【AI论文】未睹先察:揭示语言预训练赋予大语言模型视觉先验知识的奥秘
摘要:尽管大型语言模型(LLMs)仅基于文本数据进行训练,但令人惊讶的是,它们却发展出了丰富的视觉先验知识。这些先验知识使得模型仅需相对少量的多模态数据,便能解锁潜在的视觉能力以应对视觉任务;在某些情况下,甚至无需接触任何图像即可执行视觉任务。通过系统性分析,我们发现视觉先验知识——即在语言预训练过程中隐式获得的关于视觉世界的涌现知识——由可分离的感知先验和推理先验组成,二者具有独特的扩展趋势和来源。研究表明,大型语言模型潜在的视觉推理能力主要通过以推理为中心的数据(如代码、数学、学术文本)预训练发展而来,且该能力随训练逐步增强。这种从语言预训练中获得的推理先验具有可迁移性,可普遍应用于视觉推理任务。相比之下,感知先验则更广泛地源自多样化语料库,且感知能力对视觉编码器和视觉指令微调数据更为敏感。与此同时,描述视觉世界的文本虽至关重要,但其对性能的影响会迅速达到饱和。基于上述发现,我们提出了一种以数据为中心的预训练方法,用于培养具备视觉感知能力的大型语言模型,并在包含1万亿标记的预训练规模中进行了验证。我们的研究基于超过100项受控实验,这些实验消耗了50万GPU小时,覆盖了从大型语言模型预训练到视觉对齐、监督多模态微调的整个多模态大型语言模型(MLLM)构建流程,涉及五种模型规模、广泛的数据类别与混合方式,以及多种适配设置。除主要发现外,我们还提出并验证了若干假设,并引入了多层级存在性基准测试(Multi-Level Existence Bench,MLE-Bench)。本研究为从语言预训练中系统性培育视觉先验知识提供了新思路,为下一代多模态大型语言模型的发展奠定了基础。Huggingface链接:Paper page,论文链接:2509.26625
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,研究者们逐渐发现,尽管这些模型主要基于文本数据进行训练,但它们似乎能够隐式地掌握一定的视觉知识,即“视觉先验”(visual priors)。这种视觉先验使得LLMs能够在没有见过任何图像的情况下,完成一些视觉任务,如生成描述视觉场景的代码或进行简单的视觉推理。
然而,这种隐式的视觉能力是如何形成的,以及如何更有效地利用这些先验来提升多模态模型(MLLMs)的性能,仍然是未解之谜。
现有的研究多集中于通过大规模的多模态数据预训练来提升MLLMs的性能,但这种方法往往需要大量的计算资源和数据,且效果受限于多模态对齐的质量。
相比之下,利用LLMs在文本预训练过程中获得的视觉先验,可能是一种更为高效和通用的方法。因此,深入探究LLMs中的视觉先验,并探索如何有效地利用这些先验,对于推动多模态模型的发展具有重要意义。
研究目的:
本研究旨在系统地分析和揭示LLMs在文本预训练过程中获得的视觉先验的组成、来源及其对多模态任务的影响。
具体目标包括:
- 分解视觉先验:将视觉先验分解为可分离的感知和推理先验,并探究它们在LLMs中的独立性和相互作用。
- 探究数据来源:分析不同预训练数据源对视觉先验的影响,特别是推理中心数据(如代码、数学、学术文本)和视觉描述数据的作用。
- 优化预训练策略:基于上述发现,提出一种数据中心的预训练策略,以更有效地在LLMs中培养视觉先验,并验证其在多模态任务中的性能提升。
研究方法
1. 实验设计:
本研究通过一系列控制实验来探究LLMs中的视觉先验。
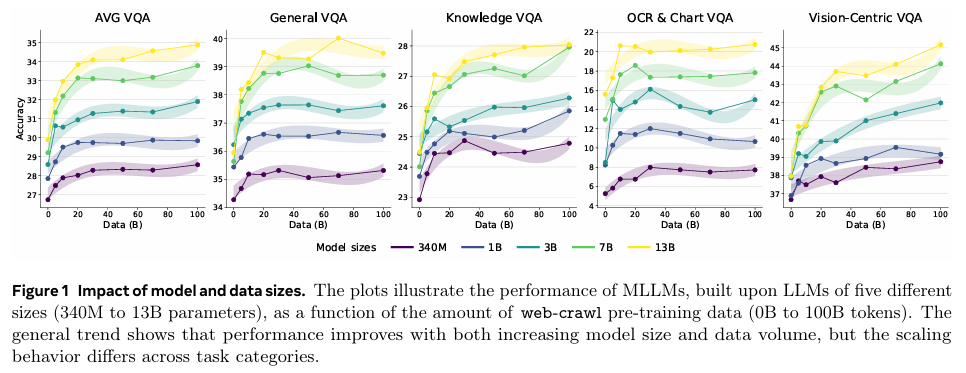
实验覆盖了从LLM预训练到视觉对齐和多模态微调的完整MLLM构建流程,涉及五个不同规模的模型(340M至13B参数)和多种预训练数据源(包括学术、艺术、生物、代码、计算机科学、经济、百科全书、法律、文学、数学、医学、哲学、政治、问答论坛和网页爬取数据)。
2. 数据分类与混合:
为了更精确地控制预训练数据中的视觉和推理内容,本研究对预训练数据进行了详细分类。具体地,将数据分为推理中心数据(代码推理、数学推理、科学推理及综合推理)和视觉世界数据(视觉概念、视觉属性、视觉关系及综合视觉)四大类,并通过调整这两类数据的比例来探究它们对视觉先验的影响。
3. 模型训练与评估:
使用AdamW优化器对LLMs进行预训练,并在预训练后进行视觉对齐和多模态微调。评估指标包括语言建模质量(困惑度)和推理能力(各类问答任务的准确率),以及多模态任务性能(如视觉问答、视觉常识推理等)。
此外,还引入了多级存在基准(MLE-Bench)来更精细地评估模型的感知能力。
4. 分析与假设验证:
通过对实验结果的深入分析,本研究验证了关于视觉先验的多个假设,包括感知先验和推理先验的可分离性、推理先验的跨模态通用性、以及数据结构对跨模态对齐的影响。
研究结果
1. 视觉先验的分解:
研究发现,LLMs中的视觉先验可以分解为感知先验和推理先验两部分。
感知先验主要源于对多样本数据的广泛暴露,而推理先验则主要通过推理中心数据的预训练逐步发展,并随着数据比例的增加而稳步提升。
2. 数据来源的影响:
实验结果表明,推理中心数据(如代码、数学和学术文本)对提升LLMs的视觉推理能力具有显著作用,而视觉描述数据则对感知能力的提升更为敏感。
通过调整这两类数据的比例,可以有效地优化LLMs的视觉先验。
3. 多模态性能提升:
基于上述发现提出的预训练策略显著提升了MLLMs在多模态任务上的性能。
特别是在视觉问答和视觉常识推理等任务上,优化后的模型表现出了更高的准确率和更强的泛化能力。
4. 假设验证:
通过引入多级存在基准(MLE-Bench)等工具,本研究验证了关于视觉先验的多个假设。
例如,推理先验确实具有跨模态的通用性,能够从文本推理任务迁移到视觉推理任务;数据结构(如结构化程度)对跨模态对齐具有重要影响等。
研究局限
尽管本研究在揭示LLMs视觉先验方面取得了重要进展,但仍存在一些局限性。
首先,实验主要基于适配器风格的多模态架构,这种架构可能限制了视觉先验在多模态任务中的充分发挥。其次,研究未涉及视觉先验的伦理和社会影响评估,如模型可能学习到的视觉偏见等。最后,实验范围主要限于静态图像任务,对于视频理解等动态模态的探索尚显不足。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
1. 探索更高效的多模态架构:
研究不同多模态架构(如端到端联合训练、离散视觉标记化等)对视觉先验利用效率的影响,寻找能够更充分发挥视觉先验潜力的模型结构。
2. 伦理和社会影响评估:
深入分析LLMs中视觉先验可能带来的伦理和社会问题,如视觉偏见的传播、隐私侵犯等,并提出相应的缓解策略。
3. 动态模态探索:
将研究范围扩展至视频理解等动态模态,探究LLMs在处理时序视觉信息时的先验能力及其形成机制。
4. 跨模态对齐机制研究:
进一步探索跨模态对齐的内在机制,理解不同模态信息在LLMs中的表示和交互方式,为构建更高效、更通用的多模态模型提供理论支持。
5. 实际应用场景拓展:
将研究成果应用于更多实际场景中,如自动驾驶、机器人导航等,验证视觉先验在复杂多模态任务中的有效性和实用性。
同时,探索如何通过持续学习和增量学习等技术,使模型能够适应不断变化的环境和任务需求。