C++----哈希以及unorder map与set的封装
哈希表继暴力查找,二分查找,搜索二叉树后的又一种的查找方法。今天主要模拟一下哈希表的开散列处理冲突法的实现。
哈希表--开散列
分析结构,哈希表的底层可以用vector来实现,存储数据:
template<class T>struct HashiNode{using Node = HashiNode;T _data;Node* _next;HashiNode(const T& data = T(), Node* next = nullptr):_data(data), _next(next){}};template<class K, class T>class hashi_bucket{using Node = HashiNode<T>;public:hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}private:vector<Node*> _table;size_t n;};
}注意,开散列的方式要对vector中的Node进行释放,因为vector不会主动释放指针类型的数据,也就是内置类型。
哈希表中,是根据插入数据的某些数字特征来计算他在哈希表中要被存储的位置,对于整形数据可以是本身与tablesize进行模运算,具有整形特征的数据都可以,比如char,double,但是string是不可以的,所以我们要对其进行处理,如何处理的更好?使用仿函数:
template<class K>struct DefaultHashFun{size_t operator()(const K& data){return data;}};//特化template<>struct DefaultHashFun<string>{size_t operator()(const string& data){size_t sum = 0;for (auto ch : data){sum += ch;ch *= 131;}return sum;}};template<class K, class T,class Fun = DefaultHashFun<K>>class hashi_bucket{using Node = HashiNode<T>;template<class K, class T, class KeyofT, class Fun>friend struct iterator;public:using iterator = iterator<K, T, KeyofT, Fun>;hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}iterator begin(){for (int i = 0; i < _table.size(); i++){if (_table[i])return iterator(_table[i], this);}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}private:vector<Node*> _table;size_t n;};
}这里特地使用了缺省参数与模板特化,与stl中保持一致,这样我们在使用时就不用显示地指定数据类型了,而且编译器也可以自己处理string的哈希值,十分方便。
接下来实现insert和erase,要想插入数据,在这种单链表的情况下一定要记录pre指针,而且一定要注意当负载因子n与table的个数相同时,就要扩容,防止效率下降。
先手写一个Find,防止插入相同的值:
bool Find(const K& data){Fun f;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_data == data)return true;cur = cur->_next;}return false;}insert,这里主要看扩容后的思想,都是头插
bool insert(const T& data){Fun f;if (Find(data))return false;//是否超载if (n / _table.size() >= 1){size_t newsize = _table.size() * 2;vector<Node*> newtable(newsize, nullptr);//顺手牵羊for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = f(cur->_data) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//插入kvsize_t hashi = f(data) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return true;}erase也是这个思想:
bool Erase(const K& data){Fun f;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];Node* pre = nullptr;while (cur){if (cur->_data == data){if (pre == nullptr){_table[hashi] = cur->_next;delete cur;}else{pre->_next = cur->_next;delete cur;}n--;return true;}pre = cur;cur = cur->_next;}return false;}看完整代码:
template<class K>struct DefaultHashFun{size_t operator()(const K& data){return data;}};//特化template<>struct DefaultHashFun<string>{size_t operator()(const string& data){size_t sum = 0;for (auto ch : data){sum += ch;ch *= 131;}return sum;}};template<class T>struct HashiNode{using Node = HashiNode;T _data;Node* _next;HashiNode(const T& data = T(), Node* next = nullptr):_data(data), _next(next){}};template<class K, class T,class Fun = DefaultHashFun<K>>class hashi_bucket{using Node = HashiNode<T>;public:hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}bool insert(const T& data){Fun f;if (Find(data))return false;//是否超载if (n / _table.size() >= 1){size_t newsize = _table.size() * 2;vector<Node*> newtable(newsize, nullptr);//顺手牵羊for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = f(cur->_data) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//插入kvsize_t hashi = f(data) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return true;}bool Erase(const K& data){Fun f;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];Node* pre = nullptr;while (cur){if (cur->_data == data){if (pre == nullptr){_table[hashi] = cur->_next;delete cur;}else{pre->_next = cur->_next;delete cur;}n--;return true;}pre = cur;cur = cur->_next;}return false;}bool Find(const K& data){Fun f;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_data == data)return true;cur = cur->_next;}return false;}void Print(){Fun f;for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];printf("%d:", i);while (cur){printf("%d-->", cur->_data);cur = cur->_next;}printf("nullptr");cout << endl;}cout << endl;}private:vector<Node*> _table;size_t n;};
}封装unorder_map与set
unorder_map与set,顾名思义,是没有顺序要求的map和set,正是因为存储的数据结构为哈希表所以才无序。使用上述实现的哈希表来实现unorder_map与set。
泛型
如何用一个模板就能封装存储一个数据的set与pair的map?使用模板参数来表示存储的数据类型。由于set的节点中存储的是单个数据,而map中是pair,所以为了支持泛型,要写一个仿函数取出数据中的key。
//unorder_set.htemplate<class K>class unorder_set{public:struct SetofT{const K& operator()(const K& data){return data;}};bool insert(const K& data){return _ht.insert(data);}bool erase(const K& data){return _ht.Erase(data);}private:hashi_bucket<K, K, SetofT> _ht;};//unorder_map.htemplate<class K, class V>class unorder_map{public:struct MapofT{const K& operator()(const pair<K, V>& data){return data.first;}};bool insert(const pair<K, V>& data){return _ht.insert(data);}bool erase(const K& key){return _ht.Erase(key);}private:hashi_bucket<K, pair<K,V>, MapofT> _ht;};//hash.htemplate<class K, class T, class KeyofT, class Fun = DefaultHashFun<K>>class hashi_bucket{using Node = HashiNode<T>;public:hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}bool insert(const T& data){Fun f;KeyofT kt;if (Find(kt(data)))return false;//是否超载if (n / _table.size() >= 1){size_t newsize = _table.size() * 2;vector<Node*> newtable(newsize, nullptr);//顺手牵羊for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = f(kt(cur->_data)) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//插入kvsize_t hashi = f(kt(data)) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return true;}bool Erase(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];Node* pre = nullptr;while (cur){if (kt(cur->_data) == data){if (pre == nullptr){_table[hashi] = cur->_next;delete cur;}else{pre->_next = cur->_next;delete cur;}n--;return true;}pre = cur;cur = cur->_next;}return false;}bool Find(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == data)return true;cur = cur->_next;}return false;}void Print(){Fun f;KeyofT kt;for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];printf("%d:", i);while (cur){printf("%d-->", kt(cur->_data));cur = cur->_next;}printf("nullptr");cout << endl;}cout << endl;}private:vector<Node*> _table;size_t n;};迭代器
接下来写迭代器,实现哈希迭代器比较麻烦的地方就是++,怎么处理呢?这涉及到找下一个有效值,要在哈希表中的_table上找,所以迭代器中需要一个当前哈希表的指针!来直接访问_table的数据。但是这里又有一个问题,哈希表中使用迭代器,而迭代器中又存放哈希表指针!这涉及到了相互依赖,如何解决?只需要在迭代器的定义前声明一下哈希表就ok,可以通过编译!由于要访问哈希表中的table,在前面我们把它定义为了私有成员,所以在这里要把迭代器写成哈希表的友元类!看具体实现:
//声明template<class K, class T, class KeyofT, class Fun>class hashi_bucket;template<class K, class T, class KeyofT, class Fun = DefaultHashFun<K>>struct iterator{using Node = HashiNode<T>;typedef iterator<K, T, KeyofT, Fun> self;Node* _node; hashi_bucket<K, T, KeyofT, Fun>* pht;iterator(Node* node, hashi_bucket<K, T, KeyofT, Fun>* ptr):_node(node),pht(ptr){}T& operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}self& operator++(){if (_node->_next){_node = _node->_next;return *this;}else{KeyofT kt;Fun f;size_t hashi = f(kt(_node->_data)) % pht->_table.size();size_t cur = hashi+1;while (cur < pht->_table.size()){if (pht->_table[cur]){_node = pht->_table[cur];return *this;}cur++;}}_node = nullptr;return *this;}bool operator==(const self& it){return _node == it._node;}bool operator!=(const self& it){return _node != it._node;}};template<class K, class T, class KeyofT, class Fun = DefaultHashFun<K>>class hashi_bucket{using Node = HashiNode<T>;//模板的友元类要加上模板参数template<class K, class T, class KeyofT, class Fun>friend struct iterator;public:using iterator = iterator<K, T, KeyofT, Fun>;hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}iterator begin(){for (int i = 0; i < _table.size(); i++){if (_table[i])return iterator(_table[i], this);}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}bool insert(const T& data){Fun f;KeyofT kt;if (Find(kt(data)))return false;//是否超载if (n / _table.size() >= 1){size_t newsize = _table.size() * 2;vector<Node*> newtable(newsize, nullptr);//顺手牵羊for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = f(kt(cur->_data)) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//插入kvsize_t hashi = f(kt(data)) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return true;}bool Erase(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];Node* pre = nullptr;while (cur){if (kt(cur->_data) == data){if (pre == nullptr){_table[hashi] = cur->_next;delete cur;}else{pre->_next = cur->_next;delete cur;}n--;return true;}pre = cur;cur = cur->_next;}return false;}bool Find(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == data)return true;cur = cur->_next;}return false;}void Print(){Fun f;KeyofT kt;for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];printf("%d:", i);while (cur){printf("%d-->", kt(cur->_data));cur = cur->_next;}printf("nullptr");cout << endl;}cout << endl;}private:vector<Node*> _table;size_t n;};
}
template<class K>class unorder_set{public:struct SetofT{const K& operator()(const K& data){return data;}};typedef typename wzz::hashi_bucket<K, K, SetofT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}bool insert(const K& data){return _ht.insert(data);}bool erase(const K& data){return _ht.Erase(data);}private:hashi_bucket<K, K, SetofT> _ht;};
template<class K, class V>class unorder_map{public:struct MapofT{const K& operator()(const pair<K, V>& data){return data.first;}};typedef typename wzz::hashi_bucket<K, pair<K, V>, MapofT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}bool insert(const pair<K, V>& data){return _ht.insert(data);}bool erase(const K& key){return _ht.Erase(key);}private:hashi_bucket<K, pair<K,V>, MapofT> _ht;};set与map的key不能改变的问题
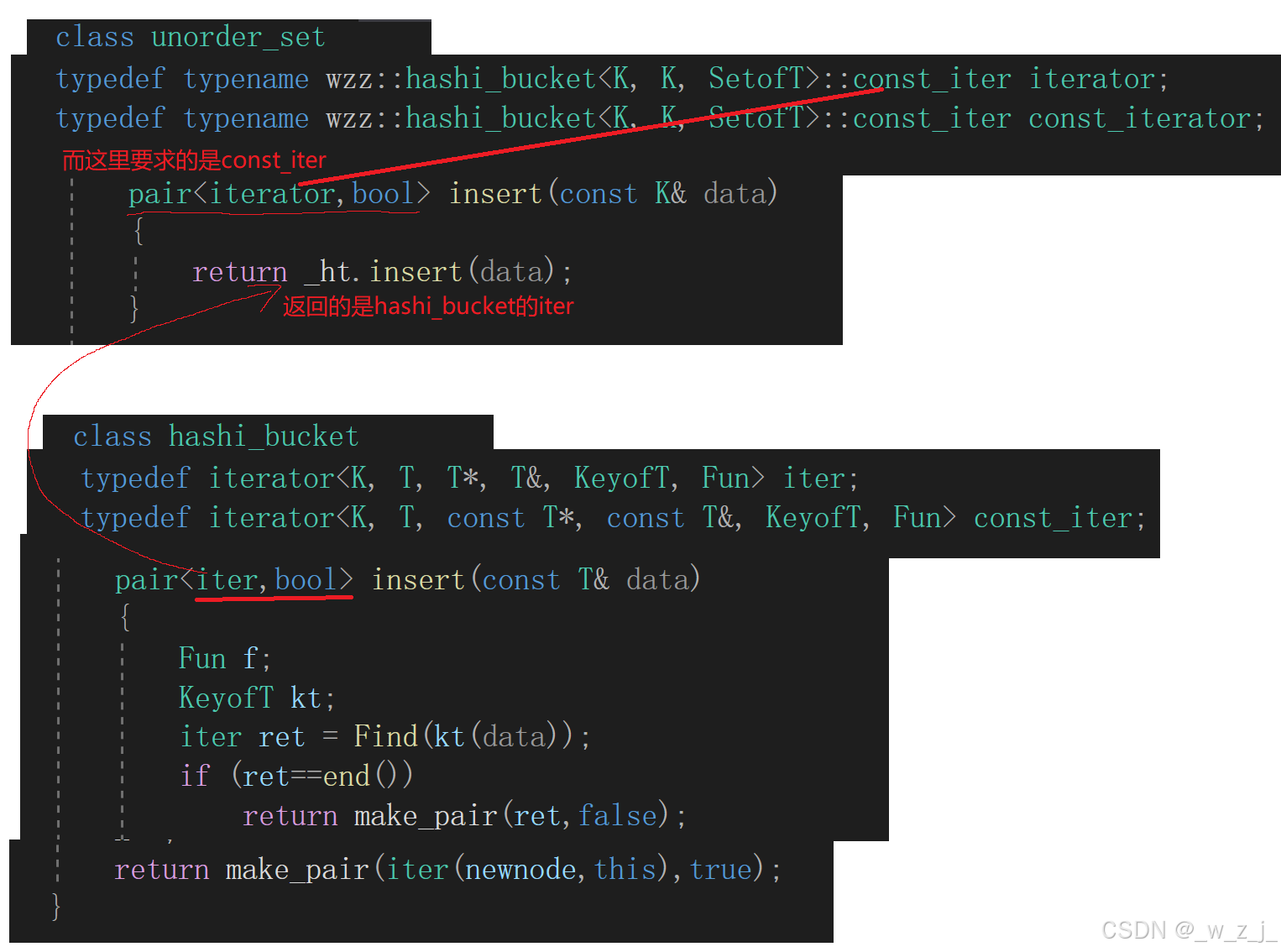
set与map中的key不允许改变。这是规定的,如何进行处理?与红黑树封装set和map的方法差不多。unorder_set设置两个迭代器,但其实都复用了哈希中const迭代器,unorder_map只需要将pair中K设置为const类型即可。
template<class K>class unorder_set{public:struct SetofT{const K& operator()(const K& data){return data;}};typedef typename wzz::hashi_bucket<K, K, SetofT>::const_iter iterator;typedef typename wzz::hashi_bucket<K, K, SetofT>::const_iter const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const K& data){return _ht.insert(data);}bool erase(const K& data){return _ht.Erase(data);}private:hashi_bucket<K, K, SetofT> _ht;};
template<class K, class V>class unorder_map{public:struct MapofT{const K& operator()(const pair<K, V>& data){return data.first;}};typedef typename wzz::hashi_bucket<K, pair<const K, V>, MapofT>::iter iterator;typedef typename wzz::hashi_bucket<K, pair<const K, V>, MapofT>::const_iter const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& data){return _ht.insert(data);}bool erase(const K& key){return _ht.Erase(key);}private:hashi_bucket<K, pair<const K,V>, MapofT> _ht;};在这里更新insert的返回值,与stl中保持一致,这样的话就会出现问题,复用函数返回类型与要求返回类型不一致,类型不一样就会报错,因为这是两个模板实例化出来的对象,类型肯定是不一样的。虽然这两个类型不一样,但却是有联系的,const迭代器和普通迭代器,虽然是自定义类型,但是与内置类型很相似,我们可以自己实现一个函数,使得普通迭代器可以转换成const迭代器。
一个构造函数
其实stl中也是这么实现的,仔细观察这个函数,我们知道,迭代器的拷贝构造函数使用默认生成的即可,因为默认生成的浅拷贝就已经满足我们的使用要求了,本来浅拷贝节点和哈希表指针就行。但是这里为什么还是写了一个酷似拷贝构造的函数呢?如果类型是self,那就是拷贝构造!但是却是iter。我们来分析一下。
template<class K, class T, class PTR, class REF, class KeyofT, class Fun = DefaultHashFun<K>>struct iterator{using Node = HashiNode<T>;typedef iterator<K, T,PTR,REF, KeyofT, Fun> self;typedef iterator<K, T, T*, T&, KeyofT, Fun> iter;Node* _node; hashi_bucket<K, T, KeyofT, Fun>* pht;//构造函数iterator(const iter& it):_node(it._node),pht(it.pht){}//........
所以这个既可以用来转换成const_iter,满足stl中的规则,又可以作为iter类型的拷贝构造函数。这样我们在unorderset中复用insert就不会再报错。
unorder_map的operator[]
我们希望调用operator[]可以修改对应key的value值,同时也希望如果不存在key的值那么插入一个值,这时仍需要调用insert,体现了它的返回值从原来bool到pair的优越性,可以拿到已经存在的,和刚插入的节点的值:
V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}全部代码:
hash.h
#include<iostream>
#include<vector>
using namespace std;namespace wzz
{template<class K>struct DefaultHashFun{size_t operator()(const K& data){return data;}};//特化template<>struct DefaultHashFun<string>{size_t operator()(const string& data){size_t sum = 0;for (auto ch : data){sum += ch;ch *= 131;}return sum;}};template<class T>struct HashiNode{using Node = HashiNode;T _data;Node* _next;HashiNode(const T& data = T(), Node* next = nullptr):_data(data), _next(next){}};//声明template<class K, class T, class KeyofT, class Fun>class hashi_bucket;template<class K, class T, class PTR, class REF, class KeyofT, class Fun = DefaultHashFun<K>>struct iterator{using Node = HashiNode<T>;typedef iterator<K, T,PTR,REF, KeyofT, Fun> self;typedef iterator<K, T, T*, T&, KeyofT, Fun> iter;Node* _node; hashi_bucket<K, T, KeyofT, Fun>* pht;iterator(Node* node, hashi_bucket<K, T, KeyofT, Fun>* ptr):_node(node),pht(ptr){}iterator(const iter& it):_node(it._node),pht(it.pht){}REF operator*(){return _node->_data;}PTR operator->(){return &(_node->_data);}self& operator++(){if (_node->_next){_node = _node->_next;return *this;}else{KeyofT kt;Fun f;size_t hashi = f(kt(_node->_data)) % pht->_table.size();size_t cur = hashi+1;while (cur < pht->_table.size()){if (pht->_table[cur]){_node = pht->_table[cur];return *this;}cur++;}}_node = nullptr;return *this;}bool operator==(const self& it){return _node == it._node;}bool operator!=(const self& it){return _node != it._node;}};template<class K, class T, class KeyofT, class Fun = DefaultHashFun<K>>class hashi_bucket{using Node = HashiNode<T>;template<class K, class T,class PTR,class REF, class KeyofT, class Fun>friend struct iterator;public:typedef iterator<K, T, T*, T&, KeyofT, Fun> iter;typedef iterator<K, T, const T*, const T&, KeyofT, Fun> const_iter;hashi_bucket(size_t size = 10){_table.resize(size, nullptr);n = 0;}hashi_bucket(const hashi_bucket& hb){_table.resize(hb._table.size(), nullptr);for (int i = 0; i < hb._table.size(); i++){Node* cur = hb._table[i];Node* pre = nullptr;while (cur){Node* newnode = new Node(cur->_data);if (pre == nullptr){_table[i] = newnode;}else{pre->_next = newnode;}pre = newnode;cur = cur->_next;n++;}}}~hashi_bucket(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}n = 0;}iter begin(){for (int i = 0; i < _table.size(); i++){if (_table[i])return iter(_table[i], this);}return iter(nullptr, this);}iter end(){return iter(nullptr, this);}pair<iter,bool> insert(const T& data){Fun f;KeyofT kt;iter ret = Find(kt(data));if (ret!=end())return make_pair(ret,false);//是否超载if (n / _table.size() >= 1){size_t newsize = _table.size() * 2;vector<Node*> newtable(newsize, nullptr);//顺手牵羊for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t newhashi = f(kt(cur->_data)) % newsize;cur->_next = newtable[newhashi];newtable[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//插入kvsize_t hashi = f(kt(data)) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return make_pair(iter(newnode,this),true);}bool Erase(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];Node* pre = nullptr;while (cur){if (kt(cur->_data) == data){if (pre == nullptr){_table[hashi] = cur->_next;delete cur;}else{pre->_next = cur->_next;delete cur;}n--;return true;}pre = cur;cur = cur->_next;}return false;}iter Find(const K& data){Fun f;KeyofT kt;size_t hashi = f(data) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == data)return iter(cur,this);cur = cur->_next;}return iter(nullptr,this);}void Print(){Fun f;KeyofT kt;for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];printf("%d:", i);while (cur){printf("%d-->", kt(cur->_data));cur = cur->_next;}printf("nullptr");cout << endl;}cout << endl;}private:vector<Node*> _table;size_t n;};
}unorder_set.h
#include"hash.h"
namespace wzz
{template<class K>class unorder_set{public:struct SetofT{const K& operator()(const K& data){return data;}};typedef typename wzz::hashi_bucket<K, K, SetofT>::const_iter iterator;typedef typename wzz::hashi_bucket<K, K, SetofT>::const_iter const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const K& data){return _ht.insert(data);}bool erase(const K& data){return _ht.Erase(data);}private:hashi_bucket<K, K, SetofT> _ht;};
}unorder_map.h
#include"hash.h"
namespace wzz
{template<class K, class V>class unorder_map{public:struct MapofT{const K& operator()(const pair<K, V>& data){return data.first;}};typedef typename wzz::hashi_bucket<K, pair<const K, V>, MapofT>::iter iterator;typedef typename wzz::hashi_bucket<K, pair<const K, V>, MapofT>::const_iter const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& data){return _ht.insert(data);}bool erase(const K& key){return _ht.Erase(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}private:hashi_bucket<K, pair<const K,V>, MapofT> _ht;};
}