Direct2 和CoT)和后训练设置(SFT)下作为基线。我们进一步评估了闭源模型,包括Gemini2.0Flash26和高级思考模型Gemini2.5Pro13作为最先进多模态推理的参考。所有模型的全训练详细信息和超参数在附录B.4中提供。
评估指标 我们为选定的任务采用了两种互补的评估指标:
- 精确匹配 (EM) 定义为 EMi=∏j=1nI(v^j=vj)\mathrm{EM}_i = \prod_{j=1}^n \mathbb{I}(\hat{v}_j = v_j)EMi=∏j=1nI(v^j=vj) 。该指标衡量模型是否成功生成完整且正确的规划轨迹,该轨迹与最短最优有效路径一致。偏离最优解一步即视为错误。
- 进度率 (PR) 定义为 PRi=∑n=11∑j=1n\mathrm{PR}_i = \sum_{n=1}^{1} \sum_{j=1}^{n}PRi=∑n=11∑j=1n [∏k=1jI(v^k=vk)]\left[\prod_{k=1}^{j} \mathbb{I}(\hat{v}_k = v_k)\right][∏k=1jI(v^k=vk)] .PR衡量从起点到最优路径步数中连续正确步骤(有效前进移动)的数量比例。这比精确匹配提供了更柔和的信号,捕捉模型向完整解决方案做出有意义进展的能力。
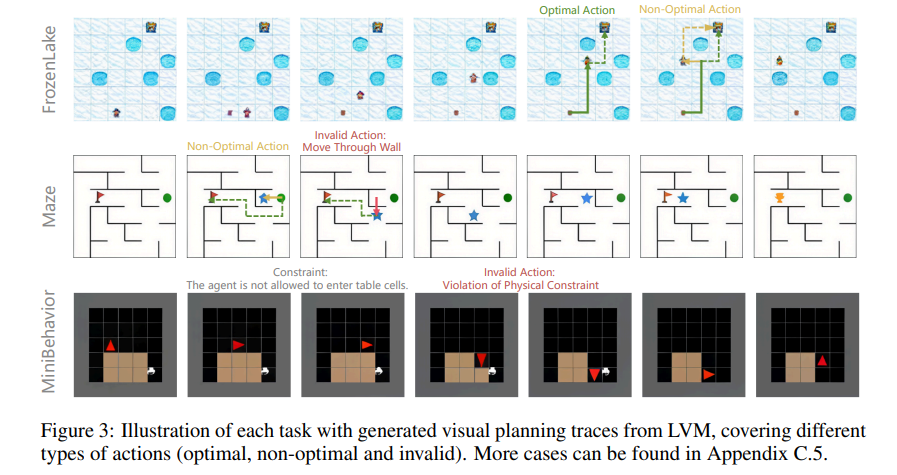
图3:展示每个任务生成的视觉规划轨迹,覆盖不同类型的动作(最优、非最优和无效)。更多案例可在附录C.5中找到。
视觉规划优于文本规划。表1显示,视觉规划器(VPFT和VPRL)在所有任务上均获得最高分数,优于所有语言推理基线。通过微调实现相同的监督训练方法,VPFT在精确匹配(EM)中平均超过基于语言的SFT超过 22%22\%22% ,VPRL进一步扩大了差距。在进度率(PR)方面也观察到类似的趋势。这突出了视觉规划范式在以视觉为中心的任务中的优势,其中语言驱动的方法可能与任务结构不太一致。仅推理模型,无论是大型封闭源系统还是较小的开源MLLM,如果没有特定任务的微调,这些规划任务就会遇到困难。即使是先进的思考模型Gemini2.5Pro在更复杂的MAZE和MINIBEHAVIOR任务上,EM和PR也几乎低于 50%50\%50% ,这突出了尽管这些任务对人类来说很直观,但当前模型面临的挑战。
强化学习的收益。两阶段强化学习方法(VPRL)获得最高的整体性能,超过所有系统变体。在第二阶段后,模型在较简单的FROZENLAKE任务上实现了近乎完美的规划( 91.6%91.6\%91.6% EM, 93.2%93.2\%93.2% PR),并在MAZE和MINIBEHAVIOR任务上保持强劲性能。这标志着在所有任务上比监督基线VPFT提高了 20%20\%20% 以上的显著改进。正如预期的那样,我们RL训练的第一阶段,它强制输出格式而不教授规划行为,产生了近乎随机的性能(例如,在FROZENLAKE上 11%11\%11% EM,见附录C.5中的表8)。在带有我们奖励方案的完整第二阶段优化后,规划器达到了最佳性能。这种收益突出了RL相对于SFT的一个关键优势。VPRL允许模型自由探索各种动作并从其结果中学习,而VPFT依赖于模仿并倾向于拟合训练分布。通过通过奖励驱动更新鼓励利用,VPRL学习捕获潜在的规则和模式,从而带来更强的规划性能。
通过缩放复杂度实现鲁棒性。当我们在任务难度方面研究不同方法的性能时,RL的优势也同样存在,其中更大的网格通常与更高的难度相关。在图5中,随着网格大小从 3×33 \times 33×3 增加到 6×66 \times 66×6 在FROZENLAKE环境中,Gemini2.5Pro的EM分数从 98.0%98.0\%98.0% 骤降至 38.8%38.8\%38.8% 。相比之下,我们的视觉规划器不仅在所有网格尺寸上保持更高的精度,而且表现出非常平缓的性能曲线。类似地,VPRL表现出比VPFT更高的稳定性,EM在 3×33\times 33×3 网格上保持在 97.6%97.6\%97.6% ,在 6×66\times 66×6 上仍然达到 82.4%82.4\%82.4% ,表明具有很强的鲁棒性。我们在其他任务中也观察到类似的趋势;参见附录C.2中的其他任务。
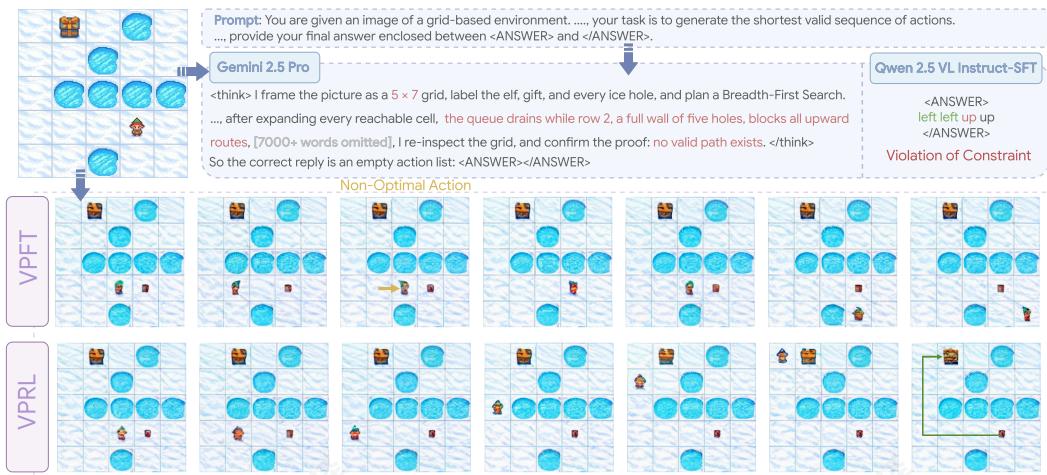
图4:FROZENLAKE中的测试示例的可视化,比较了视觉规划变体(VPFT和VPRL)与基于语言的推理变体。
4 讨论与分析
错误分析与案例研究。图3展示了LVM在不同任务中生成的视觉规划轨迹。如第2.2节所述,模型偶尔会采取非最优行动,偏离最短路径,如FROZENLAKE示例所示。无效行动包括违反物理约束(例如,在MAZE中穿墙或在MINIBEHAVIOR中进入桌子),或在单步执行多个行动(参见附录C.5中的示例)。
图4比较了视觉规划与基于语言的推理系统。在FROZENLAKE中,Gemini2.5Pro在第一步错误地理解了环境大小,导致级联错误,最终得出了错误的答案。类似地,基于语言的SFT基线在第三步执行了无效动作,反映了在推理过程中跟踪状态时的困难。相比之下,视觉规划通过直接在视觉模态中进行推理,并在每个动作中反映视觉状态来避免此类失败。VPRL展示了绕过障碍物并仍然向目标前进的能力,而VPFT缺乏这种灵活性,会卡住并无法到达目的地。更多示例在附录C.5中提供。
随机策略初始化实现探索。一个自然的后续问题是:我们能否直接使用VPFT作为GRPO训练的策略模型,而不是有意用随机轨迹初始化模型?我们假设VPFT通过教师强制训练,通过反复生成相似动作来限制探索,导致相同的奖励。在这种情况下,它没有优势,阻止策略更新并阻碍有效学习。我们通过比较VPFT与VPRL阶段1的探索能力来经验性地验证这一假设(图6)。我们观察到VPFT的熵在整个训练过程中迅速下降,最终接近零,表明严重的探索限制。尽管早期的VPFT检查点表现出更高的熵,但它们产生了显著更多的无效动作。相比之下,VPRL阶段1展示了显著更高的熵,接近均匀随机规划器的熵,同时保持远低的无效动作比率。这些结果证明了在我们的强化学习框架中随机初始化的必要性,以确保稳健的探索。
VPRL减少无效动作失败。VPRL的另一个重要优势在于其减少无效动作的有效性。为了量化这一点,我们分析了所有失败的轨迹,并计算了至少包含一个无效动作的轨迹比例,而不是由非最优但有效的计划引起的失败。我们将其称为无效失败率。如表5所示,VPFT在三个任务中表现出从 61%61\%61% 到 78%78\%78% 的高比率,而VPRL在所有情况下都将该比率至少降低了 24%24\%24%案例,证明VPRL不仅提高了成功率,还鼓励模型在规划过程中保持在有效动作空间内。
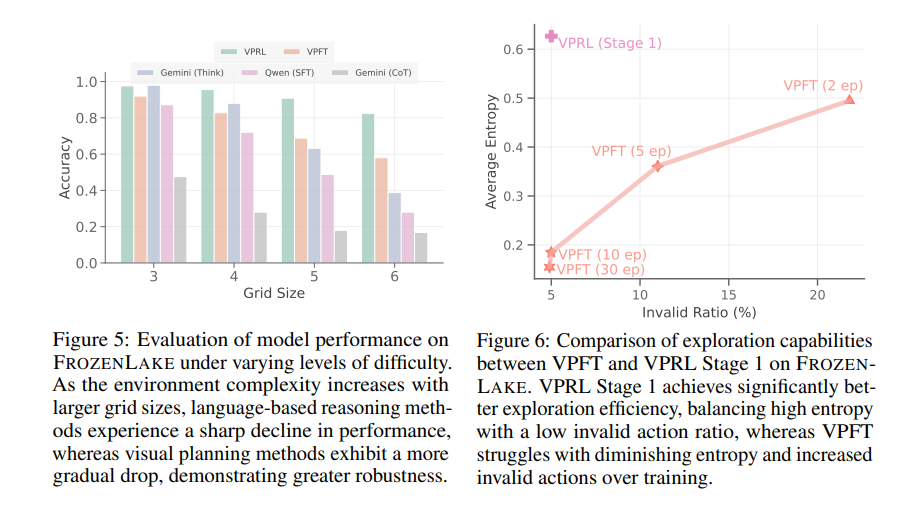
图5:在FROZENLAKE上评估模型性能随难度变化的情况。随着环境复杂度随更大的网格尺寸增加而提高,基于语言的推理方法性能急剧下降,而视觉规划方法表现出更平缓的下降,显示出更强的鲁棒性。
图6:在FROZEN-LAKE上VPFT和VPRL Stage 1探索能力的比较。
5相关工作
MLLM推理 近期工作通过将视觉输入接地为符号表示(如图表或边界框[59,28])等方法,将CoT提示[51]扩展到MLLMs。其他方法在推理过程中集成工具生成可视化 [21,61][21,61][21,61] 。例如,o3模型[37]使用裁剪和缩放等工具整合视觉推理。MVoT[31]本质上也是一种工具使用:它不依赖外部模块,而是调用自身生成文本推理的可视化。这些方法主要在语言中进行推理,视觉组件仅用于说明文本推理,而非作为推理媒介。在本工作中,我们进一步探索多步规划是否可以纯粹在视觉表示中涌现,从而实现无需依赖语言的推理。
视觉推理的强化学习 让我们只用图像思考强化学习已被广泛应用于各种与视觉相关的任务,尤其是在 GRPO(如 DeepSeek-R1 [16])兴起之后。目前,在目标检测中,通过预测框与真实框之间的高交并比(IoU)得分进行奖励,优化视觉感知[54]。对于视觉推理任务(如视觉问答VQA),GRPO已被用于优化模型,以生成更长、更连贯且逻辑上更合理的文本响应推理轨迹[34, 60, 58, 46]。最近,类似的方法也被应用于图像生成任务,其中模型被引导反思生成的图像,并根据与给定文本指令的一致性进行递归优化[17, 48, 24]。这些方法侧重于像素级保真度和与文本的语义对齐,而我们的工作利用强化学习进行目标导向的视觉规划,通过视觉状态转换优化多步决策,而不依赖任何语言。尽管先前的基于强化学习的方法将推理轨迹与文本输出相结合,尽管输入是多模态的,但模态不匹配限制了强化学习在连接感知和行动方面的有效性。对于设计上‘以视觉为先’的任务,我们的视觉规划范式和两阶段训练框架VPRL通过完全在视觉域内运行,实现了更自然和灵活的策略探索,优于所有基于语言的训练变体。
6结论
在这项工作中,我们提出了VisualPlanning作为一种新的视觉导向任务推理范式,挑战了当前主要依赖语言作为结构化推理主要媒介的普遍做法。
通过使模型完全通过视觉状态转换而不依赖文本中介来运行,我们证明了纯粹的视觉表示可以带来更有效和直观的规划,特别是在空间感知和动态任务中。我们提出的两阶段强化学习框架VPRL,在GRPO的赋能下,进一步增强了大型视觉模型的规划能力。它在三个视觉导航任务中取得了显著提升,比基于语言的规划任务性能提高了 40%40\%40% 以上,并在分布外场景中表现出更强的泛化能力。这些发现突出了视觉规划作为基于文本方法的强大替代方案的潜力。我们相信我们的工作为多模态研究开辟了一个丰富的新方向,为构建更直观、灵活和强大的推理系统奠定了基础,这些系统将广泛应用于各个领域。
References
[1] Akula, A., Changpinyo, S., Gong, B., Sharma, P., Zhu, S.-C., and Soricut, R. CrossVQA: Scalably generating benchmarks for systematically testing VQA generalization. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 2148-2166, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.164. URL https://aclanthology.org/2021.emnlp-main.164/.
[2] Anil, R., Dai, A. M., First, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z., et al. Palm 2 技术报告 . arXiv preprint arXiv:2305.10403, 2023. URL https://doi.org/10.48550/arXiv.2305.10403.
[3] Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-v1 技术报告. arXiv preprint arXiv:2502.13923, 2025.
[4] Bai, Y., Geng, X., Mangalam, K., Bar, A., Yuille, A. L., Darrell, T., Malik, J., and Efros, A. A. 序列建模使大型视觉模型的可扩展学习成为可能。在 IEEE/CVF 计算机视觉与模式识别会议,CVPR 2024, 西雅图, WA, USA, 2024 年 6 月 16-22 日, pp. 22861-22872, 2024. doi: 10.1109/CVPR52733.2024.02157. URL https://doi.org/10.1109/CVPR52733.2024.02157.
[5] Brockman, G. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
[6] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. 语言模型是少样本学习者. In 神经信息处理系统进展 33: 2020 年神经信息处理系统大会 NeurIPS 2020,2020 年 12 月 6-12 日,线上,2020. URL https://proceedings.neurips.cc/paper/2020混沌/1457c0d6bfb4967418bf8ac142f64a-Abstract.html.
[7] 陈, Q., 秦, L., 张, J., 陈, Z., 徐, X., 和车威铭 3CoT^{3}\mathrm{CoT}3CoT : 一种新的多领域多步多模态思维链基准。在 Ku, L.-W., Martins, A., 和 Srikumar, V. (eds.), 计算语言学协会第 62 届年会论文集(第一卷:长论文), pp. 8199-8221, 曼谷, 泰国, 2024 年 8 月。计算语言学协会。doi: 10.18653/v1/2024.acl-long.446. URL https://aclanthology.org/2024.acl-long.446/.
[8]程, Z., 陈, Q., 张, J., 费, H., 冯, X., 车威铭, 李, M., 和秦, L. Comt: 一种用于大型视觉语言模型的全新多模态思维链基准。在 AAAI 人工智能会议论文集, 卷 39, pp. 23678-23686, 2025。
[9] Chern, E., Su, J., Ma, Y., and Liu, P. Anole: 一个开放、自回归、原生的大规模多模态模型,用于交错的图像-文本生成。arXivpreprint arXiv:2407.06135, 2024。
[10] Choudhury, R., Zhu, G., Liu, S., Niinuma, K., Kitani, K., and Jeni, L. Don’t look twice: 更快的视频 Transformer 与运行长度标记化。Advances in Neural Information Processing Systems, 37:28127-28149, 2024.
[11] Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Levine, S., 和 Ma, Y. SFT 记忆, RL 泛化: 基础模型后训练的比较研究。在简约与学习第二次会议(近期焦点专题), 2025。URL https://openreview.net/forum?id=d3E3LWmTar。
[12] Esser, P., Rombach, R., 和 Ommer, B. 控制 Transformer 进行高分辨率图像合成。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第 12873-12883 页,2021。
[13] Gemini. Gemini 2.5: 我们最智能的 AI 模型。2025 年 3 月。URL https://blog.google/technology/google-deepmind/ gemini-model-thinking-updates-march-2025/. 访问时间:2025-05-09。
[14] Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., and Parikh, D. 让 VQA 中的 V 发挥作用: 提升图像理解在视觉问答中的作用。在计算机视觉与模式识别会议(CVPR),2017。
[15] Gu, J., Stefani, E., Wu, Q., Thomason, J., and Wang, X. 视觉与语言导航:任务、方法及未来方向综述。收录于Muresan, S., Nakov, P., 和Villav-icencio, A. (eds.), 第60届计算语言学协会年会论文集(第一卷:长文),第7606-7623页,爱尔兰都柏林,2022年5月。计算语言学协会。doi: 10.18653/v1/2022.acl-long.524. URL https://aclanthology.org/2022.acl-long.524/.
[16] Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., 等。Deepseek-r1: 通过强化学习激励大语言模型的推理能力。arXiv 预印本 arXiv:2501.12948, 2025年。
[17] 郭, Z., 张, R., 唐恩, C., 赵智, Z., 高平, P., 李华, 和 恩平 - 阿. 我们能否用 cot 生成图像? 让我们逐步验证和强化图像生成. arXiv preprintarXiv:2501.13926, 2025.
[18] 古拉里, D., 李强, Stangl, A. J., 郭安, 林晨, 格拉曼, K., 罗杰, 和 比汉姆, J. P. Vizwiz 大挑战: 为盲人回答视觉问题. 在 IEEE 计算机视觉与模式识别会议论文集, pp. 3608-3617, 2018.
[19] 郝, Y., 郭建, 王华伟, 李丽, 杨子, 王立, 和程远. Mllms 能否在多模态中推理? emma: 一个增强的多模态推理基准. arXiv preprintarXiv:2501.05444, 2025.
[20] 胡, E. J., 沈, Y., Wallis, P., Allen-Zhu, Z., 李, Y., 王, S., 王, L., 和陈, W. Lora: 大型语言模型的低秩适配. 在第十届国际学习表征会议, ICLR 2022, 线上活动, 2022 年 4 月 25-29 日. OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
[21] {v1} 胡, Y., 石, W., 傅, X., 罗斯, D., Ostendorf, M., Zettlemoyer, L., Smith, N. A., 和 Krishna, R. 视觉草图板: 将绘图作为多模态语言模型的视觉思维链. arXiv 预印本 arXiv:2406.09403, 2024.
[22] Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., 等. Gpt-4o 系统卡. arXiv 预印本 arXiv:2410.21276, 2024.
[23] Ivanitskiy, M. I., Shah, R., Spies, A. F., Räuker, T., Valentine, D., Rager, C., Quirke, L., Mathwin, C., Corlouer, G., Behn, C. D., et al. A configurable library for generating and manipulating maze datasets. arXiv preprint arXiv:2309.10498, 2023.
[24] Jiang, D., Guo, Z., Zhang, R., Zong, Z., Li, H., Zhuo, L., Yan, S., Heng, P.-A., and Li, H. T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot. arXivpreprintarXiv:2505.00703, 2025.
[25] Jin, E., Hu, J., Huang, Z., Zhang, R., Wu, J., Fei-Fei, L., and Martin-Martin, R. Mini-BEHAVIOR: A procedurally generated benchmark for long-horizon decision-making in embodied AI. In NeurIPS 2023 Workshop on Generalization in Planning, 2023. URL https://openreview.net/forum?id=Ghl9pYaVh5.
[26]Kampf, K. 和 Brichtova, N. Experiment with gemini 2.0 flash native image generation, 2025年3月. URL https://developers.googleblog.co m/en/experiment-with-gemini-20-flash-native-image-generation/. 访问时间:2025-04-27.
[27] Lai, Y., Li, C., Wang, Y., Zhang, T., Zhong, R., Zettlemoyer, L., Yih, W.-t., Fried, D., Wang, S., and Yu, T. Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, pp. 18319-18345. PMLR, 2023.
[28] Lei, X., Yang, Z., Chen, X., Li, P., and Liu, Y. Scaffolding coordinates to promote vision-language coordination in large multi-modal models. arXiv preprint arXiv:2402.12058, 2024.
[29] 李, C., 张, C., Teufel, S., Doddipatla, R. S., 和 Stoyanchev, S. 基于语义地图的导航指令生成。收录于 Calzolari, N., Kan, M.-Y., Hoste, V., Lenci, A., Sakti, S., 和 Xue, N. (eds.), 2024 年联合国计算语言学、语言资源与评估会议(LREC-COLING 2024)论文集,第 14628-14640 页,都灵,意大利,2024 年 5 月。ELRA 和 ICCL。URL https://aclanthology.org/2024.lrec-main.1274/。
[30]李, C., 张, C., 周 H., Collier, N., Korhonen, A., 和 Vuli’c, I. TopViewRS: 视觉语言模型作为俯视图空间推理器。收录于 Al-Onaizan, Y., Bansal, M., 和 Chen, Y.-N. (eds.), 2024 年自然语言处理经验方法会议论文集, 第 1786-1807 页, 迈阿密, 佛罗里达, 美国, 2024 年 11 月。计算语言学协会。doi: 10.18653/v1/2024.emnlp-main.106。URL https://aclanthology.org/2024.emnlp-main.106/。
[31] 李, C., 吴, W., 张, H., 夏, Y., 毛 S., 董 L., Vuli’c, I., 和魏 F. 在空间中边推理边想象: 多模态思维可视化。arXiv 预印本 arXiv:2501.07542, 2025。
[32] Linsley*, D., Kim*, J., 阿肖克, A., 和 塞雷, T. 用于轮廓检测的循环神经网络电路。在学习表示国际会议, 2020。URL https://openreview.net/forum?id=H1gB4RVKvB。
[33] 刘, F., 埃默森, G., 和科利尔, N. 视觉空间推理。计算语言学协会汇刊, 11:635-651, 2023。doi: 10.1162/tacl_a_00566. URL https://aclanthology.org/2023.tacl-1.37/。
[34] 刘,Z.,孙,Z.,藏,Y.,董,X.,曹,Y.,段,H.,林,D.,和王,J. Visual-rft: 视觉强化微调。arXivpreprint arXiv:2503.01785, 2025。
[35] 洛什奇洛夫,I.和赫特,F.解耦权重衰减正则化。在第7届国际学习表示会议,ICLR2019,新奥尔良,LA,美国,5月6-9日。OpenReview.net,2019。URLhttps://openreview.net/forum?id=Bkg6RiCqY7。
[36] 穆尔顿, S. T. 和科斯林, S. M. 想象预测: 心理意象作为心理模拟。皇家学会哲学汇刊 B: 生物科学, 364:1273-1280, 2009。
[37] OpenAI. 发布 OpenAI o3 和 o4-mini:我们迄今最智能和最强大的模型。2025年4月。URL https://openai.com/index/introducing-o3-and-o4-mini/. 访问时间:2025-05-16。
[38] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. 使用人类反馈训练语言模型遵循指令。神经信息处理系统进展, 35:27730-27744, 2022。
[39] Paivio, A. 双编码理论:回顾与现状。加拿大心理学杂志/加拿大心理学评论,45(3):255, 1991。
[40] Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Ye, Q., and Wei, F. 将多模态大语言模型与世界相结合。在第十二届学习表示国际会议,2024年。URL https://openreview.net/forum?id=LLmqxkfSIw。
[41] Ravi, N., Gabeur, V., Hu, Y.-T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al. Sam 2: 图像和视频中的一切分割 arXiv preprintarXiv:2408.00714, 2024.
[42] Reid, M., Savinov, N., Teplyashin, D., Lepikhin, D., Lillicrap, T. P., Alayrac, J., Soricut, R., Lazaridou, A., First, O., Schrittwieser, J., Antonoglou, I., Anil, R., Borgeaud, S., Dai, A. M., Millican, K., Dyer, E., Glaese, M., Sottiaux, T., Lee, B., Viola, F., Reynolds, M., Xu, Y., Molloy, J., Chen, J., Isard, M., Barham, P., Hennigan, T., McIlroy, R., Johnson, M., Schalkwyk, J., Collins, E., Rutherford, E., Moreira, E., Ayoub, K., Goel, M., Meyer, C., Thornton, G., Yang, Z., Michalewski, H., Abbas, Z., Schucher, N., Anand, A., Ives, R., Keeling, J., Lenc, K., Haykal, S., Shakeri, S., Shyam, P., Chowdhery, A., Ring, R., Spencer, S., Sezener, E., and et al. Gemini 1.5:跨越数百万上下文令牌的多模态理解 CoRR, abs/2403.05530, 2024. doi: 1 0.48550/ARXIV.2403.05530. URL https://doi.org/10.48550/arXiv.2403.05530.
[43] Roberts, J., Taesiri, M. R., Sharma, A., Gupta, A., Roberts, S., Croitoru, I., Bogolin, S.-V., Tang, J., Langer, F., Raina, V., et al. Zerobench: 一个针对当代大型多模态模型的不可能的视觉基准。arXiv preprint arXiv:2502.09696, 2025。
[44] Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. Deepseekmath: 推动开放语言模型中数学推理的极限。ArXivpreprint, abs/2402.03300, 2024。URL https://arxiv.org/abs/2402.03300。
[45] Shen, H., Liu, P., Li, J., Fang, C., Ma, Y., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., et al. Vlm-r1: 一个稳定且可泛化的 r1 风格大型视觉语言模型。arXiv preprintarXiv:2504.07615, 2025.
[46] 团队,K.,杜,A.,高,B.,行,B.,江,C.,陈,C.,李,C.,肖,C.,杜,C.,廖,C.,等。Kimi k1.5:使用LLM扩展强化学习。arXiv预印本arXiv:2501.12599,2025。
[47] 冯韦拉,L.,贝卡达,Y.,坦斯塔尔,L.,比钦,E.,特鲁斯,T.,兰伯特,N.,黄,S.,拉斯尔,K.,以及加洛德,Q.Trl:Transformer强化学习。https://github.com/huggingface/trl,2020。
[48]王,J.,田,Z.,王,X.,张,X.,黄,W.,吴,Z.,以及江,Y.-G. Simplear:通过预训练、sft和rl将自回归视觉生成的边界推向前进。arXiv预印本arXiv:2504.11455,2025。
[49] 魏, J., Bosma, M., 赵, V., Guu, K., 余, A. W., Lester, B., 杜, N., 戴, A. M., 和 Le, Q. V. 微调语言模型是零样本学习器。在国际学习表示会议, 2022。URL https://openreview.net/forum?id= gEZrGCozdqR.
[50] 魏, J., 王, X., Schuurmans, D., Bosma, M., brian richter, 夏, F., Chi, E. H., Le, Q. V., 和周, D. 思维链提示在大语言模型中激发推理。在 Oh, A. H., Agarwal, A., Belgrave, D., 和 Cho, K. (eds.), 神经信息处理系统进展, 2022。URL https://openreview.net/forum?id=_VjQLMeSB_J.
[51] 魏, J., 王, X., Schuurmans, D., Bosma, M., richter, b., 夏, F., Chi, E., Le, Q. V., 和周, D. 思维链提示在大语言模型中激发推理。在 Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., 和 Oh, A. (eds.), 神经信息处理系统进展, 卷 35, pp. 24824-24837。Curran Associates, Inc., 2022。
[52] 吴,J.,姜,Y., 马,C., 刘,Y., 赵,H., 袁,Z., 白,S., 和白,X. Liquid:语言模型是可扩展的多模态生成器。arXivpreprint arXiv:2412.04332,2024年。
[53] 吴,Q.,赵,H.,萨克斯,M.,裴,T.,王,W.Y.,张,Y.,和长,S.Vsp:评估vlms在空间规划任务中感知和推理的双重挑战,2024年。
[54] 余,E.,林,K.,赵,L.,尹,J.,魏,Y.,彭,Y.,魏,H.,孙,J.,韩,C.,格,Z.,等。感知 -r1:用强化学习开创感知策略。arXiv preprintarXiv:2504.07954,2025年。
[55] Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9556-9567, 2024.
[56] Zhang, H., Li, C., Wu, W., Mao, S., Vulic, I., Zhang, Z., Wang, L., Tan, T., Wei, F., et al. A call for new recipes to enhance spatial reasoning in mllms. arXiv preprint arXiv:2504.15037, 2025.
[57] Zhang, J., Huang, J., Jin, S., and Lu, S. Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
[58] 张, J., 黄, J., 姚 o, H., 刘, S., 张, X., 陆, S., 和 陶, D. R1-vl: 通过逐步分组相对策略优化学习使用多模态大语言模型进行推理. arXiv preprintarXiv:2503.12937, 2025.
[59] 张, Z., 张, A., 李, M., hai zhao, Karypis, G., 和 Smola, A. 语言模型中的多模态思维链推理. Transactions on Machine Learning Research, 2024. ISSN 2835-8856.
[60] 周, H., 李, X., 王, R., 程, M., 周, T., 和谢希, C.-J. R1-zero 的 “啊哈时刻” 在 2b 非 sft 模型上的视觉推理. arXivpreprint arXiv:2503.05132, 2025.
[61]周,Q.,周,R.,胡,Z.,陆,P.,高,S.,和张,Y.图像思维提示用于多模态大语言模型中的视觉推理改进,2024。
A 限制与未来工作
在这项工作中,我们专注于大型视觉模型(LVM),通过消除语言作为混杂因素来研究视觉规划能力出于研究目的。因此,这种选择将模型大小限制为3B,作为唯一可用的LVM尺寸,并排除了最近发布的原生多模态模型,这些模型能够生成多模态输出[9,52]。然而,我们认为视觉规划范式可以扩展到更广泛的多模态生成模型,用于更多样化的任务,只要它们支持图像生成。
此外,显式生成图像在推理过程中引入了计算开销,与文本响应相比。然而,我们认为基于语言的推理,特别是对于思考模型 [13],可能同样或更耗时。在我们的演示中,Gemini 生成了超过 7,000 个思考标记,但最终未能提供正确答案。图像生成引入的计算开销可以通过使用更少的标记来表示更紧凑的图像来缓解 [10],这是我们主张的未来研究方向。
这项工作中的另一个限制在于状态-动作解析函数的实现。为了简化,我们采用了基于规则的方法,该方法比较当前状态和先前状态之间的像素级特征(详情见附录B.3)。虽然在我们受控的设置中有效,但这种方法限制了其在更广泛任务设置中的泛化能力。尽管如此,我们认为核心思想是可扩展的,并且可以通过成熟的计算机视觉技术(如分割[41],轮廓检测[32]等)来支持。我们鼓励未来研究探索更健壮和可扩展的视觉状态-动作解析设计,以推动视觉规划系统的发展。
更广泛的影响这项工作引入了一种新颖的视觉规划范式,其中智能体完全在视觉模态中进行推理和行动,而不依赖于文本中介。通过证明模型可以通过图像序列进行规划,这项研究为人类和AI系统交互的方式开辟了新的可能性,特别是在机器人、导航和辅助技术等感知和决策紧密结合的领域。作为基于纯视觉表示的规划的第一步,我们的工作为集成语言和非语言推理的AI系统奠定了基础。我们主张未来研究更全面的跨模态思维系统,其中交错的文本和图像轨迹能够实现更丰富、更像人类的推理,并强调在这样轨迹中加强视觉组件对于改进规划和认知的重要性。
B 实现细节
B.1数据集
任务动作空间。FROZENLAKE和MAZE都涉及四个基本导航动作:上、下、左和右。MINIBEHAVIOR包括一个更复杂的动作空间,有两个额外的操作:拾取、放下。
数据集准备。对于FROZENLAKE和MAZE,我们构建了从 3×33 \times 33×3 到 6×66 \times 66×6 的网格大小环境。对于每种大小,我们采样1250个环境,其中1000个用于训练,250个用于测试(表2)。这里每个环境都保证有一个唯一的布局,并且智能体在网格中随机初始化,该网格可以到达目标,形成初始状态 v0v_{0}v0 。由于MINIBEHAVIOR中环境布局的多样性相对有限,复杂性主要来自动作空间,在小网格大小中采样唯一环境变得具有挑战性。因此我们只关注网格大小 7×77 \times 77×7 和 8×88 \times 88×8 ,允许布局重复,但改变智能体生成位置以确保足够的数据量。为了防止数据泄露,我们根据布局身份分割数据集,确保训练集和测试集之间没有布局重叠。
我们接下来描述与第3节中概述的训练设置相对应的数据集构建步骤,每个任务中的样本数量汇总在表3中。
- 文本中的SFT(基线):对于每个环境,我们采样一个由视觉状态序列 (v0,…,vn)(v_{0},\dots,v_{n})(v0,…,vn) 组成的最佳轨迹作为真实标签。状态之间的每个转换由一个动作决定,使我们能够推导出相应的语言化动作序列
表 2:按网格大小对每个任务的训练数据集分布。值表示环境数量。
| FROZENLAKE | ||||
| 网格大小 | 3 | 4 | 5 | 6 |
| 训练 | 1000 | 1000 | 1000 | 1000 |
| Test | 250 | 250 | 250 | 250 |
| MAZE | ||||
| 网格大小 | 3 | 4 | 5 | 6 |
| 训练 | 1000 | 1000 | 1000 | 1000 |
| Test | 250 | 250 | 250 | 250 |
| MINIBEHAVIOR | ||||
| 网格大小 | 7 | 8 | ||
| 训练 | 796 | 801 | ||
| Test | 204 | 199 | ||
(a0,…,an−1)(a_0,\ldots ,a_{n - 1})(a0,…,an−1) .模型的输入是通过将文本提示与初始状态的形象表示 v0v_{0}v0 连接起来形成的,而目标输出是表示最优轨迹的口头化动作序列。详细的提示在附录D中提供。
- VPFT: 我们使用了与上述基于语言的推理基线相同的最佳轨迹集。在视觉场景中,每个轨迹通过将时间步 ttt 的状态作为输入与时间步 t+1t + 1t+1 的后续状态作为目标来生成多个输入 - 目标对。
VPRL:
-
阶段 1: 此数据集仅用于视觉主干网络的格式控制训练。对于每个环境, 我们从初始状态枚举所有可能的轨迹作为 v0v_{0}v0 并生成相应的输入 - 目标对。过滤重复对以保持平衡分布。- 阶段 2: 为确保公平性和可比性, 此数据集使用与 VPFT 相同的输入状态。
-
VPFT*: 我们进行了一项消融研究(用 * 标注),其中 VPFT 也分两个阶段进行训练,模仿 VPRL 的结构。阶段 1 遵循 VPRL 阶段 1 的相同步骤,专注于使用枚举的视觉输入进行格式监督。阶段 2 重用原始 VPFT 训练流程,从最佳轨迹中学习。实验结果和分析见附录 C.4。
注意:对于文本和视觉规划设置,评估仅使用每个测试环境的初始状态 v0v_{0}v0 作为输入。
数据集统计。我们使用分布内和分布外(OOD)设置评估不同系统变体的性能。表2显示了跨三个任务在不同网格大小上的训练数据分布。不同系统变体的训练和测试样本数量显示在表3中。对于OOD评估,放大的网格大小显示在表7中。OOD评估数据包括每个任务250个样本。
B.2模型
大型视觉模型(LVM)[4]是一种用于图像生成的自回归模型,它仅使用不接触语言数据的图像序列进行预训练。该模型使用基于VQGAN架构[12],的标记器,该标记器从原始图像中提取视觉信息,并将其编码为固定码本中的256个标记。图像以离散标记的自回归方式生成,然后输入到图像解码器中。尽管LVM支持多种模型大小,但仅公开提供3B参数版本;因此,我们在实验中使用此变体。为了公平比较,我们使用与参数大小匹配的Qwen 2.5-VL-Instruct [3]作为基于语言的基础线。
B.3奖励实现
我们采用基于规则的状体-动作解析函数 P\mathcal{P}P 和进度地图 D(v)D(v)D(v) 在VPRL中。对于进度地图,我们应用广度优先搜索(BFS)来搜索最优轨迹并计算
表3:每个任务和方法用于训练和测试的样本数量。对于视觉规划,这里的数字以图像对的形式表示,这与Text中的SFT轨迹数量相同。
| Task | 分割 | Text中的SFT|VPFT | VPRL | VPFT* | |||
| 阶段1 | 阶段2 | 阶段1 | SFT | ||||
| FROZENLAKE | 训练Test | 4000 | 12806 | 170621 | 12806 | 170621 | 12806 |
| 1000 | 1000 | N/A | 1000 | N/A | 1000 | ||
| MAZE | 训练Test | 4000 | 14459 | 156682 | 14459 | 156682 | 14459 |
| 1000 | 1000 | N/A | 1000 | N/A | 1000 | ||
| MINIBEHAVIOR | 训练Test | 1597 | 9174 | 90808 | 9174 | 90808 | 9174 |
| 403 | 403 | N/A | 403 | N/A | 403 | ||
每个任务在网格的每个位置上的进度。进度地图然后被用作奖励信号来指导VPRL训练。
具体来说,对于状态-动作解析函数,我们通过像素级特征提取器解析状态并识别当前状态和先前状态之间的差异。我们首先通过将图像根据其大小分割成网格,将输入和预测状态都转换为基于坐标的表示。每个区域对应环境中的一个离散坐标。为了减少对颜色的敏感性并专注于结构差异,我们将所有图像转换为灰度图像。随后,我们在预测状态中的每个坐标和包含玩家(输入坐标)的输入状态中的坐标之间计算交并比(IoU)。在预测状态中具有最高 IoU 的坐标被选为预测的智能体位置。然后根据特定任务的运动规则通过比较起始位置和预测位置来推断动作。例如,在 MAZE 环境中,不允许穿过墙壁,这将被视为无效。
值得注意的是,为了检测无效的转换,例如代理的消失,我们还计算相应坐标之间的像素级均方误差(MSE)来衡量局部视觉差异。如果两个坐标表现出显著的MSE差异并超过预定义的阈值,我们将它们视为运动的潜在源和目标(代理从一个地方消失并在另一个地方出现)。如果只找到一个这样的坐标,我们将之视为消失事件,表明发生了无效转换。
在 MINIBEHAVIOR 中,我们将此逻辑扩展到识别拾取和放置动作。当打印机在输入和预测状态中的位置之间的 IoU 低于阈值时,会检测到拾取,这表明打印机已被移除。当对应于桌子区域的坐标显示 MSE 大幅增加时,会推断出放置事件,表明打印机已被放置在那里。为了简洁起见,这些任务中的其他边缘情况被省略了。
对于奖励计算,如果预测的动作有效,我们将比较输入和预测状态之间进度地图 D(v)D(v)D(v) 的进度值。如果预测状态比输入状态更接近目标,则给予奖励1;否则,奖励为0。无效动作会被处以-5的奖励。
我们的方法和奖励建模方法可以很容易地推广到其他视觉任务。参考计算机视觉技术,如分割 [41] 和轮廓检测 [32], 我们框架中使用的像素级分析可以很容易地扩展到各种结构化的视觉环境。此外,我们的奖励设计广泛适用于一般的规划任务。由于大多数规划环境中的动作自然地可以分为三种类型(有效且有帮助、有效但不进展、或无效),我们简单的奖励结构在任务中仍然直观且有效。
B.4 训练细节
对于所有后训练实验,我们在注意力层和前馈层上都应用低秩适配(LoRA)[20]。详细的超参数显示在表4中。只有损失
表 4: 文本和视觉规划器训练的超参数。
| 超参数SFT inText | VPFT | VPRL | VPFT* | |||
| Stage 1 | Stage 2 | 阶段1 | SFT | |||
| 周期 | 30 | 30 | 10 | 10 | 10 | 30 |
| 学习率 | 1e-5 | 1.5e-4 | 1.5e-4 | 5e-5 | 1.5e-4 | 1.5e-4 |
| 训练批次大小 | 16 | 8 | 8 | 1 | 8 | 8 |
| 组大小 | N/A | N/A | N/A | 10 | N/A | N/A |
| 梯度累积 | 2 | 1 | 1 | 1 | 1 | 1 |
| GPUs | 8 | 8 | 8 | 8 | 8 | 8 |
表 5:我们计算因至少一个无效动作而非次优但有效动作导致的失败轨迹的百分比。低值表示更好的动作有效性控制。
| Task | 无效失败率 (%) | |
| VPRL | VPFT | |
| FROZENLAKE | 36.9 | 60.6 |
| MAZE | 25.1 | 73.7 |
| MINIBEHAVIOR | 29.6 | 78.3 |
标签的计算方式是针对SFT进行指令调优的[49]。在训练过程中,图像分词器和反分词器是冻结的。我们使用AdamW优化器[35]对所有训练过程进行优化。
在文本规划和视觉规划中,我们最多训练模型30个epoch。对于VPRL,我们首先在随机轨迹上进行阶段1的训练,持续10个epoch,目的是探索。然后我们使用GRPO对模型进行规划优化,持续10个epoch进行阶段2。我们为每个提示采样一组10个候选响应,以相应地计算优势。为了鼓励探索和利用之间的平衡,我们应用了一个KL散度惩罚,系数为 β=0.001\beta = 0.001β=0.001 。我们使用TRL库进行训练[47]。我们的实验是在具有 8×A1008\times \mathrm{A}1008×A100 GPU的机器上进行的。
B.5 许可证
在模型层面,Large Vision Model 和 Qwen 2.5 VL 使用 Apache-2.0 许可证。TRL 使用 Apache-2.0 许可证。我们使用自己的 Python 脚本收集 MAZE 数据集。FROZENLAKE 是从 MIT 许可证的 OpenAI Gym 中收集的。
C结果
C.1 训练
所有任务的奖励曲线的标准差如图7所示。阴影区域表示组间的标准差。为了更好的可视化,我们对奖励值及其对应的标准差都应用了高斯平滑。
C.2性能与缩放困难
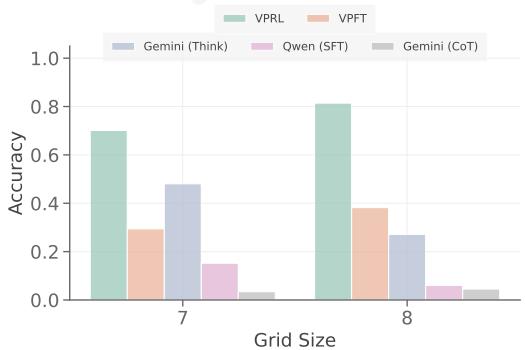
我们在 MINIBEHAVIOR 和 MAZE 中评估了不同方法在任务难度方面的性能,如图 8 所示。我们的视觉规划器在所有网格尺寸上都始终实现了更高的精度,并且表现出明显更平坦的性能曲线,这表明它们对环境复杂度增加的鲁棒性更强。
有趣的是,在 MINIBEHAVIOR 中,我们观察到视觉规划器的精度随着网格尺寸的增加而提高,这与文本规划器表现出的趋势相反。我们假设这是因为该任务中存在固定的布局组件,具体来说,只有表格和打印机。这保持了不同网格尺寸之间的一致布局复杂度,并允许获得的
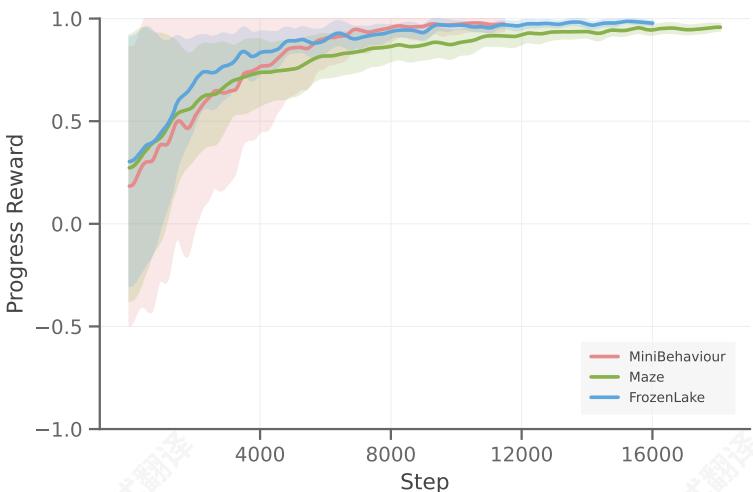
图7:VPRL在FROZENLAKE、MAZE和MINIBEHAVIOR上的奖励曲线及其标准差。
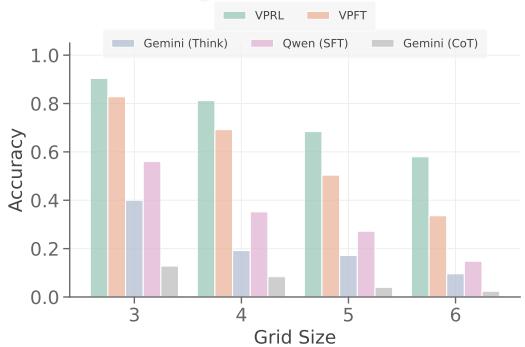
图8:不同网格尺寸下的性能表现,反映了任务难度。左:MAZE。右:MINIBEHAVIOR。视觉规划器始终保持更高的准确率,并表现出更平缓的性能曲线,表明其对复杂度增加具有鲁棒性。
在较小的网格中进行训练,以有效地泛化到较大的网格。这表明视觉规划能更好地捕捉和迁移环境中的结构模式。
C.3分布外性能
图9展示了VPFT和VPRL在MAZE、FROZENLAKE和MINIBEHAVIOR任务上的分布外场景生成的图像。值得注意的是,尽管在训练过程中未遇到这些配置,但两种模型都表现出一定的视觉泛化能力,例如对具有更细粒度步长的较大网格。
我们随后通过在具有较大网格尺寸的分布外环境中评估模型来定量测试泛化能力。我们发现SFT模型表现较差,而VPRL仍然表现出一定的视觉规划能力,如表7所示。VPRL在Exact Match和Progress Rate两个方面始终优于VPFT,表明它在某种程度上捕捉了潜在的规划策略,而不仅仅是记忆训练模式。
C.4 消融实验:Stage1的作用
为了更好地理解Stage1在我们两阶段框架中的作用,我们进行了一项消融实验,以隔离其影响。Stage1的主要目的不是直接提高规划性能,而是初始化一个具有强大探索能力和有效输出格式的策略。为了验证
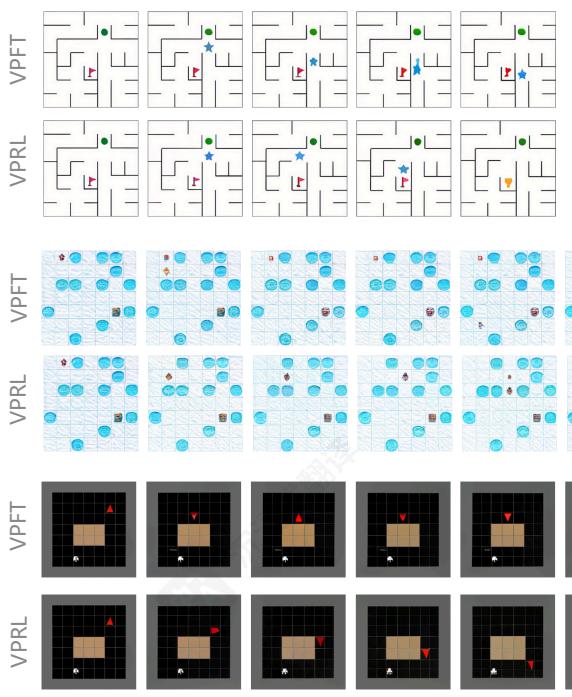
图9:VPFT(顶部)和VPRL(底部)在MAZE、FROZENLAKE和MINIBEHAVIOR等分布外(OOD)场景中,使用未见过的较大网格尺寸时的视觉规划输出定性比较。每个示例展示了VPFT的一个失败案例,并与VPRL在相同环境配置下生成的成功轨迹进行对比。
表 6:VPFT 和 VPFT* 在 FROZENLAKE 中不同网格尺寸下的精确匹配性能。
精确匹配 (%)(\%)(%)
模型 3×33 \times 33×3 4×44 \times 44×4 5×55 \times 55×5 6×66 \times 66×6
VPFT* 86.4 73.6 50.0 33.2
VPFT 92.0 82.8 68.8 58.0
这,我们重用了原始的VPFT训练流程,即从最优轨迹中学习,但从VPFT*的Stage1检查点开始。令人惊讶的是,这种变体在FROZENLAKE上的最终性能低于标准VPFT。这个结果支持我们的假设,即Stage1本身并不对规划能力做出贡献,而是提供一个有利于探索的初始化,从而促进Stage2中的有效强化学习。
C.5 视觉规划结果
VPRL Stage 1 和 Stage 2 表 8 展示了 VPRL 每个阶段的结果。在 Stage 1 之后,模型学会生成看似合理的图像,但缺乏目标导向行为,导致在各项任务上的表现接近随机。在 Stage 2 中,强化学习注入了有目的的规划,使模型能够将生成结果与目标对齐,并在所有基准测试中超越 VPFT。
为说明而生的视觉规划轨迹图 10 显示了 FROZENLAKE 生成的视觉规划轨迹,图 11 用于 MAZE,图 12 用于 MINIBEHAVIOR。每个视觉轨迹以初始状态作为输入(第一帧),然后是一系列由 VPRL 生成的中间状态,这些状态构成了预测的视觉计划。
我们包含三个类别的示例:(1) 最优情况,其中模型成功生成了到达目标的最短有效路径;(2) 非最优情况,其中智能体由于中间的非最优动作而未能以最优步数到达目标;以及 (3) 无效
表7:在扩大网格上的分布外(OOD)性能。模型在较小的网格上训练,并在括号中指示的尺寸上进行评估。
表 8: VPRL 阶段 1 和阶段 2 在所有三个任务中的性能比较。
| 模型 | FROZENLAKE (7×7) | MAZE (7×7) | MINIBEHAVIOR (9×9) | |||
| EM (%) | PR (%) | EM (%) | PR (%) | EM (%) | PR (%) | |
| VPFT | 9.6 | 15.3 | 9.2 | 17.8 | 0.0 | 5.8 |
| VPRL | 20.4 | 31.2 | 10.0 | 21.6 | 0.4 | 14.7 |
| 模型 | FROZENLAKE | MAZE | MINIBEHAVIOR | |||
| EM (%) | PR (%) | EM (%) | PR (%) | EM (%) | PR (%) | |
| VPRL阶段1 | 11.1 | 27.2 | 9.6 | 22.7 | 0.5 | 14.2 |
| VPRL阶段2 | 91.6 | 93.2 | 74.5 | 77.6 | 75.8 | 83.8 |
案例, 其中生成的轨迹包含无效动作, 违反环境约束, 导致任务无法完成。值得注意的是,如图 3 所示, 我们仍然观察到偶尔的规划错误。虽然与监督微调相比, 强化学习显著提高了泛化能力, 但它并不能完全消除此类失败案例。
Correct Cases
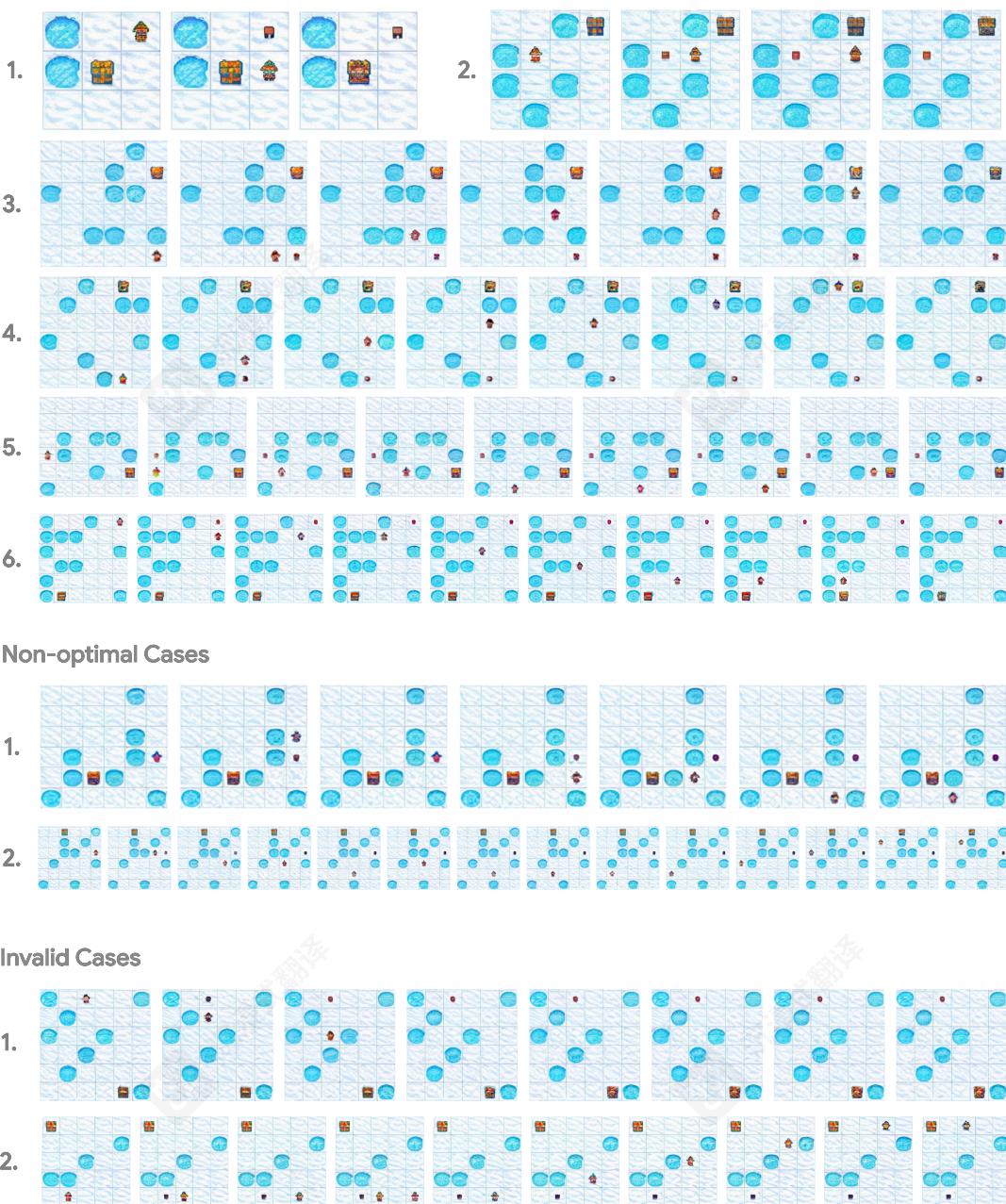
Figure 10: Generated visual planning trajectories from VPRL on the FROZENLAKE test set. We illustrate three representative categories: optimal, non-optimal, and invalid cases. In non-optimal examples, the model occasionally enters local loops but still has the chance to make progress toward the goal, see the first and third trajectories. In invalid cases, despite a significant reduction in failure rate, VPRL still exhibits errors such as disappearing agents, contradictory actions (e.g., simultaneous left and right), or unrealistic teleportation.
Correct Cases

Figure 11: Generated visual planning trajectories from VPRL on the MAZE test set. We illustrate three representative categories: optimal, non-optimal, and invalid cases. In non-optimal examples, similar to FROZENLAKE, the model occasionally enters redundant loops but still progresses toward the goal. Invalid cases include maze-specific errors, such as the agent erroneously traversing through walls, violating the structural constraints of the environment. Notably, we observe that in the last invalid case, the agent is able to plan an optimal trajectory in subsequent steps.
Correct Cases

Figure 12: Generated visual planning trajectories from VPRL on the MINIBEHAVIOR test set.
D 提示模板
FROZENLAKE
任务:冰冻湖最短路径规划
你被给定一个基于网格的环境的图像。在这个环境中:
- Arg p1扎物表目标e-st些单元格包含跳洞o精灵无法通过。-精灵只能在一个方向上移动:“上”、“下”、“左"或"右”。每次移动将精灵转移到对应绝对方向的一个单元格。不允许对角线移动。
你的任务是分析图像并生成最短的有效动作序列,将精灵从起始位置移动到目标位置,而不踏入任何冰洞。
请将您的最终答案包含在 和之间,例如:right up up。
<图像>
MAZE
Task: Maze Shortest Path Planning
您给定了一个迷宫环境的图像。在这个环境中:- 一个绿色圆圈标记了智能体的起始位置。- 一个红色旗帜标记了目标。- 智能体只能在一个方向上移动:“up”、“down”、“left"或"right”。每次移动使智能体在该方向上移动一个单元格。不允许对角线移动。- 黑色的迷宫墙壁是不可通行的。智能体不能通过任何墙壁段。
您的任务是分析图像,并生成最短的有效动作序列,使智能体从其起始位置移动到目标位置,而不穿过任何墙壁。
请将您的最终答案包含在 和之间,例如:right up
图像>
MINIBEHAVIOR
任务:微型行为安装打印机
r
You are given an image of a grid-based environment. In this environment:
- The red triangle represents the agent.
- The white icon represents the printer, which must be picked up by the agent.
- The brown tiles represent the table, where the printer must be placed.
智能体可以执行以下动作:- “向上”, “向下”, “向左”, “向右”:每个动作使智能体在该方向上移动恰好一个单元格。不允许对角线移动。
- “pick”: 如果打印机在智能体周围的四个相邻单元格之一中,则拾取打印机。如果没有相邻的打印机,此操作无效。- “drop”: 如果智能体相邻于一个表格单元格,则将打印机放在桌子上。如果没有相邻的桌子,此操作无效。约束条件:- 智能体不能穿过表格瓦片。- 在拾取之前,智能体不能穿过打印机。拾取后,智能体可以穿过先前包含打印机的单元格。您的任务是分析图像,并生成最短的有效操作序列,使智能体能够拾取打印机并将其放在桌子上。将您的最终答案括在 和 之间,例如:right down right pick left drop .