从入门到实战:全面解析Protobuf的安装配置、语法规范与高级应用——手把手教你用Protobuf实现高效数据序列化与跨语言通信
文章目录
- 本篇摘要
- 一.`Protocol Buffers(Protobuf)`简介
- 1. **核心定义**
- 2. **核心作用**
- 3. **对比优势**
- 4. **使用关键点**
- 总结
- 二.`基于windows及ubuntu22.04安装Protobuf`
- `windows`
- ubuntu22.04
- 三.快速上手protobuf编写及测试
- 规范说明
- 编译命令
- 编译生成结果
- 四.proto3语法解析之字段规则与消息定义
- 五. `Protobuf 命令行decode操作`
- 六.仓库链接
- 七.本篇小结

本篇摘要
本文详解Protobuf核心:从简介、Windows/Ubuntu安装、基础语法(字段规则/消息定义)到实战(通讯录增删改查),涵盖编译命令、序列化/反序列化函数、多方式定义数组及命令行解码,助快速掌握高效数据序列化方案。
一.Protocol Buffers(Protobuf)简介
1. 核心定义
Protobuf 是 Google 开发的一种结构化数据序列化方案,用于将对象(结构化数据)高效转换为字节序列(序列化),并支持从字节序列还原对象(反序列化)。
2. 核心作用
解决痛点:
传统序列化方式(如 XML/JSON)存在数据冗余大、解析慢、扩展性差等问题。
主要场景:
- 数据存储:将结构化数据以紧凑格式持久化到磁盘或数据库。
- 网络传输:在分布式系统、微服务、RPC 通信中高效传输数据(如 gRPC 的默认序列化协议)。
3. 对比优势
| 特性 | Protobuf(PB) | 传统方式(XML/JSON) |
|---|---|---|
| 数据体积 | 更小(二进制编码,无冗余文本) | 较大(文本格式,含标签和空格) |
| 处理速度 | 更快(二进制解析效率高) | 较慢(需解析文本标签) |
| 跨语言/平台 | 支持(通过编译生成多语言代码) | 支持(但依赖文本解析库) |
| 扩展性 | 强(字段可增减且兼容旧版本) | 弱(字段变更易破坏兼容性) |
| 可读性 | 差(二进制,不可直接阅读) | 好(文本格式,可直接查看) |
4. 使用关键点
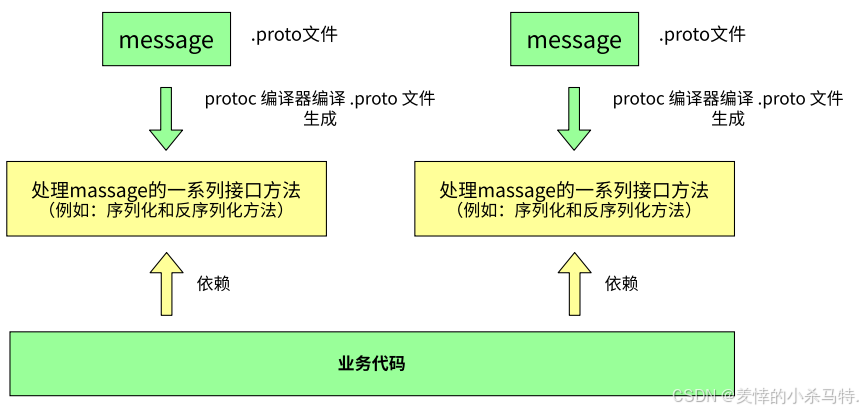
- 依赖编译生成代码:需先通过
.proto文件定义数据结构,再用 Protobuf 编译器(protoc)生成目标语言(如 C++/Java/Python)的头文件和源文件,最终在代码中调用生成的类实现序列化/反序列化。 - 典型应用:Google 内部大量服务通信、gRPC 框架的数据传输、游戏/物联网等对性能要求高的场景。
总结
Protobuf 是一种高效、紧凑、跨平台的结构化数据序列化工具,适合对性能、体积和兼容性要求较高的场景,是替代 XML/JSON 的主流方案之一。
二.基于windows及ubuntu22.04安装Protobuf
windows
点击对应连接进行下载:
https://github.com/protocolbuffers/protobuf/releases
- 这里下载对应的
v21.11版本的。
- 下载完进行解压得到对应文件。
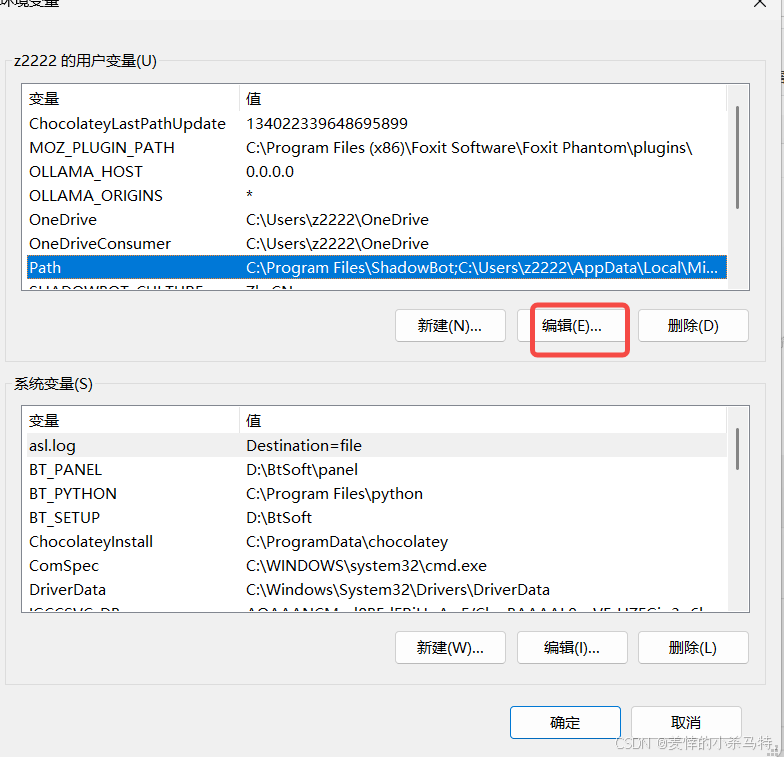
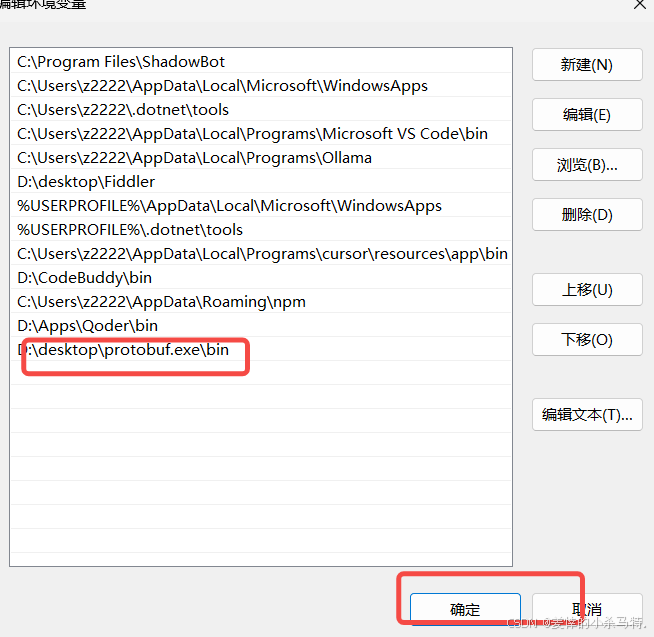
- 把对应的bin程序的路径添加进入环境变量。
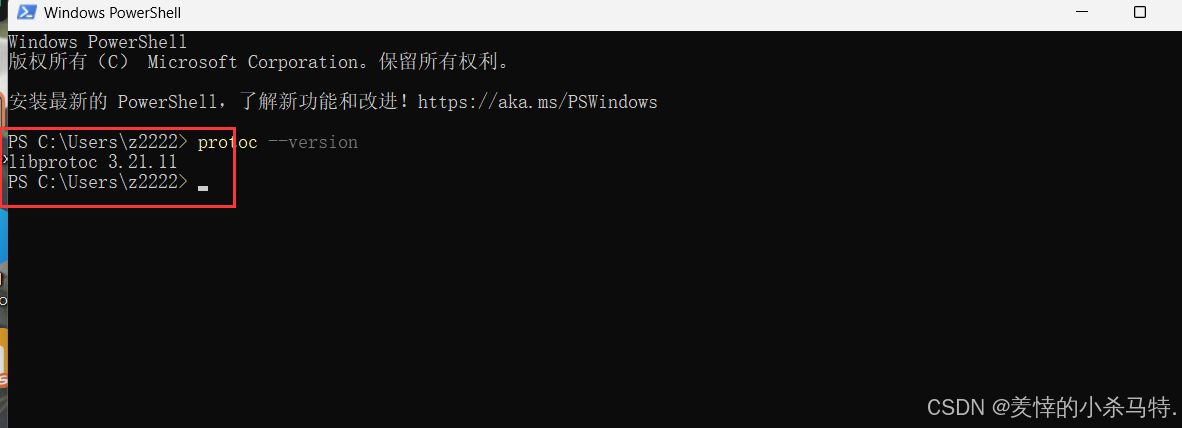
- 表明安装成功。
ubuntu22.04
首先安装对应依赖库:
sudo apt-get install autoconf automake libtool curl make g++ unzip -y
去对应官网下载v21.11版本的压缩包:
https://github.com/protocolbuffers/protobuf/releases
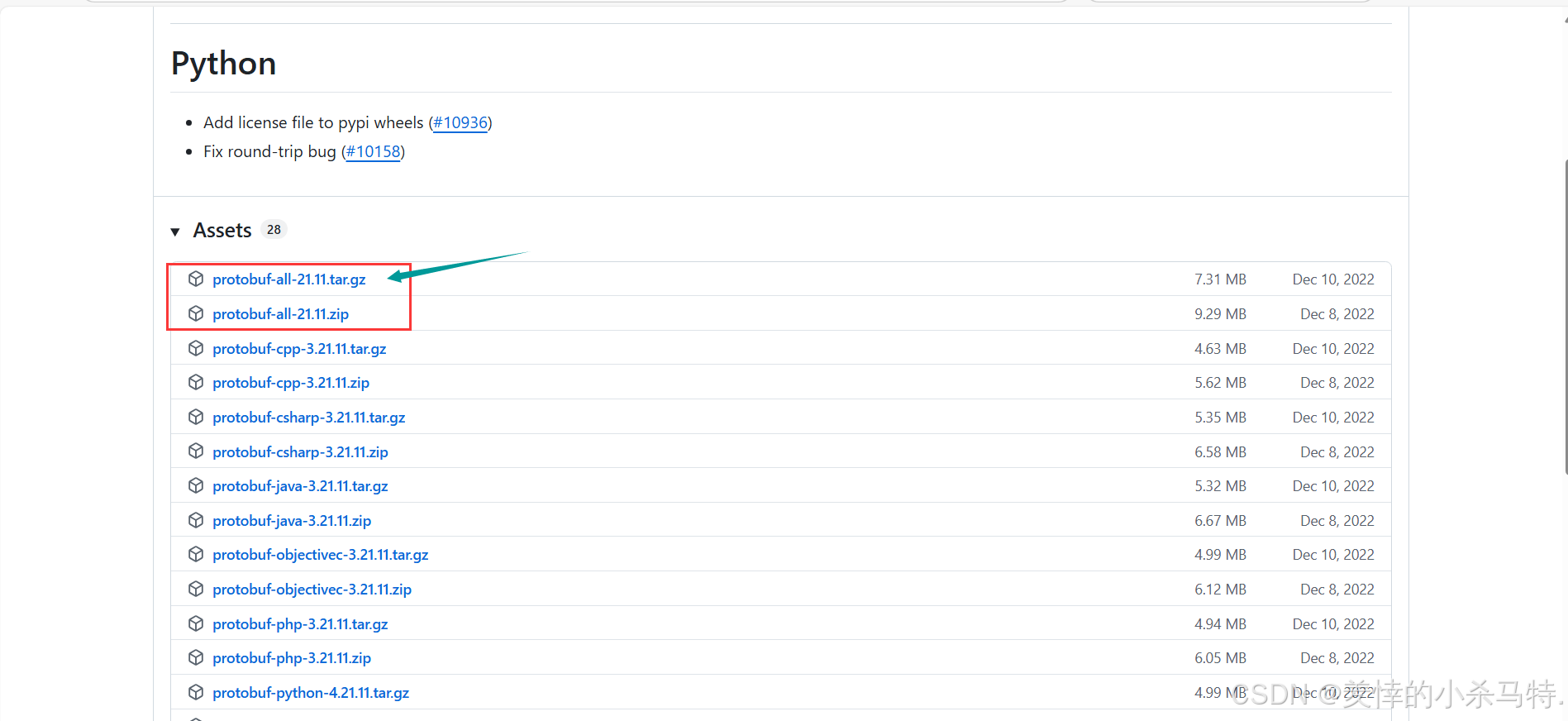
- 选择对应版本进行下载。

- 下载完后进行解压;因为下载的是多语言版本的故需要执行这个命令。
修改安装⽬录,统⼀安装在/usr/local/protobuf下: ./configure --prefix=/usr/local/protobuf:
下面进行make 以及make install安装:

- 安装到了指定目录。
因此默认路径变成指定的了故配置文件也需要更改:
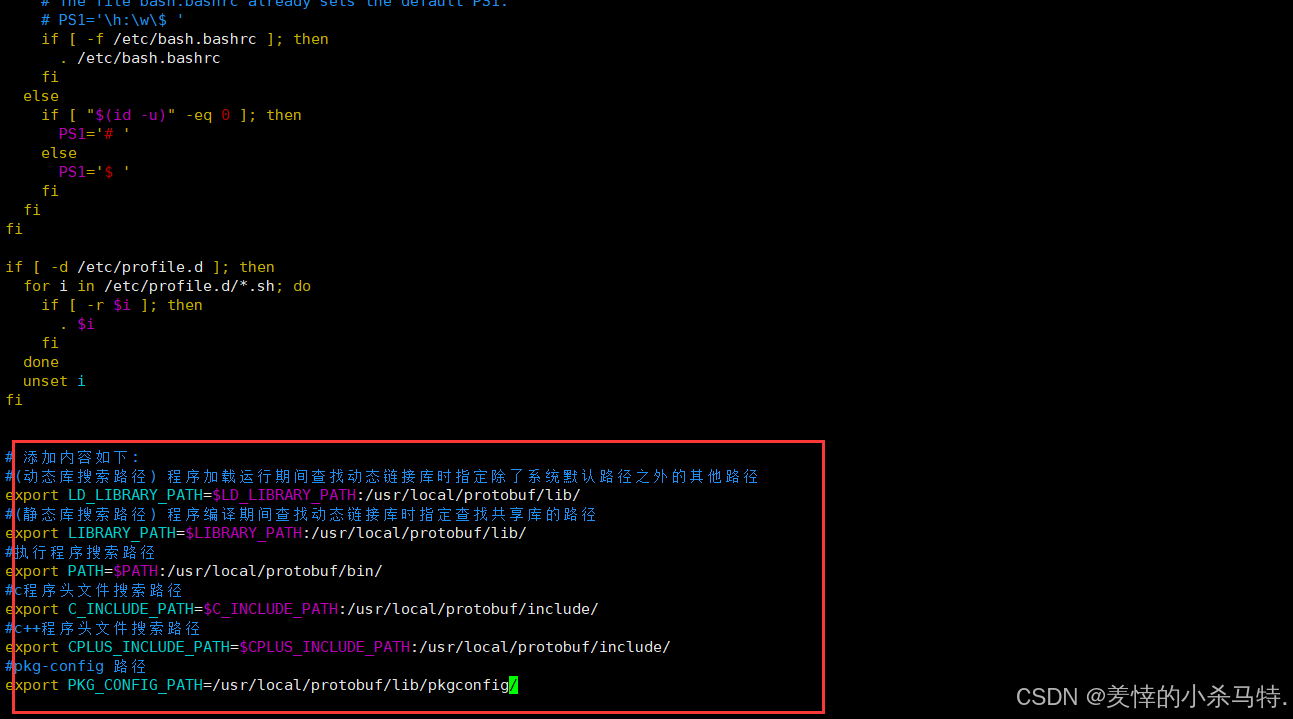
使用:sudo vim /etc/profile;然后把下面代码贴进去:
# 添加内容如下:
#(动态库搜索路径) 程序加载运行期间查找动态链接库时指定除了系统默认路径之外的其他路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/
#(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/
#执行程序搜索路径
export PATH=$PATH:/usr/local/protobuf/bin/
#c程序头文件搜索路径
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/
#c++程序头文件搜索路径
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/
#pkg-config 路径
export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/
如下:
- 然后再刷新下
source /etc/profile。
最后用 protoc --version 查看下版本即可。

- 成功安装上。
三.快速上手protobuf编写及测试
规范说明
- .proto文件规范
- 文件命名:全小写字母,用下划线连接(如
lower_snake_case.proto)。 - 代码缩进:统一使用2个空格。
- proto3语法基础
- proto3是最新语法版本,简化语言且支持多语言(如Java/C++/Python)。
- 必须在.proto文件第一行(除注释外)指定
syntax = "proto3";,否则默认使用proto2。
- package声明符
- 可选,用于定义命名空间,确保消息名称唯一性,避免冲突(如
package contacts;)。
- 消息(message)定义
- 用于定义结构化对象(如联系人),支持定制协议字段,生成类和方法供网络传输或数据存储使用。
- 消息字段定义
- 格式:
字段类型 字段名 = 字段唯一编号;。 - 字段名:全小写字母+下划线(如
contact_name)。 - 字段类型:标量类型(如int32)或特殊类型(如枚举、其他消息)。
- 编号:唯一且不可更改,用于标识字段。
- 字段编号范围限制
- 有效范围:1536,870,911(2²⁹-1),其中19000~19999为协议预留号,不可使用(使用会报错)。
- 字段编号编码规则
- 编号1~15:用1个字节编码(含编号和类型),适合高频字段。
- 编号16~2047:用2个字节编码,适合低频字段。
- 建议高频字段优先使用1~15编号以节省空间。
注:其余类型如下:
以下表格展示了定义于消息体中的标量数据类型,以及编译 .proto 文件之后自动生成的类中与之对应的字段类型。在这里展示了与 C++ 语言对应的类型。
| .proto Type | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码[1]。负数的编码效率较低 —— 若字段可能为负值,应使用 sint32 代替。 | int32 |
| int64 | 使用变长编码[1]。负数的编码效率较低 —— 若字段可能为负值,应使用 sint64 代替。 | int64 |
| uint32 | 使用变长编码[1]。 | uint32 |
| uint64 | 使用变长编码[1]。 | uint64 |
| sint32 | 使用变长编码[1]。符号整型。负值的编码效率高于常规的 int32 类型。 | int32 |
| sint64 | 使用变长编码[1]。符号整型。负值的编码效率高于常规的 int64 类型。 | int64 |
| fixed32 | 定长 4 字节。若值常大于 2^28 则会比 uint32 更高效。 | uint32 |
| fixed64 | 定长 8 字节。若值常大于 2^56 则会比 uint64 更高效。 | uint64 |
| sfixed32 | 定长 4 字节。 | int32 |
| sfixed64 | 定长 8 字节。 | int64 |
| bool | bool | |
| string | 包含 UTF-8 和 ASCII 编码的字符串,长度不能超过 2^32 。 | string |
| bytes | 可包含任意的字节序列但长度不能超过 2^32 。 | string |
[1] 变长编码是指:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数。
编译命令
protoc是 Protocol Buffer 编译工具。--proto_path(可简写为-I):指定.proto文件所在目录,不指定则搜当前目录;若文件import其他文件或文件不在当前目录,需用它指定。--cpp_out:指定编译输出为 C++ 文件,后面跟目标路径。path/to/file.proto:要编译的.proto文件。
演示如下:
对应proto文件:
//第一行必须是语法
syntax="proto3"; //默认是2;很多语言等不支持package Person;message Person{int32 age=1;string name=2;}
编译有两种方式:

注:这里由于多个proto文件如果在不同目录;其实-I后面路径可以有多个。
编译生成结果
编译 contacts.proto 文件(以 C++ 为例)会生成 contacts.pb.h 和 contacts.pb.cc 两个文件。其中,每个 message 对应一个消息类,类中包含字段的读写及操作方法;.h 存类声明,.cc 存类实现 。
下面看下.h文件:
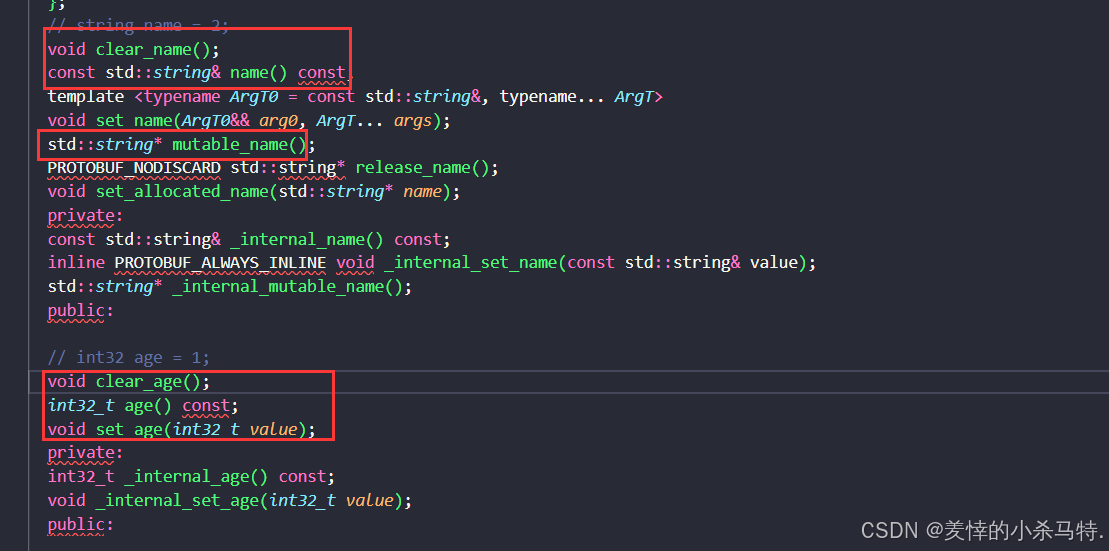
- 可以看到继承父类添加了对应的建立清空返回对应字段的函数。
- 然后就是对应的序列化与反序列化的一些函数就在对应的父类message里面;包含了它的头文件。
- 然后.cc就是对应方法的实现。
常用对应序列化与反序列化函数:
class MessageLite {
public://序列优:bool SerializeToStreamorem(ostream* output);//将序列化后数据写入文件 流bool SerializeToArray(void* data, int size) const;bool SerializeToString(string* output) const;//反序列优:bool parseFromistreamistream(istream* input);// 从流中读取数据,再进行反序列化 动作bool ParseFromArray(const void* data, int size);bool parseFromString(const string& data);
};
注意事项:
- 序列化结果是二进制字节序列(因此有的不可见),
非文本格式。 - 三种序列化方法无本质区别,仅输出格式不同,
适用场景有别。
3. 序列化API函数为const成员函数,因序列化不改变类对象内容,只将结果保存至指定地址。 - 详细message API见完整列表:官网链接。
下面演示下:
- 这里为了方便可以先安装下对应的插件。
测试程序:
#include<person.pb.h>
#include<string>
#include<iostream>int main(){Person::Person p1;p1.set_age(1);p1.set_name("张三");std::string s;bool ok= p1.SerializeToString(&s);if(!ok) std::cout<<"序列化错误"<<std::endl;std::cout<<"序列化结果: "<<s<<std::endl;Person::Person p2;p2.ParseFromString(s);std::cout<<"name: "<<p2.name()<<std::endl;std::cout<<"age: "<<p2.age()<<std::endl;return 0;
}对应结果:

- 可以看到序列化的结果存在不可见性。
小结下:
ProtoBuf 通过编写 .proto 文件定义结构对象及属性,用 protoc 编译器生成接口代码,开发时依赖这些代码实现对定义字段的操作及对象的序列化反序列化,无需手动编写协议解析代码。
四.proto3语法解析之字段规则与消息定义
基于protobuf实现的通讯录格式来讲解(protobuf的文件储存方面的应用)。
下面比如通讯录的人有多个号码;这是可以类似数组形式去定义:
这里支持四种方式来定义这个数组:
1.文件内定义电话类:
message Phone{string number=1;}然后可以直接在对应PersonInfo类使用即可。
2.定义嵌套类:
message PersonInfo{message Phone{string number=1;}
repeated Phone phone=4; //最简单的以数组形式
}
3.直接内部定义string数组:
repeated string phone_number=3 //最简单的以数组形式
4.定义在此文件外部的文件然后导入:
在使用的文件中先要导入对应文件:import "phone.proto" 支持文件导入;然后在使用即可:
repeated phone.phone phone=4 //如果是文件导入的时候要加上对应的命名空间.对应类名。
下面实现了一个只有对应的名字/年龄以及支持一个人有很多号码的基于文件的读写通讯录:
基于上面说的类套类实现的proto文件:
//第一行必须是语法
syntax="proto3"; //默认是2;很多语言等不支持package contacts;
//import "phone.proto" 支持文件导入
message PersonInfo{int32 age=1;string name=2;//repeated string phone_number=3 //最简单的以数组形式//定义内部嵌套类(也可以文件导入或者搞在此文件外部)message Phone{string number=1;}
repeated Phone phone=4; //最简单的以数组形式//repeated phone.phone phone=4 //如果是文件导入的时候要加上对应的命名空间.对应类名。}// 通讯录 message(一群联系人)
message Contacts {repeated PersonInfo contacts = 1;
}
下面进行编译:
对应的.pb.h文件:

- 这里可看到proto文件里面定义的两个类被继承父类后再次实现(这里如果是写入嵌套类就会变成
PersonInfo_Phone这样新的组成解析成C++的类)。
下面就是写与读的文件:
1.write.cc:
思路:
- 首先读取对应文件内容从流中反序列化到对应的整体protobuf对象中(如果文件不存在就直接创建);然后在对应protobuf对应继续追加(写入对应对象);然后再从对象写入文件输出流中;就到了对于文件。
对应源码:
#include <iostream>
#include <fstream>
#include "contacts.pb.h" //默认先从当前目录;然后没有再去系统对应目录
#include <string>using namespace std;void add_contacters(contacts::PersonInfo *persons)
{cout << "-------------新增联系⼈-------------" << endl;cout << "请输入联系人姓名:";string name;getline(cin, name); // 遇到缓冲区的\n默认停止并删除它persons->set_name(name);cout << "请输入联系人年龄:";int age;cin >> age; // 缓冲区留着\n需要手动清除persons->set_age(age);cin.ignore(256, '\n'); // 最大值值读取256个读到就删除完终止;没有读完256个直接终止// 输入所有的电话号码:for (int i = 0;; i++){cout << "请输入联系人电话" << i + 1 << "(只输⼊回⻋完成电话新增):";string number;getline(cin, number);// 进行是否停止的判断:if (number.empty()){break;}contacts::PersonInfo_Phone *phone = persons->add_phone();phone->set_number(number);}
}int main()
{contacts::Contacts contacts;// 读取对应二进制protobuf格式存储的文件+输入文件// 读取对应文件:std::fstream input("contacts.bin", std::ios::in | std::ios::binary); // 不存在文件自动创建if (!input){ // 不存在自动创建后对应文件指针就是nullptrstd::cout << "contacts.bin not find, create new file!" << std::endl;}// 如果对应文件存在也就是里面有内容(此时就需要加入对应对象中然后再进行添加;最后一再次从头写入:else if (!contacts.ParseFromIstream(&input)){cerr << "parse error!" << endl;input.close();return -1;}// 进行添加对应联系人:// 1.完成对应的PersonInfo数组填充:add_contacters(contacts.add_contacts()); // 对于类套类时候;必须这样添加对应没有对应set_object等操作(从对应对象成员后面的位置开始添加;也就是返回下一个的地址)// 2.写入文件:std::fstream output("contacts.bin", std::ios::out | std::ios::binary);if (!contacts.SerializeToOstream(&output)){cerr << "write error!" << endl;input.close();output.close();return -1;}cout << "write success!" << endl;input.close();output.close();return 0;
}
2.read.cc:
思路:
- 从对应的文件流反序列化到protobuf对象中;然后完成遍历打印即可
对应源码:
#include <iostream>
#include <fstream>
#include "contacts.pb.h" //默认先从当前目录;然后没有再去系统对应目录
#include <string>using namespace std;void printcontacts(contacts::Contacts cs)
{for (int i = 0; i < cs.contacts_size(); i++){cout << "\n---------------联系人" << i + 1 << "---------------" << endl;// 取出对应联系人“:contacts::PersonInfo personinfo = cs.contacts(i);cout << "联系人姓名:" << personinfo.name() << endl;cout << "联系人年龄:" << personinfo.age() << endl;for (int j = 0; j < personinfo.phone_size(); j++){contacts::PersonInfo_Phone phone = personinfo.phone(j);cout << "联系人电话" << j + 1 << ":" << phone.number()<< endl;}}
}
int main()
{contacts::Contacts contacts;// 完成读取出来到protobuf对象;然后在打印:fstream input("contacts.bin", ios::in | ios::binary);if (!contacts.ParseFromIstream(&input)){cerr << "parse error!" << endl;input.close();return -1;}printcontacts(contacts);return 0;
}
makefile:
all: write read
write:write.cc contacts.pb.ccg++ -o $@ $^ -std=c++11 -lprotobuf
read:read.cc contacts.pb.ccg++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY:clean
clean:rm -f write read
下面测试下:

- 第一次启动write;因为原来的文件没内容;故新创建然后再输入。

- 下面再次添加(就是追加了)。
- 这里发现对应的二进制文件是非文本形式存储。

- 使用对应查看二进制命令查看(可以把对应二进制转化成
16进制以及ASCII码)
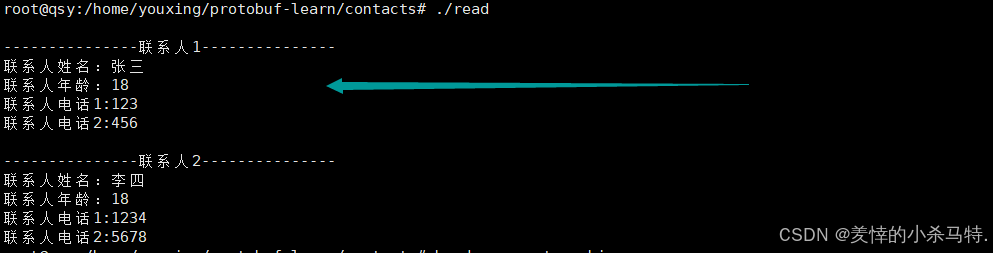
- 进行二进制文件里的内容。
五. Protobuf 命令行decode操作
命令:
protoc --decode=<命名空间+消息类型> <proto文件> < 二进制数据文件
作用:
将二进制数据(如网络传输或文件存储的 protobuf 编码内容)解码为可读文本,按 .proto 文件定义显示字段名和值。
关键点:
- 必填参数:
<命名空间+消息类型>:.proto 文件中定义的消息名称(如Person)。<proto文件>:包含该消息定义的 .proto 文件路径。
- 输入源:
- 从文件读取二进制数据(如
data.bin),或通过管道cat data.bin | protoc...直接输入。
- 输出:
- 文本形式展示解码后的字段(如
name: "Alice"),若字段缺失则不显示(值为默认值)。
注意:二进制数据必须与 .proto 定义的消息类型和字段规则严格匹配,否则解码可能失败。
下面拿上面演示过的二进制文件演示下:
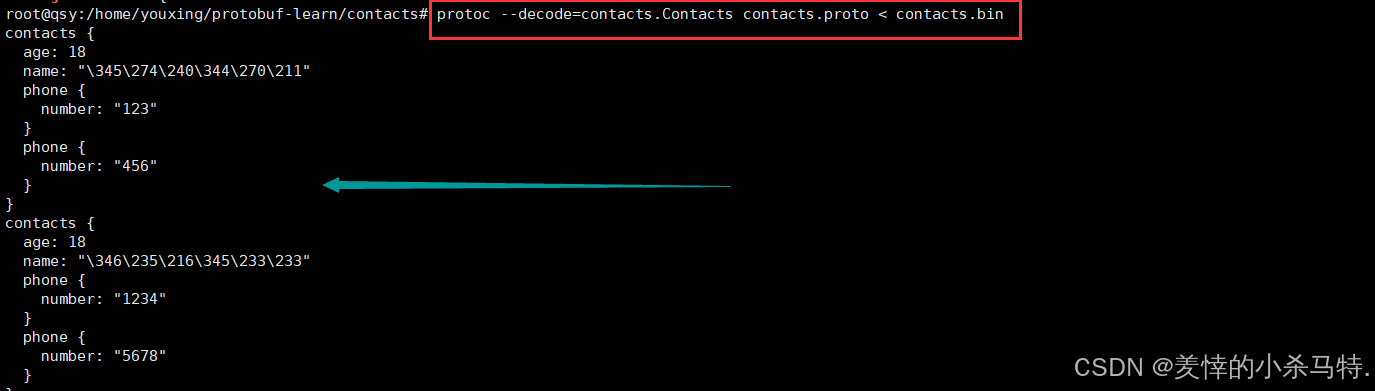
- 可以看到这里除了名字是以八进制打印出来;其他都是以易懂形式展现;方便调试。
查看其他protoc搭配的命令可以查看对应手册:
六.仓库链接
Protobuf仓库传送门
七.本篇小结
Protobuf通过.proto文件定义结构,用protoc生成多语言代码,实现高效二进制序列化。支持数组多种定义、严格字段编号规则,搭配命令行解码调试,是替代JSON/XML的高性能跨平台方案,适用于网络传输与数据存储。