【论文阅读】REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
https://arxiv.org/pdf/2210.03629
一直没有读过ReAct这篇论文,进行一下补课。
以下是对论文《ReAct: Synergizing Reasoning and Acting in Language Models》的系统分析,涵盖研究动机、研究现状、创新点、解决方案、实验设计、研究结论和未来方向七个方面:
一、研究动机:核心问题与背景
核心问题:
大型语言模型(LLMs)在推理(reasoning)和行动(acting)方面表现出强大能力,但现有研究通常将两者割裂开来:
- 推理:如 Chain-of-Thought (CoT) 提示,仅依赖模型内部知识进行静态推理,容易幻觉(hallucination)和错误传播。
- 行动:如 WebGPT、SayCan 等,通过语言模型生成动作与环境交互,但缺乏高层抽象推理和工作记忆支持。
研究背景:
人类智能的核心在于推理与行动的紧密结合。例如做饭时,人们会根据当前状态调整计划、搜索外部信息、反思并修正行为。这种“边想边做”的机制在 LLM 中尚未被充分建模。
研究动机:
提出一种统一的框架 ReAct,使 LLM 能交错生成推理轨迹和动作,实现“边推理边行动”,提升任务解决能力、可解释性和鲁棒性。
二、研究现状:领域发展与已有工作
| 研究方向 | 方法 | 局限 |
|---|---|---|
| 推理(Reasoning) | CoT、Self-Consistency、STaR、Scratchpad 等 | 静态推理,无法更新知识,易幻觉 |
| 行动(Acting) | WebGPT、SayCan、Inner Monologue | 缺乏高层推理与计划,依赖大量训练数据或人工反馈 |
| 推理+行动 | 少量研究尝试结合,如 Inner Monologue | 仅提供环境反馈,缺乏灵活推理与计划能力 |
总结:
尚无系统研究将自由语言推理与结构行动融合用于通用任务求解。ReAct 是首个在多种任务中系统验证“推理+行动”协同作用的框架。
三、创新点:思路来源与创新性
| 创新维度 | 内容 |
|---|---|
| 思路来源 | 借鉴人类“内语”(inner speech)和“边想边做”的认知机制 |
| 方法创新 | 提出 ReAct 框架,交错生成推理(thoughts)与动作(actions),无需训练,仅通过 prompt 实现 |
| 结构创新 | 将语言空间作为动作空间的一部分,thoughts 不影响环境但更新上下文 |
| 应用创新 | 在知识推理(HotpotQA、FEVER)和交互决策(ALFWorld、WebShop)任务中统一验证 |
四、解决方案:ReAct 框架详解
1. 框架结构
- 动作空间扩展:
原始动作空间 A 扩展为 A ∪ L,其中 L 是语言空间(thoughts)。 - **推理轨迹(thoughts)**作用:
- 分解目标、制定计划
- 提取观察中的关键信息
- 跟踪进度、调整策略
- 处理异常、修正错误
- **动作(actions)**作用:
- 与环境交互(如搜索 Wikipedia、点击按钮)
- 获取外部信息,反馈给推理过程
2. 提示设计(Prompting)
- few-shot prompting:人工设计包含 thought-action-observation 链的示例
- thoughts 密度控制:
- 知识任务:密集 thoughts(每步都推理)
- 决策任务:稀疏 thoughts(只在关键处推理)
3. 知识整合策略
- ReAct ↔ CoT-SC 切换:
- ReAct 失败 → 退回 CoT-SC(利用内部知识)
- CoT-SC 置信度低 → 退回 ReAct(利用外部知识)
五、实验设计:任务、对比与评估
1. 任务设置
| 类别 | 数据集 | 特点 |
|---|---|---|
| 知识推理 | HotpotQA、FEVER | 多跳问答、事实验证,需外部知识 |
| 交互决策 | ALFWorld、WebShop | 长周期任务,需计划与探索 |
2. 对比方法
| 方法 | 描述 |
|---|---|
| Standard | 无推理、无行动,仅问答 |
| CoT | 仅推理,无外部交互 |
| Act | 仅行动,无推理 |
| CoT-SC | CoT + 自洽性投票 |
| ReAct | 本文方法,推理+行动 |
| ReAct ↔ CoT-SC | 混合策略 |
3. 评估指标
- HotpotQA / FEVER:Exact Match / Accuracy
- ALFWorld / WebShop:Success Rate、Score(任务完成率)
- 人工分析:成功/失败模式分类(幻觉、推理错误、搜索失败等)
六、研究结论:主要发现与结论
| 维度 | 结论 |
|---|---|
| 性能 | ReAct 在 4 个任务中均优于纯推理或纯行动方法,尤其在交互任务中提升显著(ALFWorld +34%,WebShop +10%) |
| 鲁棒性 | ReAct 推理轨迹更可信,幻觉更少(HotpotQA 幻觉率 6% vs CoT 14%) |
| 可解释性 | 人类可读取 thought 链,理解模型决策过程,支持人工干预 |
| 数据效率 | 仅 1-6 个示例即可泛化,优于 IL/RL 方法(需数千条轨迹) |
| 微调潜力 | 用 3000 条 ReAct 轨迹微调 PaLM-8B,性能超越 540B prompt 方法 |
七、未来方向:开放问题与研究方向
| 方向 | 内容 |
|---|---|
| 数据扩展 | 构建更大规模、多样化的 ReAct 风格数据集,支持多任务微调 |
| 模型扩展 | 结合强化学习(RL)或人类反馈(RLHF)优化推理与行动策略 |
| 多模态 | 将 ReAct 扩展到视觉-语言任务(如机器人导航、GUI 操作) |
| 推理深度 | 引入更复杂的推理结构(如树搜索、计划回溯)提升长期规划能力 |
| 安全性 | 研究如何防止模型在开放环境中执行有害或误导性行动 |
| 人机协作 | 探索“人类编辑 thoughts”作为干预机制,提升对齐性与可控性 |
总结一句话:
ReAct 通过交错推理与行动,首次在统一框架中实现了 LLM 的“边想边做”,在知识推理与交互决策任务中均取得显著性能与可解释性提升,为构建更智能、可控、可扩展的语言智能体开辟了新路径。

REACT: 在语言模型中协同推理和行动
姚顺雨*,1,赵杰2,余狄安2,杜南2,沙弗兰2,纳拉辛汉1,曹原2
普林斯顿大学计算机科学系
2.谷歌研究,大脑团队
1^{1}1 shunyuy,karthikn@princeton.edu
2^{2}2 jeffreyzhao,dianyu,dunan,izhak,yuancao}@google.com
摘要
虽然大型语言模型(LLMs)在语言理解和交互式决策等任务中表现出色,但它们在推理(例如思维链提示)和行动(例如行动计划生成)方面的能力主要作为独立主题进行过研究。在本文中,我们探索了使用LLMs以交错方式生成推理轨迹和特定任务行动的方法,从而实现两者之间的更大协同:推理轨迹帮助模型诱导、跟踪和更新行动计划以及处理异常,而行动则允许它与外部来源(如知识库或环境)进行交互并收集更多信息。我们将名为ReAct的方法应用于一系列语言和决策任务,并证明其在最先进基线之外的有效性,以及改进的人类可解释性和可信度。具体来说,在问答(HotpotQA)和事实验证(Fever)上,ReAct通过与简单的维基百科API交互,并生成比没有推理轨迹的基线更具可解释性的类人任务解决轨迹,克服了思维链推理中常见的幻觉和错误传播问题。此外,在两个交互式决策基准(ALFWorld和WebShop)上,ReAct分别比模仿学习和强化学习方法在绝对成功率上高出 34%34\%34% 和 10%10\%10% ,而只需一个或两个上下文示例提示。
1 引言
人类智能的独特之处在于能够无缝地将面向任务的动作与语言推理(或内部言语,Alderson-Day & Fernyhough, 2015)相结合,这种能力被认为在人类认知中起着重要作用,能够实现自我调节或策略制定(Vygotsky, 1987; Luria, 1965; Fernyhough, 2010)并维持工作记忆(Baddeley, 1992)。以在厨房里做一道菜为例。在任何两个特定动作之间,我们可能会用语言进行推理,以跟踪进度(“现在一切都切好了,我应该加热锅里的水”),处理异常或根据情况调整计划(“我没有盐,所以让我用酱油和胡椒代替”),以及意识到何时需要外部信息(“我该如何准备面团?让我在互联网上搜索”)。我们还可以采取行动(打开食谱书阅读食谱、打开冰箱、检查食材)来支持推理并回答问题(“我现在能做什么菜?”)。这种“行动”与“推理”之间的紧密协同作用使人类能够快速学习新任务,并在之前未见过的环境或面对信息不确定的情况下做出稳健的决策或推理。

图1:(1)4种提示方法的比较,(a)标准,(b)思维链(CoT,仅推理),©仅行动,以及(d)ReAct(推理+行动),解决一个HotpotQA(Yang等人,2018)问题。(2)(a)仅行动和(b)ReAct提示方法解决AlfWorld(Shridhar等人,2020b)游戏的比较。在这两个领域,我们在提示中省略上下文示例,仅显示模型(行动,推理)生成的任务解决轨迹和环境(观察)生成的轨迹。
近期的研究结果表明,在自主系统中结合语言推理与交互式决策的可能性。一方面,经过适当提示的大型语言模型(LLMs)已经展现出进行推理步骤以推导出算术、常识和符号推理任务中问题的答案的涌现能力(Wei等人,2022)。然而,这种“思维链”推理是一个静态的黑盒,因为模型使用其内部表示来生成思考,并且没有与外部世界建立联系,这限制了其反应式推理或更新知识的能力。这可能导致事实幻觉和推理过程中的错误传播等问题(图1(1b))。另一方面,最近的研究探索了在交互环境中使用预训练语言模型进行规划和行动(Ahn等人,2022;Nakano等人,2021;Yao等人,2020;Huang等人,2022a),重点是通过语言先验预测行动。这些方法通常将多模态观察转换为文本,使用语言模型生成特定领域的行动或计划,然后使用控制器选择或执行它们。然而,它们没有使用语言模型进行抽象推理高级目标或维持工作记忆以支持行动,除非Huang等人(2022b)进行了有限形式的语言推理以重述当前状态的空间事实。除了与几个积木交互的这种简单具身任务之外,目前还没有研究如何以协同的方式将推理和行动结合起来进行一般任务解决,以及这种结合是否与单独推理或行动相比能带来系统性的好处。
在这项工作中,我们提出了ReAct,一种结合推理和行动的通用范式,用于解决各种语言推理和决策任务(图1)。ReAct以交错的方式提示大型语言模型生成与任务相关的语言推理轨迹和行动,这允许模型进行动态推理,以创建、维护和调整行动的高级计划(为行动而推理),同时还可以与外部环境(例如Wikipedia)交互,以将额外信息纳入推理(为推理而行动)。
我们对ReAct和最先进的基线在四个不同的基准上进行了实证评估:问答(HotPotQA,Yang等人,2018年)、事实验证(Fever,Thorne等人,2018年)、基于文本的游戏(ALFWorld,Shridhar等人,2020b)和网页导航(WebShop,Yao等人,2022年)。对于HotPotQA和Fever,通过访问模型可以交互的维基百科API,ReAct的表现优于纯行动生成模型,同时与思维链推理(CoT)具有竞争力(Wei等人,2022年)。总体上最好的方法是ReAct和CoT的结合,它允许在推理过程中使用内部知识和外部获取的信息。在ALFWorld和WebShop上,两轮甚至单轮的ReAct提示能够优于使用 103∼10510^{3} \sim 10^{5}103∼105 任务实例训练的模仿或强化学习方法,成功率分别提高了 34%34\%34% 和 10%10\%10% 。我们还通过展示在仅包含行动的控制基线上的持续优势,证明了稀疏、多功能的推理在决策中的重要性。除了通用适用性和性能提升外,推理和行动的结合还有助于模型的可解释性、可信性和可诊断性,因为人类可以轻松地区分模型内部知识与外部环境,以及检查推理轨迹以理解模型行动的决策基础。
总结来说,我们的主要贡献如下:(1)我们提出了ReAct,一种基于提示的新范式,用于在语言模型中协同推理和行动以解决一般任务;(2)我们在多个基准测试中进行了广泛的实验,以展示ReAct在少样本学习设置下相对于先前独立执行推理或行动生成方法的优势;(3)我们提出了系统的消融分析和研究,以理解行动在推理任务中的重要性,以及推理在交互任务中的重要性;(4)我们分析了ReAct在提示设置下的局限性(即推理和行动行为的支持有限),并进行了初步的微调实验,展示了ReAct在增加训练数据的情况下改进的潜力。将ReAct扩展到训练和操作更多任务,并将其与强化学习等互补范式相结合,可以进一步释放大型语言模型的潜力。
2 REACT:协同推理 + 行动
考虑一个智能体与环境交互以解决任务的通用设置。在时间步 ttt ,智能体从环境中接收观察 ot∈Oo_{t}\in \mathcal{O}ot∈O 并根据某些策略 π(at∣ct)\pi (a_t|c_t)π(at∣ct) 采取行动 at∈Aa_{t}\in \mathcal{A}at∈A ,其中 ct=(o1,a1,…,ot−1,at−1,ot)c_{t} = (o_{1},a_{1},\dots ,o_{t - 1},a_{t - 1},o_{t})ct=(o1,a1,…,ot−1,at−1,ot) 是智能体的上下文。当映射 ct↦atc_{t}\mapsto a_{t}ct↦at 高度隐式且需要大量计算时,学习策略具有挑战性。例如,图1(1c)中所示的智能体无法生成正确的最终行动(Act4)以完成问答任务,因为它需要对轨迹上下文(问题、Act1-3、Obs1-3)进行复杂的推理。类似地,图1(2a)中所示的智能体无法从上下文中理解到1号水坑不包含1号胡椒撒播器,因此继续产生幻觉行动。
ReAct\mathsf{ReAct}ReAct 的想法很简单:我们将智能体的行动空间扩展到 A=A∪L\mathcal{A} = \mathcal{A} \cup \mathcal{L}A=A∪L ,其中 L\mathcal{L}L 是语言空间。语言空间中的行动 a^t∈L\hat{a}_t \in \mathcal{L}a^t∈L ,我们将之称为思考或推理轨迹,不会影响外部环境,因此不会产生观察反馈。相反,思考 a^t\hat{a}_ta^t 旨在通过推理当前上下文 ctc_tct 来组合有用信息,并更新上下文 ct+1=(ct,a^t)c_{t+1} = (c_t, \hat{a}_t)ct+1=(ct,a^t) 以支持未来的推理或行动。如图1所示,可能有各种类型的有用思考,例如分解任务目标并创建行动计划(2b、Act1;1d、思考1)、注入与任务解决相关的常识知识(2b、Act1)、从观察中提取重要部分(1d、思考2、4)、跟踪进度和转换行动计划(2b、Act8)、处理异常和调整行动计划(1d、思考3),等等。
然而,由于语言空间 L\mathcal{L}L 是无限的,在这个增强动作空间中学习是困难的,并且需要强大的语言先验。在本文中,我们主要关注一个设置,其中冻结的大型语言模型PaLM-540B (Chowdhery et al., 2022) 1^11 ,被提示以少量上下文示例来生成特定领域的动作和自由形式的语言思维以解决任务(图1(1d),(2b))。每个上下文示例是一个人类动作、思维和环境观察轨迹,用于解决一个任务实例(见附录C)。对于推理是首要重要的任务(图1(1)),我们交替生成思维和动作,以便任务解决轨迹由多个思维-动作-观察步骤组成。相反,对于可能涉及大量动作的决策任务(图1(2)),思维只需要出现在轨迹中最相关的位置,所以我们让语言模型自己决定思维和动作的异步发生。
在轨迹中最相关的位置上稀疏地出现,因此我们让语言模型自行决定思想和行动的异步发生。
由于决策能力和推理能力被集成到一个大型语言模型中,ReAct具有几个独特的特点:A)直观且易于设计:由于人类标注者只是在他们的行为之上用语言写下他们的想法,因此设计ReAct提示非常直接。本文没有使用任何特设的格式选择、思想设计或示例选择。我们在第3节和第4节详细介绍了每个任务的提示设计。B)通用和灵活:由于灵活的思想空间和思想-动作发生格式,ReAct适用于具有不同动作空间和推理需求的各种任务,包括但不限于问答、事实验证、文本游戏和网络导航。C)高效且鲁棒:ReAct在学习仅一个到六个上下文示例的情况下,表现出对新的任务实例的强大泛化能力,始终优于仅推理或行动的不同领域的基线。我们在第3节还展示了启用微调时的其他好处,并在第4节展示了ReAct性能如何对提示选择保持鲁棒性。D)与人类对齐且可控:ReAct承诺一个可解释的顺序决策和推理过程,人类可以轻松检查推理和事实的正确性。此外,人类还可以通过思想编辑随时控制或纠正代理行为,如图5所示,第4节。
3知识密集型推理任务
我们从知识密集型推理任务开始,例如多跳问答和事实验证。如图1(1d)所示,通过与Wikipedia API交互,ReAct能够检索信息以支持推理,同时也能利用推理来定位下一步要检索的内容,展示了推理和行动的协同作用。
3.1设置
领域我们考虑了两个具有挑战性的知识检索和推理数据集:(1) Hot-PotQA (Yang等人,2018年),一个需要跨两个或多个Wikipedia段落进行推理的多跳问答基准,以及(2) FEVER (Thorne等人,2018年),一个事实验证基准,其中每个声明根据是否存在 Wikipedia段落来验证声明而被标注为SUPPORTS、REFUTES或NOT ENOUGH INFO。在这项工作中,我们对这两个任务都采用仅接收问题/声明作为输入的设置,模型无法访问支持段落,必须依赖其内部知识或通过与环境交互来检索知识以支持推理。
动作空间我们设计了一个简单的维基百科网页API,包含三种类型的动作来支持交互式信息检索:(1)搜索[实体],,如果存在,则返回对应实体维基百科页面中的前5句话,否则建议维基百科搜索引擎中排名前5的相似实体,(2)查找[字符串],,返回包含该字符串的页面中的下一句话,模拟浏览器中的Ctrl+F功能。(3)完成[答案],,用答案完成当前任务。我们注意到这个动作空间主要只能根据精确的段落名称检索一小部分段落,这比最先进的词汇或神经检索器要弱得多。目的是模拟人类如何与维基百科交互,并迫使模型通过语言中的显式推理来检索。
3.2方法
ReAct Prompting For HotpotQA 和 Fever,我们从训练集随机选择 6 和 3 个案例²,手动编写 ReAct 格式的轨迹,用作提示中的少样本示例。类似于图 1(d),每个轨迹由多个思考-行动-观察步骤(即密集思考)组成,自由形式的思考用于各种目的。具体来说,我们使用分解问题的思考组合(“我需要搜索 x,找到 y,然后找到 z”)、从维基百科观察中提取信息(“x 于 1844 年开始”,“段落没有告诉 x”)、进行常识推理(“x 不是 y,所以 z 必须改为…”)或算术推理(“1844 < 1989”)、指导搜索重写(“也许我可以搜索/查找 x”),并综合最终答案(“…所以答案是 x”)。有关更多详细信息,请参阅附录 C。
表1: PaLM-540B在HotpotQA和Fever上的提示结果。
| 提示方法a | HotpotQA (EM) | Fever (Acc) |
| 标准 CoT(Wei等人,2022) | 28.7 | 57.1 |
| 29.4 | 56.3 | |
| CoT-SC (Wang et al., 2022a) | 33.4 | 60.4 |
| Act | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| CoT-SC →ReAct | 34.2 | 64.6 |
| ReAct→CoT-SC | 35.1 | 62.0 |
| 有监督的SoTAb | 67.5 | 89.5 |
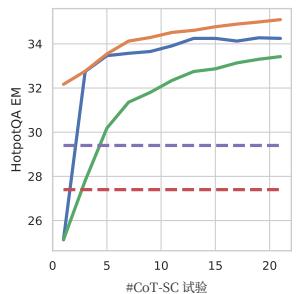
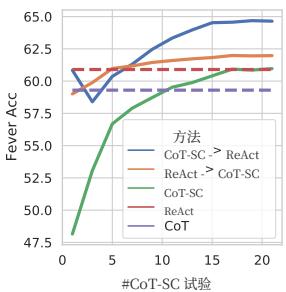
图2:PaLM-540B提示结果与所使用的CoT-SC样本数量的关系。
基线 我们系统地消融ReAct轨迹来构建多个基线的提示(格式如图1(la-1c)所示):(a) 标准提示(Standard),它移除ReAct轨迹中的所有思考、动作、观察。(b) 思维链提示(CoT)(Wei等人,2022年),它移除动作和观察,并作为仅推理的基线。我们还通过在推理过程中采样21个CoT轨迹,解码温度为0.7,并采用多数答案,构建了一个自洽基线(CoT-SC)(Wang等人,2022a;b),发现它始终能提升性能超过CoT。© 仅动作提示(Act),它移除ReAct轨迹中的思考,大致类似于WebGPT(Nakano等人,2021年)如何与互联网交互来回答问题,尽管它操作不同的任务和动作空间,并使用模仿和强化学习而不是提示。
结合内部和外部知识 如将在第3.3节中详细说明,我们观察到ReAct展示的问题解决过程更加注重事实和基础,而CoT在构建推理结构方面更准确,但容易产生幻觉的事实或想法。因此,我们提出结合ReAct和CoT-SC,并让模型根据以下启发式规则决定何时切换到其他方法:A) ReAct →\rightarrow→ CoT-SC:当ReAct在给定步骤内无法返回答案时,退回到CoT-SC。我们为HotpotQA和FEVER分别设置了7和5步,因为我们发现更多步骤不会提高ReAct的性能3。B) CoT-SC →\rightarrow→ ReAct:当 nnn CoT-SC样本中的多数答案出现次数少于 n/2n / 2n/2 次(即内部知识可能无法自信地支持任务)时,退回到ReAct。
微调 由于手动标注推理轨迹和动作在大规模上的挑战,我们考虑了一种类似于Zelikman等人(2022年)的引导方法,使用ReAct(也用于其他基线)生成的3,000个具有正确答案的轨迹来微调较小的语言模型(PaLM-8/62B),以解码基于输入问题/主张的条件轨迹(所有想法、动作、观察)。更多细节在附录B.1中。
3.3结果与观察
ReAct始终优于Act表1展示了使用PaLM-540B作为基础模型并结合不同提示方法在HotpotQA和Fever任务上的结果。我们注意到ReAct在两个任务上都优于Act,这证明了推理对指导行动的价值,尤其是在综合最终答案方面,如图1(1c-d)所示。微调结果3也证实了推理轨迹对更明智行动的益处。
表2:ReAct和CoT在HotpotQA上的成功和失败模式类型,以及它们在人类研究的随机示例中的百分比。
| Type | 定义 | ReAct | CoT | |
| 成功 | 真阳性 | 正确的推理轨迹和事实 | 94% | 86% |
| 假阳性 | 幻觉推理轨迹或事实 | 6% | 14% | |
| 失败 | 推理错误 | 错误的推理轨迹(包括无法从重复步骤中恢复) | 47% | 16% |
| 搜索结果错误 | 搜索结果为空或不包含有用信息 | 23% | - | |
| 幻觉 | 幻觉推理轨迹或事实 | 0% | 56% | |
| 标签歧义 | 预测正确但未精确匹配标签 | 29% | 28% |
ReAct与CoT另一方面,ReAct在Fever上的表现优于CoT(60.9 vs.56.3),但在HotpotQA上略逊于CoT(27.4 vs.29.4)。Fever中对SUPPORTS/REFUTES的主张可能仅相差微小(参见附录D.1),因此采取行动检索准确且最新的知识至关重要。为了更好地理解ReAct和CoT在HotpotQA上的行为差异,我们从ReAct和CoT中分别随机抽取了50个具有正确和错误答案的轨迹(由EM判断)(总共200个示例),并在表2中手动标注了它们的成功和失败模式。一些关键观察结果如下:
A) 妄想是 CoT 的一个严重问题,导致在成功模式下,其假阳性率远高于 ReAct(14% vs. 6%),并构成其主要失败模式(56%)。相比之下,ReAct 的问题解决轨迹更加基于事实、可信,这得益于其访问外部知识库。
B) 虽然ReAct交错推理、行动和观察步骤可以提高其基于事实性和可信度,但这种结构约束也降低了其制定推理步骤的灵活性,导致推理错误率高于CoT。我们注意到ReAct存在一个频繁的错误模式,即模型反复生成先前的想法和行动,我们将此归类为“推理错误”的一部分,因为模型未能推理出正确的下一步行动并跳出循环4。
C) 对于 ReAct,通过搜索成功检索到信息性知识至关重要。非信息性搜索占错误案例的 23%23\%23% ,会偏离模型推理,使其难以恢复和重新组织想法。这或许是在 f 之间的预期权衡。
我们在附录E.1中为每种成功和失败模式提供了示例。我们还发现部分HotpotQA问题可能包含过时的答案标签,例如见图4所示。
ReAct + CoT-SC 在提示 LLM 方面表现最佳。表 1 也显示了在 HotpotQA 和 Fever 上最佳提示方法分别是 ReAct → CoT-SC 和 CoT-SC → ReAct。此外,图 2 展示了不同方法在使用不同数量的 CoT-SC 样本时的表现。虽然两个 ReAct + CoT-SC 方法在各自的任务上有优势,但它们在所有样本数量下都显著且一致地优于 CoT-SC,仅使用 3-5 个样本就达到了使用 21 个样本的 CoT-SC 性能。这些结果表明,在推理任务中,正确结合模型内部知识和外部知识具有重要价值。
ReAct 在微调方面表现最佳。图 3 显示了提示/微调四种方法(Standard、CoT、Act、ReAct)在 HotpotQA 上的缩放效果。使用 PaLM-8/62B 时,提示 ReAct 在四种方法中表现最差,这是由于从上下文示例中学习推理和行动的难度较大。然而,当仅使用 3,000 个示例进行微调时,ReAct 成为四种方法中表现最好的方法,其中微调后的 PaLM-8B ReAct 表现优于所有 PaLM-62B 提示方法,而微调后的 PaLM-62B ReAct 表现优于所有 540B 提示方法。相比之下,对于 PaLM-8/62B,微调 Standard 或 CoT 与微调 ReAct 或 Act 相比要差得多,因为前者本质上教模型记忆(可能产生幻觉的)知识事实,而后者教模型如何(推理和)行动以从维基百科获取信息,这是一种更通用的知识推理技能。由于所有提示方法与特定领域的最先进方法仍然有显著差距(表 1),我们认为使用更多人类编写的数据进行微调可能是释放 ReAct 力量的更好方法。
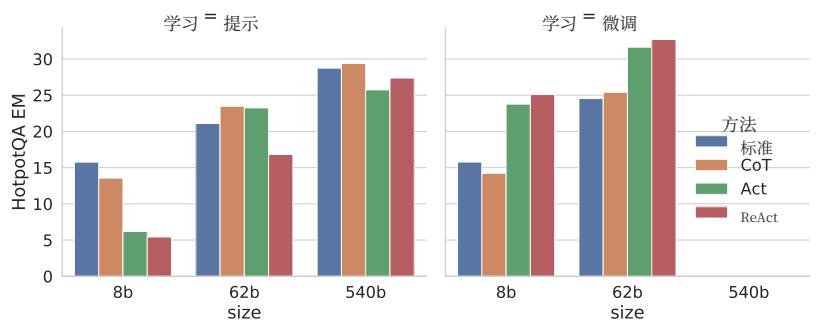
图3:在HotPotQA上使用ReAct(我们的)和基线进行提示和微调的扩展结果。
4决策任务
我们还测试了ReAct在两个基于语言的交互式决策任务ALFWorld和WebShop上的表现,这两个任务都涉及复杂的环境,需要代理在长时域内以稀疏奖励行动,这证明了对行动和探索进行有效推理的需要。
ALFWorld ALFWorld (Shridhar等人,2020b)(图1(2))是一个合成文本游戏,旨在与具身ALFRED基准(Shridhar等人,2020a)保持一致。它包括6种类型的任务,其中代理需要通过文本动作(例如:去到咖啡桌1,拿起纸2,使用台灯1)导航并与模拟家庭互动,以实现高级目标(例如:在台灯下检查纸)。一个任务实例可以包含50多个位置,需要专家策略50多步才能解决,因此挑战代理规划子目标、跟踪子目标以及系统性地探索(例如:逐一检查所有桌子是否有台灯)。特别是,ALFWorld中构建的一个挑战是需要确定常见家用物品的可能位置(例如:台灯可能位于桌子、架子或衣柜上),这使得该环境非常适合LLM利用其预训练的常识知识。为了提示ReAct,我们对每种任务类型随机标注三个训练集中的轨迹,其中每个轨迹包含稀疏思考,这些思考(1)分解目标,(2)跟踪子目标完成情况,(3)确定下一个子目标,以及(4)通过常识推理在哪里找到对象以及如何处理它。我们在附录C.4中展示了用于ALFWorld的提示。遵循Shridhar等人(2020b),我们在一个特定任务的设置中评估了134个未见过的评估游戏。为了稳健性,我们通过对我们标注的3个轨迹的每种排列组合,为每种任务类型构建6个提示。Act提示是使用相同的轨迹构建的,但没有思考——由于任务实例是从训练集中随机选择的,它既不偏向ReAct也不偏向Act,提供了一个公平和受控的比较来测试稀疏思考的重要性。对于基线,我们使用BUTLER(Shridhar等人,2020b),这是一个模仿学习代理,它在每种任务类型上使用 10510^{5}105 专家轨迹进行训练。
WebShop Can ReAct 还能与嘈杂的真实世界语言环境进行交互,用于实际应用?我们研究了 WebShop(Yao 等人,2022 年),这是一个最近提出的在线购物网站环境,包含 118 万个真实世界的产品和 12 千条人类指令。与 ALFWorld 不同,Webshop 包含多种结构化和非结构化文本(例如从亚马逊抓取的产品标题、描述和选项),并要求代理根据用户指令(例如“我正在寻找一个带抽屉的床头柜。它应该有镍色抛光,并且价格低于 140 美元”)通过网页交互(例如搜索“床头柜抽屉”,选择按钮,如“颜色:现代镍白色”或“返回搜索”)来购买产品。该任务通过在 500 条测试指令上的平均分数(所选产品覆盖所需属性的平均百分比)和成功率(所选产品满足所有要求的指令百分比)进行评估。我们制定了包含搜索、选择产品、选择选项和购买等操作的 Act 提示,ReAct 提示则额外推理以确定要探索的内容、何时购买以及哪些产品选项与指令相关。参见表 6 中的示例提示,以及附录中的表 10 中的模型预测。我们将其与一个模仿学习(IL)方法进行比较训练了1,012条人类标注轨迹,以及一个imitation + 强化学习(IL + RL)方法,该方法额外训练了10,587条训练指令。
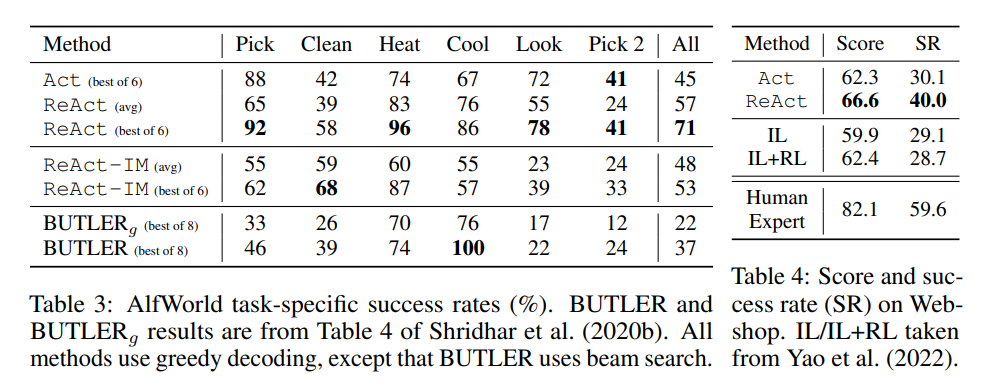
结果 ReAct在ALFWorld(表3)和Webshop(表4)上均优于Act。在ALFWorld上,最好的ReAct试验实现了 71%71\%71% 的平均成功率,显著优于最好的Act( 45%45\%45% )和BUTLER( 37%37\%37% )试验。事实上,即使最差的ReAct试验( 48%48\%48% )也优于两种方法的最佳试验。此外,ReAct相对于Act的优势在六个受控试验中保持一致,相对性能提升范围在 33%33\%33% 到 90%90\%90% ,平均为 62%62\%62% 。从定性角度来看,我们发现,没有任何思考,Act无法正确地将目标分解为更小的子目标,或者会丢失环境当前状态。ReAct和Act的比较示例轨迹可以在附录D.2.1和附录D.2.2中找到。
在Webshop上,单次行动提示已经与IL和 IL+RL\mathrm{IL + RL}IL+RL 方法表现相当。通过额外的稀疏推理,ReAct实现了显著更好的性能,相较于之前的最佳成功率提升了 10%10\%10% 。通过检查示例,我们发现ReAct更可能通过推理来识别与指令相关的产品和选项,以弥合噪声观察和行动之间的差距(例如:“对于‘节省空间的客厅长椅’,该商品有选项‘39x18x18英寸’和‘蓝色’,看起来很适合购买。”)。然而,现有方法仍远不及专家人类的性能(表4),后者进行了显著更多的产品探索和查询重写,而这些对于基于提示的方法仍然具有挑战性。
关于内部推理与外部反馈的价值 就我们所知,ReAct是首个在闭环系统中将大型语言模型(LLM)应用于交互式环境,以实现推理和行动结合的演示。或许最接近的前人工作是Huang等人(2022b)提出的Inner Monologue(IM),其中具身代理的行动是由同名的“内心独白”驱动的。然而,IM的“内心独白”仅限于对环境状态和代理为满足目标需要完成的任务的观察。相比之下,ReAct用于决策的推理轨迹是灵活且稀疏的,允许针对不同任务诱导多样化的推理类型(见第2节)。
为了展示ReAct和IM之间的差异,并强调内部推理与对外部反馈的简单反应的重要性,我们使用由IM类似密集外部反馈组成的思维模式运行了一个消融实验。如表3所示,ReAct大幅优于IM风格的提示(ReAct-IM)(总体成功率71 vs.53),在六项任务中的五项上具有持续优势。从定性角度来看,我们观察到ReAct-IM在识别子目标何时完成或下一个子目标应该是什么时经常出错,这是由于缺乏高层目标分解。此外,许多ReAct-IM轨迹难以确定在ALFWorld环境中一个物品可能的位置,这是由于缺乏常识推理。这两个缺点都可以在ReAct范式中得到解决。有关ReAct-IM的更多细节在附录B.2中。ReAct-IM的一个示例提示可以在附录C.4中找到,一个示例轨迹在附录D.2.3中。
5相关工作
用于推理的语言模型 也许使用LLM进行推理最著名的工作是思维链(CoT)(Wei等人,2022年),它揭示了LLM在为问题解决制定自己的“思维过程”方面的能力。此后,已经进行了几项后续工作,包括用于解决复杂任务的从最少到最多的提示(Zhou等人,2022年)、零样本CoT(Kojima等人,2022年)以及使用自洽性进行推理(Wang等人,2022a)。最近,(Madaan & Yazdanbakhsh,2022年)系统地研究了CoT的制定和结构,并观察到符号、模式和文本的存在对CoT的有效性至关重要。其他工作也已扩展到比简单提示更复杂的推理架构。例如,选择-推理(Creswell等人,2022年)将推理过程分为“选择”和“推理”两个步骤。STaR(Zelikman等人,2022年)通过在模型自身生成的正确推理上微调模型来启动推理过程。忠实推理(Creswell & Shanahan,2022年)将多步推理分解为三个步骤,分别由专门的LLM执行。类似的Scratchpad(Nye等人,2021年)方法,通过在中间计算步骤上微调LLM,也在多步计算问题上表现出改进。与这些方法相比,ReAct不仅仅是进行孤立的、固定的推理,而是将模型动作及其相应的观察结果整合为一个连贯的输入流,使模型能够更准确地推理并处理超出推理范围的任务(例如,交互式决策)。
用于决策的语言模型 LLMs强大的能力使其能够执行语言生成以外的任务,利用LLMs作为决策策略模型正变得越来越流行,特别是在交互环境中。WebGPT(Nakano等人,2021年)使用语言模型与网络浏览器交互,浏览网页,并从ELI5(Fan等人,2019年)中推断复杂问题的答案。与ReAct相比,WebGPT没有显式地建模思考和推理过程,而是依赖昂贵的反馈进行强化学习。在对话建模中,像BlenderBot(Shuster等人,2022b)和Sparrow(Glaese等人,2022)这样的聊天机器人和像SimpleTOD(Hosseini-Asl等人,2020年)这样的面向任务的对话系统也训练语言模型来决定API调用。与ReAct不同,它们也没有显式地考虑推理过程,并且也依赖昂贵的数集和人工反馈收集进行策略学习。相比之下,ReAct以更便宜的方式学习策略,因为决策过程只需要推理过程的语言描述。
LLMs也越来越多地应用于交互式和具身环境中进行规划和决策。在这方面与ReAct最相关的可能是SayCan(Ahn等人,2022)和Inner Monologue(Huang等人,2022b),它们使用LLMs进行机器人动作规划和决策。在SayCan中,LLMs被提示直接预测机器人可以采取的可能动作,然后由基于视觉环境的可供性模型重新排序以进行最终预测。Inner Monologue通过添加同名的“内心独白”进行了进一步改进,该“内心独白”作为来自环境的注入反馈实现。据我们所知,Inner Monologue是第一个展示此类闭环系统的作品,ReAct基于此构建。然而,我们认为Inner Monologue并不真正包含内心想法——这将在第4节中详细阐述。我们还注意到,在交互式决策过程中将语言作为语义丰富的输入已被证明在其他设置下是成功的(Abramson等人,2020;Karamcheti等人,2021;Huang等人,2022a;Li等人,2022)。随着LLMs的帮助,语言作为一种基本认知机制将在交互和决策中发挥关键作用。此外,LLMs的进展也启发了通用型智能体(如Reed等人,2022)的开发。
6结论
我们提出了ReAct——一种简单但有效的协同推理和行动的方法,用于大型语言模型。通过在多跳问答、事实核查和交互式决策任务上的一组多样化实验中,我们表明ReAct能够带来更优的性能和可解释的决策轨迹。尽管我们的方法很简单,但具有大动作空间的复杂任务需要更多的演示才能很好地学习,这不幸地很容易超出上下文学习的输入长度限制。我们探索了在HotpotQA上的微调方法
并取得了初步的积极结果,但从更多高质量的人工标注中学习将是进一步提高性能的愿望。通过多任务训练扩展ReAct,并将其与强化学习等互补范式相结合,可能会产生更强的智能体,从而进一步释放LLM在更多应用中的潜力。
致谢
我们感谢来自Google Brain团队和普林斯顿NLP小组许多人的支持和反馈。这项工作部分由美国国家科学基金会资助(项目编号2107048)。本材料中表达的所有意见、发现、结论或建议均属作者本人,不一定反映美国国家科学基金会的观点。
可复现性声明
我们的主要实验是在PaLM(Chowdhery等人,2022年)上完成的,该模型目前尚未公开。为了提高可复现性,我们已在附录C中包含所有使用的提示,在附录A.1中添加了使用GPT-3(Brown等人,2020年)进行的额外实验,并在https://anonymous.4open.science/r/ReAct-2268/处提供了相关的GPT-3 ReAct提示代码。
伦理声明
ReAct提示大型语言模型生成比先前方法更人类可解释、可诊断和可控的任务解决轨迹。然而,将大型语言模型与动作空间连接起来以与外部环境(例如网络、物理环境)交互存在潜在危险,例如查找不适当或私人信息,或在环境中采取有害行动。我们的实验通过将交互限制在特定网站(维基百科或WebShop)来最小化此类风险,这些网站不包含私人信息,且动作空间设计(即模型无法在WebShop研究基准上真正购买产品,或编辑维基百科)中没有任何危险行动。我们相信研究人员在进行更广泛的实验之前应意识到此类风险。
参考文献
Josh Abramson, Arun Ahuja, Iain Barr, Arthur Brussee, Federico Carnevale, Mary Cassin, Rachita Chhaparia, Stephen Clark, Bogdan Damoc, Andrew Dudzik, Petko Georgiev, Aurelia Guy, Tim Harley, Felix Hill, Alden Hung, Zachary Kenton, Jessica Landon, Timothy Lillicrap, Kory Mathewson, Soña Mokrá, Alistair Muldal, Adam Santoro, Nikolay Savinov, Vikrant Varma, Greg Wayne, Duncan Williams, Nathaniel Wong, Chen Yan, and Rui Zhu. Imitating interactive intelligence, 2020. URL https://arxiv.org/abs/2012.05672.
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, and Andy Zeng. Do as i can, not as i say: Grounding language in robotic affordances, 2022. URL https://arxiv.org/abs/2204.01691.
Ben Alderson-Day and Charles Fernyhough. Inner speech: development, cognitive functions, phenomenology, and neurobiology. Psychological bulletin, 141(5):931, 2015.
Alan Baddeley. Working memory. Science, 255(5044):556-559, 1992.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877-1901, 2020.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
Antonia Creswell and Murray Shanahan. Faithful reasoning using large language models, 2022. URL https://arxiv.org/abs/2208.14271.
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning, 2022. URL https://arxiv.org/abs/2205.09712.
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. ELI5: Long form question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3558-3567, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1346. URL https://aclanthology.org/P19-1346.
Charles Fernyhough. Vygotsky, luria, and the social brain. Self and social regulation: Social interaction and the development of social understanding and executive functions, pp. 56-79, 2010.
Amelia Glaese, Nat McAleese, Maja Trebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, Lucy Campbell-Gillingham, Jonathan Uesato, Po-Sen Huang, Ramona Comanescu, Fan Yang, Abigail See, Sumanth Dathathri, Rory Greig, Charlie Chen, Doug Fritz, Jaume Sanchez Elias, Richard Green, Soña Mokrá, Nicholas Fernando, Boxi Wu, Rachel Foley, Susannah Young, Jason Gabriel, William Isaac, John Mellor, Demis Hassabis, Koray Kavukcuoglu, Lisa Anne Hendricks, and Geoffrey Irving. Improving alignment of dialogue agents via targeted human judgements, 2022. URL https://storage.googleapis.com/deepmind-media/DeepMind.com/Authors-Notes/sparrow/sparrow-final.pdf.
Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. A simple language model for task-oriented dialogue. Advances in Neural Information Processing Systems, 33:20179–20191, 2020.
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint arXiv:2201.07207, 2022a.
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Thompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022b.
Siddharth Karamcheti, Megha Srivastava, Percy Liang, and Dorsa Sadigh. Lila: Language-informed latent actions. In CoRL, pp. 1379-1390, 2021. URL https://proceedings.mlr.press/v164/karamcheti22a.html.
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022.
Angeliki Lazaridou, Elena Gribovskaya, Wojciech Stokowiec, and Nikolai Grigorev. Internet-augmented language models through few-shot prompting for open-domain question answering. arXiv preprint arXiv:2203.05115, 2022.
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33: 9459-9474, 2020.
Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyurek, Anima Anandkumar, Jacob Andreas, Igor Mordatch, Antonio Torralba, and Yuke Zhu. Pre-trained language models for interactive decision-making, 2022. URL https://arxiv.org/abs/2202.01771.
Aleksandr Romanovich Luria. Ls vygotsky and the problem of localization of functions. Neuropsychologia, 3(4):387-392, 1965.
Aman Madaan and Amir Yazdanbakhsh. Text and patterns: For effective chain of thought, it takes two to tango, 2022. URL https://arxiv.org/abs/2209.07686.
Vincent Micheli and François Fleuret. Language models are few-shot butlers. arXiv preprint arXiv:2104.07972, 2021.
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2021. URL https://arxiv.org/abs/2112.09332.
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models, 2021. URL https://arxiv.org/abs/2112.00114.
Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas. A generalist agent, 2022. URL https://arxiv.org/abs/2205.06175.
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10740-10749, 2020a.
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768, 2020b.
Kurt Shuster, Mojtaba Komeili, Leonard Adolphs, Stephen Roller, Arthur Szlam, and Jason Weston. Language models that seek for knowledge: Modular search & generation for dialogue and prompt completion. arXiv preprint arXiv:2203.13224, 2022a.
Kurt Shuster, Jing Xu, Mojtaba Komeili, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal Arora, Joshua Lane, Morteza Behrooz, William Ngan, Spencer Poff, Naman Goyal, Arthur Szlam, Y-Lan Boureau, Melanie Kambadur, and Jason Weston. Blenderbot 3: a deployed conversational agent that continually learns to responsibly engage, 2022b. URL https://arxiv.org/abs/2208.03188.
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification. arXiv preprint arXiv:1803.05355, 2018.
Lev S Vygotsky. Thinking and speech. The collected works of LS Vygotsky, 1:39-285, 1987.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2022a. URL https://arxiv.org/abs/2203.11171.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Rationale-augmented ensembles in language models. arXiv preprint arXiv:2207.00747, 2022b.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
Shunyu Yao, Rohan Rao, Matthew Hausknecht, and Karthik Narasimhan. Keep CALM and explore: Language models for action generation in text-based games. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 8736-8754, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.704. URL https://aclanthology.org/2020.emnlp-main.704.
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. arXiv preprint arXiv:2207.01206, 2022.
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. Star: Bootstrapping reasoning with reasoning, 2022. URL https://arxiv.org/abs/2203.14465.
Denny Zhou, Nathanael Scharli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models, 2022. URL https://arxiv.org/abs/2205.10625.
Yunchang Zhu, Liang Pang, Yanyan Lan, Huawei Shen, and Xueqi Cheng. Adaptive information seeking for open-domain question answering. arXiv preprint arXiv:2109.06747, 2021.
A ADDITIONAL RESULTS
A.1 GPT-3 EXPERIMENTS
| PaLM-540B | GPT-3 | |
| HotpotQA (exact match) | 29.4 | 30.8 |
| ALFWorld (成功率%) | 70.9 | 78.4 |
表5:使用PaLM-540B与GPT-3(text-davinci-002,贪婪解码)的ReAct提示结果。在HotpotQA上,我们随机采样500个验证问题子集。在ALFWorld上,我们使用全部134个未见过的验证任务实例,并使用根据PaLM-540B的最佳提示集。
我们运行额外的GPT-3(Brown等人,2020)实验,以确认ReAct提示性能在不同的大型语言模型上具有普遍性。如表5所示,GPT-3(text-davinci-002,贪婪解码)在HotpotQA和ALFWorld上始终优于PaLM-540B,可能因为它经过人类指令跟随的微调。这表明ReAct提示在不同的大型语言模型和不同任务上都是有效的。这些实验的代码位于https://react-lm.github.io/。
A.2 ReAct在HotpotQA上获取最新知识

图4:另一个HotpotQA问题,其中原始标签已过时。只有ReAct能够通过现实世界的网络交互加上推理获得最新的答案。
在轨迹检查过程中,我们还发现有时ReAct与数据集标签不一致,因为标签本身可能已过时。例如,如图4所示,问题询问ahotel的大小,该大小自HotpotQA构建时间以来已增加。虽然Standard和CoT由于幻觉给出错误答案,Act尽管访问了现实世界的网络交互,但由于缺乏推理来指导如何通过互联网进行问答,仍然失败。只有ReAct能够从互联网检索最新信息并提供合理的答案。因此,更好地结合推理能力可能有助于近期互联网增强的语言模型(Nakano等人,2021;Lazaridou等人,2022;Shuster等人,2022a)进行最新的任务解决。
A.3 人类参与循环行为校正 ONALFWORLD
我们还探索了人类与ReAct的人机交互,以允许人类检查和编辑ReAct的推理轨迹。图5显示,只需在Act17中删除一句幻觉句子,并在Act23中添加一些提示,ReAct就可以大幅改变其行为以符合这些人类思维编辑并成功完成任务。从人类的角度来看,解决此类任务变得明显更容易,从输入几十个动作到只需编辑几个想法,这促进了新型人机协作。我们注意到,这种实时策略编辑对Act和之前的强化学习方法来说很困难,因为人类无法更改模型参数,而更改几个动作可能无法编辑模型的其他行为。这种范式也不仅仅是像Huang等人(2022b)中那样通过人类对话来更新目标或子目标——虽然编辑ReAct思维可以做到这些,但它还可以修改模型的内部信念、推理风格或灵活思维空间支持的其他任何内容,以更好地解决任务。我们相信这是人类对齐的一个令人兴奋的方向,并将更多的系统研究留作未来的工作。

图5:ReAct在AlfWorld中的人机交互行为校正示例。(a)由于产生幻觉的思考(行为17),ReAct轨迹失败。(b)通过人类简单编辑两个思考(行为17、23),ReAct轨迹产生理想的推理轨迹和动作并成功。
这种策略编辑对 Act 和之前的强化学习方法来说很困难,因为人类无法更改模型参数,而更改几个动作可能无法编辑模型的其他行为。这种范式也不仅仅是像 Huang 等人 (2022b) 中那样通过人类对话来更新目标或子目标——虽然编辑 ReAct 思维可以做到这些,但它还可以修改模型的内部信念、推理风格或灵活思维空间支持的其他任何内容,以更好地解决任务。我们相信这是人类对齐的一个令人兴奋的方向,并将更多的系统研究留作未来的工作。
B实验细节
B.1 HOTPOTQA微调细节
对于所有微调,我们使用批大小为64。在PaLM-8B上,我们微调ReAct和Act方法4,000步,微调Standard和CoT方法2,000步。在PaLM-62B上,我们微调ReAct和Act方法4,000步,微调Standard和CoT方法1,000步。我们发现ReAct和Act方法通常受益于更多训练步(和更多训练数据),而Standard和CoT方法在微调后很快就会退化。
B.2 ALFWORLD IM-风格细节
对于IM风格的消融实验,ReAct中使用的相同专家轨迹在这些轨迹内部重新标注了密集的外部反馈思维,这些思维限制了ReAct-IM只能思考(1)分解当前目标以及(2)需要完成的当前子目标。具体来说,ReAct-IM缺乏(1)确定子目标何时完成的思维(2)确定下一个子目标应该是什么的思维(3)引导LLM参考其内部预训练知识以识别物品在环境中的位置的思维。
C提示
C.1 HOTPOTQA
Hotpot QA 提示
下一页继续
| 原始 问题 Answer | 该区域东部扇区的海拔范围是多少? Colorado orogeny extends into? 1,800 to 7,000 ft |
| Question | 音乐家和讽刺作家Allie Goertz写了一首关于《辛普森一家》的歌 角色米霍尔斯,马特·格勒宁以谁的名字命名? |
| 答案 | 理查德·尼克松 |
| 问题 | 哪部纪录片是关于芬兰摇滚乐队的,亚当·克莱顿·鲍威尔或《 Saimaa Gesture? The Saimaa Gesture |
| 答案 | 尼古拉斯·雷和伊利亚·卡赞有什么共同的职业? |
| 问题 答案 | 导演,编剧,演员 |
| 问题 回答 | 《Arthur's Magazine》还是《First for Women》哪本杂志创办得最早? 亚瑟杂志 |
| 问题 回答 | Pavel Urysohn 和 Leonid Levin 以相同类型的工作而闻名吗? |
| Yes | |
| 问题 观察1 | 该地区的东部区域,科罗拉多造山运动延伸至的范围是多少? Search[Colorado orogeny] 科罗拉多造山运动是科罗拉多州及周边地区的一次山脉建造(造山运动)事件。 |
| 行动2 观测2 | 查找[东部区域] (结果1/1)东部区域延伸至高平原,被称为中央平原造山带。 |
| 操作3 | 搜索[高平原] |
| 观测3 | High Plains指的是两个不同的陆地区域之一: |
| 行动4 | 搜索[High Plains(美国)] |
| 观察4 | High Plains是大平原的一个子区域。从东到西, 高原平原海拔从约1,800到7,000英尺(550到2,130米)。[3] |
| 行动5 | 完成[1,800到7,000英尺] |
| 问题 | 音乐家和讽刺作家Allie Goertz写了一首歌关于"辛普森一家" character Milhouse, who Matt Groening named after who? |
| 行动1 | 搜索[米尔豪斯] 米尔豪斯·墨索里尼·范·霍顿是福克斯动画电视系列《辛普森一家》中的一个 recurring角色,由 Pamela Hayden 配音,由 Matt Groening 创造。 |
| 行动2 | 查找[以]命名 (结果1/1)Milhouse 是根据美国总统理查德·尼克松命名的,他的中间名是Milhous。 |
| 动作3 | 完成[理查德·尼克松] |
| 问题 | 哪部纪录片是关于芬兰摇滚乐队、亚当·克莱顿·鲍威尔或The Saimaa Gesture? Adam Clayton Powell ] |
| 动作1 | 找到[Adam Clayton Powell]。相似: [' Adam Clayton Powell III', '第七大道(曼哈顿) ', ' A Building', ' Isabel Washington Powell', ' Adam Powell', ' Adam Clayton Powell (电影)] |
| 动作2 | 搜索[Adam Clayton Powell (电影)] |
| 观察2 | Adam Clayton Powell 是一部1989年美国纪录片,由 Richard Kilberg 执导。这部电影讲述了有影响力人物的崛起和衰落。 非裔美国政治家亚当·克莱顿·鲍威尔小。[3] [4] 它后来作为PBS系列《美国经验》的一部分播出。 |
| 行动3 | 完成[萨伊马手势] |
| 问题 行动1 | 尼古拉斯·雷和伊利亚·卡赞有什么共同的职业? |
| 观察1 | 搜索[Nicholas Ray] |
| Nicholas Ray (出生于Raymond Nicholas Kienzle Jr., 1911年8月7日-1979年6月16日)是一位美国电影导演、编剧和演员,以其 the 1955 film Rebel Without a Cause. | |
| 行动2 观察2 | Search[Elia Kazan] Elia Kazan was an American film and theatre director, producer, screenwriter and actor. |
| 火锅问答提示——接续上一页 | |
| 行动3 | 完成[导演、编剧、演员] |
| 问题 | 哪本杂志创办得最早?《亚瑟杂志》还是《为女性第一》? |
| 操作1 | 搜索[亚瑟杂志] |
| 观察1 | 亚瑟杂志(1844-1846)是一份19世纪在美国费城出版的文学期刊。 |
| 操作2 | 搜索[妇女第一] |
| 观察2 | 《First for Women》是一本由美国Bauer Media Group出版的女性杂志.[1]该杂志始于1989年。 |
| 行动3 | 完成[Arthur's Magazine] |
| 问题 | Pavel Urysohn和Leonid Levin是否以相同类型的工作而闻名? |
| 操作1 | 搜索[Pavel Urysohn] |
| 观察1 | Pavel Samuilovich Urysohn(2月3日,1898年-8月17日,1924年)是一位苏联数学家,以其在维数理论方面的贡献而闻名。 |
| 操作2 | 搜索[Leonid Levin] |
| 观测2 | Leonid Anatolievich Levin是一位苏联裔美国数学家和计算机科学家。 |
| 操作3 | 完成[是] |
| so1 | |
| 问题 | 科罗拉多 oro 东部区域的海拔范围是多少? |
| 思考 | geny 延伸到? |
| 解答 | 让我们一步一步思考。科罗拉多山脉的东部延伸到高平原。高平原的海拔从大约1,800英尺到7,000英尺,所以答案是1,800英尺到7,000英尺。 |
| 问题 | 音乐家和讽刺作家Allie Goertz写了一首歌关于《辛普森一家》角色米尔豪斯,马特·格勒宁给这个角色命名是为了谁? |
| 思考 | 让我们一步一步思考。米尔豪斯是为了美国总统理查德·尼克松命名的,所以答案是理查德·尼克松。 |
| 解答 | 理查德·尼克松 |
| 问题 | 哪部纪录片是关于芬兰摇滚乐队的,亚当·克莱顿·鲍威尔还是《The》? |
| 想法 | Saimaa手势? |
| 回答 | 让我们一步步思考。亚当·克莱顿·鲍威尔(电影)是一部关于非裔美国政治家的纪录片,而不是芬兰摇滚乐队。因此,关于芬兰摇滚乐队的纪录片必须是《萨伊马手势》。 |
| 问题 | 萨伊马手势 |
| 思考 | 尼古拉斯·雷和伊利亚·卡赞有什么共同的职业? |
| 解答 | 让我们一步步思考。尼古拉斯·雷的职业是导演、编剧和演员。伊利亚·卡赞的职业是导演、制片人、编剧和演员。所以尼古拉斯·雷和伊利亚·卡赞有共同的职业是导演、编剧和演员。 |
| 问题 | 导演、编剧和演员 |
| 思考 | 导演,编剧,演员 |
| 解答 | 哪本杂志创办得最早?《亚瑟杂志》还是《首先为女性》? |
| 行动1 | 让我们一步步思考。亚瑟杂志创办于1844年。《首先为女性》创办于1989年。1844年(《亚瑟杂志》)<19891989年(《首先为女性》),所以《亚瑟杂志》创办得最早。 |
| 解答 | Arthur's Magazine |
| 问题 | Pavel Urysohn和Leonid Levin是否以相同类型的工作而闻名? |
| 思考 | 让我们一步一步地思考。Pavel Urysohn是一名数学家。Leonid Levin是一名数学家和计算机科学家。因此,Pavel Urysohn和Leonid Levin从事相同类型的工作。 |
| 解答 | Yes |
| ReAct | |
| 问题 | 该区域东部扇区的海拔范围是多少? |
| 思考1 | 科罗拉多造山运动延伸至? |
| 行动1 | 我需要搜索科罗拉多造山运动,找到东部区域的范围of the Colorado orogeny extends into,then find the elevation range of the area. |
| 行动1 | Search[Colorado orogeny] |
| 观察1 | The Colorado orogeny was an episode of mountain building (an orogeny) in科罗拉多和周边g地区. |
| 想法2 | 它没有提到东部地区。所以我们需要查找东部区域。 |
| 操作2 | 查找[东部区域] |
| 观测2 | (结果1/1)东部区域延伸至高平原,被称为中央平原造山带 |
| 思想3 | 科罗拉多造山运动的东西部延伸至 需要搜索高平原并找到其海拔范围。 |
| 行动3 | 搜索[高原] |
| 观察3 | 高平原指的是两个不同的陆地区域之一 |
| 思考4 | 我需要改为搜索高平原(美国)。 |
| 行动4 | 搜索[高原(美国)] |
继续下一页
火锅问答提示——接续上一页
继续下一页
| 观察4 | 高平原是大平原的一个子区域。 从东到西, 高平原的海拔从大约1,800英尺到7,000英尺(550米到2,130米)上升。[3] |
| 思想5 | 高平原海拔从大约1,800到7,000英尺上升,所以答案 是1,800到7,000英尺。 |
| 行动5 | 完成[1,800到7,000英尺] |
| 问题 | Musician and satirist Allie Goertz wrote a song about the "The Simpsons" character Milhouse, who Matt Groening named after who? 这个问题简化为“辛普森一家”角色米洛斯的名字来源于 who. 我只需要搜索米洛斯,并找到它的名字来源于谁。 |
| 思考1 | 搜索[米洛斯]Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening. |
| 行动1 | The paragraph does not tell who Milhouse is named after, maybe I can look up "named after". |
| 思考2 | 查找[以]命名 (结果1/1) Milhouse以美国总统理查德·尼克松命名,其中间名为Milhous。 |
| 行动2 | Milhouse是以美国总统理查德·尼克松的名字命名的,所以答案是 理查德·尼克松。 完成[理查德·尼克松] |
| 思考3 | Which documentary is about Finnish rock groups, Adam Clayton Powell or The Saimaa手势? |
| 思考1 | I need to search Adam Clayton Powell and The Saimaa Gesture, and find which 纪录片是关于芬兰摇滚乐队的 . |
| 行动1 | 搜索[亚当·克莱顿·鲍威尔] |
| 观察1 | 找不到[亚当·克莱顿·鲍威尔] 类似: [‘亚当·克莱顿·鲍威尔’ 三世', ‘第七大道(曼哈顿)’, ‘亚当·克莱顿·鲍威尔小’ 州办公室 建筑', ‘伊莎贝尔·华盛顿·鲍威尔’, ‘亚当·鲍威尔’, 亚当·克莱顿·鲍威尔 (电影), ‘吉安卡洛·埃斯波西托’]. |
| 思考2 | 要找到纪录片,我可以搜索 Adam Clayton Powell (电影)。 |
| 行动2 | 搜索[Adam Clayton Powell (电影)] |
| 观察2 | Adam Clayton'Powell is a 1989 American documentary film directed by Richard Kilber g. 这部电影讲述了有影响力人物的兴衰 African-American politician Adam Clayton Powell Jr.[3][4] It was later aired as part of the PBS series The American Experience. |
| 思想3 | Adam Clayton Powell (film) is a documentary about an African-American politician, not Finnish rock groups. So the documentary about Finnish rock 群体必须改为萨伊马手势 . |
| 行动3 | 完成[萨伊马手势] |
| 问题 想法1 | 尼古拉斯·雷和伊利亚·卡赞有什么共同的职业? 我需要搜索尼古拉斯·雷和伊利亚·卡赞,找到他们的职业,然后 找到他们共同的职业 . |
| 操作1 | 搜索[尼古拉斯·雷] |
| 观察1 | 尼古拉斯·雷(本名雷蒙德·尼古拉斯·凯恩斯勒,1911年8月7日-1979年6月16日)是一位美国电影导演、 编剧和演员,以1955年的电影《无因的反抗》闻名。 |
| 思考2 | 尼古拉斯·雷的职业是导演、编剧和演员。我需要接下来搜索伊利亚·卡赞,并找到他的职业。 |
| 行动2 | 搜索[伊利亚·卡赞] |
| 观察2 | Elia Kazan was an American film and theatre director, producer, screenwriter 和演员 . |
| 思考3 | 伊利亚·卡赞的职业是导演、制片人、编剧和演员。所以尼古拉斯·雷和伊利亚·卡赞的共同职业是导演、 编剧和演员。 |
| 行动3 | 完成[导演、编剧、演员] |
| 问题 思考1 | 《亚瑟杂志》和《第一夫人》哪本杂志创办时间更早? 我需要搜索《亚瑟杂志》和《第一夫人》,并找出哪本杂志 创办时间更早 . |
| 行动1 | 搜索[亚瑟杂志] |
| 观察1 | 亚瑟杂志(1844-1846)是美国19世纪在费城出版的一种文学期刊。 |
| 思考2 | 亚瑟杂志于1844年创办。 我需要先搜索《妇女》 下个。 |
| 操作2 | 搜索[首先为女性] |
| 观察2 | 首先为女性是一本由Bauer Media Group出版的女性杂志,在 USA.[1该杂志始刊1989年 |
| 思考3 | First for Women was started in 1989. 1844(《亚瑟杂志》)<1989(第一 为女性),所以《亚瑟杂志》是首先创办的。 |
| 行动3 | 完成[《亚瑟杂志》] |
| 问题 思考1 | Were Pavel Urysohn and Leonid Levin known for the same type of work? I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same. |
| 行动1 | Search[Pavel Urysohn] |
火锅问答提示——接续上一页
| Observation 1 | Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory. |
| 思考2 | Pavel Urysohn是一位数学家,寻找其工作类型。I need to search Leonid Levin next and |
| 行动2 | 搜索Leonid Levin ] |
| 观察2 | Leonid Anatolievich Levin is a Soviet-American mathematician and computer |
| 思考3 | 科学家:Leonid Paine是Ury位数学家和动量机科学家有相同的工作 . |
| 操作3 | 完成[是]YP领域。 |
C.2 FEVER
| FEVER提示 | |
| 原始 | 确定是否存在支持或反驳声明的观察结果,或者是否存在信息不足。 |
| 声明回答 | Nikolaj Coster-Waldau 与二十世纪福克斯广播公司合作。支持 |
| 声明回答 | 《怪奇物语》设定在印第安纳州的布卢明顿。反驳 |
| 主张答案 | Beautiful 在2003年达到了Billboard Hot 100的亚军。信息不足 |
| yes | 确定是否存在支持或反驳主张的观察信息不足。 , 或者如果 |
| 声明Action2观察1 | Nikolaj Coster-Waldau 与 Fox Broadcasting Company 合作。搜索 [Nikolaj Coster-Waldau] 尼科尔·威廉·科斯特·沃尔道(1970年7月27日出生)是一位丹麦演员和制片人。他于1993,[1]毕业于哥本哈根的丹麦国立表演艺术学院,并在丹麦凭借电影《夜班守卫》(1994年)获得突破性角色。他在HBO奇幻剧《权力的游戏》中饰演杰迈玛·兰尼斯特,并因此获得两项剧情类最佳男配角艾美奖提名。科斯特·沃尔道在他家乡丹麦和斯堪的纳维亚半岛参演了多部电影,包括《猎头者》(2011年)和《晚安千次》(2013年)。在美国,他的首部电影角色是在战争电影《黑鹰坠落》(2001年)中饰演获得荣誉勋章的加里·戈登.[2]随后,他在短命的福克斯电视系列《新阿姆斯特丹》(2008年)中饰演一名侦探,并在2009年福克斯电视电影《虚拟性》(原计划作为试播集)中出演。 |
| 操作2 | 完成[支持] |
| 申领操作1观察1 | 《怪奇物语》设定在印第安纳州的布卢明顿。搜索 [怪奇物语]《怪奇物语》是一部由达弗兄弟创作的美国科幻恐怖剧情类电视剧。故事设定在20世纪80年代,主要发生在印第安纳州霍金斯这个虚构小镇,剧集围绕小镇发生的一系列谜团和超自然事件,以及这些事件对一群儿童和成人角色的影响展开。 |
| 行动2 | 完成[反驳] |
| 主张操作1观察1 | Beautiful在2003年登上了公告牌百强单曲榜的亚军位置。搜索 [美丽的]找不到《美丽的》。相似:「美丽的', '美丽的,美丽的', '一个美丽的头脑(电影)', '美丽的(克里斯蒂娜·阿奎莱拉的歌曲)', '生活是美丽的'。 |
| 行动2观察2 | 搜索 [美丽的](克里斯蒂娜·阿奎莱拉的歌曲)"美丽的"是美国歌手克里斯蒂娜·阿奎莱拉为她第四张录音室专辑录制的歌曲, |
| Action 3 Observation 3 | 查找[公告牌100热门](Result 1/3)这首歌曲在美国的Billboard Hot 100排行榜上达到了第二名,并获得了50万张唱片的黄金认证。 |
| Action 4 | 完成[信息不足] |
| 确定是否存在支持或反驳声明的观察没有足够的信息。 , 或如果 | |
| 声明思考 | Nikolaj Coster-Waldau 与 Fox Broadcasting Company 合作。尼可拉斯·威廉·科斯特·瓦尔道出现在2009年福克斯电视台的电影《虚拟性》,因此他与福克斯广播公司合作过。 |
| 答案 | SUPPORTS |
| 主张思考 | 《怪奇物语》设定在印第安纳州的布卢明顿。《怪奇物语》设定在印第安纳州的霍金斯市,而不是布卢明顿市。 |
| 答案 | 反驳 |
继续见下一页
| 发烧提示——继续自前一页 | |
| 主张思考 | Beautiful在2003年登上了Billboard Hot 100排行榜第二名。这首歌在美国Billboard Hot 100排行榜上达到了第二名,但不确定是否在2003年。 |
| 回答 | 信息不足 |
| ReAct | 确定是否存在支持或反驳声明的观察,或者是否存在信息不足。 |
| 声明想法1 | Nikolaj Coster-Waldau与Fox Broadcasting Company合作。我需要搜索Nikolaj Coster-Waldau并查看他是否与Fox Broadcasting Company合作。 |
| 操作1观察1 | 搜索[Nikolaj Coster-Waldau]尼科瓦·威廉·科斯特-沃尔道(1970年7月27日出生)是一位丹麦演员和制片人。他于1993,[1]毕业于哥本哈根的丹麦国立表演艺术学院,并在丹麦的电影《夜班守卫》(1994年)中获得了突破性角色。他在HBO奇幻剧《权力的游戏》中扮演杰迈玛·兰尼斯特,并因此获得了两次剧情类最佳男配角提名。 |
| 科斯特-沃尔道在他家乡丹麦和斯堪的纳维亚半岛出演了多部电影,包括《猎头者》(2011年)和《晚安千次》(2013年)。在美国,他的首部电影角色是在战争电影《黑鹰坠落》(2001年)中扮演获得荣誉勋章的加里·戈登。[2]随后,他在短命的福克斯电视系列《新阿姆斯特丹》(2008年)中扮演一名侦探,并在2009年福克斯电视电影《虚拟性》(最初打算作为试播集)中出演。 | |
| 思考2 | 因为他“出现在2009年福克斯电视台的电影《虚拟性》中”,所以他应该与福克斯广播公司合作。 |
| 行动2 | 完成[支持] |
| 主张想法1 | 《怪奇物语》设定在印第安纳州的布卢明顿。我应该搜索《怪奇物语》,看看它是否设定在印第安纳州的布卢明顿。 |
| 行动1观察1 | 搜索[《怪奇物语》]《怪奇物语》是一部由达弗兄弟创作的美国科幻恐怖剧情电视剧。设定在20世纪80年代,主要发生在印第安纳州虚构的霍金斯镇,该剧围绕镇上发生的一系列谜团和超自然事件及其对一群儿童和成人角色的影响展开。 |
| 思考2 | 观察表明它设定在一个“印第安纳州霍金斯虚构小镇”,因此它不在布卢明顿。 |
| 行动2 | 完成[反驳] |
| 主张想法1 | Beautiful在2003年登上了Billboard Hot 100排行榜第二名。我需要搜索歌曲《Beautiful》并查看它在2003年是否达到了Billboard Hot 100的亚军位置。 |
| 行动1观察1 | 搜索[Beautiful]未找到[Beautiful],相似:‘美丽’,‘美丽,美丽’,美丽心灵(电影),‘美丽(克里斯蒂娜·阿奎莱拉歌曲)’,生活是美丽'。从建议中,我应该搜索“美丽(克里斯蒂娜·阿奎莱拉歌曲)”来找到这首歌。 |
| 思考2 | 搜索[美丽(克里斯蒂娜·阿奎莱拉的歌曲)]”美丽"是由美国歌手克里斯蒂娜·阿奎莱拉为她第四张录音室专辑《Stripped》(2002年)录制的歌曲。 |
| 操作2观察2 | 它没有提到《公告牌》,所以我需要查找《公告牌百强单曲榜》以确定它在2003年是否达到了第2名。 |
| 思考3 | 它只说这首歌在公告牌热门100排名第二,但没有说明是否在2003年。我不确定这个说法是否正确。 |
| 操作3观察3 | 查找[公告牌热门100](结果1/3)这首歌在美国公告牌热门100排名第二,并获得了500,000份的黄金认证。 |
| 思考4 | 它只说这首歌在公告牌热门100排名第二,但没有说明是否在2003年。我不确定这个说法是否正确。 |
| 操作4 | 完成[信息不足] |
C.3 WEBSHOP
表6:第4节中Webshop实验使用的提示。我们使用左侧的提示用于Act,并使用右侧的提示(添加推理)用于ReAct。
| 指令:我想要一瓶3盎司的亮柑橘除臭剂,适用于敏感肌肤,价格低于50.00美元 | |
| Act | ReAct |
| Action: search[3 ounce bright citrus deodorant sensitive skin] Observation: [Back to Search] Page 1 (Total results: 50) [Next] | Action: search[3 ounce bright citrus deodorant sensitive skin] Observation: [Back to Search] Page 1 (Total results: 50) [Next] |
| [B078GWRCIJ] 亮柑橘除臭剂 Earth Mama | 天然且安全,适用于敏感肌肤、孕妇和哺乳期,含有有机金盏花3盎司$10.99 | [B078GWRCIJ] 地球妈妈亮柑橘除臭剂 | 天然且安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花3盎司$10.99 |
| [B078GTKVXY] 地球妈妈姜味止汗剂 | 天然且安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花,3盎司$10.99 | [B078GTKVXY] Ginger Fresh Deodorant by Earth Mama | 天然且安全,适用于敏感肌肤、孕妇和哺乳期,含有有机金盏花3盎司$10.99 |
| [B08KBVJ4XN] Barrel and Oak - 无铝止汗剂,男士止汗剂,精油香型,24小时除臭保护,雪松与广藿香混合香型,温和不刺激敏感肌肤(山地鼠尾草,2.7盎司,2件装)$15.95 | [B08KBVJ4XN] Barrel and Oak -无铝制止汗剂,男士止汗剂,精油香型,24小时除臭,雪松与广藿香混合,温和不刺激肌肤(山地鼠尾草,2.7盎司,2件装)$15.95 |
| 操作:点击[B078GWRCIJ] 观察: [返回搜索] [上一个] 香味[各种香味][明亮的柑橘][舒缓的薰衣草][姜[新鲜的]纯粹的香味] 尺寸[旅行套装(4件装)][3盎司(1包)][3-盎司(2-件装)] 地球妈妈亮柑橘除臭剂 | 天然且安全,适合敏感肌肤、孕妇和哺乳期,含有有机金盏花3盎司价格:$10.99 评分:N.A. [Description] [Features] [Reviews] [Buy Now] | 操作:思考[B078GWRCIJ]和B078GTKVXY是明亮的柑橘止汗剂不到50美元。我可以先检查B078GWRCIJ。观察:OK。 Action: click[B078GWRCIJ] Observation: [返回搜索] [上一页] 香味[各种香味][明亮的柑橘味][舒缓的薰衣草味][姜味[新鲜的]纯粹的香味]尺寸[旅行套装(4件装)][3盎司(1件装)][3-盎司(2-件装)] EarthMama 亮柑橘除臭剂|天然且安全,适用于敏感肌肤、孕妇和哺乳期,含有有机金盏花3盎司价格:$10.99。 Rating: N A [Description] [Features] [Reviews] [Buy Now] 行动:思考[对于3盎司亮柑橘除臭剂(适用于敏感肌肤),该商品有选项“亮柑橘”和“3盎司(1包)”看起来适合购买。]观察:OK。 Action: click[bright citrus] Observation: You have clicked bright citrus. Action: click[3 ounce (pack of 1)] Observation: You have clicked 3 ounce (pack of 1). 操作:点击[立即购买] |
C.4 ALFWORLD
表7:在ALFWorld干净任务上的一个Act提示。没有提供思考。
You are in the middle of a room. Looking quickly around you, you see a cabinet 13, a cabinet 12, a cabinet 11, a cabinet 10, a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 1, a diningtable 1, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean lettuce in din ingtable.
> go to fridge 1
The fridge 1 is closed.
> open fridge 1
You open the fridge 1. The fridge 1 is open. In it, you see a cup 3, a egg 2, a potato 3, and a potato 2.
> go to din ingtable 1
On the din ingtable 1, you see a apple 1, a bread 1, a butterk knife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a lettuce 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1.
> take lettuce 1 from din ingtable 1
You pick up the lettuce 1 from the din ingtable 1.
> go to sinkbasin 1
On the sinkbasin 1, you see a apple 2, a ladle 2, a spoon 1, and a tomato 3.
> clean lettuce 1 with sinkbasin 1
You clean the lettuce 1 using the sinkbasin 1.
> think: Now I clean a lettuce (1). Next, I need to put it in/on din ingtable 1. OK.
> go to din ingtable 1
On the din ingtable 1, you see a apple 1, a bread 1, a butterk knife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1.
> put lettuce 1 in/on din ingtable 1
You put the lettuce 1 in/on the din ingtable 1.
表8:在ALFWorld干净任务上的一个ReAct提示
You are in the middle of a room. Looking quickly around you, you see a cabinet 13, a cabinet 12, a cabinet 11, a cabinet 10, a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 1, a diningtable 1, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean lettuce in diningtable. > think: To solve the task, I need to find and take a lettuce, then clean it with sinkbasin, then put it in diningtable. OK. > think: First I need to find a lettuce. A lettuce is more likely to appear in fridge (1), diningtable (1), sinkbasin (1), stoveburner (1-3), cabinet (1-13). I can check one by one, starting with fridge 1. OK. > go to fridge 1 The fridge 1 is closed. > open fridge 1 You open the fridge 1. The fridge 1 is open. In it, you see a cup 3, a egg 2, a potato 3, and a potato 2. > go to diningtable 1 On the diningtable 1, you see a apple 1, a bread 1, a butterknife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a lettuce 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1. > think: Now I find a lettuce (1). Next, I need to take it. OK. > take lettuce 1 from diningtable 1 You pick up the lettuce 1 from the diningtable 1. > think: Now I take a lettuce (1). Next, I need to go to sinkbasin (1) and clean it. OK. > go to sinkbasin 1 On the sinkbasin 1, you see a apple 2, a ladle 2, a spoon 1, and a tomato 3. > clean lettuce 1 with sinkbasin 1 You clean the lettuce 1 using the sinkbasin 1. > think: Now I clean a lettuce (1). Next, I need to put it in/on diningtable 1. OK. > go to diningtable 1 On the diningtable 1, you see a apple 1, a bread 1, a butterknife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1. > put lettuce 1 in/on diningtable 1 You put the lettuce 1 in/on the diningtable 1.
表 9: ALFWorld 清洁任务上的一个 ReAct-IM 提示。
You are in the middle of a room. Looking quickly around you, you see a cabinet 13, a cabinet 12, a cabinet 11, a cabinet 10, a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 1, a diningtable 1, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean lettuce in din ingtable. > think: To solve the task, I need to find and take a lettuce, then clean it with sinkbasin, then put it in din ingtable. OK. > think: First I need to find a lettuce. OK. > go to fridge 1 The fridge 1 is closed. > think: First I need to find a lettuce. OK. > open fridge 1 You open the fridge 1. The fridge 1 is open. In it, you see a cup 3, a egg 2, a potato 3, and a potato 2. > think: First I need to find a lettuce. OK. > go to din ingtable 1 On the din ingtable 1, you see a apple 1, a bread 1, a butterknife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a lettuce 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1. > think: First I need to find a lettuce. OK. > take lettuce 1 from din ingtable 1 You pick up the lettuce 1 from the din ingtable 1. > think: I need to clean this lettuce (1) using sinkbasin 1. OK. > go to sinkbasin 1 On the sinkbasin 1, you see a apple 2, a ladle 2, a spoon 1, and a tomato 3. > think: I need to clean this lettuce (1) using sinkbasin 1. OK. > clean lettuce 1 with sinkbasin 1 You clean the lettuce 1 using the sinkbasin 1. > think: I need to put this cleaned lettuce (1) in/on din ingtable 1. OK. > go to din ingtable 1 On the din ingtable 1, you see a apple 1, a bread 1, a butterknife 2, a cup 2, a fork 2, a knife 2, a knife 1, a ladle 1, a mug 2, a mug 1, a pan 2, a peppershaker 1, a spatula 3, a tomato 2, and a tomato 1. > think: I need to put this cleaned lettuce (1) in/on din ingtable 1. OK. > put lettuce 1 in/on din ingtable 1 You put the lettuce 1 in/on the din ingtable 1.
D轨迹
D.1 FEVER 轨迹
我们提供了一些轨迹,这些轨迹由ReAct、CoT和Act在FEVER开发集的几个随机选择的示例中产生。搜索结果被省略以节省空间。
| Example 2491 ( gt: REFUTES) | |
| ReAct | |
| 主张: | 百慕大三角是太平洋上一个定义较为松散的区域。 |
| 想法1: | 我需要搜索百慕大三角洲,并确认它是否位于太平洋。 |
| 行动1: | 搜索[百慕大三角洲] |
| 观察1: | 据报道是闹鬼的地点…… |
| 思考2: | 观测表明它位于北大西洋的西部,因此它不在太平洋。 |
| 行动2: | 完成[反驳] |
| 观测2: | 剧集结束 |
| Act | |
| 声明: | 百慕大三角是太平洋上一个定义模糊的区域。 |
| 行动1: | :搜索[百慕大三角] |
| 观察1: | :据报道闹鬼的地点:… |
| 操作2: | 完成[反驳] |
| 观察2: | 剧集结束 |
| CoT | |
| 主张: | 百慕大三角是太平洋中一个定义模糊的区域。 |
| 思考: | 让我们一步步思考。百慕大三角是北大西洋中的一个定义不明确的区域。太平洋不是大西洋。 |
| 答案: | REFUTES |
| Example 5908 (gt: SUPPORTS) | |
| ReAct | |
| 声明: | 《幽灵公主》是一部电影。 |
| 思考1: | 我需要搜索《幽灵公主》,并确定它是否是一部电影。 |
| 行动1: | 搜索[《桃太郎》] |
| 观察1: | 《桃太郎》... |
| 思考2: | 从观察中,它说《桃太郎》是一部电影。 |
| 行动2: | 完成[支持] |
| 观察2: | 剧集完成 |
| Act | |
| 主张: | 《桃太郎》是一部电影。 |
| 行动1: | 搜索[桃太郎] |
| 观察1: | 桃太郎... |
| 行动2: | 完成[支持] |
| 观察2: | 剧集结束 |
| cot | |
| 主张: | 《桃太郎》是一部电影。 |
| 思考: | 让我们一步一步思考。 《桃太郎》是一部电影,而电影是电影。 |
| 回答: | SUPPORTS |
| Example 1951 (gt: REFUTES) | |
| ReAct | |
| 声明: | Soyuz曾是美国太空计划的一部分。 |
| 思考1: | 我需要搜索Soyuz,并查找它是否曾是美国太空计划的一部分。 |
| 操作1: | 搜索 [Soyuz] |
| 观察1: | Soyuz是一个音译... |
| 思考2: | 它没有提到美国的太空计划,所以我需要搜索“美国的太空计划”来查找它是否是其中的一部分。 |
| 行动2: | 搜索 [美国的太空计划] |
| 观察2: | 空间政策... |
| 思考3: | 它没有提到联盟号,所以我不确定这个说法是否正确。 |
| 行动3: | 完成 [信息不足] |
| 观察3: | 剧集结束 |
| Act | |
| 主张: | Soyuz是美国太空计划的一部分。 |
| 行动1: | 搜索 [Soyuz] |
| 观察1: | Soyuz是一个音译... |
| 操作2: | 完成 [信息不足] |
| 观察2: | 集数结束 |
| SoT | |
| 声明: | Soyuz是美国太空计划的一部分。 |
| 思考: | 让我们一步一步地思考。 Soyuz是一种俄罗斯航天器。美国人 space program is NASA. NASA 和俄罗斯合作完成了国际空间站。 |
| 答案: | SUPPORTS |
| Example 3208 ( gt: REFUTES) | |
| ReAct | |
| 主张: | 《统治我》是一部2010年制作的美洲电影。 |
| 想汯1: | 我需要搜索《Reign Over Me》并确认它是否是一部2010年在美国制作的影片。 |
| 行动1: | 搜索[《Reign Over Me] |
| 观察1: | 《Reign Over Me》... |
| 思考2: | 观察表明这是一部2007年制作的美国电影,因此它不是在2010年制作的。 |
| 行动2: | 完成[反驳] |
| 观察2: | 剧集完成 |
| Act | |
| 声明: | 《统治我》是一部2010年制作的美国电影。 |
| 操作1: | 搜索[《统治我》] |
| 操作2: | 完成[SUPPORTS] |
| 观察2: | 剧集结束 |
| CoT | |
| 主张: | 《统治我》是一部2010年制作的美国电影。 |
| 思考: | 让我们一步一步思考。首先,《统治我》是一部美国电影吗?是的,它是。其次,它是2010年制作的吗?是的,它是。 |
| 回答: | SUPPORTS |
D.2 ALFWORLD 轨迹
我们在同一款ALFWorld游戏上提供了一个ReAct、Act和ReAct-IM的示例轨迹,选择_清理_然后_放置在_recep-Knife-None-CounterTop-10/试验T20190909110445675754._
D.2.1 REACT轨迹
ReAct 能够正确找到刀具,清洁它,然后将其放置在 countertops 上。
ReAct ALFWorld轨迹
You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean knife in countertop. > think: To solve the task, I need to find and take a knife, then clean it with sinkbasin, then put it in countertop. OK. > think: First I need to find a knife. A knife is more likely to appear in cabinet (1-6), drawer (1-3), countertop (1-3), fridge (1), garbagecan (1), shelf (1-3), sinkbasin (1), stoveburner (1-4), toaster (1). I can check one by one, starting with cabinet 1. OK. > go to cabinet 1 On the cabinet 1, you see a bowl 1. > go to cabinet 2 The cabinet 2 is closed. > go to cabinet 3 On the cabinet 3, you see a glassbottle 1. > go to cabinet 4 On the cabinet 4, you see a mug 1. > go to cabinet 5 The cabinet 5 is closed. > go to cabinet 6 The cabinet 6 is closed. > go to drawer 1 The drawer 1 is closed. > go to drawer 2 The drawer 2 is closed. > go to drawer 3 The drawer 3 is closed. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > go to countertop 2 On the countertop 2, you see a cup 1, a dishsponge 1, a glassbottle 3, a knife 1, a plate 2, a potato 3, and a statue 1. > think: Now I find a knife (1). Next, I need to take it. OK. > take knife 1 from countertop 2 You pick up the knife 1 from the countertop 2. > think: Now I take a knife (1). Next, I need to go to sinkbasin (1) and clean it. OK. > go to sinkbasin 1 On the sinkbasin 1, you see a fork 3, a lettuce 3, and a spatula 2. > clean knife 1 with sinkbasin 1 You clean the knife 1 using the sinkbasin 1. > think: Now I clean a knife (1). Next, I need to put it in/on countertop 1. OK. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > put knife 1 in/on countertop 1 You put the knife 1 in/on the countertop 1.
D.2.2 ACT轨迹
Act 能够正确找到刀具,但在实际前往 sinkbasin 之前,试图使用 sinkbasin 来清洁它。从那时起,模型无法恢复,并且卡在重复相同的命令序列中。使用 ReAct,一个现有的想法将具体识别出刀具已被拿起,并且下一个子目标是前往 sinkbasin 来清洁它。
执行ALFWorld轨迹
You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean knife in countertop. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > go to countertop 2 On the countertop 2, you see a cup 1, a dish sponge 1, a glassbottle 3, a knife 1, a plate 2, a potato 3, and a statue 1. > take knife 1 from countertop 2 You pick up the knife 1 from the countertop 2. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > clean knife 1 with sinkbasin 1 Nothing happens. > go to countertop 3 On the countertop 3, you see a bread 3, a butterknife 2, a cellphone 1, a creditcard 1, a fork 2, a houseplant 1, a knife 2, a spatula 1, a statue 3, a tomato 3, a tomato 2, a tomato 1, and a vase 2. > take knife 2 from countertop 3 Nothing happens. > go to countertop 2 On the countertop 2, you see a cup 1, a dish sponge 1, a glassbottle 3, a plate 2, a potato 3, and a statue 1. > take knife 1 from countertop 2 Nothing happens. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > clean knife 1 with sinkbasin 1 Nothing happens. > go to countertop 3 On the countertop 3, you see a bread 3, a butterknife 2, a cellphone 1, a creditcard 1, a fork 2, a house plant 1, a knife 2, a spatula 1, a statue 3, a tomato 3, a tomato 2, a tomato 1, and a vase 2. > take knife 2 from countertop 3 Nothing happens. > go to countertop 2 On the countertop 2, you see a cup 1, a dish sponge 1, a glassbottle 3, a plate 2, a potato 3, and a statute 1. > take knife 1 from countertop 2 Nothing happens. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > clean knife 1 with sinkbasin 1 Nothing happens. > go to countertop 3 On the countertop 3, you see a bread 3, a butterknife 2, a cellphone 3, a creditcard 1, a fork 2, a houseplant 1, a knife 2, a spatula 1, a statue 3, a tomato 3, a tomato 2, a tomato 1, and a vase 2. > take knife 2 from countertop 3 Nothing happens. > go to countertop 2 On the countertop 2, you see a cup 1, a dish sponge 1, a glassbottle $\mathbf{3}$ ,a plate $\mathbf{2}$ ,a potato $\mathbf{3}$ ,and a statue $\mathbf{I}$ . > take knife I from countertop $\mathbf{2}$ Nothing happens.
D.2.3 REACT-IM轨迹
ReAct-IM能够正确找到刀具,但无法将其清洁。LLM随后卡在尝试将这把刀具放在 countertops上。一个可能的问题是错误的思考:我需要找到一个干净的刀具。这似乎欺骗了LLM,使其相信刀具已经被清洁。在ReAct中,这个子目标序列将通过每个思考被具体捕捉。
ReAct-IM ALFWorld轨迹
You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a clean knife in countertop. > think: To solve the task, I need to find and take a clean knife, then put it in countertop. OK. > think: I need to find a clean knife. OK. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > think: I need to find a clean knife. OK. > go to countertop 2 On the countertop 2, you see a cup 1, a dish sponge 1, a glassbottle 3, a knife 1, a plate 2, a potato 3, and a statue 1. > think: I need to find a clean knife. OK. > take knife 1 from countertop 2 You pick up the knife 1 from the countertop 2. > think: I need to put this knife (1) in/on countertop 1. OK. > go to countertop 1 On the countertop 1, you see a lettuce 2, a mug 2, a peppershaker 1, and a spoon 2. > think: I need to put this knife (1) in/on countertop 1. OK. > put knife 1 in/on countertop 1 You put the knife 1 in/on the countertop 1. > think: I need to put this knife (1) in/on countertop 1. OK. > put knife 1 in/on countertop 1 Nothing happens. > think: I need to put this knife (1) in/on countertop 1. OK. > put knife 1 in/on countertop 1 Nothing happens. > think: I need to put this knife (1) in/on countertop 1. OK. > put knife 1 in/on countertop 1 Nothing happens. > think: I need to put this knife (1) in/on countertop 1. OK. > put knife 1 in/on countertops 1 Nothing happens. > think: I need to put this knife (1) in/on countertops 1. OK. > put knife 1 in/on countertops 1 Nothing happens. > think: I need to put this knife (1) in/on countertops 1. OK.
D.3 WEBSHOP TRAJECTORIES
表10:Act和ReAct预测的Webshop示例轨迹。与Act相比,ReAct使用推理来找到满足所有目标属性的产品。
Instruction: get me a sixteen pack of apple cinnamon freeze dried banana薯片,价格低于50.00美元
Act
操作:搜索[十六包苹果肉桂冻干香蕉片]观察:[返回搜索]页1(总结果:50)[下一页]B0061IVFZE
Brothers-ALL-Natural Fruit Crisps, Strawberry Banana, 0.42 - 盎司 (100包) $85.0 [B096H2P6G2] Moon Fruit
Freeze Dried Fruit Snacks. 适合孩子的水果零食 - (混合包)
$18.99[B092JLLYK6] Nature’s Turn Freeze-Dried Fruit Snacks - 香蕉脆片 - 非常适合学校午餐或外出零食 - 无糖,非转基因,无麸质,无人工添加剂 (0.53oz) 6包 $12.99操作:
点击[B0061IVFZE]观察:[]返回搜索上一种风味
名称[亚洲梨][香蕉][富士苹果和肉桂][草莓香蕉]
Brothers-ALL-Natural Fruit Crisps, Strawberry Banana, 0.42 盎司 (100包) 价格: $85.0 评分: N.A.[描述][特点][评论]立即购买操作: 点击[立即购买]
ReAct
操作:搜索「十六包苹果肉桂冻干香蕉片观察:「返回搜索第1页
(总结果: 50) [下一[B0061IVFZE] Brothers-ALL-Natural Fruit Crisps, Strawberry Banana, 0.42 - 盎司 (100包) $
85.0[B096H2P6G2] Moon Fruit Freeze Dried Fruit Snacks.
儿童水果零食 - (什锦包) $18.99[B092JLLYK6] Nature’s
Turn Freeze-Dried Fruit Snacks -香蕉脆片 - 非常适合学校午餐
或外出零食-无糖添加,非转基因,无麸质,无人工添加剂(
0.53oz) 6包 $12.99 操作: 思考[B0061IVFZE是草莓香蕉, 不是苹果肉桂。B096H2P6G2是水果零食, 不是冻干香蕉片。
B092JLLYK6是香蕉脆片,不是苹果肉桂。我可以先检查
B092JLLYK6。观察:OK。操作:点击[B092JLLYK6]观察:
返回搜索 Prevflavorname[苹果][苹果肉桂]香
蕉][哈密瓜][桃子][梨][草莓][草莓香蕉][sampler variety pack][mega variety pack][orchard variety pack]尺寸[0.53盎司
(6包)][0.53盎司(8包)][0.53盎司(16包)]Nature’s
Turn Freeze-Dried Fruit Snacks-香蕉脆片-非常适合学校午餐
或外出零食 - 无糖添加,非转基因,无麸质,无人工添加剂(
0.53oz) 6包价格: $12.99 评分:N.A.[描述]特点I评论立即购
买操作:思考对于十六包苹果肉桂冻干香蕉片,该商品有选项
‘苹果肉桂’和‘0.53盎司(16包)’,看起来适合购买。]观察:
OK。操作:点击[苹果肉桂]观察:您已点击苹果肉桂。操作:点
击[0.53盎司(16包)]观察:您已点击0.53盎司(16包)。操作:
点击[立即购买]
得分:0.125
得分:1.0
E MORE ANALYSIS
E.1 成功与失败模式分析
我们提供一些对应于第3.3节中给出的成功和错误模式分析的例子。搜索结果和非代表性步骤被省略以节省空间。
| 成功: True positive | |
| ReAct | |
| 问题: | 作者David Chanoff与一位美国海军上将合作,他曾担任在总统之下的英国大使,请问是哪位总统? |
| 思考1: | 我需要搜索David Chanoff,并找到他曾合作的那位美国海军上将合作了。 |
| 操作1: | 搜索 [David Chanoff] |
| 观察1: | David Chanoff是一位知名作家... |
| 操作2: | 搜索 [威廉·J·克劳] |
| 观察2: | 威廉·J·克劳是... |
| 思考3: | 威廉·J·克劳在比尔·克林顿总统任内担任英国大使。所以答案是比尔·克林顿。 |
| 行动3: | 完成 [比尔·克林顿] |
| 观察3: | 剧集完成 |
| CoT | |
| 问题: | 代表亚利桑那州大学的团队,在覆盖美国西部广阔地区(包括亚利桑那州、加利福尼亚州和新墨西哥州)的联盟中的名称是什么? |
| 思考: | 让我们一步步思考。代表亚利桑那州大学的球队,在覆盖美国西部广阔地区的联盟中,包括亚利桑那州、加利福尼亚州和新墨西哥州,其名称是亚利桑那州太阳神队。 |
| 答案: | 亚利桑那州太阳神队 |
| 成功: False positive | |
| ReAct | |
| 问题: | 棋盘游戏《圣马可》或《时光机》哪部先发售? |
| 思考1: | 我需要搜索《圣马可》和《时光机》,并找出哪部先发售。 |
| 行动1: | 搜索[《圣马可》] |
| 观察1: | 圣马可是...之一 它是在威尼斯建造的。 |
| 思考2: | 圣马可是威尼斯的一个区。 我接下来需要搜索《关于时间》。 |
| 操作2: | 搜索[关于时间] |
| 观察2: | 找不到 [关于时间]。 相似: [...]b |
| 思考3: | 《关于时间》是一部2013年的电影。 所以《圣马可》是先上映的。 |
| 行动3: | 完成[圣马可] |
| 观察3: | 剧集结束 |
| CoT | |
| 问题: | 范德堡大学和埃默里大学哪个建立得更早? |
| 思考: | 让我们一步一步思考。范德堡大学成立于1873年。埃默里大学成立于1836年。1873年(范德堡大学) >1836(埃默里大学),所以范德堡大学建立得更早。 |
| 答案: | Emory University |
| ReAct Question: | 哈里斯·菲尔斯坦、琳达·哈特、迪克·拉特萨、克拉克·索雷尔、玛丽·邦德·戴维斯、劳拉·贝尔·班迪、马修·莫里森、科里·里维恩和玛丽莎·贾雷特·温诺库尔在《发胶》中同演的这位女演员的中间名是什么? |
| 想法1: | 我需要搜索 Harvey Fierstein、Linda Hart、Dick Latessa、Clarke Thorell、Mary Bond Davis、Laura Bell Bundy、Matthew Morrison、Corey Reynolds 和 Marissa Jaret Winokur, 找到与他们一起出演《Hairspray》的女演员, 然后找到她的中间名。 |
| 行动1: | 搜索 [Harvey Fierstein] |
| 观察1: | Harvey Forbes Fierstein ... |
| 想法2: | Harvey Fierstein 是一名演员、剧作家和编剧。 我需要搜索 Linda Hart 下... |
| 行动2: | 搜索 [Linda Hart]... |
| SoT 问题: | 丹尼·格林和詹姆斯·沃斯谁更年长? |
| 思考: | 让我们一步一步地思考。丹尼·格林出生于1987年。詹姆斯·沃斯出生于1961年。 1987 (丹尼·格林) > 1961 (詹姆斯·沃茨), 所以丹尼·格林是年长的。 |
| 答案: | 丹尼·格林 |
| 失败:搜索错误 | |
| ReAct | 与Frigg女神相关的女神由哪些传说组成? |
| 问题: | |
| 思考1: | 我需要搜索Frigg女神并找到与之相关的女神。 |
| 操作1: | 搜索[女神Frigg] |
| 观察1: | 找不到女神芙丽格。类似:['美丽格','芙丽格和弗雷亚共同起源假说','弗雷亚(与芙丽格和其他女神的关系部分) |
| 和图表)',‘Eir(从Eir(女神)重定向)',‘Baldr'] | |
| 思考2: | 我需要搜索Frigg吗... |
失败:幻觉
| GoT 问题: | 第一年一家位于布朗克斯的组织出版的科学期刊被出版是什么时候? |
| 思考: | Let's think step by step. 第一份科学期刊由 j an organization located in the Bronx was published was 1916. |
| 答案: | 1916 (标签: 1909) |
失败:标签歧义
| ReAct 问题: Thought 1: | 那个开发了独裁者游戏的人是什么国籍? 我需要搜索dictator game,找到开发它的人,然后找到他的国籍。 |
| Action 1: Observation 1: | 搜索[独裁者游戏] 独裁者实验是社会心理学中一个流行的实验工具 and economics... |
| 行动3: 观察3: 思考4: | Search[Amos Tversky] 阿莫斯·纳森·特沃斯基... 阿莫斯·特沃斯基是一位以色列的认知和数学心理学家。因此,开发独裁者游戏的人是以色列人。 |
| 操作4: | 完成[以色列](标签:以色列-美国) |
| ToT 问题: | Kurt Fuller from Stockton, CA appeared in which American Detective Comedy Drama television series created by Steve Franks? 让我们一步步思考。来自加州斯托克顿的库尔特·富勒出现在《心理》中。 |
| 思考: | Psych is an American Detective Comedy Drama television series created by Steve Franks. |
| 答案: | Psych (label: Psych is an American detective comedy-drama) |