向量化编码和RAG增强搜索
向量化编码
我们要想把文本进行向量化的处理,我们需要使用redis7的新特性,所以这里我们使用DockerDesktop来进行redis的使用
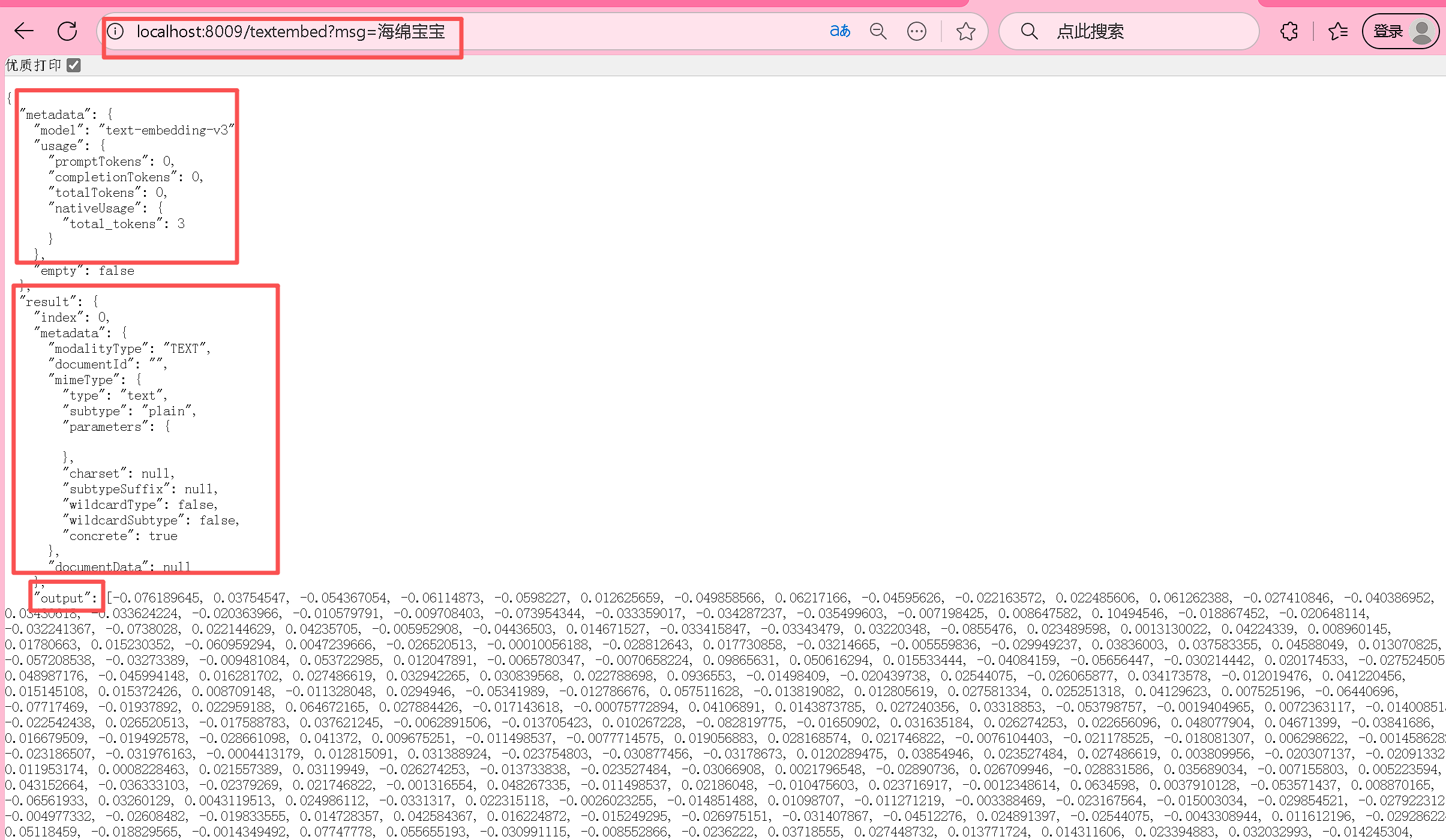
我们在配置文件里面可以定义全局的文本向量化使用的大模型,如果我们不在约束里面进行配置,那么我们也可以在控制层进行指定,效果如下:
package ai.controller;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingOptions;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
@RestController
@Slf4j
public class EmbedVectorController {@Resourceprivate EmbeddingModel embeddingModel;
@Resourceprivate VectorStore vectorStore;@GetMapping("/textembed")public EmbeddingResponse textEmbed(String msg) {EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg),DashScopeEmbeddingOptions.builder().withModel("text-embedding-v3").build()));System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));return embeddingResponse;}
}当我们进行连接成功之后,我们在浏览器进行搜索就可以得到:
我们进行文本向量化之后,更重要的是存入redisStack所以我们需要以下设置。
@GetMapping("/addVectorStore")
public void addVectorStore() {List<Document> documents = List.of(new Document("I love you"),new Document("I hate you"));vectorStore.add(documents);
}当我们调用这个方法的时候,浏览器不会返回任何的东西,但是我们可以在控制台查看redis的key'是否成功的存入。

这样我们就可以在这个地方正常的使用redis的向量化存储。
我们首先需要写一个控制台的方法
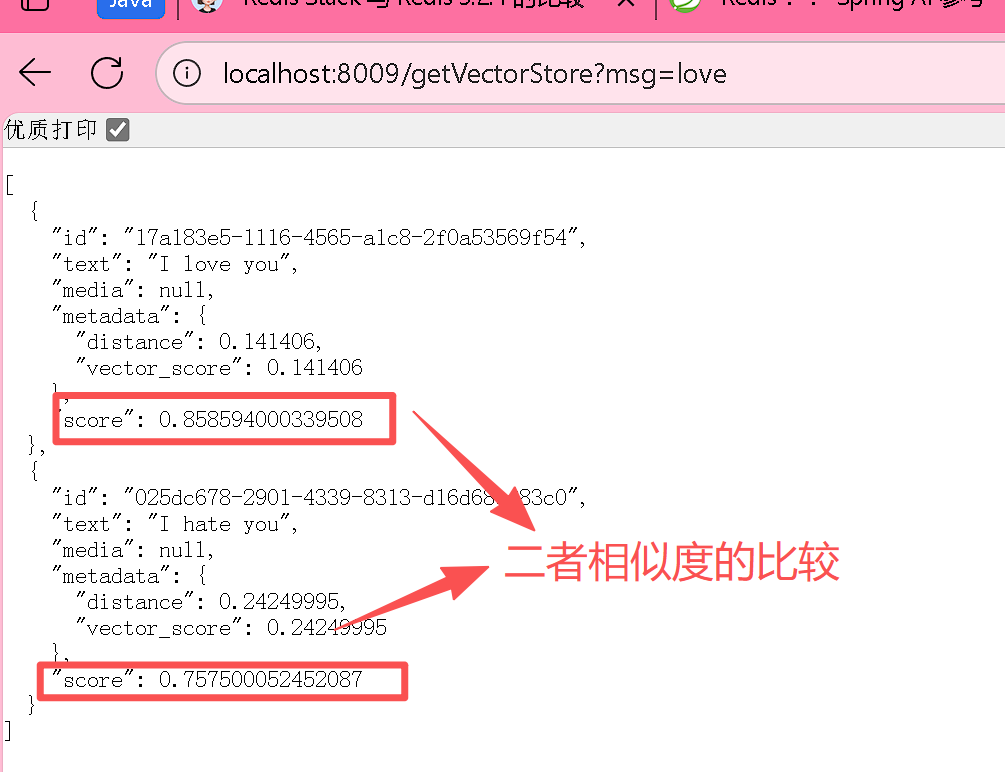
@GetMapping("/getVectorStore")
public List getAllVectorStore(@RequestParam(name = "msg") String msg) {SearchRequest searchRequest = SearchRequest.builder().query(msg).topK(5).build();List<Document> documents = vectorStore.similaritySearch(searchRequest);System.out.println(documents);return documents;
}然后我们进行访我问就可以实现这个功能。数据库里面有两条,然后我们也可以实现这个功能
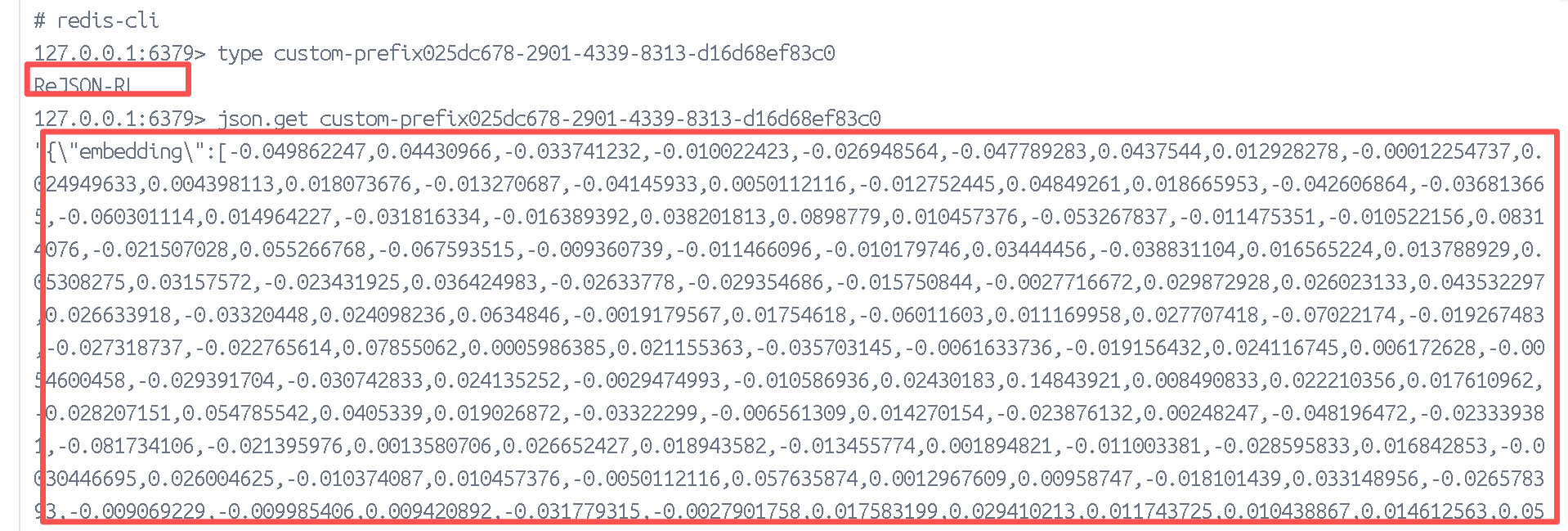
最后我们在控制台进行输入,我们可以看到redis的存储文件类型是json,下面这一串向量化的东西就被转化成java了:
RAG检索增强生成
我们在写的代码的时候,我们就会发现一个问题,经常有错误的时候,我们就会在控制台输出很多错误,无论怎么样,我们都会在AI上面进行搜索,所以无论怎么样,大模型对于你传来的错误码,比方说00000:success A0001:网络故障,A0002:系统限流,如果问AI的话,我们就会发现,会出现很多错误的提示,让我们不断的试错,所以为了解决这个LLM缺陷,因为大模型的知识并不是实时的,所以是不具备知识更新的,大模型是不知道你私有的领域和知识的,比方说不同的大模型定义的错误码是不一样的,所以生成的答案是不一样的,同时大模型会出现幻读问题,生成的问题逻辑很清楚,但是答案却是错误的。
我们在官网可以看到RAG的功能就是这样。

大模型的知识是仅限于它所接受的训练数据,所以如果我们想要让大模型了解某一个领域的知识,那么就可以使用RAG,简单来说嘛,RAG是从我们给予的数据库知识,来进行返回答案。因为大模型的幻读会出现,已读乱回的情况,所以我们就需要进行RAG的使用。
总的来说,RAG就是给我们的AI大模型装上了一个大脑,当大模型需要回答的时候就会在数据库里面进行查找,通过先查找资料然后再进行回答,让AI摆脱传统模型的遗忘和幻觉回复。
所以使用RAG需要两步走,索引和检索,首先我们需要先建立索引,建立索引的话,我们需要先将一个大的文档文件进行分割,通过设置成统一的文本格式,然后我们就可以把这些分好的块,通过嵌入式模型把这些块编码成向量进行表示,并存储在向量库当中。当我们创建索引之后就可以进行检索了,检索(Retrieval):在收到用户查询(Query)后,RAG 系统采用与索引阶段相同的编码模型将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最高k(Top-K)块,显示最大的相似性查询。
我们要想使用首先我们需要进行依赖的导入
<!--引入redisstack,也就是redis8--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-dashscope</artifactId></dependency>当我们引入依赖之后就可以在yml文件里面进行配置了
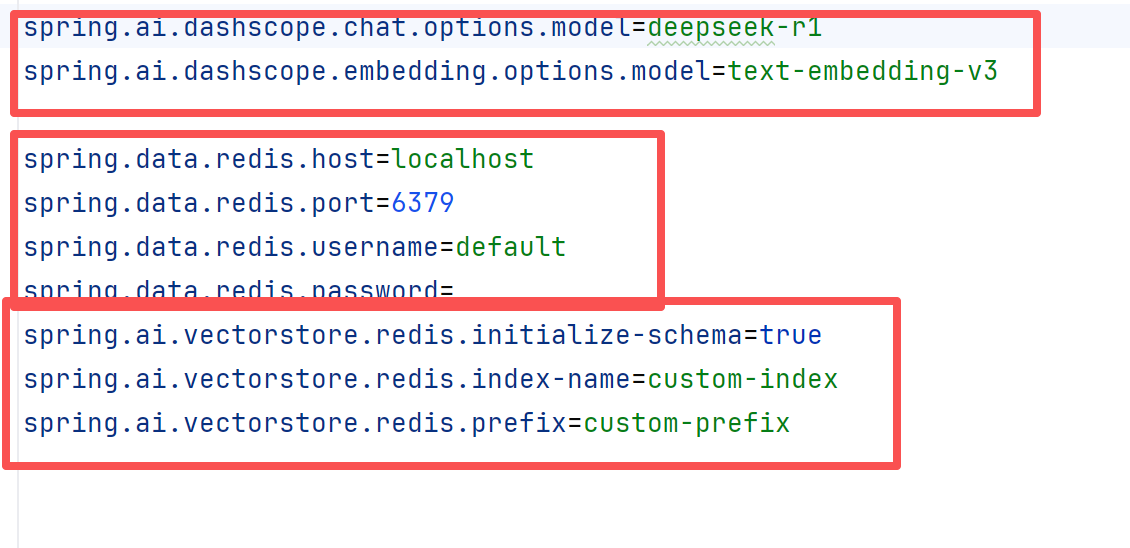
然后就可以编写配置类了,我们可以提供相对应的脚本文件,存入向量数据库RedisStack行成文档知识库。
package ai.config;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.nio.charset.Charset;
import java.util.List;
@Configuration
public class InitVectorDatabaseConfig {@Autowiredprivate VectorStore vectorStore;
@Value("classpath:ops.text")private Resource opsFile;@PostConstructpublic void init() throws Exception {//1.读取文件TextReader textReader = new TextReader(opsFile);//设置编码格式textReader.setCharset(Charset.defaultCharset());//2.读取文件内容,添加到向量数据库中List<Document> transform = new TokenTextSplitter().transform(textReader.read());//3.添加到向量数据库中vectorStore.add(transform);}
}
当我们的准备工作完成之后,就可以进行控制层的编写。
package ai.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class RagController {@Resourceprivate VectorStore vectorStore;@Resource(name = "qwenChatClient")private ChatClient chatClient;@GetMapping("/ragAIOps")public Flux<String> ragAIOps(String msg) {String systemInfo = "你是一个AI情感助手,你需要根据用户输入的查询内容,从知识库中进行搜索," +"并给出相应的答案,找不到就回复找不到信息";RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder().documentRetriever(VectorStoreDocumentRetriever.builder().vectorStore(vectorStore).build()).build();return chatClient.prompt().system(systemInfo).user( msg).advisors( advisor).stream().content();}
}注意我们在使用redis的时候它的基础配置一定要设置好。
我们围绕这个问题就可以得到我们需要的答案。

这里有个问题,当我们进行重启微服务的时候,就会出现问题,每当我们重启一次就会再一次出现向量库的编码。所以为了解决这个问题,我们就需要这样配置了:
package ai.config;import cn.hutool.crypto.SecureUtil;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.data.redis.core.RedisTemplate;import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.List;@Configuration
public class InitVectorDatabaseConfig {@Autowiredprivate VectorStore vectorStore;@Autowiredprivate RedisTemplate redisTemplate;@Value("classpath:ops.text")private Resource opsFile;@PostConstructpublic void init() throws Exception {//1.读取文件TextReader textReader = new TextReader(opsFile);//设置编码格式textReader.setCharset(StandardCharsets.UTF_8);//2.读取文件内容,添加到向量数据库中List<Document> transform = new TokenTextSplitter().transform(textReader.read());//3.添加到向量数据库中/*vectorStore.add(transform);*///解决数据重复问题String source = (String) textReader.getCustomMetadata().get("source");String s = SecureUtil.md5(source);String redisKey = "vector-xxx:" + s;//判断数据是否已经存在Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");if (Boolean.TRUE.equals(retFlag)){//数据不存在,首次插入vectorStore.add(transform);}else{System.out.println("数据已经存在");}}
}这样我们就可以看到我们设置的版本了
